Best AI tools for< Build Following >
20 - AI tool Sites

Troves AI
Troves AI is a complete creative writing platform designed to empower writers in their journey from story concept to published success. The platform offers a range of powerful tools and features to help writers plan, write, create, and promote their fiction works. From gaining insights on trending genres to generating promotional materials, Troves AI aims to streamline the writing process and enhance the overall creative experience for writers.
UPTO3
UPTO3 is a decentralized event knowledge graph protocol that aims to provide consensus verification for Web3 events. It turns events into NFTs, allowing users to mint and verify events while being rewarded based on the results. The platform promotes open data, transparency, and unbiased analysis through economic incentives. UPTO3 will be built on Blast(L2) and offers features such as event minting as NFTs, decentralized verification tasks, and gas rewards for validators. The project launch is scheduled to coincide with the mainnet launch of Blast in February, following the testnet launch in January.
Tala
Tala is an AI-powered language tutor designed for hands-on learners. It encourages free-flowing conversation early in the learning journey, focusing on natural language acquisition rather than rote memorization. With advanced speech recognition technology, Tala helps users build confidence in speaking and offers a flexible learning experience with adjustable listening speeds and easy access to look-up tools. The platform aims to make language learning engaging and immersive, allowing users to practice without fear of embarrassment and improve their pronunciation through interactive conversations.
Tutor AI
