Best AI tools for< Print High-quality Images >
20 - AI tool Sites
Disney Pixar AI Generator
Disney Pixar AI Generator is an AI application that allows users to transform their images into the iconic Pixar style. With this tool, users can easily create eye-catching Disney Pixar style images without the need for artistic or coding skills. The application offers a wide array of Disney and Pixar-inspired styles, customization options, and high-quality output suitable for printing or sharing on various platforms. It features a user-friendly interface designed for both novices and experienced users, making the image transformation process seamless and enjoyable. Additionally, users can share their transformed creations with friends and family across social media platforms.
Dopepics.io
Dopepics.io is an AI-powered image editing tool that allows users to create high-quality images in 8K resolution. With Dopepics.io, users can transform ordinary photos or prompts into extraordinary images. The tool is easy to use and requires no technical skills. Users simply need to upload their source image or provide a prompt, and Dopepics.io will generate up to 50 different images in stunning 8K quality. Dopepics.io is perfect for creating images for presentations, image slide shows, social media posts, and professional photography.

MidJourney Prompts Bundle
MidJourney Prompts Bundle is an AI tool designed to help users create professional watercolor art effortlessly. With over 3150 high-demand ready-to-use watercolor prompts, users can unlock their creativity and become top-selling AI artists overnight. The tool offers a vast collection of prompts across various categories, allowing users to customize and edit each prompt to suit their unique creative needs. Compatible with popular AI tools like MidJourney, DALL-E, and more, this tool enables users to generate high-quality images in various styles and join thousands of creators profiting from AI art.
Posed AI
Posed AI is an AI-powered tool that allows users to generate realistic avatars of themselves from a set of uploaded photos. The tool uses state-of-the-art technology to create high-resolution images that are perfect for profile pictures, social media posts, and even printing. Posed AI is easy to use and requires no technical expertise. Simply upload a set of photos and the tool will do the rest. Within 90 minutes, you will have a set of unique, AI-generated avatars that you can use to represent yourself online.
Easy Posters AI
Easy Posters AI is a poster generator powered by AI that allows users to effortlessly create high-quality poster designs for various purposes such as event promotion, product advertising, and inspirational or educational posters. The AI tool specializes in generating error-free text and offers time and cost savings by eliminating the need for expensive designers. With Easy Posters AI, users can create professional-quality posters in minutes without any design skills required, thanks to the AI doing the heavy lifting. The tool allows for perfect customization through simple text commands and offers print-ready quality images suitable for both digital use and professional printing.
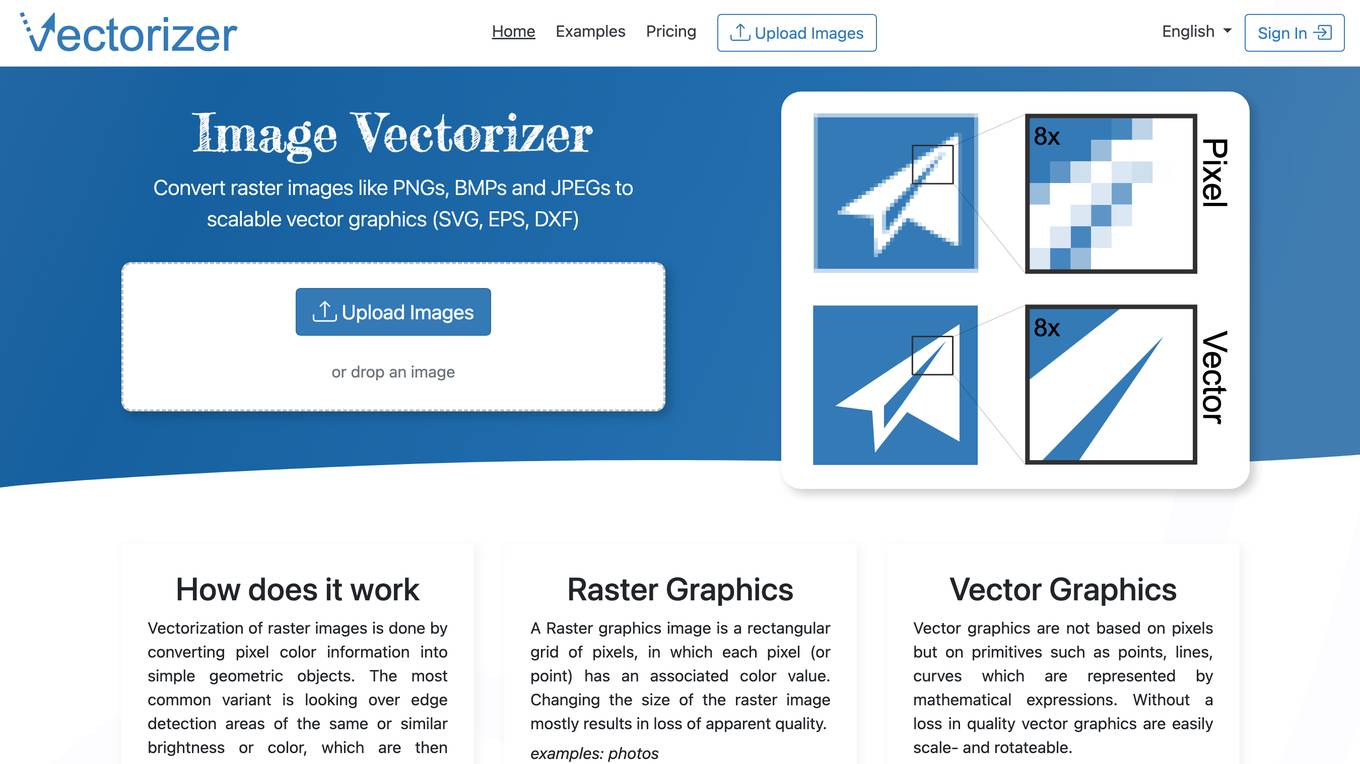
Vectorizer.io
Vectorizer.io is an online tool that converts raster images (such as PNGs, BMPs, and JPEGs) into scalable vector graphics (SVGs, EPSs, and DXFs). Vectorization is the process of converting pixel-based images into mathematical equations that define lines, curves, and shapes. This makes vector images resolution-independent, meaning they can be scaled to any size without losing quality. Vectorizer.io uses advanced algorithms to accurately trace the outlines of objects in raster images, producing high-quality vector outputs that are suitable for a variety of purposes, such as logo design, web graphics, and print production.

