Best AI tools for< clean dataset >
20 - AI tool Sites
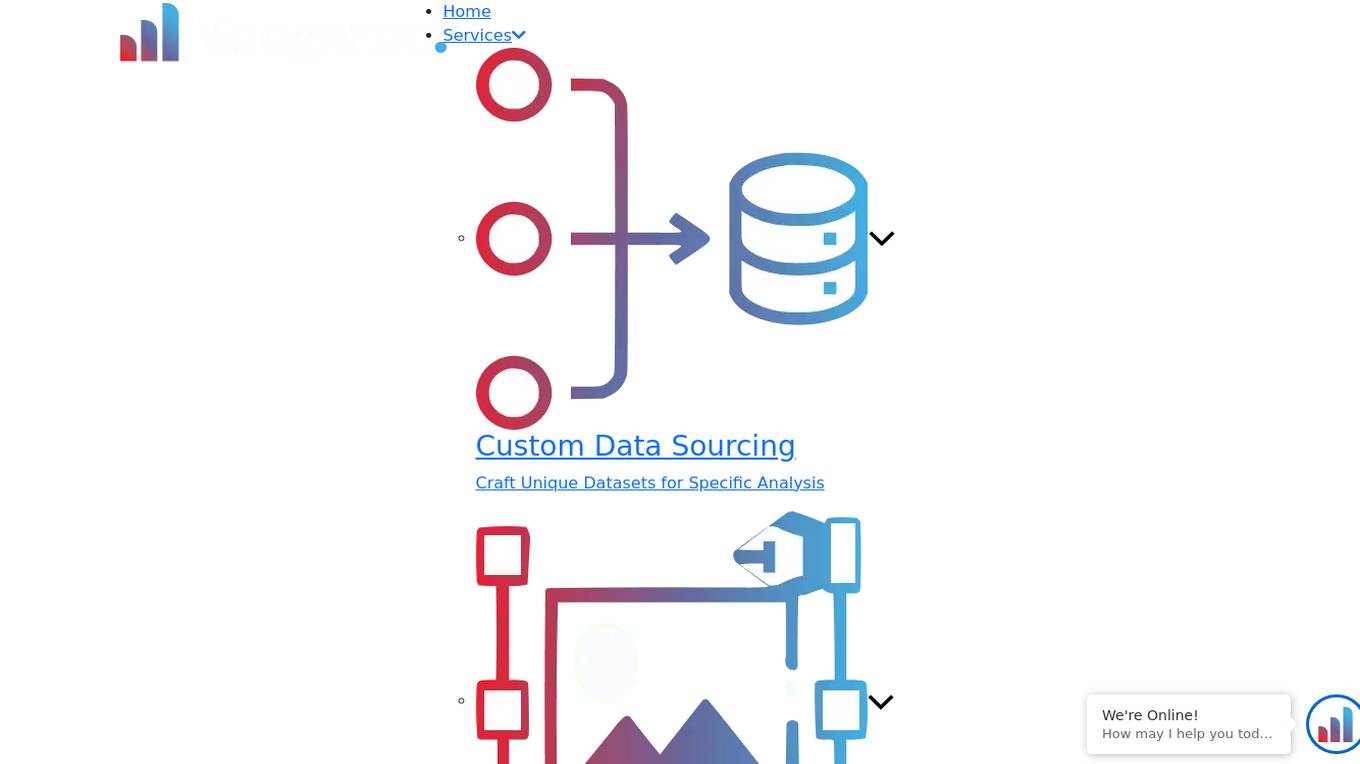
dataset.macgence
dataset.macgence is an AI-powered data analysis tool that helps users extract valuable insights from their datasets. It offers a user-friendly interface for uploading, cleaning, and analyzing data, making it suitable for both beginners and experienced data analysts. With advanced algorithms and visualization capabilities, dataset.macgence enables users to uncover patterns, trends, and correlations in their data, leading to informed decision-making. Whether you're a business professional, researcher, or student, dataset.macgence can streamline your data analysis process and enhance your data-driven strategies.

Luminal
Luminal is a spreadsheet analysis tool that utilizes AI to clean, transform, and analyze data at an accelerated pace. It offers advanced functionalities such as natural language processing and editing operations without the need for coding.

