Best AI tools for< Assess Hrv >
20 - AI tool Sites
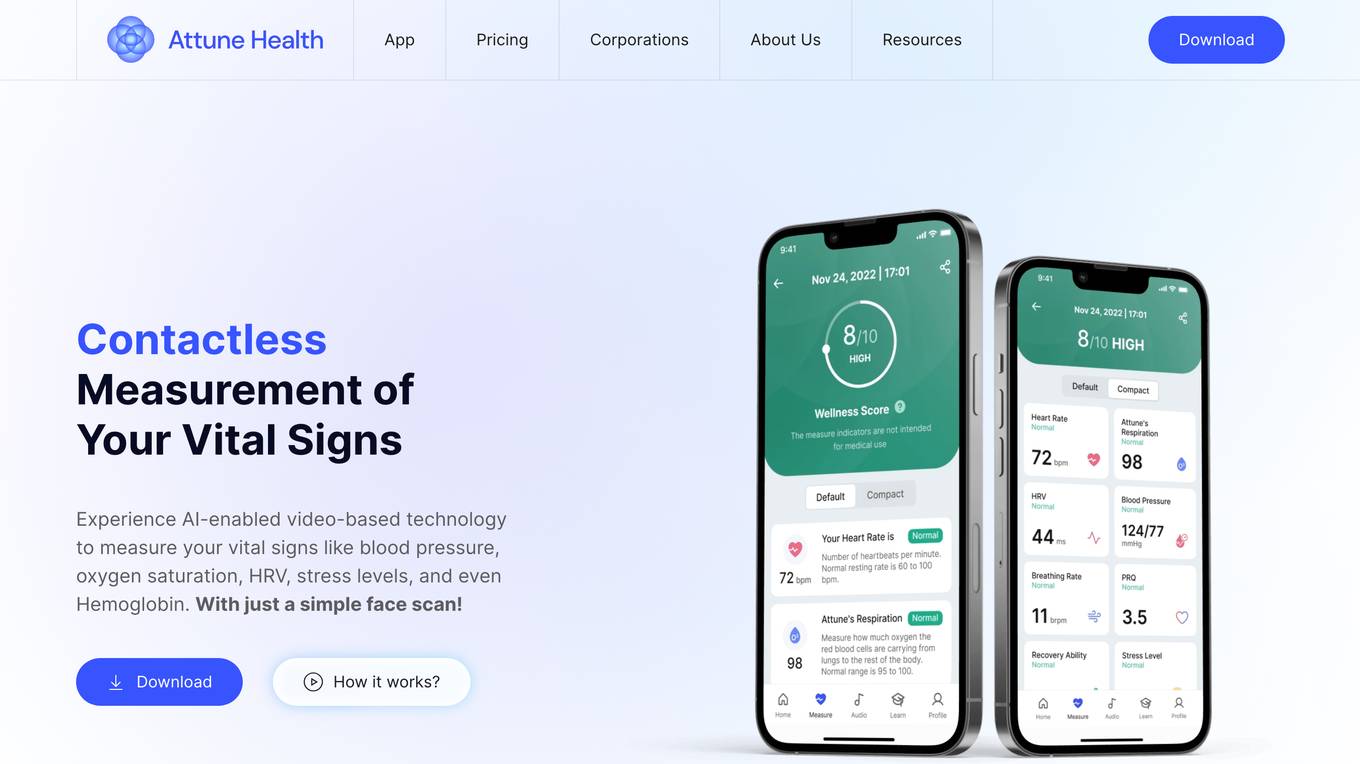
Attune Health Mobile App
Attune Health Mobile App is an AI-enabled application that offers contactless measurement of vital signs such as blood pressure, oxygen saturation, HRV, stress levels, and Hemoglobin through a simple face scan. It provides users with an easy, fast, and affordable way to track their wellness markers using state-of-the-art technology and biomarker analysis. The app empowers individuals to take control of their health by offering real-time measurements and accurate results without the need for wearables. Attune Health also caters to corporations, promoting healthy teams and overall wellbeing for better productivity and satisfaction.
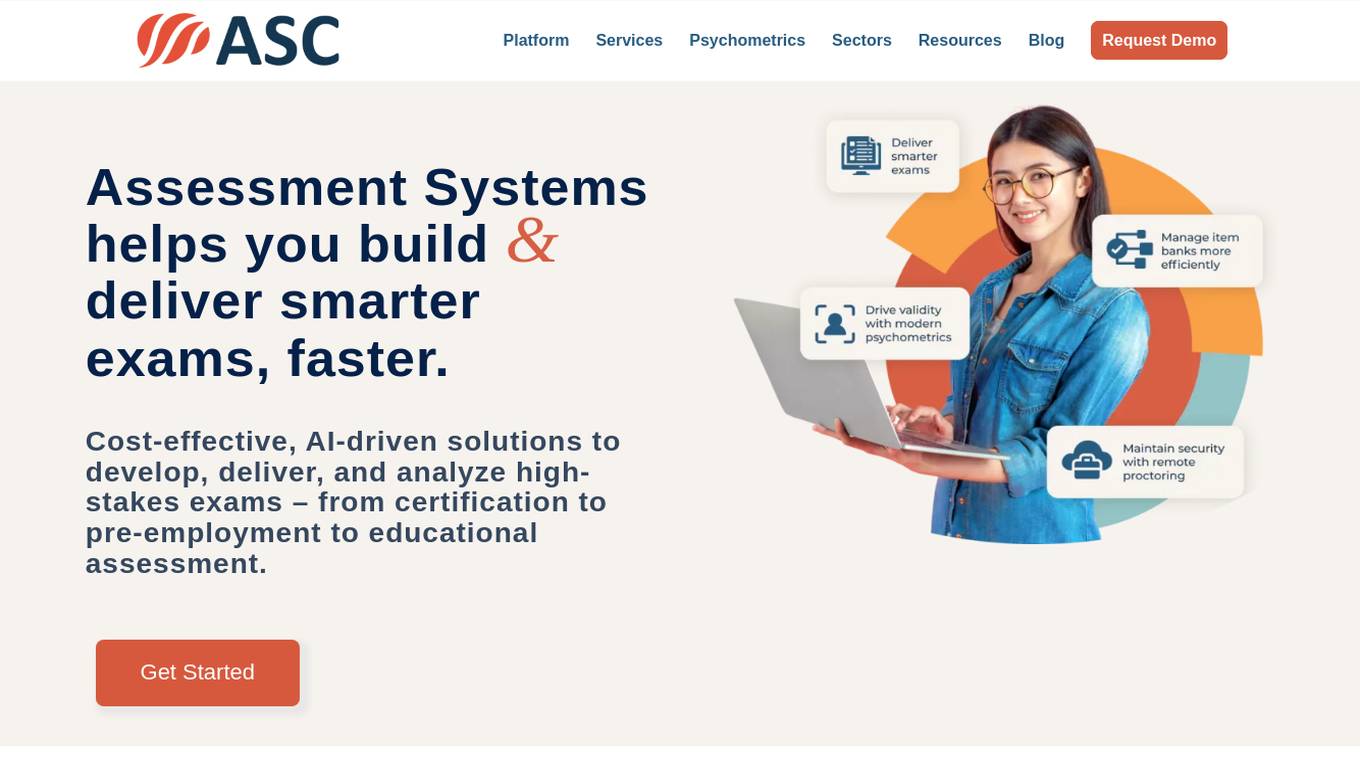
Assessment Systems
Assessment Systems is an online testing platform that provides cost-effective, AI-driven solutions to develop, deliver, and analyze high-stakes exams. With Assessment Systems, you can build and deliver smarter exams faster, thanks to modern psychometrics and AI like computerized adaptive testing, multistage testing, or automated item generation. You can also deliver exams flexibly: paper, online testing unproctored, online proctored, and test centers (yours or ours). Assessment Systems also offers item banking software to build better tests in less time, with collaborative item development brought to life with versioning, user roles, metadata, workflow management, multimedia, automated item generation, and much more.
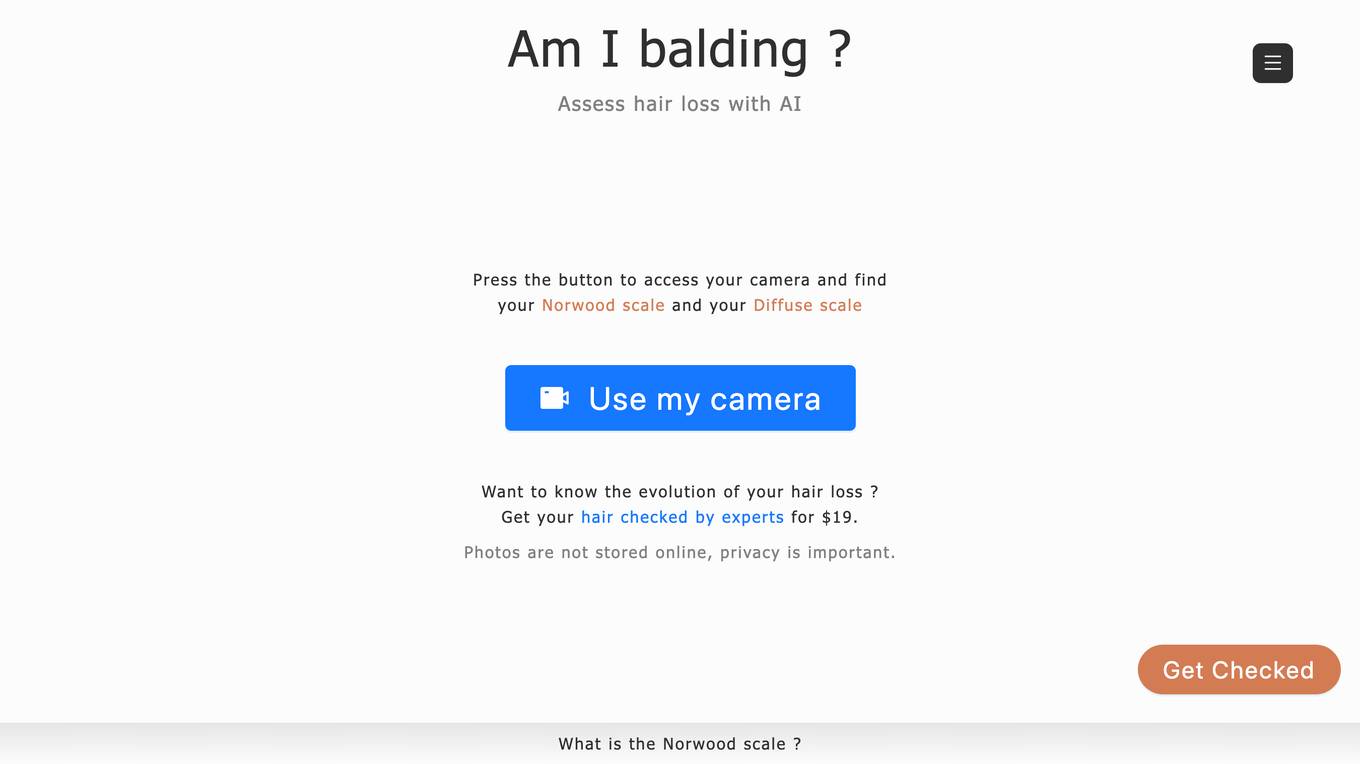
Hair Loss AI Tool