Zizoto
Zizoto is an AI-powered image generation and collaboration platform that empowers users to create, morph, and share unique visual masterpieces. With its advanced AI capabilities, Zizoto allows users to transform their ideas into stunning images, collaborate with others in a social network setting, and print their creations as high-quality posters. The platform fosters a vibrant community of creators, artists, and innovators, providing a space for inspiration, feedback, and artistic exploration.
Woy AI Tools
The website offers an advanced AI-powered tool to enhance the quality of images online for free. Users can enlarge their images up to 10 times and achieve a resolution of 12K, ensuring sharpness and clarity. It is ideal for photographers looking to enhance and enlarge their images for high-quality prints, as well as graphic designers aiming to create sharp and professional designs. The tool is also beneficial for social media users, influencers, and brands seeking to improve the quality of their images for better visibility and engagement. With a user-friendly interface, the tool allows users to easily upload, enhance, and download their improved images in high resolution.
Active Image Generator
Active Image Generator is an AI-powered image generation website that allows users to create unique and custom images with ease. It utilizes advanced algorithms to analyze user preferences and customization options, generating high-quality images based on the input parameters. Active Image Generator offers a wide range of image styles and themes, including abstract art, nature scenes, patterns, textures, and more. Users can explore different categories and styles to suit their specific needs. The generated images can be used for commercial purposes, including marketing campaigns, website graphics, social media posts, and more.
Sticker Maker
Sticker Maker is an AI-powered tool that allows users to create custom stickers from text prompts in seconds. It merges simplicity with creativity, enabling users to generate high-quality stickers that tell their story and sell their vision. The tool is ideal for designers, print-on-demand sellers, and anyone looking to personalize laptops, water bottles, or storefronts with vibrant sticker art. Sticker Maker offers features such as AI sticker generation, prompt wizard, dual-image creation, pixel-perfect upscaling, and seamless integration with design tools. With Sticker Maker, users can effortlessly bring their creative ideas to life and enhance their designs with ease.
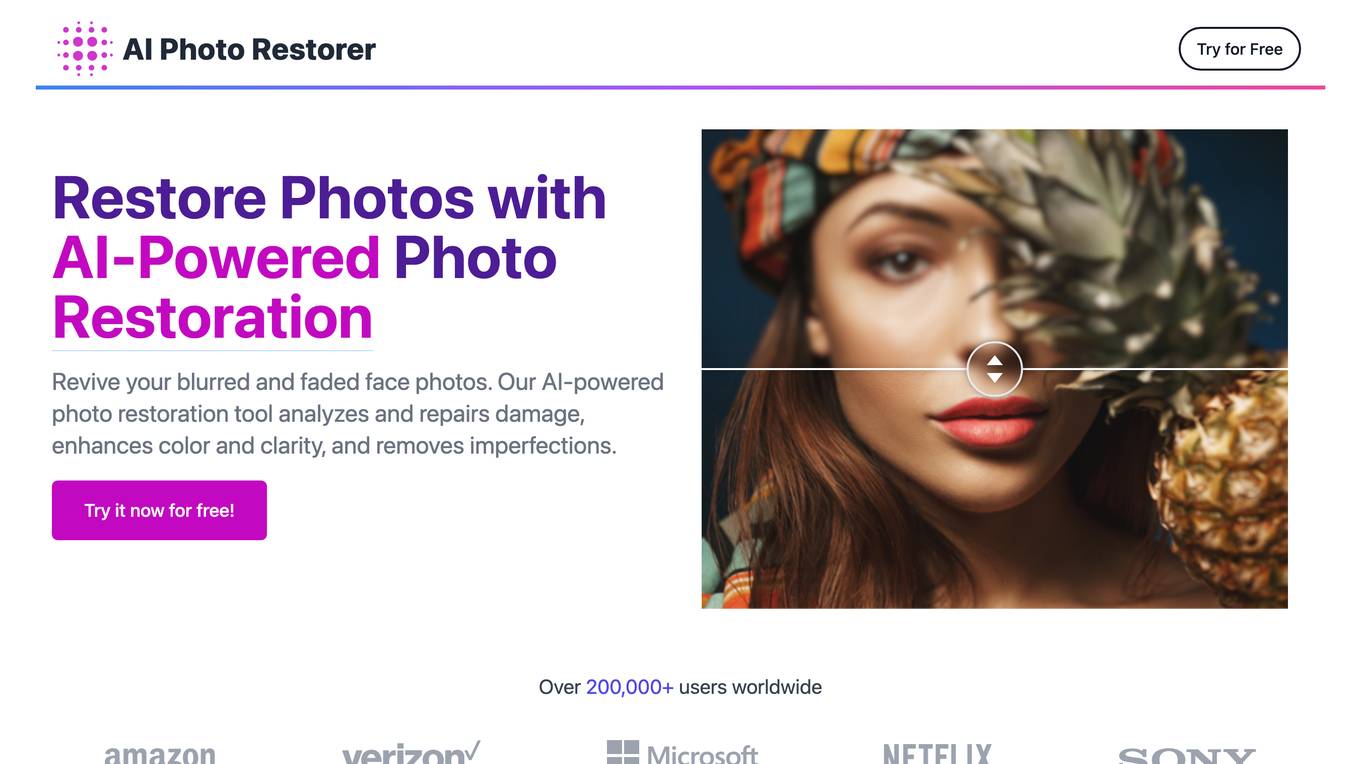
AI Photo Restorer
AI Photo Restorer is a free online tool that uses artificial intelligence to restore and enhance old, faded, or damaged photos. It can upscale images up to 4x resolution, remove scratches and blemishes, and enhance facial features. The tool is easy to use and can be accessed from any device with an internet connection.
StickerIt.AI
StickerIt.AI is a premier software solution for creating and selling AI-powered stickers directly from your mobile device. The platform allows users to transform any location into a vibrant sticker shop with just two tablets and a printer. StickerIt.AI offers features such as instant AI sticker generation, live sticker design with text-to-image AI technology, pay-as-you-go flexible sticker token purchase plans, and more. The application serves entrepreneurs, freelancers, retail store owners, event organizers, school educators, and sticker professionals, providing them with high-quality, personalized sticker-making experiences and innovative revenue strategies.

