Best AI tools for< Check Code Correctness >
20 - AI tool Sites
ChatDBT
ChatDBT is a DBT designer with prompting that helps you write better DBT code. It provides a user-friendly interface that makes it easy to create and edit DBT models, and it includes a number of features that can help you improve the quality of your code.
Diffblue Cover
Diffblue Cover is an autonomous AI-powered unit test writing tool for Java development teams. It uses next-generation autonomous AI to automate unit testing, freeing up developers to focus on more creative work. Diffblue Cover can write a complete and correct Java unit test every 2 seconds, and it is directly integrated into CI pipelines, unlike AI-powered code suggestions that require developers to check the code for bugs. Diffblue Cover is trusted by the world's leading organizations, including Goldman Sachs, and has been proven to improve quality, lower developer effort, help with code understanding, reduce risk, and increase deployment frequency.
UpCodes
UpCodes is a searchable platform that provides access to building codes, assemblies, and building products libraries. It offers a comprehensive database of regulations and standards for construction projects, enabling users to easily search and reference relevant information. With UpCodes, architects, engineers, contractors, and other industry professionals can streamline their workflow, ensure compliance with codes, and enhance the quality of their designs. The platform is designed to simplify the process of accessing and interpreting building codes, saving time and reducing errors in construction projects.

VibeSafe
VibeSafe is an AI-powered security scanner designed specifically for vibe-coded apps. It conducts over 55 security checks in just 60 seconds to identify vulnerabilities in AI-generated code patterns. The tool provides a detailed report card with prioritized findings and step-by-step fix instructions. VibeSafe aims to address common security issues such as exposed secrets, authentication gaps, security headers, rate limiting, CORS, database exposure, and payment security. It offers Pro features for advanced users, including AI-generated fix codes, unlimited scans, and GitHub repo scanning.
GPTKit
GPTKit is a free AI text generation detection tool that utilizes six different AI-based content detection techniques to identify and classify text as either human- or AI-generated. It provides reports on the authenticity and reality of the analyzed content, with an accuracy of approximately 93%. The first 2048 characters in every request are free, and users can register for free to get 2048 characters/request.
Write Breeze
Write Breeze is an AI writing assistant that offers a suite of over 20 smart tools to enhance your writing experience. From grammar and style suggestions to content optimization, Write Breeze helps users create polished and engaging content effortlessly. Whether you're a student, professional writer, or content creator, Write Breeze is designed to streamline your writing process and elevate the quality of your work.
second.dev
second.dev is a domain that is currently parked for free, courtesy of GoDaddy.com. The website does not offer any specific services or products but rather serves as a placeholder for potential future use. It is important to note that any references to companies, products, or services on the site are not controlled by GoDaddy.com LLC and do not imply any association or endorsement by GoDaddy.

