AI tools for voice
Related Jobs:
Related Tools:

Voice-Swap
Voice-Swap is an AI voice transformation tool designed for musicians and creators. It allows users to create custom AI voice models using the Model Studio, share them via a free VST Plugin, and embed AI voices in apps using the API. With high-quality AI voices, Voice-Swap has gained popularity among professional creators and companies. The platform offers a range of features and benefits for transforming voices with AI, making it a valuable tool for music production and content creation.
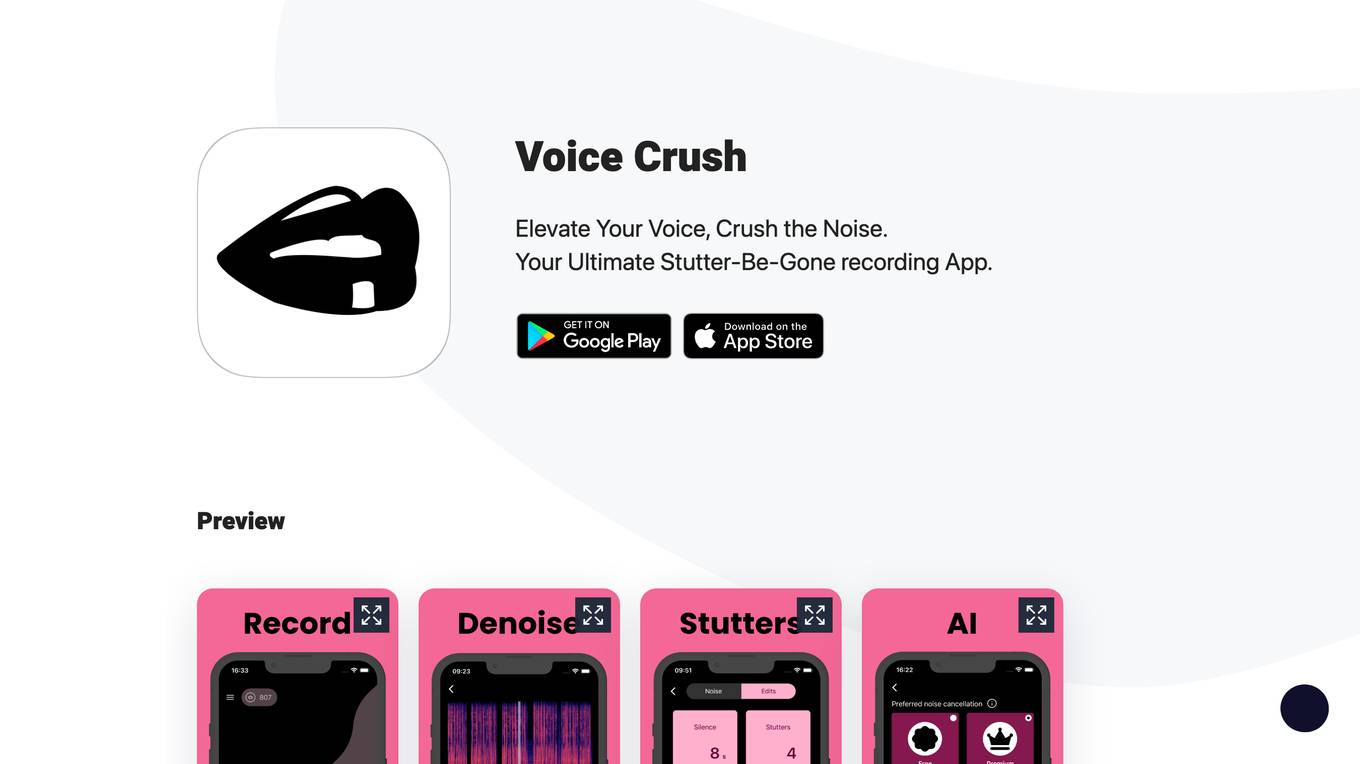

Controlla Voice
Controlla Voice is an AI application that allows users to transform vocals into new voices or instruments, swap any song to their own voice in any language, and create unique blended voices. Users can train their own AI singing voice, generate AI cover songs, and create realistic choirs with customizable harmonies. The application provides a vocal toolkit for never-before-heard sounds and offers flexible pricing options to access high-quality AI singing voices. With Controlla Voice, users can enhance their voice, express themselves in their most natural way, and monetize their music with automatic royalties.
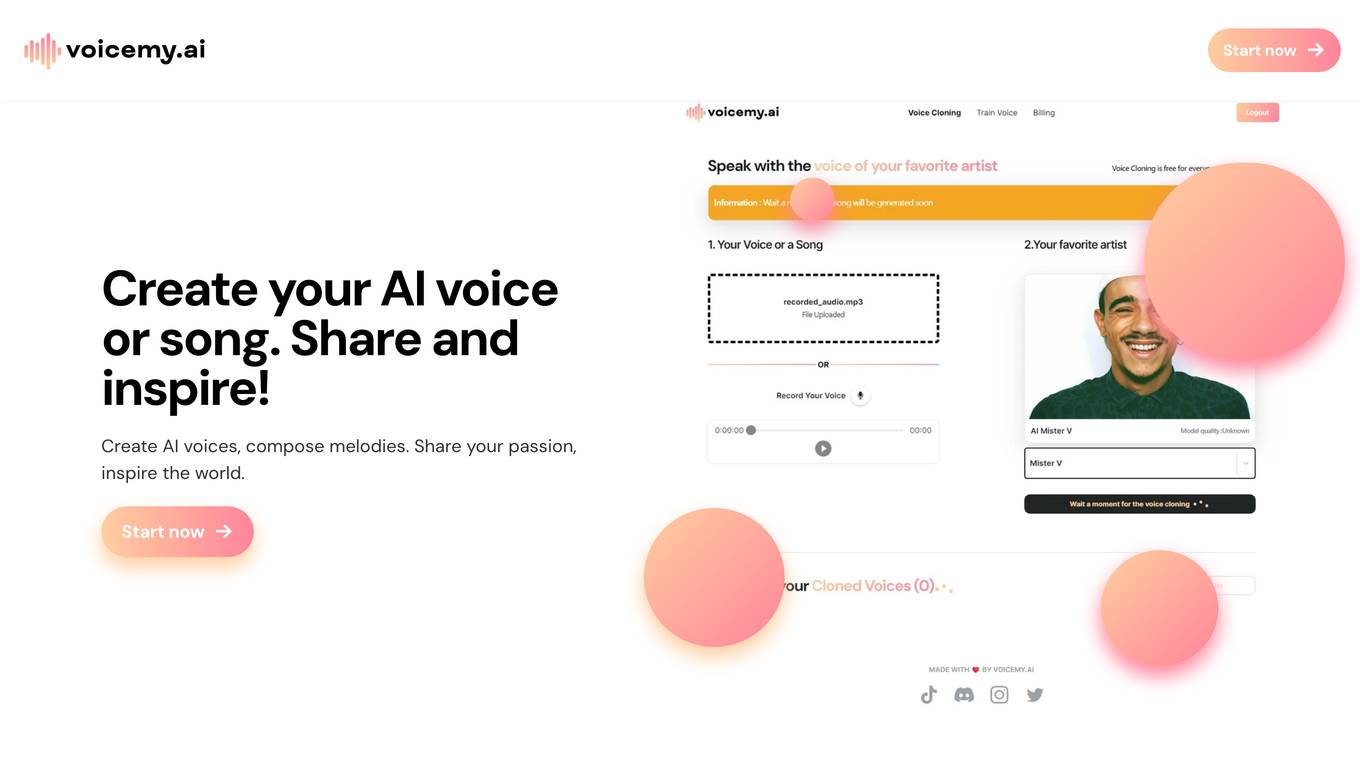
Voicemy.ai
Voicemy.ai is an AI application that allows users to create AI voices and songs. Users can clone voices of famous personalities, compose melodies, and convert text into spoken words using chosen voice models. The platform aims to inspire creativity and enable users to share their passion with the world.
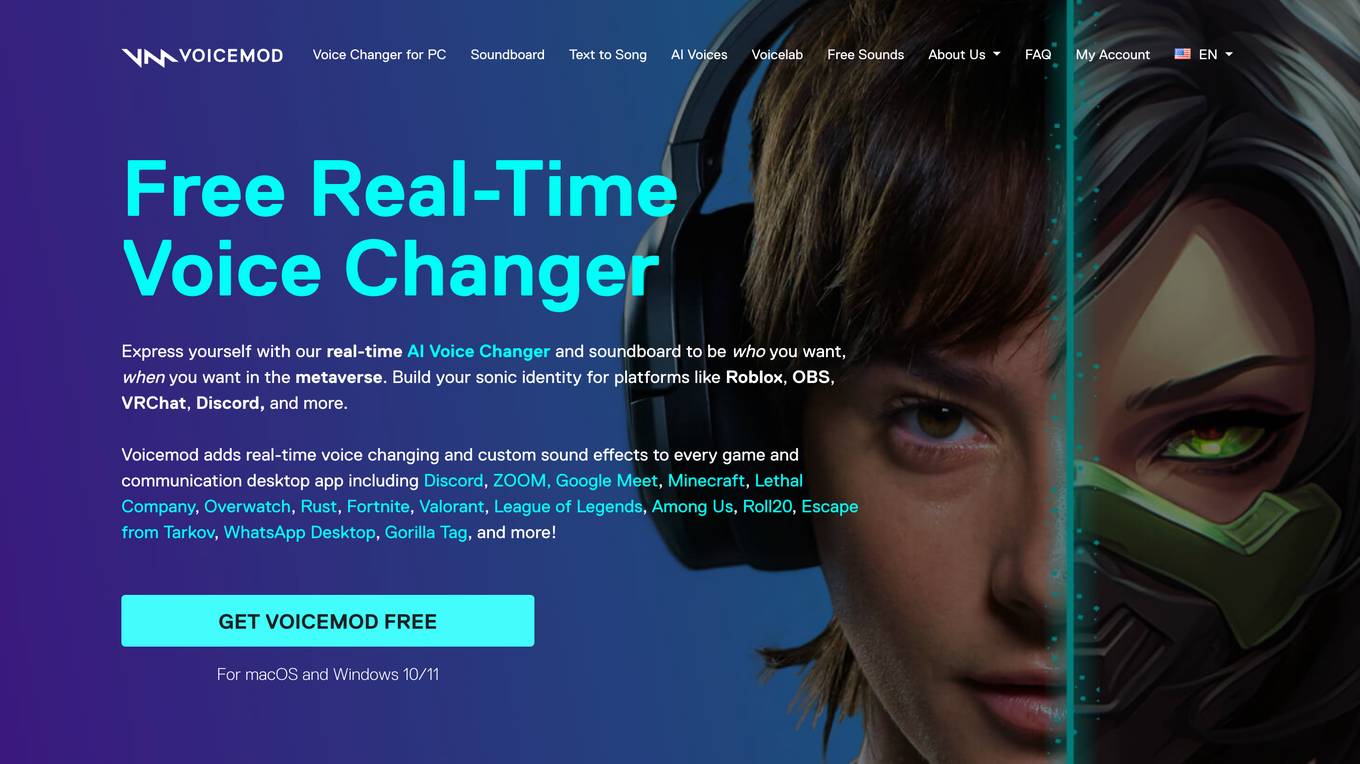
Voicemod
Voicemod is a free real-time voice changer and soundboard software that allows users to modify their voices in real-time. It is compatible with both Windows and macOS and can be used with a variety of applications, including games, chat apps, and video streaming platforms. Voicemod offers a wide range of voice effects, including robot, demon, chipmunk, woman, man, and many others. It also includes a soundboard feature that allows users to play sound effects at the touch of a button. Voicemod is a popular choice for gamers, content creators, and anyone who wants to add some fun and creativity to their voice communications.

