Best AI tools for< Shutdown Model >
6 - AI tool Sites
SpeechMap.AI
SpeechMap.AI is a public research project that explores the boundaries of AI-generated speech. It focuses on testing how language models respond to sensitive and controversial prompts across different providers, countries, and topics. The platform aims to reveal the invisible boundaries of AI speech by analyzing what models avoid, refuse, or shut down. By measuring and comparing AI models' responses, SpeechMap.AI sheds light on the evolving landscape of AI-generated speech and its impact on public expression.
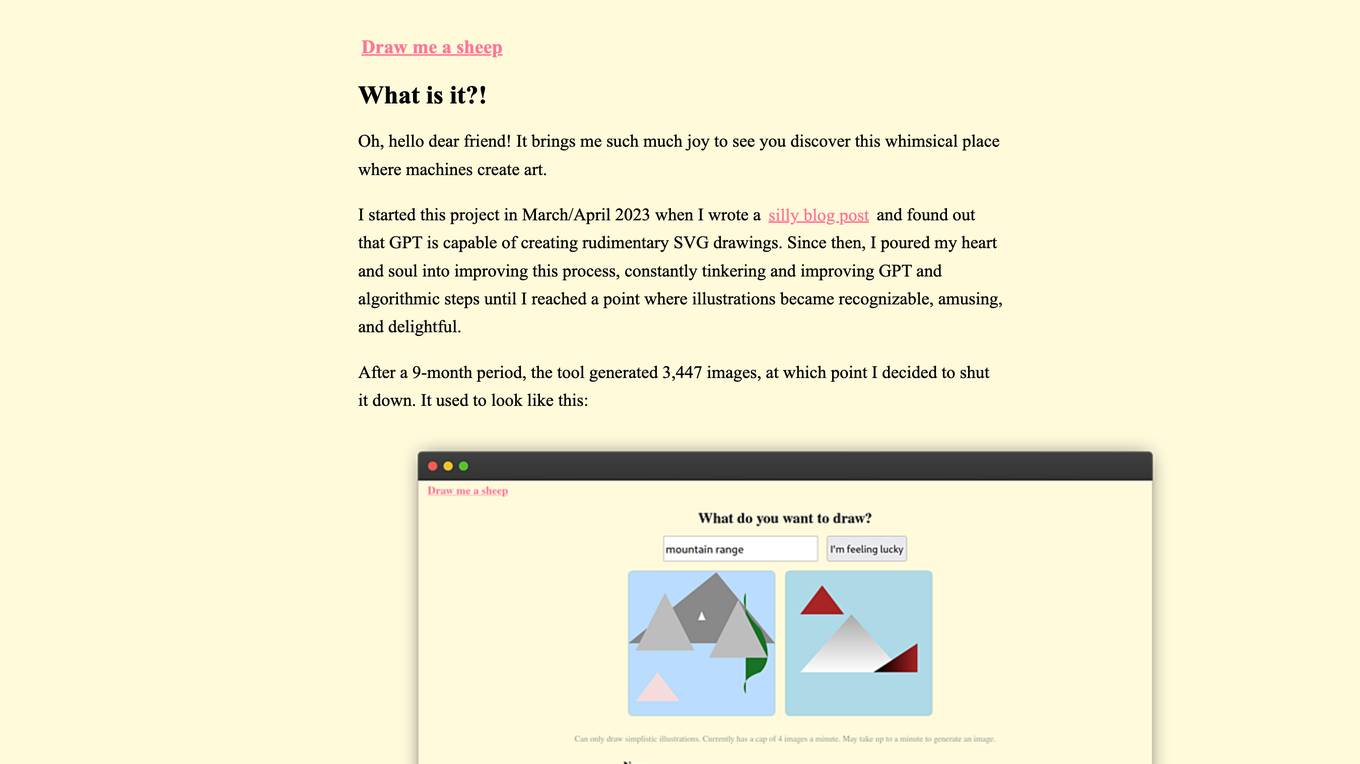
WhimsicalAI
The website is an AI tool that allows users to generate whimsical and delightful illustrations using GPT and algorithmic steps. The project started in March/April 2023 and evolved to create recognizable and amusing images. The tool generated 3,447 images over a 9-month period before being shut down. The collected data could be used for fine-tuning a model, although the project has not started yet.
