AI tools for finetunedb
Related Tools:

FinetuneDB
FinetuneDB is an AI fine-tuning platform that allows users to easily create and manage datasets to fine-tune LLMs, evaluate outputs, and iterate on production data. It integrates with open-source and proprietary foundation models, and provides a collaborative editor for building datasets. FinetuneDB also offers a variety of features for evaluating model performance, including human and AI feedback, automated evaluations, and model metrics tracking.

Stocked
Stocked is an AI-powered stock advisory service that provides monthly stock recommendations to help investors build a portfolio that outperforms the S&P 500. The service uses machine learning models to analyze terabytes of data and identify stocks with the highest potential for growth. Stocked is designed for buy-and-hold investors who are looking to significantly grow their portfolio over long periods of time.
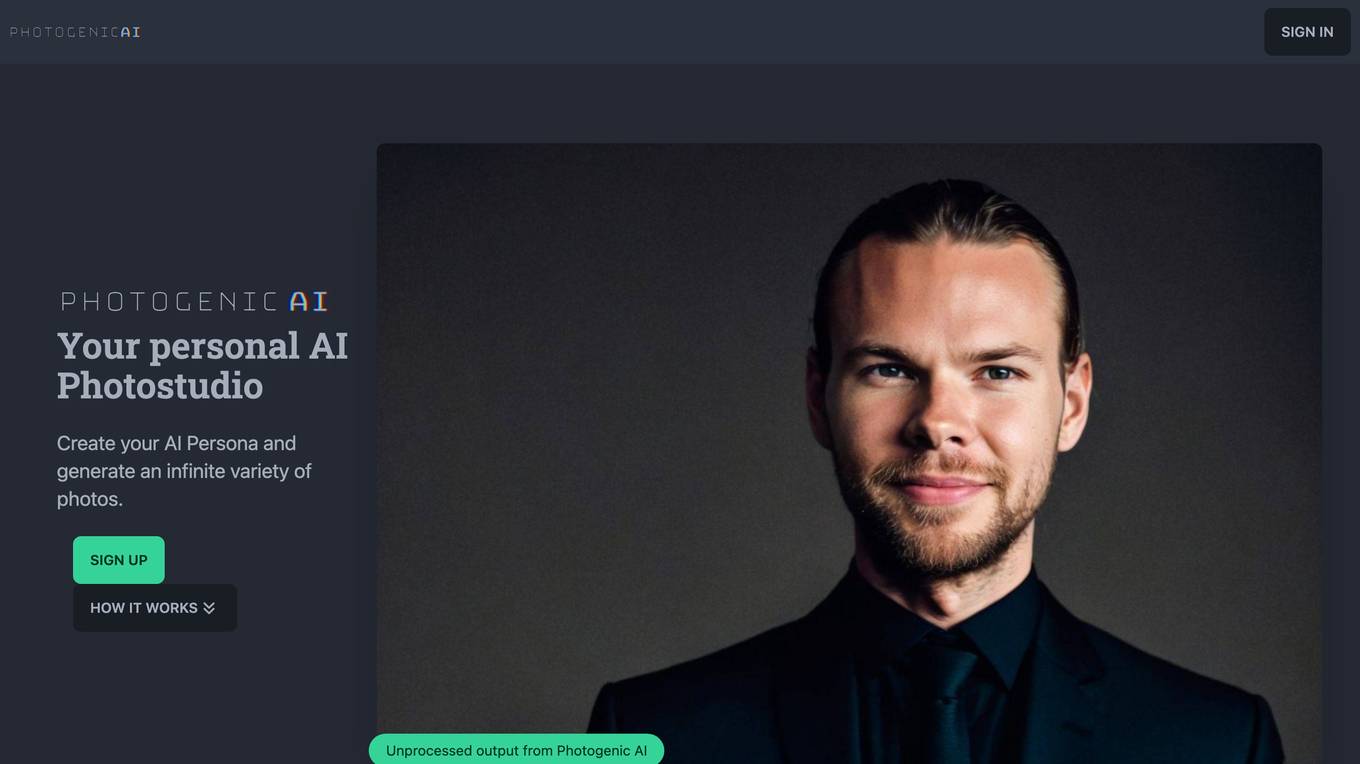
Photogenic AI
Photogenic AI is a personal AI photo studio that allows users to create an infinite variety of photos using their own AI persona. With Photogenic AI, users can take hundreds of photos, change anything they like, and have finetuned control over the results. Users can also upload photos to copy the style of any photo they like. Photogenic AI is perfect for anyone who wants to create high-quality photos for social media, marketing, or personal use.