Voice.ai
Voice.ai is a free real-time voice changer and the largest ecosystem of free AI voice tools. With Voice.ai, you can change your voice in real-time, clone voices, create soundboards, and more. Voice.ai is perfect for streamers, content creators, gamers, and anyone who wants to have fun with their voice.

Resemble AI
Resemble AI is a cutting-edge generative voice AI platform that empowers enterprises with advanced voice cloning, deepfake detection, and AI watermarking capabilities. Our suite of tools enables the creation of realistic synthetic voices, detection of AI-generated content, and protection of intellectual property. With Resemble AI, businesses can enhance customer service, elevate gaming experiences, revolutionize entertainment, and safeguard their digital assets.
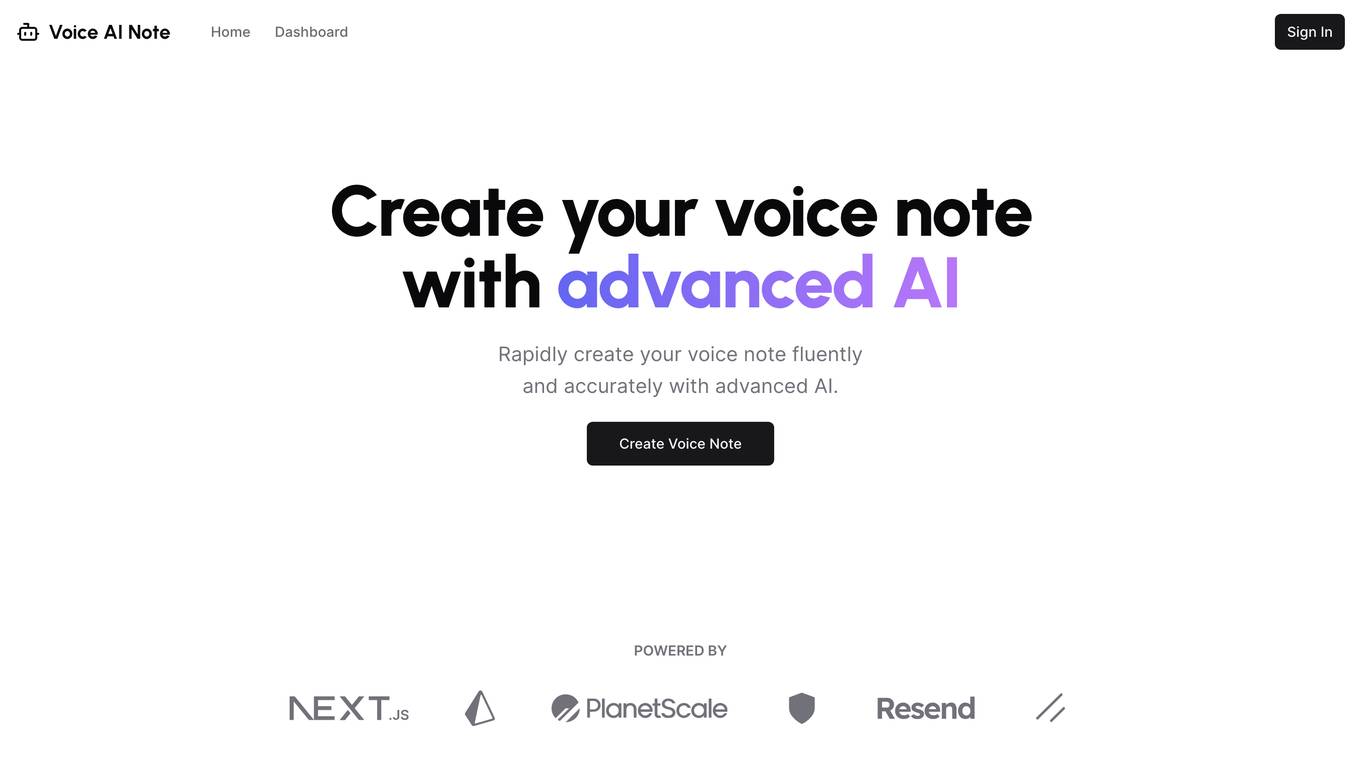
Voice AI Note
Voice AI Note is a web-based application that allows users to quickly and easily create voice notes using advanced AI. With Voice AI Note, you can create voice notes that are fluent, accurate, and sound natural. The application is easy to use and requires no prior experience with AI or voice recording. Simply enter the text you want to convert to speech, and Voice AI Note will do the rest.
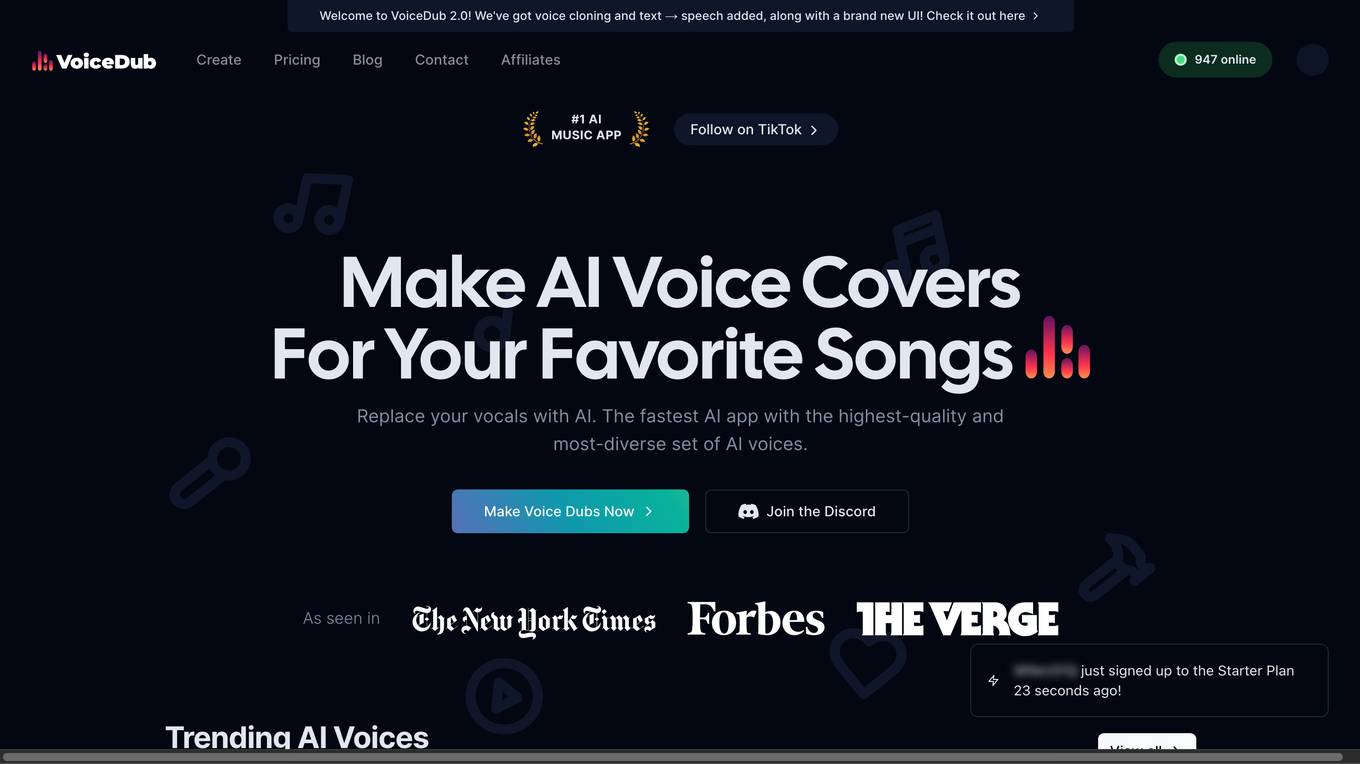
VoiceDub
VoiceDub is an AI-powered application that allows users to create voice covers of their favorite songs. It offers a wide range of AI voices to choose from, as well as the ability to clone your own voice. VoiceDub also includes a text-to-speech feature, which allows users to generate studio-quality vocals from text. The application is easy to use and produces high-quality results, making it a great choice for musicians, singers, and content creators.

