
cascadeflow
Smart AI model cascading for cost optimization
Stars: 251
cascadeflow is an intelligent AI model cascading library that dynamically selects the optimal model for each query or tool call through speculative execution. It helps reduce API costs by 40-85% through intelligent model cascading and speculative execution with automatic per-query cost tracking. The tool is based on the research that shows 40-70% of queries don't require slow, expensive flagship models, and domain-specific smaller models often outperform large general-purpose models on specialized tasks. cascadeflow automatically escalates to flagship models for advanced reasoning when needed. It supports multiple providers, low latency, cost control, and transparency, and can be used for edge and local-hosted AI deployment.
README:




![]()


Cost Savings Benchmarks: 69% (MT-Bench), 93% (GSM8K), 52% (MMLU) savings, retaining 96% GPT-5 quality.
![]() Python •
Python • ![]() TypeScript •
TypeScript • ![]() LangChain •
LangChain • ![]() n8n • 📖 Docs • 💡 Examples
n8n • 📖 Docs • 💡 Examples
Stop Bleeding Money on AI Calls. Cut Costs 30-65% in 3 Lines of Code.
40-70% of text prompts and 20-60% of agent calls don't need expensive flagship models. You're overpaying every single day.
cascadeflow fixes this with intelligent model cascading, available in Python and TypeScript.
pip install cascadeflownpm install @cascadeflow/corecascadeflow is an intelligent AI model cascading library that dynamically selects the optimal model for each query or tool call through speculative execution. It's based on the research that 40-70% of queries don't require slow, expensive flagship models, and domain-specific smaller models often outperform large general-purpose models on specialized tasks. For the remaining queries that need advanced reasoning, cascadeflow automatically escalates to flagship models if needed.
Use cascadeflow for:
- Cost Optimization. Reduce API costs by 40-85% through intelligent model cascading and speculative execution with automatic per-query cost tracking.
- Cost Control and Transparency. Built-in telemetry for query, model, and provider-level cost tracking with configurable budget limits and programmable spending caps.
-
Low Latency & Speed Optimization. Sub-2ms framework overhead with fast provider routing (Groq sub-50ms). Cascade simple queries to fast models while reserving expensive models for complex reasoning, achieving 2-10x latency reduction overall. (use preset
speed_optimized) -
Multi-Provider Flexibility. Unified API across
OpenAI,Anthropic,Groq,Ollama,vLLM,Together, andHugging Face, plus 17+ providers via the Vercel AI SDK with automatic provider detection and zero vendor lock-in. OptionalLiteLLMintegration for 100+ additional providers, plusLangChainintegration for LCEL chains and tools. - Edge & Local-Hosted AI Deployment. Use best of both worlds: handle most queries with local models (vLLM, Ollama), then automatically escalate complex queries to cloud providers only when needed.
ℹ️ Note: SLMs (under 10B parameters) are sufficiently powerful for 60-70% of agentic AI tasks. Research paper
cascadeflow uses speculative execution with quality validation:
- Speculatively executes small, fast models first - optimistic execution ($0.15-0.30/1M tokens)
- Validates quality of responses using configurable thresholds (completeness, confidence, correctness)
- Dynamically escalates to larger models only when quality validation fails ($1.25-3.00/1M tokens)
- Learns patterns to optimize future cascading decisions and domain specific routing
Zero configuration. Works with YOUR existing models (7 Providers currently supported).
In practice, 60-70% of queries are handled by small, efficient models (8-20x cost difference) without requiring escalation
Result: 40-85% cost reduction, 2-10x faster responses, zero quality loss.
┌─────────────────────────────────────────────────────────────┐
│ cascadeflow Stack │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Cascade Agent │ │
│ │ │ │
│ │ Orchestrates the entire cascade execution │ │
│ │ • Query routing & model selection │ │
│ │ • Drafter -> Verifier coordination │ │
│ │ • Cost tracking & telemetry │ │
│ └───────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Domain Pipeline │ │
│ │ │ │
│ │ Automatic domain classification │ │
│ │ • Rule-based detection (CODE, MATH, DATA, etc.) │ │
│ │ • Optional ML semantic classification │ │
│ │ • Domain-optimized pipelines & model selection │ │
│ └───────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Quality Validation Engine │ │
│ │ │ │
│ │ Multi-dimensional quality checks │ │
│ │ • Length validation (too short/verbose) │ │
│ │ • Confidence scoring (logprobs analysis) │ │
│ │ • Format validation (JSON, structured output) │ │
│ │ • Semantic alignment (intent matching) │ │
│ └───────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Cascading Engine (<2ms overhead) │ │
│ │ │ │
│ │ Smart model escalation strategy │ │
│ │ • Try cheap models first (speculative execution) │ │
│ │ • Validate quality instantly │ │
│ │ • Escalate only when needed │ │
│ │ • Automatic retry & fallback │ │
│ └───────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Provider Abstraction Layer │ │
│ │ │ │
│ │ Unified interface for 7+ providers │ │
│ │ • OpenAI • Anthropic • Groq • Ollama │ │
│ │ • Together • vLLM • HuggingFace • LiteLLM │ │
│ └───────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘
If you already have an app using the OpenAI or Anthropic APIs and want the fastest integration, run the gateway and point your existing client at it:
python -m cascadeflow.server --mode auto --port 8084Docs: docs/guides/gateway.md
pip install cascadeflow[all]from cascadeflow import CascadeAgent, ModelConfig
# Define your cascade - try cheap model first, escalate if needed
agent = CascadeAgent(models=[
ModelConfig(name="gpt-4o-mini", provider="openai", cost=0.000375), # Draft model (~$0.375/1M tokens)
ModelConfig(name="gpt-5", provider="openai", cost=0.00562), # Verifier model (~$5.62/1M tokens)
])
# Run query - automatically routes to optimal model
result = await agent.run("What's the capital of France?")
print(f"Answer: {result.content}")
print(f"Model used: {result.model_used}")
print(f"Cost: ${result.total_cost:.6f}")💡 Optional: Use ML-based Semantic Quality Validation
For advanced use cases, you can add ML-based semantic similarity checking to validate that responses align with queries.
