
voicechat2
Local SRT/LLM/TTS Voicechat
Stars: 500
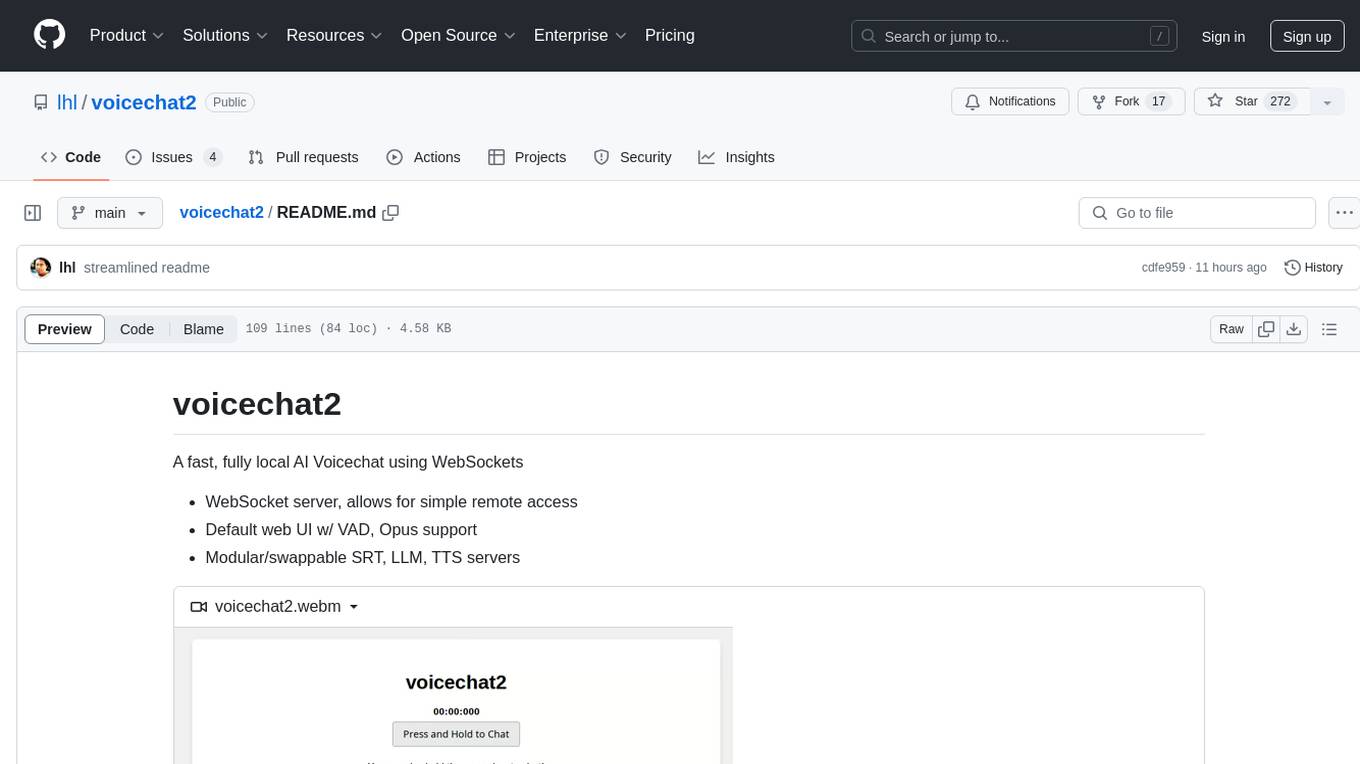
Voicechat2 is a fast, fully local AI voice chat tool that uses WebSockets for communication. It includes a WebSocket server for remote access, default web UI with VAD and Opus support, and modular/swappable SRT, LLM, TTS servers. Users can customize components like SRT, LLM, and TTS servers, and run different models for voice-to-voice communication. The tool aims to reduce latency in voice communication and provides flexibility in server configurations.
README:
A fast, fully local AI Voicechat using WebSockets
- WebSocket server, allows for simple remote access
- Default web UI w/ VAD using ricky0123/vad, Opus support using symblai/opus-encdec
- Modular/swappable SRT, LLM, TTS servers
- SRT: whisper.cpp, faster-whisper, or HF Transformers whisper
- LLM: llama.cpp or any OpenAI API compatible server
- TTS: coqui-tts, StyleTTS2, Piper, MeloTTS
Unmute to hear the audio
On an 7900-class AMD RDNA3 card, voice-to-voice latency is in the 1 second range:
- distil-whisper/distil-large-v2
- bartowski/Meta-Llama-3.1-8B-Instruct-GGUF (Q4_K_M)
- tts_models/en/vctk/vits (Coqui TTS default VITS models)
On a 4090, using Faster Whisper with faster-distil-whisper-large-v2 we can cut the latency down to as low as 300ms:
You can of course run any model or swap out any of the SRT, LLM, TTS components as you like. For example, you can run whisper.cpp for SRT, or we have a StyleTTS2 server in the test folder for an alternative TTS. For a bit more about this project, see my Hackster.io writeup.