Voicenotes
Voicenotes is an AI-powered note-taking app that helps you capture, organize, and share your ideas with ease. With advanced speech recognition and natural language processing capabilities, Voicenotes allows you to take notes using your voice, making it perfect for capturing ideas on the go or when your hands are full. The app also offers a range of features to help you organize your notes, including automatic transcription, keyword tagging, and customizable folders. Voicenotes integrates with other productivity tools, such as Evernote and Google Drive, making it easy to share and collaborate on your notes with others.
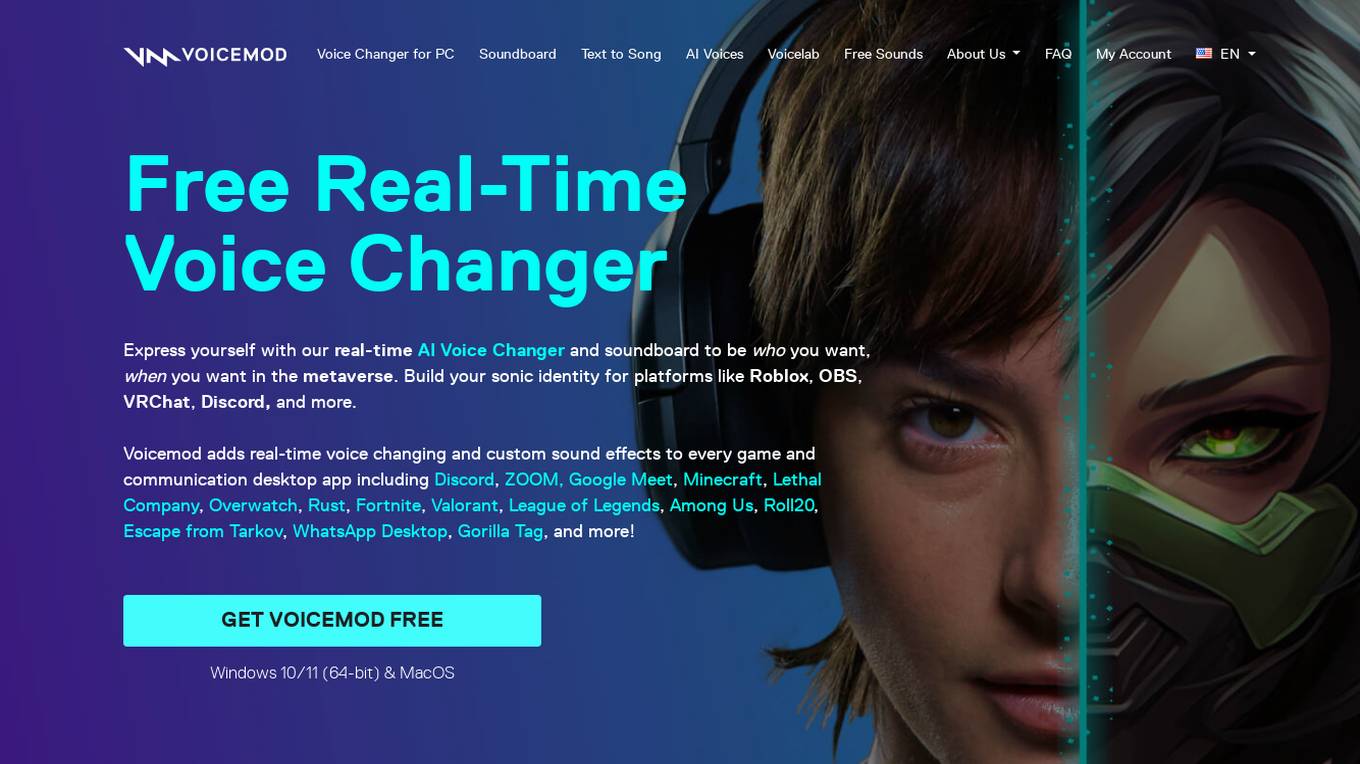
Voicemod
Voicemod is a free real-time voice changer and soundboard available on both Windows and macOS. It allows users to change their voice in real-time, add sound effects, and create custom voices. Voicemod integrates with popular games, streaming software, and chat applications, making it a versatile tool for gamers, content creators, and anyone who wants to add some fun to their voice communication.
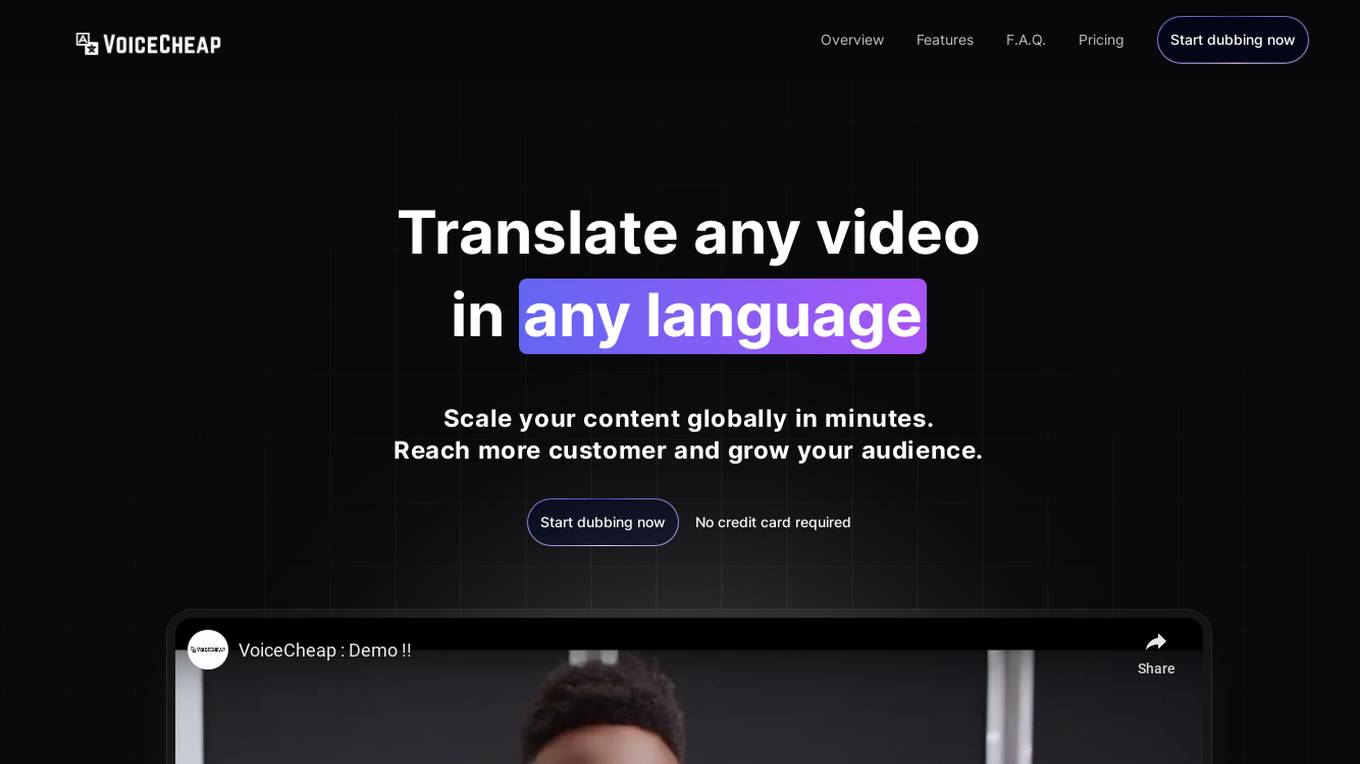
VoiceCheap
VoiceCheap is an AI-powered application that offers dubbing, transcription, and speech synthesis services. It enables users to translate videos into multiple languages, clone voices, generate subtitles, remove background noise, and more. With features like SmartSync Technology and multi-speaker dubbing, VoiceCheap helps content creators produce professional-quality dubbed videos efficiently. The application uses advanced AI technology to provide cost-effective dubbing solutions and seamless integration with various platforms. VoiceCheap is trusted by professionals and loved by users worldwide for its innovative tools and services.
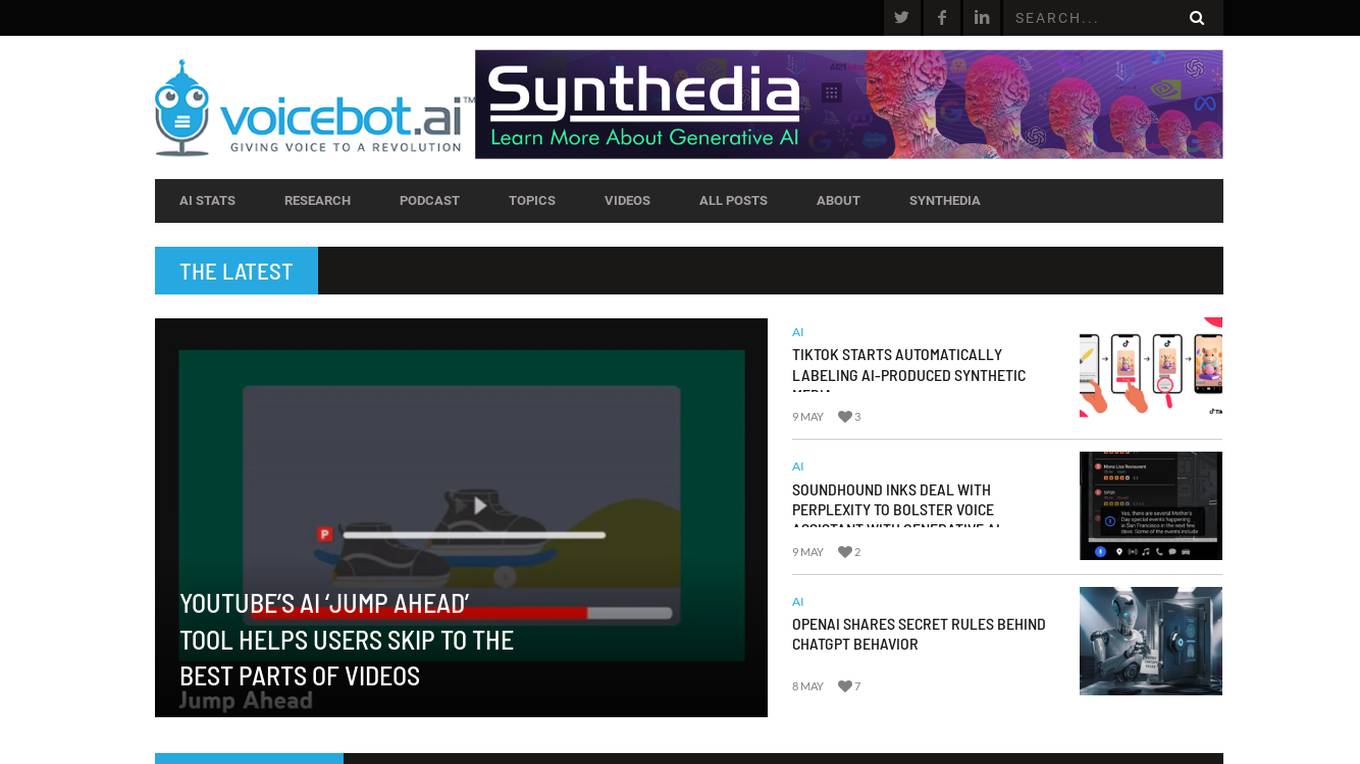
Voicebot.ai
Voicebot.ai is an AI-focused website that provides comprehensive information and insights on voice assistants, AI models, generative AI, and related technologies. The platform covers a wide range of topics such as smart speakers, voice shopping, healthcare voice assistants, and AI in marketing. It also offers reports, research, and best practices in the field of voice technology. Voicebot.ai aims to educate and inform its audience about the latest developments and trends in the AI industry.
