Best AI tools for< Scale Gpu Operations >
20 - AI tool Sites
NVIDIA Run:ai
NVIDIA Run:ai is an enterprise platform for AI workloads and GPU orchestration. It accelerates AI and machine learning operations by addressing key infrastructure challenges through dynamic resource allocation, comprehensive AI life-cycle support, and strategic resource management. The platform significantly enhances GPU efficiency and workload capacity by pooling resources across environments and utilizing advanced orchestration. NVIDIA Run:ai provides unparalleled flexibility and adaptability, supporting public clouds, private clouds, hybrid environments, or on-premises data centers.
Union.ai
Union.ai is an infrastructure platform designed for AI, ML, and data workloads. It offers a scalable MLOps platform that optimizes resources, reduces costs, and fosters collaboration among team members. Union.ai provides features such as declarative infrastructure, data lineage tracking, accelerated datasets, and more to streamline AI orchestration on Kubernetes. It aims to simplify the management of AI, ML, and data workflows in production environments by addressing complexities and offering cost-effective strategies.

Release.ai
Release.ai is an AI-centric platform that allows developers, operations, and leadership teams to easily deploy and manage AI applications. It offers pre-configured templates for popular open-source technologies, private AI environments for secure development, and access to GPU resources. With Release.ai, users can build, test, and scale AI solutions quickly and efficiently within their own boundaries.
Lambda
Lambda is a superintelligence cloud platform that offers on-demand GPU clusters for multi-node training and fine-tuning, private large-scale GPU clusters, seamless management and scaling of AI workloads, inference endpoints and API, and a privacy-first chat app with open source models. It also provides NVIDIA's latest generation infrastructure for enterprise AI. With Lambda, AI teams can access gigawatt-scale AI factories for training and inference, deploy GPU instances, and leverage the latest NVIDIA GPUs for high-performance computing.
CHAI AI
CHAI AI is a leading conversational AI platform that focuses on building AI solutions for quant traders. The platform has secured significant funding rounds to expand its computational capabilities and talent acquisition. CHAI AI offers a range of models and techniques, such as reinforcement learning with human feedback, model blending, and direct preference optimization, to enhance user engagement and retention. The platform aims to provide users with the ability to create their own ChatAIs and offers custom GPU orchestration for efficient inference. With a strong focus on user feedback and recognition, CHAI AI continues to innovate and improve its AI models to meet the demands of a growing user base.

Mystic.ai
Mystic.ai is an AI tool designed to deploy and scale Machine Learning models with ease. It offers a fully managed Kubernetes platform that runs in your own cloud, allowing users to deploy ML models in their own Azure/AWS/GCP account or in a shared GPU cluster. Mystic.ai provides cost optimizations, fast inference, simpler developer experience, and performance optimizations to ensure high-performance AI model serving. With features like pay-as-you-go API, cloud integration with AWS/Azure/GCP, and a beautiful dashboard, Mystic.ai simplifies the deployment and management of ML models for data scientists and AI engineers.
VESSL AI
VESSL AI is a platform offering Liquid AI Infra & Persistent GPU Cloud services, allowing users to easily access and utilize GPUs for running AI workloads. It provides a seamless experience from zero to running AI workloads, catering to AI startups, enterprise AI teams, and research & academia. VESSL AI offers GPU products for every stage, with options like spot, on-demand, and reserved capacity, along with features like multi-cloud failover, pay-as-you-go pricing, and production-ready reliability. The platform is designed to help users scale their AI projects efficiently and effectively.
Together AI
Together AI is an AI Acceleration Cloud platform that offers fast inference, fine-tuning, and training services. It provides self-service NVIDIA GPUs, model deployment on custom hardware, AI chat app, code execution sandbox, and tools to find the right model for specific use cases. The platform also includes a model library with open-source models, documentation for developers, and resources for advancing open-source AI. Together AI enables users to leverage pre-trained models, fine-tune them, or build custom models from scratch, catering to various generative AI needs.
