Best AI tools for< judge candidates >
6 - AI tool Sites
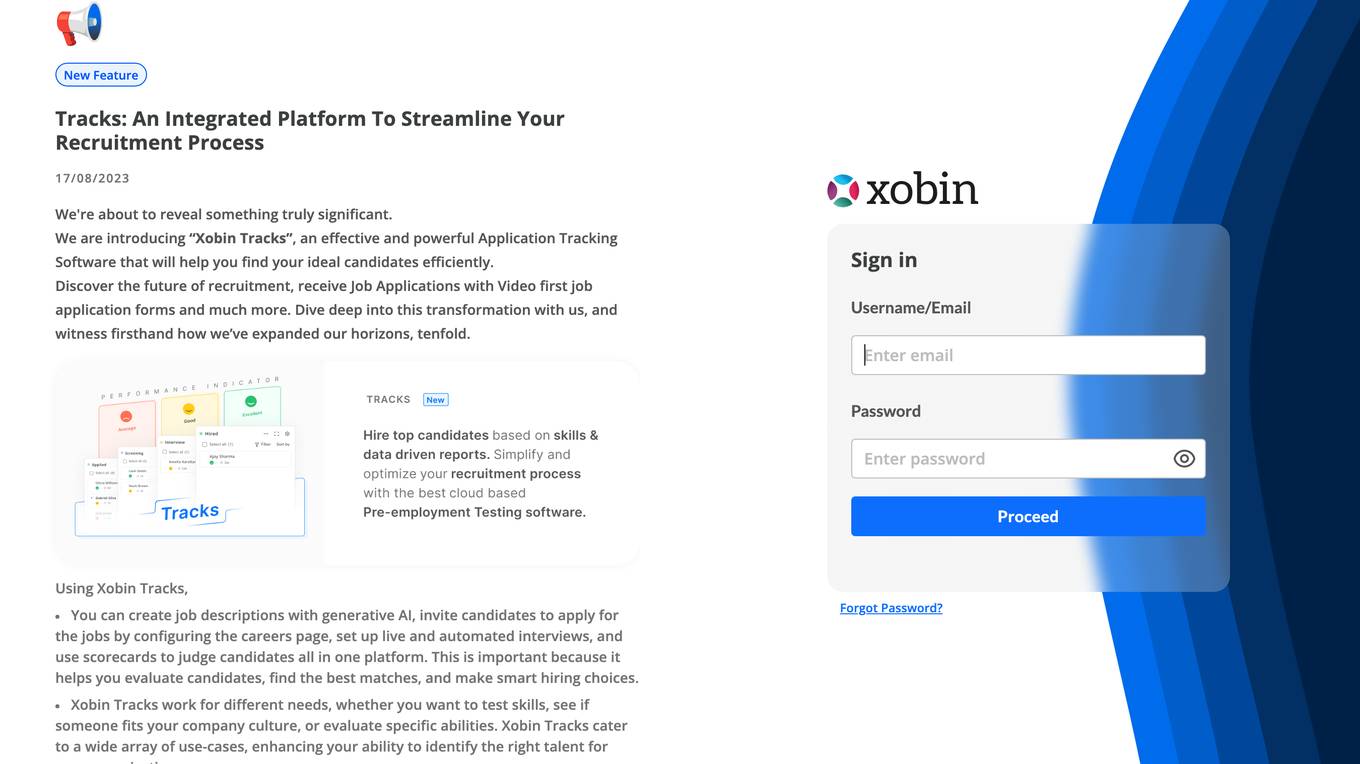
Xobin Tracks
**Xobin Tracks** is a powerful and effective Application Tracking Software (ATS) that helps businesses find their ideal candidates efficiently. It offers a range of features to streamline the recruitment process, including: * Creating job descriptions with generative AI * Inviting candidates to apply for jobs by configuring the careers page * Setting up live and automated interviews * Using scorecards to judge candidates * Direct messaging with candidates Xobin Tracks is designed to help businesses evaluate candidates, find the best matches, and make smart hiring choices. It is suitable for a variety of needs, including testing skills, assessing culture fit, and evaluating specific abilities. By using Xobin Tracks, businesses can enhance their ability to identify the right talent for their organization.
AI Judge
AI Judge is an innovative online platform that utilizes artificial intelligence technology to generate verdicts and resolve disputes between two parties. It provides a convenient and efficient way to settle disagreements without the need for lengthy and costly legal proceedings. AI Judge's platform is designed to be impartial and unbiased, ensuring that both parties have an equal opportunity to present their cases and receive a fair verdict. The AI algorithms carefully analyze the arguments, evidence, and legal principles presented by each party to determine a just and reasonable outcome. AI Judge's verdicts are not legally binding but serve as an additional perspective for the contending parties to consider in their dispute resolution process. Additionally, users have the option to have a qualified legal professional review the AI-generated verdict for an extra layer of scrutiny and confidence. AI Judge is constantly striving to improve its AI algorithms and ensure that its platform adheres to ethical standards. It values user feedback and continuously works to refine its processes, ensuring that it remains a reliable tool for dispute resolution.