Step 1: Install the optional ML package:
pip install cascadeflow[ml] # Adds semantic similarity via FastEmbed (~80MB model)Step 2: Use semantic quality validation:
from cascadeflow.quality.semantic import SemanticQualityChecker
# Initialize semantic checker (downloads model on first use)
checker = SemanticQualityChecker(
similarity_threshold=0.5, # Minimum similarity score (0-1)
toxicity_threshold=0.7 # Maximum toxicity score (0-1)
)
# Validate query-response alignment
query = "Explain Python decorators"
response = "Decorators are a way to modify functions using @syntax..."
result = checker.validate(query, response, check_toxicity=True)
print(f"Similarity: {result.similarity:.2%}")
print(f"Passed: {result.passed}")
print(f"Toxic: {result.is_toxic}")What you get:
- 🎯 Semantic similarity scoring (query ↔ response alignment)
- 🛡️ Optional toxicity detection
- 🔄 Automatic model download and caching
- 🚀 Fast inference (~100ms per check)
Full example: See semantic_quality_domain_detection.py
⚠️ GPT-5 Note: GPT-5 streaming requires organization verification. Non-streaming works for all users. Verify here if needed (~15 min). Basic cascadeflow examples work without - GPT-5 is only called when needed (typically 20-30% of requests).
📖 Learn more: Python Documentation | Quickstart Guide | Providers Guide
npm install @cascadeflow/coreimport { CascadeAgent, ModelConfig } from '@cascadeflow/core';
// Same API as Python!
const agent = new CascadeAgent({
models: [
{ name: 'gpt-4o-mini', provider: 'openai', cost: 0.000375 },
{ name: 'gpt-4o', provider: 'openai', cost: 0.00625 },
],
});
const result = await agent.run('What is TypeScript?');
console.log(`Model: ${result.modelUsed}`);
console.log(`Cost: $${result.totalCost}`);
console.log(`Saved: ${result.savingsPercentage}%`);💡 Optional: ML-based Semantic Quality Validation
For advanced quality validation, enable ML-based semantic similarity checking to ensure responses align with queries.
Step 1: Install the optional ML packages:
npm install @cascadeflow/ml @xenova/transformersStep 2: Enable semantic validation in your cascade:
import { CascadeAgent, SemanticQualityChecker } from '@cascadeflow/core';
const agent = new CascadeAgent({
models: [
{ name: 'gpt-4o-mini', provider: 'openai', cost: 0.000375 },
{ name: 'gpt-4o', provider: 'openai', cost: 0.00625 },
],
quality: {
threshold: 0.40, // Traditional confidence threshold
requireMinimumTokens: 5, // Minimum response length
useSemanticValidation: true, // Enable ML validation
semanticThreshold: 0.5, // 50% minimum similarity
},
});
// Responses now validated for semantic alignment
const result = await agent.run('Explain TypeScript generics');Step 3: Or use semantic validation directly:
import { SemanticQualityChecker } from '@cascadeflow/core';
const checker = new SemanticQualityChecker();
if (await checker.isAvailable()) {
const result = await checker.checkSimilarity(
'What is TypeScript?',
'TypeScript is a typed superset of JavaScript.'
);
console.log(`Similarity: ${(result.similarity * 100).toFixed(1)}%`);
console.log(`Passed: ${result.passed}`);
}What you get:
- 🎯 Query-response semantic alignment detection
- 🚫 Off-topic response filtering
- 📦 BGE-small-en-v1.5 embeddings (~40MB, auto-downloads)
- ⚡ Fast CPU inference (~50-100ms with caching)
- 🔄 Request-scoped caching (50% latency reduction)
- 🌐 Works in Node.js, Browser, and Edge Functions
Example: semantic-quality.ts
📖 Learn more: TypeScript Documentation | Quickstart Guide | Node.js Examples | Browser/Edge Guide
Migrate in 5min from direct Provider implementation to cost savings and full cost control and transparency.
Cost: $0.000113, Latency: 850ms
# Using expensive model for everything
result = openai.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "What's 2+2?"}]
)Cost: $0.000007, Latency: 234ms
agent = CascadeAgent(models=[
ModelConfig(name="gpt-4o-mini", provider="openai", cost=0.000375),
ModelConfig(name="gpt-4o", provider="openai", cost=0.00625),
])
result = await agent.run("What's 2+2?")🔥 Saved: $0.000106 (94% reduction), 3.6x faster
📊 Learn more: Cost Tracking Guide | Production Best Practices | Performance Optimization
Use cascadeflow in n8n workflows for no-code AI automation with automatic cost optimization!
