
MyScaleDB
An open-source, high-performance SQL vector database built on ClickHouse.
Stars: 689
MyScaleDB is a SQL vector database optimized for AI applications, enabling developers to manage and process massive volumes of data efficiently. It offers fast and powerful vector search, filtered search, and SQL-vector join queries, making it fully SQL-compatible. MyScaleDB provides unmatched performance and scalability by leveraging cutting-edge OLAP database architecture and advanced vector algorithms. It is production-ready for AI applications, supporting structured data, text, vector, JSON, geospatial, and time-series data. MyScale Cloud offers fully-managed MyScaleDB with premium features on billion-scale data, making it cost-effective and simpler to use compared to specialized vector databases. Built on top of ClickHouse, MyScaleDB combines structured and vector search efficiently, ensuring high accuracy and performance in filtered search operations.
README:


Enable every developer to build production-grade GenAI applications with powerful and familiar SQL.
MyScaleDB is the SQL vector database that enables developers to build production-ready and scalable AI applications using familiar SQL. It is built on top of ClickHouse and optimized for AI applications and solutions, allowing developers to effectively manage and process massive volumes of data.
Key benefits of using MyScaleDB include:
-
Fully SQL-Compatible
- Fast, powerful, and efficient vector search, filtered search, and SQL-vector join queries.
- Use SQL with vector-related functions to interact with MyScaleDB. No need to learn complex new tools or frameworks – stick with what you know and love.
-
Production-Ready for AI applications
- A unified and time-tested platform to manage and process structured data, text, vector, JSON, geospatial, time-series data, and more. See supported data types and functions
- Improved RAG accuracy by combining vectors with rich metadata, full-text search, and performing high-precision, high-efficiency filtered search at any ratio1.
-
Unmatched performance and scalability
- MyScaleDB leverages cutting-edge OLAP database architecture and advanced vector algorithms for lightning-fast vector operations.
- Scale your applications effortlessly and cost-effectively as your data grows.
MyScale Cloud provides fully-managed MyScaleDB with premium features on billion-scale data2. Compared with specialized vector databases that use custom APIs, MyScale is more powerful, performant, and cost-effective while remaining simpler to use. This makes it suitable for a large community of programmers. Additionally, when compared to integrated vector databases like PostgreSQL with pgvector or ElasticSearch with vector extensions, MyScale consumes fewer resources and achieves better accuracy and speed for structured and vector joint queries, such as filtered searches.
- Fully SQL compatible
- Unified structured and vectorized data management
- Millisecond search on billion-scale vectors
- Highly reliable & linearly scalable
- Powerful text-search and text/vector hybrid search functions
- Complex SQL vector queries
See our documentation and blogs for more about MyScale’s unique features and advantages. Our open-source benchmark provides detailed comparison with other vector database products.
ClickHouse is a popular open-source analytical database that excels at big data processing and analytics due to its columnar storage with advanced compression, skip indexing, and SIMD processing. Unlike transactional databases like PostgreSQL and MySQL, which use row storage and main optimzies for transactional processing, ClickHouse has significantly faster analytical and data scanning speeds.
One of the key operations in combining structured and vector search is filtered search, which involves filtering by other attributes first and then performing vector search on the remaining data. Columnar storage and pre-filtering are crucial for ensuring high accuracy and high performance in filtered search, which is why we chose to build MyScaleDB on top of ClickHouse.
While we have modified ClickHouse's execution and storage engine in many ways to ensure fast and cost-effective SQL vector queries, many of the features (#37893, #38048, #37859, #56728, #58223) related to general SQL processing have been contributed back to the ClickHouse open source community.
The simplest way to use MyScaleDB is to create an instance on MyScale Cloud service. You can start from a free pod supporting 5M 768D vectors. Sign up here and checkout MyScaleDB QuickStart for more instructions.
To quickly get a MyScaleDB instance up and running, simply pull and run the latest Docker image:
docker run --name myscaledb --net=host myscale/myscaledb:1.5Note: Myscale's default configuration only allows localhost ip access. For the docker run startup method, you need to specify
--net=hostto access services deployed in docker mode on the current node.