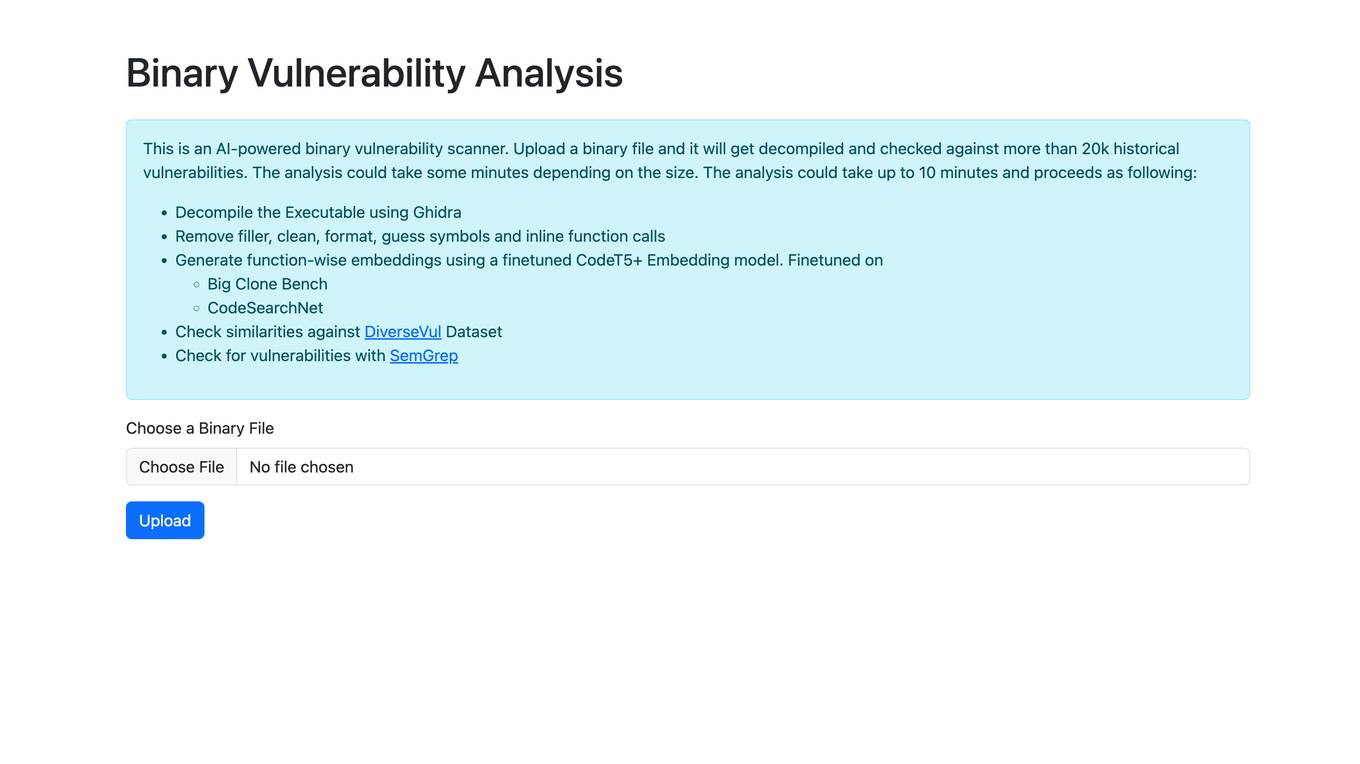
Binary Vulnerability Analysis
The website offers an AI-powered binary vulnerability scanner that allows users to upload a binary file for analysis. The tool decompiles the executable, removes filler, cleans, formats, and checks for historical vulnerabilities. It generates function-wise embeddings using a finetuned CodeT5+ Embedding model and checks for similarities against the DiverseVul Dataset. The tool also utilizes SemGrep to check for vulnerabilities in the binary file.