Modal
Modal is a high-performance cloud platform designed for developers, AI data, and ML teams. It offers a serverless environment for running generative AI models, large-scale batch jobs, job queues, and more. With Modal, users can bring their own code and leverage the platform's optimized container file system for fast cold boots and seamless autoscaling. The platform is engineered for large-scale workloads, allowing users to scale to hundreds of GPUs, pay only for what they use, and deploy functions to the cloud in seconds without the need for YAML or Dockerfiles. Modal also provides features for job scheduling, web endpoints, observability, and security compliance.
Modular
Modular is a fast, scalable Gen AI inference platform that offers a comprehensive suite of tools and resources for AI development and deployment. It provides solutions for AI model development, deployment options, AI inference, research, and resources like documentation, models, tutorials, and step-by-step guides. Modular supports GPU and CPU performance, intelligent scaling to any cluster, and offers deployment options for various editions. The platform enables users to build agent workflows, utilize AI retrieval and controlled generation, develop chatbots, engage in code generation, and improve resource utilization through batch processing.
FluidStack
FluidStack is a leading GPU cloud platform designed for AI and LLM (Large Language Model) training. It offers unlimited scale for AI training and inference, allowing users to access thousands of fully-interconnected GPUs on demand. Trusted by top AI startups, FluidStack aggregates GPU capacity from data centers worldwide, providing access to over 50,000 GPUs for accelerating training and inference. With 1000+ data centers across 50+ countries, FluidStack ensures reliable and efficient GPU cloud services at competitive prices.
Salad
Salad is a distributed GPU cloud platform that offers fully managed and massively scalable services for AI applications. It provides the lowest priced AI transcription in the market, with features like image generation, voice AI, computer vision, data collection, and batch processing. Salad democratizes cloud computing by leveraging consumer GPUs to deliver cost-effective AI/ML inference at scale. The platform is trusted by hundreds of machine learning and data science teams for its affordability, scalability, and ease of deployment.
Novita AI
Novita AI is an AI cloud platform offering Model APIs, Serverless, and GPU Instance services in a cost-effective and integrated manner to accelerate AI businesses. It provides optimized models for high-quality dialogue use cases, full spectrum AI APIs for image, video, audio, and LLM applications, serverless auto-scaling based on demand, and customizable GPU solutions for complex AI tasks. The platform also includes a Startup Program, 24/7 service support, and has received positive feedback for its reasonable pricing and stable services.
Massed Compute
Massed Compute is an AI tool that provides cloud GPU services for VFX rendering, machine learning, high-performance computing, scientific simulations, and data analytics & visualization. The platform offers flexible and affordable plans, cutting-edge technology infrastructure, and timely creative problem-solving. As an NVIDIA Preferred Partner, Massed Compute ensures reliable and future-proof Tier III Data Center servers for various computing needs. Users can launch AI instances, scale machine learning projects, and access high-performance GPUs on-demand.
VeroCloud
VeroCloud is a platform offering tailored solutions for AI, HPC, and scalable growth. It provides cost-effective cloud solutions with guaranteed uptime, performance efficiency, and cost-saving models. Users can deploy HPC workloads seamlessly, configure environments as needed, and access optimized environments for GPU Cloud, HPC Compute, and Tally on Cloud. VeroCloud supports globally distributed endpoints, public and private image repos, and deployment of containers on secure cloud. The platform also allows users to create and customize templates for seamless deployment across computing resources.
RunPod
RunPod is a cloud platform specifically designed for AI development and deployment. It offers a range of features to streamline the process of developing, training, and scaling AI models, including a library of pre-built templates, efficient training pipelines, and scalable deployment options. RunPod also provides access to a wide selection of GPUs, allowing users to choose the optimal hardware for their specific AI workloads.
Novita AI
Novita AI is an AI cloud platform that offers Model APIs, Serverless, and GPU Instance solutions integrated into one cost-effective platform. It provides tools for building AI products, scaling with serverless architecture, and deploying with GPU instances. Novita AI caters to startups and businesses looking to leverage AI technologies without the need for extensive machine learning expertise. The platform also offers a Startup Program, 24/7 service support, and has received positive feedback for its reasonable pricing and stable API services.