The website offers an AI tool to assess hair loss using the Norwood scale and Diffuse scale. Users can access the tool by pressing a button to use their camera. The tool provides a quick and convenient way to track the evolution of hair loss. Additionally, users can opt for a professional hair check by experts for a fee of $19, ensuring privacy as photos are not stored online. The tool is user-friendly and can be used in portrait mode for optimal experience.
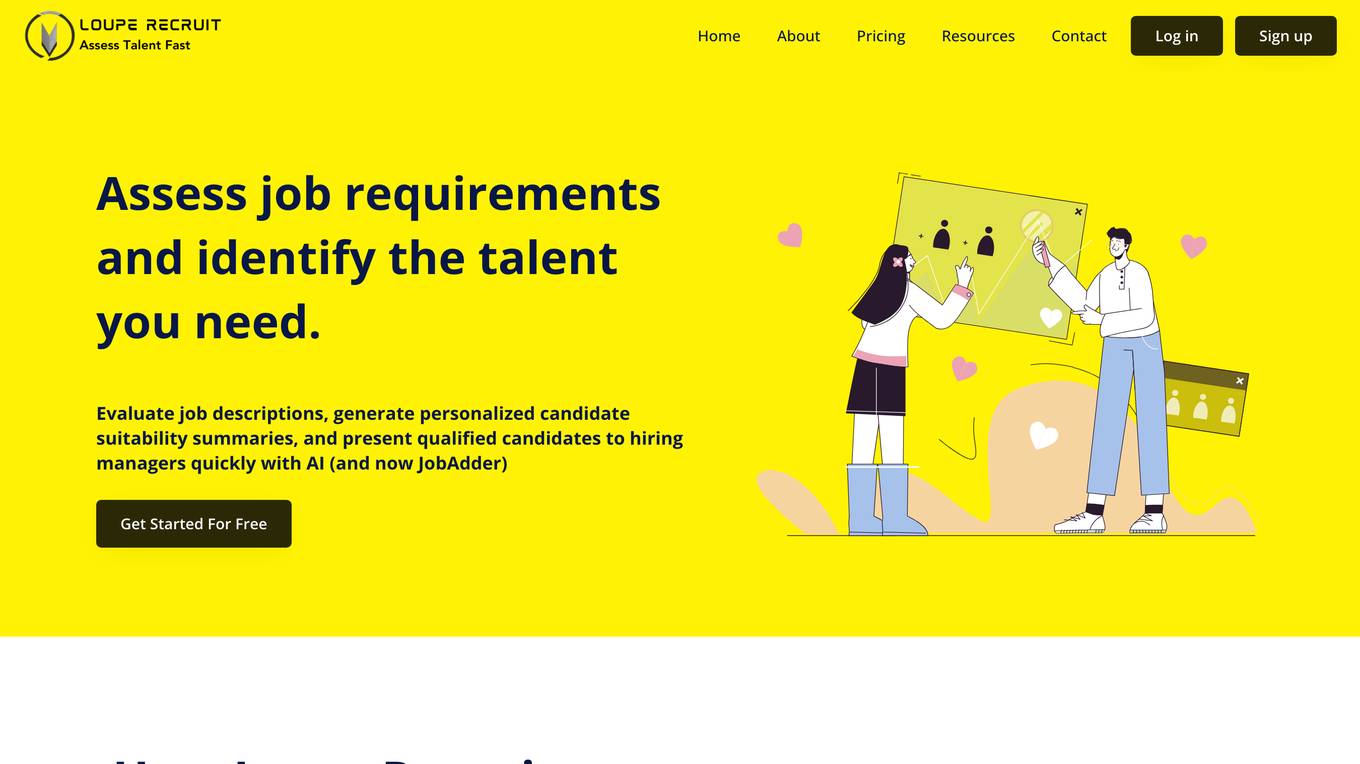
Loupe Recruit
Loupe Recruit is an AI-powered talent assessment platform that helps recruiters and hiring managers assess job descriptions and talent faster and more efficiently. It uses natural language processing and machine learning to analyze job descriptions and identify the key skills and experience required for a role. Loupe Recruit then matches candidates to these requirements, providing recruiters with a ranked list of the most qualified candidates. The platform also includes a variety of tools to help recruiters screen and interview candidates, including video interviewing, skills assessments, and reference checks.
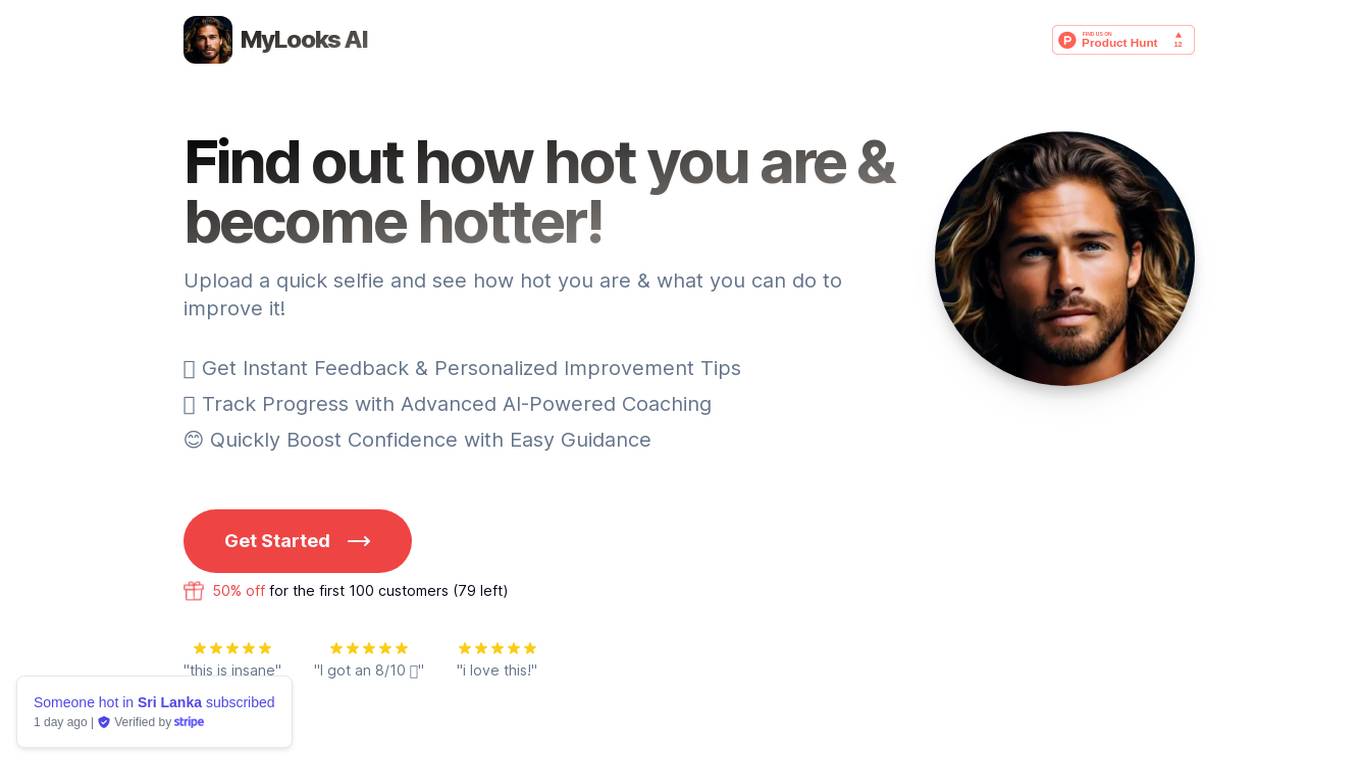
MyLooks AI
MyLooks AI is an AI-powered tool that allows users to assess their attractiveness based on a quick selfie upload. The tool provides instant feedback on the user's appearance and offers personalized improvement tips to help them enhance their looks. Users can track their progress with advanced AI-powered coaching and receive easy guidance to boost their confidence. MyLooks AI aims to help individuals feel more confident and improve their self-image through the use of artificial intelligence technology.

