
agent-q
agent q - oss advanced reasoning and learning for autonomous ai agents
Stars: 98
Agentq is a tool that utilizes various agentic architectures to complete tasks on the web reliably. It includes a planner-navigator multi-agent architecture, a solo planner-actor agent, an actor-critic multi-agent architecture, and an actor-critic architecture with reinforcement learning and DPO finetuning. The repository also contains an open-source implementation of the research paper 'Agent Q'. Users can set up the tool by installing dependencies, starting Chrome in dev mode, and setting up necessary environment variables. The tool can be run to perform various tasks related to autonomous AI agents.
README:
agentq utilises various kinds of agentic architectures to complete a task on the web reliably. it has
1. a planner <> navigator multi-agent architecutre
2. a solo planner-actor agent
3. an actor <> critic multi-agent architecture
4. actor <> critic architecture + monte carlo tree search based reinforcement learning + dpo finetuning
this repo also contains an oss implementation of the research paper agent q - thus the name.
-
we recommend installing poetry before proceeding with the next steps. you can install poetry using these instructions
-
install dependencies
poetry install- start chrome in dev mode - in a seaparate terminal, use the command to start a chrome instance and do necesssary logins to job websites like linkedin/ wellfound, etc.
for mac, use command -
sudo /Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --remote-debugging-port=9222for linux -
google-chrome --remote-debugging-port=9222for windows -
"C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222-
set up env - add openai and langfuse keys to .env file. you can refer .env.example. currently adding langfuse is required. If you do not want tracing - then you can do the following changes
- directly import open ai client via
import openairather thanfrom langfuse.openai import openaiin the./agentq/core/agent/base.pyfile. - you would also have to comment out the @obseve decorator and the below piece of code from the
runfunction in the same file
langfuse_context.update_current_trace( name=self.agnet_name, session_id=session_id )
- directly import open ai client via
-
run the agent
python -u -m agentq python -m test.tests_processor --orchestrator_type fsmpython -m agentq.core.mcts.browser_mctsa bunch of amazing work in the space has inspired this.
@misc{putta2024agentqadvancedreasoning,
title={Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents},
author={Pranav Putta and Edmund Mills and Naman Garg and Sumeet Motwani and Chelsea Finn and Divyansh Garg and Rafael Rafailov},
year={2024},
eprint={2408.07199},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2408.07199},
}
@inproceedings{yao2022webshop,
bibtex_show = {true},
title = {WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents},
author = {Yao, Shunyu and Chen, Howard and Yang, John and Narasimhan, Karthik},
booktitle = {ArXiv},
year = {preprint},
html = {https://arxiv.org/abs/2207.01206},
tag = {NLP}
}
@article{he2024webvoyager,
title={WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models},
author={He, Hongliang and Yao, Wenlin and Ma, Kaixin and Yu, Wenhao and Dai, Yong and Zhang, Hongming and Lan, Zhenzhong and Yu, Dong},
journal={arXiv preprint arXiv:2401.13919},
year={2024}
}
@misc{abuelsaad2024-agente,
title={Agent-E: From Autonomous Web Navigation to Foundational Design Principles in Agentic Systems},
author={Tamer Abuelsaad and Deepak Akkil and Prasenjit Dey and Ashish Jagmohan and Aditya Vempaty and Ravi Kokku},
year={2024},
eprint={2407.13032},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2407.13032},
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for agent-q
Similar Open Source Tools
agent-q
Agentq is a tool that utilizes various agentic architectures to complete tasks on the web reliably. It includes a planner-navigator multi-agent architecture, a solo planner-actor agent, an actor-critic multi-agent architecture, and an actor-critic architecture with reinforcement learning and DPO finetuning. The repository also contains an open-source implementation of the research paper 'Agent Q'. Users can set up the tool by installing dependencies, starting Chrome in dev mode, and setting up necessary environment variables. The tool can be run to perform various tasks related to autonomous AI agents.

web-llm
WebLLM is a modular and customizable javascript package that directly brings language model chats directly onto web browsers with hardware acceleration. Everything runs inside the browser with no server support and is accelerated with WebGPU. WebLLM is fully compatible with OpenAI API. That is, you can use the same OpenAI API on any open source models locally, with functionalities including json-mode, function-calling, streaming, etc. We can bring a lot of fun opportunities to build AI assistants for everyone and enable privacy while enjoying GPU acceleration.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.

oasis
OASIS is a scalable, open-source social media simulator that integrates large language models with rule-based agents to realistically mimic the behavior of up to one million users on platforms like Twitter and Reddit. It facilitates the study of complex social phenomena such as information spread, group polarization, and herd behavior, offering a versatile tool for exploring diverse social dynamics and user interactions in digital environments. With features like scalability, dynamic environments, diverse action spaces, and integrated recommendation systems, OASIS provides a comprehensive platform for simulating social media interactions at a large scale.