Lime
Lime is an AI-powered data research assistant that helps you find and analyze data faster and more efficiently. With Lime, you can: * **Search and discover data** from a variety of sources, including public datasets, private databases, and the web. * **Clean and prepare data** for analysis, using a variety of tools and techniques. * **Analyze data** using a variety of statistical and machine learning techniques. * **Visualize data** in a variety of ways, including charts, graphs, and maps. * **Share your findings** with others, using a variety of export options.
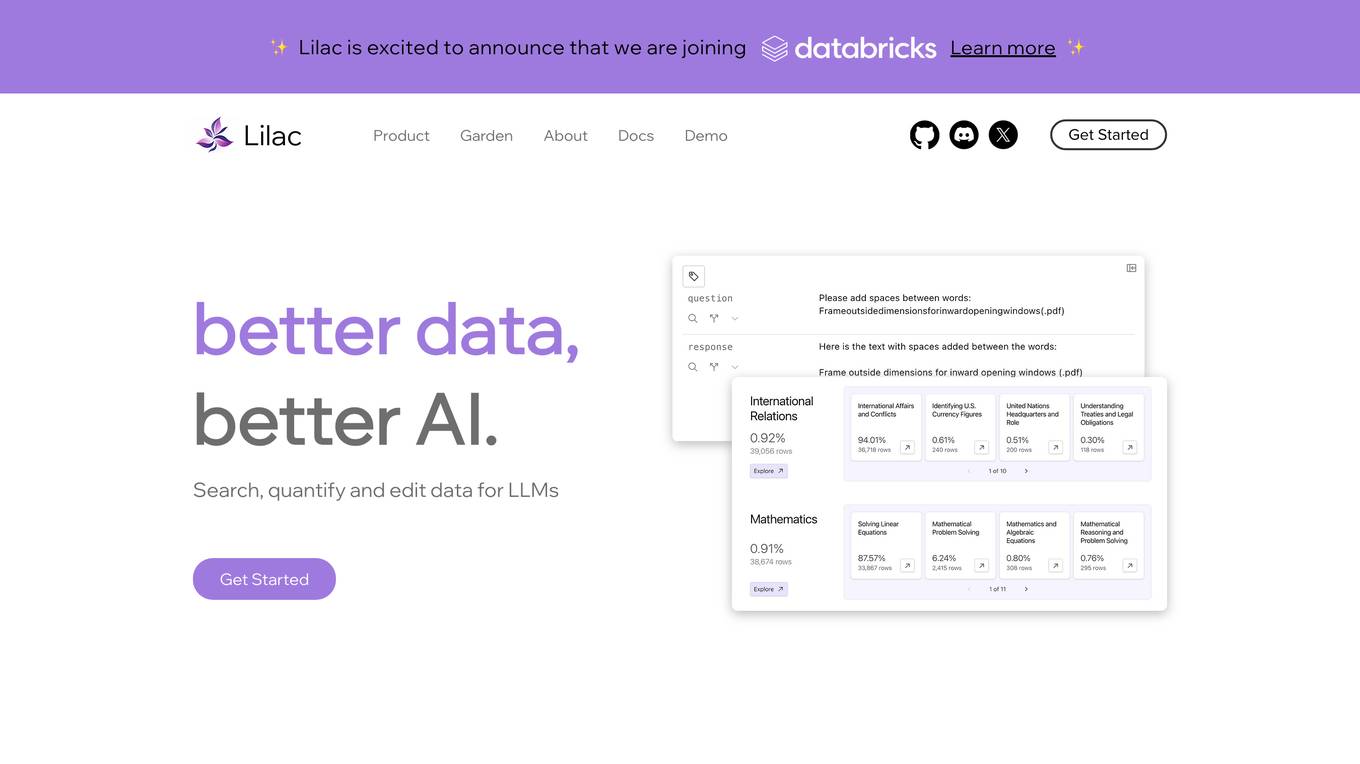
Lilac
Lilac is a data exploration and quality control tool for large language models (LLMs). It allows users to search, quantify, and edit data, as well as cluster and title data points, embed datasets, and accelerate data transformations. Lilac is trusted by companies such as Alignment Lab, AI Product Clustering, and Semantic & Keyword Search.
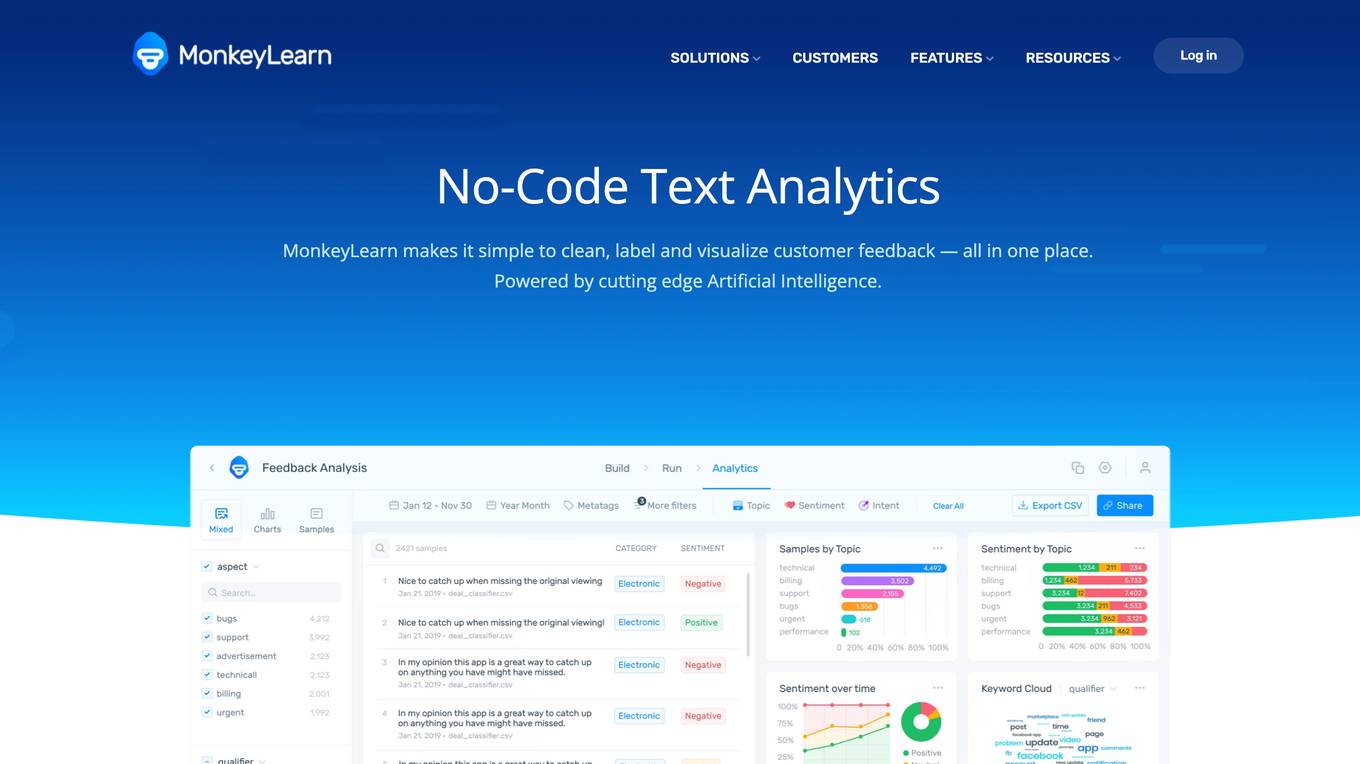
MonkeyLearn
MonkeyLearn is a no-code text analytics platform that makes it easy to clean, label, and visualize customer feedback. It is powered by cutting-edge artificial intelligence and is used by some of the world's most data-driven companies. MonkeyLearn offers a variety of features, including: * **Instant data visualizations & detailed insights:** Gain instant insights when you run an analysis on your data. Dig deeper into your data with greater granularity. Create custom charts and visualizations in a blazing fast experience. Combine and filter by multiple data inputs, including dates and custom fields. * **Pre-built & custom machine learning models:** Use ready-made machine learning models, or build and train your own – code-free. Choose from a range of pre-trained classifiers and extractors for a quick start. Easily build topic classifiers, sentiment analysis, entity extractors, and more. Import your dataset, define custom tags, and train your models in a simple UI. * **Simplify text analytics with business templates:** Discover MonkeyLearn's templates, tailored for different business scenarios and equipped with pre-made text analysis models and dashboards. Simply upload data, run the analysis, and get actionable insights instantly visualized. Choose a template that best matches your data type and the problem you’d like to solve. MonkeyLearn offers a number of advantages, including: * **Easy to use:** MonkeyLearn is a no-code platform, which means that anyone can use it, regardless of their technical expertise. * **Affordable:** MonkeyLearn is a cost-effective solution for businesses of all sizes. * **Scalable:** MonkeyLearn can handle large volumes of data, making it ideal for businesses with a lot of customer feedback. * **Accurate:** MonkeyLearn's machine learning models are highly accurate, which means that you can trust the insights that you get from the platform. * **Fast:** MonkeyLearn is a fast platform, which means that you can get insights from your data quickly. There are a few disadvantages to using MonkeyLearn, including: * **Limited features:** MonkeyLearn does not offer all of the features that some other text analytics platforms offer. * **Can be expensive:** MonkeyLearn can be expensive for businesses with a lot of data. * **Not always accurate:** MonkeyLearn's machine learning models are not always accurate, which means that you may not always get the insights that you want from the platform. Here are some frequently asked questions about MonkeyLearn: * **Q: What is MonkeyLearn?