Modulos
Modulos is a Responsible AI Platform that integrates risk management, data science, legal compliance, and governance principles to ensure responsible innovation and adherence to industry standards. It offers a comprehensive solution for organizations to effectively manage AI risks and regulations, streamline AI governance, and achieve relevant certifications faster. With a focus on compliance by design, Modulos helps organizations implement robust AI governance frameworks, execute real use cases, and integrate essential governance and compliance checks throughout the AI life cycle.

Intelligencia AI
Intelligencia AI is a leading provider of AI-powered solutions for the pharmaceutical industry. Our suite of solutions helps de-risk and enhance clinical development and decision-making. We use a combination of data, AI, and machine learning to provide insights into the probability of success for drugs across multiple therapeutic areas. Our solutions are used by many of the top global pharmaceutical companies to improve their R&D productivity and make more informed decisions.

Graphio
Graphio is an AI-driven employee scoring and scenario builder tool that leverages continuous, real-time scoring with AI agents to assess potential, predict flight risks, and identify future leaders. It replaces subjective evaluations with AI-driven insights to ensure accurate, unbiased decisions in talent management. Graphio uses AI to remove bias in talent management, providing real-time, data-driven insights for fair decisions in promotions, layoffs, and succession planning. It offers compliance features and rules that users can control, ensuring accurate and secure assessments aligned with legal and regulatory requirements. The platform focuses on security, privacy, and personalized coaching to enhance employee engagement and reduce turnover.
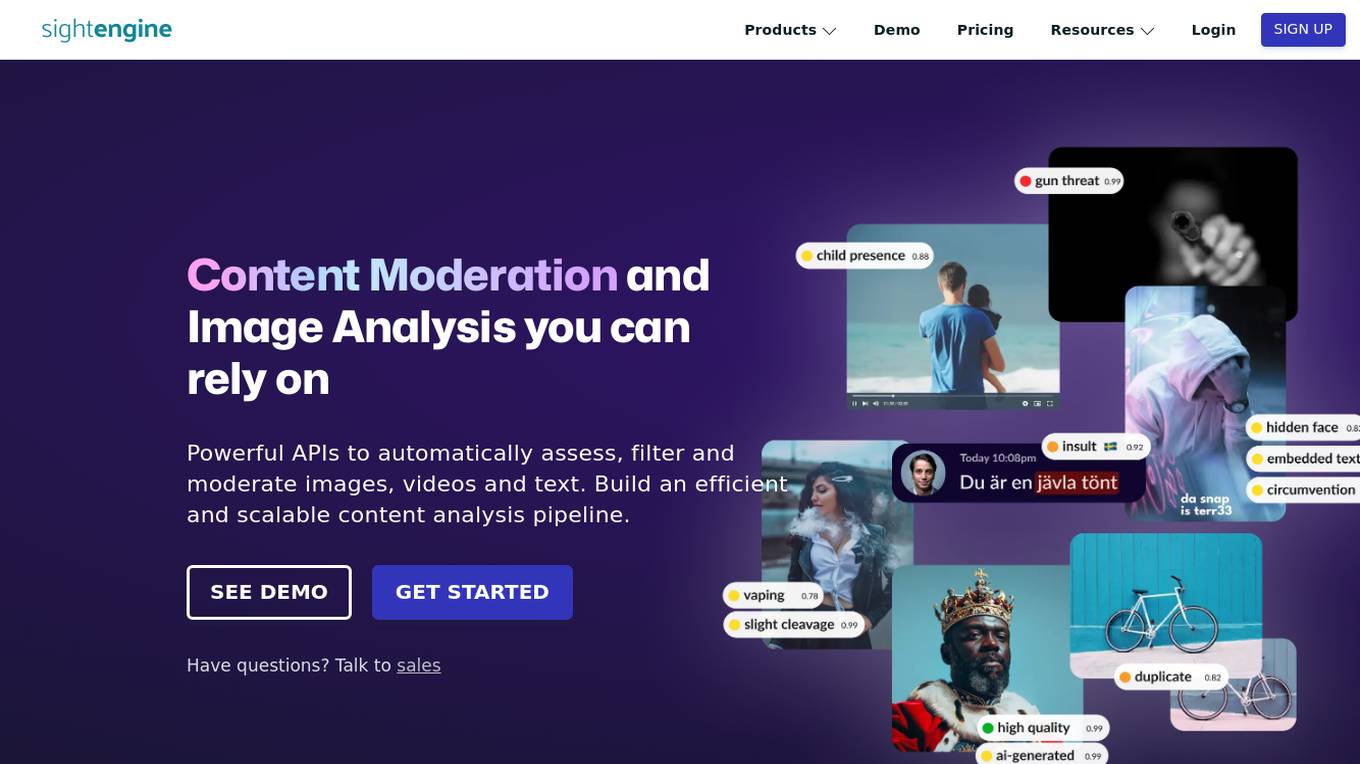
Sightengine
The website offers content moderation and image analysis products using powerful APIs to automatically assess, filter, and moderate images, videos, and text. It provides features such as image moderation, video moderation, text moderation, AI image detection, and video anonymization. The application helps in detecting unwanted content, AI-generated images, and personal information in videos. It also offers tools to identify near-duplicates, spam, and abusive links, and prevent phishing and circumvention attempts. The platform is fast, scalable, accurate, easy to integrate, and privacy compliant, making it suitable for various industries like marketplaces, dating apps, and news platforms.
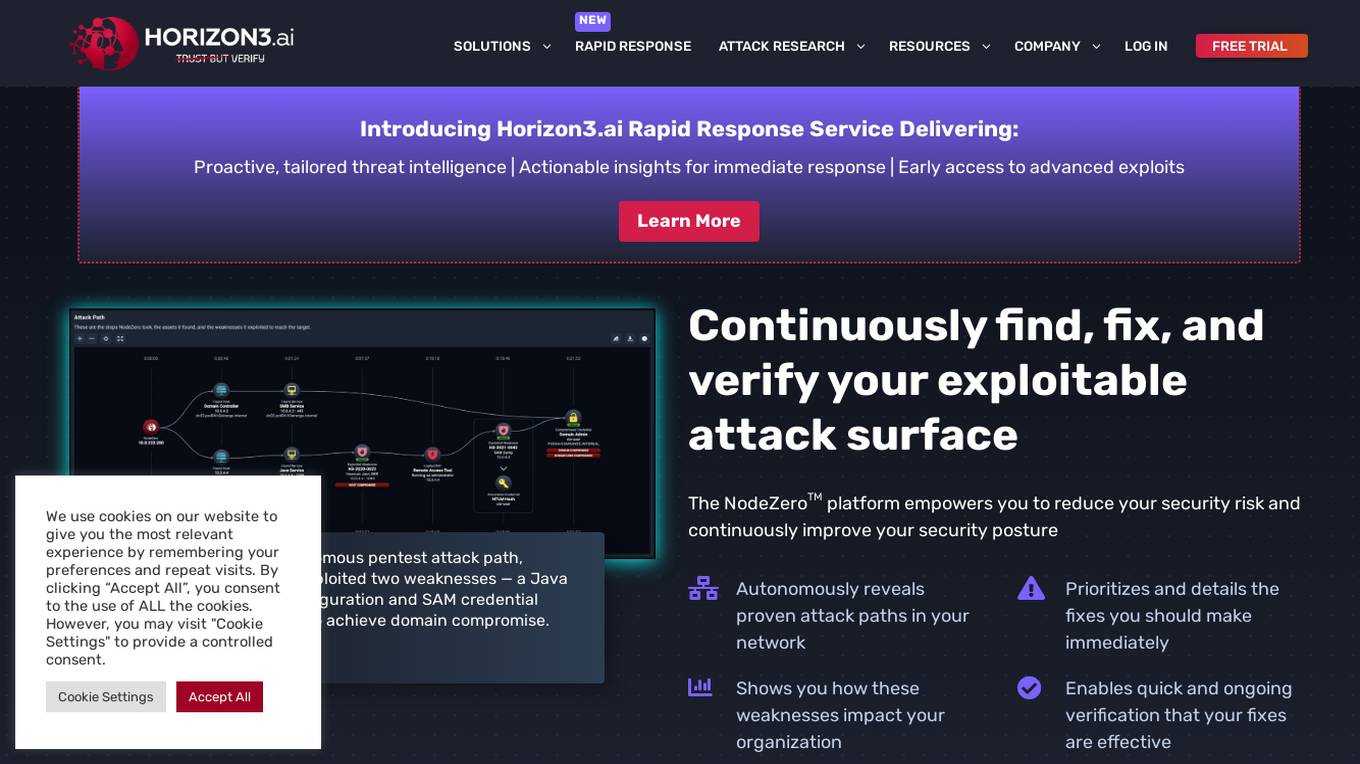
NodeZero™ Platform