These installation instructions are for Ubuntu LTS and assume you've setup your ROCm or CUDA already.
I recommend you use conda or (my preferred), mamba for environment management. It will make your life easier.
sudo apt update
# Not strictly required but the helpers we use
sudo apt install byobu curl wget
# Audio processing
sudo apt install espeak-ng ffmpeg libopus0 libopus-dev
# Create env
mamba create -y -n voicechat2 python=3.11
# Setup
mamba activate voicechat2
git clone https://github.com/lhl/voicechat2
cd voicechat2
pip install -r requirements.txt
# Build llama.cpp
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
# AMD version
make GGML_HIPBLAS=1 -j
# Nvidia version
make GGML_CUDA=1 -j
# Grab your preferred GGUF model
wget https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF/resolve/main/Meta-Llama-3-8B-Instruct-Q4_K_M.gguf
# If you're going to go to the next instruction
cd ..
Some extra convenience scripts for launching:
run-voicechat2.sh - on your GPU machine, tries to launch all servers in separate byobu sessions; update the MODEL variables
remote-tunnel.sh - connect your GPU machine to a jump machine
local-tunnel.sh - connect to the GPU machine via a jump machine
A project released after voicechat2 that uses a similar modular approach but is local device oriented
- https://github.com/eustlb/speech-to-speech
- No license?
The demo shows a fair amount of latency (~10s) but this project isn't the closest to what we're doing (it uses WebRTC not websockets) from voicechat2 (HF Transformers, Ollama)
A console-based local client (HF Transformers, Ollama, Coqui TTS, PortAudio)
This is a very responsive console-based local-client app that also has VAD and interruption support, plus a really clever hook! (whisper.cpp, llama.cpp, piper, espeak)
Another console-based local client, more of a proof of concept but with w/ blog writeup.
- https://github.com/vndee/local-talking-llm
- https://blog.duy.dev/build-your-own-voice-assistant-and-run-it-locally/
- MIT
Another console-based local client (FastConformer, HF Transformers, StyleTTS2, espeak)
KoljaB has a number of interesting projects around console-based local clients like RealtimeSTT, RealtimeTTS, Linguflex, etc. (faster_whisper, llama.cpp, Coqui XTTS)
- https://github.com/KoljaB/LocalAIVoiceChat
- NC (Coqui Model License)
This is not a local voicechat client, but it does have a neat WebRTC front-end, so might be worth poking around into (Vite/React, Tailwind, Radix)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for voicechat2
Similar Open Source Tools
voicechat2
Voicechat2 is a fast, fully local AI voice chat tool that uses WebSockets for communication. It includes a WebSocket server for remote access, default web UI with VAD and Opus support, and modular/swappable SRT, LLM, TTS servers. Users can customize components like SRT, LLM, and TTS servers, and run different models for voice-to-voice communication. The tool aims to reduce latency in voice communication and provides flexibility in server configurations.
llocal
LLocal is an Electron application focused on providing a seamless and privacy-driven chatting experience using open-sourced technologies, particularly open-sourced LLM's. It allows users to store chats locally, switch between models, pull new models, upload images, perform web searches, and render responses as markdown. The tool also offers multiple themes, seamless integration with Ollama, and upcoming features like chat with images, web search improvements, retrieval augmented generation, multiple PDF chat, text to speech models, community wallpapers, lofi music, speech to text, and more. LLocal's builds are currently unsigned, requiring manual builds or using the universal build for stability.
toolmate
ToolMate AI is an advanced AI companion that integrates agents, tools, and plugins to excel in conversations, generative work, and task execution. It supports multi-step actions, allowing users to customize workflows for tackling complex projects with ease. The tool offers a wide range of AI backends and models, including Ollama, Llama.cpp, Groq Cloud API, OpenAI API, and Google Gemini via Vertex AI. Users can easily switch between backends and leverage AI models like wizardlm2 and mixtral. ToolMate AI stands out for its distinctive features such as tool calling for any LLMs, running multiple tools in one go, highly customizable plugins, and integration with popular AI tools. It also supports quick tool calling using '@' notation and enables the execution of computing tasks on demand. With features like multiple tools in one go, customizable plugins, system command and fabric integration, GPU offloading support, real-time data access, and device information retrieval, ToolMate AI offers a comprehensive solution for various tasks and content creation.