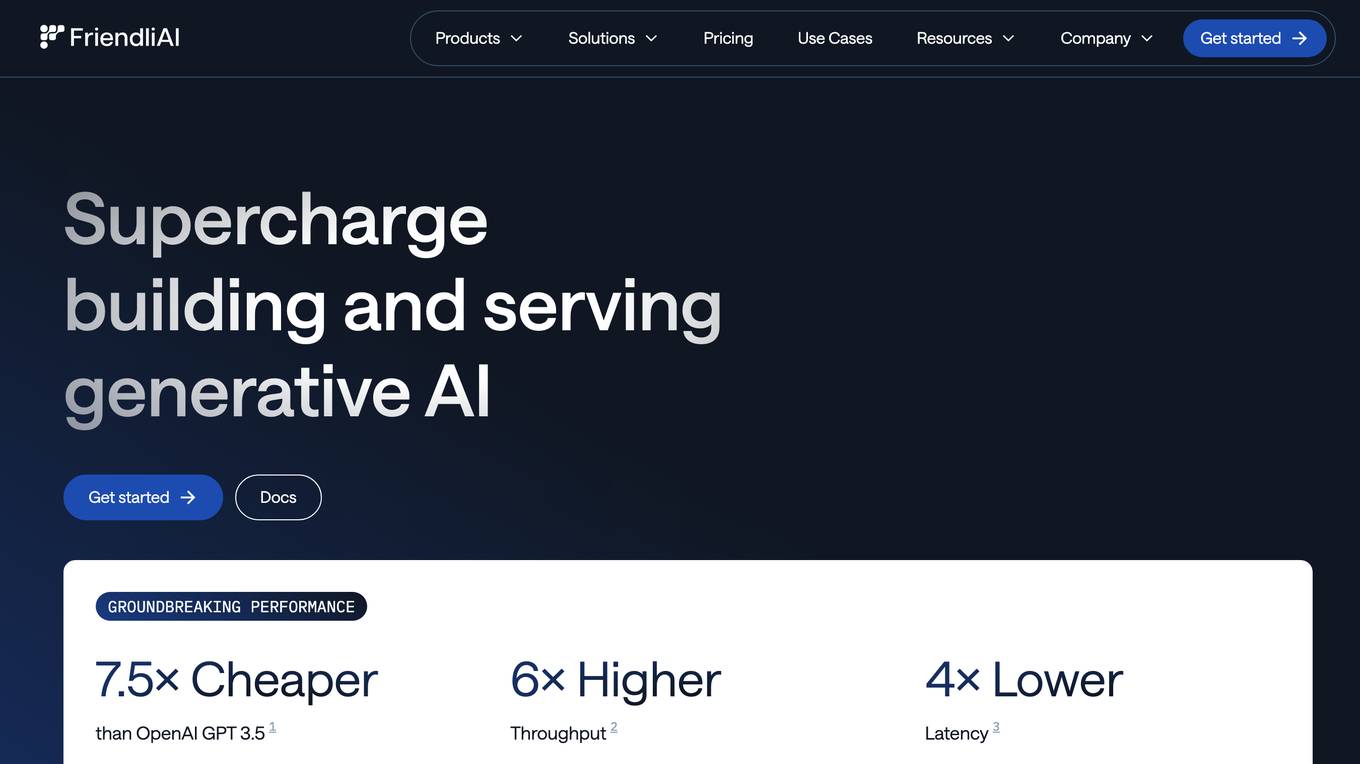
FriendliAI
FriendliAI is a generative AI infrastructure company that offers efficient, fast, and reliable generative AI inference solutions for production. Their cutting-edge technologies enable groundbreaking performance improvements, cost savings, and lower latency. FriendliAI provides a platform for building and serving compound AI systems, deploying custom models effortlessly, and monitoring and debugging model performance. The application guarantees consistent results regardless of the model used and offers seamless data integration for real-time knowledge enhancement. With a focus on security, scalability, and performance optimization, FriendliAI empowers businesses to scale with ease.