This will start a MyScaleDB instance with default user default and no password. You can then connect to the database using clickhouse-client:
docker exec -it myscaledb clickhouse-client- Use the following recommended directory structure and the location of the
docker-compose.yamlfile:
> tree myscaledb
myscaledb
├── docker-compose.yaml
└── volumes
└── config
└── users.d
└── custom_users_config.xml
3 directories, 2 files- Define the configuration for your deployment. We recommend starting with the following configuration in your
docker-compose.yamlfile, which you can adjust based on your specific requirements:
version: '3.7'
services:
myscaledb:
image: myscale/myscaledb:1.5
tty: true
ports:
- '8123:8123'
- '9000:9000'
- '8998:8998'
- '9363:9363'
- '9116:9116'
networks:
myscaledb_network:
ipv4_address: 10.0.0.2
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/data:/var/lib/clickhouse
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/log:/var/log/clickhouse-server
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/config/users.d/custom_users_config.xml:/etc/clickhouse-server/users.d/custom_users_config.xml
deploy:
resources:
limits:
cpus: "16.00"
memory: 32Gb
networks:
myscaledb_network:
driver: bridge
ipam:
driver: default
config:
- subnet: 10.0.0.0/24custom_users_config.xml:
<clickhouse>
<users>
<default>
<password></password>
<networks>
<ip>::1</ip>
<ip>127.0.0.1</ip>
<ip>10.0.0.0/24</ip>
</networks>
<profile>default</profile>
<quota>default</quota>
<access_management>1</access_management>
</default>
</users>
</clickhouse>Note: The custom_users_config configuration allows you to use the default user to access the database on the node where the database service is deployed using docker compose. If you want to access the database service on other nodes, it is recommended to create a user that can be accessed through other IPs. For detailed settings, see: MyScaleDB Create User. You can also customize the configuration file of MyScaleDB. Copy the
/etc/clickhouse-serverdirectory from yourmyscaledbcontainer to your local drive, modify the configuration, and add a directory mapping to thedocker-compose.yamlfile to make the configuration take effect:- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/config:/etc/clickhouse-server
- Use the following command to get it running:
cd myscaledb
docker compose up -d- Access the MyScaleDB command line interface using the following command.
docker exec -it myscaledb-myscaledb-1 clickhouse-client- You can now run SQL statements. See Executing SQL Queries.
See Vector Search Documentation for how to create a SQL table with vector index and perform vector search. It's recommended to specify TYPE SCANN when creating a vector index in open source MyScaleDB.
-- Create a table with body_vector of length 384
CREATE TABLE default.wiki_abstract
(
`id` UInt64,
`body` String,
`title` String,
`url` String,
`body_vector` Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 384
)
ENGINE = MergeTree
ORDER BY id;-- Insert data from parquet files on S3
INSERT INTO default.wiki_abstract SELECT * FROM s3('https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/wiki_abstract_with_vector.parquet','Parquet');-- Build a SCANN vector index with Cosine metric on the body_vector
ALTER TABLE default.wiki_abstract ADD VECTOR INDEX vec_idx body_vector TYPE SCANN('metric_type=Cosine');
-- Query the index build progress from the `vector_indices` table
-- Wait until the index progress becomes `Built`
SELECT * FROM system.vector_indices;-- Perform vector search return the top-5 results
