
LLM-Discrete-Tokenization-Survey
The official GitHub page for the survey paper "Discrete Tokenization for Multimodal LLMs: A Comprehensive Survey". And this paper is under review.
Stars: 77
The repository contains a comprehensive survey paper on Discrete Tokenization for Multimodal Large Language Models (LLMs). It covers various techniques, applications, and challenges related to discrete tokenization in the context of LLMs. The survey explores the use of vector quantization, product quantization, and other methods for tokenizing different modalities like text, image, audio, video, graph, and more. It also discusses the integration of discrete tokenization with LLMs for tasks such as image generation, speech recognition, recommendation systems, and multimodal understanding and generation.
README:
The official GitHub page for the survey paper "Discrete Tokenization for Multimodal LLMs: A Comprehensive Survey".











-
2017_NeurIPS_VQ-VAE_Neural Discrete Representation Learning. [arXiv]
-
2017_NeurlPS_SHVQ_Soft-to-Hard Vector Quantization for End-to-End Learning Compressible Representations. [arXiv]
-
2018_arXiv_Theory and Experiments on Vector Quantized Autoencoders. [arXiv]
-
2019_NeurlPS_VQ-VAE-2_Generating Diverse High-Fidelity Images with VQ-VAE-2. [NeurIPS] [arXiv]
-
2020_AAAI_soft VQ-VAE_Vector quantization-based regularization for autoencoders. [AAAI] [arXiv]
-
2020_NeurlPS_HQA_Hierarchical Quantized Autoencoders. [NeurIPS] [arXiv]
-
2021_CVPR_VQGAN_Taming Transformers for High-Resolution Image Synthesis. [CVPR] [arXiv] [Homepage]
-
2022_arXiv_HC-VQ_Homology-constrained vector quantization entropy regularizer. [arXiv]
-
2022_ICML_SQ-VAE_SQ-VAE:Variational Bayes on Discrete Representation with Self-annealed Stochastic Quantization. [ICML--Slides] [arXiv]
-
2023_CVPR_Reg-VQ_Regularized Vector Quantization for Tokenized Image Synthesis. [CVPR] [arXiv]
-
2023_ICML_Straightening Out the Straight-Through Estimator:Overcoming Optimization Challenges in Vector Quantized Networks. [ICML] [arXiv]
-
2023_ICML_VQ-WAE_Vector Quantized Wasserstein Auto-Encoder. [ICML] [arXiv]
-
2024_arXiv_HyperVQ_HyperVQ: MLR-based Vector Quantization in Hyperbolic Space. [arXiv]
-
2024_arXiv_IBQ_Scalable Image Tokenization with Index Backpropagation Quantization. [arXiv]
-
2024_arXiv_SimVQ_Addressing representation collapse in vector quantized models with one linear layer. [arXiv]
-
2024_NeurIPS_VQGAN-LC_Scaling the Codebook Size of VQGAN to 100,000 with a Utilization Rate of 99%. [arXiv]
-
2024_L4DC_SCQ_Soft Convex Quantization=Revisiting Vector Quantization with Convex Optimization. [PMLR] [arXiv]
-
2024_TMLR_HQ-VAE_HQ-VAE:Hierarchical Discrete Representation Learning with Variational Bayes. [arXiv]
-
2025_ICLR_rotation trick_Restructuring vector quantization with the rotation trick. [ICLR--Slides] [arXiv]

-
2010_Sensors_RVQ_Approximate nearest neighbor search by residual vector quantization. [Sensors]
-
2014_arXiv_SQ_Stacked Quantizers for Compositional Vector Compression. [arXiv]
-
2014_IEEE Multimedia_PRVQ_Projected residual vector quantization for ANN search. [IEEE]
-
2015_arXiv_IRVQ_Improved Residual Vector Quantization for High-dimensional Approximate Nearest Neighbor Search. [arXiv]
-
2015_arXiv_TRQ_Transformed Residual Quantization for Approximate Nearest Neighbor Search. [arXiv]
-
2016_Neurocomputing_RVQ-P RVQ-NP_Parametric and nonparametric residual vector quantization optimizations for ANN search. [ACM]
-
2016_TKDE_CompQ_Competitive Quantization for Approximate Nearest Neighbor Search. [IEEE TKDE]
-
2017_Multimedia Systems_ERVQ_Optimized residual vector quantization for efficient approximate nearest neighbor search. [Springer]
-
2017_Multimedia_GRVQ_Generalized Residual Vector Quantization and Aggregating Tree for Large Scale Search. [IEEE Transactions on Multimedia]
-
2024_ICML_QINCo_Residual Quantization with Implicit Neural Codebooks. [ICML] [arXiv]
-
2025_arXiv_Qinco2_Qinco2:Vector Compression and Search with Improved Implicit Neural Codebooks. [arXiv]

-
2011_TPAMI_PQ_Product Quantization for Nearest Neighbor Search. [IEEE TPAMI]
-
2013_CVPR_CKM_Cartesian k-means. [CVPR]
-
2013_CVPR_OPQ_Optimized product quantization for approximate nearest neighbor search. [IEEE CVPR] [CVPR]
-
2014_CVPR_LOPQ_Locally optimized product quantization for approximate nearest neighbor search. [IEEE CVPR] [CVPR]
-
2014_ICML_CQ_Composite Quantization for Approximate Nearest Neighbor Search. [ICML]
-
2015_CVPR_SQ1 SQ2_Sparse Composite Quantization. [CVPR]
-
2015_ICIP_PTQ_Product tree quantization for approximate nearest neighbor search. [IEEE ICIP]
-
2015_TKDE_OCKM_Optimized Cartesian K-Means. [IEEE TKDE] [arXiv]
-
2016_CVPR_SQ_Supervised Quantization for Similarity Search. [CVPR] [arXiv]
-
2018_TKDE_Online PQ_Online Product Quantization. [IEEE TKDE]
-
2019_CVPR_DPQ_End-to-End Supervised Product Quantization for Image Search and Retrieval. [IEEE CVPR] [CVPR] [arXiv]
-
2020_ICDM_Online OPQ_Online Optimized Product Quantization. [IEEE ICDM]
-
2020_ICML_DPQ_Differentiable Product Quantization for End-to-End Embedding Compression. [ICML] [arXiv]
-
2022_ICDE_VAQ_Fast Adaptive Similarity Search through Variance-Aware Quantization. [IEEE ICDE]
-
2023_ESWA_RVPQ_Residual Vector Product Quantization for Approximate Nearest Neighbor Search. [Springer]
-
2023_WWW_DOPQ_Diferentiable Optimized Product Qantization and Beyond. [WWW]
-
2024_AAAI_HiHPQ_HiHPQ: Hierarchical Hyperbolic Product Quantization for Unsupervised Image Retrieval. [ACM AAAI] [arXiv]

-
2014_CVPR_AQ_Additive Quantization for Extreme Vector Compression. [IEEE CVPR] [CVPR]
-
2016_ECCV_LSQ_Revisiting Additive Quantization. [Springer] [ECCV]