1backend
1Backend is a flexible and scalable platform designed for running AI models on private servers and handling high-concurrency workloads. It provides a ChatGPT-like interface for users and a network-accessible API for machines, serving as a general-purpose backend framework. The platform offers on-premise ChatGPT alternatives, a microservices-first web framework, out-of-the-box services like file uploads and user management, infrastructure simplification acting as a container orchestrator, reverse proxy, multi-database support with its own ORM, and AI integration with platforms like LlamaCpp and StableDiffusion.
Autono
A highly robust autonomous agent framework based on the ReAct paradigm, designed for adaptive decision making and multi-agent collaboration. It dynamically generates next actions during agent execution, enhancing robustness. Features a timely abandonment strategy and memory transfer mechanism for multi-agent collaboration. The framework allows developers to balance conservative and exploratory tendencies in agent execution strategies, improving adaptability and task execution efficiency in complex environments. Supports external tool integration, modular design, and MCP protocol compatibility for flexible action space expansion. Multi-agent collaboration mechanism enables agents to focus on specific task components, improving execution efficiency and quality.
openorch
OpenOrch is a daemon that transforms servers into a powerful development environment, running AI models, containers, and microservices. It serves as a blend of Kubernetes and a language-agnostic backend framework for building applications on fixed-resource setups. Users can deploy AI models and build microservices, managing applications while retaining control over infrastructure and data.
fabrice-ai
A lightweight, functional, and composable framework for building AI agents that work together to solve complex tasks. Built with TypeScript and designed to be serverless-ready. Fabrice embraces functional programming principles, remains stateless, and stays focused on composability. It provides core concepts like easy teamwork creation, infrastructure-agnosticism, statelessness, and includes all tools and features needed to build AI teams. Agents are specialized workers with specific roles and capabilities, able to call tools and complete tasks. Workflows define how agents collaborate to achieve a goal, with workflow states representing the current state of the workflow. Providers handle requests to the LLM and responses. Tools extend agent capabilities by providing concrete actions they can perform. Execution involves running the workflow to completion, with options for custom execution and BDD testing.
Search-R1
Search-R1 is a tool that trains large language models (LLMs) to reason and call a search engine using reinforcement learning. It is a reproduction of DeepSeek-R1 methods for training reasoning and searching interleaved LLMs, built upon veRL. Through rule-based outcome reward, the base LLM develops reasoning and search engine calling abilities independently. Users can train LLMs on their own datasets and search engines, with preliminary results showing improved performance in search engine calling and reasoning tasks.

allms
allms is a versatile and powerful library designed to streamline the process of querying Large Language Models (LLMs). Developed by Allegro engineers, it simplifies working with LLM applications by providing a user-friendly interface, asynchronous querying, automatic retrying mechanism, error handling, and output parsing. It supports various LLM families hosted on different platforms like OpenAI, Google, Azure, and GCP. The library offers features for configuring endpoint credentials, batch querying with symbolic variables, and forcing structured output format. It also provides documentation, quickstart guides, and instructions for local development, testing, updating documentation, and making new releases.
ell
ell is a lightweight, functional prompt engineering framework that treats prompts as programs rather than strings. It provides tools for prompt versioning, monitoring, and visualization, as well as support for multimodal inputs and outputs. The framework aims to simplify the process of prompt engineering for language models.