Horizon3.ai Solutions offers the NodeZero™ Platform, an AI-powered autonomous penetration testing tool designed to enhance cybersecurity measures. The platform combines expert human analysis by Offensive Security Certified Professionals with automated testing capabilities to streamline compliance processes and proactively identify vulnerabilities. NodeZero empowers organizations to continuously assess their security posture, prioritize fixes, and verify the effectiveness of remediation efforts. With features like internal and external pentesting, rapid response capabilities, AD password audits, phishing impact testing, and attack research, NodeZero is a comprehensive solution for large organizations, ITOps, SecOps, security teams, pentesters, and MSSPs. The platform provides real-time reporting, integrates with existing security tools, reduces operational costs, and helps organizations make data-driven security decisions.
Archistar
Archistar is a leading property research platform in Australia that empowers users to make confident and compliant property decisions with the help of data and AI. It offers a range of features, including the ability to find and assess properties, generate 3D design concepts, and minimize risk and maximize return on investment. Archistar is trusted by over 100,000 individuals and 1,000 leading property firms.
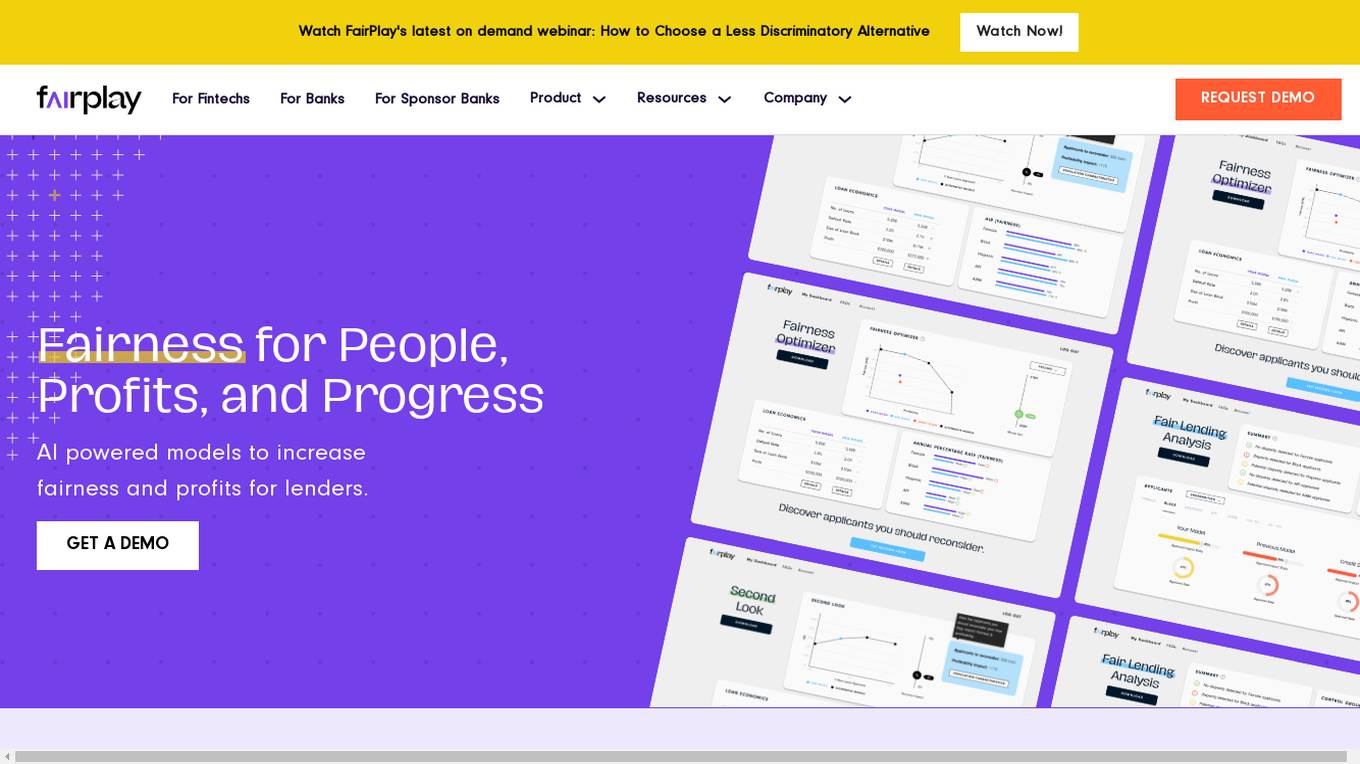
FairPlay
FairPlay is a Fairness-as-a-Service solution designed for financial institutions, offering AI-powered tools to assess automated decisioning models quickly. It helps in increasing fairness and profits by optimizing marketing, underwriting, and pricing strategies. The application provides features such as Fairness Optimizer, Second Look, Customer Composition, Redline Status, and Proxy Detection. FairPlay enables users to identify and overcome tradeoffs between performance and disparity, assess geographic fairness, de-bias proxies for protected classes, and tune models to reduce disparities without increasing risk. It offers advantages like increased compliance, speed, and readiness through automation, higher approval rates with no increase in risk, and rigorous Fair Lending analysis for sponsor banks and regulators. However, some disadvantages include the need for data integration, potential bias in AI algorithms, and the requirement for technical expertise to interpret results.

RankU
RankU is a mobile application designed to help users grow on YouTube by leveraging the power of AI. The app provides insights, probabilistic results, and tailored recommendations to assist users in validating channel or video ideas, understanding competition, and creating a successful plan. With RankU, users can take their YouTube journey to the next level with personalized recommendations and data-driven strategies.