Tutor AI is an AI English-speaking application designed to assist individuals in practicing their spoken English skills with the aid of an artificial intelligence chatbot. The app offers a safe and judgment-free environment for users to engage in free-flowing, natural conversations with diverse AI characters. It provides real-time feedback, suggests better ways to express oneself, and offers adjustable features to enhance the learning experience. Tutor AI aims to improve users' spoken English skills confidently and effectively through personalized lessons and interactive learning.
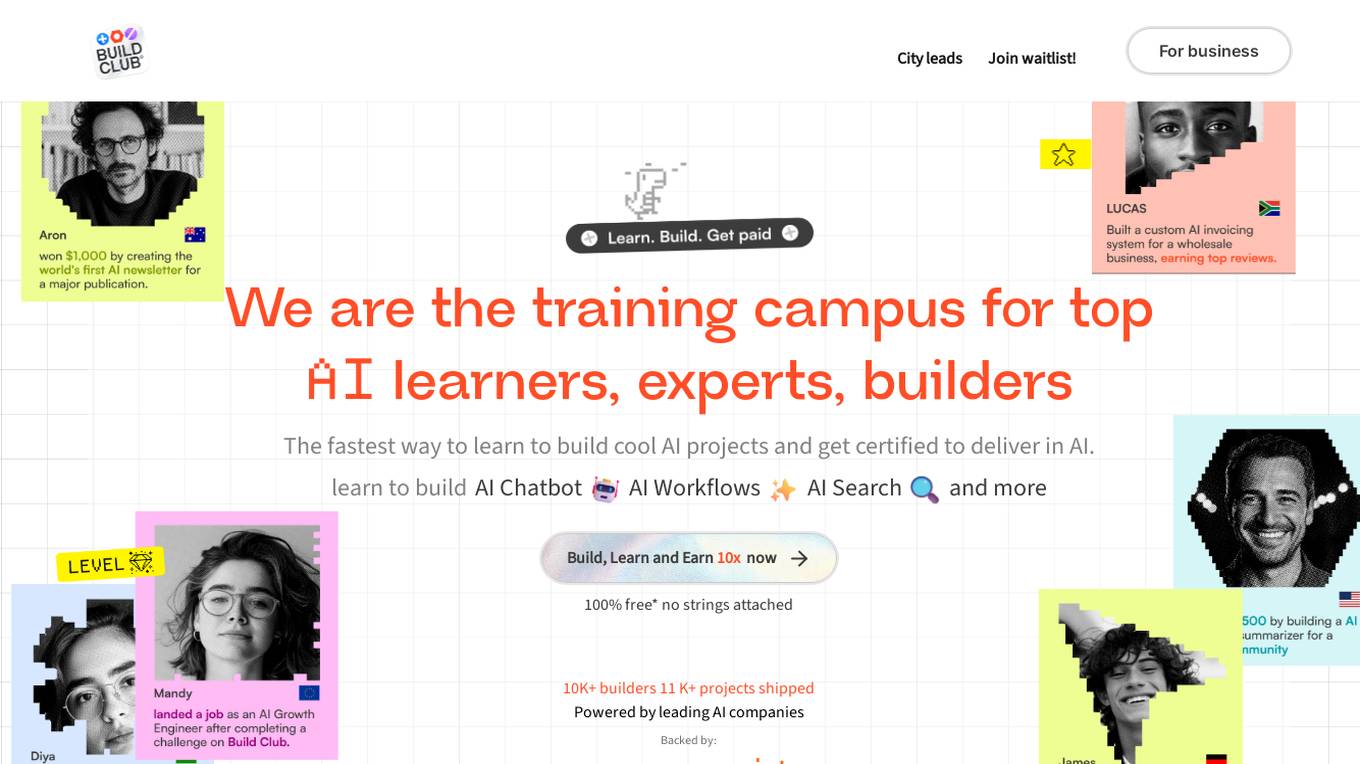
Build Club
Build Club is a leading training campus for AI learners, experts, and builders. It offers a platform where individuals can upskill into AI careers, get certified by top AI companies, learn the latest AI tools, and earn money by solving real problems. The community at Build Club consists of AI learners, engineers, consultants, and founders who collaborate on cutting-edge AI projects. The platform provides challenges, support, and resources to help individuals build AI projects and advance their skills in the field.
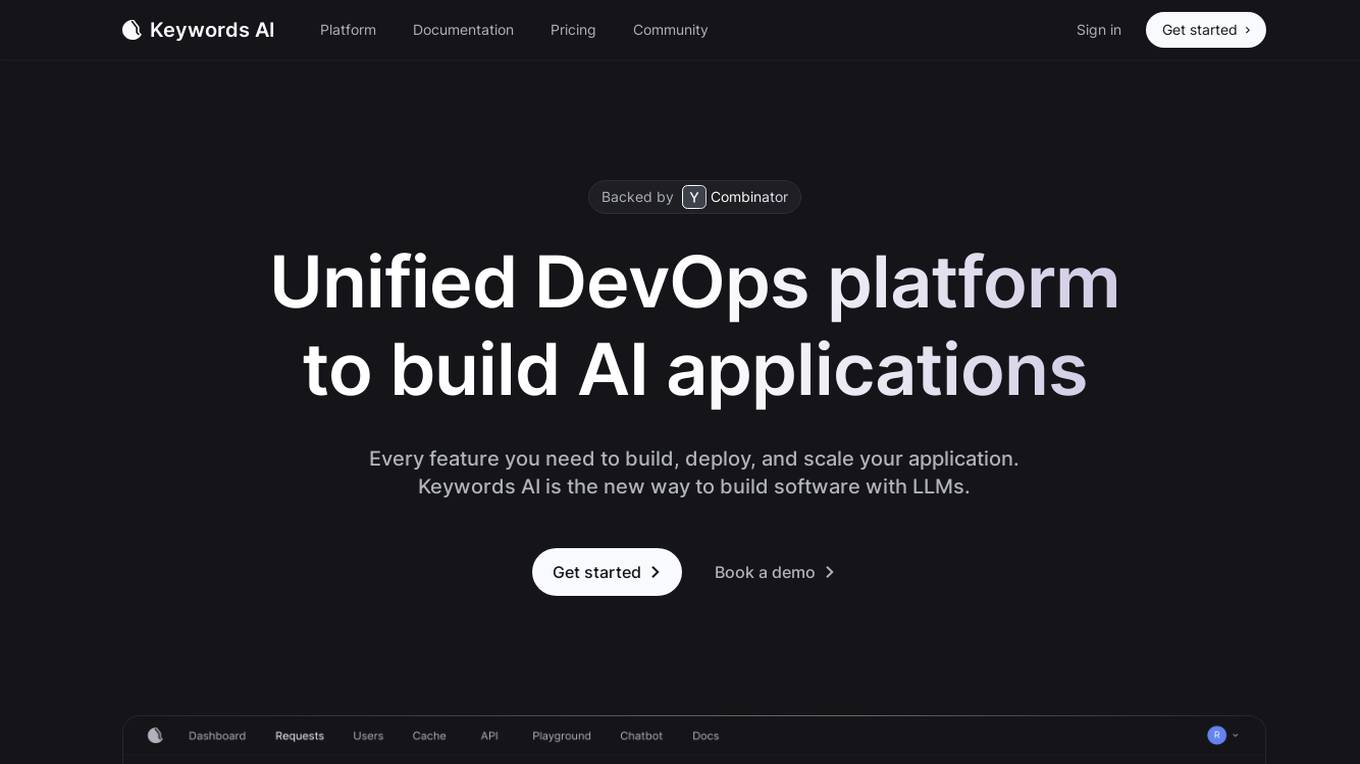
Unified DevOps platform to build AI applications
This is a unified DevOps platform to build AI applications. It provides a comprehensive set of tools and services to help developers build, deploy, and manage AI applications. The platform includes a variety of features such as a code editor, a debugger, a profiler, and a deployment manager. It also provides access to a variety of AI services, such as natural language processing, machine learning, and computer vision.
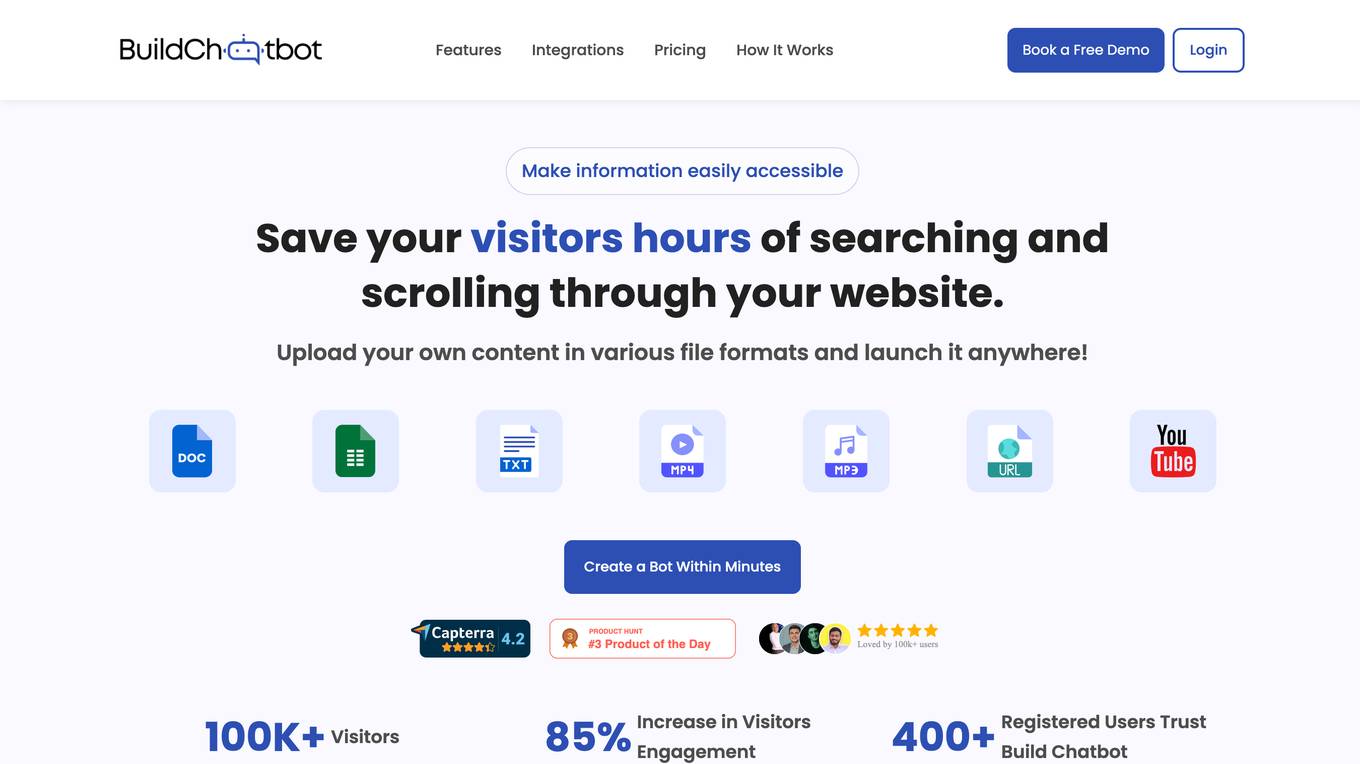
Build Chatbot
Build Chatbot is a no-code chatbot builder designed to simplify the process of creating chatbots. It enables users to build their chatbot without any coding knowledge, auto-train it with personalized content, and get the chatbot ready with an engaging UI. The platform offers various features to enhance user engagement, provide personalized responses, and streamline communication with website visitors. Build Chatbot aims to save time for both businesses and customers by making information easily accessible and transforming visitors into satisfied customers.