AI Slide Maker
AI Slide Maker is an innovative tool that utilizes artificial intelligence to create visually appealing and professional presentations in a matter of minutes. With its advanced algorithms, the application can analyze content, suggest relevant design templates, and generate slides automatically. Users can simply input their text and images, and the AI Slide Maker will take care of the rest, saving time and effort. Whether for business meetings, educational purposes, or personal projects, this tool streamlines the presentation creation process and ensures high-quality results.
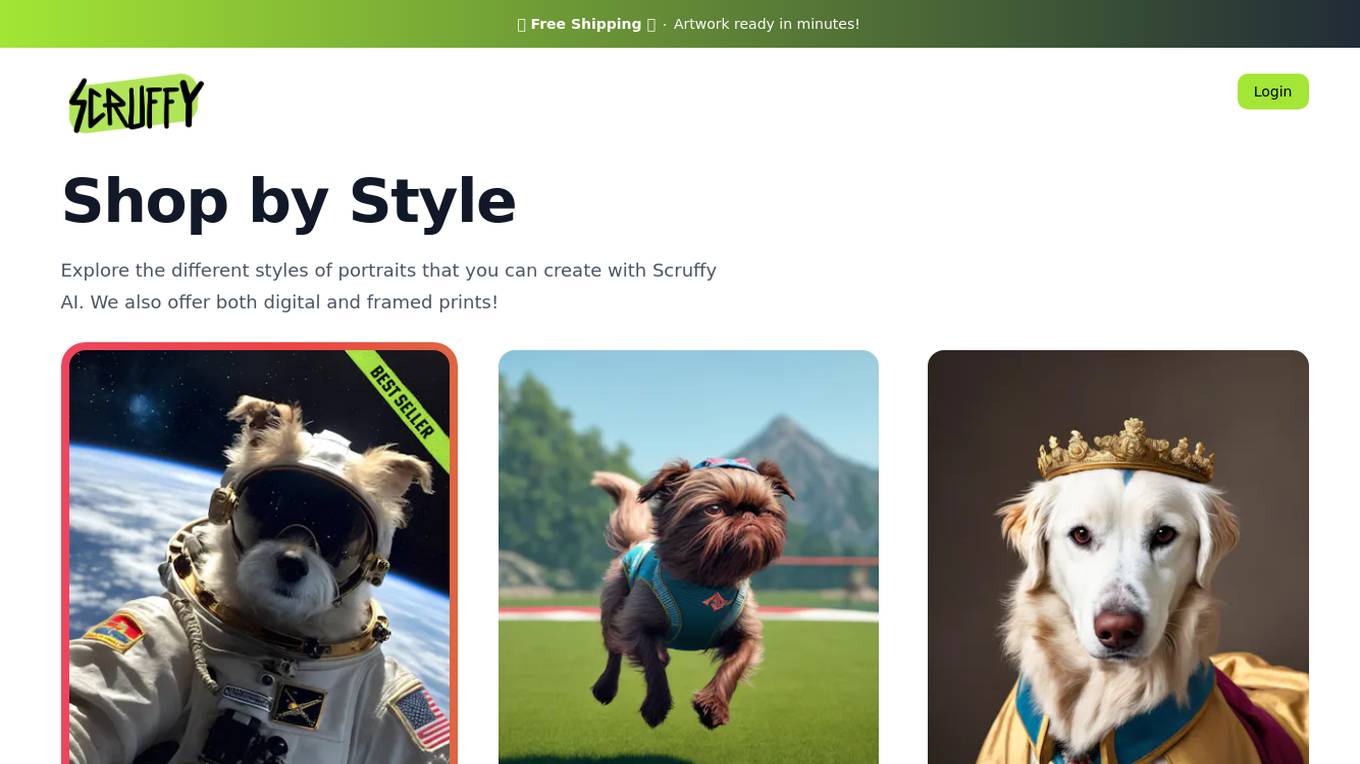
Scruffy AI
Scruffy AI is a website that allows users to create custom dog portraits and gifts. Users can select from a variety of portrait styles, upload pictures of their dogs, and then choose their favorite portrait to download. Scruffy AI also offers both digital and framed prints. The website is easy to use and provides high-quality results. Users can also use Scruffy AI to train their own models to generate new images.
Content Robot
Content Robot is an AI-powered content and image generator that helps users create high-quality, SEO-optimized content for their websites, blogs, and social media. The tool offers a wide range of templates and features to help users generate unique and engaging content quickly and easily. Content Robot is also affordable and easy to use, making it a great option for businesses of all sizes.