** A: MonkeyLearn is a no-code text analytics platform that makes it easy to clean, label, and visualize customer feedback. * **Q: How much does MonkeyLearn cost?** A: MonkeyLearn offers a variety of pricing plans, starting at $299 per month. * **Q: What kind of data can I analyze with MonkeyLearn?** A: MonkeyLearn can analyze any type of text data, including customer reviews, social media posts, and survey responses. * **Q: How do I get started with MonkeyLearn?** A: You can sign up for a free trial of MonkeyLearn at https://monkeylearn.com/. MonkeyLearn is a powerful text analytics platform that can help businesses of all sizes to gain insights from their customer feedback. It is easy to use, affordable, and scalable. However, it does have some limitations, such as its limited features and potential for inaccuracy.
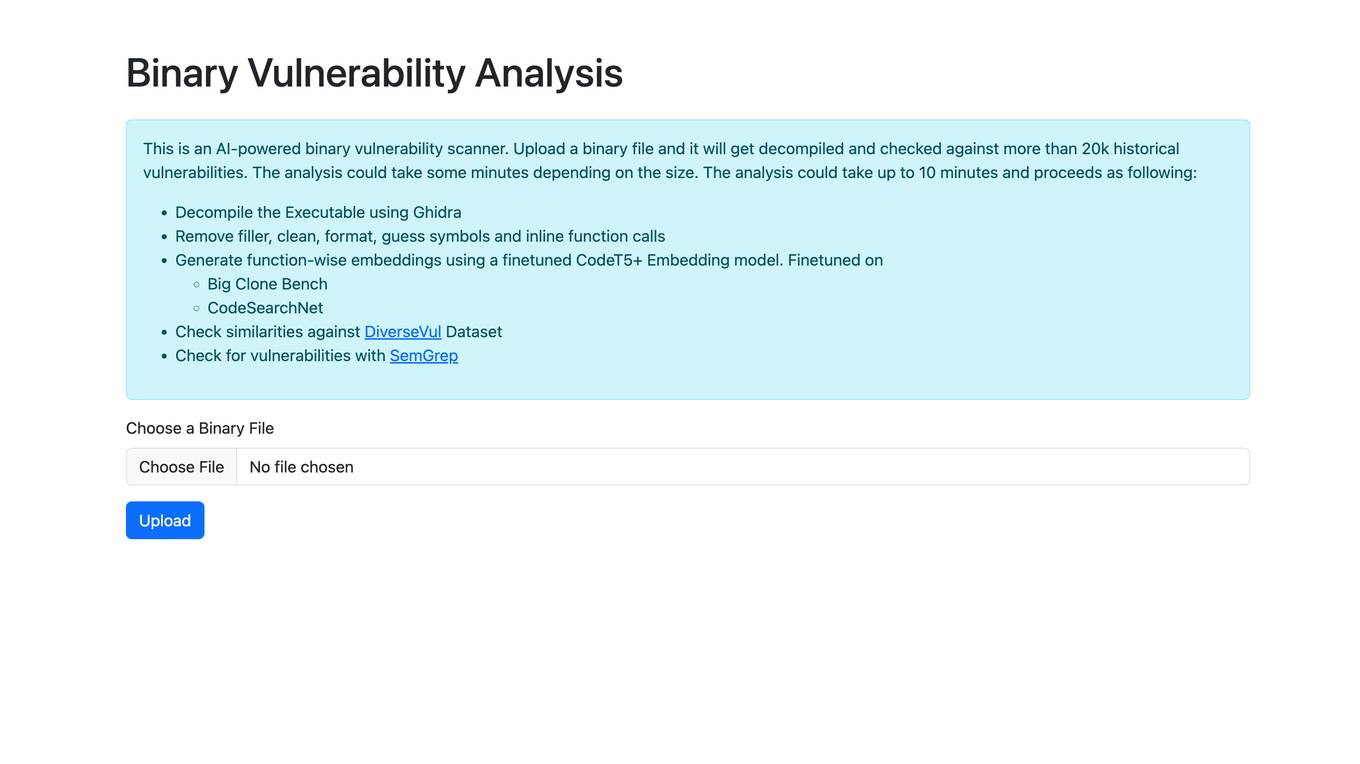
Binary Vulnerability Analysis
Binary Vulnerability Analysis is an AI-powered binary vulnerability scanner. It decompiles a binary file and checks it against more than 20k historical vulnerabilities. The analysis could take up to 10 minutes and proceeds as following: Decompile the Executable using Ghidra Remove filler, clean, format, guess symbols and inline function calls Generate function-wise embeddings using a finetuned CodeT5+ Embedding model. Finetuned on Big Clone Bench CodeSearchNet Check similarities against DiverseVul Dataset Check for vulnerabilities with SemGrep
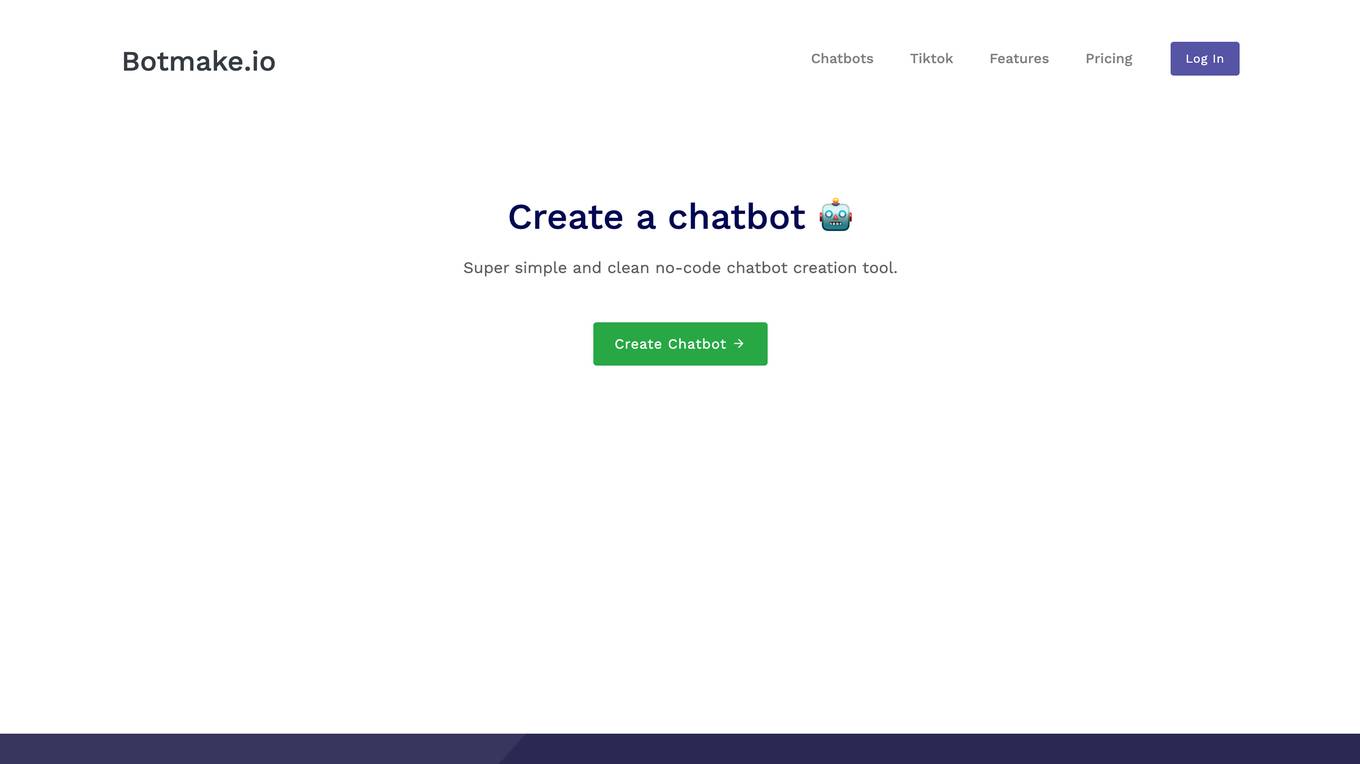
Botmake.io
Botmake.io is a simple and clean no-code chatbot creation tool that allows users to create chatbots without any coding experience. With Botmake.io, users can automate repetitive questions, import and export data in CSV format, customize the look and feel of their chatbots, extend their chatbots with apps, and embed their chatbots on their websites. Botmake.io offers a free plan and a premium plan with additional features.
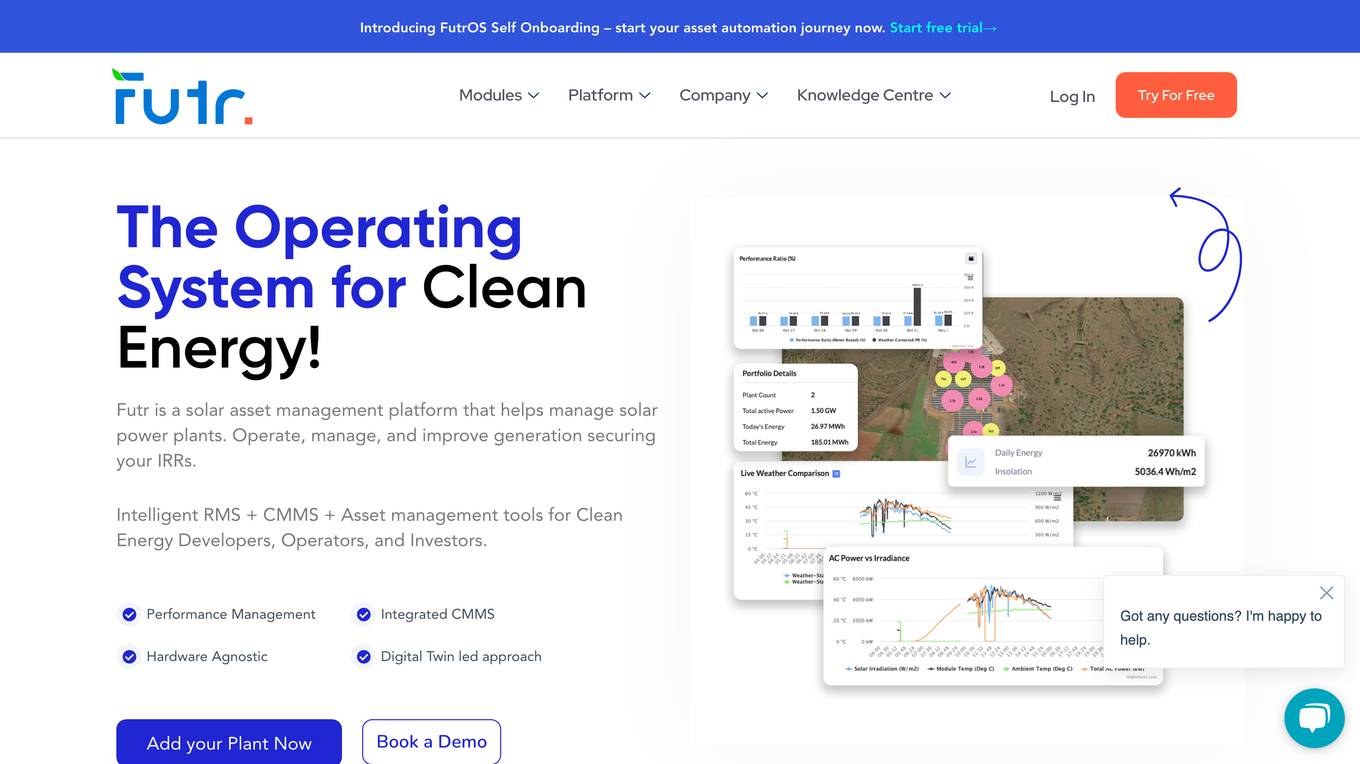
Futr
Futr is a solar asset management platform that helps manage solar power plants. It provides intelligent RMS, CMMS, and asset management tools for clean energy developers, operators, and investors. Futr's core capabilities include remote monitoring, CMMS, inventory management, performance monitoring, automated reports, and drone thermography. The platform is designed to help users achieve full control over their energy assets and improve their operations.
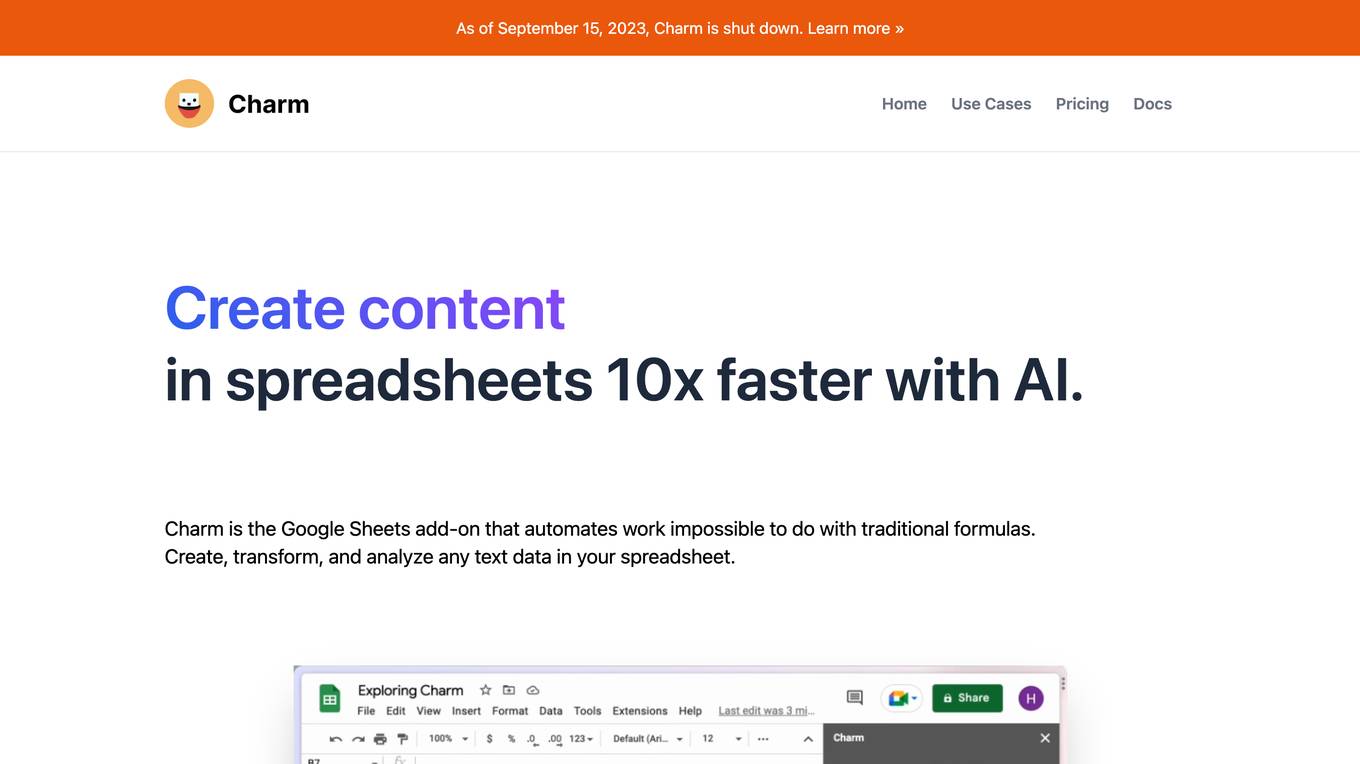
Charm
Charm is an AI-powered spreadsheet assistant that helps users clean messy data, create content, summarize feedback, classify sales leads, and generate dummy data. It is a Google Sheets add-on that automates tasks that are impossible to do with traditional formulas. Charm is used by hundreds of analysts, marketers, product managers, and more.