anon-kode
ANON KODE is a terminal-based AI coding tool that utilizes any model supporting the OpenAI-style API. It helps in fixing spaghetti code, explaining function behavior, running tests and shell commands, and more based on the model used. Users can easily set up models, submit bugs, and ensure data privacy with no telemetry or backend servers other than chosen AI providers.
open-cuak
Open CUAK (Computer Use Agent) is a platform for managing automation agents at scale, designed to run and manage thousands of automation agents with reliability. It allows for abundant productivity by ensuring scalability and profitability. The project aims to usher in a new era of work with equally distributed productivity, making it open-sourced for real businesses and real people. The core features include running operator-like automation workflows locally, vision-based automation, turning any browser into an operator-companion, utilizing a dedicated remote browser, and more.
SwarmUI
SwarmUI is a modular stable diffusion web-user-interface designed to make powertools easily accessible, high performance, and extensible. It is in Beta status, offering a primary Generate tab for beginners and a Comfy Workflow tab for advanced users. The tool aims to become a full-featured one-stop-shop for all things Stable Diffusion, with plans for better mobile browser support, detailed 'Current Model' display, dynamic tab shifting, LLM-assisted prompting, and convenient direct distribution as an Electron app.
whisplay-ai-chatbot
Whisplay-AI-Chatbot is a pocket-sized AI chatbot device built using a Raspberry Pi Zero 2w. It features a PiSugar Whisplay HAT with an LCD screen, on-board speaker, and microphone. Users can interact with the chatbot by pressing a button, speaking, and receiving responses, similar to a futuristic walkie-talkie. The tool supports various functionalities such as adjusting volume autonomously, resetting conversation history, local ASR and TTS capabilities, image generation, and integration with APIs like Google Gemini and Grok. It also offers support for LLM8850 AI Accelerator for offline capabilities like ASR, TTS, and LLM API. The chatbot saves conversation history and generated images in a data folder, and users can customize the tool with different enclosure cases available for Pi02 and Pi5 models.
starter-monorepo
Starter Monorepo is a template repository for setting up a monorepo structure in your project. It provides a basic setup with configurations for managing multiple packages within a single repository. This template includes tools for package management, versioning, testing, and deployment. By using this template, you can streamline your development process, improve code sharing, and simplify dependency management across your project. Whether you are working on a small project or a large-scale application, Starter Monorepo can help you organize your codebase efficiently and enhance collaboration among team members.
minecraft-mcp-server
Minecraft MCP Server is a bot powered by large language models and Mineflayer API. It uses the Model Context Protocol (MCP) to enable models like Claude to control a Minecraft character. The bot allows users to interact with Minecraft through commands and chat messages, facilitating tasks such as movement, inventory management, block interaction, entity interaction, and more. Users can also upload images of buildings and ask the bot to build them. The tool is designed to work with Claude Desktop and requires specific configurations for Minecraft and MCP clients. Contributions to the project, including refactoring, testing, documentation, and new functionality, are welcome.
ChatLLM-Web
ChatLLM Web is a browser-based AI chat tool powered by WebGPU, providing a seamless and private chat experience. It runs models in a web worker, supports model caching, and offers multi-conversation chat with data stored locally. The tool features a well-designed UI with dark mode, PWA support for offline use, and markdown and streaming response capabilities. Users can deploy it easily on Vercel and interact with the AI like Vicuna in their browser.
Demucs-Gui
Demucs GUI is a graphical user interface for the music separation project Demucs. It aims to allow users without coding experience to easily separate tracks. The tool provides a user-friendly interface for running the Demucs project, which originally used the scientific library torch. The GUI simplifies the process of separating tracks and provides support for different platforms such as Windows, macOS, and Linux. Users can donate to support the development of new models for the project, and the tool has specific system requirements including minimum system versions and hardware specifications.
minimal-llm-ui
This minimalistic UI serves as a simple interface for Ollama models, enabling real-time interaction with Local Language Models (LLMs). Users can chat with models, switch between different LLMs, save conversations, and create parameter-driven prompt templates. The tool is built using React, Next.js, and Tailwind CSS, with seamless integration with LangchainJs and Ollama for efficient model switching and context storage.