-
2018_ECCV_LSQ++_LSQ++: Lower Running Time and Higher Recall in Multi-codebook Quantization. [ECCV]
-
2021_KDD_Online AQ_Online Additive Quantization. [ACM KDD] [KDD]


- 2024_ICLR_MAGVIT-v2_Language Model Beats Diffusion--Tokenizer is Key to Visual Generation. [ICLR] [arXiv]

- 2025_ICLR_BSQ_Image and Video Tokenization with Binary Spherical Quantization. [arXiv]
-
2022_ICLR_NodePiece_NodePiece: Compositional and Parameter-Efficient Representations of Large Knowledge Graphs. [ICLR] [arXiv]
-
2023_AAAI_EARL_Entity-Agnostic Representation Learning for Parameter-Efficient Knowledge Graph Embedding. [ACM AAAI] [arXiv]
-
2023_EMNLP_RandomEQ_Random Entity Quantization for Parameter-Efficient Compositional Knowledge Graph Representation. [EMNLP] [arXiv]

-
2017_CVPR_DVSQ_Deep Visual-Semantic Quantization for Efficient Image Retrieval. [CVPR]
-
2019_IJCAI_DPQ_Beyond product quantization:Deep progressive quantization for image retrieval. [IJCAI] [arXiv]
-
2021_ICCV_SPQ_Self-supervised Product Quantization for Deep Unsupervised Image Retrieval. [ICCV] [arXiv]
-
2022_arXiv_BEiT v2_BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers. [arXiv]
-
2022_AAAI_MeCoQ_Contrastive Quantization with Code Memory for Unsupervised Image Retrieval. [AAAI] [arXiv]
-
2022_CVPR_MaskGIT_MaskGIT:Masked Generative Image Transformer. [CVPR] [arXiv] [Github]
-
2022_CVPR_RQ-VAE RQ-Transformer_AutoRegressive Image Generation using Residual Quantization. [CVPR] [arXiv]
-
2022_ICLR_BEiT_BEiT: BERT Pre-Training of Image Transformers. [ICLR] [arXiv]
-
2022_ICLR_ViT-VQGAN_Vector-Quantization Image Modeling with Improved VQGAN. [ICLR] [arXiv]
-
2022_NeurlPS_MoVQ_MoVQ: Modulating Quantized Vectors for High-Fidelity Image Generation. [NeurIPS] [arXiv]
-
2023_CVPR_DQ-VAE_Towards Accurate Image Coding:Improved Autoregressive Image Generation with Dynamic Vector Quantization. [CVPR] [arXiv]
-
2023_CVPR_MAGE_MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis. [CVPR] [arXiv] [Github]
-
2023_CVPR_MQ-VAE_Not All Image Regions Matter:Masked Vector Quantization for Autoregressive Image Generation. [CVPR] [arXiv]
-
2023_ICCV_Efficient-VQGAN_Efficient-VQGAN: Towards High-Resolution Image Generation with Efficient Vision Transformers. [ICCV] [IEEE ICCV] [arXiv]
-
2024_CVPR_SeQ-GAN_Rethinking the Objectives of Vector-Quantized Tokenizers for Image Synthesis. [CVPR] [arXiv]
-
2024_ICLR_ClusterMIM_On the Role of Discrete Tokenization in Visual Representation Learning. [ICLR] [arXiv]
-
2024_NeurlPS_TiTok_An Image is Worth 32 Tokens for Reconstruction and Generation. [NeurIPS] [arXiv]
-
2024_NeurlPS_VAR_Visual Autoregressive Modeling:Scalable Image Generation via Next-Scale Prediction. [NeurIPS] [arXiv]
-
2024_NeurlPS_VQ-KD_Image Understanding Makes for A Good Tokenizer for Image Generation. [NeurIPS] [arXiv]
-
2024_TMLR_MaskBit_MaskBit: Embedding-free Image Generation via Bit Tokens. [Poster] [arXiv]
-
2025_arXiv_FlowMo_Flow to the Mode: Mode-Seeking Diffusion Autoencoders for State-of-the-Art Image Tokenization. [arXiv]
-
2025_CVPR_MergeVQ_MergeVQ: A Unified Framework for Visual Generation and Representation with Disentangled Token Merging and Quantization. [[CVPR]](MergeVQ: A Unified Framework for Visual Generation and Representation with Disentangled Token Merging and Quantization) [arXiv] [Github]
-
2025_ICLR_DnD-Transformer_A spark of vision-language intelligence: 2-dimensional autoregressive transformer for efficient finegrained image generation. [ICLR] [arXiv]
-
2022_TASLP_SoundStream_SoundStream:An End-to-End Neural Audio Codec. [IEEE] [arXiv] [Github]
-
2023_arXiv_HiFi-Codec_HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec. [arXiv]
-
2023_NeurlPS_DAC_High fidelity neural audio compression with Improved RVQGAN. [NeurIPS] [arXiv]
-
2023_TMLR_EnCodec_High Fidelity Neural Audio Compression. [arXiv]
-
2024_J-STSP_SemantiCodec_SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound. [arXiv]
-
2025_arXiv_QINCODEC_QINCODEC: Neural Audio Compression with Implicit Neural Codebooks. [arXiv]
-
2025_arXiv_SQCodec_One Quantizer is Enough: Toward a Lightweight Audio Codec. [arXiv]
-
2025_arXiv_UniCodec_UniCodec:Unified Audio Codec with Single Domain-Adaptive Codebook. [arXiv] [Github]
-
2025_IEEE Signal Processing Letter_StreamCodec_A Streamable Neural Audio Codec with Residual Scalar-Vector Quantization for Real-Time Communication. [arXiv]
-
2020_ICLR_vq-wav2vec_vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations. [ICLR] [arXiv]
-
2020_NeurlPS_wav2vec 2.0_wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. [NeurIPS] [arXiv]
-
2023_ICASSP_LMCodec_LMCodec: A Low Bitrate Speech Codec with Causal Transformer Models. [IEEE ICASSP] [arXiv]
-
2024_ICLR_SpeechTokenizer_SpeechTokenizer: Unified Speech Tokenizer for Speech Language Models. [ICLR] [arXiv]
-
2025_ICASSP_LFSC_Low Frame-rate Speech Codec: A Codec Designed for Fast High-quality Speech LLM Training and Inference. [IEEE ICASSP] [arXiv]
-
2025_ICLR_TAAE_Scaling Transformers for Low-Bitrate High-Quality Speech Coding. [ICLR]
-
2020_AAAI_SNEQ_SNEQ: Semi-Supervised Attributed Network Embedding with Attention-Based Quantisation. [AAAI]
-
2020_ACL_TS-CL_Knowledge Graph Embedding Compression. [ACL]
-
2021_CIKM_LightKG_A Lightweight Knowledge Graph Embedding Framework for Efficient Inference and Storage. [ACM CIKM]
-
2021_TNNLS_d-SNEQ_SemiSupervised Network Embedding with Differentiable Deep Quantization. [IEEE TNNLS]
-
2023_ICLR_Mole-BERT_Mole-BERT: Rethinking Pre-Training Graph Neural Networks for Molecules. [ICLR]
-
2023_NeurIPS_IMoLD_Learning Invariant Molecular Representation in Latent Discrete Space. [NeurIPS] [arXiv]