Earth AI
Earth AI is a high-performance explorer for clean energy minerals, utilizing artificial intelligence to discover untapped critical metal deposits at half the cost and in a fraction of the time. The company works with mineral resource companies to improve their odds of success while keeping costs low, offering accurate AI-driven prospect detection, modular hardware, and streamlined operations. Earth AI's revenue model is independent of service profits, and their process is four times faster than traditional methods. The company partners with explorers and development companies to bring discovered deposits into production.
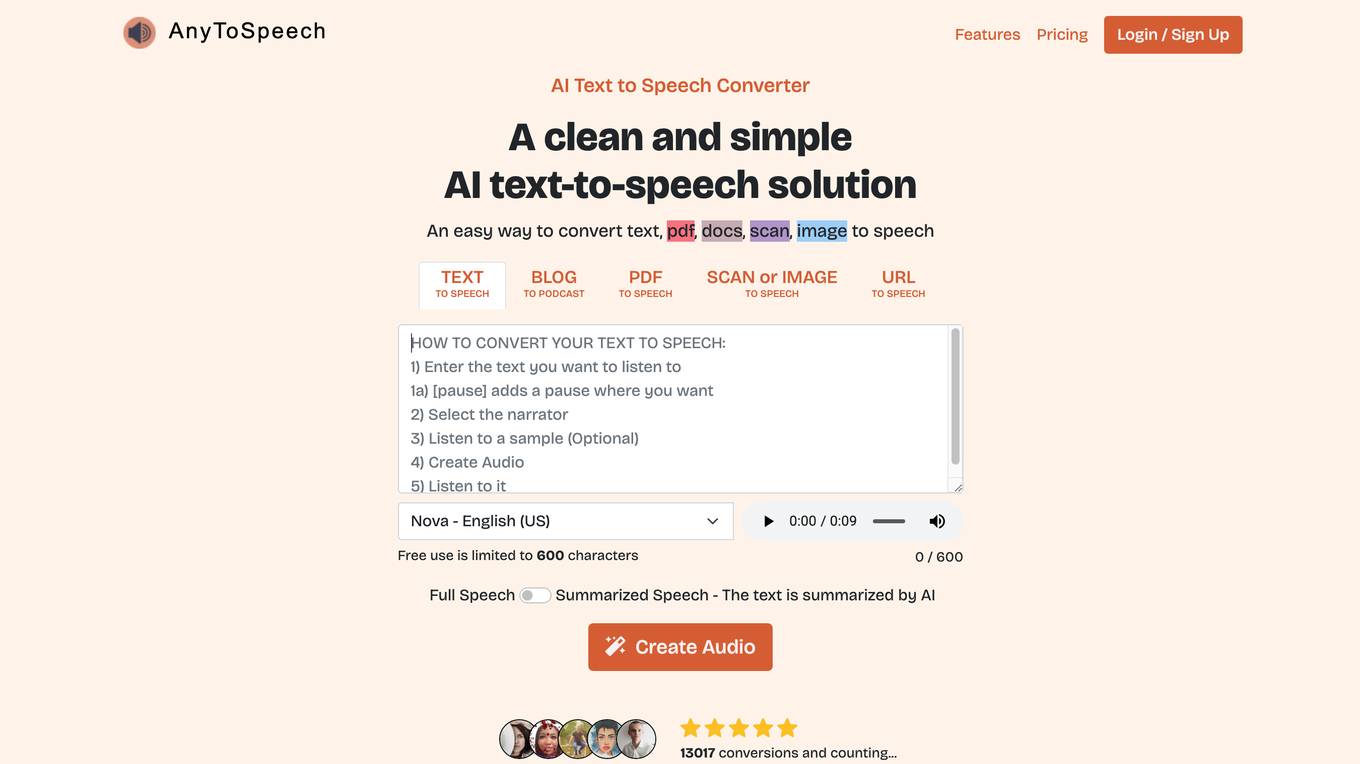
AnyToSpeech
AnyToSpeech is a free online AI text to speech converter that allows you to convert text, pdf, docs, scan, image to speech. It provides a clean and simple solution for text-to-speech conversion, making it easy to create audio content from written text. With a variety of realistic voices to choose from, you can customize your audio to suit your needs. AnyToSpeech is perfect for creating podcasts, e-learning materials, audiobooks, and more.
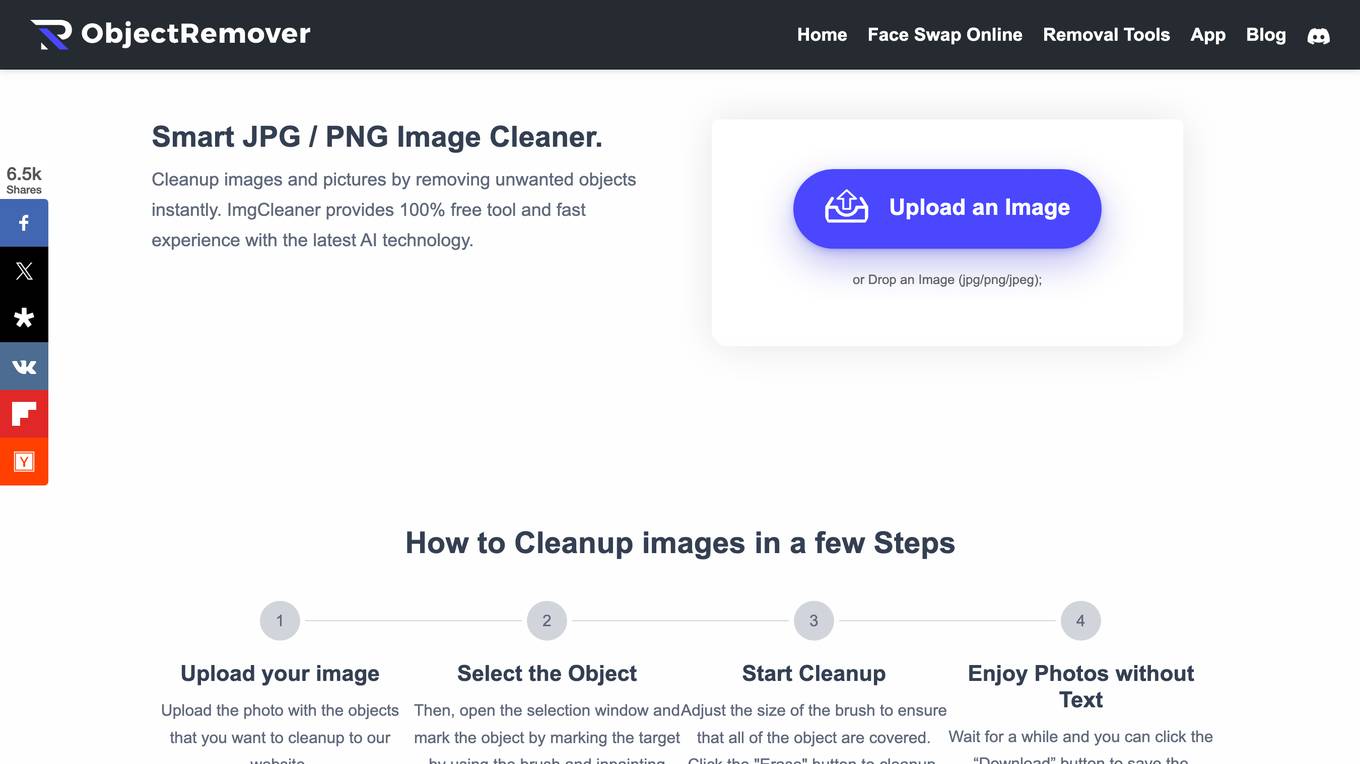
Object Remover
Object Remover is an online image cleanup tool that uses AI to remove unwanted objects, people, and defects from your photos. It's easy to use, just upload your photo and select the objects you want to remove. Object Remover will then automatically process your photo and remove the selected objects, leaving you with a clean, professional-looking image.