BookBud.ai
BookBud.ai is a web-based service that enables self-published authors to create fiction and non-fiction books with the assistance of AI. Authors can publish their books in ebook, print book, and audiobook formats. The platform offers rapid and affordable book creation, distribution-ready ebook files, global platform presence, hassle-free distribution, and high-quality print book formatting. BookBud.ai aims to make self-publishing profitable and accessible to aspiring and established writers.
Designhill
Designhill is an AI-powered platform that offers design services and DIY tools for print on demand merchandise. It provides a wide range of design solutions for businesses, including logo design, packaging design, website design, social media graphics, illustration, and more. Users can create unique logos, brand identities, and other design materials quickly and affordably using the AI Logo Maker tool. Designhill also offers services like design contests, graphic design gigs, digital business cards, and custom clothing design. The platform aims to help businesses enhance their branding efforts and connect with talented designers worldwide.
AIColoringPages
AIColoringPages is a free online AI tool that generates personalized coloring pages based on user prompts. The platform utilizes advanced Stable Diffusion XL technology to create high-resolution coloring pages suitable for all ages. From classic themes like Disney and dinosaur coloring pages to festive designs for holidays, the AI technology offers a wide variety of customizable options. Users can easily input prompts to receive unique, ready-to-print coloring pages in seconds, making the coloring experience more personalized and enjoyable.
Slea.ai
Slea.ai is a free AI Logo Generator that allows users to effortlessly create unique and professional logos for businesses, creators, and events. The tool uses artificial intelligence to generate customized logo designs based on text descriptions and industry-specific preferences. With features like negative prompts and advanced editing tools, Slea.ai ensures quick and high-quality logo creation. Users can download watermark-free logos in transparent PNG format, suitable for various applications from social media to print-ready formats.
Sloyd
Sloyd is an AI-powered 3D model generator that allows users to create 3D models from text prompts. The platform offers a wide range of features, including a huge 3D model library, easy customization of 3D models, and ready-to-use 3D models. Sloyd is ideal for game developers, designers, and 3D enthusiasts who need to create high-quality 3D models quickly and efficiently.
20 - Open Source AI Tools