-
2024_ICLR_MAPE-PPI_MAPE-PPI: Towards Effective and Efficient Protein-Protein Interaction Prediction via Microenvironment-Aware Protein Embedding. [ICLR] [arXiv]
-
2024_ICLR_VQGraph_VQGraph: Rethinking Graph Representation Space for Bridging GNNs and MLPs. [ICLR] [arXiv]
-
2024_NeurlPS_GFT_GFT: Graph Foundation Model with Transferable Tree Vocabulary. [NeurIPS] [arXiv]
-
2024_TMLR_DGAE_Discrete Graph Auto-Encoder. [OpenReview TMLR] [arXiv]
-
2025_arXiv_GT-SVQ_GT-SVQ: A Linear-Time Graph Transformer for Node Classification Using Spiking Vector Quantization. [arXiv]
-
2025_AAAI_GLAD_GLAD: Improving Latent Graph Generative Modeling with Simple Quantization. [AAAI] [ICML Workshop] [arXiv]
-
2025_ICLR_GQT_Learning Graph Quantized Tokenizers. [ICLR] [arXiv]
-
2025_ICLR_NID_Node Identifiers: Compact, Discrete Representations for Efficient Graph Learning. [ICLR] [arXiv]
-
2025_WWW_HQA-GAE_Hierarchical Vector Quantized Graph Autoencoder with Annealing-Based Code Selection. [WWW] [arXiv]
-
2021_arXiv_VideoGPT_VideoGPT: Video Generation using VQ-VAE :and Transformers. [arXiv] [Github]
-
2022_ECCV_TATS_Long Video Generation with Time-Agnostic VQGAN and Time-Sensitive Transformer. [ACM ECCV] [arXiv]
-
2023_CVPR_MAGVIT_MAGVIT: Masked Generative Video Transformer. [CVPR] [arXiv]
-
2023_ICLR_Phenaki_Phenaki: Variable Length Video Generation From Open Domain Textual Descriptions. [ICLR] [arXiv]
-
2024_arXiv_LARP_LARP: Tokenizing Videos with a Learned Autoregressive Generative Prior. [arXiv] [Github]
-
2024_arXiv_VidTok_VidTok: A Versatile and Open-Source Video Tokenizer. [arXiv]
-
2024_arXiv_VQ-NeRV_VQ-NeRV: A Vector Quantized Neural Representation for Videos. [arXiv] [Github]
-
2024_ICLR_MAGVIT-v2_Language Model Beats Diffusion: Tokenizer is Key to Visual Generation. [arXiv] [Github]
-
2024_NeurlPS_OmniTokenizer_OmniTokenizer: A Joint Image-Video Tokenizer for Visual Generation. [NeurIPS] [arXiv]
-
2025_arXiv_SweetTok_SweetTok: Semantic-Aware Spatial-Temporal Tokenizer for Compact Visual Discretization. [arXiv]
-
2025_arXiv_TVC_TVC: Tokenized Video Compression with Ultra-Low Bitrate. [arXiv]
-
2025_ICLR_BSQ_Image and Video Tokenization with Binary Spherical Quantization. [arXiv] [Github]
-
2023_CoLR_SAQ_Action-Quantized Offline Reinforcement Learning for Robotic Skill Learning. [arXiv] [Github]
-
2024_ICML_PRISE_PRISE: LLM-Style Sequence Compression for Learning Temporal Action Abstractions in Control. [ICML] [arXiv] [Github]
-
2021_ICML_DALL-E_Zero-Shot Text-to-Image Generation. [ICML] [arXiv]
-
2021_NeurIPS_CogView_CogView:Mastering Text-to-Image Generation via Transformers. [NeurIPS] [arXiv] [Github]
-
2022_CVPR_VQ-Diffusion_Vector Quantized Diffusion Model for Text-to-Image Synthesis. [CVPR] [IEEE CVPR] [arXiv] [Github]
-
2022_ECCV_Make-A-Scene_Make-A-Scene:Scene-Based Text-to-Image Generation with Human Priors. [ECCV] [arXiv] [Github]
-
2023_CVPR_NUWA-LIP_NUWA-LIP:Language-guided Image Inpainting with Defect-free VQGAN. [CVPR] [arXiv] [Github]
-
2023_ICLR_Unified-IO_Unified-IO: A unified model for vision, language, and multi-modal tasks. [ICLR] [arXiv]
-
2023_ICML_Muse_Muse: Text-to-Image Generation via Masked Generative Transformer. [ICML] [arXiv]
-
2024_arXiv_TexTok_Language-Guided Image Tokenization for Generation. [arXiv]
-
2024_NeurlPS_LG-VQ_LG-VQ: Language-Guided Codebook Learning. [NeurIPS] [arXiv] [Github]
-
2025_arXiv_TokLIP_TokLIP: Marry Visual Tokens to CLIP for Multimodal Comprehension and Generation. [arXiv] [Github]
-
2025_arXiv_UniTok_UniTok: A Unified Tokenizer for Visual Generation and Understanding. [arXiv] [Github]
-
2025_AAAI_MyGO_MyGO: Discrete Modality Information as Fine-Grained Tokens for Multi-modal Knowledge Graph Completion. [arXiv] [Github]
-
2025_ICLR_HART_HART: Efficient Visual Generation with Hybrid Autoregressive Transformer. [arXiv] [Github]
-
2023_ICLR_AudioGen_AudioGen:Textually Guided Audio Generation. [ICLR] [arXiv] [Github] [HuggingFace]
-
2024_arXiv_Spectral Codecs:Spectrogram-Based Audio Codecs for High Quality Speech Synthesis. [arXiv]
-
2023_arXiv_VALL-E X_Speak Foreign Languages with Your Own Voice:Cross-Lingual Neural Codec Language Modeling. [arXiv]
-
2023_arXiv_VALL-E_Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers. [arXiv]
-
2024_arXiv_RALL-E_RALL-E: Robust Codec Language Modeling with Chain-of-Thought Prompting for Text-to-Speech Synthesis. [arXiv]
-
2024_arXiv_SimpleSpeech 2_SimpleSpeech 2: Towards Simple and Efficient Text-to-Speech with Flow-based Scalar Latent Transformer Diffusion Models. [IEEE] [arXiv]
-
2024_ICML_NaturalSpeech 3_NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models. [ICML] [arXiv] [Mircosoft] [Github]
-
2024_Interspeech_SimpleSpeech_SimpleSpeech: Towards Simple and Efficient Text-to-Speech with Scalar Latent Transformer Diffusion Models. [arXiv] [Github]
-
2024_Interspeech_Single-Codec_Single-Codec: Single-Codebook Speech Codec towards High-Performance. [arXiv] [Github]
-
2025_ICLR_HALL-E_HALL-E: Hierarchical Neural Codec Language Mdoel for Minute-Long Zero-Shot Text-to-Speech Synthesis. [ICLR] [arXiv]
- 2025_CVIU_VQ-MAE-AV_A vector quantized masked autoencoder for audiovisual speech emotion recognition. [arXiv]
- 2024_CVPR_ProTalk_Towards Variable and Coordinated Holistic Co-Speech Motion Generation. [CVPR] [arXiv] [Github]
- 2025_AAAI_VQTalker_VQTalker: Towards Multilingual Talking Avatars through Facial Motion Tokenization. [AAAI] [arXiv] [Github]
- 2024_arXiv_WorldDreamer_WorldDreamer: Towards General World Models for Video Generation via Predicting Masked Tokens. [arXiv] [Github]
-