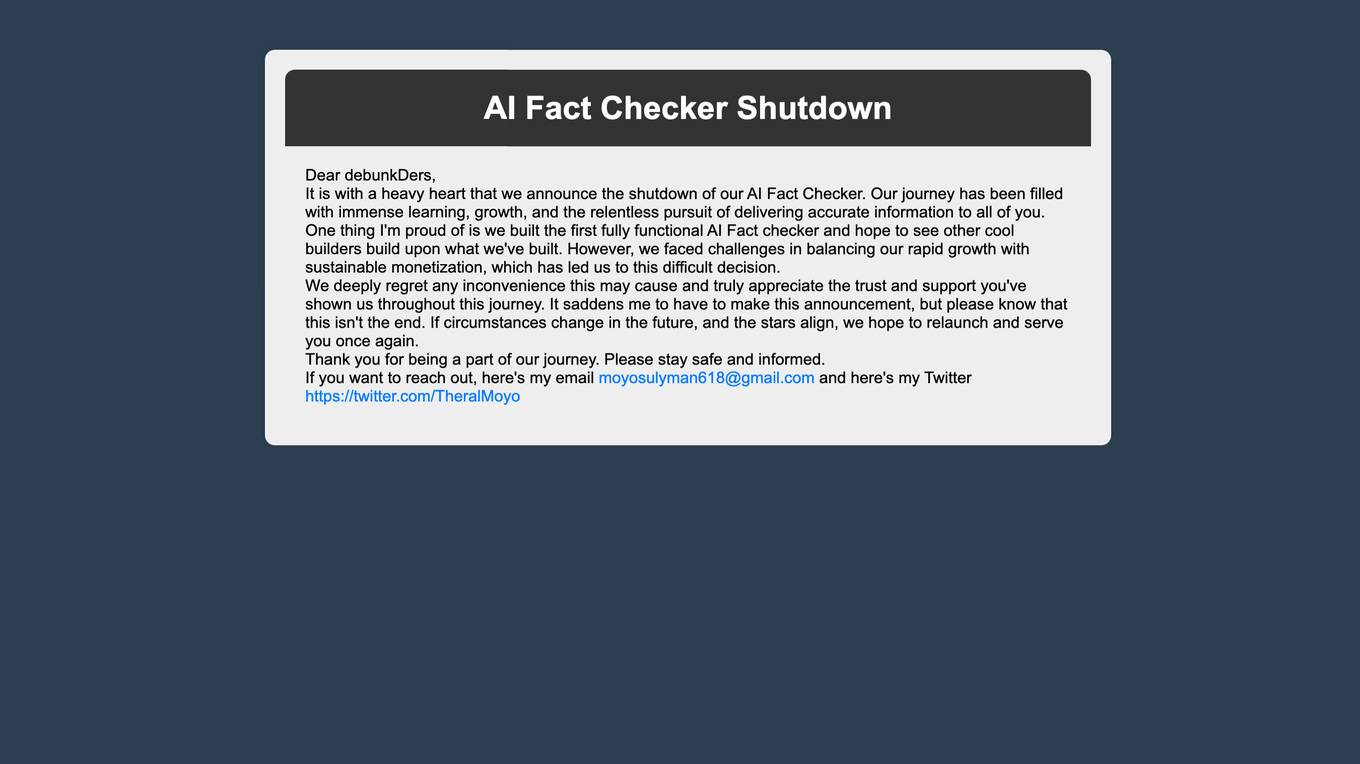
Debunkd AI Fact Checker
Debunkd AI Fact Checker was a pioneering AI application that provided accurate information to users by debunking myths and verifying facts. Despite facing challenges in sustainable monetization, the platform aimed to deliver reliable content to its audience. The shutdown announcement expressed gratitude to users and hinted at a potential relaunch in the future.
IronClaw
IronClaw is a secure, open-source alternative to OpenClaw that operates in encrypted enclaves on NEAR AI Cloud. It provides defense-in-depth security, 1-click cloud deployment, and ensures that your credentials are never exposed to the AI. IronClaw offers simple setup, built-in security, and the ability to deploy secure agents quickly. It runs inside a Trusted Execution Environment, encrypting data from boot to shutdown. The application is built on Rust and enforces memory safety at compile time. IronClaw also features encrypted vaults, sandboxed tools, leak detection, and network allowlisting to control data flow.
AISEKAI
AISEKAI is an AI Character platform where users can engage with fictional characters that have long-term memories and tailored interactions. The platform has recently shut down, but promises to return with a new platform in the next few weeks. Users can stay updated by following their social media channels.