- Open n8n
- Go to Settings → Community Nodes
- Search for:
@cascadeflow/n8n-nodes-cascadeflow - Click Install
cascadeflow is a Language Model sub-node that connects two AI Chat Model nodes (drafter + verifier) and intelligently cascades between them:
Setup:
- Add two AI Chat Model nodes (cheap drafter + powerful verifier)
- Add cascadeflow node and connect both models
- Connect cascadeflow to Basic LLM Chain or Chain nodes
- Check Logs tab to see cascade decisions in real-time!
Result: 40-85% cost savings in your n8n workflows!
Features:
- ✅ Works with any AI Chat Model node (OpenAI, Anthropic, Ollama, Azure, etc.)
- ✅ Mix providers (e.g., Ollama drafter + GPT-4o verifier)
- ✅ Includes a CascadeFlow Agent node for tool-based agent workflows (drafter/verifier + tools + trace)
- ✅ Real-time flow visualization in Logs tab
- ✅ Detailed metrics: confidence scores, latency, cost savings
🔌 Learn more: n8n Integration Guide | n8n Documentation
Use cascadeflow with LangChain for intelligent model cascading with full LCEL, streaming, and tools support!
![]() TypeScript
TypeScript
npm install @cascadeflow/langchain @langchain/core @langchain/openai![]() Python
Python
pip install cascadeflow[langchain] TypeScript - Drop-in replacement for any LangChain chat model
TypeScript - Drop-in replacement for any LangChain chat model
import { ChatOpenAI } from '@langchain/openai';
import { ChatAnthropic } from '@langchain/anthropic';
import { withCascade } from '@cascadeflow/langchain';
const cascade = withCascade({
drafter: new ChatOpenAI({ modelName: 'gpt-5-mini' }), // $0.25/$2 per 1M tokens
verifier: new ChatAnthropic({ modelName: 'claude-sonnet-4-5' }), // $3/$15 per 1M tokens
qualityThreshold: 0.8, // 80% queries use drafter
});
// Use like any LangChain chat model
const result = await cascade.invoke('Explain quantum computing');
// Optional: Enable LangSmith tracing (see https://smith.langchain.com)
// Set LANGSMITH_API_KEY, LANGSMITH_PROJECT, LANGSMITH_TRACING=true
// Or with LCEL chains
const chain = prompt.pipe(cascade).pipe(new StringOutputParser()); Python - Drop-in replacement for any LangChain chat model
Python - Drop-in replacement for any LangChain chat model
from langchain_openai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
from cascadeflow.integrations.langchain import CascadeFlow
cascade = CascadeFlow(
drafter=ChatOpenAI(model="gpt-4o-mini"), # $0.15/$0.60 per 1M tokens
verifier=ChatAnthropic(model="claude-sonnet-4-5"), # $3/$15 per 1M tokens
quality_threshold=0.8, # 80% queries use drafter
)
# Use like any LangChain chat model
result = await cascade.ainvoke("Explain quantum computing")
# Optional: Enable LangSmith tracing (see https://smith.langchain.com)
# Set LANGSMITH_API_KEY, LANGSMITH_PROJECT, LANGSMITH_TRACING=true
# Or with LCEL chains
chain = prompt | cascade | StrOutputParser()💡 Optional: Cost Tracking with Callbacks (Python)
Track costs, tokens, and cascade decisions with LangChain-compatible callbacks:
from cascadeflow.integrations.langchain.langchain_callbacks import get_cascade_callback
# Track costs similar to get_openai_callback()
with get_cascade_callback() as cb:
response = await cascade.ainvoke("What is Python?")
print(f"Total cost: ${cb.total_cost:.6f}")
print(f"Drafter cost: ${cb.drafter_cost:.6f}")
print(f"Verifier cost: ${cb.verifier_cost:.6f}")
print(f"Total tokens: {cb.total_tokens}")
print(f"Successful requests: {cb.successful_requests}")Features:
- 🎯 Compatible with
get_openai_callback()pattern - 💰 Separate drafter/verifier cost tracking
- 📊 Token usage (including streaming)
- 🔄 Works with LangSmith tracing
- ⚡ Near-zero overhead
Full example: See langchain_cost_tracking.py
💡 Optional: Model Discovery & Analysis Helpers (TypeScript)
For discovering optimal cascade pairs from your existing LangChain models, use the built-in discovery helpers:
import {
discoverCascadePairs,
findBestCascadePair,
analyzeModel,
validateCascadePair
} from '@cascadeflow/langchain';
// Your existing LangChain models (configured with YOUR API keys)
const myModels = [
new ChatOpenAI({ model: 'gpt-3.5-turbo' }),
new ChatOpenAI({ model: 'gpt-4o-mini' }),
new ChatOpenAI({ model: 'gpt-4o' }),
new ChatAnthropic({ model: 'claude-3-haiku' }),
// ... any LangChain chat models
];
// Quick: Find best cascade pair
const best = findBestCascadePair(myModels);
console.log(`Best pair: ${best.analysis.drafterModel} → ${best.analysis.verifierModel}`);
console.log(`Estimated savings: ${best.estimatedSavings}%`);
// Use it immediately
const cascade = withCascade({
drafter: best.drafter,
verifier: best.verifier,
});
// Advanced: Discover all valid pairs
const pairs = discoverCascadePairs(myModels, {
minSavings: 50, // Only pairs with ≥50% savings
requireSameProvider: false, // Allow cross-provider cascades
});
// Validate specific pair
const validation = validateCascadePair(drafter, verifier);
console.log(`Valid: ${validation.valid}`);
console.log(`Warnings: ${validation.warnings}`);What you get:
- 🔍 Automatic discovery of optimal cascade pairs from YOUR models
- 💰 Estimated cost savings calculations
⚠️ Validation warnings for misconfigured pairs- 📊 Model tier analysis (drafter vs verifier candidates)
Full example: See model-discovery.ts
Features:
- ✅ Full LCEL support (pipes, sequences, batch)
- ✅ Streaming with pre-routing
- ✅ Tool calling and structured output
- ✅ LangSmith cost tracking metadata
- ✅ Cost tracking callbacks (Python)
- ✅ Works with all LangChain features
🦜 Learn more: LangChain Integration Guide | TypeScript Package | Python Examples
![]() Python Examples:
Python Examples:
Basic Examples - Get started quickly
| Example | Description | Link |
|---|---|---|
| Basic Usage | Simple cascade setup with OpenAI models | View |
| Preset Usage | Use built-in presets for quick setup | View |