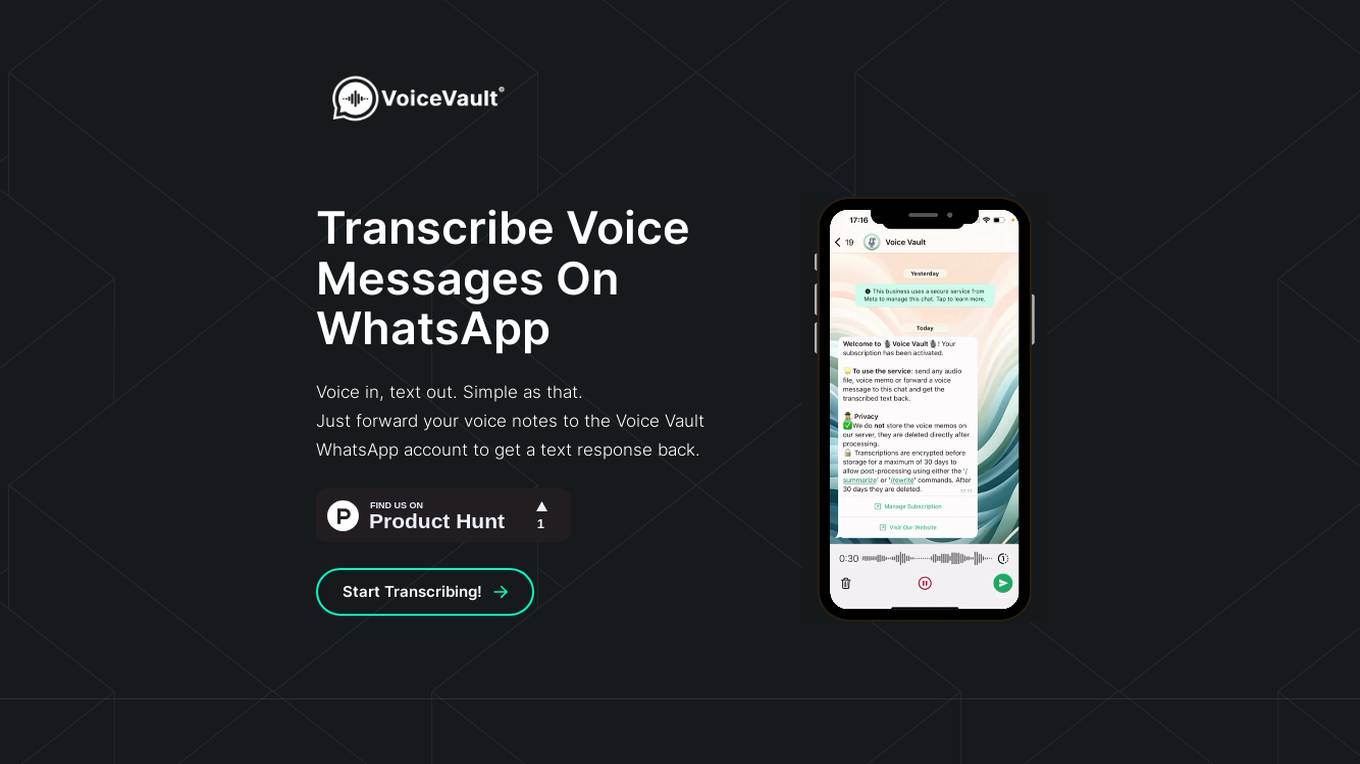
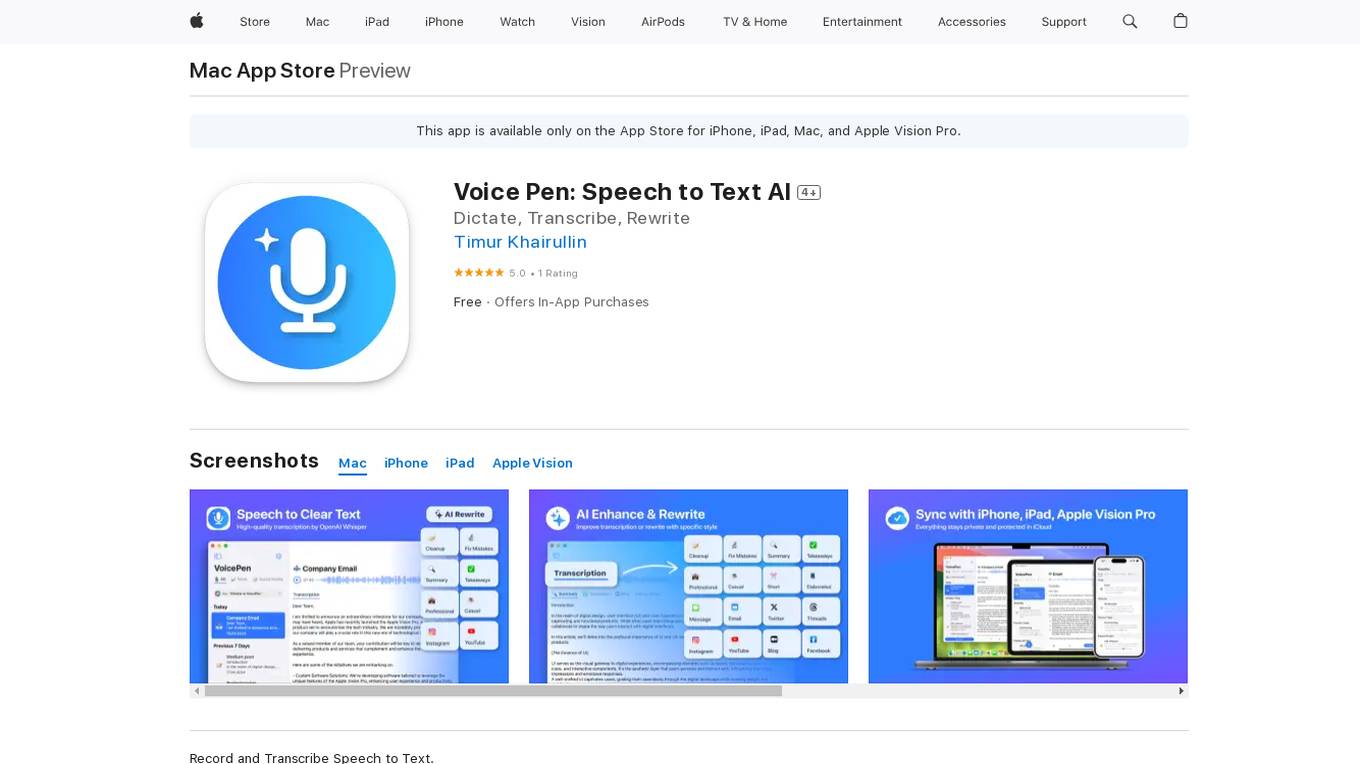
Voice Pen
Voice Pen is a Speech to Text AI application available on the App Store for Apple devices. It allows users to record and transcribe speech into text, which can then be used to create notes, summaries, emails, messages, and blog posts. The app supports more than 50 languages and offers AI options for rewriting and transforming text. Voice Pen enhances productivity by providing features like background audio recording, language autodetection, and the ability to create various types of content. It also prioritizes user privacy by only collecting app usage analytics and not storing any audio or text data on its servers.
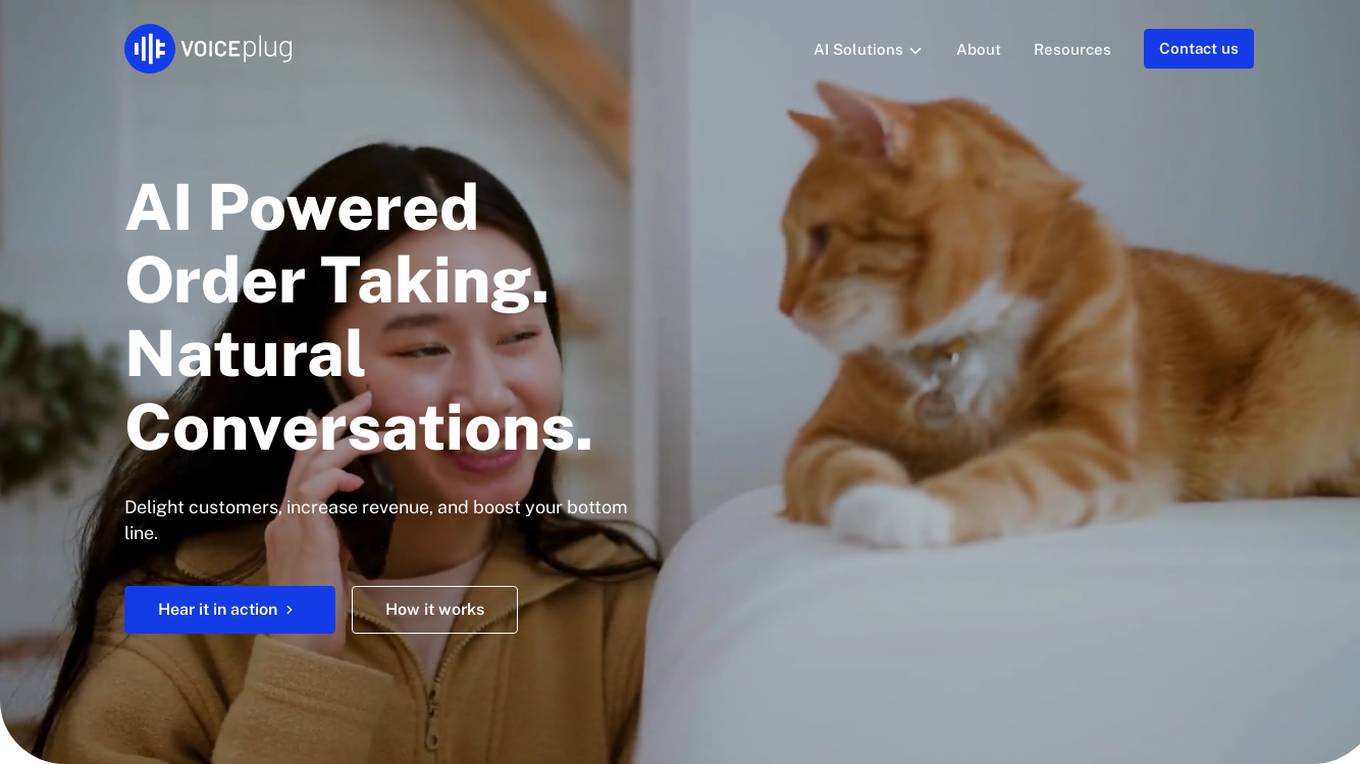
Voiceplug.ai
Voiceplug.ai is an AI-powered food ordering system designed for restaurants. It offers various AI solutions such as Phone AI, Drive-Thru AI, Kiosk AI, and PizzaVoice, each tailored to enhance customer experience, increase revenue, and boost operational efficiency. The system ensures personalized conversations, efficient order taking, and targeted customer engagement through natural conversations and AI-driven upselling. Voiceplug.ai empowers restaurant owners to streamline their operations, reduce labor costs, and improve customer service by leveraging the capabilities of Voice AI technology.
VoiceGen
VoiceGen is an AI audio platform that enables users to create realistic speech using the best technology from leading providers like OpenAI, Google, AWS, and Azure. It offers natural, high-quality voices with support for multiple languages and unrestricted commercial use. VoiceGen prioritizes simplicity, transparency, and innovation, providing an accessible and affordable solution for voice generation needs. The platform ensures security and privacy of user data, offering a pay-as-you-go pricing model with fair and transparent costs.
