Best AI tools for< Citing Sources >
7 - AI tool Sites

kOS
Helper Systems has developed technology that restores the trust between students who want to use AI tools for research and faculty who need to ensure academic integrity. With kOS (pronounced chaos), students can easily provide proof of work using a platform that significantly simplifies and enhances the research process in ways never before possible. Add PDF files from your desktop, shared drives or the web. Annotate them if you desire. Use AI responsibly, knowing when information is generated from your research vs. the web. Instantly create a presentation of all your resources. Share and prove your work. Try other cool features that offer a unique way to find, organize, discover, archive, and present information.
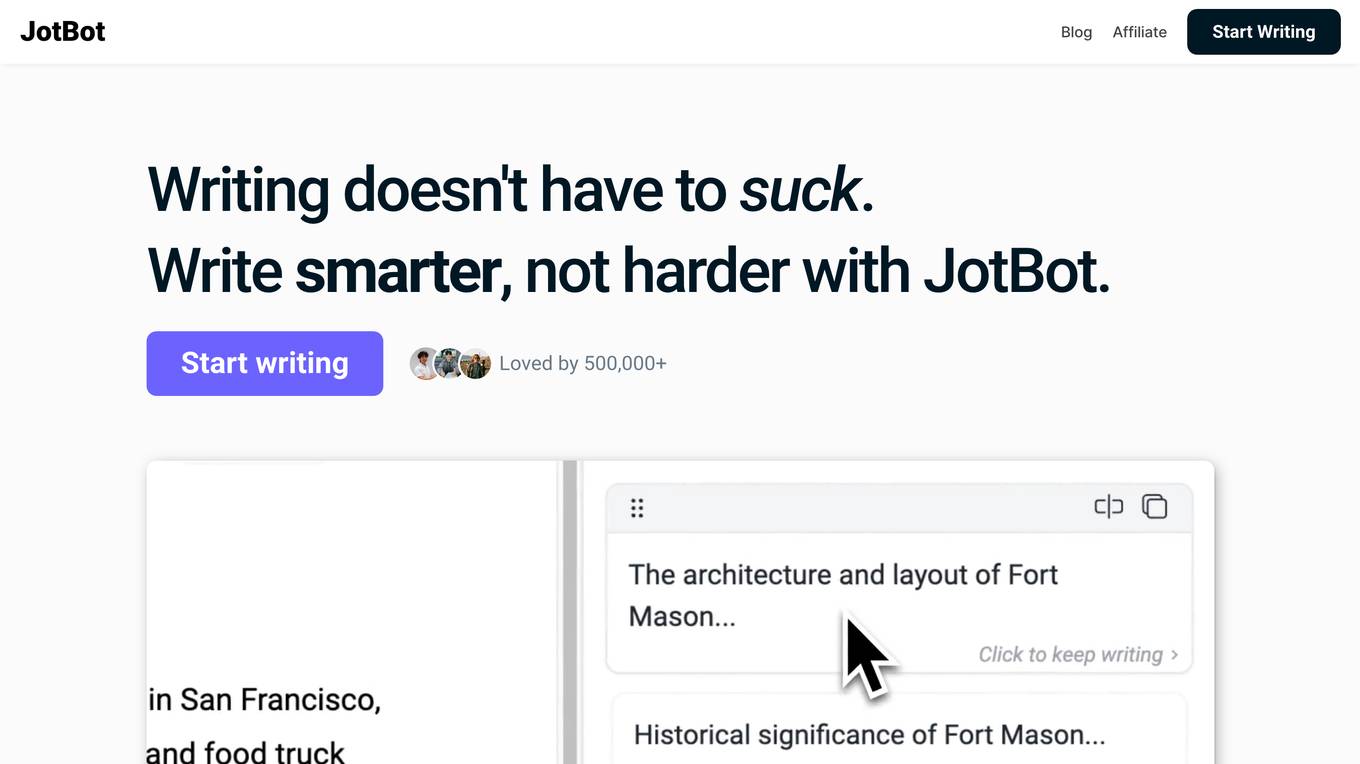
JotBot AI
JotBot is an AI writing tool that assists users in writing and research tasks by handling the struggle of finding the right words and sources. It offers features such as AI autocomplete, finding and citing sources, generating drafts in the user's voice, chat assistance, AI commands for writing and editing, and automatic note-taking. JotBot is trusted by top universities and businesses, with over 750,000 users leveraging its capabilities to enhance their writing process.