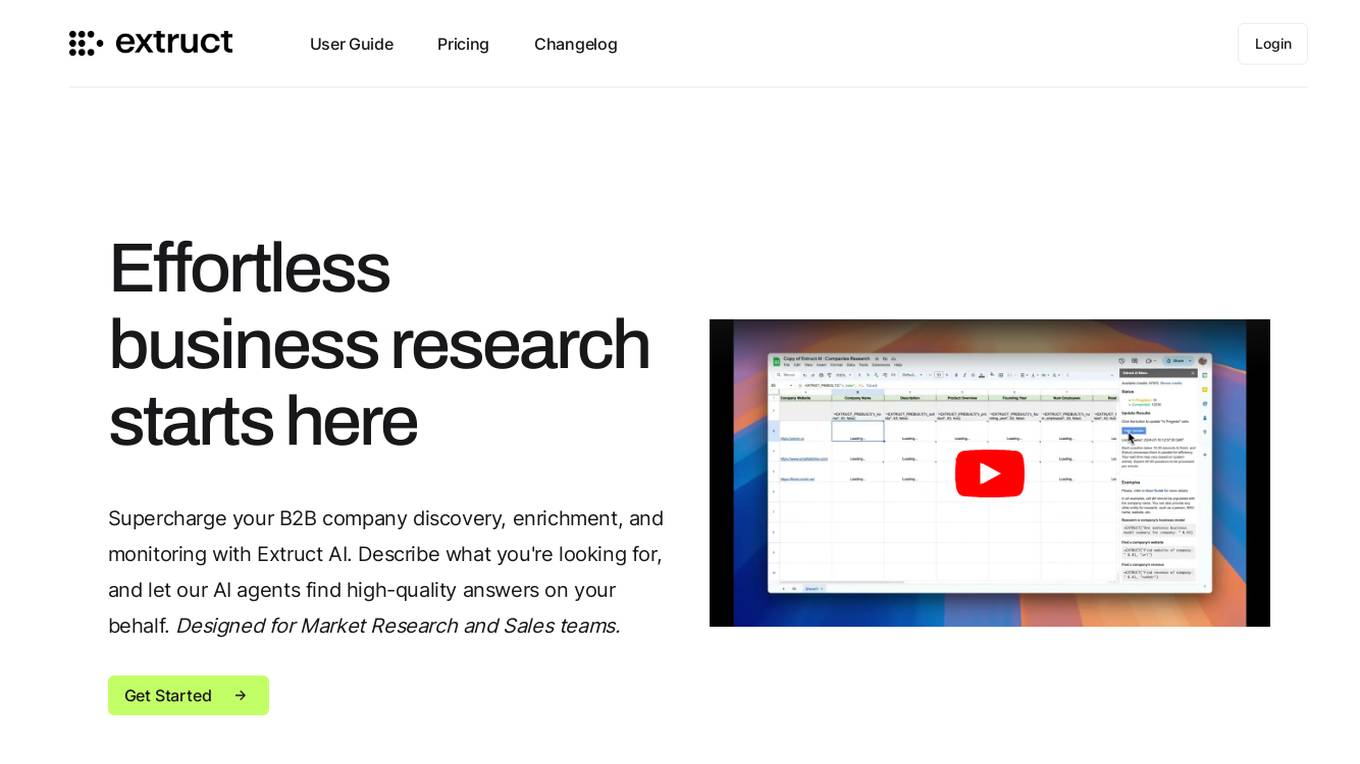
Extruct AI
Extruct AI is a Company Intelligence Platform that leverages AI technology to supercharge B2B company discovery, enrichment, and monitoring. It automates market research, lead generation, and competition analysis for Market Research and Sales teams. With autonomous AI agents, it provides high-quality answers, tailored market insights, and precise monitoring. Extruct AI offers a Company Discovery Engine, Flexible Data Enrichment, and Finetuned Models to streamline research workflows and access aggregated data sources. It ensures up-to-date data and hyper-customizable workflows for efficient business intelligence.