SELECT
id,
title,
distance(body_vector, [-0.052, -0.0146, -0.0677, -0.0256, -0.0395, -0.0381, -0.025, 0.0911, -0.0429, -0.0592, 0.0017, -0.0358, -0.0464, -0.0189, -0.0192, 0.0544, -0.0022, -0.0292, -0.0474, -0.0286, 0.0746, -0.013, -0.0217, -0.0246, -0.0169, 0.0495, -0.0947, 0.0139, 0.0445, -0.0262, -0.0049, 0.0506, 0.004, 0.0276, 0.0063, -0.0643, 0.0059, -0.0229, -0.0315, 0.0549, 0.1427, 0.0079, 0.011, -0.0036, -0.0617, 0.0155, -0.0607, 0.0258, -0.0205, 0.0008, -0.0547, 0.0329, -0.0522, -0.0347, 0.0921, 0.0139, -0.013, 0.0716, -0.0165, 0.0257, -0.0071, 0.0084, -0.0653, 0.0091, 0.0544, -0.0192, -0.0169, -0.0017, -0.0304, 0.0427, -0.0389, 0.0921, -0.0622, -0.0196, 0.0025, 0.0214, 0.0259, -0.0493, -0.0211, -0.119, -0.0736, -0.1545, -0.0578, -0.0145, 0.0138, 0.0478, -0.0451, -0.0332, 0.0799, 0.0001, -0.0737, 0.0427, 0.0517, 0.0102, 0.0386, 0.0233, 0.0425, -0.0279, -0.0529, 0.0744, -0.0305, -0.026, 0.1229, -0.002, 0.0038, -0.0491, 0.0352, 0.0027, -0.056, -0.1044, 0.123, -0.0184, 0.1148, -0.0189, 0.0412, -0.0347, -0.0569, -0.0119, 0.0098, -0.0016, 0.0451, 0.0273, 0.0436, 0.0082, 0.0166, -0.0989, 0.0747, -0.0, 0.0306, -0.0717, -0.007, 0.0665, 0.0452, 0.0123, -0.0238, 0.0512, -0.0116, 0.0517, 0.0288, -0.0013, 0.0176, 0.0762, 0.1284, -0.031, 0.0891, -0.0286, 0.0132, 0.003, 0.0433, 0.0102, -0.0209, -0.0459, -0.0312, -0.0387, 0.0201, -0.027, 0.0243, 0.0713, 0.0359, -0.0674, -0.0747, -0.0147, 0.0489, -0.0092, -0.018, 0.0236, 0.0372, -0.0071, -0.0513, -0.0396, -0.0316, -0.0297, -0.0385, -0.062, 0.0465, 0.0539, -0.033, 0.0643, 0.061, 0.0062, 0.0245, 0.0868, 0.0523, -0.0253, 0.0157, 0.0266, 0.0124, 0.1382, -0.0107, 0.0835, -0.1057, -0.0188, -0.0786, 0.057, 0.0707, -0.0185, 0.0708, 0.0189, -0.0374, -0.0484, 0.0089, 0.0247, 0.0255, -0.0118, 0.0739, 0.0114, -0.0448, -0.016, -0.0836, 0.0107, 0.0067, -0.0535, -0.0186, -0.0042, 0.0582, -0.0731, -0.0593, 0.0299, 0.0004, -0.0299, 0.0128, -0.0549, 0.0493, 0.0, -0.0419, 0.0549, -0.0315, 0.1012, 0.0459, -0.0628, 0.0417, -0.0153, 0.0471, -0.0301, -0.0615, 0.0137, -0.0219, 0.0735, 0.083, 0.0114, -0.0326, -0.0272, 0.0642, -0.0203, 0.0557, -0.0579, 0.0883, 0.0719, 0.0007, 0.0598, -0.0431, -0.0189, -0.0593, -0.0334, 0.02, -0.0371, -0.0441, 0.0407, -0.0805, 0.0058, 0.1039, 0.0534, 0.0495, -0.0325, 0.0782, -0.0403, 0.0108, -0.0068, -0.0525, 0.0801, 0.0256, -0.0183, -0.0619, -0.0063, -0.0605, 0.0377, -0.0281, -0.0097, -0.0029, -0.106, 0.0465, -0.0033, -0.0308, 0.0357, 0.0156, -0.0406, -0.0308, 0.0013, 0.0458, 0.0231, 0.0207, -0.0828, -0.0573, 0.0298, -0.0381, 0.0935, -0.0498, -0.0979, -0.1452, 0.0835, -0.0973, -0.0172, 0.0003, 0.09, -0.0931, -0.0252, 0.008, -0.0441, -0.0938, -0.0021, 0.0885, 0.0088, 0.0034, -0.0049, 0.0217, 0.0584, -0.012, 0.059, 0.0146, -0.0, -0.0045, 0.0663, 0.0017, 0.0015, 0.0569, -0.0089, -0.0232, 0.0065, 0.0204, -0.0253, 0.1119, -0.036, 0.0125, 0.0531, 0.0584, -0.0101, -0.0593, -0.0577, -0.0656, -0.0396, 0.0525, -0.006, -0.0149, 0.003, -0.1009, -0.0281, 0.0311, -0.0088, 0.0441, -0.0056, 0.0715, 0.051, 0.0219, -0.0028, 0.0294, -0.0969, -0.0852, 0.0304, 0.0374, 0.1078, -0.0559, 0.0805, -0.0464, 0.0369, 0.0874, -0.0251, 0.0075, -0.0502, -0.0181, -0.1059, 0.0111, 0.0894, 0.0021, 0.0838, 0.0497, -0.0183, 0.0246, -0.004, -0.0828, 0.06, -0.1161, -0.0367, 0.0475, 0.0317]) AS distance
FROM default.wiki_abstract
ORDER BY distance ASC
LIMIT 5;We're committed to continuously improving and evolving MyScaleDB to meet the ever-changing needs of the AI industry. Join us on this exciting journey and be part of the revolution in AI data management!