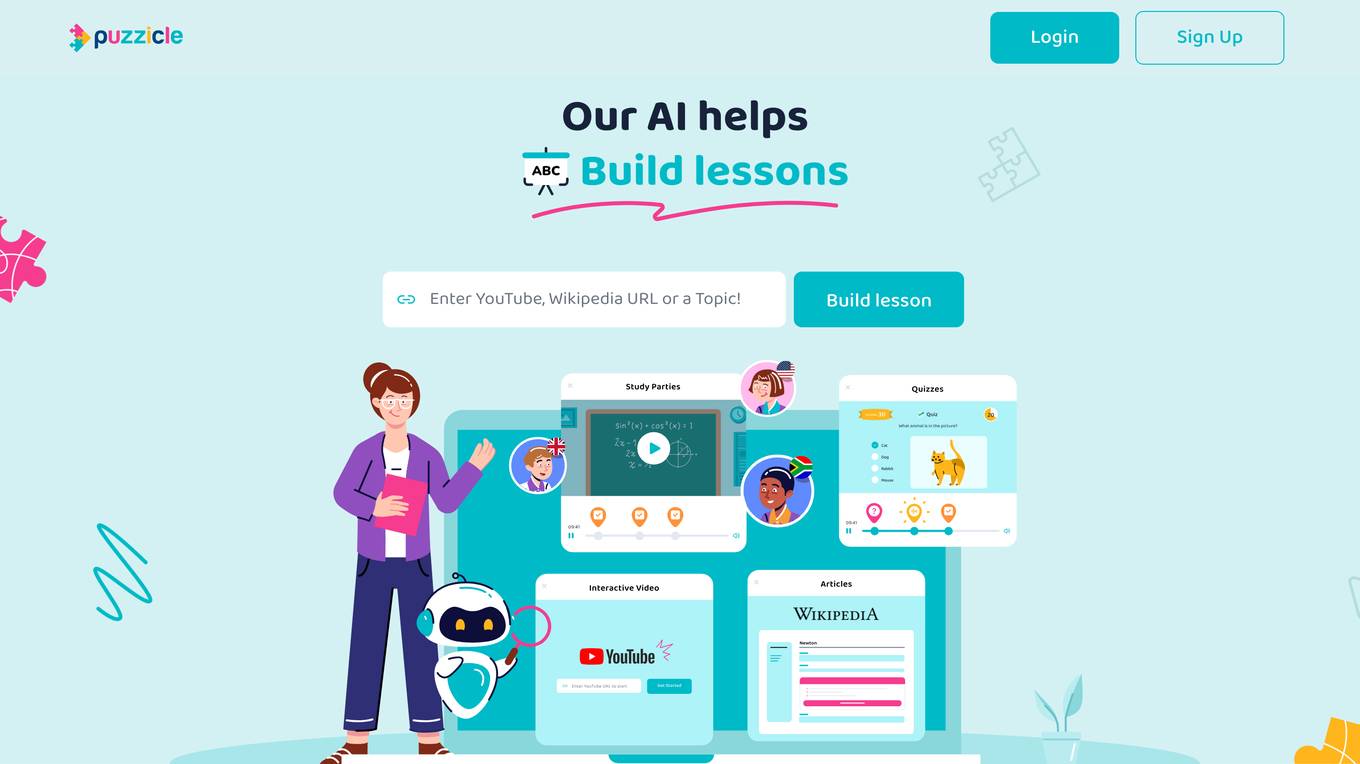
Build-a-Lesson
Build-a-Lesson is an AI-powered platform that allows educators and individuals to create interactive video lessons effortlessly. The application leverages AI technology to generate quizzes, enhance learning experiences, and transform traditional study sessions into engaging and collaborative activities. With Build-a-Lesson, users can turn any YouTube video or Wikipedia article into an immersive learning experience, complete with interactive elements and assessments. The platform aims to revolutionize the way lessons are created and delivered, making learning more interactive, engaging, and effective for students of all ages.
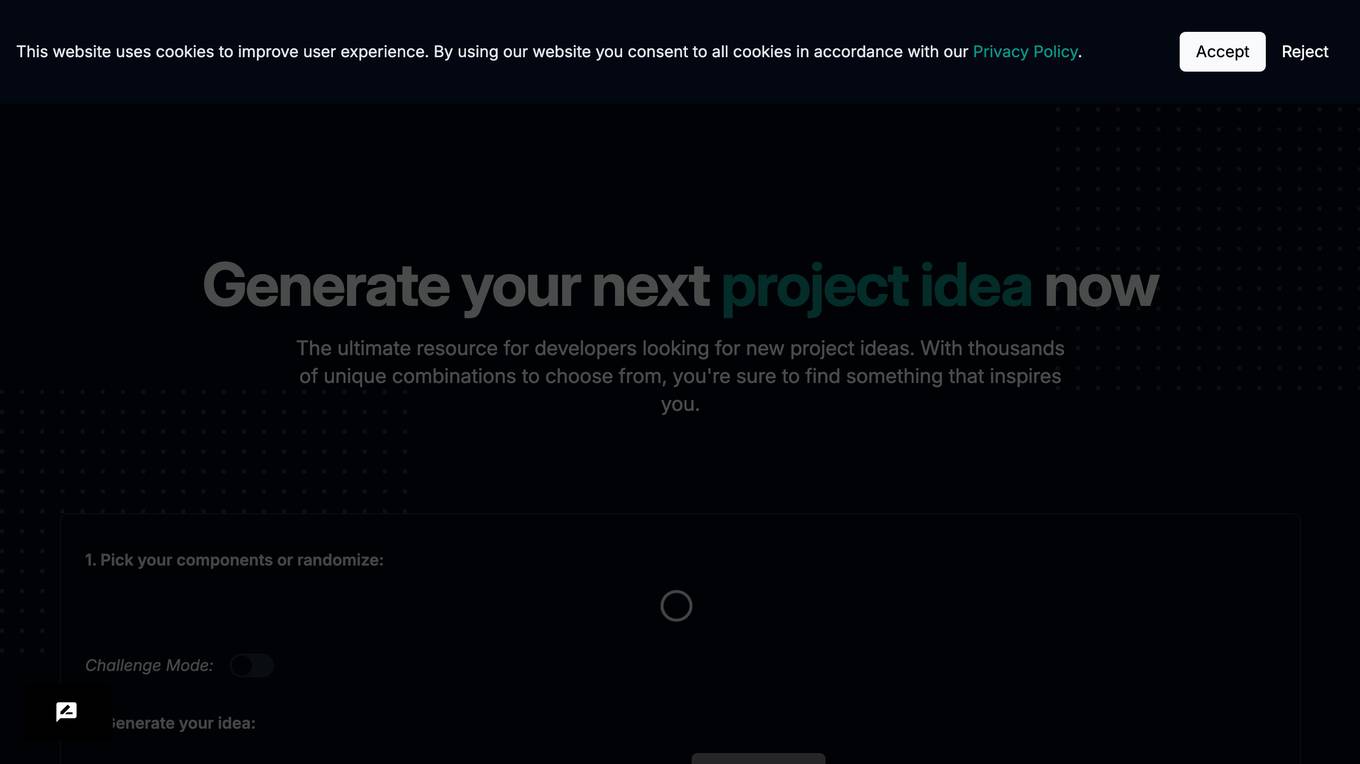
What should I build next?
The website 'What should I build next?' is a platform designed to help developers generate random development project ideas. It offers a variety of unique combinations for users to choose from, inspiring them to start new projects. Users can pick components or randomize, participate in challenge mode, and generate project ideas. The platform also rewards active users with free credits daily, ensuring a continuous flow of ideas for development projects.
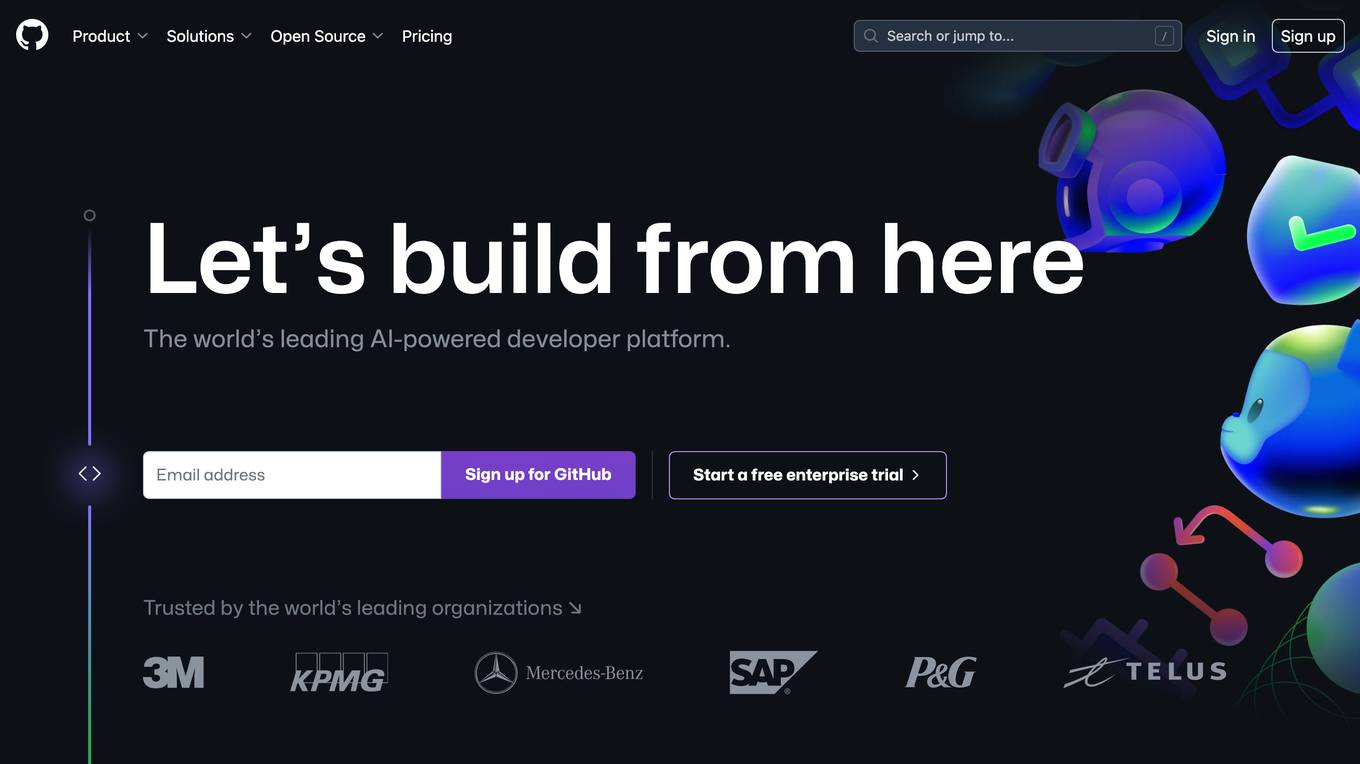
GitHub
GitHub is a collaborative platform for building and shipping software that offers various features such as GitHub Copilot for AI-powered coding assistance, security tools for finding and fixing vulnerabilities, automation of workflows, instant development environments, project management, code review, and collaboration tools. It aims to simplify the software development process and improve developer productivity by leveraging AI technology.