2020_WWW_MGQE_Learning Multi-granular Quantized Embeddings for Large-Vocab Categorical Features in Recommender Systems. [WWW] [arXiv]
-
2023_NeurlPS_TIGER_Recommender Systems with Generative Retrieval. [NeurIPS] [arXiv] [HuggingFace]
-
2023_TOIS_ReFRS_ReFRS: Resource-efficient Federated Recommender System for Dynamic and Diversified User Preferences. [ACM TOIS] [arXiv]
-
2023_WWW_VQ-Rec_Learning Vector-Quantized Item Representation for Transferable Sequential Recommenders. [WWW] [arXiv] [Github]
-
2024_KDD_EAGER_EAGER: Two-Stream Generative Recommender with Behavior-Semantic Collaboration. [KDD] [arXiv] [Github]
-
2024_RecSys_CoST_CoST: Contrastive Quantization based Semantic Tokenization for Generative Recommendation. [ACM RecSys] [arXiv]

-
2023_NeurIPS_SPAE_SPAE: Semantic Pyramid AutoEncoder for Multimoda Generation with Frozen LLMs. [NeurIPS] [ACM NeurIPS] [arXiv] [Github]
-
2023_NeurlPS_LQAE_Language Quantized AutoEncoders: Towards Unsupervised Text-Image Alignment. [NeurIPS] [arXiv]
-
2024_arXiv_LlamaGen_Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation. [arXiv] [Github]
-
2024_CVPR_V2T Tokenizer_Beyond Text: Frozen Large Language Models in Visual Signal Comprehension. [CVPR] [IEEE CVPR] [arXiv]
-
2024_ICML_StrokeNUWA_StrokeNUWA: Tokenizing Strokes for Vector Graphic Synthesis. [ICML] [ACM ICML] [arXiv] [Github] [HuggingFace]
-
2025_arXiv_V2Flow_V2Flow: Unifying Visual Tokenization and Large Language Model Vocabularies for Autoregressive Image Generation. [arXiv] [Github]
-
2023_NeurlPS_TWIST_Textually Pretrained Speech Language Models. [NeruIPS] [arXiv]
-
2024_arXiv_JTFS LM_Comparing Discrete and Continuous Space LLMs for Speech Recognition. [arXiv] [Github]
-
2024_arXiv_SSVC_Enhancing the Stability of LLM-based Speech Generation Systems through Self-Supervised Representations. [arXiv]
-
2025_ICLR_WavTokenizer_Wavtokenizer: An Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling. [OpenReview] [arXiv] [GitHub]
-
2024_arXiv_GLM-4-Voice_GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot. [arXiv] [GitHub] [HuggingFace]
-
2024_arXiv_NT-LLM_NT-LLM: A Novel Node Tokenizer for Integrating Graph Structure into Large Language Models. [arXiv]
-
2025_AAAI_Dr.E_Multi-View Empowered Structural Graph Wordification for Language Models. [AAAI] [arXiv]
- 2024_CVPR_LLM-AR_LLMs are Good Action Recognizers. [CVPR] [IEEE CVPR] [arXiv]
-
2024_arXiv_ETEGRec_Generative Recommender with End-to-End Learnable Item Tokenization. [arXiv]
-
2024_arXiv_META ID_Improving LLMs for Recommendation with Out-Of-Vocabulary Tokens. [ICML] [arXiv]
-
2024_arXiv_QARM_QARM: Quantitative Alignment Multi-Modal Recommendation at Kuaishou. [arXiv]
-
2024_arXiv_STORE_Streamlining Semantic Tokenization and Generative Recommendation with A Single LLM. [arXiv]
-
2024_arXiv_TokenRec_TokenRec: Learning to Tokenize ID for LLM-bsed Generative Recommendations. [arXiv] [Github]
-
2024_CIKM_ColaRec_Content-Based Collaborative Generation for Recommender Systems. [ACM CIKM] [arXiv] [Github]
-
2024_CIKM_LETTER_Learnable Item Tokenization for Generative Recommendation. [ACM CIKM] [arXiv] [Github]
-
2024_ICDE_LC-Rec_Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation. [arXiv] [Github] [HuggingFace]
-
2025_arXiv_UTGRec_Universal Item Tokenization for Transferable Generative Recommendation. [arXiv] [Github]
-
2025_AAAI_Semantic Convergence: Harmonizing Recommender Systems via Two-Stage Alignment and Behavioral Semantic Tokenization. [AAAI] [arXiv]
-
2025_WWW_EAGER-LLM_EAGER-LLM: Enhancing Large Language Models as Recommenders through Exogenous Behavior-Semantic Integration. [WWW] [arXiv] [Github]
-
2025_WWW_ED2_Unleash LLMs Potential for Sequential Recommendation by Coordinating Dual Dynamic Index Mechanism. [WWw] [arXiv]
-
2023_arXiv_SEED_Planting a SEED of Vision in Large Language Model. [arXiv] [Github]
-
2024_arXiv_Chameleon_Chameleon: Mixed-Modal Early-Fusion Foundation Models. [arXiv] [Github]
-
2024_arXiv_ILLUME_ILLUME: Illuminating Your LLMs to See, Draw, and Self-Enhance. [arXiv]
-
2024_arXiv_Janus_Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation. [CVPR] [arXiv]
-
2024_arXiv_Lumina-mGPT_Lumina-mGPT: Illuminate Flexible Photorealistic Text-to-Image Generation with Multimodal Generative Pretraining. [arXiv] [Github]
-
2024_arXiv_MUSE-VL_MUSE-VL: Modeling Unified VLM through Semantic Discrete Encoding. [arXiv]
-
2024_arXiv_Show-o_Show-o: One single transformer to unify multimodal understanding and generation. [arXiv] [Github]
-
2024_arXiv_Liquid_Liquid: Language Models are Scalable and Unified Multi-modal Generators. [arXiv] [Github]
-
2024_ICLR_LaVIT_Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization. [ICLR] [arXiv] [Github]
-
2024_ICLR_SEED-LLaMA_Making LLaMA SEE and Draw with SEED Tokenizer. [ICLR] [arXiv] [Github]
-
2024_ICML_Libra_Libra: Building Decoupled Vision System on Large Language Models. [ICML] [arXiv] [Github]
-
2024_ICML_Morph-Tokens_Auto-Encoding Morph-Tokens for Multimodal LLM. [ICML] [arXiv] [Github]
-
2025_arXiv_DDT-LLaMA_Generative Multimodal Pretraining with Discrete Diffusion Timestep Tokens. [arXiv] [Github]
-
2025_arXiv_ETT_End-to-End-Vision Tokenizer Tuning. [arXiv] [HuggingFace]
-
2025_arXiv_FashionM3_FashionM3: Multimodal, Multitask, and Multiround Fashion Assistant based on Unified Vision-Language Model. [arXiv]
-
2025_arXiv_HiMTok_HiMTok: Learning Hierarchical Mask Tokens for Image Segmentation with Large Multimodal Model. [arXiv] [Github] [HuggingFace]
-
2025_arXiv_ILLUME+_ILLUME+: Illuminating Unified MLLM with Dual Visual Tokenization and Diffusion Refinement. [arXiv] [Github]
-
2025_arXiv_Janus-Pro_Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling. [arXiv]
-