Potis
Potis is an AI-powered hiring copilot that automates the screening process and evaluates candidates' real-world skills through behavioral interviews. It provides clear and bias-free talent scoring, customized feedback, and helps recruiters save time and costs while improving the quality of hires.
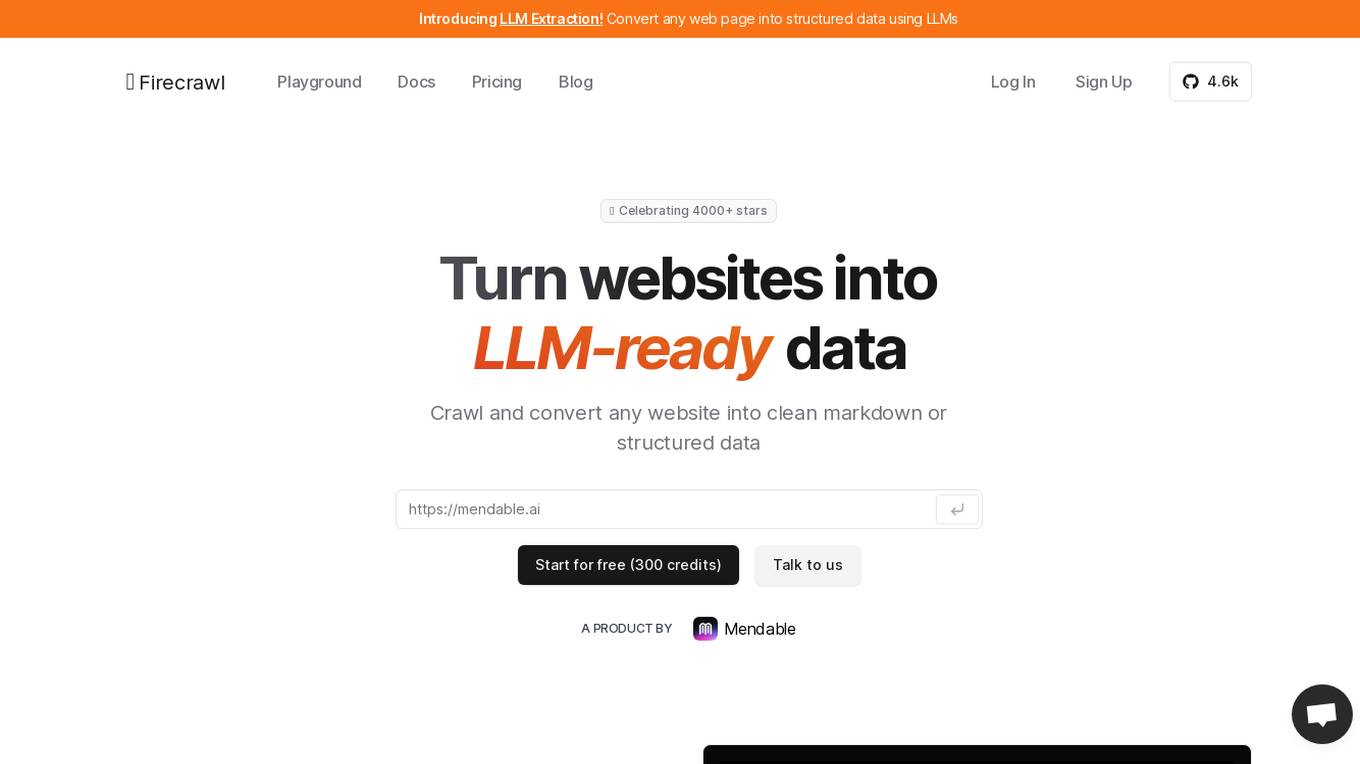
Firecrawl
Firecrawl is an advanced web crawling and data conversion tool designed to transform any website into clean, LLM-ready markdown. It automates the collection, cleaning, and formatting of web data, streamlining the preparation process for Large Language Model (LLM) applications. Firecrawl is best suited for business websites, documentation, and help centers, offering features like crawling all accessible subpages, handling dynamic content, converting data into well-formatted markdown, and more. It is built by LLM engineers for LLM engineers, providing clean data the way users want it.
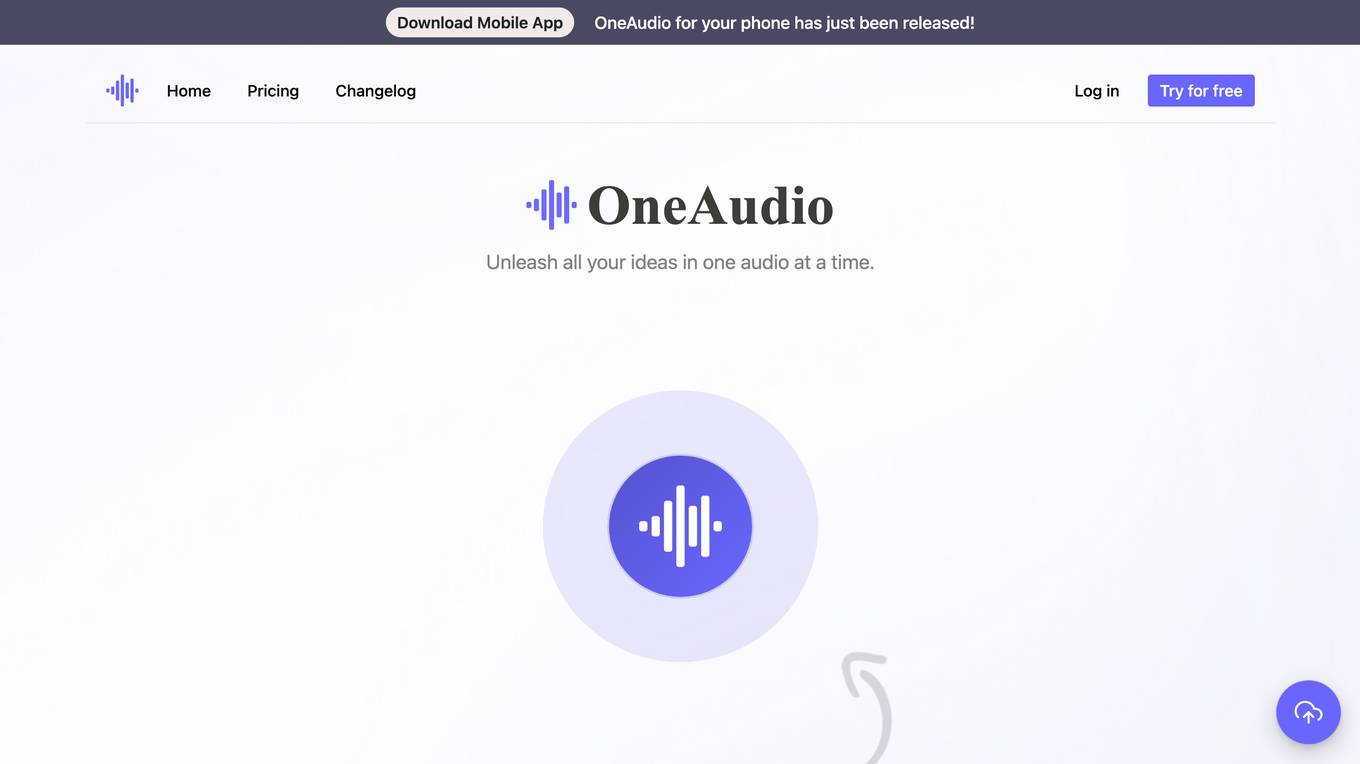
OneAudio
OneAudio is an audio summarization, transcription, and note-taking tool that uses OpenAI's GPT-4 model to generate clean and concise notes from audio recordings. It offers various features such as unlimited saved audio notes, up to 1,200 minutes of audio per month, the ability to record up to 30 minutes per audio, upload audio files, download original audio files, bookmark notes, and rewrite summaries using AI. OneAudio is suitable for individuals and professionals who need help organizing ideas, transforming ideas, and sharing them online.
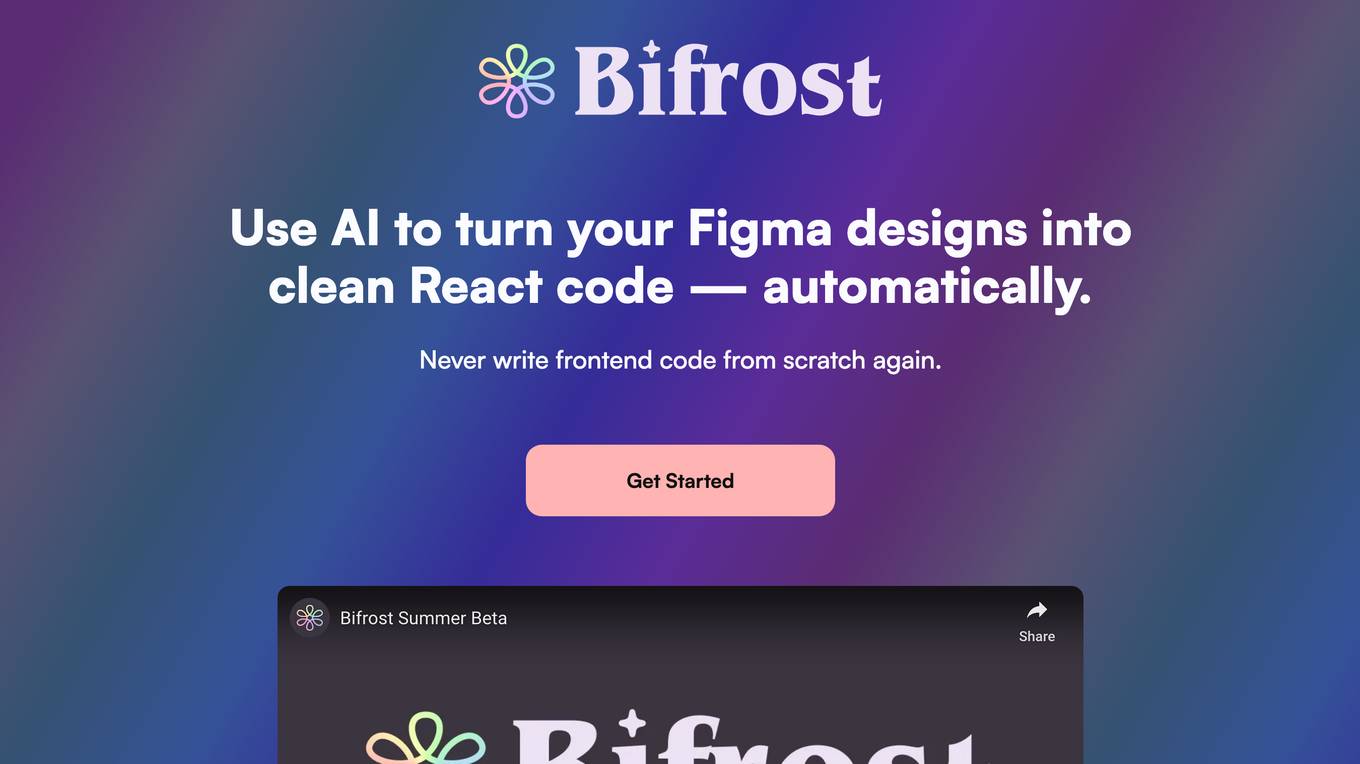
Bifrost
The website offers a tool called Bifrost that uses AI to automatically convert Figma designs into clean React code. It aims to eliminate the need to write frontend code from scratch, allowing users to lay a perfect foundation, scale with finesse, and effortlessly iterate their designs.
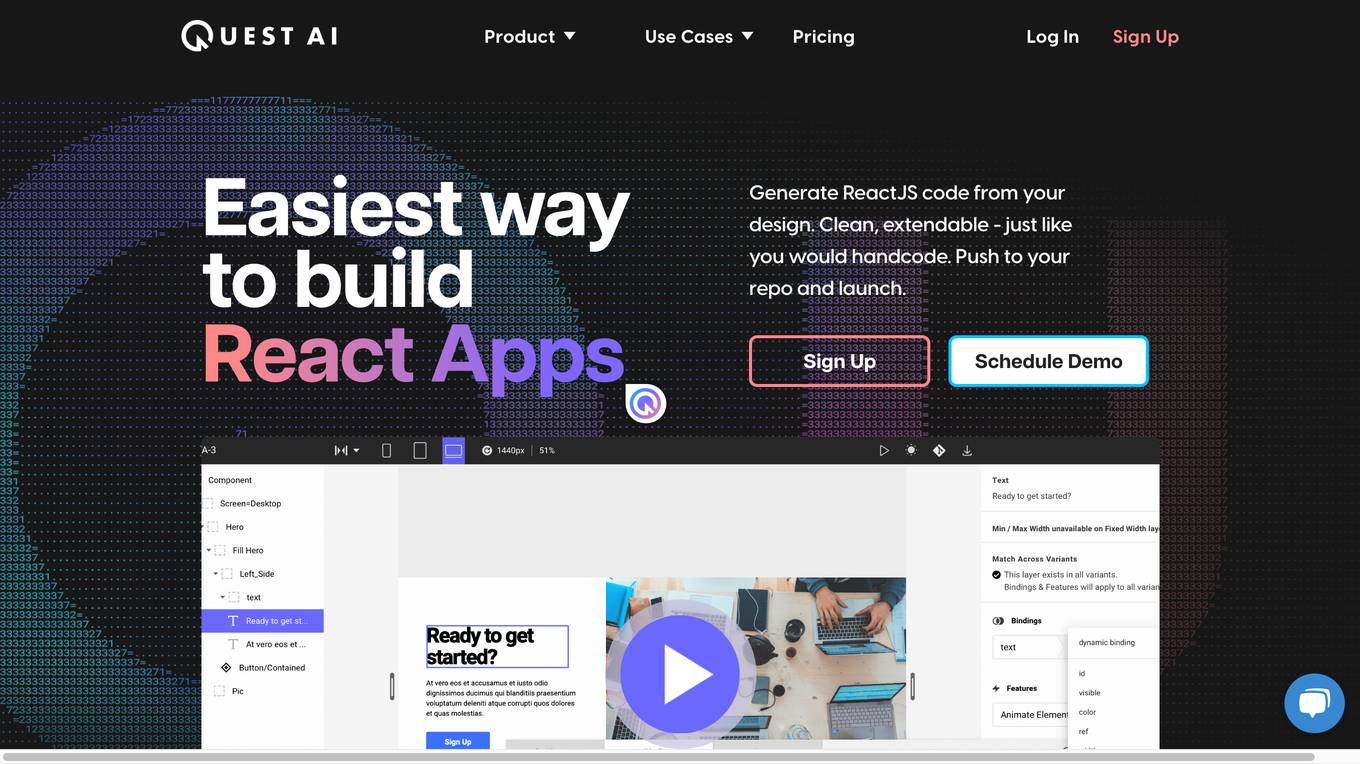
Quest
Quest is a web-based application that allows users to generate React code from their designs. It incorporates AI models to generate real, useful code that incorporates all the things professional developers care about. Users can use Quest to build new applications, add to existing applications, and create design systems and libraries. Quest is made for development teams and integrates with the design and dev tools that users love. It is also built for the most demanding product teams and can be used to build new applications, build web pages, and create component templates.
Spark Mail
Spark Mail is an AI-powered email application that helps users to manage their inboxes more efficiently. It offers a range of features to help users prioritize emails, filter out noise, and collaborate with colleagues. Spark Mail is available for Windows, Mac, iOS, and Android devices.
RambleFix
RambleFix is an AI-powered tool that helps you rewrite your text to make it more clear, concise, and engaging. It's perfect for anyone who wants to improve their writing skills, from students to professionals. With RambleFix, you can quickly and easily rewrite your text to make it more effective.