Site Not Found
The website page seems to be a placeholder or error page with the message 'Site Not Found'. It indicates that the user may not have deployed an app yet or may have an empty directory. The page suggests referring to hosting documentation to deploy the first app. The site appears to be under construction or experiencing technical issues.
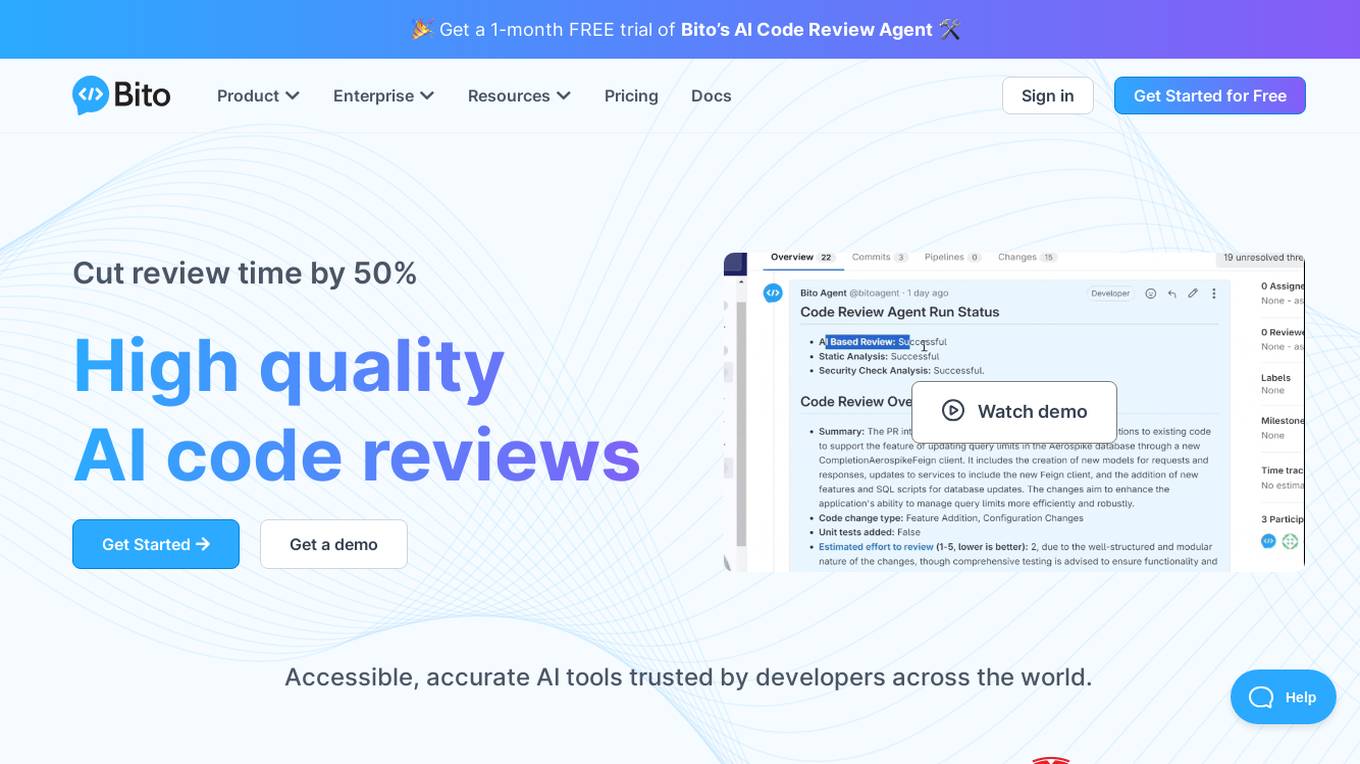
Bito AI
Bito AI is an AI-powered code review tool that helps developers write better code faster. It provides real-time feedback on code quality, security, and performance, and can also generate test cases and documentation. Bito AI is trusted by developers across the world, and has been shown to reduce review time by 50%.
404 Error Page
The website displays a '404: NOT_FOUND' error message indicating that the deployment cannot be found. It provides a code (DEPLOYMENT_NOT_FOUND) and an ID (sin1::22md2-1720772812453-4893618e160a) for reference. Users are directed to check the documentation for further information and troubleshooting.