-
Get the latest MyScaleDB news or updates
- Follow @MyScaleDB on Twitter
- Follow @MyScale on LinkedIn
- Read MyScale Blog
- [x] Inverted index & performant keyword/vector hybrid search (supported since 1.5)
- [ ] Support more storage engines, e.g.
ReplacingMergeTree - [ ] LLM observability with MyScaleDB
- [ ] Data-centric LLM
- [ ] Automatic data science with MyScaleDB
MyScaleDB is licensed under the Apache License, Version 2.0. View a copy of the License file.
We give special thanks for these open-source projects, upon which we have developed MyScaleDB:
- ClickHouse - A free analytics DBMS for big data.
- Faiss - A library for efficient similarity search and clustering of dense vectors, by Meta's Fundamental AI Research.
- hnswlib - Header-only C++/python library for fast approximate nearest neighbors.
- ScaNN - Scalable Nearest Neighbors library by Google Research.
- Tantivy - A full-text search engine library inspired by Apache Lucene and written in Rust.
-
See why metadata filtering is crucial for imporoving RAG accuracy here. ↩
-
The MSTG (Multi-scale Tree Graph) algorithm is provided through MyScale Cloud, achieving high data density with disk-based storage and better indexing & search performance on billion-scale vector data. ↩
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MyScaleDB
Similar Open Source Tools
MyScaleDB
MyScaleDB is a SQL vector database optimized for AI applications, enabling developers to manage and process massive volumes of data efficiently. It offers fast and powerful vector search, filtered search, and SQL-vector join queries, making it fully SQL-compatible. MyScaleDB provides unmatched performance and scalability by leveraging cutting-edge OLAP database architecture and advanced vector algorithms. It is production-ready for AI applications, supporting structured data, text, vector, JSON, geospatial, and time-series data. MyScale Cloud offers fully-managed MyScaleDB with premium features on billion-scale data, making it cost-effective and simpler to use compared to specialized vector databases. Built on top of ClickHouse, MyScaleDB combines structured and vector search efficiently, ensuring high accuracy and performance in filtered search operations.
myscaledb
MyScaleDB is a SQL vector database designed for scalable AI applications, enabling developers to efficiently manage and process massive volumes of data using familiar SQL. It offers fast and efficient vector search, filtered search, and SQL-vector join queries. MyScaleDB is fully SQL-compatible and production-ready for AI applications, providing unmatched performance and scalability through cutting-edge OLAP architecture and advanced vector algorithms. Built on top of ClickHouse, it combines structured and vectorized data management for high accuracy and speed in filtered searches.

semlib
Semlib is a Python library for building data processing and data analysis pipelines that leverage the power of large language models (LLMs). It provides functional programming primitives like map, reduce, sort, and filter, programmed with natural language descriptions. Semlib handles complexities such as prompting, parsing, concurrency control, caching, and cost tracking. The library breaks down sophisticated data processing tasks into simpler steps to improve quality, feasibility, latency, cost, security, and flexibility of data processing tasks.

guidellm
GuideLLM is a platform for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM enables users to assess the performance, resource requirements, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality. The tool provides features for performance evaluation, resource optimization, cost estimation, and scalability testing.

AgentCPM
AgentCPM is a series of open-source LLM agents jointly developed by THUNLP, Renmin University of China, ModelBest, and the OpenBMB community. It addresses challenges faced by agents in real-world applications such as limited long-horizon capability, autonomy, and generalization. The team focuses on building deep research capabilities for agents, releasing AgentCPM-Explore, a deep-search LLM agent, and AgentCPM-Report, a deep-research LLM agent. AgentCPM-Explore is the first open-source agent model with 4B parameters to appear on widely used long-horizon agent benchmarks. AgentCPM-Report is built on the 8B-parameter base model MiniCPM4.1, autonomously generating long-form reports with extreme performance and minimal footprint, designed for high-privacy scenarios with offline and agile local deployment.
quarkus-langchain4j
This repository contains Quarkus extensions that facilitate seamless integration between Quarkus and LangChain4j, enabling easy incorporation of Large Language Models (LLMs) into your Quarkus applications. Here is a non-exhaustive list of features that are currently supported: Declarative AI services, Integration with diverse LLMs (OpenAI GPTs, Hugging Faces, Ollama...), Tool support, Embedding support, Document store integration (Redis, Chroma, Infinispan...), Native compilation support, Integration with Quarkus observability stack (metrics, tracing...).