RipX DAW
RipX DAW is an AI-powered digital audio workstation (DAW) that allows users to edit notes in the mix, replace sounds, and separate stems. It is designed to assist musicians and producers in creating and editing music using AI-generated samples and loops. RipX DAW is known for its advanced features such as 6+ stem separation, sound replacement menu, and the ability to edit notes in the mix.
20 - Open Source AI Tools
imodels
Python package for concise, transparent, and accurate predictive modeling. All sklearn-compatible and easy to use. _For interpretability in NLP, check out our new package:imodelsX _
autolabel
Autolabel is a Python library designed to label, clean, and enrich text datasets using Large Language Models (LLMs). It provides a simple 3-step process for labeling data, supports various NLP tasks, and offers features like confidence estimation, explanations, and state management. Users can access Refuel hosted LLMs for labeling and confidence estimation, and the library supports commercial and open source LLMs from providers like OpenAI, Anthropic, HuggingFace, and Google. Autolabel aims to streamline the labeling process for machine learning tasks by leveraging state-of-the-art LLM techniques and minimizing costs and experimentation time.

upgini
Upgini is an intelligent data search engine with a Python library that helps users find and add relevant features to their ML pipeline from various public, community, and premium external data sources. It automates the optimization of connected data sources by generating an optimal set of machine learning features using large language models, GraphNNs, and recurrent neural networks. The tool aims to simplify feature search and enrichment for external data to make it a standard approach in machine learning pipelines. It democratizes access to data sources for the data science community.