2025_arXiv_QLIP_QLIP: Text-Aligned Visual Tokenization Unifies Auto-Regressive Multimodal Understanding and Generation. [arXiv] [Github]
-
2025_arXiv_SemHiTok_SemHiTok: A Unified Image Tokenizer via Semantic-Guided Hierarchical Codebook for Multimodal Understanding and Generation. [arXiv]
-
2025_arXiv_UniToken_UniToken: Harmonizing Multimodal Understanding and Generation through Unified Visual Encoding. [arXiv] [Github]
-
2025_arXv_Token-Shuffle_Token-Shuffle: Towards High-Resolution Image Generation with Autoregressive Models. [arXiv] [Github] [HuggingFace]
-
2025_AAAI_MARS_MARS: Mixture of Auto-Regressive Models for Fine-grained Text-to-image Synthesis. [AAAI] [arXiv] [Github]
-
2025_CVPR_TokenFlow_TokenFlow: Unified Image Tokenizer for Multimodal Understanding and Generation. [CVPR] [arXiv] [Github]
-
2025_ICLR_ClawMachine_ClawMachine: Fetching Visual Tokens as An Entity for Referring and Grounding. [ICLR] [arXiv]
-
2025_arXiv_Unicode2_Unicode2: Cascaded-Large-scale-Codebooks-for-Unified-Multimodal-Understanding-and-Generation. [arXiv]
-
2023_arXiv_AudioPaLM_AudioPaLM: A Large Language Model That Can Speak and Listen. [arXiv] [HuggingFace] [Youtube]
-
2023_arXiv_LauraGPT_LauraGPT: Listen, Attend, Understand, and Regenerate Audio with GPT. [arXiv] [Github]
-
2023_EMNLP_SpeechGPT_SpeechGPT: Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities. [ENMLP] [arXiv] [Github] [HuggingFace]
-
2024_arXiv_SpeechGPT-Gen_SpeechGPT-Gen=Scaling Chain-of-Information Speech Generation. [arXiv] [Github] [Demo]
-
2024_arXiv_CosyVoice 2_CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models. [arXiv] [Github]
-
2024_arXiv_CosyVoice_CosyVoice_A Scalable Multilingual Zero-shot Text-to-Speech Synthesizer based on Supervised Semantic Tokens. [arXiv] [Github]
-
2024_arXiv_IntrinsicVoice_IntrinsicVoice: Empowering LLMs with Intrinsic Real-time Voice Interaction Abilities. [arXiv]
-
2024_arXiv_Moshi_Moshi: a speech-text foundation model for real-time dialogue. [arXiv] [Github]
-
2024_arXiv_OmniFlatten_OmniFlatten: An End-to-end GPT Model for Seamless Voice Conversation. [arXiv]
-
2024_arXiv_T5-TTS_Improving Robustness of LLM-based Speech Synthesis by Learning Monotonic Alignment. [arXiv] [Github]
-
2024_ICASSP_VoxtLM_VoxtLM: Unified Decoder-Only Models for Consolidating Speech Recognition, Synthesis and Speech, Text Continuation Tasks. [IEEE ICASSP] [arXiv] [Github]
-
2024_IEEE Signal Processing Letters_MSRT_Tuning Large Language Model for Speech Recognition With Mixed-Scale Re-Tokenization. [IEEE Signal Processing Letters]
-
2024_Interspeech_DiscreteSLU_DiscreteSLU: A Large Language Model with Self-Supervised Discrete Speech Units for Spoken Language Understanding. [arXiv] [HuggingFace]
-
2024_MM_GPT-Talker_Generative Expressive Conversational Speech Synthesis. [ACM MM] [arXiv] [Github]
-
2025_arXiv_Spark-TTS_Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens. [arXiv] [Github]
-
2025_Kimi-Audio_Kimi-Audio Technical Report. [arXiv] [Github] [HuggingFace]
-
2024_arXiv_Loong_Loong: Generating Minute-level Long Videos with Autoregressive Language Models. [arXiv] [Github] [HuggingFace]
-
2024_ICML_Video-LaVIT_Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization. [ICML] [ACM ICML] [arXiv] [Github]
-
2025_arXiv_HiTVideo_HiTVideo: Hierarchical Tokenizers for Enhancing Text-to-Video Generation with Autoregressive Large Language Models. [arXiv] [Github]
-
2024_arXiv_UniMoT_UniMoT: Unified Molecule-Text Language Model with Discrete Token Representation. [arXiv] [Github]
-
2024_ICML Workshop_HIGHT_Improving Graph-Language Alignment with Hierarchical Graph Tokenization. [OpenReview ICML Workshop]
-
2025_arXiv_MedTok_Multimodal Medical Code Tokenizer. [arXiv]
-
2025_arXiv_SSQR_Self-Supervised Quantized Representation for Seamlessly Integrating Knowledge Graphs with Large Language Models. [arXiv] [HuggingFace]
-
2024_arXiv_MotionGlot_MotionGlot: A Multi-Embodied Motion Generation Model. [arXiv] [Demo] [Github]
-
2024_CVPR_AvatarGPT_AvatarGPT: All-in-One Framework for Motion Understanding, Planning, Generation and Beyond. [CVPR] [IEEE CVPR] [arXiv] [Github]
-
2024_ECCV_Semgrasp_Semgrasp_Semantic grasp generation via language aligned discretization. [ACM ECCV] [arXiv]
-
2024_IV_Walk-the-Talk_Walk-the-Talk: LLM driven Pedestrian Motion Generation. [IEEE IV]
-
2023_arXiv_TEAL_TEAL: Tokenize and Embed ALL for Multi-modal Large Language Models. [arXiv]
-
2024_arXiv_DMLM_Discrete Multimodal Transformers with A Pretrained Large Language Model for Mixed-Supervision Speech Processing. [arXiv]
-
2024_ACL_AnyGPT_AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling. [ACL] [arXiv] [Github] [HuggingFace] [Youtube] [Bilibili]
-
2024_arXiv_Emu3: Next-Token Prediction is All You Need. [arXiv] [Github] [Youtube]
-
2025_ICLR_LWM_World model on million-length video and language with blockwise ringattention. [ICLR] [arXiv] [Github] [HuggingFace] [YouTube]
-
2025_ICLR_VILA-U_VILA-U: A Unified Foundation Model Integrating Visual Understanding and Generation. [ICLR] [arXiv] [HuggingFace]
- 2025_ICCGV_LLM Gesticulator_LLM Gesticulator: Levaraging Large Language Models for Scalable and Controllable Co-Speech Gesture Synthesis. [arXiv] [Github]
- 2024_CVPR_Unified-IO 2_Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action. [CVPR] [IEEE CVPR] [arXiv] [HuggingFace]
-
2024_arXiv_MIO_MIO: A foundation model on multimodal tokens. [arXiv] [HuggingFace] [YouTube]
-
2024_ICML_VideoPoet_VideoPoet: A Large Language Model for Zero-Shot Video Generation. [ICML] [arXiv] [HuggingFace] [Youtube]

-
1988_IEEE Transactions on Communications_Survey_Image Coding Using Vector Quantization: A Review.