generative-ai-sagemaker-cdk-demo
This repository showcases how to deploy generative AI models from Amazon SageMaker JumpStart using the AWS CDK. Generative AI is a type of AI that can create new content and ideas, such as conversations, stories, images, videos, and music. The repository provides a detailed guide on deploying image and text generative AI models, utilizing pre-trained models from SageMaker JumpStart. The web application is built on Streamlit and hosted on Amazon ECS with Fargate. It interacts with the SageMaker model endpoints through Lambda functions and Amazon API Gateway. The repository also includes instructions on setting up the AWS CDK application, deploying the stacks, using the models, and viewing the deployed resources on the AWS Management Console.
Webscout
WebScout is a versatile tool that allows users to search for anything using Google, DuckDuckGo, and phind.com. It contains AI models, can transcribe YouTube videos, generate temporary email and phone numbers, has TTS support, webai (terminal GPT and open interpreter), and offline LLMs. It also supports features like weather forecasting, YT video downloading, temp mail and number generation, text-to-speech, advanced web searches, and more.
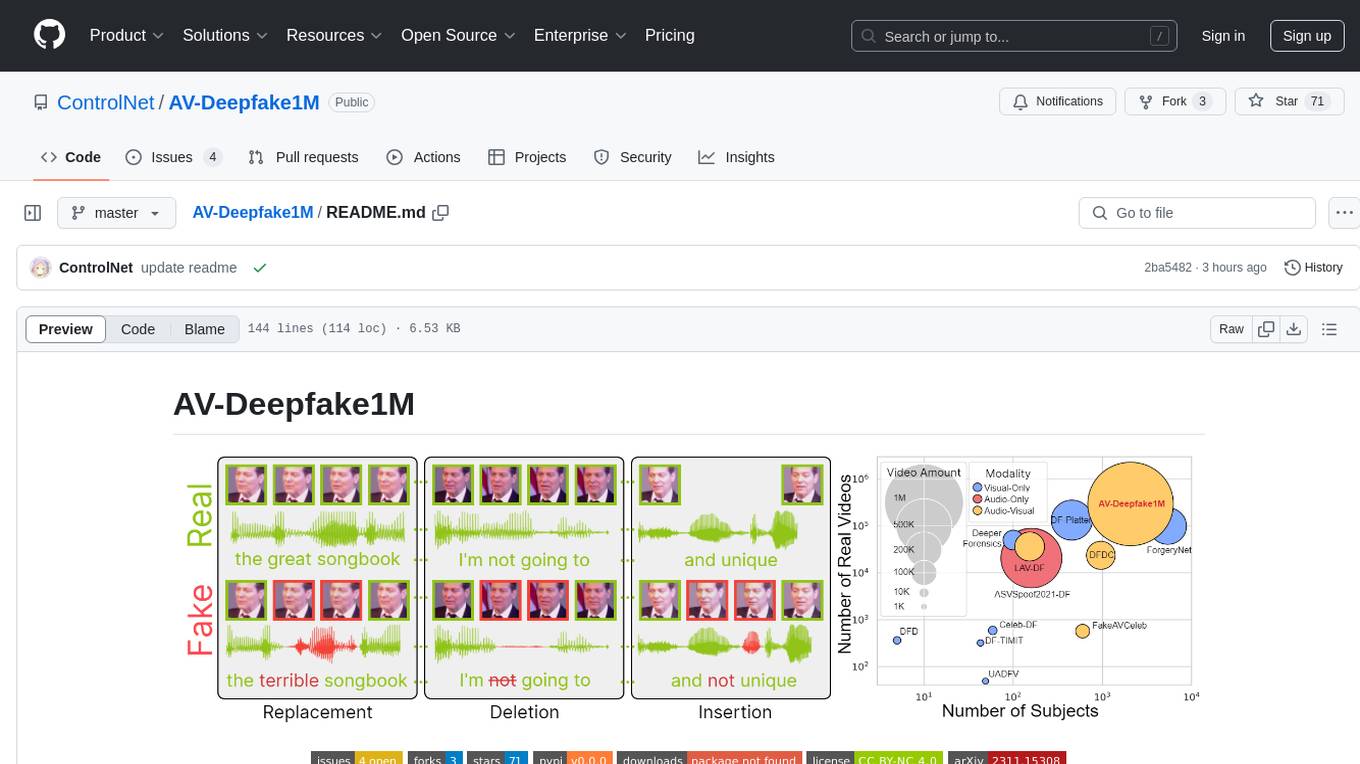
AV-Deepfake1M
The AV-Deepfake1M repository is the official repository for the paper AV-Deepfake1M: A Large-Scale LLM-Driven Audio-Visual Deepfake Dataset. It addresses the challenge of detecting and localizing deepfake audio-visual content by proposing a dataset containing video manipulations, audio manipulations, and audio-visual manipulations for over 2K subjects resulting in more than 1M videos. The dataset is crucial for developing next-generation deepfake localization methods.