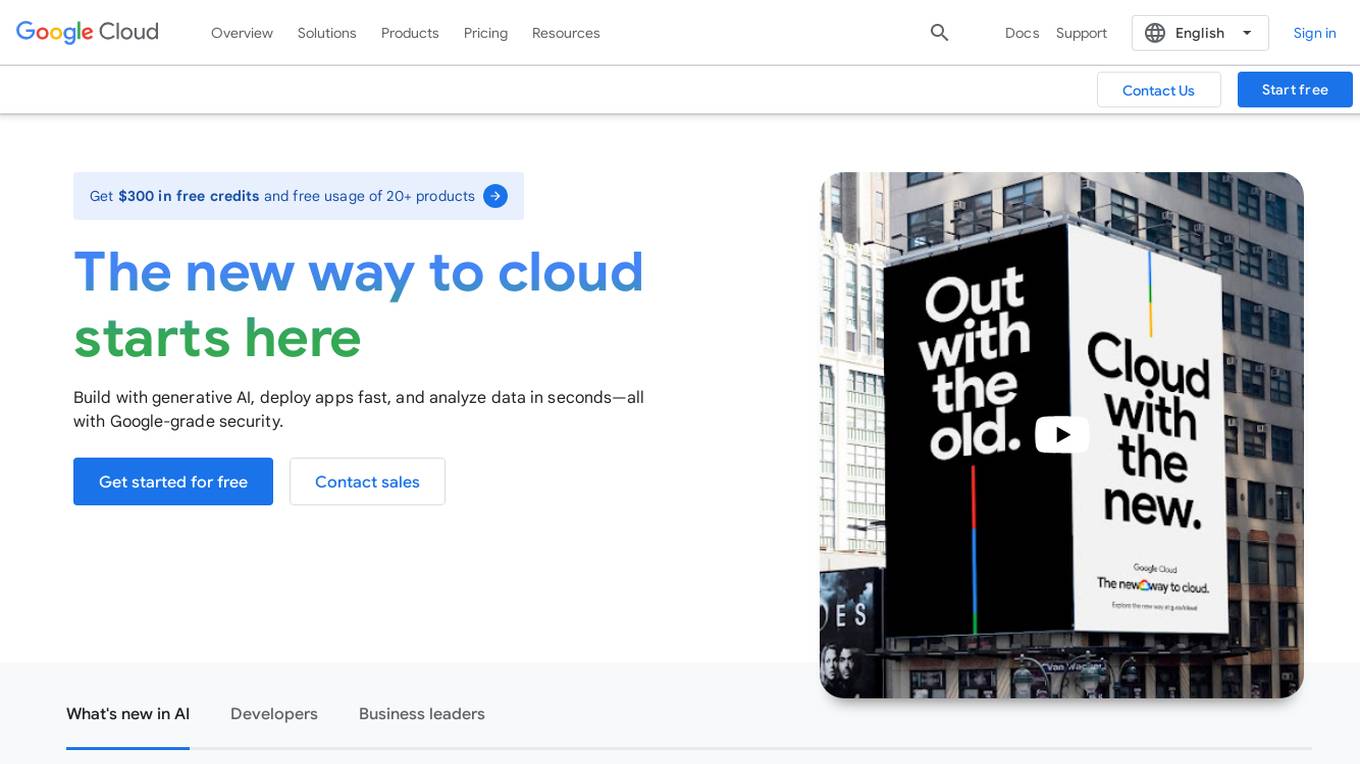
Google Cloud
Google Cloud is a suite of cloud computing services that runs on the same infrastructure as Google. Its services include computing, storage, networking, databases, machine learning, and more. Google Cloud is designed to make it easy for businesses to develop and deploy applications in the cloud. It offers a variety of tools and services to help businesses with everything from building and deploying applications to managing their infrastructure. Google Cloud is also committed to sustainability, and it has a number of programs in place to reduce its environmental impact.
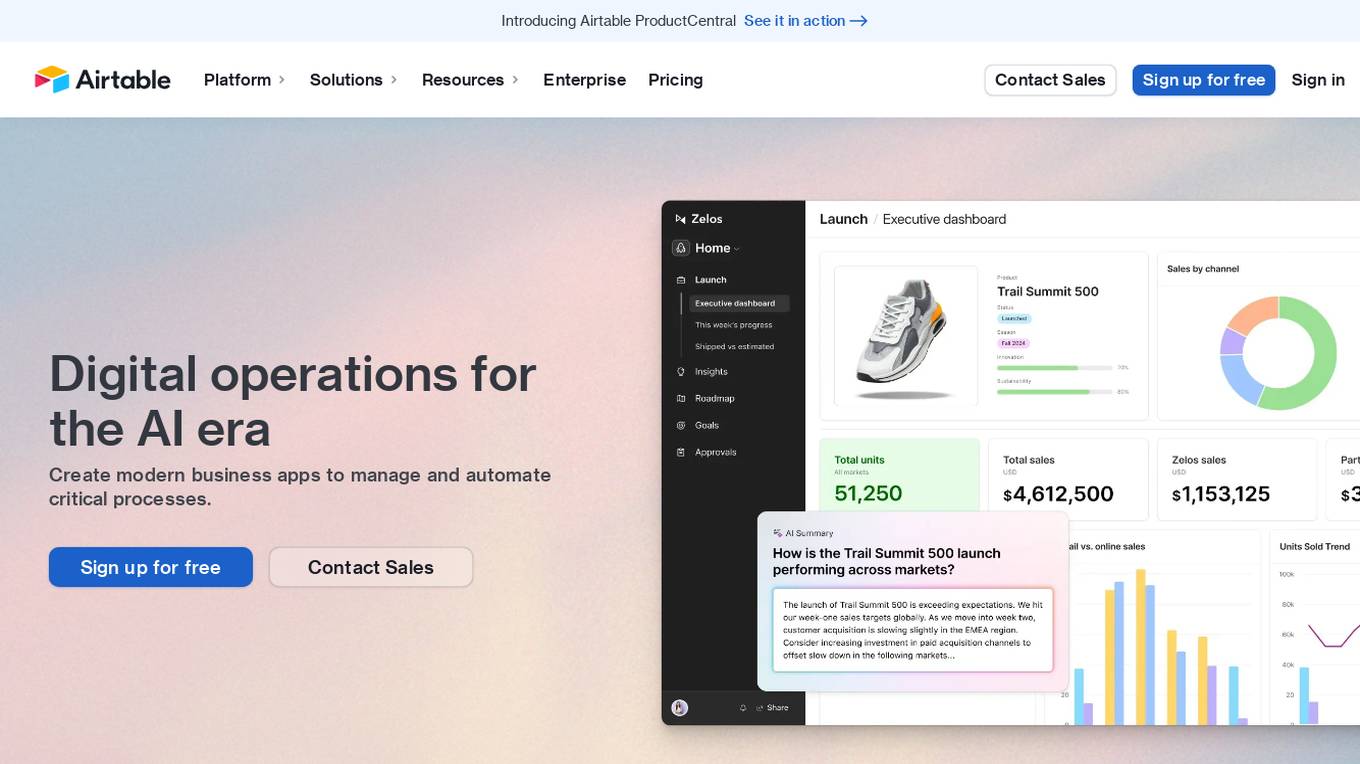
Airtable
Airtable is a next-gen app-building platform that enables teams to create custom business apps without the need for coding. It offers features like AI integration, connected data, automations, interface design, and data visualization. Airtable allows users to manage security, permissions, and data protection at scale. The platform also provides integrations with popular tools like Slack, Google Drive, and Salesforce, along with an extension marketplace for additional templates and apps. Users can streamline workflows, automate processes, and gain insights through reporting and analytics.
Gemini
Gemini is a large and powerful AI model developed by Google. It is designed to handle a wide variety of text and image reasoning tasks, and it can be used to build a variety of AI-powered applications. Gemini is available in three sizes: Ultra, Pro, and Nano. Ultra is the most capable model, but it is also the most expensive. Pro is the best performing model for a wide variety of tasks, and it is a good value for the price. Nano is the most efficient model, and it is designed for on-device use cases.