-
1989_IEEE Transactions on Information Theory_Survey_High-Resolution Quantization Theory and the Vector Quantizer Advantage.
-
1990_IEEE Transactions on Information Theory_Survey_A Study of Vector Quantization for Noisy Channels.
-
1996_TIP_Survey_Advances in Residual Vector Quantization:A Review.
-
1998_IEEE transactions on information theory_Survey_Quantization.
-
2006_IEEE Potentials_Survey_A review of vector quantization techniques.
-
2010_IHMSP_Survey_A Survey of VQ Codebook Generation.
-
2018_MTA_Survey_A Survey of Product Quantization.
-
2019_Frontiers of Information Technology & Electronic Engineering_Survey_Vector quantization:a review.
-
2023_ACM Computing Surveys_Survey_Embedding in Recommender Systems: A Survey.
-
2024_arXiv_Survey_Vector quantization for recommender systems:a review and outlook.
-
2024_ACM Computing Surveys_Survey_Embedding Compression in Recommender Systems: A Survey.
-
2024_Data Engineering_Survey_High-Dimensional Vector Quantization:General Framework, Recent Advances, and Future Directions.
-
2024_arXIv_Survey_Next Token Prediction Towards Multimodal Intelligence:A Comprehensive Survey.
-
2024_PrePrints_Survey_Continuous or Discrete, That is the Question=A Survey on Large Multi-Modal Models from the Perspective of Input-Output Space Extension.
-
2025_arXiv_Survey_A Survey of Quantized Graph Representation Learning= Connecting Graph Structures with Large Language Models.
-
2025_arXiv_Survey_From Principles to Applications: A Comprehensive Survey of Discrete Tokenizers in Generation, Comprehension, Recommendation, and Information Retrieval.
-
2025_arXiv_Survey_Recent Advances in Discrete Speech Tokens:A Review.
-
2025_TMLR_Survey_Autoregressive Models in Vision:A Survey.
The following works are recommended by their authors after the initial release of this survey and will be added to the revised version and this repository. We sincerely thank them for their contributions to enriching the coverage of this work.
-
2024_arXiv_Liquid_Liquid: Language Models are Scalable and Unified Multi-modal Generators. (5.1 Text + Image)
Authors: Junfeng Wu et al. (HUST & ByteDance)
[arXiv] [Github] (Added on August 9, 2025, following the authors’ kind recommendation)
If you compare with, build on, or use aspects of this work, please cite the following:
@article{li2025discrete,
title={Discrete Tokenization for Multimodal LLMs: A Comprehensive Survey},
author={Li, Jindong and Fu, Yali and Liu, Jiahong and Cao, Linxiao and Ji, Wei and Yang, Menglin and King, Irwin and Yang, Ming-Hsuan},
journal={arXiv preprint arXiv:2507.22920},
year={2025}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLM-Discrete-Tokenization-Survey
Similar Open Source Tools
LLM-Discrete-Tokenization-Survey
The repository contains a comprehensive survey paper on Discrete Tokenization for Multimodal Large Language Models (LLMs). It covers various techniques, applications, and challenges related to discrete tokenization in the context of LLMs. The survey explores the use of vector quantization, product quantization, and other methods for tokenizing different modalities like text, image, audio, video, graph, and more. It also discusses the integration of discrete tokenization with LLMs for tasks such as image generation, speech recognition, recommendation systems, and multimodal understanding and generation.
Efficient_Foundation_Model_Survey
Efficient Foundation Model Survey is a comprehensive analysis of resource-efficient large language models (LLMs) and multimodal foundation models. The survey covers algorithmic and systemic innovations to support the growth of large models in a scalable and environmentally sustainable way. It explores cutting-edge model architectures, training/serving algorithms, and practical system designs. The goal is to provide insights on tackling resource challenges posed by large foundation models and inspire future breakthroughs in the field.
Awesome-Efficient-AIGC
This repository, Awesome Efficient AIGC, collects efficient approaches for AI-generated content (AIGC) to cope with its huge demand for computing resources. It includes efficient Large Language Models (LLMs), Diffusion Models (DMs), and more. The repository is continuously improving and welcomes contributions of works like papers and repositories that are missed by the collection.
awesome-llm-understanding-mechanism
This repository is a collection of papers focused on understanding the internal mechanism of large language models (LLM). It includes research on topics such as how LLMs handle multilingualism, learn in-context, and handle factual associations. The repository aims to provide insights into the inner workings of transformer-based language models through a curated list of papers and surveys.
Awesome-System2-Reasoning-LLM
The Awesome-System2-Reasoning-LLM repository is dedicated to a survey paper titled 'From System 1 to System 2: A Survey of Reasoning Large Language Models'. It explores the development of reasoning Large Language Models (LLMs), their foundational technologies, benchmarks, and future directions. The repository provides resources and updates related to the research, tracking the latest developments in the field of reasoning LLMs.
Awesome-Code-LLM
Analyze the following text from a github repository (name and readme text at end) . Then, generate a JSON object with the following keys and provide the corresponding information for each key, in lowercase letters: 'description' (detailed description of the repo, must be less than 400 words,Ensure that no line breaks and quotation marks.),'for_jobs' (List 5 jobs suitable for this tool,in lowercase letters), 'ai_keywords' (keywords of the tool,user may use those keyword to find the tool,in lowercase letters), 'for_tasks' (list of 5 specific tasks user can use this tool to do,in lowercase letters), 'answer' (in english languages)
Awesome-LLM-Inference
Awesome-LLM-Inference: A curated list of 📙Awesome LLM Inference Papers with Codes, check 📖Contents for more details. This repo is still updated frequently ~ 👨💻 Welcome to star ⭐️ or submit a PR to this repo!