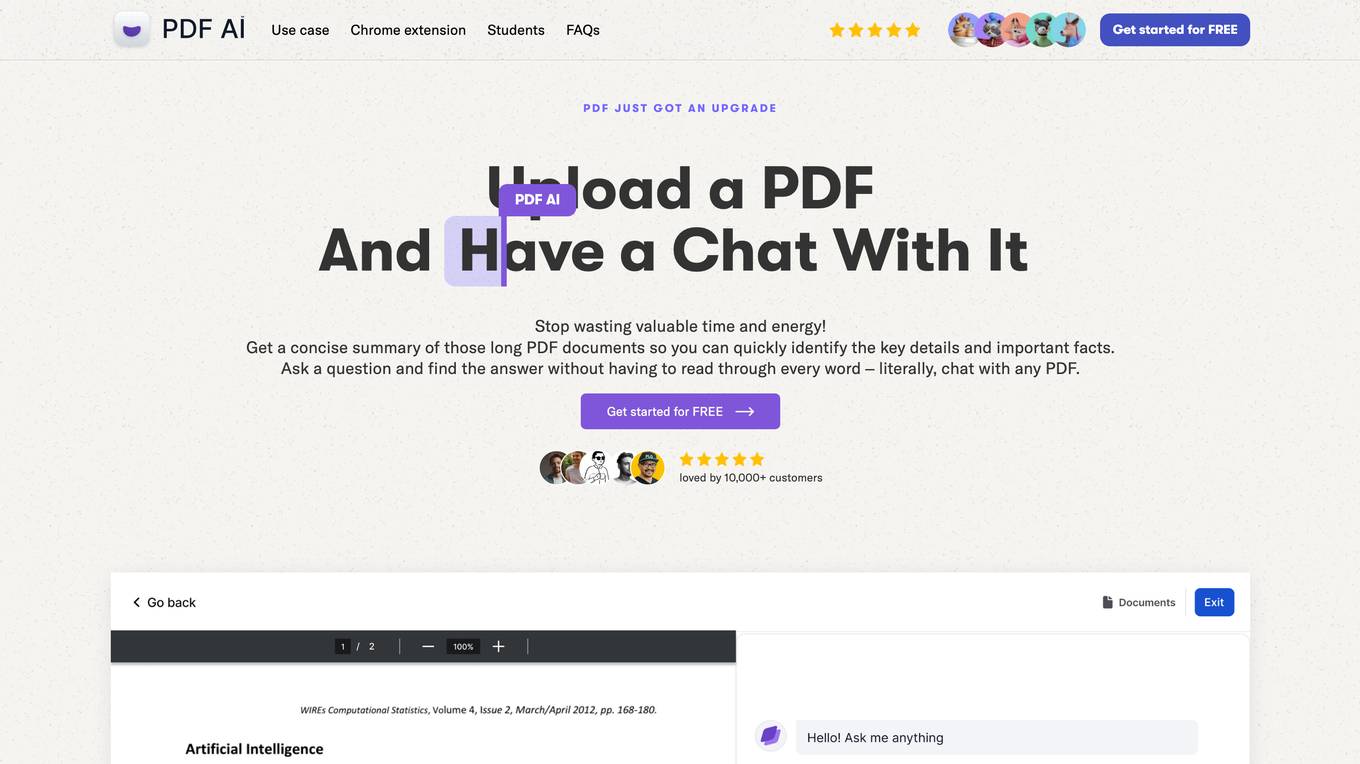
PDF AI
The website offers an AI-powered PDF reader that allows users to chat with any PDF document. Users can upload a PDF, ask questions, get answers, extract precise sections of text, summarize, annotate, highlight, classify, analyze, translate, and more. The AI tool helps in quickly identifying key details, finding answers without reading through every word, and citing sources. It is ideal for professionals in various fields like legal, finance, research, academia, healthcare, and public sector, as well as students. The tool aims to save time, increase productivity, and simplify document management and analysis.