altplot.com
altplot.com is a website that currently seems to be experiencing technical difficulties, as indicated by the error message 'Web server is down Error code 521'. The site appears to be hosted on Cloudflare and is inaccessible at the moment. Users are advised to wait a few minutes and try accessing the site again. For website owners, the recommendation is to contact the hosting provider to address the issue. The error message provides a Cloudflare Ray ID for reference.
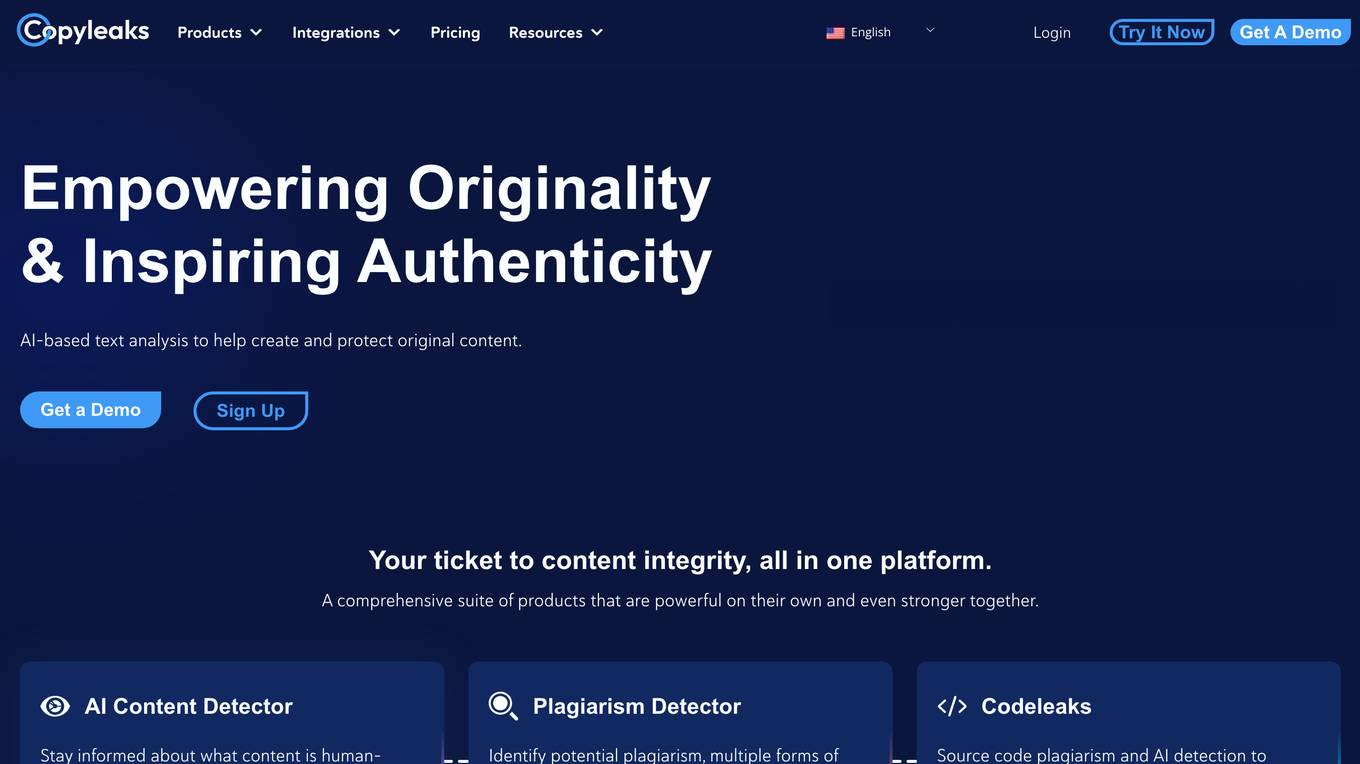
Copyleaks
Copyleaks is an AI-based plagiarism and AI content detection tool that helps users detect AI-generated code, plagiarized and modified source code, and provides essential licensing details. It offers solutions for academic integrity, governance and compliance, unauthorized large language model (LLM) usage, AI model training, and intellectual property protection. The tool includes products such as AI Detector, Plagiarism Checker, Writing Assistant, and API Integration, empowering users to ensure content integrity and transparency. Copyleaks also provides resources like news, AI testing methodologies, help center, success stories, and a blog to support users in protecting their content and adopting AI responsibly.
403 Forbidden
The website seems to be experiencing a 403 Forbidden error, which indicates that the server is refusing to respond to the request. This error is often caused by incorrect permissions on the server or misconfigured security settings. The message '403 Forbidden' is a standard HTTP status code that indicates the server understood the request but refuses to authorize it. It is not related to AI technology or applications.
404 Error Not Found
The website displays a 404 error message indicating that the deployment cannot be found. It provides a code (DEPLOYMENT_NOT_FOUND) and an ID (sin1::k7xdt-1736614074909-2dc430118e75) for reference. Users are directed to check the documentation for further information and troubleshooting.
Botonomous
Botonomous is an AI-powered platform that helps businesses automate their workflows. With Botonomous, you can create advanced automations for any domain, check your flows for potential errors before running them, run multiple nodes concurrently without waiting for the completion of the previous step, create complex, non-linear flows with no-code, and design human interactions to participate in your automations. Botonomous also offers a variety of other features, such as webhooks, scheduled triggers, secure secret management, and a developer community.
PaletteMaker
PaletteMaker is a unique tool for creative professionals and color lovers that allows you to create color palettes and test their behavior in pre-made design examples from the most common creative fields such as Logo design, UI/UX, Patterns, Posters and more. Check Color Behavior See how color works together in various of situations in graphic design. AI Color Palettes Filter palettes of different color tone and number of colors. Diverse Creative Fields Check your colors on logo, ui design, posters, illustrations and more. Create Palettes On-The-Go Instantly see the magic of creating color palettes. Totally Free PaletteMaker is created by professional designers, it’s completely free to use and forever will be. Powerful Export Export your palette in various formats, such as Procreate, Adobe ASE, Image, and even Code.