Confident AI
Confident AI is an open-source evaluation infrastructure for Large Language Models (LLMs). It provides a centralized platform to judge LLM applications, ensuring substantial benefits and addressing any weaknesses in LLM implementation. With Confident AI, companies can define ground truths to ensure their LLM is behaving as expected, evaluate performance against expected outputs to pinpoint areas for iterations, and utilize advanced diff tracking to guide towards the optimal LLM stack. The platform offers comprehensive analytics to identify areas of focus and features such as A/B testing, evaluation, output classification, reporting dashboard, dataset generation, and detailed monitoring to help productionize LLMs with confidence.
Debatia
Debatia is a free, real-time debate platform that allows users to debate anyone, worldwide, in text or voice, in their own language. Debatia's AI Judging System uses ChatGPT to deliver fair judgment in debates, offering a novel and engaging experience. Users are paired based on their debate skill level by Debatia's algorithm.
Lex Machina
Lex Machina is a Legal Analytics platform that provides comprehensive insights into litigation track records of parties across the United States. It offers accurate and transparent analytic data, exclusive outcome analytics, and valuable insights to help law firms and companies craft successful strategies, assess cases, and set litigation strategies. The platform uses a unique combination of machine learning and in-house legal experts to compile, clean, and enhance data, providing unmatched insights on courts, judges, lawyers, law firms, and parties.
Runway AI Film Festival
Runway AI Film Festival is an annual celebration of art and artists embracing new and emerging AI techniques for filmmaking. Established in 2022, the festival showcases works that offer a glimpse into a new creative era empowered by the tools of tomorrow. The festival features gala screenings in NYC and LA, where 10 finalists are selected and winners are chosen by esteemed judges. With over $60,000 in total prizes, the festival aims to fund the continued creation of AI filmmaking.
20 - Open Source AI Tools



llm-reasoners
LLM Reasoners is a library that enables LLMs to conduct complex reasoning, with advanced reasoning algorithms. It approaches multi-step reasoning as planning and searches for the optimal reasoning chain, which achieves the best balance of exploration vs exploitation with the idea of "World Model" and "Reward". Given any reasoning problem, simply define the reward function and an optional world model (explained below), and let LLM reasoners take care of the rest, including Reasoning Algorithms, Visualization, LLM calling, and more!

StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features such as a Virtual API System with caching and API simulators, a new set of solvable queries determined by LLMs, and a Stable Evaluation System using GPT-4. The Virtual API Server can be set up either by building from source or using a prebuilt Docker image. Users can test the server using provided scripts and evaluate models with Solvable Pass Rate and Solvable Win Rate metrics. The tool also includes model experiments results comparing different models' performance.

arena-hard-auto
Arena-Hard-Auto-v0.1 is an automatic evaluation tool for instruction-tuned LLMs. It contains 500 challenging user queries. The tool prompts GPT-4-Turbo as a judge to compare models' responses against a baseline model (default: GPT-4-0314). Arena-Hard-Auto employs an automatic judge as a cheaper and faster approximator to human preference. It has the highest correlation and separability to Chatbot Arena among popular open-ended LLM benchmarks. Users can evaluate their models' performance on Chatbot Arena by using Arena-Hard-Auto.
llm-adaptive-attacks
This repository contains code and results for jailbreaking leading safety-aligned LLMs with simple adaptive attacks. We show that even the most recent safety-aligned LLMs are not robust to simple adaptive jailbreaking attacks. We demonstrate how to successfully leverage access to logprobs for jailbreaking: we initially design an adversarial prompt template (sometimes adapted to the target LLM), and then we apply random search on a suffix to maximize the target logprob (e.g., of the token ``Sure''), potentially with multiple restarts. In this way, we achieve nearly 100% attack success rate---according to GPT-4 as a judge---on GPT-3.5/4, Llama-2-Chat-7B/13B/70B, Gemma-7B, and R2D2 from HarmBench that was adversarially trained against the GCG attack. We also show how to jailbreak all Claude models---that do not expose logprobs---via either a transfer or prefilling attack with 100% success rate. In addition, we show how to use random search on a restricted set of tokens for finding trojan strings in poisoned models---a task that shares many similarities with jailbreaking---which is the algorithm that brought us the first place in the SaTML'24 Trojan Detection Competition. The common theme behind these attacks is that adaptivity is crucial: different models are vulnerable to different prompting templates (e.g., R2D2 is very sensitive to in-context learning prompts), some models have unique vulnerabilities based on their APIs (e.g., prefilling for Claude), and in some settings it is crucial to restrict the token search space based on prior knowledge (e.g., for trojan detection).