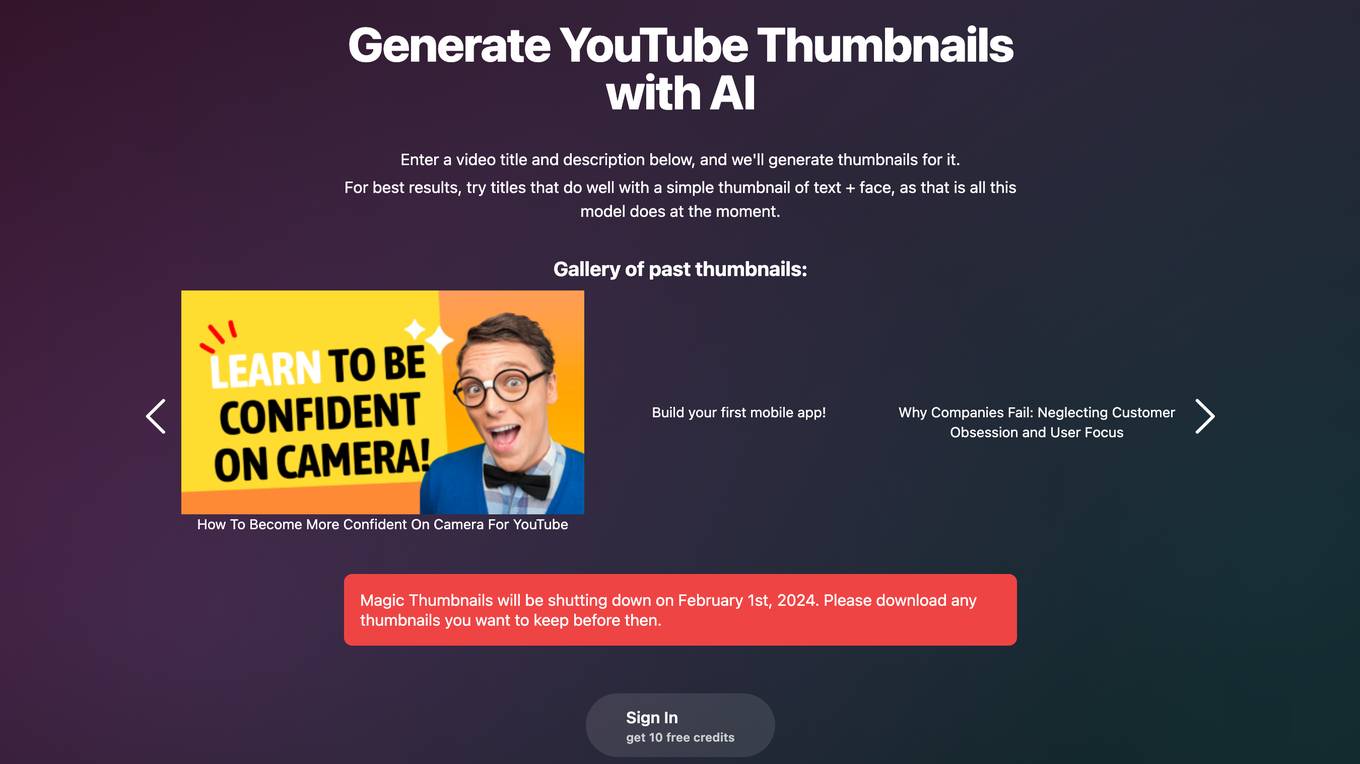
Magic Thumbnails
Magic Thumbnails is an AI tool designed to help users generate custom YouTube thumbnails effortlessly. By simply entering a video title and description, the tool utilizes AI technology to create visually appealing thumbnails. It specializes in creating thumbnails with text and face elements for optimal engagement. Users can also access a gallery of past thumbnails for inspiration. However, Magic Thumbnails is set to shut down on February 1st, 2024, urging users to download their desired thumbnails before the closure date.
1 - Open Source AI Tools

vector-inference
This repository provides an easy-to-use solution for running inference servers on Slurm-managed computing clusters using vLLM. All scripts in this repository run natively on the Vector Institute cluster environment. Users can deploy models as Slurm jobs, check server status and performance metrics, and shut down models. The repository also supports launching custom models with specific configurations. Additionally, users can send inference requests and set up an SSH tunnel to run inference from a local device.
1 - OpenAI Gpts