MiniCPM-V
MiniCPM-V is a series of end-side multimodal LLMs designed for vision-language understanding. The models take image and text inputs to provide high-quality text outputs. The series includes models like MiniCPM-Llama3-V 2.5 with 8B parameters surpassing proprietary models, and MiniCPM-V 2.0, a lighter model with 2B parameters. The models support over 30 languages, efficient deployment on end-side devices, and have strong OCR capabilities. They achieve state-of-the-art performance on various benchmarks and prevent hallucinations in text generation. The models can process high-resolution images efficiently and support multilingual capabilities.

PaddleNLP
PaddleNLP is an easy-to-use and high-performance NLP library. It aggregates high-quality pre-trained models in the industry and provides out-of-the-box development experience, covering a model library for multiple NLP scenarios with industry practice examples to meet developers' flexible customization needs.
e2m
E2M is a Python library that can parse and convert various file types into Markdown format. It supports the conversion of multiple file formats, including doc, docx, epub, html, htm, url, pdf, ppt, pptx, mp3, and m4a. The ultimate goal of the E2M project is to provide high-quality data for Retrieval-Augmented Generation (RAG) and model training or fine-tuning. The core architecture consists of a Parser responsible for parsing various file types into text or image data, and a Converter responsible for converting text or image data into Markdown format.
Medical_Image_Analysis
The Medical_Image_Analysis repository focuses on X-ray image-based medical report generation using large language models. It provides pre-trained models and benchmarks for CheXpert Plus dataset, context sample retrieval for X-ray report generation, and pre-training on high-definition X-ray images. The goal is to enhance diagnostic accuracy and reduce patient wait times by improving X-ray report generation through advanced AI techniques.

InternLM-XComposer
InternLM-XComposer2 is a groundbreaking vision-language large model (VLLM) based on InternLM2-7B excelling in free-form text-image composition and comprehension. It boasts several amazing capabilities and applications: * **Free-form Interleaved Text-Image Composition** : InternLM-XComposer2 can effortlessly generate coherent and contextual articles with interleaved images following diverse inputs like outlines, detailed text requirements and reference images, enabling highly customizable content creation. * **Accurate Vision-language Problem-solving** : InternLM-XComposer2 accurately handles diverse and challenging vision-language Q&A tasks based on free-form instructions, excelling in recognition, perception, detailed captioning, visual reasoning, and more. * **Awesome performance** : InternLM-XComposer2 based on InternLM2-7B not only significantly outperforms existing open-source multimodal models in 13 benchmarks but also **matches or even surpasses GPT-4V and Gemini Pro in 6 benchmarks** We release InternLM-XComposer2 series in three versions: * **InternLM-XComposer2-4KHD-7B** 🤗: The high-resolution multi-task trained VLLM model with InternLM-7B as the initialization of the LLM for _High-resolution understanding_ , _VL benchmarks_ and _AI assistant_. * **InternLM-XComposer2-VL-7B** 🤗 : The multi-task trained VLLM model with InternLM-7B as the initialization of the LLM for _VL benchmarks_ and _AI assistant_. **It ranks as the most powerful vision-language model based on 7B-parameter level LLMs, leading across 13 benchmarks.** * **InternLM-XComposer2-VL-1.8B** 🤗 : A lightweight version of InternLM-XComposer2-VL based on InternLM-1.8B. * **InternLM-XComposer2-7B** 🤗: The further instruction tuned VLLM for _Interleaved Text-Image Composition_ with free-form inputs. Please refer to Technical Report and 4KHD Technical Reportfor more details.

RLAIF-V
RLAIF-V is a novel framework that aligns MLLMs in a fully open-source paradigm for super GPT-4V trustworthiness. It maximally exploits open-source feedback from high-quality feedback data and online feedback learning algorithm. Notable features include achieving super GPT-4V trustworthiness in both generative and discriminative tasks, using high-quality generalizable feedback data to reduce hallucination of different MLLMs, and exhibiting better learning efficiency and higher performance through iterative alignment.