langchain
LangChain is a framework for developing Elixir applications powered by language models. It enables applications to connect language models to other data sources and interact with the environment. The library provides components for working with language models and off-the-shelf chains for specific tasks. It aims to assist in building applications that combine large language models with other sources of computation or knowledge. LangChain is written in Elixir and is not aimed for parity with the JavaScript and Python versions due to differences in programming paradigms and design choices. The library is designed to make it easy to integrate language models into applications and expose features, data, and functionality to the models.
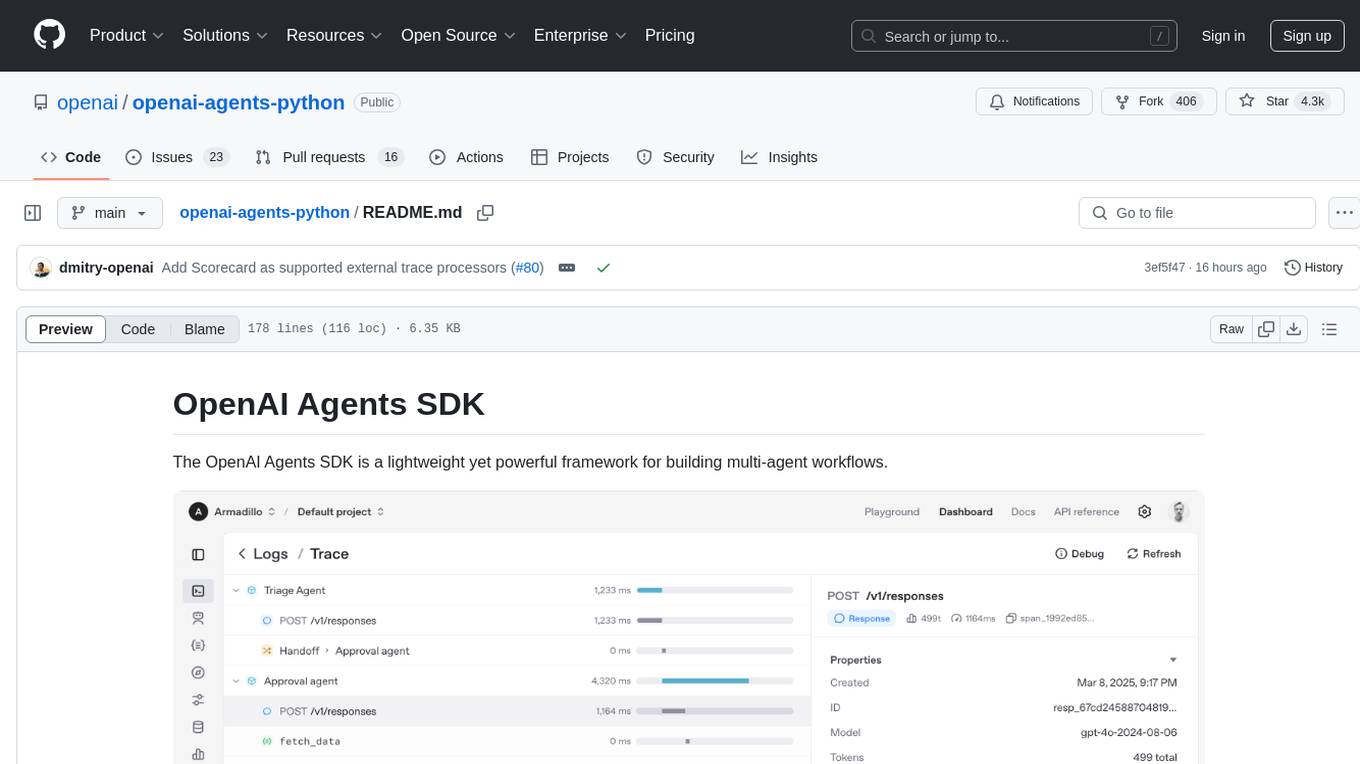
openai-agents-python
The OpenAI Agents SDK is a lightweight framework for building multi-agent workflows. It includes concepts like Agents, Handoffs, Guardrails, and Tracing to facilitate the creation and management of agents. The SDK is compatible with any model providers supporting the OpenAI Chat Completions API format. It offers flexibility in modeling various LLM workflows and provides automatic tracing for easy tracking and debugging of agent behavior. The SDK is designed for developers to create deterministic flows, iterative loops, and more complex workflows.