FinetuneFast
FinetuneFast is an AI tool designed to help developers, indie makers, and businesses to efficiently finetune machine learning models, process data, and deploy AI solutions at lightning speed. With pre-configured training scripts, efficient data loading pipelines, and one-click model deployment, FinetuneFast streamlines the process of building and deploying AI models, saving users valuable time and effort. The tool is user-friendly, accessible for ML beginners, and offers lifetime updates for continuous improvement.
FineTuneAIs.com
FineTuneAIs.com is a platform that specializes in custom AI model fine-tuning. Users can fine-tune their AI models to achieve better performance and accuracy. The platform requires JavaScript to be enabled for optimal functionality.
Sentence Transformers
Sentence Transformers is a Python module that provides access to state-of-the-art embedding and reranker models. It allows users to compute embeddings, calculate similarity scores, and generate sparse embeddings for various applications such as semantic search, semantic textual similarity, and paraphrase mining. The module offers a wide selection of pre-trained models and enables users to train or finetune their own models for specific use cases.
Contentable.ai
Contentable.ai is a platform for comparing multiple AI models, rapidly moving from prototyping to production, and management of your custom AI solutions across multiple vendors. It allows users to test multiple AI models in seconds, compare models side-by-side across top AI providers, collaborate on AI models with their team seamlessly, design complex AI workflows without coding, and pay as they go.
Secta Labs
Secta Labs is an AI-powered platform that allows users to create professional headshots and portraits from their own photos. The platform uses a variety of AI techniques to generate realistic and authentic-looking images that can be used for a variety of purposes, such as social media profiles, job applications, and marketing materials. Secta Labs is the first company in the world to offer this service, and it has been featured in Forbes, The Washington Post, and other publications.
awesome-generative-ai
A curated list of Generative AI projects, tools, artworks, and models
dodari
Dodari is a local web service that makes NHNDQ AI Korean-English/English-Korean translation easy for everyday people to use (based on Gradio).
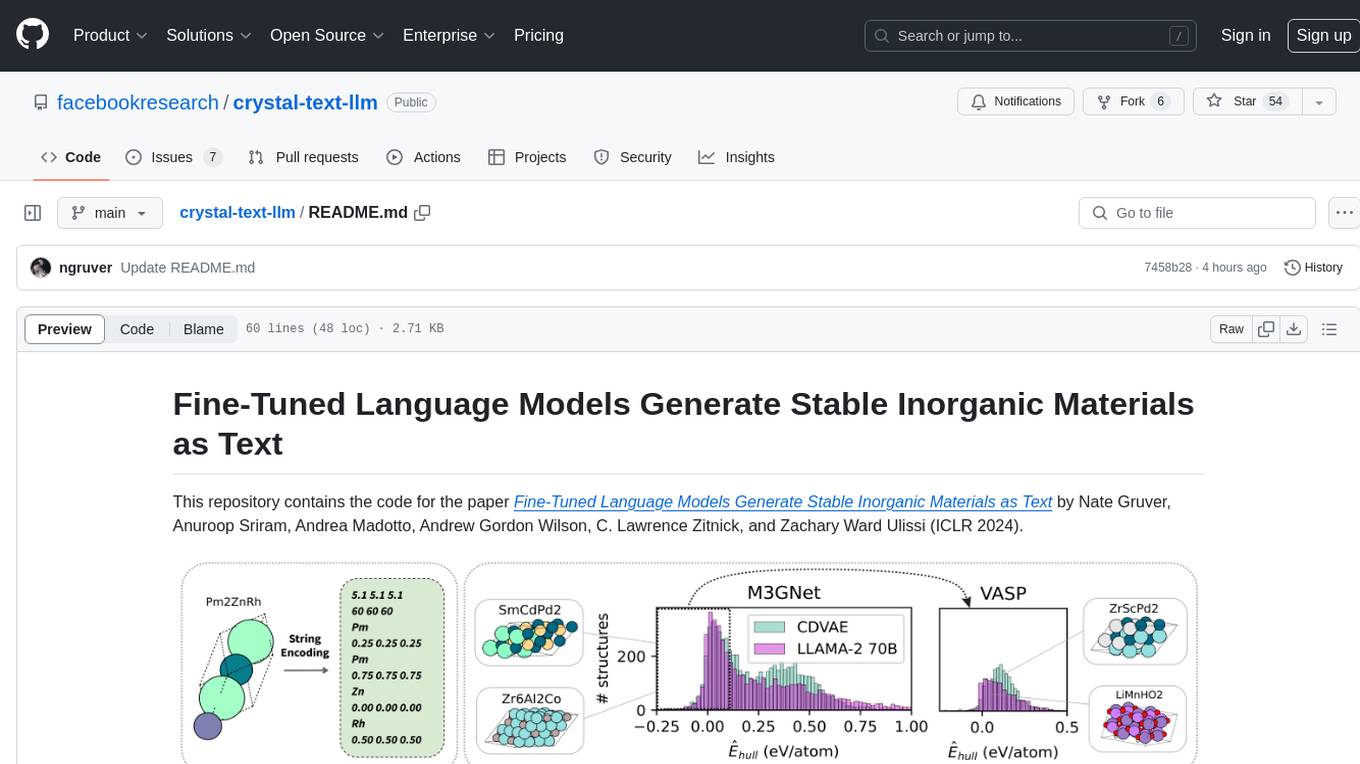
crystal-text-llm
This repository contains the code for the paper Fine-Tuned Language Models Generate Stable Inorganic Materials as Text. It demonstrates how finetuned LLMs can be used to generate stable materials, match or exceed the performance of domain specific models, mutate existing materials, and sample crystal structures conditioned on text descriptions. The method is distinct from CrystaLLM, which trains language models from scratch on CIF-formatted crystals.
LLM-Assistant