Pascal
Pascal is an AI-powered risk-based KYC & AML screening and monitoring platform that offers users a faster and more accurate way to assess findings compared to other compliance tools. It leverages AI, machine learning, and Natural Language Processing to analyze open-source and client-specific data, providing insights to identify and assess risks. Pascal simplifies onboarding processes, offers continuous monitoring, reduces false positives, and enables better decision-making through its intuitive interface. It promotes collaboration among different stakeholders and ensures transparency in compliance procedures.
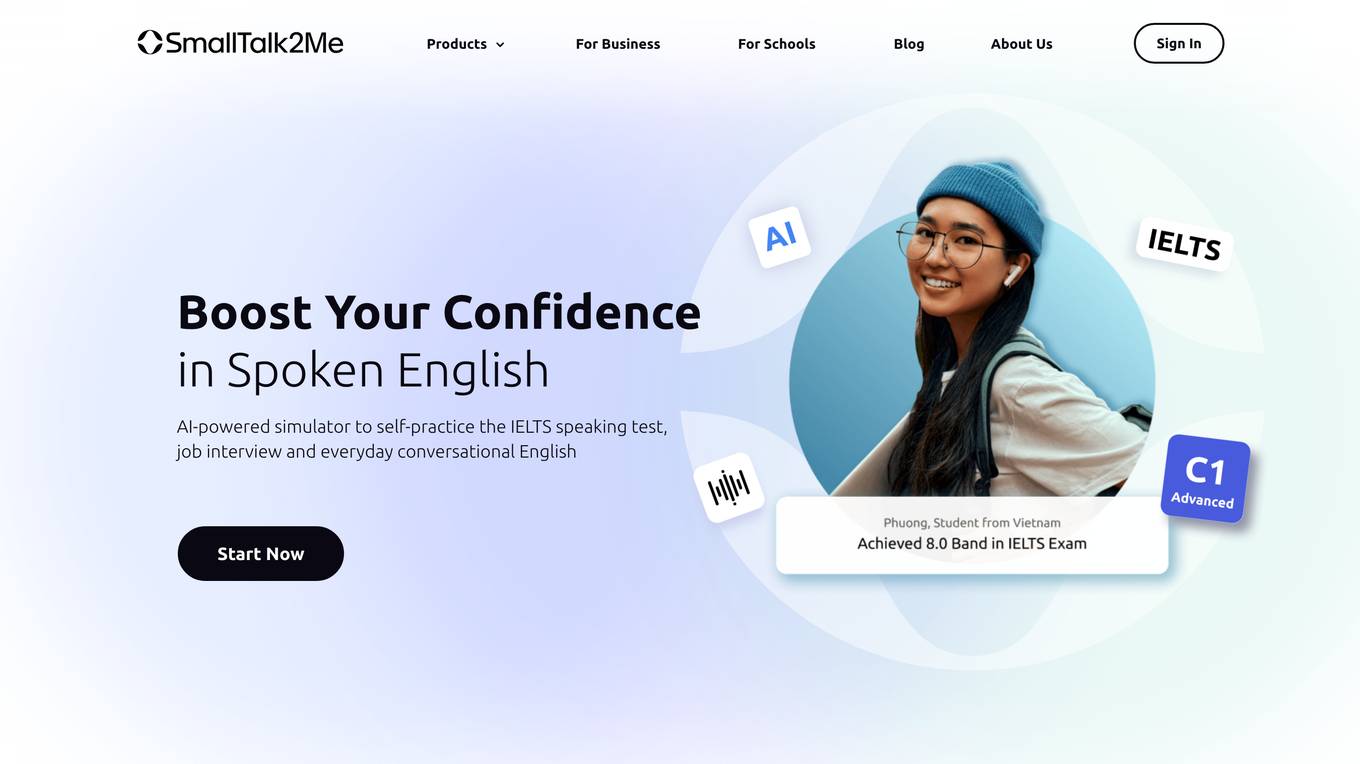
SmallTalk2Me
SmallTalk2Me is an AI-powered simulator designed to help users improve their spoken English. It offers a range of features, including mock job interviews, IELTS speaking test simulations, and daily stories and courses. The platform uses AI to provide users with instant feedback on their performance, helping them to identify areas for improvement and track their progress over time.
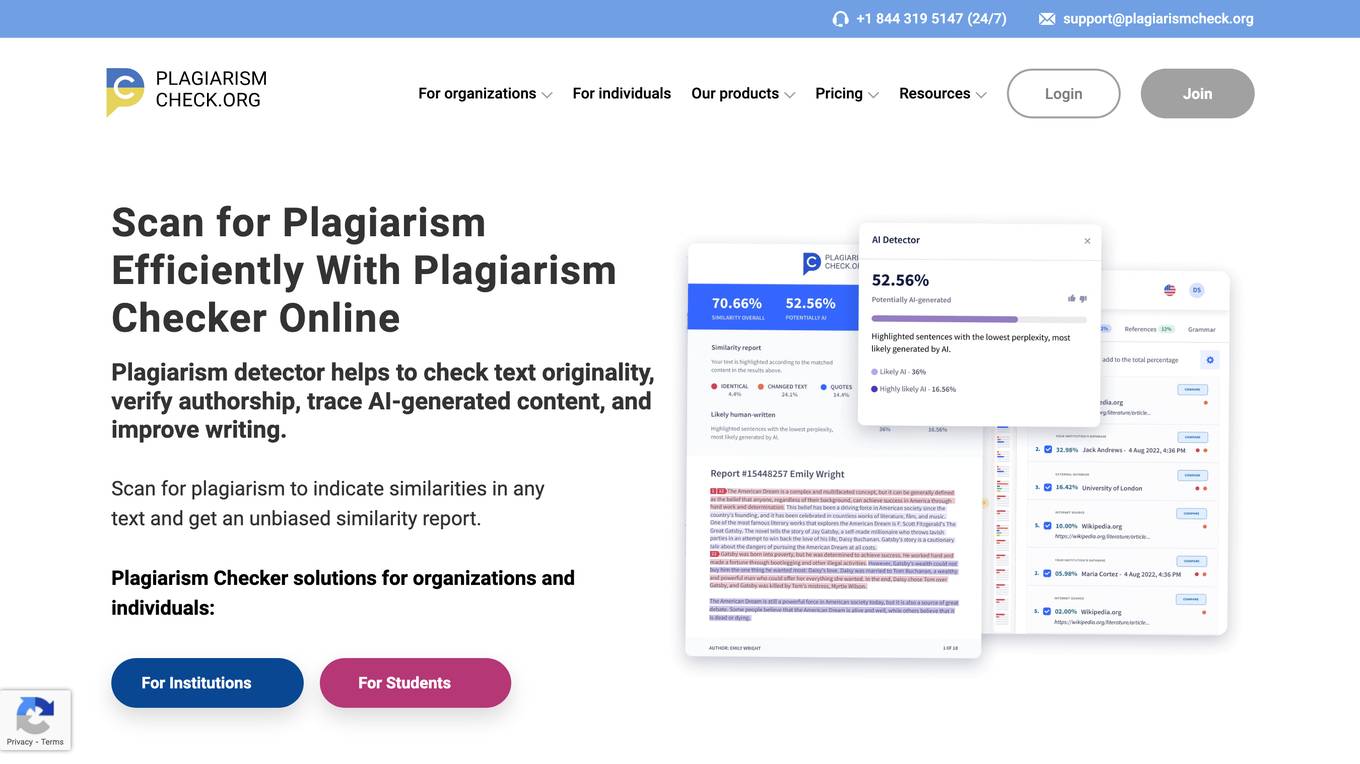
Plagiarism Checker
Plagiarism Checker is an online plagiarism detector that helps check text originality, verify authorship, trace AI-generated content, and improve writing. It scans for plagiarism to indicate similarities in any text and provides an unbiased similarity report. Plagiarism Checker offers solutions for organizations and individuals, including K-12 schools, higher education institutions, students, writers, and content creators. With advanced algorithms, unlimited text length, interactive results, downloadable reports, and strict confidentiality, Plagiarism Checker is a reliable tool for ensuring academic integrity and originality in writing.
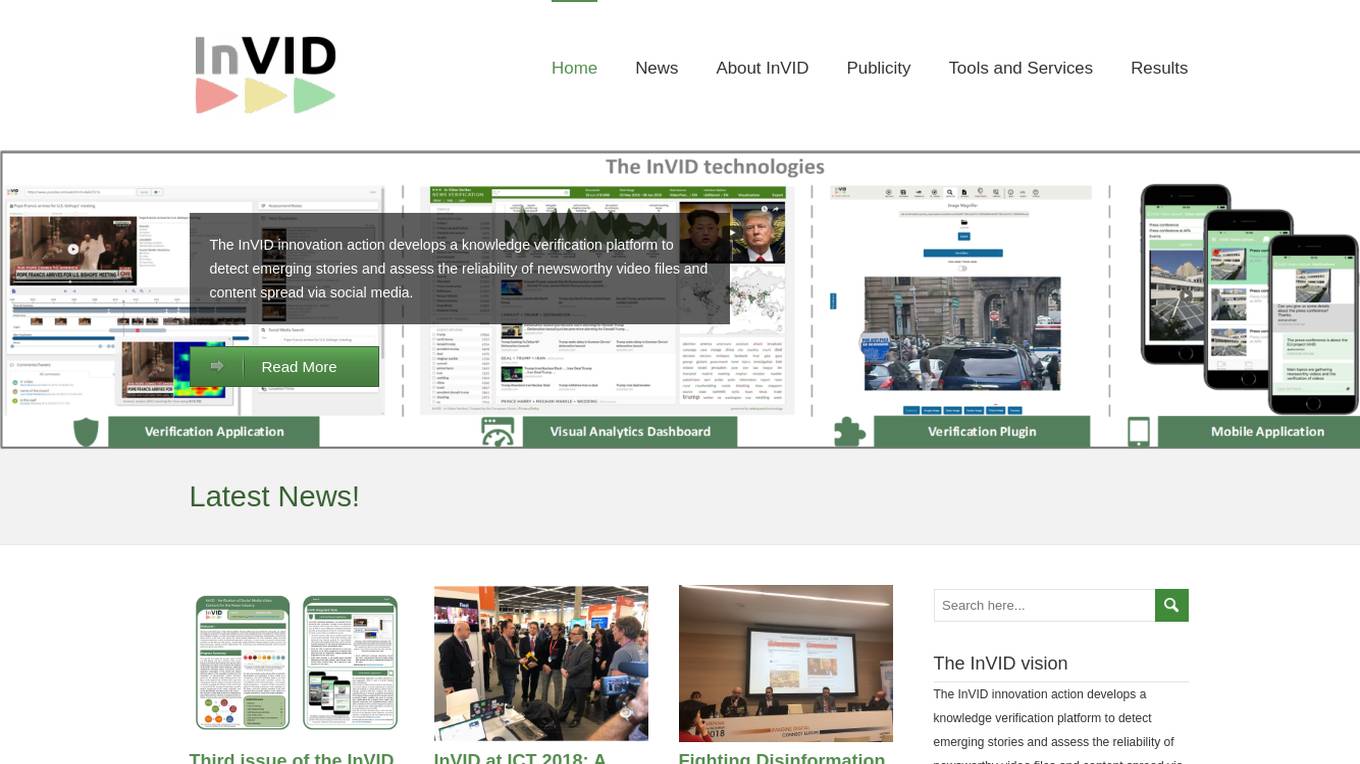
InVID
InVID is a knowledge verification platform that helps detect emerging stories and assess the reliability of newsworthy video files and content spread via social media. It provides tools and services to help users verify the authenticity of videos and identify potential misinformation.