OM1
OpenMind's OM1 is a modular AI runtime empowering developers to create and deploy multimodal AI agents across digital environments and physical robots. OM1 agents process diverse inputs like web data, social media, camera feeds, and LIDAR, enabling actions including motion, autonomous navigation, and natural conversations. The goal is to create highly capable human-focused robots that are easy to upgrade and reconfigure for different physical form factors. OM1 features a modular architecture, supports new hardware via plugins, offers web-based debugging display, and pre-configured endpoints for various services.
dream-team
Build your dream team with Autogen is a repository that leverages Microsoft Autogen 0.4, Azure OpenAI, and Streamlit to create an end-to-end multi-agent application. It provides an advanced multi-agent framework based on Magentic One, with features such as a friendly UI, single-line deployment, secure code execution, managed identities, and observability & debugging tools. Users can deploy Azure resources and the app with simple commands, work locally with virtual environments, install dependencies, update configurations, and run the application. The repository also offers resources for learning more about building applications with Autogen.
lmstudio-js
LM Studio Client SDK lmstudio-ts is LM Studio's official JavaScript/TypeScript client SDK. It allows you to use LLMs to respond in chats or predict text completions, define functions as tools, and turn LLMs into autonomous agents that run completely locally, load, configure, and unload models from memory, supports both browser and any Node-compatible environments, generate embeddings for text, and more! Why use `lmstudio-js` over `openai` sdk? Open AI's SDK is designed to use with Open AI's proprietary models. As such, it is missing many features that are essential for using LLMs in a local environment, such as managing loading and unloading models from memory, configuring load parameters (context length, gpu offload settings, etc.), speculative decoding, getting information (such as context length, model size, etc.) about a model, and more. In addition, while `openai` sdk is automatically generated, `lmstudio-js` is designed from ground-up to be clean and easy to use for TypeScript/JavaScript developers.

OSWorld
OSWorld is a benchmarking tool designed to evaluate multimodal agents for open-ended tasks in real computer environments. It provides a platform for running experiments, setting up virtual machines, and interacting with the environment using Python scripts. Users can install the tool on their desktop or server, manage dependencies with Conda, and run benchmark tasks. The tool supports actions like executing commands, checking for specific results, and evaluating agent performance. OSWorld aims to facilitate research in AI by providing a standardized environment for testing and comparing different agent baselines.
For similar tasks

omnia
Omnia is a deployment tool designed to turn servers with RPM-based Linux images into functioning Slurm/Kubernetes clusters. It provides an Ansible playbook-based deployment for Slurm and Kubernetes on servers running an RPM-based Linux OS. The tool simplifies the process of setting up and managing clusters, making it easier for users to deploy and maintain their infrastructure.
voicechat2
Voicechat2 is a fast, fully local AI voice chat tool that uses WebSockets for communication. It includes a WebSocket server for remote access, default web UI with VAD and Opus support, and modular/swappable SRT, LLM, TTS servers. Users can customize components like SRT, LLM, and TTS servers, and run different models for voice-to-voice communication. The tool aims to reduce latency in voice communication and provides flexibility in server configurations.
open-edison
OpenEdison is a secure MCP control panel that connects AI to data/software with additional security controls to reduce data exfiltration risks. It helps address the lethal trifecta problem by providing visibility, monitoring potential threats, and alerting on data interactions. The tool offers features like data leak monitoring, controlled execution, easy configuration, visibility into agent interactions, a simple API, and Docker support. It integrates with LangGraph, LangChain, and plain Python agents for observability and policy enforcement. OpenEdison helps gain observability, control, and policy enforcement for AI interactions with systems of records, existing company software, and data to reduce risks of AI-caused data leakage.
ai-factory
AI Factory is a CLI tool and skill system that streamlines AI-powered development by handling context setup, skill installation, and workflow configuration. It supports multiple AI coding agents, offers spec-driven development, and integrates with popular tech stacks like Next.js, Laravel, Django, and Express. The tool ensures zero configuration, best practices adherence, community skills utilization, and multi-agent support. Users can create plans, tasks, and commits for structured feature development, bug fixes, and self-improvement. Security is a priority with mandatory two-level scans for external skills. The tool's learning loop generates patches from bug fixes to enhance future implementations.