LLM-Assistant is a browser interface based on Gradio that interfaces with local LLMs to call functions and act as a general assistant. It works with any instruct-finetuned LLM, can search for information (RAG), knows when to call functions, has realtime mode for working across the system, and answers questions from PDF files. The tool aims to provide voice access and more functions in the future. Current bugs include rare crashes. Setup involves cloning the repo to a virtual environment, installing requirements, downloading and placing LLM model in the model folder, and running main.py. Usage includes Assistant mode for general chat and calling functions like playing music, as well as Realtime mode for editing documents or replying to emails in real-time.

LLaSA_training
LLaSA_training is a repository focused on training models for speech synthesis using a large amount of open-source speech data. The repository provides instructions for finetuning models and offers pre-trained models for multilingual speech synthesis. It includes tools for training, data downloading, and data processing using specialized tokenizers for text and speech sequences. The repository also supports direct usage on Hugging Face platform with specific codecs and collections.
dbrx
DBRX is a large language model trained by Databricks and made available under an open license. It is a Mixture-of-Experts (MoE) model with 132B total parameters and 36B live parameters, using 16 experts, of which 4 are active during training or inference. DBRX was pre-trained for 12T tokens of text and has a context length of 32K tokens. The model is available in two versions: a base model and an Instruct model, which is finetuned for instruction following. DBRX can be used for a variety of tasks, including text generation, question answering, summarization, and translation.
awesome-gpt-security
Awesome GPT + Security is a curated list of awesome security tools, experimental case or other interesting things with LLM or GPT. It includes tools for integrated security, auditing, reconnaissance, offensive security, detecting security issues, preventing security breaches, social engineering, reverse engineering, investigating security incidents, fixing security vulnerabilities, assessing security posture, and more. The list also includes experimental cases, academic research, blogs, and fun projects related to GPT security. Additionally, it provides resources on GPT security standards, bypassing security policies, bug bounty programs, cracking GPT APIs, and plugin security.
chatglm.cpp
ChatGLM.cpp is a C++ implementation of ChatGLM-6B, ChatGLM2-6B, ChatGLM3-6B and more LLMs for real-time chatting on your MacBook. It is based on ggml, working in the same way as llama.cpp. ChatGLM.cpp features accelerated memory-efficient CPU inference with int4/int8 quantization, optimized KV cache and parallel computing. It also supports P-Tuning v2 and LoRA finetuned models, streaming generation with typewriter effect, Python binding, web demo, api servers and more possibilities.
ai-clone-whatsapp
This repository provides a tool to create an AI chatbot clone of yourself using your WhatsApp chats as training data. It utilizes the Torchtune library for finetuning and inference. The code includes preprocessing of WhatsApp chats, finetuning models, and chatting with the AI clone via a command-line interface. Supported models are Llama3-8B-Instruct and Mistral-7B-Instruct-v0.2. Hardware requirements include approximately 16 GB vRAM for QLoRa Llama3 finetuning with a 4k context length. The repository addresses common issues like adjusting parameters for training and preprocessing non-English chats.