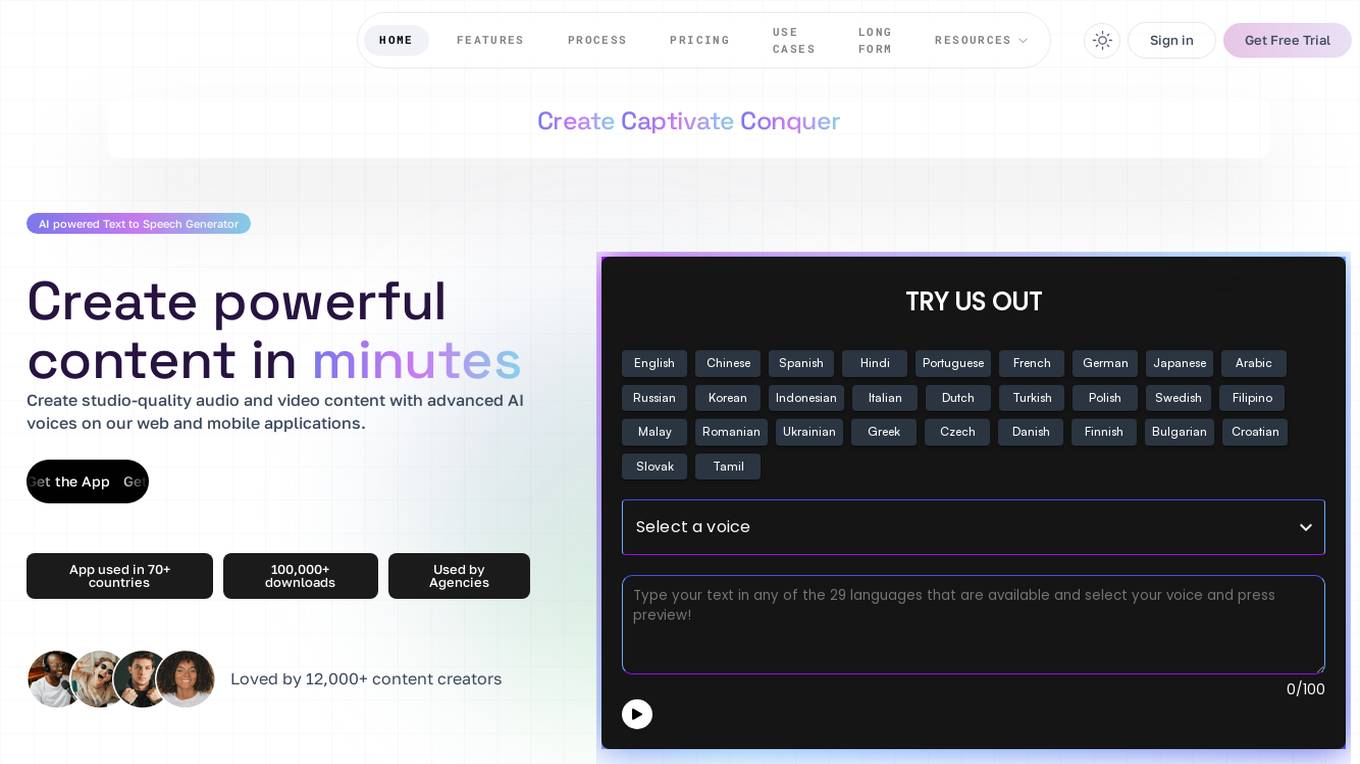
Voice Air
Voice Air is an AI-powered Text to Speech Generator that allows users to create studio-quality audio and video content with advanced AI voices on web and mobile applications. It offers cutting-edge features to enhance content creation, such as human-like voiceovers, award-winning music library, and AI features for content scaling. Voice Air is used in 70+ countries, with 100,000+ downloads and is loved by 12,000+ content creators. The application aims to revolutionize content creation by providing high-quality, natural-sounding voices and innovative features.
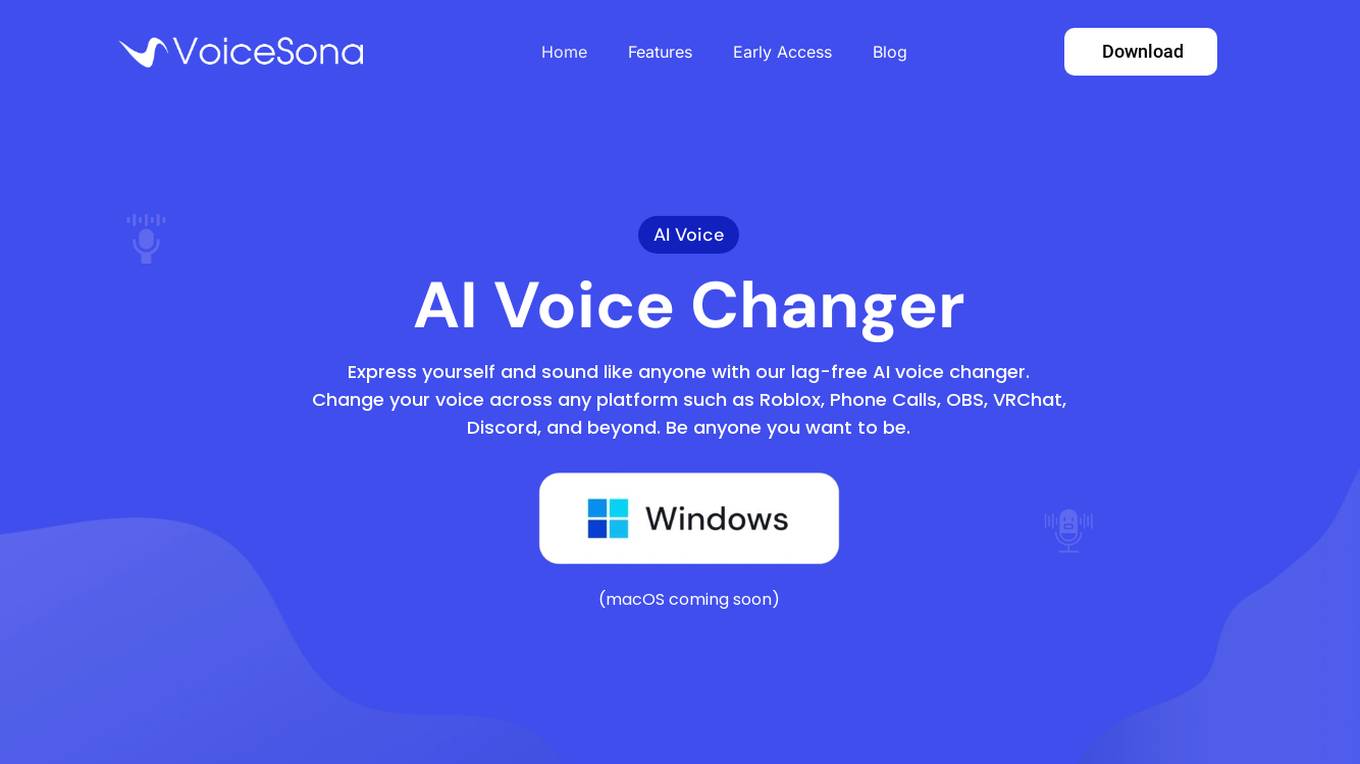
VoiceSona
VoiceSona is an AI-powered voice changer application that allows users to transform their voice to sound like anyone they want. With a lag-free experience, users can change their voice across various platforms such as Roblox, phone calls, OBS, VRChat, and Discord. The application offers thousands of voices including singers, villains, rappers, presidents, and actors, providing a new level of voice-changing technology.
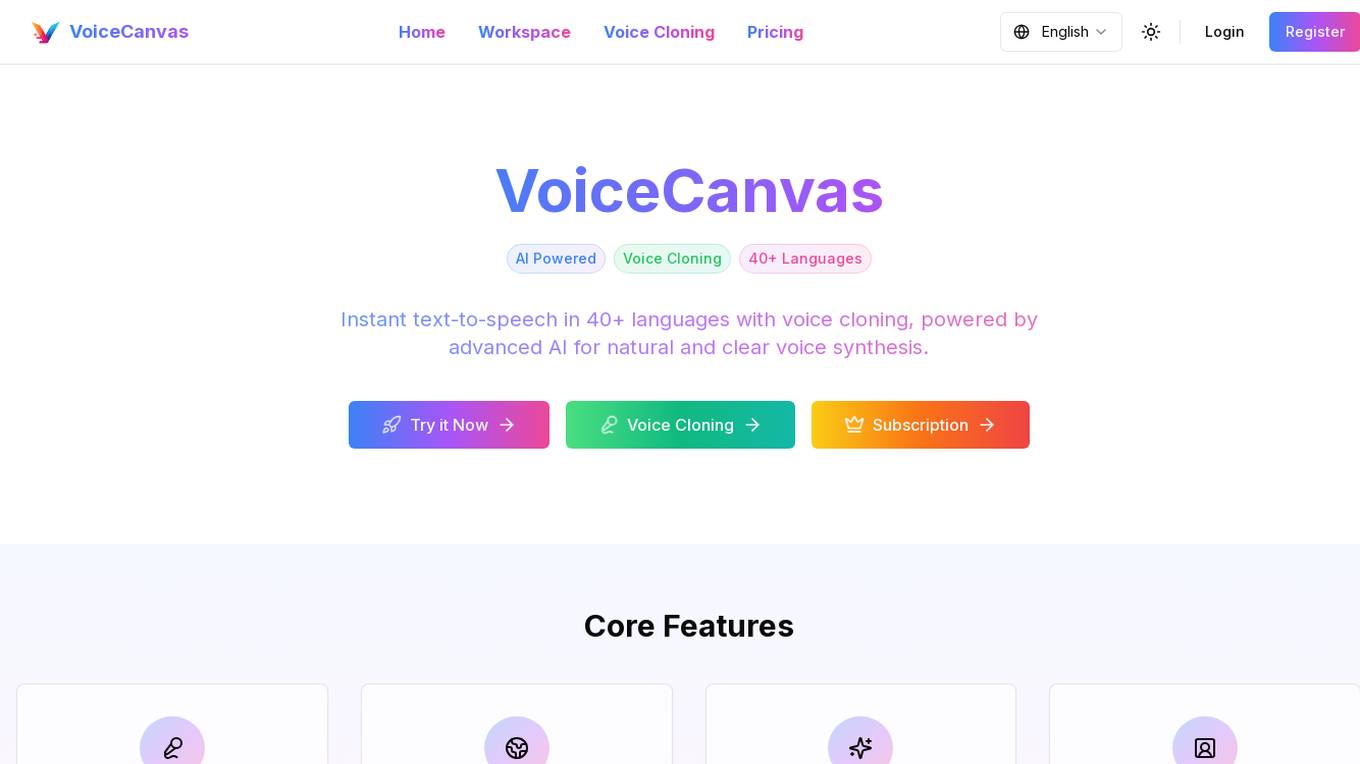
VoiceCanvas
VoiceCanvas is an advanced AI-powered multilingual voice synthesis and voice cloning platform that offers instant text-to-speech in over 40 languages. It utilizes cutting-edge AI technology to provide high-quality voice synthesis with natural intonation and rhythm, along with personalized voice cloning for more human-like AI speech. Users can upload voice samples, have AI analyze voice features, generate personalized AI voice models, input text for conversion, and apply the cloned AI voice model to generate natural voice speech. VoiceCanvas is highly praised by language learners, content creators, teachers, business owners, voice actors, and educators for its exceptional voice quality, multiple language support, and ease of use in creating voiceovers, learning materials, and podcast content.
Anime Voice Match
Anime Voice Match, identifies anime characters similar to the user's voice.