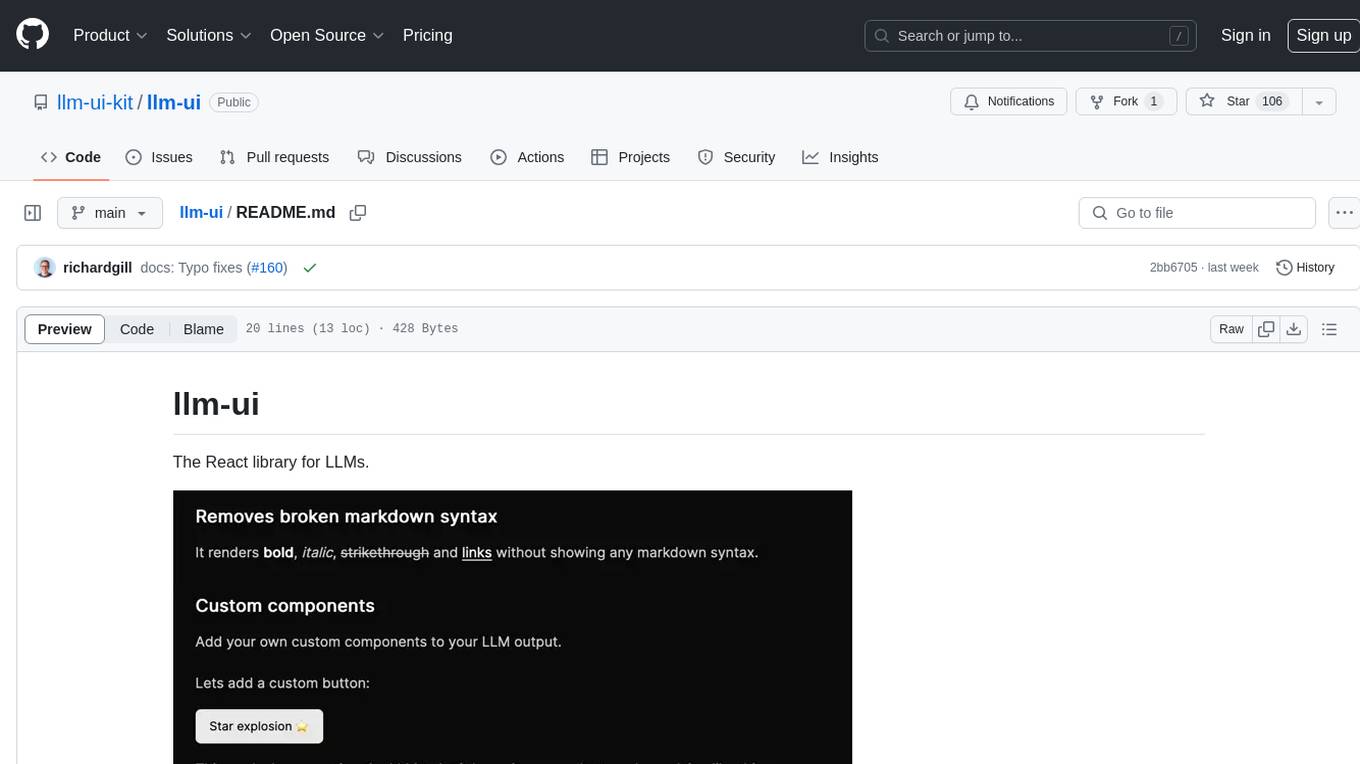
llm-ui
llm-ui is a React library designed for LLMs, providing features such as removing broken markdown syntax, adding custom components to LLM output, smoothing out pauses in streamed output, rendering at native frame rate, supporting code blocks for every language with Shiki, and being headless to allow for custom styles. The library aims to enhance the user experience and flexibility when working with LLMs.
david-ai
David UI is a free and open-source collection of customizable, production-ready UI components built with Tailwind CSS. It is designed to be developer-friendly and performance-focused, streamlining the creation of modern, visually appealing interfaces to help deliver high-quality user experiences faster.
ai-cms-grapesjs
The Aimeos GrapesJS CMS extension provides a simple to use but powerful page editor for creating content pages based on extensible components. It integrates seamlessly with Laravel applications and allows users to easily manage and display CMS content. The tool also supports Google reCAPTCHA v3 for enhanced security. Users can create and customize pages with various components and manage multi-language setups effortlessly. The extension simplifies the process of creating and managing content pages, making it ideal for developers and businesses looking to enhance their website's content management capabilities.
continew-admin
Continew-admin is a responsive admin dashboard template built with Bootstrap 4. It provides a clean and intuitive user interface for managing and visualizing data in web applications. The template includes various components and widgets that can be easily customized to suit different project requirements. With Continew-admin, developers can quickly set up a professional-looking admin panel for their web applications.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.