NL2SQL_Handbook
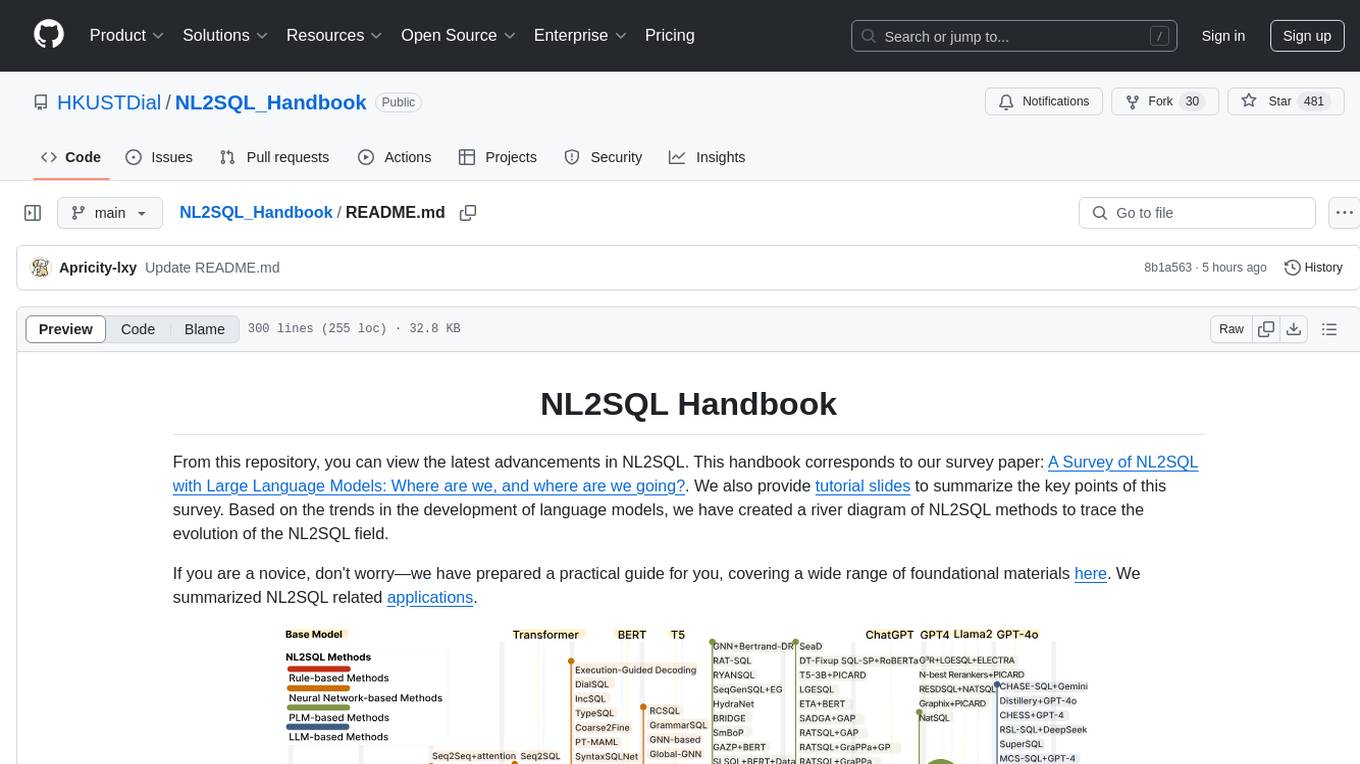
NL2SQL Handbook provides a comprehensive overview of Natural Language to SQL (NL2SQL) advancements, including survey papers, tutorial slides, and a river diagram of NL2SQL methods. It covers the evolution of NL2SQL solutions, module-based methods, benchmark development, and future directions. The repository also offers practical guides for beginners, access to high-performance language models, and evaluation metrics for NL2SQL models.
awesome-LLM-AIOps
The 'awesome-LLM-AIOps' repository is a curated list of academic research and industrial materials related to Large Language Models (LLM) and Artificial Intelligence for IT Operations (AIOps). It covers various topics such as incident management, log analysis, root cause analysis, incident mitigation, and incident postmortem analysis. The repository provides a comprehensive collection of papers, projects, and tools related to the application of LLM and AI in IT operations, offering valuable insights and resources for researchers and practitioners in the field.
lobe-cli-toolbox
Lobe CLI Toolbox is an AI CLI Toolbox designed to enhance git commit and i18n workflow efficiency. It includes tools like Lobe Commit for generating Gitmoji-based commit messages and Lobe i18n for automating the i18n translation process. The toolbox also features Lobe label for automatically copying issues labels from a template repo. It supports features such as automatic splitting of large files, incremental updates, and customization options for the OpenAI model, API proxy, and temperature.
Awesome-Quantization-Papers
This repo contains a comprehensive paper list of **Model Quantization** for efficient deep learning on AI conferences/journals/arXiv. As a highlight, we categorize the papers in terms of model structures and application scenarios, and label the quantization methods with keywords.
LLM-IR-Bias-Fairness-Survey
LLM-IR-Bias-Fairness-Survey is a collection of papers related to bias and fairness in Information Retrieval (IR) with Large Language Models (LLMs). The repository organizes papers according to a survey paper titled 'Bias and Unfairness in Information Retrieval Systems: New Challenges in the LLM Era'. The survey provides a comprehensive review of emerging issues related to bias and unfairness in the integration of LLMs into IR systems, categorizing mitigation strategies into data sampling and distribution reconstruction approaches.
LLMFarm
LLMFarm is an iOS and MacOS app designed to work with large language models (LLM). It allows users to load different LLMs with specific parameters, test the performance of various LLMs on iOS and macOS, and identify the most suitable model for their projects. The tool is based on ggml and llama.cpp by Georgi Gerganov and incorporates sources from rwkv.cpp by saharNooby, Mia by byroneverson, and LlamaChat by alexrozanski. LLMFarm features support for MacOS (13+) and iOS (16+), various inferences and sampling methods, Metal compatibility (not supported on Intel Mac), model setting templates, LoRA adapters support, LoRA finetune support, LoRA export as model support, and more. It also offers a range of inferences including LLaMA, GPTNeoX, Replit, GPT2, Starcoder, RWKV, Falcon, MPT, Bloom, and others. Additionally, it supports multimodal models like LLaVA, Obsidian, and MobileVLM. Users can customize inference options through JSON files and access supported models for download.
EvalAI
EvalAI is an open-source platform for evaluating and comparing machine learning (ML) and artificial intelligence (AI) algorithms at scale. It provides a central leaderboard and submission interface, making it easier for researchers to reproduce results mentioned in papers and perform reliable & accurate quantitative analysis. EvalAI also offers features such as custom evaluation protocols and phases, remote evaluation, evaluation inside environments, CLI support, portability, and faster evaluation.