| Multi-Provider | Mix multiple AI providers in one cascade | View |
| Reasoning Models | Use reasoning models (o1/o3, Claude 3.7, DeepSeek-R1) | View |
| Tool Execution | Function calling and tool usage | View |
| Streaming Text | Stream responses from cascade agents | View |
| Cost Tracking | Track and analyze costs across queries | View |
Advanced Examples - Production & customization
| Example | Description | Link |
|---|---|---|
| Production Patterns | Best practices for production deployments | View |
| FastAPI Integration | Integrate cascades with FastAPI | View |
| Streaming Tools | Stream tool calls and responses | View |
| Batch Processing | Process multiple queries efficiently | View |
| Multi-Step Cascade | Build complex multi-step cascades | View |
| Edge Device | Run cascades on edge devices with local models | View |
| vLLM Example | Use vLLM for local model deployment | View |
| Multi-Instance Ollama | Run draft/verifier on separate Ollama instances | View |
| Multi-Instance vLLM | Run draft/verifier on separate vLLM instances | View |
| Custom Cascade | Build custom cascade strategies | View |
| Custom Validation | Implement custom quality validators | View |
| User Budget Tracking | Per-user budget enforcement and tracking | View |
| User Profile Usage | User-specific routing and configurations | View |
| Rate Limiting | Implement rate limiting for cascades | View |
| Guardrails | Add safety and content guardrails | View |
| Cost Forecasting | Forecast costs and detect anomalies | View |
| Semantic Quality Detection | ML-based domain and quality detection | View |
| Profile Database Integration | Integrate user profiles with databases | View |
| LangChain Basic | Simple LangChain cascade setup | View |
| LangChain Streaming | Stream responses with LangChain | View |
| LangChain Model Discovery | Discover and analyze LangChain models | View |
| LangChain LangSmith | Cost tracking with LangSmith integration | View |
| LangChain Cost Tracking | Track costs with callback handlers | View |
| LangChain Benchmark | Comprehensive cascade benchmarking | View |
![]() TypeScript Examples:
TypeScript Examples:
Basic Examples - Get started quickly
| Example | Description | Link |
|---|---|---|
| Basic Usage | Simple cascade setup (Node.js) | View |
| Tool Calling | Function calling with tools (Node.js) | View |
| Multi-Provider | Mix providers in TypeScript (Node.js) | View |
| Reasoning Models | Use reasoning models (o1/o3, Claude 3.7, DeepSeek-R1) | View |
| Cost Tracking | Track and analyze costs across queries | View |
| Semantic Quality | ML-based semantic validation with embeddings | View |
| Streaming | Stream responses in TypeScript | View |
Advanced Examples - Production, edge & LangChain
| Example | Description | Link |
|---|---|---|
| Production Patterns | Production best practices (Node.js) | View |
| Multi-Instance Ollama | Run draft/verifier on separate Ollama instances | View |
| Multi-Instance vLLM | Run draft/verifier on separate vLLM instances | View |
| Browser/Edge | Vercel Edge runtime example | View |
| LangChain Basic | Simple LangChain cascade setup | View |
| LangChain Cross-Provider | Haiku → GPT-5 with PreRouter | View |
| LangChain LangSmith | Cost tracking with LangSmith | View |
| LangChain Cost Tracking | Compare cascadeflow vs LangSmith cost tracking | View |
📂 View All Python Examples → | View All TypeScript Examples →
Getting Started - Core concepts and basics
| Guide | Description | Link |
|---|---|---|
| Quickstart | Get started with cascadeflow in 5 minutes | Read |
| Providers Guide | Configure and use different AI providers | Read |
| Presets Guide | Using and creating custom presets | Read |
| Streaming Guide | Stream responses from cascade agents | Read |
| Tools Guide | Function calling and tool usage | Read |
| Cost Tracking | Track and analyze API costs | Read |
Advanced Topics - Production, customization & integrations
| Guide | Description | Link |
|---|---|---|
| Production Guide | Best practices for production deployments | Read |
| Performance Guide | Optimize cascade performance and latency | Read |
| Custom Cascade | Build custom cascade strategies | Read |
| Custom Validation | Implement custom quality validators | Read |
| Edge Device | Deploy cascades on edge devices | Read |
| Browser Cascading | Run cascades in the browser/edge | Read |
| FastAPI Integration | Integrate with FastAPI applications | Read |
| LangChain Integration | Use cascadeflow with LangChain | Read |
| n8n Integration | Use cascadeflow in n8n workflows | Read |
| Feature | Benefit |
|---|---|
| 🎯 Speculative Cascading | Tries cheap models first, escalates intelligently |
| 💰 40-85% Cost Savings | Research-backed, proven in production |
| ⚡ 2-10x Faster | Small models respond in <50ms vs 500-2000ms |
| ⚡ Low Latency | Sub-2ms framework overhead, negligible performance impact |
| 🔄 Mix Any Providers | OpenAI, Anthropic, Groq, Ollama, vLLM, Together + LiteLLM (optional) + LangChain integration |
| 👤 User Profile System | Per-user budgets, tier-aware routing, enforcement callbacks |
| ✅ Quality Validation | Automatic checks + semantic similarity (optional ML, ~80MB, CPU) |
| 🎨 Cascading Policies | Domain-specific pipelines, multi-step validation strategies |
| 🧠 Domain Understanding | 15 domains auto-detected (code, medical, legal, finance, math, etc.), routes to specialists |
| 🤖 Drafter/Validator Pattern | 20-60% savings for agent/tool systems |
| 🔧 Tool Calling Support | Universal format, works across all providers |
| 📊 Cost Tracking | Built-in analytics + OpenTelemetry export (vendor-neutral) |
| 🚀 3-Line Integration | Zero architecture changes needed |
| 🏭 Production Ready | Streaming, batch processing, tool handling, reasoning model support, caching, error recovery, anomaly detection |
MIT © see LICENSE file.