starcoder2-self-align
StarCoder2-Instruct is an open-source pipeline that introduces StarCoder2-15B-Instruct-v0.1, a self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. It generates instruction-response pairs to fine-tune StarCoder-15B without human annotations or data from proprietary LLMs. The tool is primarily finetuned for Python code generation tasks that can be verified through execution, with potential biases and limitations. Users can provide response prefixes or one-shot examples to guide the model's output. The model may have limitations with other programming languages and out-of-domain coding tasks.

LLM-for-Healthcare
The repository 'LLM-for-Healthcare' provides a comprehensive survey of large language models (LLMs) for healthcare, covering data, technology, applications, and accountability and ethics. It includes information on various LLM models, training data, evaluation methods, and computation costs. The repository also discusses tasks such as NER, text classification, question answering, dialogue systems, and generation of medical reports from images in the healthcare domain.
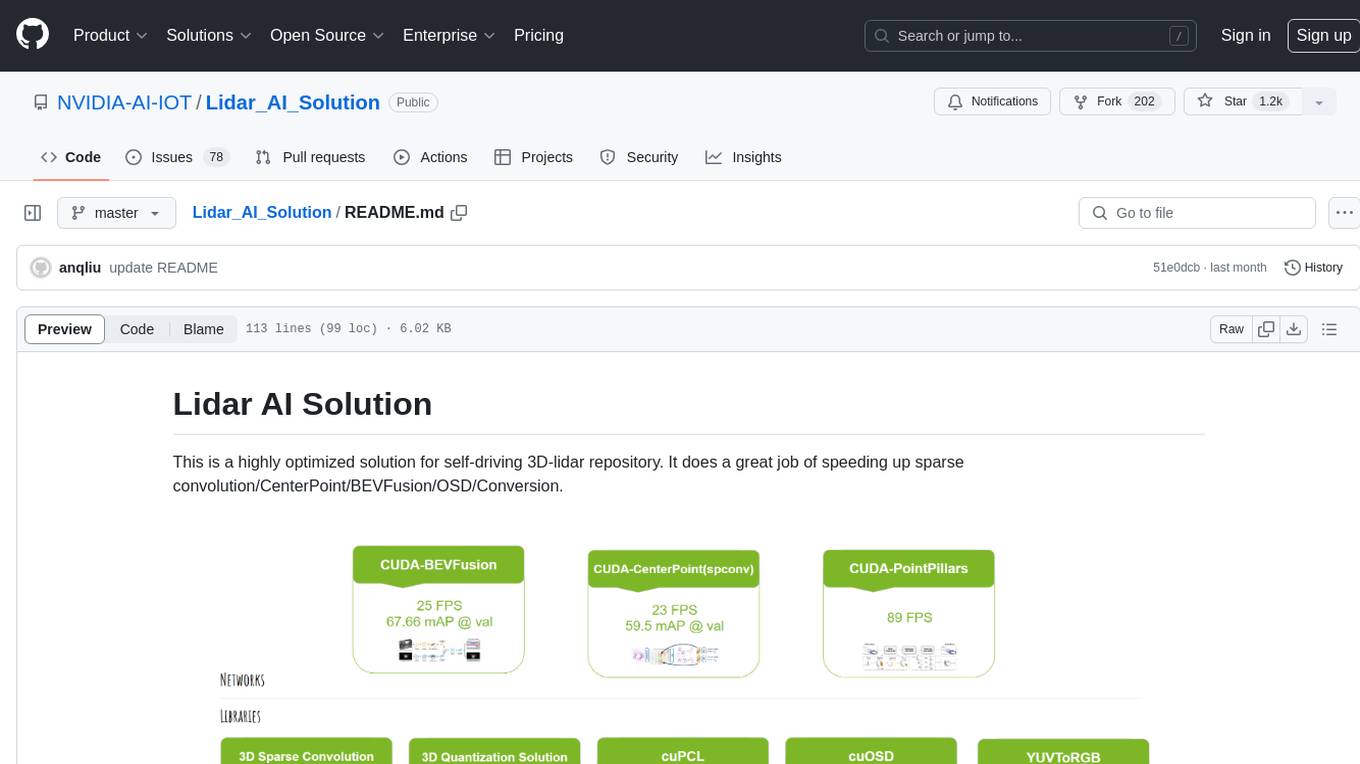
Lidar_AI_Solution
Lidar AI Solution is a highly optimized repository for self-driving 3D lidar, providing solutions for sparse convolution, BEVFusion, CenterPoint, OSD, and Conversion. It includes CUDA and TensorRT implementations for various tasks such as 3D sparse convolution, BEVFusion, CenterPoint, PointPillars, V2XFusion, cuOSD, cuPCL, and YUV to RGB conversion. The repository offers easy-to-use solutions, high accuracy, low memory usage, and quantization options for different tasks related to self-driving technology.