MathVerse
MathVerse is an all-around visual math benchmark designed to evaluate the capabilities of Multi-modal Large Language Models (MLLMs) in visual math problem-solving. It collects high-quality math problems with diagrams to assess how well MLLMs can understand visual diagrams for mathematical reasoning. The benchmark includes 2,612 problems transformed into six versions each, contributing to 15K test samples. It also introduces a Chain-of-Thought (CoT) Evaluation strategy for fine-grained assessment of output answers.

open-parse
Open Parse is a Python library for visually discerning document layouts and chunking them effectively. It is designed to fill the gap in open-source libraries for handling complex documents. Unlike text splitting, which converts a file to raw text and slices it up, Open Parse visually analyzes documents for superior LLM input. It also supports basic markdown for parsing headings, bold, and italics, and has high-precision table support, extracting tables into clean Markdown formats with accuracy that surpasses traditional tools. Open Parse is extensible, allowing users to easily implement their own post-processing steps. It is also intuitive, with great editor support and completion everywhere, making it easy to use and learn.

data-juicer
Data-Juicer is a one-stop data processing system to make data higher-quality, juicier, and more digestible for LLMs. It is a systematic & reusable library of 80+ core OPs, 20+ reusable config recipes, and 20+ feature-rich dedicated toolkits, designed to function independently of specific LLM datasets and processing pipelines. Data-Juicer allows detailed data analyses with an automated report generation feature for a deeper understanding of your dataset. Coupled with multi-dimension automatic evaluation capabilities, it supports a timely feedback loop at multiple stages in the LLM development process. Data-Juicer offers tens of pre-built data processing recipes for pre-training, fine-tuning, en, zh, and more scenarios. It provides a speedy data processing pipeline requiring less memory and CPU usage, optimized for maximum productivity. Data-Juicer is flexible & extensible, accommodating most types of data formats and allowing flexible combinations of OPs. It is designed for simplicity, with comprehensive documentation, easy start guides and demo configs, and intuitive configuration with simple adding/removing OPs from existing configs.

deepdoctection
**deep** doctection is a Python library that orchestrates document extraction and document layout analysis tasks using deep learning models. It does not implement models but enables you to build pipelines using highly acknowledged libraries for object detection, OCR and selected NLP tasks and provides an integrated framework for fine-tuning, evaluating and running models. For more specific text processing tasks use one of the many other great NLP libraries. **deep** doctection focuses on applications and is made for those who want to solve real world problems related to document extraction from PDFs or scans in various image formats. **deep** doctection provides model wrappers of supported libraries for various tasks to be integrated into pipelines. Its core function does not depend on any specific deep learning library. Selected models for the following tasks are currently supported: * Document layout analysis including table recognition in Tensorflow with **Tensorpack**, or PyTorch with **Detectron2**, * OCR with support of **Tesseract**, **DocTr** (Tensorflow and PyTorch implementations available) and a wrapper to an API for a commercial solution, * Text mining for native PDFs with **pdfplumber**, * Language detection with **fastText**, * Deskewing and rotating images with **jdeskew**. * Document and token classification with all LayoutLM models provided by the **Transformer library**. (Yes, you can use any LayoutLM-model with any of the provided OCR-or pdfplumber tools straight away!). * Table detection and table structure recognition with **table-transformer**. * There is a small dataset for token classification available and a lot of new tutorials to show, how to train and evaluate this dataset using LayoutLMv1, LayoutLMv2, LayoutXLM and LayoutLMv3. * Comprehensive configuration of **analyzer** like choosing different models, output parsing, OCR selection. Check this notebook or the docs for more infos. * Document layout analysis and table recognition now runs with **Torchscript** (CPU) as well and **Detectron2** is not required anymore for basic inference. * [**new**] More angle predictors for determining the rotation of a document based on **Tesseract** and **DocTr** (not contained in the built-in Analyzer). * [**new**] Token classification with **LiLT** via **transformers**. We have added a model wrapper for token classification with LiLT and added a some LiLT models to the model catalog that seem to look promising, especially if you want to train a model on non-english data. The training script for LayoutLM can be used for LiLT as well and we will be providing a notebook on how to train a model on a custom dataset soon. **deep** doctection provides on top of that methods for pre-processing inputs to models like cropping or resizing and to post-process results, like validating duplicate outputs, relating words to detected layout segments or ordering words into contiguous text. You will get an output in JSON format that you can customize even further by yourself. Have a look at the **introduction notebook** in the notebook repo for an easy start. Check the **release notes** for recent updates. **deep** doctection or its support libraries provide pre-trained models that are in most of the cases available at the **Hugging Face Model Hub** or that will be automatically downloaded once requested. For instance, you can find pre-trained object detection models from the Tensorpack or Detectron2 framework for coarse layout analysis, table cell detection and table recognition. Training is a substantial part to get pipelines ready on some specific domain, let it be document layout analysis, document classification or NER. **deep** doctection provides training scripts for models that are based on trainers developed from the library that hosts the model code. Moreover, **deep** doctection hosts code to some well established datasets like **Publaynet** that makes it easy to experiment. It also contains mappings from widely used data formats like COCO and it has a dataset framework (akin to **datasets** so that setting up training on a custom dataset becomes very easy. **This notebook** shows you how to do this. **deep** doctection comes equipped with a framework that allows you to evaluate predictions of a single or multiple models in a pipeline against some ground truth. Check again **here** how it is done. Having set up a pipeline it takes you a few lines of code to instantiate the pipeline and after a for loop all pages will be processed through the pipeline.