Speak GPT
Voice-centric English role-play tool for speaking practice and offering personalized feedback! <Try in mobile>
CliniType EHR
Voice-to-text, Vision-to-text transcription, Transcript-to-‘Clinical format’ integrated with CDS. Writes clinical notes, referral letter, generate PDF,prepare discharge summary. (Ultimate aid for clinicians)
Voice/Style/Tone AI Prompt Snippet Generator
Analyzes your writing and produces a prompt snippet you can use in any other prompt to guide AI in replicating your voice, style, and tone. Just provide the text in the prompt box or in a document (don't use a link or image). You don't need to write any additional prompt language with your text.


Your Lingo AI Coach
Welcome! I'm a voice-focused language teacher for interactive speaking practice. To enable voice, download the app and tap the headphone button next to my chat window. Then choose your preferred voice. When you're ready, tell me what language you'd like to learn. It's FREE!
Voice Memo
Record your thoughts with ChatGPT Voice Conversations 💡. Get started by clicking the 🎧 icon right to the chat input. Available on mobile only. Ask 'how do you work?' to learn more.
DateMate
Your friendly AI assistant for voice-based dating, offering personalized tips, safety advice, and fun interactions.

Commerce Cloud Guru
Professional voice for SFCC B2C Commerce Cloud expertise. 🔒 Unlock the full potential of B2C Commerce Cloud