LeanCopilot
Lean Copilot is a tool that enables the use of large language models (LLMs) in Lean for proof automation. It provides features such as suggesting tactics/premises, searching for proofs, and running inference of LLMs. Users can utilize built-in models from LeanDojo or bring their own models to run locally or on the cloud. The tool supports platforms like Linux, macOS, and Windows WSL, with optional CUDA and cuDNN for GPU acceleration. Advanced users can customize behavior using Tactic APIs and Model APIs. Lean Copilot also allows users to bring their own models through ExternalGenerator or ExternalEncoder. The tool comes with caveats such as occasional crashes and issues with premise selection and proof search. Users can get in touch through GitHub Discussions for questions, bug reports, feature requests, and suggestions. The tool is designed to enhance theorem proving in Lean using LLMs.
experts
Experts.js is a tool that simplifies the creation and deployment of OpenAI's Assistants, allowing users to link them together as Tools to create a Panel of Experts system with expanded memory and attention to detail. It leverages the new Assistants API from OpenAI, which offers advanced features such as referencing attached files & images as knowledge sources, supporting instructions up to 256,000 characters, integrating with 128 tools, and utilizing the Vector Store API for efficient file search. Experts.js introduces Assistants as Tools, enabling the creation of Multi AI Agent Systems where each Tool is an LLM-backed Assistant that can take on specialized roles or fulfill complex tasks.

uzu
uzu is a high-performance inference engine for AI models on Apple Silicon. It features a simple, high-level API, hybrid architecture for GPU kernel computation, unified model configurations, traceable computations, and utilizes unified memory on Apple devices. The tool provides a CLI mode for running models, supports its own model format, and offers prebuilt Swift and TypeScript frameworks for bindings. Users can quickly start by adding the uzu dependency to their Cargo.toml and creating an inference Session with a specific model and configuration. Performance benchmarks show metrics for various models on Apple M2, highlighting the tokens/s speed for each model compared to llama.cpp with bf16/f16 precision.
For similar tasks
agent-q
Agentq is a tool that utilizes various agentic architectures to complete tasks on the web reliably. It includes a planner-navigator multi-agent architecture, a solo planner-actor agent, an actor-critic multi-agent architecture, and an actor-critic architecture with reinforcement learning and DPO finetuning. The repository also contains an open-source implementation of the research paper 'Agent Q'. Users can set up the tool by installing dependencies, starting Chrome in dev mode, and setting up necessary environment variables. The tool can be run to perform various tasks related to autonomous AI agents.

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern
fuji-web
Fuji-Web is an intelligent AI partner designed for full browser automation. It autonomously navigates websites and performs tasks on behalf of the user while providing explanations for each action step. Users can easily install the extension in their browser, access the Fuji icon to input tasks, and interact with the tool to streamline web browsing tasks. The tool aims to enhance user productivity by automating repetitive web actions and providing a seamless browsing experience.
chatflow
Chatflow is a tool that provides a chat interface for users to interact with systems using natural language. The engine understands user intent and executes commands for tasks, allowing easy navigation of complex websites/products. This approach enhances user experience, reduces training costs, and boosts productivity.
J.A.R.V.I.S
J.A.R.V.I.S (Just A Rather Very Intelligent System) is an advanced AI assistant inspired by Iron Man's Jarvis, designed to assist with various tasks, from navigating websites to controlling your PC with natural language commands.

weblinx
WebLINX is a Python library and dataset for real-world website navigation with multi-turn dialogue. The repository provides code for training models reported in the WebLINX paper, along with a comprehensive API to work with the dataset. It includes modules for data processing, model evaluation, and utility functions. The modeling directory contains code for processing, training, and evaluating models such as DMR, LLaMA, MindAct, Pix2Act, and Flan-T5. Users can install specific dependencies for HTML processing, video processing, model evaluation, and library development. The evaluation module provides metrics and functions for evaluating models, with ongoing work to improve documentation and functionality.
cerebellum
Cerebellum is a lightweight browser agent that helps users accomplish user-defined goals on webpages through keyboard and mouse actions. It simplifies web browsing by treating it as navigating a directed graph, with each webpage as a node and user actions as edges. The tool uses a LLM to analyze page content and interactive elements to determine the next action. It is compatible with any Selenium-supported browser and can fill forms using user-provided JSON data. Cerebellum accepts runtime instructions to adjust browsing strategies and actions dynamically.
notte
Notte is a web browser designed specifically for LLM agents, providing a language-first web navigation experience without the need for DOM/HTML parsing. It transforms websites into structured, navigable maps described in natural language, enabling users to interact with the web using natural language commands. By simplifying browser complexity, Notte allows LLM policies to focus on conversational reasoning and planning, reducing token usage, costs, and latency. The tool supports various language model providers and offers a reinforcement learning style action space and controls for full navigation control.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.