only_train_once
Only Train Once (OTO) is an automatic, architecture-agnostic DNN training and compression framework that allows users to train a general DNN from scratch or a pretrained checkpoint to achieve high performance and slimmer architecture simultaneously in a one-shot manner without fine-tuning. The framework includes features for automatic structured pruning and erasing operators, as well as hybrid structured sparse optimizers for efficient model compression. OTO provides tools for pruning zero-invariant group partitioning, constructing pruned models, and visualizing pruning and erasing dependency graphs. It supports the HESSO optimizer and offers a sanity check for compliance testing on various DNNs. The repository also includes publications, installation instructions, quick start guides, and a roadmap for future enhancements and collaborations.
open-unlearning
OpenUnlearning is an easily extensible framework that unifies LLM unlearning evaluation benchmarks. It provides efficient implementations of TOFU and MUSE unlearning benchmarks, supporting 5 unlearning methods, 3+ datasets, 6+ evaluation metrics, and 7+ LLMs. Users can easily extend the framework to incorporate more variants, collaborate by adding new benchmarks, unlearning methods, datasets, and evaluation metrics, and drive progress in the field.
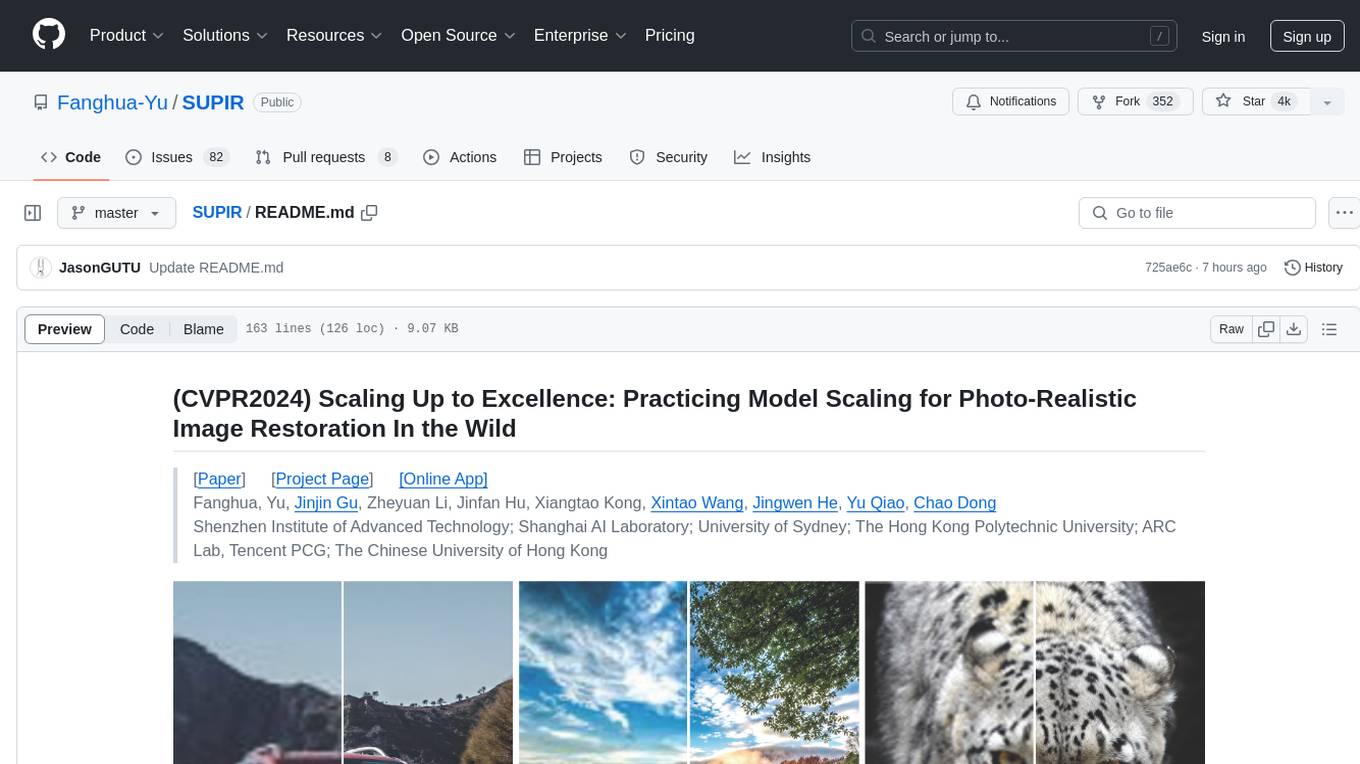
SUPIR
SUPIR is an AI-based image processing and upscaling tool that leverages cutting-edge technology to enhance image quality and resolution. The tool provides users with the ability to upscale images with high generalization and quality, as well as specific settings for light degradation scenarios. It offers a range of models and checkpoints for different use cases, along with detailed instructions for installation and usage. SUPIR also includes features for color fixing, linear CFG adjustments, and various prompts for image enhancement. The tool is designed for non-commercial use only and comes with a contact email for inquiries and permission requests for commercial use.