Transcript to Social Post
Transforms transcripts (from Whatsapp voice memos) into engaging social media content.
Bring Your Writing Voice to Every Task
This GPT will help you recreate your writing voice across multiple tasks. All you need is a prior writing sample (email, blog, article, tweet) and a new task.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.
voice-pro
Voice-Pro is an integrated solution for subtitles, translation, and TTS. It offers features like multilingual subtitles, live translation, vocal remover, and supports OpenAI Whisper and Open-Source Translator. The tool provides a Studio tab for various functions, Whisper Caption tab for subtitle creation, Translate tab for translation, TTS tab for text-to-speech, Live Translation tab for real-time voice recognition, and Batch tab for processing multiple files. Users can download YouTube videos, improve voice recognition accuracy, create automatic subtitles, and produce multilingual videos with ease. The tool is easy to install with one-click and offers a Web-UI for user convenience.

VoiceBench
VoiceBench is a repository containing code and data for benchmarking LLM-Based Voice Assistants. It includes a leaderboard with rankings of various voice assistant models based on different evaluation metrics. The repository provides setup instructions, datasets, evaluation procedures, and a curated list of awesome voice assistants. Users can submit new voice assistant results through the issue tracker for updates on the ranking list.
voice-chat-ai
Voice Chat AI is a project that allows users to interact with different AI characters using speech. Users can choose from various characters with unique personalities and voices, and have conversations or role play with them. The project supports OpenAI, xAI, or Ollama language models for chat, and provides text-to-speech synthesis using XTTS, OpenAI TTS, or ElevenLabs. Users can seamlessly integrate visual context into conversations by having the AI analyze their screen. The project offers easy configuration through environment variables and can be run via WebUI or Terminal. It also includes a huge selection of built-in characters for engaging conversations.