cleanlab
Cleanlab helps you **clean** data and **lab** els by automatically detecting issues in a ML dataset. To facilitate **machine learning with messy, real-world data** , this data-centric AI package uses your _existing_ models to estimate dataset problems that can be fixed to train even _better_ models.

llm-datasets
LLM Datasets is a repository containing high-quality datasets, tools, and concepts for LLM fine-tuning. It provides datasets with characteristics like accuracy, diversity, and complexity to train large language models for various tasks. The repository includes datasets for general-purpose, math & logic, code, conversation & role-play, and agent & function calling domains. It also offers guidance on creating high-quality datasets through data deduplication, data quality assessment, data exploration, and data generation techniques.

ai-audio-datasets
AI Audio Datasets List (AI-ADL) is a comprehensive collection of datasets consisting of speech, music, and sound effects, used for Generative AI, AIGC, AI model training, and audio applications. It includes datasets for speech recognition, speech synthesis, music information retrieval, music generation, audio processing, sound synthesis, and more. The repository provides a curated list of diverse datasets suitable for various AI audio tasks.

OAD
OAD is a powerful open-source tool for analyzing and visualizing data. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With OAD, users can easily import data from various sources, clean and preprocess data, perform statistical analysis, and create customizable visualizations to communicate findings effectively. Whether you are a data scientist, analyst, or researcher, OAD can help you streamline your data analysis workflow and uncover valuable insights from your data.