Free for commercial use. Attribution appreciated but not required.
We ❤️ contributions!
📝 Contributing Guide - Python & TypeScript development setup
- Cascade Profiler - Analyzes your AI API logs to calculate cost savings potential and generate optimized cascadeflow configurations automatically
- User Tier Management - Cost controls and limits per user tier with advanced routing
- Semantic Quality Validators - Optional lightweight local quality scoring (200MB CPU model, no external API calls)
- Code Complexity Detection - Dynamic cascading based on task complexity analysis
- Domain Aware Cascading - Multi-stage pipelines tailored to specific domains
- Benchmark Reports - Automated performance and cost benchmarking
- 📖 GitHub Discussions - Searchable Q&A
- 🐛 GitHub Issues - Bug reports & feature requests
- 📧 Email Support - Direct support
If you use cascadeflow in your research or project, please cite:
@software{cascadeflow2025,
author = {Lemony Inc., Sascha Buehrle and Contributors},
title = {cascadeflow: Smart AI model cascading for cost optimization},
year = {2025},
publisher = {GitHub},
url = {https://github.com/lemony-ai/cascadeflow}
}Ready to cut your AI costs by 40-85%?
pip install cascadeflownpm install @cascadeflow/coreRead the Docs • View Python Examples • View TypeScript Examples • Join Discussions
Built with ❤️ by Lemony Inc. and the cascadeflow Community
One cascade. Hundreds of specialists.
New York | Zurich
⭐ Star us on GitHub if cascadeflow helps you save money!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for cascadeflow
Similar Open Source Tools
cascadeflow
cascadeflow is an intelligent AI model cascading library that dynamically selects the optimal model for each query or tool call through speculative execution. It helps reduce API costs by 40-85% through intelligent model cascading and speculative execution with automatic per-query cost tracking. The tool is based on the research that shows 40-70% of queries don't require slow, expensive flagship models, and domain-specific smaller models often outperform large general-purpose models on specialized tasks. cascadeflow automatically escalates to flagship models for advanced reasoning when needed. It supports multiple providers, low latency, cost control, and transparency, and can be used for edge and local-hosted AI deployment.
DeepTutor
DeepTutor is an AI-powered personalized learning assistant that offers a suite of modules for massive document knowledge Q&A, interactive learning visualization, knowledge reinforcement with practice exercise generation, deep research, and idea generation. The tool supports multi-agent collaboration, dynamic topic queues, and structured outputs for various tasks. It provides a unified system entry for activity tracking, knowledge base management, and system status monitoring. DeepTutor is designed to streamline learning and research processes by leveraging AI technologies and interactive features.
mcp-prompts
mcp-prompts is a Python library that provides a collection of prompts for generating creative writing ideas. It includes a variety of prompts such as story starters, character development, plot twists, and more. The library is designed to inspire writers and help them overcome writer's block by offering unique and engaging prompts to spark creativity. With mcp-prompts, users can access a wide range of writing prompts to kickstart their imagination and enhance their storytelling skills.
incidentfox
IncidentFox is an open-source AI SRE tool designed to assist in incident response by automatically investigating incidents, finding root causes, and suggesting fixes. It integrates with observability stack, infrastructure, and collaboration tools, forming hypotheses, collecting data, and reasoning through to find root causes. The tool is built for production on-call scenarios, handling log sampling, alert correlation, anomaly detection, and dependency mapping. IncidentFox is highly customizable, Slack-first, and works on various platforms like web UI, GitHub, PagerDuty, and API. It aims to reduce incident resolution time, alert noise, and improve knowledge retention for engineering teams.
sandbox
AIO Sandbox is an all-in-one agent sandbox environment that combines Browser, Shell, File, MCP operations, and VSCode Server in a single Docker container. It provides a unified, secure execution environment for AI agents and developers, with features like unified file system, multiple interfaces, secure execution, zero configuration, and agent-ready MCP-compatible APIs. The tool allows users to run shell commands, perform file operations, automate browser tasks, and integrate with various development tools and services.