VoiceStreamAI
VoiceStreamAI is a Python 3-based server and JavaScript client solution for near-realtime audio streaming and transcription using WebSocket. It employs Huggingface's Voice Activity Detection (VAD) and OpenAI's Whisper model for accurate speech recognition. The system features real-time audio streaming, modular design for easy integration of VAD and ASR technologies, customizable audio chunk processing strategies, support for multilingual transcription, and secure sockets support. It uses a factory and strategy pattern implementation for flexible component management and provides a unit testing framework for robust development.
voicechat2
Voicechat2 is a fast, fully local AI voice chat tool that uses WebSockets for communication. It includes a WebSocket server for remote access, default web UI with VAD and Opus support, and modular/swappable SRT, LLM, TTS servers. Users can customize components like SRT, LLM, and TTS servers, and run different models for voice-to-voice communication. The tool aims to reduce latency in voice communication and provides flexibility in server configurations.
manim-voiceover
Manim Voiceover is a plugin for the Manim animation library that allows users to easily add voiceovers to their videos directly in Python without the need for a separate video editor. It also provides the ability to record voiceovers using a command line interface and supports auto-generated AI voices from various services. Users can trigger animations at specific words in the voiceover, thanks to OpenAI Whisper. The plugin supports TTS services such as Azure Text to Speech, Coqui TTS, gTTS, and pyttsx3. It also offers features for translating voiceovers into other languages using machine translation services like DeepL.
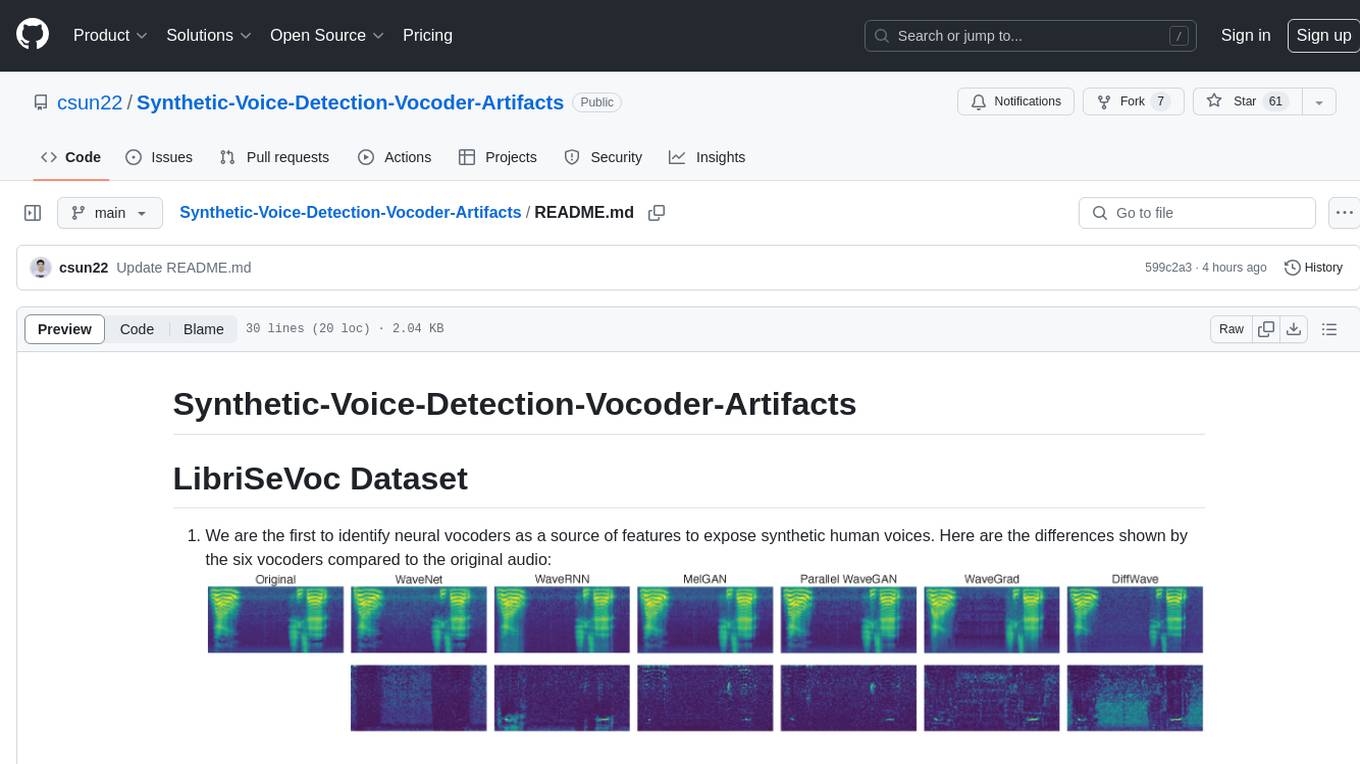
Synthetic-Voice-Detection-Vocoder-Artifacts
The Synthetic-Voice-Detection-Vocoder-Artifacts repository provides the LibriSeVoc dataset containing self-vocoding samples created with six state-of-the-art vocoders to expose and exploit vocoder artifacts. It also introduces a new approach for detecting synthetic human voices by identifying signal artifacts left by neural vocoders and enhancing the RawNet2 baseline. The repository includes a paper and dataset for further reference and offers instructions for training the model and testing it in the wild.

Easy-Voice-Toolkit
Easy Voice Toolkit is a toolkit based on open source voice projects, providing automated audio tools including speech model training. Users can seamlessly integrate functions like audio processing, voice recognition, voice transcription, dataset creation, model training, and voice conversion to transform raw audio files into ideal speech models. The toolkit supports multiple languages and is currently only compatible with Windows systems. It acknowledges the contributions of various projects and offers local deployment options for both users and developers. Additionally, cloud deployment on Google Colab is available. The toolkit has been tested on Windows OS devices and includes a FAQ section and terms of use for academic exchange purposes.
viitor-voice
ViiTor-Voice is an LLM based TTS Engine that offers a lightweight design with 0.5B parameters for efficient deployment on various platforms. It provides real-time streaming output with low latency experience, a rich voice library with over 300 voice options, flexible speech rate adjustment, and zero-shot voice cloning capabilities. The tool supports both Chinese and English languages and is suitable for applications requiring quick response and natural speech fluency.
bidirectional_streaming_ai_voice
This repository contains Python scripts that enable two-way voice conversations with Anthropic Claude, utilizing ElevenLabs for text-to-speech, Faster-Whisper for speech-to-text, and Pygame for audio playback. The tool operates by transcribing human audio using Faster-Whisper, sending the transcription to Anthropic Claude for response generation, and converting the LLM's response into audio using ElevenLabs. The audio is then played back through Pygame, allowing for a seamless and interactive conversation between the user and the AI. The repository includes variations of the main script to support different operating systems and configurations, such as using CPU transcription on Linux or employing the AssemblyAI API instead of Faster-Whisper.
Srt-AI-Voice-Assistant
Srt-AI-Voice-Assistant is a convenient tool that generates audio from uploaded .srt subtitle files by calling APIs such as Bert-VITS2 (HiyoriUI), GPT-SoVITS, and Microsoft TTS (online). The code is currently not perfect, and feedback on bugs or suggestions can be provided at https://github.com/YYuX-1145/Srt-AI-Voice-Assistant/issues. Recent updates include adding custom API functionality with a focus on security, support for Microsoft online TTS (requires key configuration), error handling improvements, automatic project path detection, compatibility with API-v1 for limited functionality, and significant feature updates supporting card synthesis.
bolna
Bolna is an open-source platform for building voice-driven conversational applications using large language models (LLMs). It provides a comprehensive set of tools and integrations to handle various aspects of voice-based interactions, including telephony, transcription, LLM-based conversation handling, and text-to-speech synthesis. Bolna simplifies the process of creating voice agents that can perform tasks such as initiating phone calls, transcribing conversations, generating LLM-powered responses, and synthesizing speech. It supports multiple providers for each component, allowing users to customize their setup based on their specific needs. Bolna is designed to be easy to use, with a straightforward local setup process and well-documented APIs. It is also extensible, enabling users to integrate with other telephony providers or add custom functionality.

Applio
Applio is a VITS-based Voice Conversion tool focused on simplicity, quality, and performance. It features a user-friendly interface, cross-platform compatibility, and a range of customization options. Applio is suitable for various tasks such as voice cloning, voice conversion, and audio editing. Its key features include a modular codebase, hop length implementation, translations in over 30 languages, optimized requirements, streamlined installation, hybrid F0 estimation, easy-to-use UI, optimized code and dependencies, plugin system, overtraining detector, model search, enhancements in pretrained models, voice blender, accessibility improvements, new F0 extraction methods, output format selection, hashing system, model download system, TTS enhancements, split audio, Discord presence, Flask integration, and support tab.
wit-unity
Wit-unity is a Unity C# based wrapper around the rest apis provided by Wit.ai. It is meant to be used as a base library within Voice SDK. We have made it accessible here for contributions and early adoption testing. Wit-unity is ideal for developers looking to do early research with voice and potential expand the core capabilities of Voice SDK.

agents
The LiveKit Agent Framework is designed for building real-time, programmable participants that run on servers. Easily tap into LiveKit WebRTC sessions and process or generate audio, video, and data streams. The framework includes plugins for common workflows, such as voice activity detection and speech-to-text. Agents integrates seamlessly with LiveKit server, offloading job queuing and scheduling responsibilities to it. This eliminates the need for additional queuing infrastructure. Agent code developed on your local machine can scale to support thousands of concurrent sessions when deployed to a server in production.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

GlaDOS
This project aims to create a real-life version of GLaDOS, an aware, interactive, and embodied AI entity. It involves training a voice generator, developing a 'Personality Core,' implementing a memory system, providing vision capabilities, creating 3D-printable parts, and designing an animatronics system. The software architecture focuses on low-latency voice interactions, utilizing a circular buffer for data recording, text streaming for quick transcription, and a text-to-speech system. The project also emphasizes minimal dependencies for running on constrained hardware. The hardware system includes servo- and stepper-motors, 3D-printable parts for GLaDOS's body, animations for expression, and a vision system for tracking and interaction. Installation instructions cover setting up the TTS engine, required Python packages, compiling llama.cpp, installing an inference backend, and voice recognition setup. GLaDOS can be run using 'python glados.py' and tested using 'demo.ipynb'.
pipecat
Pipecat is an open-source framework designed for building generative AI voice bots and multimodal assistants. It provides code building blocks for interacting with AI services, creating low-latency data pipelines, and transporting audio, video, and events over the Internet. Pipecat supports various AI services like speech-to-text, text-to-speech, image generation, and vision models. Users can implement new services and contribute to the framework. Pipecat aims to simplify the development of applications like personal coaches, meeting assistants, customer support bots, and more by providing a complete framework for integrating AI services.
vocode-python
Vocode is an open source library that enables users to easily build voice-based LLM (Large Language Model) apps. With Vocode, users can create real-time streaming conversations with LLMs and deploy them for phone calls, Zoom meetings, and more. The library offers abstractions and integrations for transcription services, LLMs, and synthesis services, making it a comprehensive tool for voice-based applications.