LLMGA
LLMGA (Multimodal Large Language Model-based Generation Assistant) is a tool that leverages Large Language Models (LLMs) to assist users in image generation and editing. It provides detailed language generation prompts for precise control over Stable Diffusion (SD), resulting in more intricate and precise content in generated images. The tool curates a dataset for prompt refinement, similar image generation, inpainting & outpainting, and visual question answering. It offers a two-stage training scheme to optimize SD alignment and a reference-based restoration network to alleviate texture, brightness, and contrast disparities in image editing. LLMGA shows promising generative capabilities and enables wider applications in an interactive manner.
shared_colab_notebooks
This repository serves as a collection of Google Colaboratory Notebooks for various tasks in Natural Language Processing (NLP), Natural Language Generation (NLG), Computer Vision, Generative Adversarial Networks (GANs), Streamlit applications, tutorials, UI/UX experiments, and other miscellaneous projects. It includes a wide range of pre-trained models, fine-tuning examples, and demos for tasks such as text generation, image processing, and more. The notebooks cover topics like self-attention, language model finetuning, emotion detection, image inpainting, and streamlit app creation. Users can explore different models, datasets, and techniques through these shared notebooks.
FireRedTTS
FireRedTTS is a foundation text-to-speech framework designed for industry-level generative speech applications. It offers a rich-punctuation model with expanded punctuation coverage and enhanced audio production consistency. The tool provides pre-trained checkpoints, inference code, and an interactive demo space. Users can clone the repository, create a conda environment, download required model files, and utilize the tool for synthesizing speech in various languages. FireRedTTS aims to enhance stability and provide controllable human-like speech generation capabilities.

olmocr
olmOCR is a toolkit designed for training language models to work with PDF documents in real-world scenarios. It includes various components such as a prompting strategy for natural text parsing, an evaluation toolkit for comparing pipeline versions, filtering by language and SEO spam removal, finetuning code for specific models, processing PDFs through a finetuned model, and viewing documents created from PDFs. The toolkit requires a recent NVIDIA GPU with at least 20 GB of RAM and 30GB of free disk space. Users can install dependencies, set up a conda environment, and utilize olmOCR for tasks like converting single or multiple PDFs, viewing extracted text, and running batch inference pipelines.

lloco
LLoCO is a technique that learns documents offline through context compression and in-domain parameter-efficient finetuning using LoRA, which enables LLMs to handle long context efficiently.
unsloth
Unsloth is a tool that allows users to fine-tune large language models (LLMs) 2-5x faster with 80% less memory. It is a free and open-source tool that can be used to fine-tune LLMs such as Gemma, Mistral, Llama 2-5, TinyLlama, and CodeLlama 34b. Unsloth supports 4-bit and 16-bit QLoRA / LoRA fine-tuning via bitsandbytes. It also supports DPO (Direct Preference Optimization), PPO, and Reward Modelling. Unsloth is compatible with Hugging Face's TRL, Trainer, Seq2SeqTrainer, and Pytorch code. It is also compatible with NVIDIA GPUs since 2018+ (minimum CUDA Capability 7.0).

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.

Awesome-LLM-Eval
Awesome-LLM-Eval: a curated list of tools, benchmarks, demos, papers for Large Language Models (like ChatGPT, LLaMA, GLM, Baichuan, etc) Evaluation on Language capabilities, Knowledge, Reasoning, Fairness and Safety.