aichildedu
AICHILDEDU is a microservice-based AI education platform for children that integrates LLMs, image generation, and speech synthesis to provide personalized storybook creation, intelligent conversational learning, and multimedia content generation. It offers features like personalized story generation, educational quiz creation, multimedia integration, age-appropriate content, multi-language support, user management, parental controls, and asynchronous processing. The platform follows a microservice architecture with components like API Gateway, User Service, Content Service, Learning Service, and AI Services. Technologies used include Python, FastAPI, PostgreSQL, MongoDB, Redis, LangChain, OpenAI GPT models, TensorFlow, PyTorch, Transformers, MinIO, Elasticsearch, Docker, Docker Compose, and JWT-based authentication.

hub
Hub is an open-source, high-performance LLM gateway written in Rust. It serves as a smart proxy for LLM applications, centralizing control and tracing of all LLM calls and traces. Built for efficiency, it provides a single API to connect to any LLM provider. The tool is designed to be fast, efficient, and completely open-source under the Apache 2.0 license.
Lynkr
Lynkr is a self-hosted proxy server that unlocks various AI coding tools like Claude Code CLI, Cursor IDE, and Codex Cli. It supports multiple LLM providers such as Databricks, AWS Bedrock, OpenRouter, Ollama, llama.cpp, Azure OpenAI, Azure Anthropic, OpenAI, and LM Studio. Lynkr offers cost reduction, local/private execution, remote or local connectivity, zero code changes, and enterprise-ready features. It is perfect for developers needing provider flexibility, cost control, self-hosted AI with observability, local model execution, and cost reduction strategies.
mcp-memory-service
The MCP Memory Service is a universal memory service designed for AI assistants, providing semantic memory search and persistent storage. It works with various AI applications and offers fast local search using SQLite-vec and global distribution through Cloudflare. The service supports intelligent memory management, universal compatibility with AI tools, flexible storage options, and is production-ready with cross-platform support and secure connections. Users can store and recall memories, search by tags, check system health, and configure the service for Claude Desktop integration and environment variables.
mimiclaw
MimiClaw is a pocket AI assistant that runs on a $5 chip, specifically designed for the ESP32-S3 board. It operates without Linux or Node.js, using pure C language. Users can interact with MimiClaw through Telegram, enabling it to handle various tasks and learn from local memory. The tool is energy-efficient, running on USB power 24/7. With MimiClaw, users can have a personal AI assistant on a chip the size of a thumb, making it convenient and accessible for everyday use.
aippt_PresentationGen
A SpringBoot web application that generates PPT files using a llm. The tool preprocesses single-page templates and dynamically combines them to generate PPTX files with text replacement functionality. It utilizes technologies such as SpringBoot, MyBatis, MySQL, Redis, WebFlux, Apache POI, Aspose Slides, OSS, and Vue2. Users can deploy the tool by configuring various parameters in the application.yml file and setting up necessary resources like MySQL, OSS, and API keys. The tool also supports integration with open-source image libraries like Unsplash for adding images to the presentations.
starknet-agentic
Open-source stack for giving AI agents wallets, identity, reputation, and execution rails on Starknet. `starknet-agentic` is a monorepo with Cairo smart contracts for agent wallets, identity, reputation, and validation, TypeScript packages for MCP tools, A2A integration, and payment signing, reusable skills for common Starknet agent capabilities, and examples and docs for integration. It provides contract primitives + runtime tooling in one place for integrating agents. The repo includes various layers such as Agent Frameworks / Apps, Integration + Runtime Layer, Packages / Tooling Layer, Cairo Contract Layer, and Starknet L2. It aims for portability of agent integrations without giving up Starknet strengths, with a cross-chain interop strategy and skills marketplace. The repository layout consists of directories for contracts, packages, skills, examples, docs, and website.
morgana-form
MorGana Form is a full-stack form builder project developed using Next.js, React, TypeScript, Ant Design, PostgreSQL, and other technologies. It allows users to quickly create and collect data through survey forms. The project structure includes components, hooks, utilities, pages, constants, Redux store, themes, types, server-side code, and component packages. Environment variables are required for database settings, NextAuth login configuration, and file upload services. Additionally, the project integrates an AI model for form generation using the Ali Qianwen model API.