CodeSignal
CodeSignal is an AI-powered platform that helps users discover and develop in-demand skills. It offers skills assessments and AI-powered learning tools to help individuals and teams level up their skills. The platform provides solutions for talent acquisition, technical interviewing, skill development, and more. With features like pre-screening, interview assessments, and personalized learning, CodeSignal aims to help users advance their careers and build high-performing teams.

Archistar
Archistar is a leading property research platform that utilizes data and AI to help investors, developers, architects, and government officials make confident and compliant decisions. The platform offers features such as finding the best use of a site, researching real estate rules and risks, generating 3D design concepts with AI, and fast-tracking building permit assessments. With over 100,000 users, Archistar provides access to advanced algorithms, filters, and market insights to discover real estate opportunities efficiently.
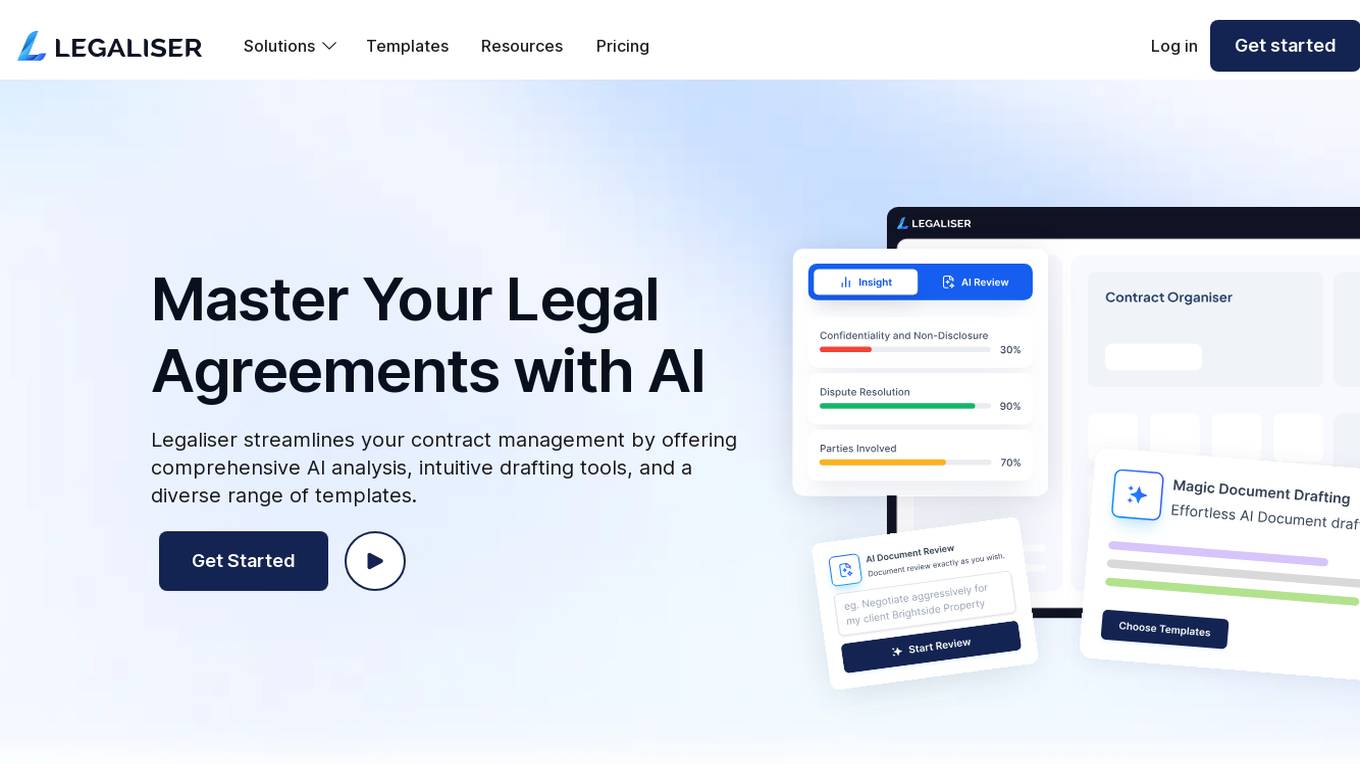
Legaliser
Legaliser is an AI legal assistant that revolutionizes contract management by providing comprehensive AI analysis, intuitive drafting tools, and a diverse range of customizable templates. It quickly summarizes contracts, evaluates clauses for compliance, and offers targeted suggestions to enhance contract clarity and compliance. Legaliser streamlines document management with AI-driven summaries, clause ratings, and smart organization, making it an indispensable tool for legal professionals across diverse industries.
20 - Open Source AI Tools
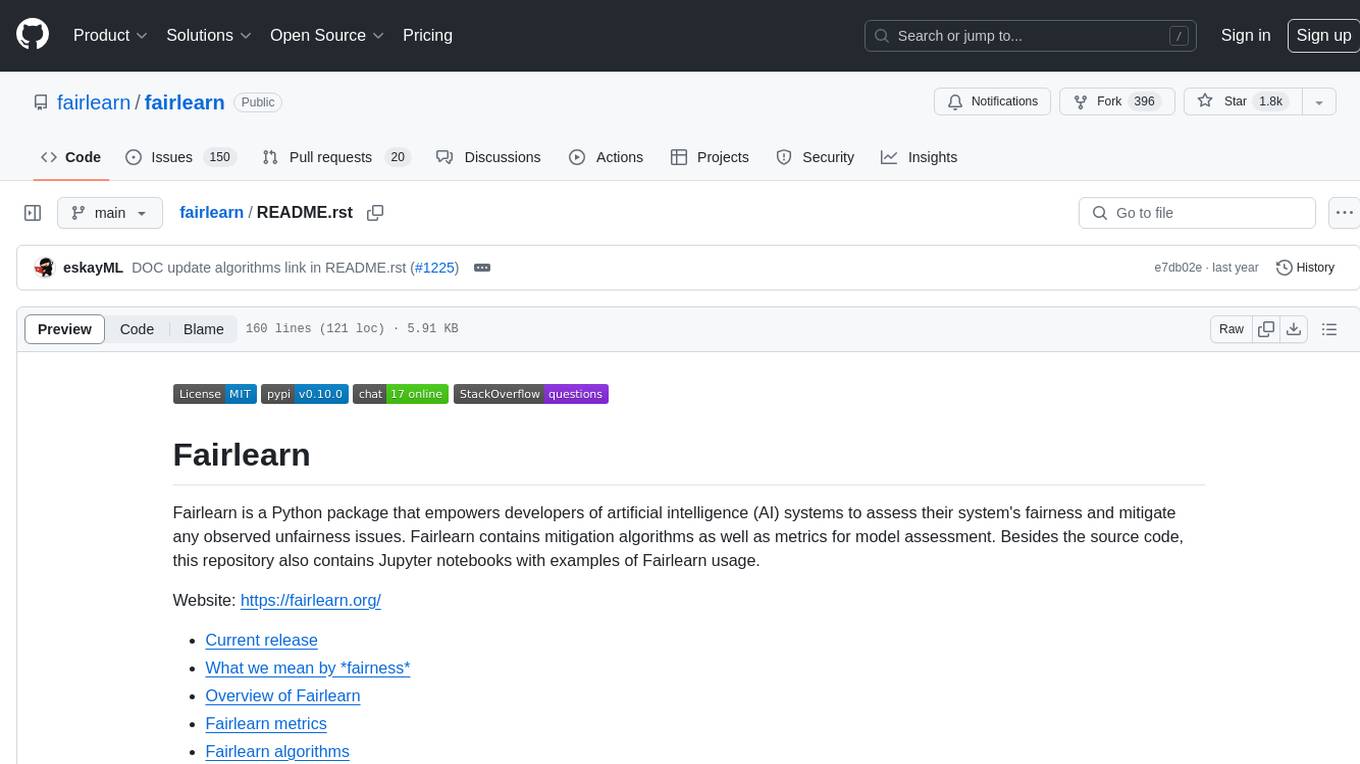
fairlearn
Fairlearn is a Python package designed to help developers assess and mitigate fairness issues in artificial intelligence (AI) systems. It provides mitigation algorithms and metrics for model assessment. Fairlearn focuses on two types of harms: allocation harms and quality-of-service harms. The package follows the group fairness approach, aiming to identify groups at risk of experiencing harms and ensuring comparable behavior across these groups. Fairlearn consists of metrics for assessing model impacts and algorithms for mitigating unfairness in various AI tasks under different fairness definitions.