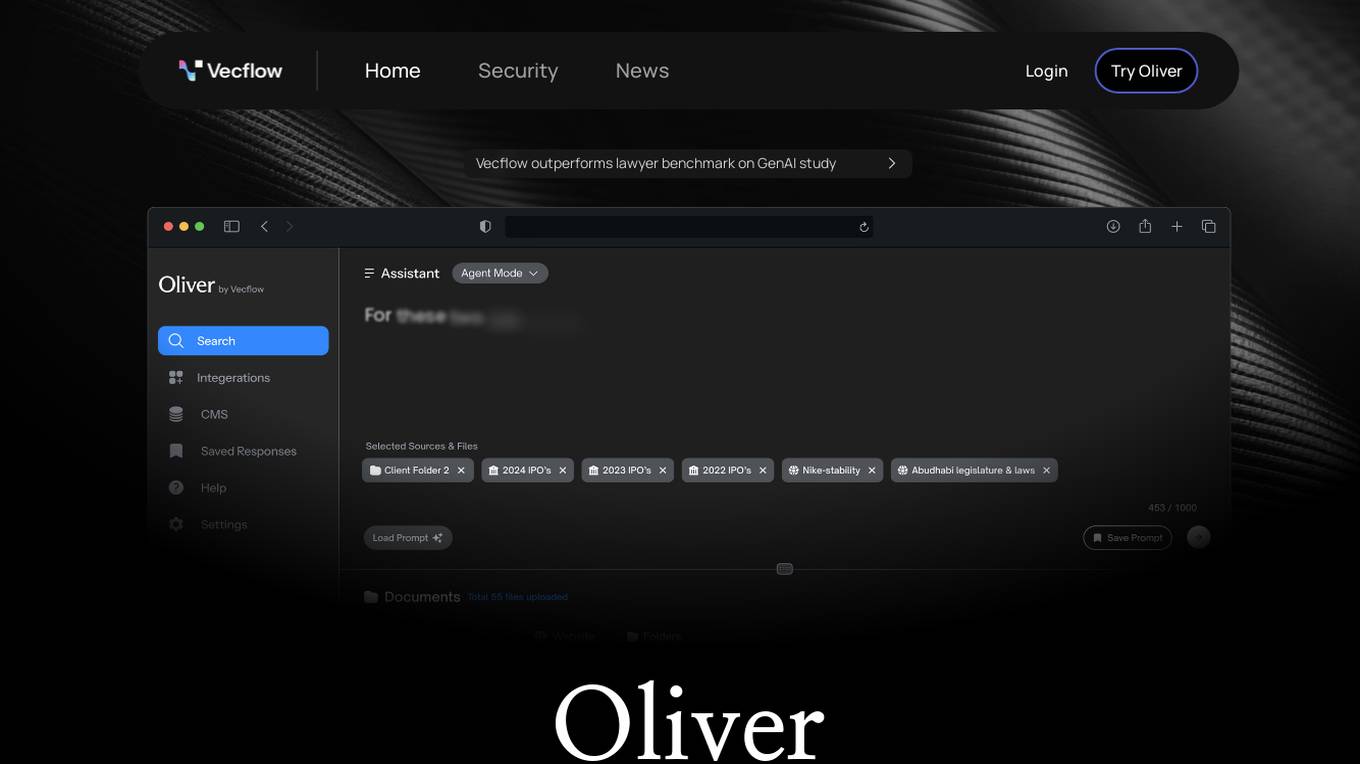
Vecflow
Vecflow is an AI-powered legal tool designed to revolutionize the legal industry by providing lawyer-level work product, long-term planning capabilities, transparency in citing sources, access to internal firm knowledge, and harnessing external data sources. It offers features such as accelerating work processes, mimicking real lawyer workflows, drafting fully formed documents, and connecting to various internal systems. Vecflow aims to streamline legal work processes and enhance efficiency by leveraging AI technology.