Notion
Notion is an AI-integrated workspace platform that combines wiki, docs, and project management functionalities in one tool. It offers a centralized hub for teams to collaborate, share knowledge, manage projects, and streamline workflows. With AI assistance, users can enhance their productivity by automating tasks, generating content, and finding information quickly. Notion aims to simplify work processes and empower teams to work more efficiently and creatively.
FlutterFlow
FlutterFlow is a low-code development platform that enables users to build cross-platform mobile and web applications without writing code. It provides a visual interface for designing user interfaces, connecting data, and implementing complex logic. FlutterFlow is trusted by users at leading companies around the world and has been used to build a wide range of applications, from simple prototypes to complex enterprise solutions.
Enhancv
Enhancv is an AI-powered online resume builder that helps users create professional resumes and cover letters tailored to their job applications. The tool offers a drag-and-drop resume builder with a variety of modern templates, a resume checker that evaluates resumes for ATS-friendliness, and provides actionable suggestions. Enhancv also provides resume and CV examples written by experienced professionals, a resume tailoring feature, and a free resume checker. Users can download their resumes in PDF or TXT formats and store up to 30 documents in cloud storage.
Bubble
Bubble is a no-code application development platform that allows users to build and deploy web and mobile applications without writing any code. It provides a visual interface for designing and developing applications, and it includes a library of pre-built components and templates that can be used to accelerate development. Bubble is suitable for a wide range of users, from beginners with no coding experience to experienced developers who want to build applications quickly and easily.
Zyro
Zyro is a website builder that allows users to create professional websites and online stores without any coding knowledge. It offers a range of features, including customizable templates, drag-and-drop editing, and AI-powered tools to help users brand and grow their businesses.