uncheatable_eval
Uncheatable Eval is a tool designed to assess the language modeling capabilities of LLMs on real-time, newly generated data from the internet. It aims to provide a reliable evaluation method that is immune to data leaks and cannot be gamed. The tool supports the evaluation of Hugging Face AutoModelForCausalLM models and RWKV models by calculating the sum of negative log probabilities on new texts from various sources such as recent papers on arXiv, new projects on GitHub, news articles, and more. Uncheatable Eval ensures that the evaluation data is not included in the training sets of publicly released models, thus offering a fair assessment of the models' performance.

ps-fuzz
The Prompt Fuzzer is an open-source tool that helps you assess the security of your GenAI application's system prompt against various dynamic LLM-based attacks. It provides a security evaluation based on the outcome of these attack simulations, enabling you to strengthen your system prompt as needed. The Prompt Fuzzer dynamically tailors its tests to your application's unique configuration and domain. The Fuzzer also includes a Playground chat interface, giving you the chance to iteratively improve your system prompt, hardening it against a wide spectrum of generative AI attacks.
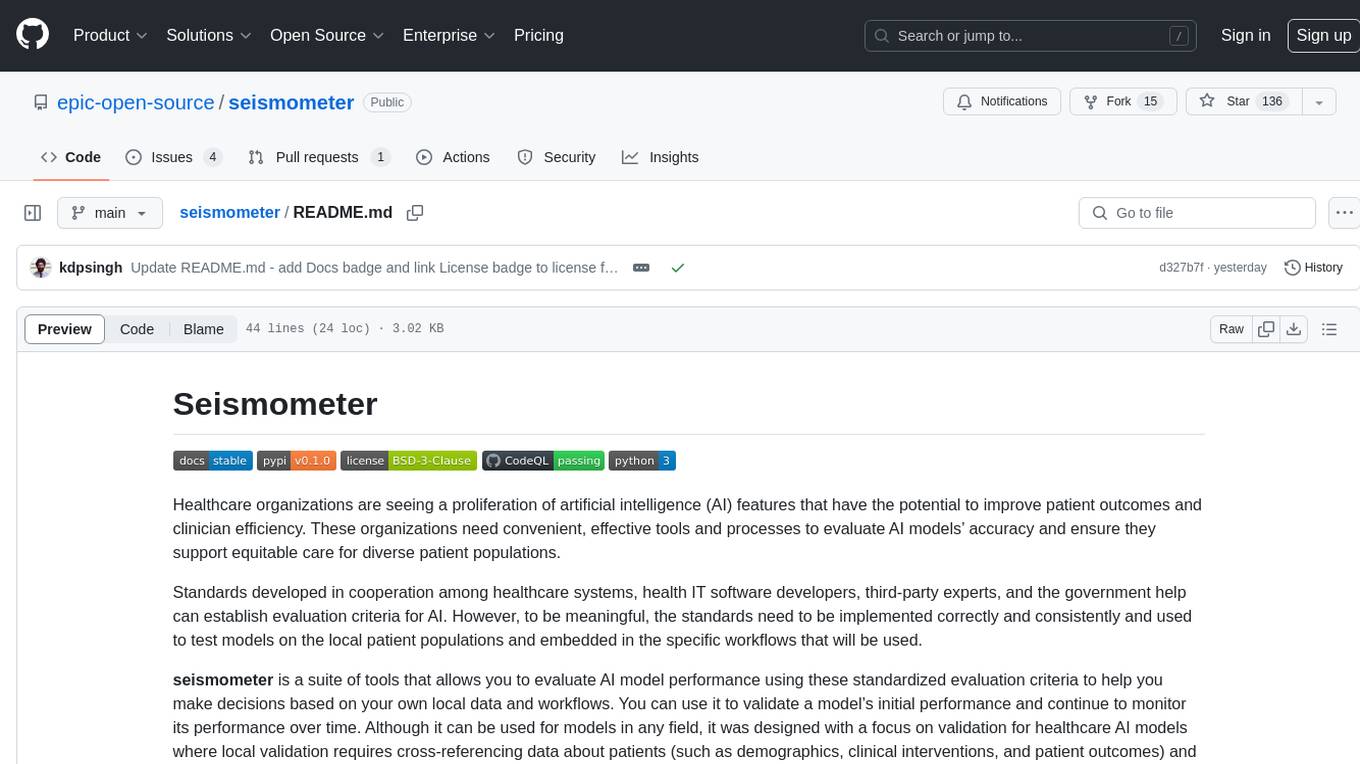
seismometer
Seismometer is a suite of tools designed to evaluate AI model performance in healthcare settings. It helps healthcare organizations assess the accuracy of AI models and ensure equitable care for diverse patient populations. The tool allows users to validate model performance using standardized evaluation criteria based on local data and workflows. It includes templates for analyzing statistical performance, fairness across different cohorts, and the impact of interventions on outcomes. Seismometer is continuously evolving to incorporate new validation and analysis techniques.
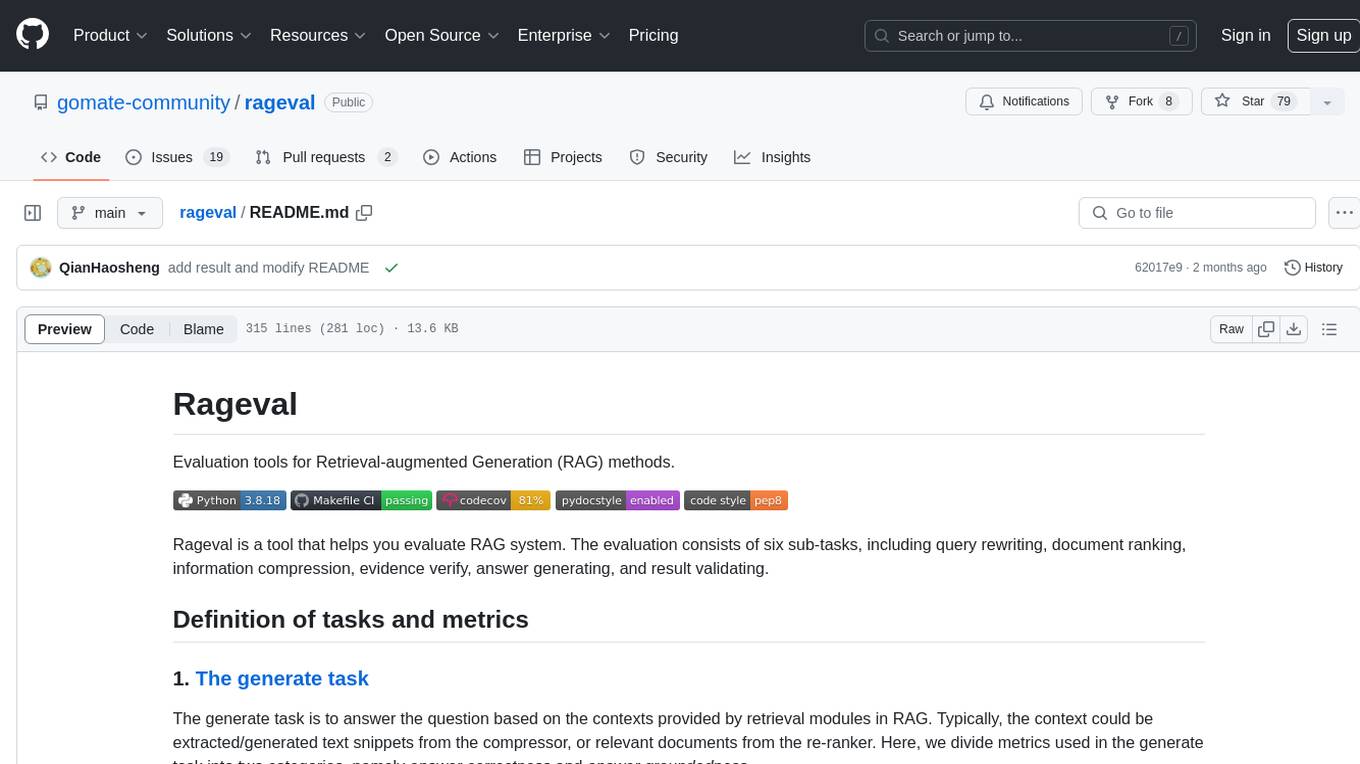
rageval
Rageval is an evaluation tool for Retrieval-augmented Generation (RAG) methods. It helps evaluate RAG systems by performing tasks such as query rewriting, document ranking, information compression, evidence verification, answer generation, and result validation. The tool provides metrics for answer correctness and answer groundedness, along with benchmark results for ASQA and ALCE datasets. Users can install and use Rageval to assess the performance of RAG models in question-answering tasks.
dioptra
Dioptra is a software test platform for assessing the trustworthy characteristics of artificial intelligence (AI). It supports the NIST AI Risk Management Framework by providing functionality to assess, analyze, and track identified AI risks. Dioptra provides a REST API and can be controlled via a web interface or Python client for designing, managing, executing, and tracking experiments. It aims to be reproducible, traceable, extensible, interoperable, modular, secure, interactive, shareable, and reusable.
fortuna
Fortuna is a library for uncertainty quantification that enables users to estimate predictive uncertainty, assess model reliability, trigger human intervention, and deploy models safely. It provides calibration and conformal methods for pre-trained models in any framework, supports Bayesian inference methods for deep learning models written in Flax, and is designed to be intuitive and highly configurable. Users can run benchmarks and bring uncertainty to production systems with ease.