lector
Lector is a text analysis tool that helps users extract insights from unstructured text data. It provides functionalities such as sentiment analysis, keyword extraction, entity recognition, and text summarization. With Lector, users can easily analyze large volumes of text data to uncover patterns, trends, and valuable information. The tool is designed to be user-friendly and efficient, making it suitable for both beginners and experienced users in the field of natural language processing and text mining.

DataDreamer
DataDreamer is a powerful open-source Python library designed for prompting, synthetic data generation, and training workflows. It is simple, efficient, and research-grade, allowing users to create prompting workflows, generate synthetic datasets, and train models with ease. The library is built for researchers, by researchers, focusing on correctness, best practices, and reproducibility. It offers features like aggressive caching, resumability, support for bleeding-edge techniques, and easy sharing of datasets and models. DataDreamer enables users to run multi-step prompting workflows, generate synthetic datasets for various tasks, and train models by aligning, fine-tuning, instruction-tuning, and distilling them using existing or synthetic data.
ChatBook
ChatBook provides a one-stop AI service, including basic AI dialogue, AI role agents, AI customer service, AI knowledge base, AI mind map generation, and AI PPTX generation. Users can define AI workflows freely to handle more complex business scenarios. The backend uses serverless functions with data stored in the ./data directory. The tool allows administrators to manage knowledge bases, configure keys, and review user registrations. Normal users can directly use AI models and knowledge bases after registration. The technology stack includes LLM models like Langchain, Pinecone, OpenAi, Gemini, Baidu Wenxin, Node Express for backend, and React, NextJS, MUI for frontend.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package designed for state-of-the-art timeseries forecasting using deep learning architectures. It offers a high-level API and leverages PyTorch Lightning for efficient training on GPU or CPU with automatic logging. The package aims to simplify timeseries forecasting tasks by providing a flexible API for professionals and user-friendly defaults for beginners. It includes features such as a timeseries dataset class for handling data transformations, missing values, and subsampling, various neural network architectures optimized for real-world deployment, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. Built on pytorch-lightning, it supports training on CPUs, single GPUs, and multiple GPUs out-of-the-box.
nous
Nous is an open-source TypeScript platform for autonomous AI agents and LLM based workflows. It aims to automate processes, support requests, review code, assist with refactorings, and more. The platform supports various integrations, multiple LLMs/services, CLI and web interface, human-in-the-loop interactions, flexible deployment options, observability with OpenTelemetry tracing, and specific agents for code editing, software engineering, and code review. It offers advanced features like reasoning/planning, memory and function call history, hierarchical task decomposition, and control-loop function calling options. Nous is designed to be a flexible platform for the TypeScript community to expand and support different use cases and integrations.
aitviewer
A set of tools to visualize and interact with sequences of 3D data with cross-platform support on Windows, Linux, and macOS. It provides a native Python interface for loading and displaying SMPL[-H/-X], MANO, FLAME, STAR, and SUPR sequences in an interactive viewer. Users can render 3D data on top of images, edit SMPL sequences and poses, export screenshots and videos, and utilize a high-performance ModernGL-based rendering pipeline. The tool is designed for easy use and hacking, with features like headless mode, remote mode, animatable camera paths, and a built-in extensible GUI.

LightLLM
LightLLM is a lightweight library for linear and logistic regression models. It provides a simple and efficient way to train and deploy machine learning models for regression tasks. The library is designed to be easy to use and integrate into existing projects, making it suitable for both beginners and experienced data scientists. With LightLLM, users can quickly build and evaluate regression models using a variety of algorithms and hyperparameters. The library also supports feature engineering and model interpretation, allowing users to gain insights from their data and make informed decisions based on the model predictions.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.