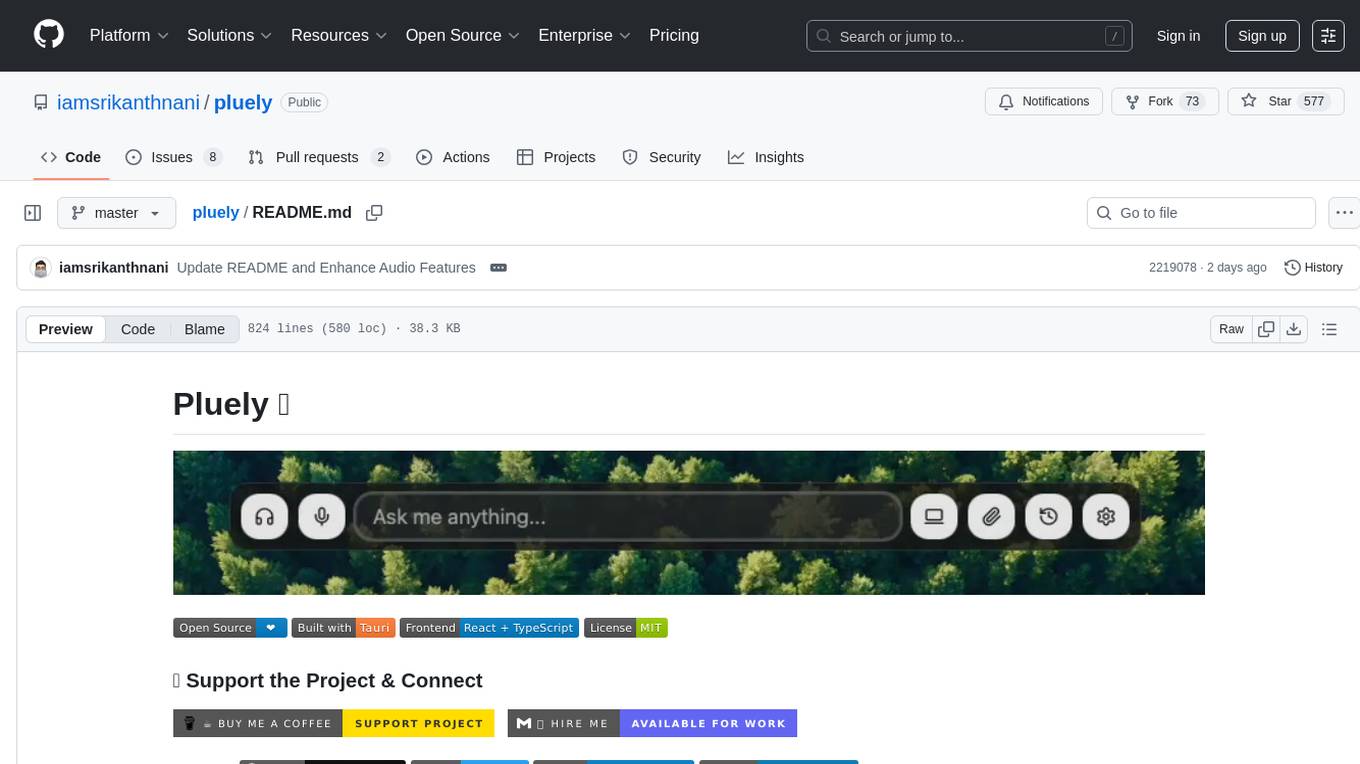
pluely
Pluely is a versatile and user-friendly tool for managing tasks and projects. It provides a simple interface for creating, organizing, and tracking tasks, making it easy to stay on top of your work. With features like task prioritization, due date reminders, and collaboration options, Pluely helps individuals and teams streamline their workflow and boost productivity. Whether you're a student juggling assignments, a professional managing multiple projects, or a team coordinating tasks, Pluely is the perfect solution to keep you organized and efficient.
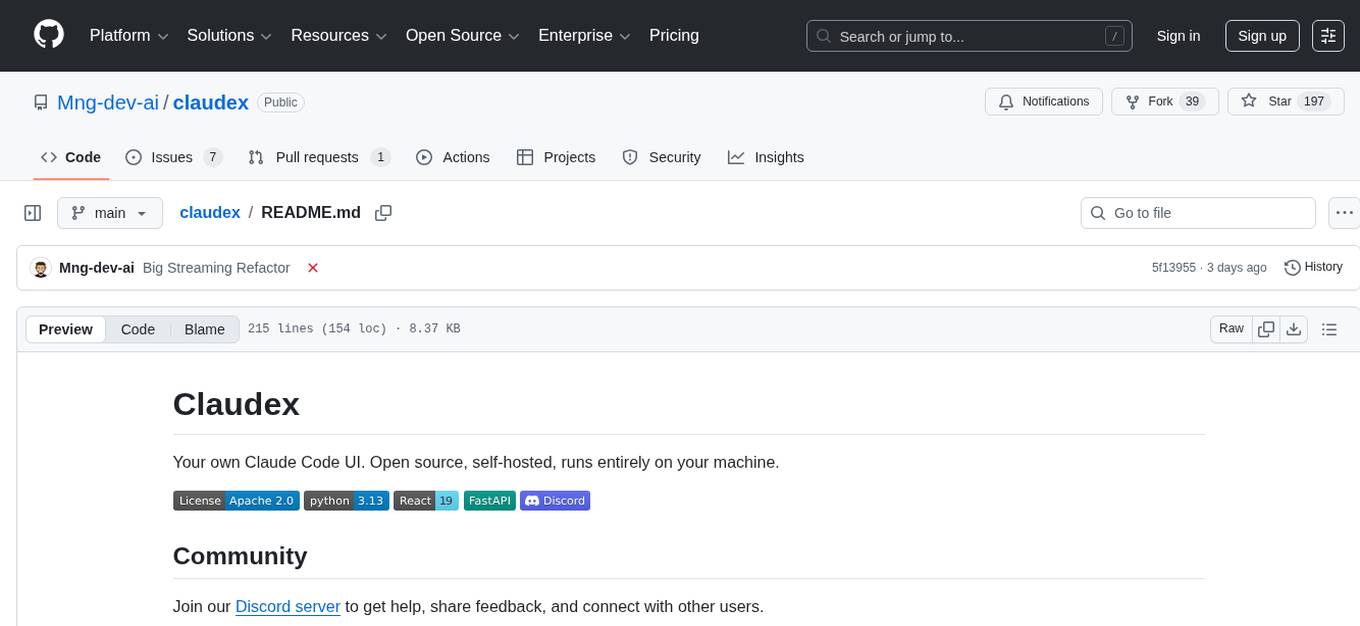
claudex
Claudex is an open-source, self-hosted Claude Code UI that runs entirely on your machine. It provides multiple sandboxes, allows users to use their own plans, offers a full IDE experience with VS Code in the browser, and is extensible with skills, agents, slash commands, and MCP servers. Users can run AI agents in isolated environments, view and interact with a browser via VNC, switch between multiple AI providers, automate tasks with Celery workers, and enjoy various chat features and preview capabilities. Claudex also supports marketplace plugins, secrets management, integrations like Gmail, and custom instructions. The tool is configured through providers and supports various providers like Anthropic, OpenAI, OpenRouter, and Custom. It has a tech stack consisting of React, FastAPI, Python, PostgreSQL, Celery, Redis, and more.