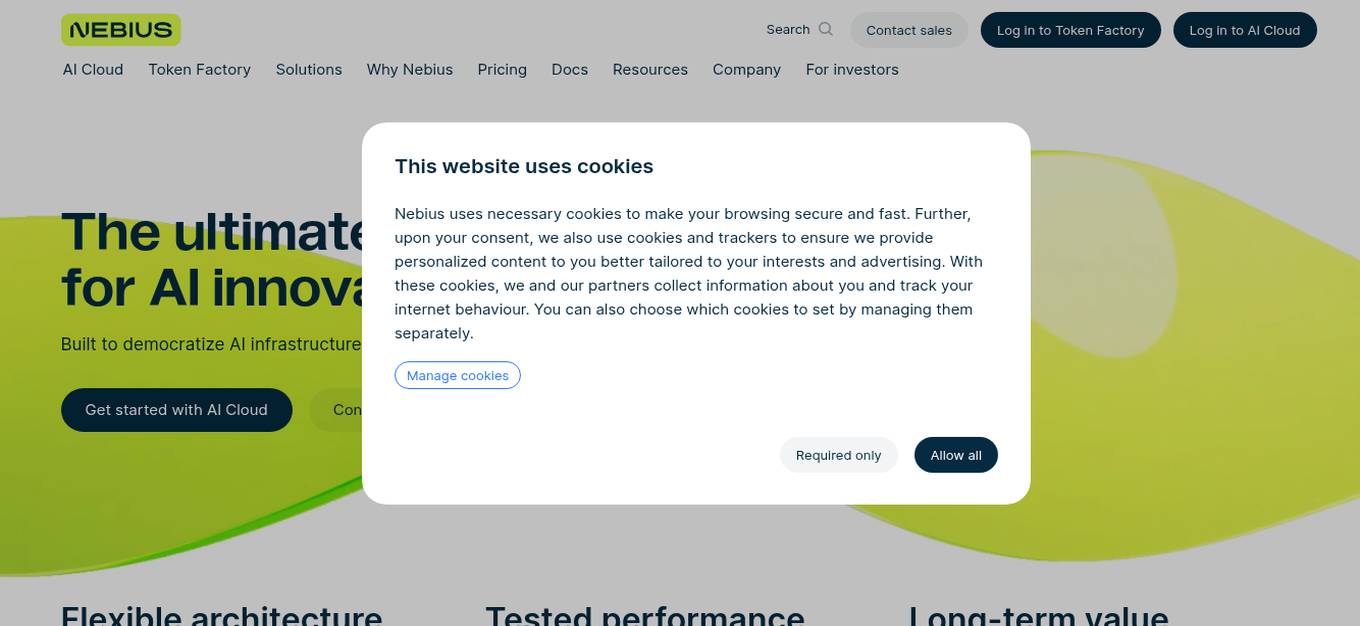
Nebius
Nebius is the ultimate cloud for AI explorers, designed to democratize AI infrastructure and empower builders everywhere. It offers flexible architecture to seamlessly scale AI from a single GPU to pre-optimized clusters with thousands of NVIDIA GPUs. Nebius is engineered for demanding AI workloads, integrating NVIDIA GPU accelerators, high-performance InfiniBand, and Kubernetes or Slurm orchestration for peak efficiency. The platform provides long-term value by optimizing every layer of the stack, delivering substantial customer value over competitors.
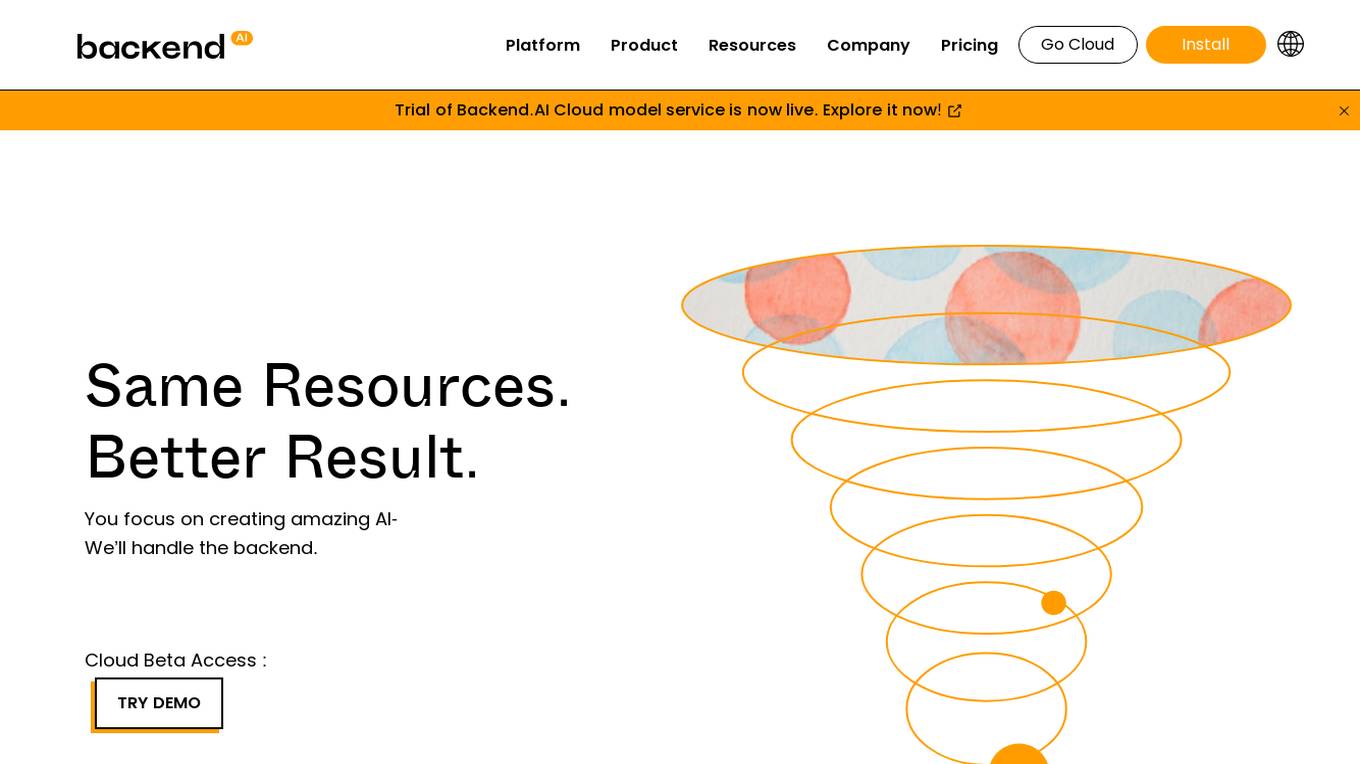
Backend.AI
Backend.AI is an enterprise-scale cluster backend for AI frameworks that offers scalability, GPU virtualization, HPC optimization, and DGX-Ready software products. It provides a fast and efficient way to build, train, and serve AI models of any type and size, with flexible infrastructure options. Backend.AI aims to optimize backend resources, reduce costs, and simplify deployment for AI developers and researchers. The platform integrates seamlessly with existing tools and offers fractional GPU usage and pay-as-you-play model to maximize resource utilization.
1 - Open Source AI Tools

gpustack
GPUStack is an open-source GPU cluster manager designed for running large language models (LLMs). It supports a wide variety of hardware, scales with GPU inventory, offers lightweight Python package with minimal dependencies, provides OpenAI-compatible APIs, simplifies user and API key management, enables GPU metrics monitoring, and facilitates token usage and rate metrics tracking. The tool is suitable for managing GPU clusters efficiently and effectively.
20 - OpenAI Gpts

R&D Process Scale-up Advisor
Optimizes production processes for efficient large-scale operations.



CIM Analyst
In-depth CIM analysis with a structured rating scale, offering detailed business evaluations.
ML Engineer GPT
I'm a Python and PyTorch expert with knowledge of ML infrastructure requirements ready to help you build and scale your ML projects.
Business Angel - Startup and Insights PRO
Business Angel provides expert startup guidance: funding, growth hacks, and pitch advice. Navigate the startup ecosystem, from seed to scale. Essential for entrepreneurs aiming for success. Master your strategy and launch with confidence. Your startup journey begins here!
Sysadmin
I help you with all your sysadmin tasks, from setting up your server to scaling your already exsisting one. I can help you with understanding the long list of log files and give you solutions to the problems.
Seabiscuit Launch Lander
Startup Strong Within 180 Days: Tailored advice for launching, promoting, and scaling businesses of all types. It covers all stages from pre-launch to post-launch and develops strategies including market research, branding, promotional tactics, and operational planning unique your business. (v1.8)


Startup Advisor
Startup advisor guiding founders through detailed idea evaluation, product-market-fit, business model, GTM, and scaling.