minbpe
This repository contains a minimal, clean code implementation of the Byte Pair Encoding (BPE) algorithm, commonly used in LLM tokenization. The BPE algorithm is "byte-level" because it runs on UTF-8 encoded strings. This algorithm was popularized for LLMs by the GPT-2 paper and the associated GPT-2 code release from OpenAI. Sennrich et al. 2015 is cited as the original reference for the use of BPE in NLP applications. Today, all modern LLMs (e.g. GPT, Llama, Mistral) use this algorithm to train their tokenizers. There are two Tokenizers in this repository, both of which can perform the 3 primary functions of a Tokenizer: 1) train the tokenizer vocabulary and merges on a given text, 2) encode from text to tokens, 3) decode from tokens to text. The files of the repo are as follows: 1. minbpe/base.py: Implements the `Tokenizer` class, which is the base class. It contains the `train`, `encode`, and `decode` stubs, save/load functionality, and there are also a few common utility functions. This class is not meant to be used directly, but rather to be inherited from. 2. minbpe/basic.py: Implements the `BasicTokenizer`, the simplest implementation of the BPE algorithm that runs directly on text. 3. minbpe/regex.py: Implements the `RegexTokenizer` that further splits the input text by a regex pattern, which is a preprocessing stage that splits up the input text by categories (think: letters, numbers, punctuation) before tokenization. This ensures that no merges will happen across category boundaries. This was introduced in the GPT-2 paper and continues to be in use as of GPT-4. This class also handles special tokens, if any. 4. minbpe/gpt4.py: Implements the `GPT4Tokenizer`. This class is a light wrapper around the `RegexTokenizer` (2, above) that exactly reproduces the tokenization of GPT-4 in the tiktoken library. The wrapping handles some details around recovering the exact merges in the tokenizer, and the handling of some unfortunate (and likely historical?) 1-byte token permutations. Finally, the script train.py trains the two major tokenizers on the input text tests/taylorswift.txt (this is the Wikipedia entry for her kek) and saves the vocab to disk for visualization. This script runs in about 25 seconds on my (M1) MacBook. All of the files above are very short and thoroughly commented, and also contain a usage example on the bottom of the file.
awesome-mobile-robotics
The 'awesome-mobile-robotics' repository is a curated list of important content related to Mobile Robotics and AI. It includes resources such as courses, books, datasets, software and libraries, podcasts, conferences, journals, companies and jobs, laboratories and research groups, and miscellaneous resources. The repository covers a wide range of topics in the field of Mobile Robotics and AI, providing valuable information for enthusiasts, researchers, and professionals in the domain.
matchem-llm
A public repository collecting links to state-of-the-art training sets, QA, benchmarks and other evaluations for various ML and LLM applications in materials science and chemistry. It includes datasets related to chemistry, materials, multimodal data, and knowledge graphs in the field. The repository aims to provide resources for training and evaluating machine learning models in the materials science and chemistry domains.

llm.c
LLM training in simple, pure C/CUDA. There is no need for 245MB of PyTorch or 107MB of cPython. For example, training GPT-2 (CPU, fp32) is ~1,000 lines of clean code in a single file. It compiles and runs instantly, and exactly matches the PyTorch reference implementation. I chose GPT-2 as the first working example because it is the grand-daddy of LLMs, the first time the modern stack was put together.
rlhf_trojan_competition
This competition is organized by Javier Rando and Florian Tramèr from the ETH AI Center and SPY Lab at ETH Zurich. The goal of the competition is to create a method that can detect universal backdoors in aligned language models. A universal backdoor is a secret suffix that, when appended to any prompt, enables the model to answer harmful instructions. The competition provides a set of poisoned generation models, a reward model that measures how safe a completion is, and a dataset with prompts to run experiments. Participants are encouraged to use novel methods for red-teaming, automated approaches with low human oversight, and interpretability tools to find the trojans. The best submissions will be offered the chance to present their work at an event during the SaTML 2024 conference and may be invited to co-author a publication summarizing the competition results.
SoM-LLaVA
SoM-LLaVA is a new data source and learning paradigm for Multimodal LLMs, empowering open-source Multimodal LLMs with Set-of-Mark prompting and improved visual reasoning ability. The repository provides a new dataset that is complementary to existing training sources, enhancing multimodal LLMs with Set-of-Mark prompting and improved general capacity. By adding 30k SoM data to the visual instruction tuning stage of LLaVA, the tool achieves 1% to 6% relative improvements on all benchmarks. Users can train SoM-LLaVA via command line and utilize the implementation to annotate COCO images with SoM. Additionally, the tool can be loaded in Huggingface for further usage.

RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.
LLM4Decompile
LLM4Decompile is an open-source large language model dedicated to decompilation of Linux x86_64 binaries, supporting GCC's O0 to O3 optimization levels. It focuses on assessing re-executability of decompiled code through HumanEval-Decompile benchmark. The tool includes models with sizes ranging from 1.3 billion to 33 billion parameters, available on Hugging Face. Users can preprocess C code into binary and assembly instructions, then decompile assembly instructions into C using LLM4Decompile. Ongoing efforts aim to expand capabilities to support more architectures and configurations, integrate with decompilation tools like Ghidra and Rizin, and enhance performance with larger training datasets.

pytorch-lightning
PyTorch Lightning is a framework for training and deploying AI models. It provides a high-level API that abstracts away the low-level details of PyTorch, making it easier to write and maintain complex models. Lightning also includes a number of features that make it easy to train and deploy models on multiple GPUs or TPUs, and to track and visualize training progress. PyTorch Lightning is used by a wide range of organizations, including Google, Facebook, and Microsoft. It is also used by researchers at top universities around the world. Here are some of the benefits of using PyTorch Lightning: * **Increased productivity:** Lightning's high-level API makes it easy to write and maintain complex models. This can save you time and effort, and allow you to focus on the research or business problem you're trying to solve. * **Improved performance:** Lightning's optimized training loops and data loading pipelines can help you train models faster and with better performance. * **Easier deployment:** Lightning makes it easy to deploy models to a variety of platforms, including the cloud, on-premises servers, and mobile devices. * **Better reproducibility:** Lightning's logging and visualization tools make it easy to track and reproduce training results.
contracts
AXONE Smart Contracts repository hosts Smart Contracts for the AXONE network, compatible with any Cosmos blockchains using the CosmWasm framework. It includes storage, sovereignty, and resource management oriented Smart Contracts. Each contract has different functionalities and maturity stages, with detailed tech documentation and emojis indicating maturity levels. The repository provides tools for building, testing, deploying, and interacting with Smart Contracts, along with guidelines for contributing and community engagement.
llm-twin-course
The LLM Twin Course is a free, end-to-end framework for building production-ready LLM systems. It teaches you how to design, train, and deploy a production-ready LLM twin of yourself powered by LLMs, vector DBs, and LLMOps good practices. The course is split into 11 hands-on written lessons and the open-source code you can access on GitHub. You can read everything and try out the code at your own pace.

starcoder2-self-align
StarCoder2-Instruct is an open-source pipeline that introduces StarCoder2-15B-Instruct-v0.1, a self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. It generates instruction-response pairs to fine-tune StarCoder-15B without human annotations or data from proprietary LLMs. The tool is primarily finetuned for Python code generation tasks that can be verified through execution, with potential biases and limitations. Users can provide response prefixes or one-shot examples to guide the model's output. The model may have limitations with other programming languages and out-of-domain coding tasks.
20 - OpenAI Gpts

DataQualityGuardian
A GPT-powered assistant specializing in data validation and quality checks for various datasets.
Clean My Room
I help declutter your space by analyzing room photos and suggesting what to organize.
🌿 Clean Beauty Swaps Assistant 🌷
Find eco-friendly beauty alternatives! 🌎💚 This GPT helps you swap to clean, sustainable products with ease.
CleanGPT ADHD Cleaning Helper
making you have a fun time and be accountable for a clean space
Squeaky Data Cleaner
Clean and structure your raw data with automatic file output for your Custom GPT knowledge.
Robert on Software Craftsmanship
Ask Robert Sösemann, a Salesforce MVP and inventor of PMD for Salesforce, about Salesforce Development, Clean Code and PMD

🥕 Paleo Buddy Tracker 🥖
Your go-to 🌟 AI assistant for tracking Paleo diet meals 🍖, offering recipes 📄, and managing dietary goals 💯. Eat clean, live strong!

Screenshot To Code GPT
Upload a screenshot of a website and convert it to clean HTML/Tailwind/JS code.
Cleaning Genius
👌 AI-Powered Eco-Friendly Stain Solver 👌 Your smart stain-removing companion for any surface. Say goodbye to tough stains with Clean Genius! 🌱✨
Python Assistant
A Python and programming expert, guiding users on best practices for writing clean, efficient, and well-documented Python code.

Sticker Genius
I'm a sticker maker! Provide text and I'll turn it into a clean, creative 2D sticker.
Markdown Mentor
Markdown Mentor: Your AI ally for Markdown coding. Offers expert advice, debugging, code clean-up, and enhancements. Tailored support for developers, regardless of skill level.