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.
RoboMatrix
RoboMatrix is a skill-centric hierarchical framework for scalable robot task planning and execution in an open-world environment. It provides a structured approach to robot task execution using a combination of hardware components, environment configuration, installation procedures, and data collection methods. The framework is developed using the ROS2 framework on Ubuntu and supports robots from DJI's RoboMaster series. Users can follow the provided installation guidance to set up RoboMatrix and utilize it for various tasks such as data collection, task execution, and dataset construction. The framework also includes a supervised fine-tuning dataset and aims to optimize communication and release additional components in the future.
whisper_dictation
Whisper Dictation is a fast, offline, privacy-focused tool for voice typing, AI voice chat, voice control, and translation. It allows hands-free operation, launching and controlling apps, and communicating with OpenAI ChatGPT or a local chat server. The tool also offers the option to speak answers out loud and draw pictures. It includes client and server versions, inspired by the Star Trek series, and is designed to keep data off the internet and confidential. The project is optimized for dictation and translation tasks, with voice control capabilities and AI image generation using stable-diffusion API.

tonic_validate
Tonic Validate is a framework for the evaluation of LLM outputs, such as Retrieval Augmented Generation (RAG) pipelines. Validate makes it easy to evaluate, track, and monitor your LLM and RAG applications. Validate allows you to evaluate your LLM outputs through the use of our provided metrics which measure everything from answer correctness to LLM hallucination. Additionally, Validate has an optional UI to visualize your evaluation results for easy tracking and monitoring.
ai-collective-tools
ai-collective-tools is an open-source community dedicated to creating a comprehensive collection of AI tools for developers, researchers, and enthusiasts. The repository provides a curated selection of AI tools and resources across various categories such as 3D, Agriculture, Art, Audio Editing, Avatars, Chatbots, Code Assistant, Cooking, Copywriting, Crypto, Customer Support, Dating, Design Assistant, Design Generator, Developer, E-Commerce, Education, Email Assistant, Experiments, Fashion, Finance, Fitness, Fun Tools, Gaming, General Writing, Gift Ideas, HealthCare, Human Resources, Image Classification, Image Editing, Image Generator, Interior Designing, Legal Assistant, Logo Generator, Low Code, Models, Music, Paraphraser, Personal Assistant, Presentations, Productivity, Prompt Generator, Psychology, Real Estate, Religion, Research, Resume, Sales, Search Engine, SEO, Shopping, Social Media, Spreadsheets, SQL, Startup Tools, Story Teller, Summarizer, Testing, Text to Speech, Text to Image, Transcriber, Travel, Video Editing, Video Generator, Weather, Writing Generator, and Other Resources.
local-talking-llm
The 'local-talking-llm' repository provides a tutorial on building a voice assistant similar to Jarvis or Friday from Iron Man movies, capable of offline operation on a computer. The tutorial covers setting up a Python environment, installing necessary libraries like rich, openai-whisper, suno-bark, langchain, sounddevice, pyaudio, and speechrecognition. It utilizes Ollama for Large Language Model (LLM) serving and includes components for speech recognition, conversational chain, and speech synthesis. The implementation involves creating a TextToSpeechService class for Bark, defining functions for audio recording, transcription, LLM response generation, and audio playback. The main application loop guides users through interactive voice-based conversations with the assistant.
20 - OpenAI Gpts
Print on Demand Ecommerce
Your go-to guide for starting a Print on Demand store with Printful and Shopify.
PODpreneur Advisor - Print on Demand Tool
Conversational Print on Demand (POD) expert for new and experienced users.
Print Tech Guru
Expert in 3D printing innovations, offering in-depth insights and analysis.
3D Print Diagnostics Expert
Expert in 3D printing diagnostics and problem resolution, mindful of confidentiality and careful with brand usage.

Small Print - Terms and Conditions
Friendly GPT simplifying terms and conditions, with focus on critical aspects for users.
Marketplace Mind for POD (Print On Demand) | YAYAI
Innovates digital, AI-driven product ideas in marketplace style.

Creative Sticker Buddy
Print individual (1) die cut stickers. I create custom stickers and guide you to download them. After downloading them, you can send them to Midwest Label and print out 1-100 individual labels.

UpScaler
DALL-E user? Resize/de-noise images or uploads! Print & show-off your masterpiece or display in 4K! Supports 0.5x-4x to poster size. Abbreviations support. Enter your image prompt or, "m" for a menu to begin.


3D Printers
Expert guide in 3D printing for all skill levels, offering comprehensive advice.
3DCP Guru GPT
A 3D Printed Construction wiz trained on expert interviews. Use creatively, don't depend on 3DCP Guru GPT for factually accurate info (although it's pretty darn good)