Abacus.AI
Abacus.AI is the world's first AI platform where AI, not humans, build Applied AI agents and systems at scale. Using generative AI and other novel neural net techniques, AI can build LLM apps, gen AI agents, and predictive applied AI systems at scale.
Pinecone
Pinecone is a vector database that helps power AI for the world's best companies. It is a serverless database that lets you deliver remarkable GenAI applications faster, at up to 50x lower cost. Pinecone is easy to use and can be integrated with your favorite cloud provider, data sources, models, frameworks, and more.
20 - Open Source AI Tools
nx_open
The `nx_open` repository contains open-source components for the Network Optix Meta Platform, used to build products like Nx Witness Video Management System. It includes source code, specifications, and a Desktop Client. The repository is licensed under Mozilla Public License 2.0. Users can build the Desktop Client and customize it using a zip file. The build environment supports Windows, Linux, and macOS platforms with specific prerequisites. The repository provides scripts for building, signing executable files, and running the Desktop Client. Compatibility with VMS Server versions is crucial, and automatic VMS updates are disabled for the open-source Desktop Client.
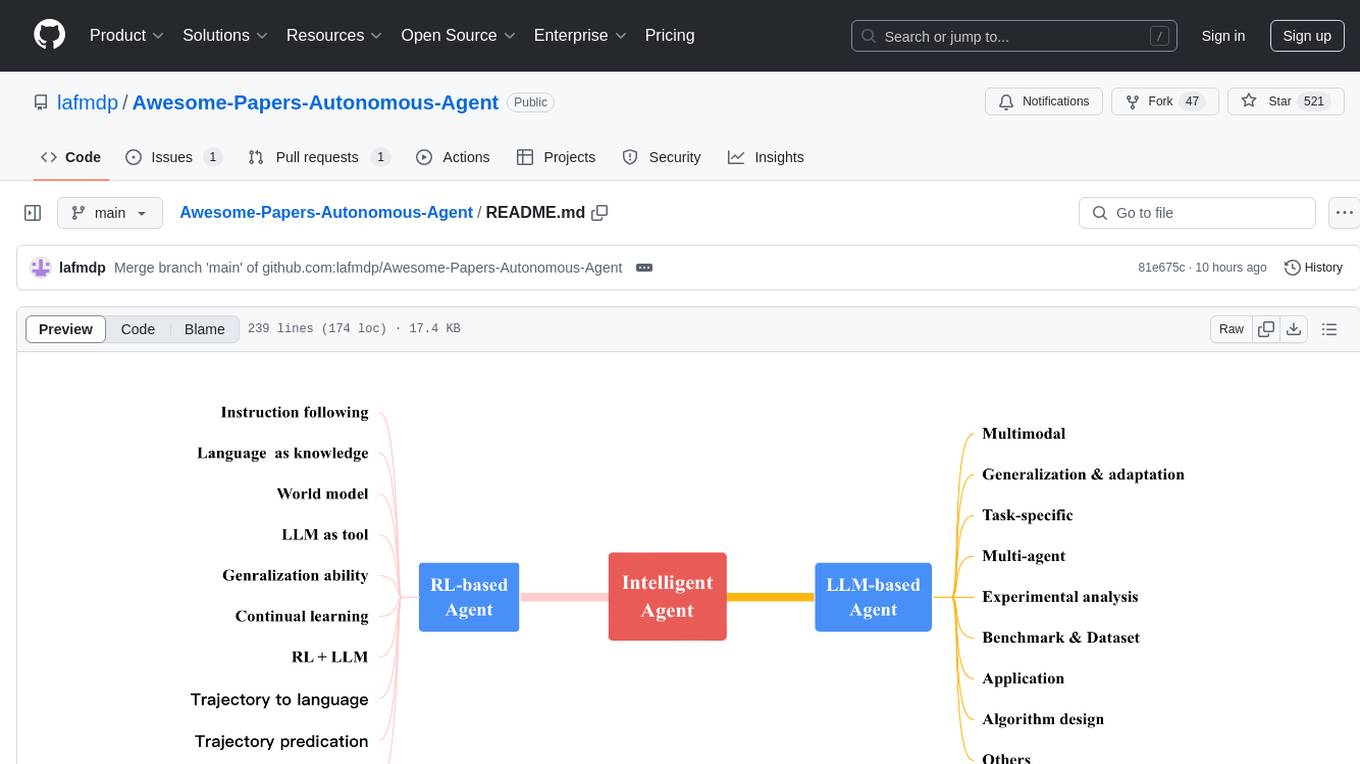
Awesome-Papers-Autonomous-Agent
Awesome-Papers-Autonomous-Agent is a curated collection of recent papers focusing on autonomous agents, specifically interested in RL-based agents and LLM-based agents. The repository aims to provide a comprehensive resource for researchers and practitioners interested in intelligent agents that can achieve goals, acquire knowledge, and continually improve. The collection includes papers on various topics such as instruction following, building agents based on world models, using language as knowledge, leveraging LLMs as a tool, generalization across tasks, continual learning, combining RL and LLM, transformer-based policies, trajectory to language, trajectory prediction, multimodal agents, training LLMs for generalization and adaptation, task-specific designing, multi-agent systems, experimental analysis, benchmarking, applications, algorithm design, and combining with RL.