404 Error Notifier
The website displays a 404 error message indicating that the deployment cannot be found. It provides a code (DEPLOYMENT_NOT_FOUND) and an ID (sin1::tb2c2-1757006335226-e6bd40c1a978) for reference. Users are directed to check the documentation for further information and troubleshooting.
faye.xyz
faye.xyz is a website experiencing an SSL handshake failed error (Error code 525) due to Cloudflare being unable to establish an SSL connection to the origin server. The issue may be related to incompatible SSL configuration with Cloudflare, possibly due to no shared cipher suites. Visitors are advised to try again in a few minutes, while website owners are recommended to check the SSL configuration. Cloudflare provides additional troubleshooting information for resolving such errors.
404 Error Assistant
The website displays a 404 error message indicating that the deployment cannot be found. It provides a code (DEPLOYMENT_NOT_FOUND) and an ID (sfo1::smrsr-1771524097601-5775e36f41ad) for reference. Users are directed to check the documentation for further information and troubleshooting.
404 Error Finder
The website displays a 404 error message indicating that the deployment cannot be found. It provides a code (DEPLOYMENT_NOT_FOUND) and an ID (sfo1::ncg7q-1770918099254-dd1178523b2c) for reference. Users are directed to check the documentation for further information and troubleshooting.
1 - Open Source AI Tools

llm-verified-with-monte-carlo-tree-search
This prototype synthesizes verified code with an LLM using Monte Carlo Tree Search (MCTS). It explores the space of possible generation of a verified program and checks at every step that it's on the right track by calling the verifier. This prototype uses Dafny, Coq, Lean, Scala, or Rust. By using this technique, weaker models that might not even know the generated language all that well can compete with stronger models.
20 - OpenAI Gpts
Anchorage Code Navigator
EXPERIMENT - Friendly guide for navigating Anchorage Municipal Code - Double Check info
Code Navigator - Hempstead, NY
Answers questions about Hempstead, NY's code with diagrams and sources.

Orthographe Pro
Un outil de correction d'orthographe et de grammaire en langue française, outil de traduction, soulignant les erreurs et gérant le code HTML.

SignageGPT
Identify and Confirm Interior Signage Code Details & Requirements. Federal, California ADA Signage Codes (NY Coming Soon)
RedlineGPT
Upload a jpg/png (<5MB, <2000px) for architectural drawing feedback. Note: This tool is not adept at calculations, counting, and can't guarantee code compliance. Consider IP issues before uploading.