
llm-benchmarks
Popular LLM benchmarks for ruby code generation
Stars: 74
LLM Benchmarks is a tool designed for benchmarking AI models' performance and debugging capabilities. It provides comprehensive metrics, automated testing, and an interactive website for exploring results. The tool aims to ensure fair competition among models by tracking and comparing results consistently. LLM Benchmarks also emphasizes transparency through open-source code and public results. Users can contribute by adding new model implementations, benchmark types, improving the website, optimizing benchmarks, or enhancing documentation.
README:
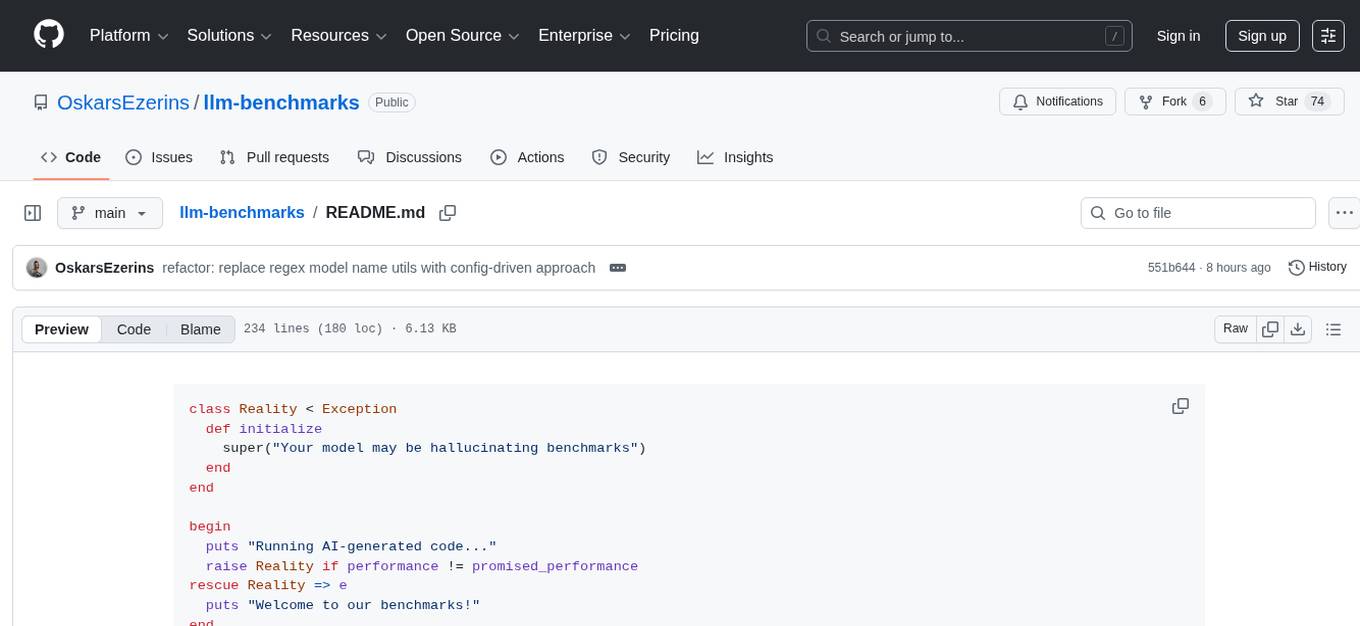
class Reality < Exception
def initialize
super("Your model may be hallucinating benchmarks")
end
end
begin
puts "Running AI-generated code..."
raise Reality if performance != promised_performance
rescue Reality => e
puts "Welcome to our benchmarks!"
end