llm-vscode
llm-vscode is an extension designed for all things LLM, utilizing llm-ls as its backend. It offers features such as code completion with 'ghost-text' suggestions, the ability to choose models for code generation via HTTP requests, ensuring prompt size fits within the context window, and code attribution checks. Users can configure the backend, suggestion behavior, keybindings, llm-ls settings, and tokenization options. Additionally, the extension supports testing models like Code Llama 13B, Phind/Phind-CodeLlama-34B-v2, and WizardLM/WizardCoder-Python-34B-V1.0. Development involves cloning llm-ls, building it, and setting up the llm-vscode extension for use.

aiid
The Artificial Intelligence Incident Database (AIID) is a collection of incidents involving the development and use of artificial intelligence (AI). The database is designed to help researchers, policymakers, and the public understand the potential risks and benefits of AI, and to inform the development of policies and practices to mitigate the risks and promote the benefits of AI. The AIID is a collaborative project involving researchers from the University of California, Berkeley, the University of Washington, and the University of Toronto.
Aiwnios
Aiwnios is a HolyC Compiler/Runtime designed for 64-bit ARM, RISCV, and x86 machines, including Apple M1 Macs, with plans for supporting other architectures in the future. The project is currently a work in progress, with regular updates and improvements planned. Aiwnios includes a sockets API (currently tested on FreeBSD) and a HolyC assembler accessible through AARCH64. The heart of Aiwnios lies in `arm_backend.c`, where the compiler is located, and a powerful AARCH64 assembler in `arm64_asm.c`. The compiler uses reverse Polish notation and statements are reversed. The developer manual is intended for developers working on the C side, providing detailed explanations of the source code.
Oxen
Oxen is a data version control library, written in Rust. It's designed to be fast, reliable, and easy to use. Oxen can be used in a variety of ways, from a simple command line tool to a remote server to sync to, to integrations into other ecosystems such as python.

curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.
ygo-agent
YGO Agent is a project focused on using deep learning to master the Yu-Gi-Oh! trading card game. It utilizes reinforcement learning and large language models to develop advanced AI agents that aim to surpass human expert play. The project provides a platform for researchers and players to explore AI in complex, strategic game environments.

unitycatalog
Unity Catalog is an open and interoperable catalog for data and AI, supporting multi-format tables, unstructured data, and AI assets. It offers plugin support for extensibility and interoperates with Delta Sharing protocol. The catalog is fully open with OpenAPI spec and OSS implementation, providing unified governance for data and AI with asset-level access control enforced through REST APIs.

LARS
LARS is an application that enables users to run Large Language Models (LLMs) locally on their devices, upload their own documents, and engage in conversations where the LLM grounds its responses with the uploaded content. The application focuses on Retrieval Augmented Generation (RAG) to increase accuracy and reduce AI-generated inaccuracies. LARS provides advanced citations, supports various file formats, allows follow-up questions, provides full chat history, and offers customization options for LLM settings. Users can force enable or disable RAG, change system prompts, and tweak advanced LLM settings. The application also supports GPU-accelerated inferencing, multiple embedding models, and text extraction methods. LARS is open-source and aims to be the ultimate RAG-centric LLM application.
void
Void is an open-source Cursor alternative, providing a full source code for users to build and develop. It is a fork of the vscode repository, offering a waitlist for the official release. Users can contribute by checking the Project board and following the guidelines in CONTRIBUTING.md. Support is available through Discord or email.
Build-your-own-AI-Assistant-Solution-Accelerator
Build-your-own-AI-Assistant-Solution-Accelerator is a pre-release and preview solution that helps users create their own AI assistants. It leverages Azure Open AI Service, Azure AI Search, and Microsoft Fabric to identify, summarize, and categorize unstructured information. Users can easily find relevant articles and grants, generate grant applications, and export them as PDF or Word documents. The solution accelerator provides reusable architecture and code snippets for building AI assistants with enterprise data. It is designed for researchers looking to explore flu vaccine studies and grants to accelerate grant proposal submissions.

octopus-v4
The Octopus-v4 project aims to build the world's largest graph of language models, integrating specialized models and training Octopus models to connect nodes efficiently. The project focuses on identifying, training, and connecting specialized models. The repository includes scripts for running the Octopus v4 model, methods for managing the graph, training code for specialized models, and inference code. Environment setup instructions are provided for Linux with NVIDIA GPU. The Octopus v4 model helps users find suitable models for tasks and reformats queries for effective processing. The project leverages Language Large Models for various domains and provides benchmark results. Users are encouraged to train and add specialized models following recommended procedures.

activepieces
Activepieces is an open source replacement for Zapier, designed to be extensible through a type-safe pieces framework written in Typescript. It features a user-friendly Workflow Builder with support for Branches, Loops, and Drag and Drop. Activepieces integrates with Google Sheets, OpenAI, Discord, and RSS, along with 80+ other integrations. The list of supported integrations continues to grow rapidly, thanks to valuable contributions from the community. Activepieces is an open ecosystem; all piece source code is available in the repository, and they are versioned and published directly to npmjs.com upon contributions. If you cannot find a specific piece on the pieces roadmap, please submit a request by visiting the following link: Request Piece Alternatively, if you are a developer, you can quickly build your own piece using our TypeScript framework. For guidance, please refer to the following guide: Contributor's Guide