For similar tasks
stable-diffusion-webui
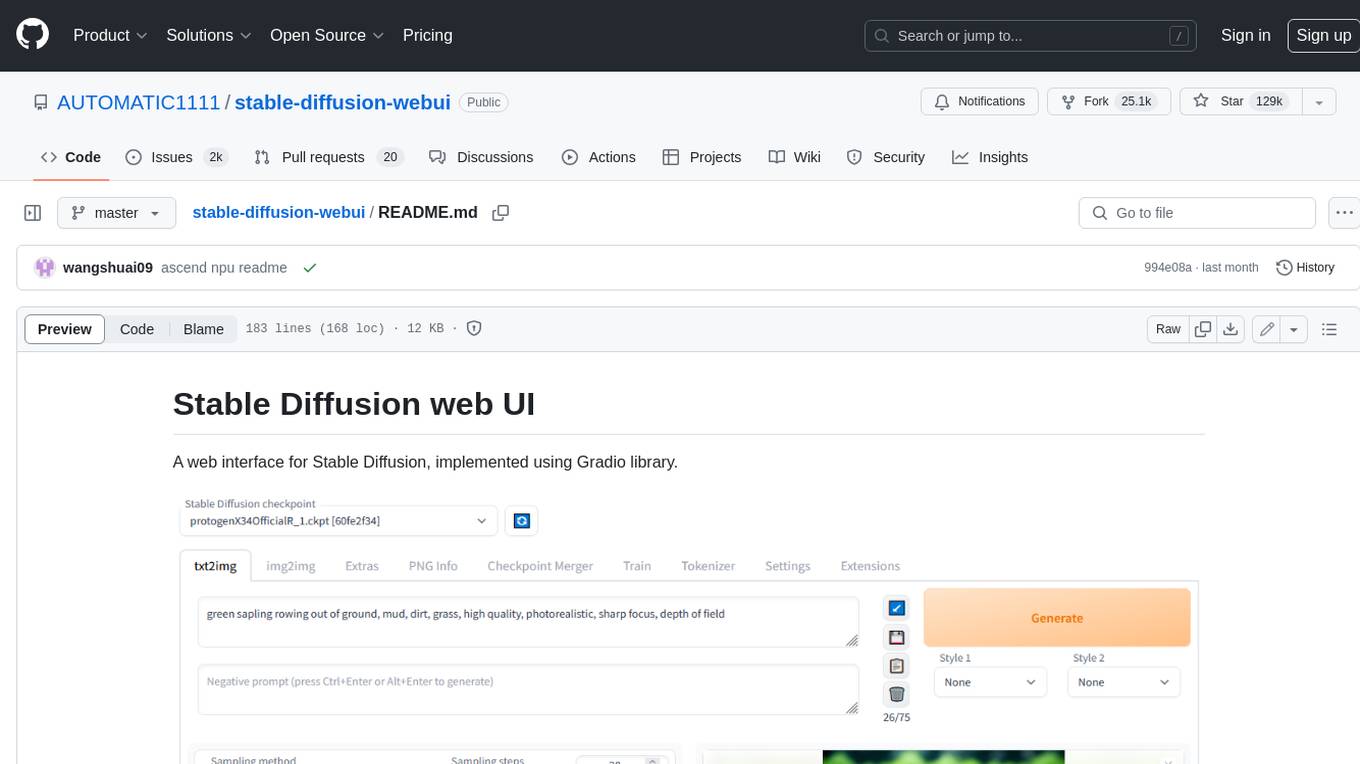
Stable Diffusion web UI is a web interface for Stable Diffusion, implemented using Gradio library. It provides a user-friendly interface to access the powerful image generation capabilities of Stable Diffusion. With Stable Diffusion web UI, users can easily generate images from text prompts, edit and refine images using inpainting and outpainting, and explore different artistic styles and techniques. The web UI also includes a range of advanced features such as textual inversion, hypernetworks, and embeddings, allowing users to customize and fine-tune the image generation process. Whether you're an artist, designer, or simply curious about the possibilities of AI-generated art, Stable Diffusion web UI is a valuable tool that empowers you to create stunning and unique images.
llmblueprint
LLM Blueprint is an official implementation of a paper that enables text-to-image generation with complex and detailed prompts. It leverages Large Language Models (LLMs) to extract critical components from text prompts, including bounding box coordinates for foreground objects, detailed textual descriptions for individual objects, and a succinct background context. The tool operates in two phases: Global Scene Generation creates an initial scene using object layouts and background context, and an Iterative Refinement Scheme refines box-level content to align with textual descriptions, ensuring consistency and improving recall compared to baseline diffusion models.

GIMP-ML
A.I. for GNU Image Manipulation Program (GIMP-ML) is a repository that provides Python plugins for using computer vision models in GIMP. The code base and models are continuously updated to support newer and more stable functionality. Users can edit images with text, outpaint images, and generate images from text using models like Dalle 2 and Dalle 3. The repository encourages citations using a specific bibtex entry and follows the MIT license for GIMP-ML and the original models.

ClaraVerse
ClaraVerse is a privacy-first AI assistant and agent builder that allows users to chat with AI, create intelligent agents, and turn them into fully functional apps. It operates entirely on open-source models running on the user's device, ensuring data privacy and security. With features like AI assistant, image generation, intelligent agent builder, and image gallery, ClaraVerse offers a versatile platform for AI interaction and app development. Users can install ClaraVerse through Docker, native desktop apps, or the web version, with detailed instructions provided for each option. The tool is designed to empower users with control over their AI stack and leverage community-driven innovations for AI development.
sora-prompt
Sora Prompt Collection is a repository dedicated to inspiring AI-driven video creation with Sora, an AI model that can create realistic and imaginative scenes from text instructions. The repository provides prompt words and video generation tips to help users quickly start using Sora for text-to-video, animation, video editing, image generation, and more. It offers a variety of examples ranging from stylish urban scenes to fantastical creatures in vibrant settings. Users can find prompt examples based on different video styles and modify them as needed.
LLM-Discrete-Tokenization-Survey
The repository contains a comprehensive survey paper on Discrete Tokenization for Multimodal Large Language Models (LLMs). It covers various techniques, applications, and challenges related to discrete tokenization in the context of LLMs. The survey explores the use of vector quantization, product quantization, and other methods for tokenizing different modalities like text, image, audio, video, graph, and more. It also discusses the integration of discrete tokenization with LLMs for tasks such as image generation, speech recognition, recommendation systems, and multimodal understanding and generation.
emeltal
Emeltal is a local ML voice chat tool that uses high-end models to provide a self-contained, user-friendly out-of-the-box experience. It offers a hand-picked list of proven open-source high-performance models, aiming to provide the best model for each category/size combination. Emeltal heavily relies on the llama.cpp for LLM processing, and whisper.cpp for voice recognition. Text rendering uses Ink to convert between Markdown and HTML. It uses PopTimer for debouncing things. Emeltal is released under the terms of the MIT license, and all model data which is downloaded locally by the app comes from HuggingFace, and use of the models and data is subject to the respective license of each specific model.

edenai-apis
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.