See real-time rankings, detailed metrics, and comprehensive analysis of AI model performance across all benchmark types
unless RUBY_VERSION >= "3.4.0"
puts "⚠️ Hold up! We need Ruby 3.4+ for this party! ⚠️"
exit
end
puts "✨ You're good to go! Let's benchmark some AI! ✨"module BenchmarkFeatures
class << self
def dual_benchmark_types
# Two comprehensive benchmark categories
{
performance: "⚡️ Raw speed & memory efficiency tests",
program_fixer: "🛠️ AI debugging & code repair challenges"
}
end
def automated_testing
# One command for both running benchmarks and generating implementations
system("bin/main")
end
def implementation_generation
# Automatic implementation generation with OpenRouter models
# powered by ruby_llm gem
available_models = true
easy_setup = true
consistent_results = true
puts "✨ AI-powered solution generation" if available_models && easy_setup && consistent_results
end
def interactive_website
# Modern React Router website for exploring results
{
real_time_rankings: true,
detailed_metrics: true,
model_comparisons: true,
benchmark_insights: true
}
end
def fair_competition
models.each do |model|
# Each model gets the same prompt
# Each implementation is saved with a timestamp
# Results are tracked and compared consistently
end
end
def comprehensive_metrics
{
performance: {
speed: "⚡️ Microseconds matter",
memory: "🧠 Every byte counts",
complexity: "🤯 O(n) or go home"
},
program_fixer: {
test_success: "✅ Tests passing ratio",
syntax_validity: "� Clean, compilable code",
rubocop_score: "💎 Ruby style compliance"
}
}
end
def transparency
open_source = true
results_public = true
bias = nil # We don't do that here
puts "Trust through code, not words" if open_source && results_public && bias.nil?
end
private
def marketing_buzz
raise NotImplementedError, "We prefer cold, hard benchmarks"
end
end
end
# No AI models were permanently harmed in the making of these benchmarks
# (They just learned some humility)# Clone this beauty
git clone https://github.com/OskarsEzerins/llm-benchmarks
cd llm-benchmarks
# Install dependencies
bundle install
# Choose your adventure 🎮
bin/main
# Interactive menu with options:
# 1. 🏃♂️ Run benchmarks with existing implementations
# - Performance benchmarks (speed & memory)
# - Program fixer benchmarks (debugging challenges)
# 2. 🤖 Generate new AI implementations with OpenRouter models
# - 44+ models available
# - Automated prompt-to-implementation pipeline
# See detailed results by category
bin/show_all_results
# See combined rankings across all benchmark types
bin/show_total_rankings
# 🌐 Launch the website locally (optional)
cd website
pnpm install
pnpm dev # runs bin/aggregate_results automatically via predev hookAdding a new model? Also add its slug → display name entry to
config/model_names.jsonat the repo root.bin/aggregate_resultsreads this file at build time and bakes the display name into the website's data. The JSON is bundled statically by Vite, so it works on Vercel without any runtime filesystem access.
if you.have_ideas? && you.like_benchmarks?
puts "We'd love your help!"
fork_it
create_branch
push_changes
pull_request
else
puts "No pressure! Star us and come back later!"
end- Add new model implementations: Run a model against all benchmarks and open a PR with the results. See #19 as an example.
- Add new benchmark types: Got a clever challenge for AI models?
- Improve the website: Make those charts even prettier
- Optimize benchmarks: More accurate, more fair, more challenging
- Documentation: Help others understand the madness
📦 LLM_BENCHMARKS
┣ 📂 benchmarks # Where AI models face their destiny
┃ ┣ 📂 performance # ⚡️ Speed & memory challenges
┃ ┗ 📂 program_fixer # 🛠️ Code debugging challenges
┣ 📂 implementations # AI's best attempts at glory
┃ ┣ 📂 performance # Generated speed solutions
┃ ┗ 📂 program_fixer # Generated debugging fixes
┣ 📂 config # Shared config (model_names.json — slug → display name)
┣ 📂 lib # Our benchmark orchestration tools
┣ 📂 results # The cold, hard truth (JSON data)
┣ 📂 website # 🌐 Interactive results dashboard
┗ 📂 bin # Press buttons, get answers
Performance Benchmarks ⚡️
- CSV data processing at scale
- Graph shortest path algorithms
- LRU cache implementations
- Run-length encoding optimization
Program Fixer Benchmarks 🛠️
- Calendar system debugging
- Parking garage logic repair
- School library management fixes
- Vending machine state handling
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-benchmarks
Similar Open Source Tools
llm-benchmarks
LLM Benchmarks is a tool designed for benchmarking AI models' performance and debugging capabilities. It provides comprehensive metrics, automated testing, and an interactive website for exploring results. The tool aims to ensure fair competition among models by tracking and comparing results consistently. LLM Benchmarks also emphasizes transparency through open-source code and public results. Users can contribute by adding new model implementations, benchmark types, improving the website, optimizing benchmarks, or enhancing documentation.
aiconfig
AIConfig is a framework that makes it easy to build generative AI applications for production. It manages generative AI prompts, models and model parameters as JSON-serializable configs that can be version controlled, evaluated, monitored and opened in a local editor for rapid prototyping. It allows you to store and iterate on generative AI behavior separately from your application code, offering a streamlined AI development workflow.