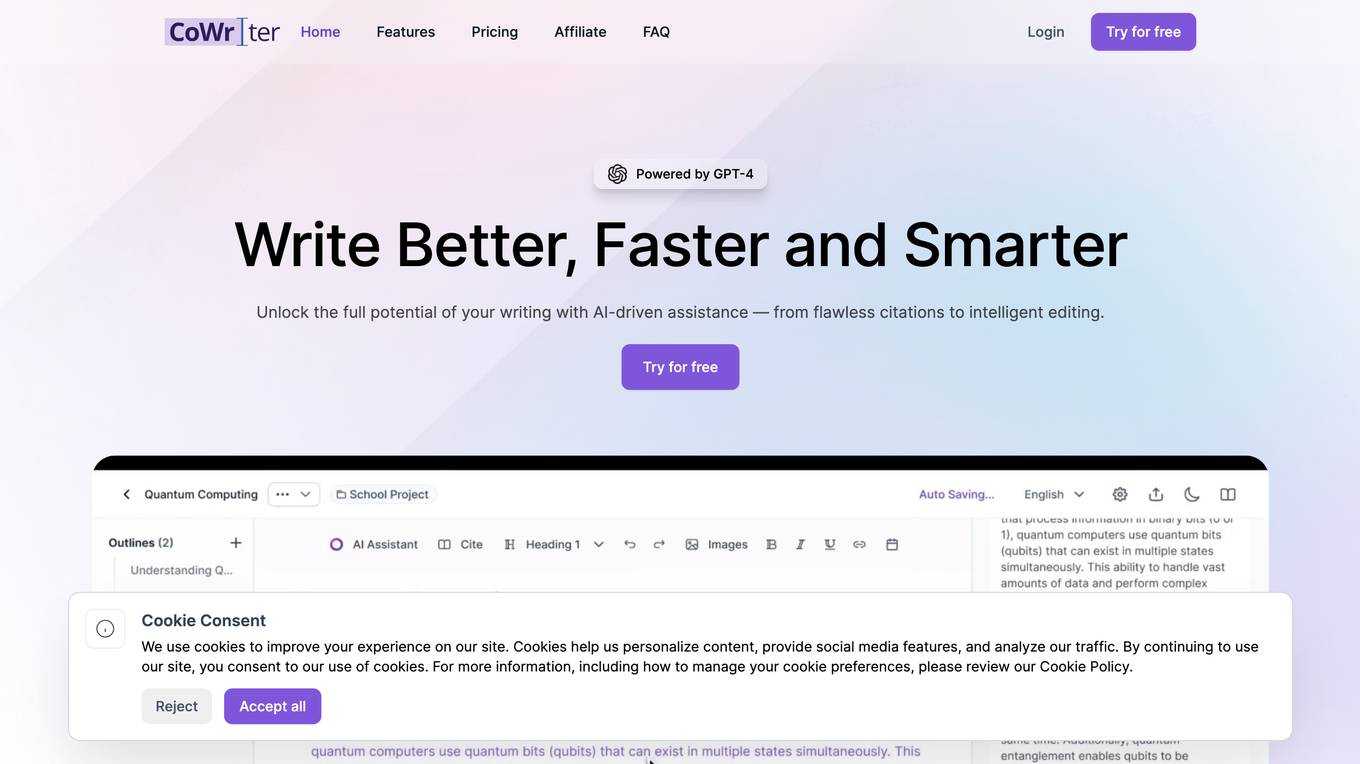
CoWriter AI
CoWriter AI is an advanced AI copilot for smart writing, powered by GPT-4 technology. It offers a range of features to enhance writing efficiency, originality, and time-saving capabilities. CoWriter caters to students, professionals, researchers, and writers by providing AI-powered autocompletion, citation formatting aid, bibliography library, writing styles and tones, and an outline builder. The application transforms writing experiences across various fields, including academic research, content creation, technical writing, business communications, creative writing, marketing, advertising, and legal documentation.