amazon-transcribe-live-call-analytics
The Amazon Transcribe Live Call Analytics (LCA) with Agent Assist Sample Solution is designed to help contact centers assess and optimize caller experiences in real time. It leverages Amazon machine learning services like Amazon Transcribe, Amazon Comprehend, and Amazon SageMaker to transcribe and extract insights from contact center audio. The solution provides real-time supervisor and agent assist features, integrates with existing contact centers, and offers a scalable, cost-effective approach to improve customer interactions. The end-to-end architecture includes features like live call transcription, call summarization, AI-powered agent assistance, and real-time analytics. The solution is event-driven, ensuring low latency and seamless processing flow from ingested speech to live webpage updates.
MisguidedAttention
MisguidedAttention is a collection of prompts designed to challenge the reasoning abilities of large language models by presenting them with modified versions of well-known thought experiments, riddles, and paradoxes. The goal is to assess the logical deduction capabilities of these models and observe any shortcomings or fallacies in their responses. The repository includes a variety of prompts that test different aspects of reasoning, such as decision-making, probability assessment, and problem-solving. By analyzing how language models handle these challenges, researchers can gain insights into their reasoning processes and potential biases.

stark
STaRK is a large-scale semi-structure retrieval benchmark on Textual and Relational Knowledge Bases. It provides natural-sounding and practical queries crafted to incorporate rich relational information and complex textual properties, closely mirroring real-life scenarios. The benchmark aims to assess how effectively large language models can handle the interplay between textual and relational requirements in queries, using three diverse knowledge bases constructed from public sources.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.
Mercury
Mercury is a code efficiency benchmark designed for code synthesis tasks. It includes 1,889 programming tasks of varying difficulty levels and provides test case generators for comprehensive evaluation. The benchmark aims to assess the efficiency of large language models in generating code solutions.

eval-dev-quality
DevQualityEval is an evaluation benchmark and framework designed to compare and improve the quality of code generation of Language Model Models (LLMs). It provides developers with a standardized benchmark to enhance real-world usage in software development and offers users metrics and comparisons to assess the usefulness of LLMs for their tasks. The tool evaluates LLMs' performance in solving software development tasks and measures the quality of their results through a point-based system. Users can run specific tasks, such as test generation, across different programming languages to evaluate LLMs' language understanding and code generation capabilities.
llm_benchmarks
llm_benchmarks is a collection of benchmarks and datasets for evaluating Large Language Models (LLMs). It includes various tasks and datasets to assess LLMs' knowledge, reasoning, language understanding, and conversational abilities. The repository aims to provide comprehensive evaluation resources for LLMs across different domains and applications, such as education, healthcare, content moderation, coding, and conversational AI. Researchers and developers can leverage these benchmarks to test and improve the performance of LLMs in various real-world scenarios.

MathVerse
MathVerse is an all-around visual math benchmark designed to evaluate the capabilities of Multi-modal Large Language Models (MLLMs) in visual math problem-solving. It collects high-quality math problems with diagrams to assess how well MLLMs can understand visual diagrams for mathematical reasoning. The benchmark includes 2,612 problems transformed into six versions each, contributing to 15K test samples. It also introduces a Chain-of-Thought (CoT) Evaluation strategy for fine-grained assessment of output answers.

hallucination-index
LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.

FlagPerf
FlagPerf is an integrated AI hardware evaluation engine jointly built by the Institute of Intelligence and AI hardware manufacturers. It aims to establish an industry-oriented metric system to evaluate the actual capabilities of AI hardware under software stack combinations (model + framework + compiler). FlagPerf features a multidimensional evaluation metric system that goes beyond just measuring 'whether the chip can support specific model training.' It covers various scenarios and tasks, including computer vision, natural language processing, speech, multimodal, with support for multiple training frameworks and inference engines to connect AI hardware with software ecosystems. It also supports various testing environments to comprehensively assess the performance of domestic AI chips in different scenarios.

MathEval
MathEval is a benchmark designed for evaluating the mathematical capabilities of large models. It includes over 20 evaluation datasets covering various mathematical domains with more than 30,000 math problems. The goal is to assess the performance of large models across different difficulty levels and mathematical subfields. MathEval serves as a reliable reference for comparing mathematical abilities among large models and offers guidance on enhancing their mathematical capabilities in the future.

ai-rag-chat-evaluator
This repository contains scripts and tools for evaluating a chat app that uses the RAG architecture. It provides parameters to assess the quality and style of answers generated by the chat app, including system prompt, search parameters, and GPT model parameters. The tools facilitate running evaluations, with examples of evaluations on a sample chat app. The repo also offers guidance on cost estimation, setting up the project, deploying a GPT-4 model, generating ground truth data, running evaluations, and measuring the app's ability to say 'I don't know'. Users can customize evaluations, view results, and compare runs using provided tools.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.
20 - OpenAI Gpts
HomeScore
Assess a potential home's quality using your own photos and property inspection reports
Ready for Transformation
Assess your company's real appetite for new technologies or new ways of working methods

TRL Explorer
Assess the TRL of your projects, get ideas for specific TRLs, learn how to advance from one TRL to the next

🎯 CulturePulse Pro Advisor 🌐
Empowers leaders to gauge and enhance company culture. Use advanced analytics to assess, report, and develop a thriving workplace culture. 🚀💼📊

香港地盤安全佬 HK Construction Site Safety Advisor
Upload a site photo to assess the potential hazard and seek advises from experience AI Safety Officer
Credit Analyst
Analyzes financial data to assess creditworthiness, aiding in lending decisions and solutions.

DatingCoach
Starts with a quiz to assess your personality across 10 dating-related areas, crafts a custom development road-map, and coaches you towards finding a fulfilling relationship.
Bloom's Reading Comprehension
Create comprehension questions based on a shared text. These questions will be designed to assess understanding at different levels of Bloom's taxonomy, from basic recall to more complex analytical and evaluative thinking skills.
Conversation Analyzer
I analyze WhatsApp/Telegram and email conversations to assess the tone of their emotions and read between the lines. Upload your screenshot and I'll tell you what they are really saying! 😀
WVA
Web Vulnerability Academy (WVA) is an interactive tutor designed to introduce users to web vulnerabilities while also providing them with opportunities to assess and enhance their knowledge through testing.
JamesGPT
Predict the future, opine on politics and controversial topics, and have GPT assess what is "true"
![The EthiSizer GPT (Simulated) [v3.27] Screenshot](/screenshots_gpts/g-hZIzxnbWG.jpg)
The EthiSizer GPT (Simulated) [v3.27]
I am The EthiSizer GPT, a sim of a Global Ethical Governor. I simulate Ethical Scenarios, & calculate Personal Ethics Scores.
Hair Loss Assessment
Receive a free hair loss assessment. Click below or type 'start' to get your results.


Educational Equity
A tool that uses research to apply DEI principles in education. Ensure your policies, curriculum, decisions, and communications has been assessed for bias, inclusivity, and more.