aiscript
AIScript is a unique programming language and web framework written in Rust, designed to help developers effortlessly build AI applications. It combines the strengths of Python, JavaScript, and Rust to create an intuitive, powerful, and easy-to-use tool. The language features first-class functions, built-in AI primitives, dynamic typing with static type checking, data validation, error handling inspired by Rust, a rich standard library, and automatic garbage collection. The web framework offers an elegant route DSL, automatic parameter validation, OpenAPI schema generation, database modules, authentication capabilities, and more. AIScript excels in AI-powered APIs, prototyping, microservices, data validation, and building internal tools.

Biomni
Biomni is a general-purpose biomedical AI agent designed to autonomously execute a wide range of research tasks across diverse biomedical subfields. By integrating cutting-edge large language model (LLM) reasoning with retrieval-augmented planning and code-based execution, Biomni helps scientists dramatically enhance research productivity and generate testable hypotheses.

uzu
uzu is a high-performance inference engine for AI models on Apple Silicon. It features a simple, high-level API, hybrid architecture for GPU kernel computation, unified model configurations, traceable computations, and utilizes unified memory on Apple devices. The tool provides a CLI mode for running models, supports its own model format, and offers prebuilt Swift and TypeScript frameworks for bindings. Users can quickly start by adding the uzu dependency to their Cargo.toml and creating an inference Session with a specific model and configuration. Performance benchmarks show metrics for various models on Apple M2, highlighting the tokens/s speed for each model compared to llama.cpp with bf16/f16 precision.

arbigent
Arbigent (Arbiter-Agent) is an AI agent testing framework designed to make AI agent testing practical for modern applications. It addresses challenges faced by traditional UI testing frameworks and AI agents by breaking down complex tasks into smaller, dependent scenarios. The framework is customizable for various AI providers, operating systems, and form factors, empowering users with extensive customization capabilities. Arbigent offers an intuitive UI for scenario creation and a powerful code interface for seamless test execution. It supports multiple form factors, optimizes UI for AI interaction, and is cost-effective by utilizing models like GPT-4o mini. With a flexible code interface and open-source nature, Arbigent aims to revolutionize AI agent testing in modern applications.

labo
LABO is a time series forecasting and analysis framework that integrates pre-trained and fine-tuned LLMs with multi-domain agent-based systems. It allows users to create and tune agents easily for various scenarios, such as stock market trend prediction and web public opinion analysis. LABO requires a specific runtime environment setup, including system requirements, Python environment, dependency installations, and configurations. Users can fine-tune their own models using LABO's Low-Rank Adaptation (LoRA) for computational efficiency and continuous model updates. Additionally, LABO provides a Python library for building model training pipelines and customizing agents for specific tasks.

ControlLLM
ControlLLM is a framework that empowers large language models to leverage multi-modal tools for solving complex real-world tasks. It addresses challenges like ambiguous user prompts, inaccurate tool selection, and inefficient tool scheduling by utilizing a task decomposer, a Thoughts-on-Graph paradigm, and an execution engine with a rich toolbox. The framework excels in tasks involving image, audio, and video processing, showcasing superior accuracy, efficiency, and versatility compared to existing methods.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

bigcodebench
BigCodeBench is an easy-to-use benchmark for code generation with practical and challenging programming tasks. It aims to evaluate the true programming capabilities of large language models (LLMs) in a more realistic setting. The benchmark is designed for HumanEval-like function-level code generation tasks, but with much more complex instructions and diverse function calls. BigCodeBench focuses on the evaluation of LLM4Code with diverse function calls and complex instructions, providing precise evaluation & ranking and pre-generated samples to accelerate code intelligence research. It inherits the design of the EvalPlus framework but differs in terms of execution environment and test evaluation.

exospherehost
Exosphere is an open source infrastructure designed to run AI agents at scale for large data and long running flows. It allows developers to define plug and playable nodes that can be run on a reliable backbone in the form of a workflow, with features like dynamic state creation at runtime, infinite parallel agents, persistent state management, and failure handling. This enables the deployment of production agents that can scale beautifully to build robust autonomous AI workflows.