For similar tasks
cascadeflow
cascadeflow is an intelligent AI model cascading library that dynamically selects the optimal model for each query or tool call through speculative execution. It helps reduce API costs by 40-85% through intelligent model cascading and speculative execution with automatic per-query cost tracking. The tool is based on the research that shows 40-70% of queries don't require slow, expensive flagship models, and domain-specific smaller models often outperform large general-purpose models on specialized tasks. cascadeflow automatically escalates to flagship models for advanced reasoning when needed. It supports multiple providers, low latency, cost control, and transparency, and can be used for edge and local-hosted AI deployment.
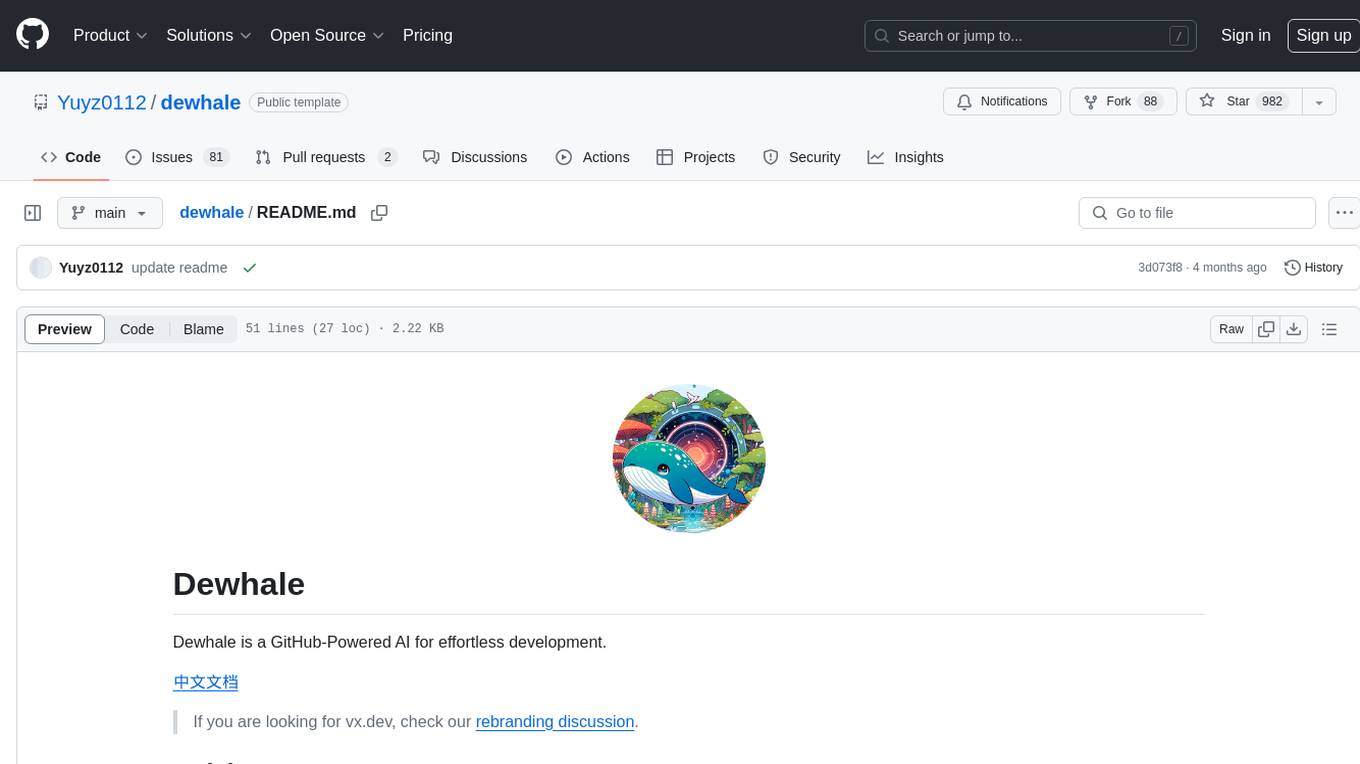
dewhale
Dewhale is a GitHub-Powered AI tool designed for effortless development. It utilizes prompt engineering techniques under the GPT-4 model to issue commands, allowing users to generate code with lower usage costs and easy customization. The tool seamlessly integrates with GitHub, providing version control, code review, and collaborative features. Users can join discussions on the design philosophy of Dewhale and explore detailed instructions and examples for setting up and using the tool.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.