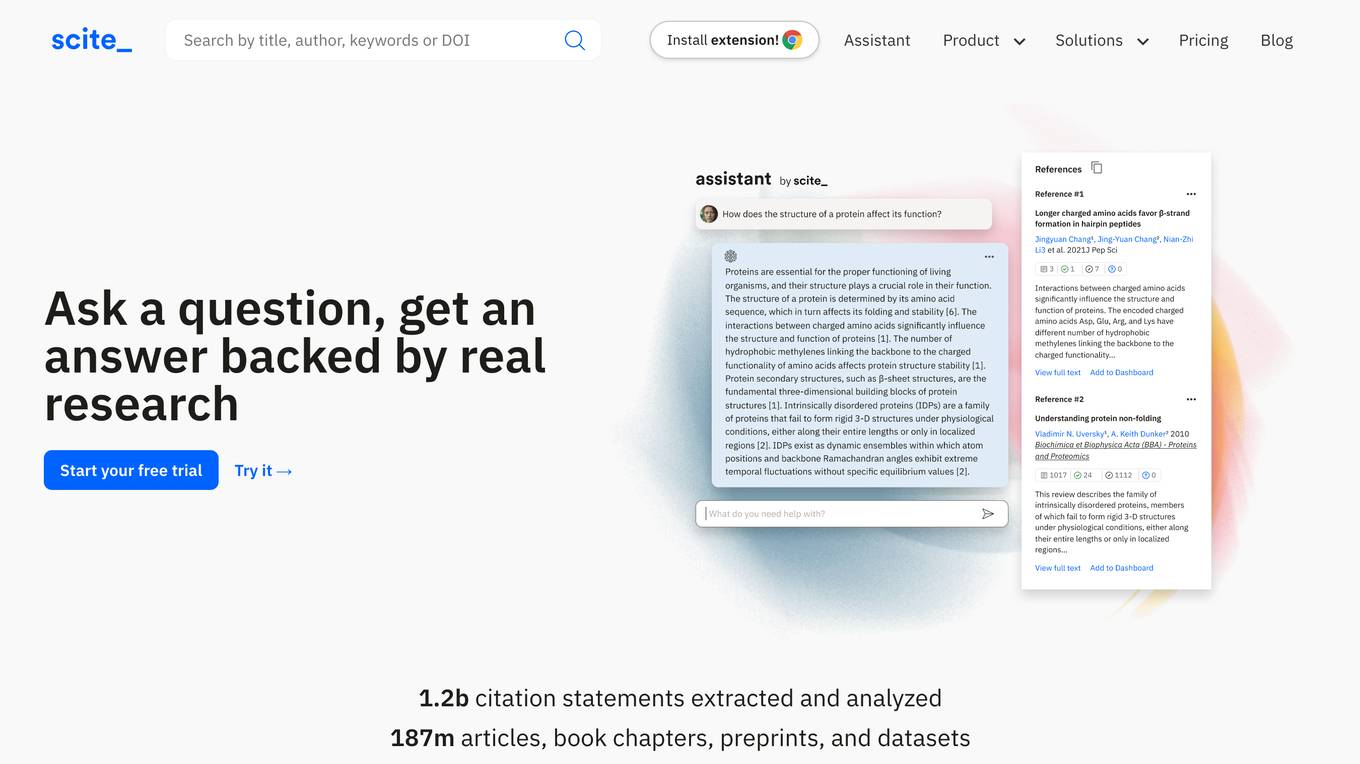
Scite
Scite is an award-winning platform for discovering and evaluating scientific articles via Smart Citations. Smart Citations allow users to see how a publication has been cited by providing the context of the citation and a classification describing whether it provides supporting or contrasting evidence for the cited claim.