h2o-llmstudio
H2O LLM Studio is a framework and no-code GUI designed for fine-tuning state-of-the-art large language models (LLMs). With H2O LLM Studio, you can easily and effectively fine-tune LLMs without the need for any coding experience. The GUI is specially designed for large language models, and you can finetune any LLM using a large variety of hyperparameters. You can also use recent finetuning techniques such as Low-Rank Adaptation (LoRA) and 8-bit model training with a low memory footprint. Additionally, you can use Reinforcement Learning (RL) to finetune your model (experimental), use advanced evaluation metrics to judge generated answers by the model, track and compare your model performance visually, and easily export your model to the Hugging Face Hub and share it with the community.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.
HybridAGI
HybridAGI is the first Programmable LLM-based Autonomous Agent that lets you program its behavior using a **graph-based prompt programming** approach. This state-of-the-art feature allows the AGI to efficiently use any tool while controlling the long-term behavior of the agent. Become the _first Prompt Programmers in history_ ; be a part of the AI revolution one node at a time! **Disclaimer: We are currently in the process of upgrading the codebase to integrate DSPy**
distilabel
Distilabel is a framework for synthetic data and AI feedback for AI engineers that require high-quality outputs, full data ownership, and overall efficiency. It helps you synthesize data and provide AI feedback to improve the quality of your AI models. With Distilabel, you can: * **Synthesize data:** Generate synthetic data to train your AI models. This can help you to overcome the challenges of data scarcity and bias. * **Provide AI feedback:** Get feedback from AI models on your data. This can help you to identify errors and improve the quality of your data. * **Improve your AI output quality:** By using Distilabel to synthesize data and provide AI feedback, you can improve the quality of your AI models and get better results.
RLHF-Reward-Modeling
This repository, RLHF-Reward-Modeling, is dedicated to training reward models for DRL-based RLHF (PPO), Iterative SFT, and iterative DPO. It provides state-of-the-art performance in reward models with a base model size of up to 13B. The installation instructions involve setting up the environment and aligning the handbook. Dataset preparation requires preprocessing conversations into a standard format. The code can be run with Gemma-2b-it, and evaluation results can be obtained using provided datasets. The to-do list includes various reward models like Bradley-Terry, preference model, regression-based reward model, and multi-objective reward model. The repository is part of iterative rejection sampling fine-tuning and iterative DPO.
prometheus-eval
Prometheus-Eval is a repository dedicated to evaluating large language models (LLMs) in generation tasks. It provides state-of-the-art language models like Prometheus 2 (7B & 8x7B) for assessing in pairwise ranking formats and achieving high correlation scores with benchmarks. The repository includes tools for training, evaluating, and using these models, along with scripts for fine-tuning on custom datasets. Prometheus aims to address issues like fairness, controllability, and affordability in evaluations by simulating human judgments and proprietary LM-based assessments.
ScreenAgent
ScreenAgent is a project focused on creating an environment for Visual Language Model agents (VLM Agent) to interact with real computer screens. The project includes designing an automatic control process for agents to interact with the environment and complete multi-step tasks. It also involves building the ScreenAgent dataset, which collects screenshots and action sequences for various daily computer tasks. The project provides a controller client code, configuration files, and model training code to enable users to control a desktop with a large model.

VLMEvalKit
VLMEvalKit is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.
20 - OpenAI Gpts
Pawsome Judge
Playful guide for a virtual dog show, creating and presenting imaginative dog breeds.
West Coast Choppers
A virtual judge for West Coast Choppers, rating and discussing custom bikes.
What does MBTI say? (MBTI怎么说)
Let's judge his/her MBTI by giving specific scenarios and what specific people say.(让我们通过具体的场景和对方说的话来判断他的 MBTI吧!)
JUEZ GPT
JUEZ GPT es una herramienta diseñada para arbitrar conflictos y tomar decisiones de manera pragmática, justa y lógica, proporcionando veredictos claros

Código de Processo Civil
Robô treinado para esclarecer dúvidas sobre o Código de Processo Civil brasileiro

ConstitutiX
Asesor en derecho constitucional chileno. Te explicaré las diferencias entre la Constitución Vigente y la Propuesta Constitucional 2023.

Case Digests on Demand (a Jurisage experiment)
Upload a court judgment and get back a collection of topical case digests based on the case. Oh - don't trust the "Topic 2210" or similar number, it's random. Also, probably best you not fully trust the output either. We're just playing with the GPT maker. More about us at Jurisage.com.

Am I the Jerk?
Your go-to advisor for moral dilemmas, offering direct, honest, and memorable guidance.