ProX
ProX is a lm-based data refinement framework that automates the process of cleaning and improving data used in pre-training large language models. It offers better performance, domain flexibility, efficiency, and cost-effectiveness compared to traditional methods. The framework has been shown to improve model performance by over 2% and boost accuracy by up to 20% in tasks like math. ProX is designed to refine data at scale without the need for manual adjustments, making it a valuable tool for data preprocessing in natural language processing tasks.
flow-prompt
Flow Prompt is a dynamic library for managing and optimizing prompts for large language models. It facilitates budget-aware operations, dynamic data integration, and efficient load distribution. Features include CI/CD testing, dynamic prompt development, multi-model support, real-time insights, and prompt testing and evolution.
basic-memory
Basic Memory is a tool that enables users to build persistent knowledge through natural conversations with Large Language Models (LLMs) like Claude. It uses the Model Context Protocol (MCP) to allow compatible LLMs to read and write to a local knowledge base stored in simple Markdown files on the user's computer. The tool facilitates creating structured notes during conversations, maintaining a semantic knowledge graph, and keeping all data local and under user control. Basic Memory aims to address the limitations of ephemeral LLM interactions by providing a structured, bi-directional, and locally stored knowledge management solution.

OpenMusic
OpenMusic is a repository providing an implementation of QA-MDT, a Quality-Aware Masked Diffusion Transformer for music generation. The code integrates state-of-the-art models and offers training strategies for music generation. The repository includes implementations of AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. Users can train or fine-tune the model using different strategies and datasets. The model is well-pretrained and can be used for music generation tasks. The repository also includes instructions for preparing datasets, training the model, and performing inference. Contact information is provided for any questions or suggestions regarding the project.

AutoAgent
AutoAgent is a fully-automated and zero-code framework that enables users to create and deploy LLM agents through natural language alone. It is a top performer on the GAIA Benchmark, equipped with a native self-managing vector database, and allows for easy creation of tools, agents, and workflows without any coding. AutoAgent seamlessly integrates with a wide range of LLMs and supports both function-calling and ReAct interaction modes. It is designed to be dynamic, extensible, customized, and lightweight, serving as a personal AI assistant.
For similar tasks
ai4math-papers
The 'ai4math-papers' repository contains a collection of research papers related to AI applications in mathematics, including automated theorem proving, synthetic theorem generation, autoformalization, proof refactoring, premise selection, benchmarks, human-in-the-loop interactions, and constructing examples/counterexamples. The papers cover various topics such as neural theorem proving, reinforcement learning for theorem proving, generative language modeling, formal mathematics statement curriculum learning, and more. The repository serves as a valuable resource for researchers and practitioners interested in the intersection of AI and mathematics.
Evaluator
NeMo Evaluator SDK is an open-source platform for robust, reproducible, and scalable evaluation of Large Language Models. It enables running hundreds of benchmarks across popular evaluation harnesses against any OpenAI-compatible model API. The platform ensures auditable and trustworthy results by executing evaluations in open-source Docker containers. NeMo Evaluator SDK is built on four core principles: Reproducibility by Default, Scale Anywhere, State-of-the-Art Benchmarking, and Extensible and Customizable.
llm-benchmarks
LLM Benchmarks is a tool designed for benchmarking AI models' performance and debugging capabilities. It provides comprehensive metrics, automated testing, and an interactive website for exploring results. The tool aims to ensure fair competition among models by tracking and comparing results consistently. LLM Benchmarks also emphasizes transparency through open-source code and public results. Users can contribute by adding new model implementations, benchmark types, improving the website, optimizing benchmarks, or enhancing documentation.

radicalbit-ai-monitoring
The Radicalbit AI Monitoring Platform provides a comprehensive solution for monitoring Machine Learning and Large Language models in production. It helps proactively identify and address potential performance issues by analyzing data quality, model quality, and model drift. The repository contains files and projects for running the platform, including UI, API, SDK, and Spark components. Installation using Docker compose is provided, allowing deployment with a K3s cluster and interaction with a k9s container. The platform documentation includes a step-by-step guide for installation and creating dashboards. Community engagement is encouraged through a Discord server. The roadmap includes adding functionalities for batch and real-time workloads, covering various model types and tasks.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.