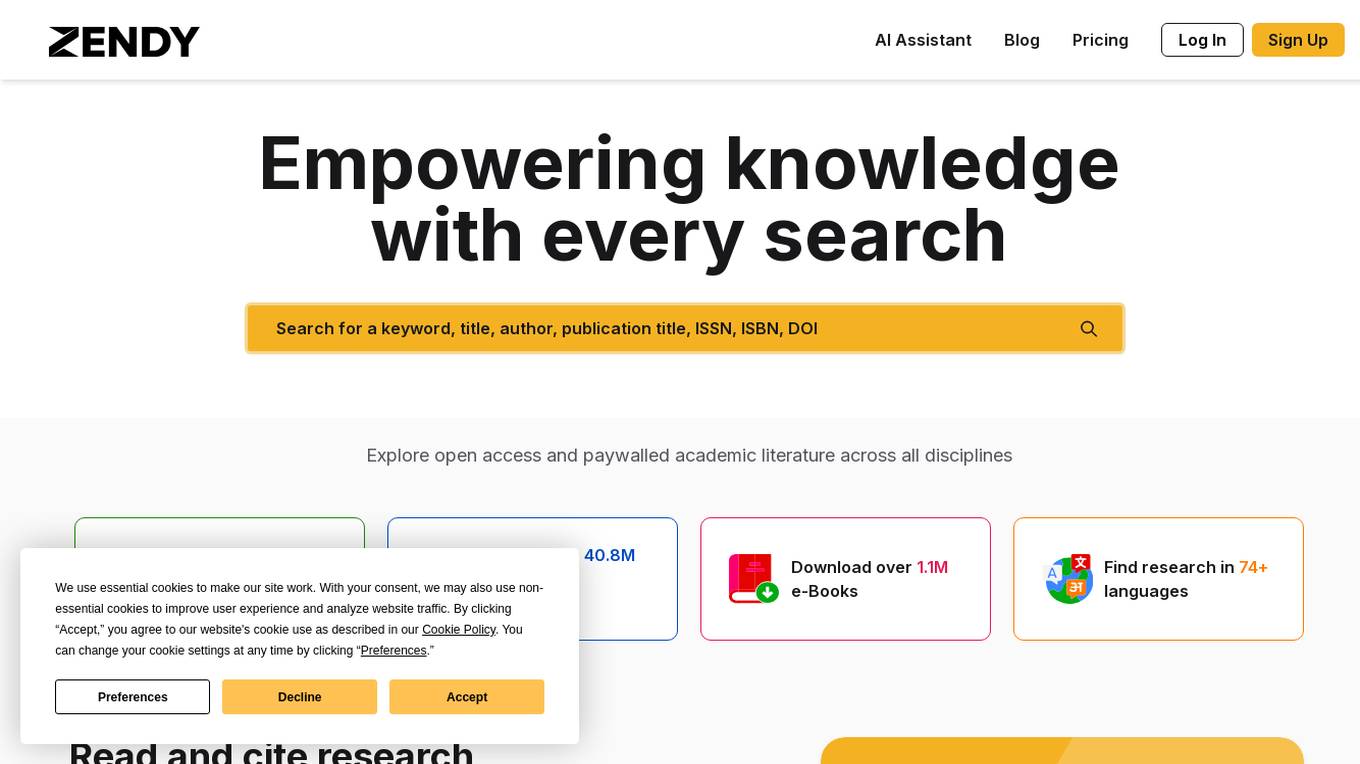
Zendy
Zendy is an AI-powered research library and AI assistant that empowers users to explore open access and paywalled academic literature across all disciplines. It offers tools for faster reading and citing of research papers, including AI summarization, key phrase highlighting, and organizing reading lists. With a user-friendly interface, Zendy helps users save time during literature review, making research more efficient and productive.
0 - Open Source AI Tools
8 - OpenAI Gpts
Disiz Mémoire
Academic writing assistant for thesis drafting, skilled in copywriting and citing sources.
Global Welding Advisor with Cited Sources
Multilingual welding expert citing information sources
Strategist Sun Tzu
Wisdom of Sun Tzu, citing 'The Art of War' with vivid sketches and multilingual insights.
"Garyaqaan - Lawyer"
Legal support, Citing civil and criminal law documents---Taageerada sharciga, tixraacaya dukumentiyada sharciga madaniga iyo dembiyada --- SOMALIA


" Personal Lawyer "
Pakistan, Legal support, Citing civil and criminal law documents --- قانونی معاونت، دیوانی اور فوجداری قانون کی دستاویزات کا حوالہ دیتے ہوئے ---