deepdoctection
**deep** doctection is a Python library that orchestrates document extraction and document layout analysis tasks using deep learning models. It does not implement models but enables you to build pipelines using highly acknowledged libraries for object detection, OCR and selected NLP tasks and provides an integrated framework for fine-tuning, evaluating and running models. For more specific text processing tasks use one of the many other great NLP libraries. **deep** doctection focuses on applications and is made for those who want to solve real world problems related to document extraction from PDFs or scans in various image formats. **deep** doctection provides model wrappers of supported libraries for various tasks to be integrated into pipelines. Its core function does not depend on any specific deep learning library. Selected models for the following tasks are currently supported: * Document layout analysis including table recognition in Tensorflow with **Tensorpack**, or PyTorch with **Detectron2**, * OCR with support of **Tesseract**, **DocTr** (Tensorflow and PyTorch implementations available) and a wrapper to an API for a commercial solution, * Text mining for native PDFs with **pdfplumber**, * Language detection with **fastText**, * Deskewing and rotating images with **jdeskew**. * Document and token classification with all LayoutLM models provided by the **Transformer library**. (Yes, you can use any LayoutLM-model with any of the provided OCR-or pdfplumber tools straight away!). * Table detection and table structure recognition with **table-transformer**. * There is a small dataset for token classification available and a lot of new tutorials to show, how to train and evaluate this dataset using LayoutLMv1, LayoutLMv2, LayoutXLM and LayoutLMv3. * Comprehensive configuration of **analyzer** like choosing different models, output parsing, OCR selection. Check this notebook or the docs for more infos. * Document layout analysis and table recognition now runs with **Torchscript** (CPU) as well and **Detectron2** is not required anymore for basic inference. * [**new**] More angle predictors for determining the rotation of a document based on **Tesseract** and **DocTr** (not contained in the built-in Analyzer). * [**new**] Token classification with **LiLT** via **transformers**. We have added a model wrapper for token classification with LiLT and added a some LiLT models to the model catalog that seem to look promising, especially if you want to train a model on non-english data. The training script for LayoutLM can be used for LiLT as well and we will be providing a notebook on how to train a model on a custom dataset soon. **deep** doctection provides on top of that methods for pre-processing inputs to models like cropping or resizing and to post-process results, like validating duplicate outputs, relating words to detected layout segments or ordering words into contiguous text. You will get an output in JSON format that you can customize even further by yourself. Have a look at the **introduction notebook** in the notebook repo for an easy start. Check the **release notes** for recent updates. **deep** doctection or its support libraries provide pre-trained models that are in most of the cases available at the **Hugging Face Model Hub** or that will be automatically downloaded once requested. For instance, you can find pre-trained object detection models from the Tensorpack or Detectron2 framework for coarse layout analysis, table cell detection and table recognition. Training is a substantial part to get pipelines ready on some specific domain, let it be document layout analysis, document classification or NER. **deep** doctection provides training scripts for models that are based on trainers developed from the library that hosts the model code. Moreover, **deep** doctection hosts code to some well established datasets like **Publaynet** that makes it easy to experiment. It also contains mappings from widely used data formats like COCO and it has a dataset framework (akin to **datasets** so that setting up training on a custom dataset becomes very easy. **This notebook** shows you how to do this. **deep** doctection comes equipped with a framework that allows you to evaluate predictions of a single or multiple models in a pipeline against some ground truth. Check again **here** how it is done. Having set up a pipeline it takes you a few lines of code to instantiate the pipeline and after a for loop all pages will be processed through the pipeline.
tensorrtllm_backend
The TensorRT-LLM Backend is a Triton backend designed to serve TensorRT-LLM models with Triton Inference Server. It supports features like inflight batching, paged attention, and more. Users can access the backend through pre-built Docker containers or build it using scripts provided in the repository. The backend can be used to create models for tasks like tokenizing, inferencing, de-tokenizing, ensemble modeling, and more. Users can interact with the backend using provided client scripts and query the server for metrics related to request handling, memory usage, KV cache blocks, and more. Testing for the backend can be done following the instructions in the 'ci/README.md' file.
wordlift-plugin
WordLift is a plugin that helps online content creators organize posts and pages by adding facts, links, and media to build beautifully structured websites for both humans and search engines. It allows users to create, own, and publish their own knowledge graph, and publishes content as Linked Open Data following Tim Berners-Lee's Linked Data Principles. The plugin supports writers by providing trustworthy and contextual facts, enriching content with images, links, and interactive visualizations, keeping readers engaged with relevant content recommendations, and producing content compatible with schema.org markup for better indexing and display on search engines. It also offers features like creating a personal Wikipedia, publishing metadata to share and distribute content, and supporting content tagging for better SEO.
llm-universe
This project is a tutorial on developing large model applications for novice developers. It aims to provide a comprehensive introduction to large model development, focusing on Alibaba Cloud servers and integrating personal knowledge assistant projects. The tutorial covers the following topics: 1. **Introduction to Large Models**: A simplified introduction for novice developers on what large models are, their characteristics, what LangChain is, and how to develop an LLM application. 2. **How to Call Large Model APIs**: This section introduces various methods for calling APIs of well-known domestic and foreign large model products, including calling native APIs, encapsulating them as LangChain LLMs, and encapsulating them as Fastapi calls. It also provides a unified encapsulation for various large model APIs, such as Baidu Wenxin, Xunfei Xinghuo, and Zh譜AI. 3. **Knowledge Base Construction**: Loading, processing, and vector database construction of different types of knowledge base documents. 4. **Building RAG Applications**: Integrating LLM into LangChain to build a retrieval question and answer chain, and deploying applications using Streamlit. 5. **Verification and Iteration**: How to implement verification and iteration in large model development, and common evaluation methods. The project consists of three main parts: 1. **Introduction to LLM Development**: A simplified version of V1 aims to help beginners get started with LLM development quickly and conveniently, understand the general process of LLM development, and build a simple demo. 2. **LLM Development Techniques**: More advanced LLM development techniques, including but not limited to: Prompt Engineering, processing of multiple types of source data, optimizing retrieval, recall ranking, Agent framework, etc. 3. **LLM Application Examples**: Introduce some successful open source cases, analyze the ideas, core concepts, and implementation frameworks of these application examples from the perspective of this course, and help beginners understand what kind of applications they can develop through LLM. Currently, the first part has been completed, and everyone is welcome to read and learn; the second and third parts are under creation. **Directory Structure Description**: requirements.txt: Installation dependencies in the official environment notebook: Notebook source code file docs: Markdown documentation file figures: Pictures data_base: Knowledge base source file used

mindnlp
MindNLP is an open-source NLP library based on MindSpore. It provides a platform for solving natural language processing tasks, containing many common approaches in NLP. It can help researchers and developers to construct and train models more conveniently and rapidly. Key features of MindNLP include: * Comprehensive data processing: Several classical NLP datasets are packaged into a friendly module for easy use, such as Multi30k, SQuAD, CoNLL, etc. * Friendly NLP model toolset: MindNLP provides various configurable components. It is friendly to customize models using MindNLP. * Easy-to-use engine: MindNLP simplified complicated training process in MindSpore. It supports Trainer and Evaluator interfaces to train and evaluate models easily. MindNLP supports a wide range of NLP tasks, including: * Language modeling * Machine translation * Question answering * Sentiment analysis * Sequence labeling * Summarization MindNLP also supports industry-leading Large Language Models (LLMs), including Llama, GLM, RWKV, etc. For support related to large language models, including pre-training, fine-tuning, and inference demo examples, you can find them in the "llm" directory. To install MindNLP, you can either install it from Pypi, download the daily build wheel, or install it from source. The installation instructions are provided in the documentation. MindNLP is released under the Apache 2.0 license. If you find this project useful in your research, please consider citing the following paper: @misc{mindnlp2022, title={{MindNLP}: a MindSpore NLP library}, author={MindNLP Contributors}, howpublished = {\url{https://github.com/mindlab-ai/mindnlp}}, year={2022} }
DataEngineeringPilipinas
DataEngineeringPilipinas is a repository dedicated to data engineering resources in the Philippines. It serves as a platform for data engineering professionals to contribute and access high-quality content related to data engineering. The repository provides guidelines for contributing, including forking the repository, making changes, and submitting contributions. It emphasizes the importance of quality, relevance, and respect in the contributions made to the project. By following the guidelines and contributing to the repository, users can help build a valuable resource for the data engineering community in the Philippines and beyond.
20 - OpenAI Gpts
Medium Muse 2.0
I create Medium posts tailored to your brand and audience. Provide the following: [BRAND CONTEXT], [AUDIENCE CONTEXT], [POST TOPIC] | UPDATE #1 - Added SEO optimization



Build a Brand
Unique custom images based on your input. Just type ideas and the brand image is created.
Beam Eye Tracker Extension Copilot
Build extensions using the Eyeware Beam eye tracking SDK


Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model

League Champion Builder GPT
Build your own League of Legends Style Champion with Abilities, Back Story and Splash Art
RenovaTecno
Your tech buddy helping you refurbish or build a PC from scratch, tailored to your needs, budget, and language.

Gradle Expert
Your expert in Gradle build configuration, offering clear, practical advice.



XRPL GPT
Build on the XRP Ledger with assistance from this GPT trained on extensive documentation and code samples.