
awesome-japanese-llm
日本語LLMまとめ - Overview of Japanese LLMs
Stars: 1347
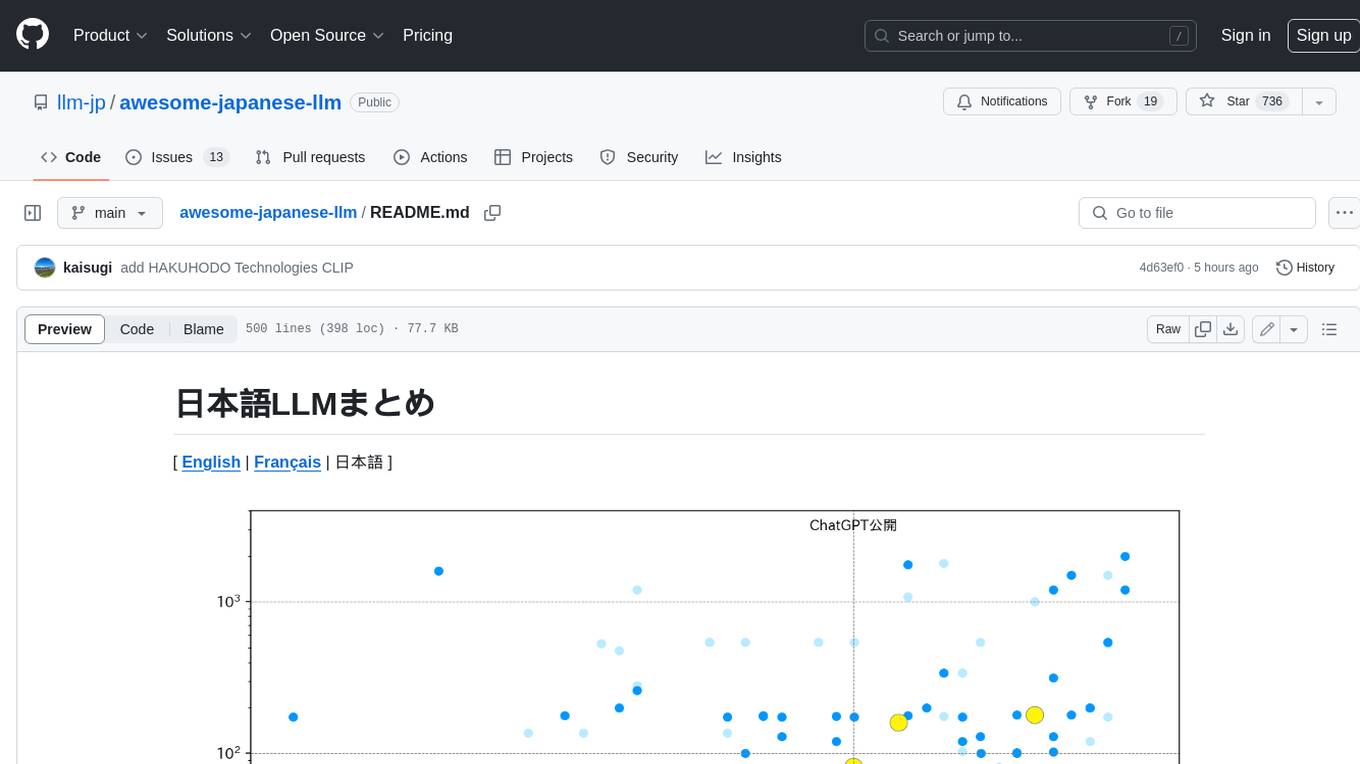
日本語LLMの包括的な概要です。400ワード未満で、改行や引用符はありません。
README:
📖 より読みやすいWeb版をご利用ください
このREADMEの内容は、llm-jp.github.io/awesome-japanese-llm でより見やすい形式でご覧いただけます。表の表示崩れやレイアウトの問題を防ぐため、Web版の閲覧を推奨いたします。
この記事は、一般公開されている日本語LLM(日本語を中心に学習されたLLM)および日本語LLM評価ベンチマークに関する情報をまとめたものです。情報は、有志により収集されており、その一部は論文や公開されているリソースなどから引用しています。
::: warning 以下の点について、あらかじめご理解とご了承をお願いいたします
- 本記事の内容は、完全性や正確性を保証するものではありません。これらの情報は予告なく変更されることがあり、また最新の情報を常に提供できるとは限りません。
- 一部の情報は、推測や個々の利用者の解釈にもとづくものである場合があります。そのため、全ての読者にとって必ずしも正確であるとは限りません。
- 本記事に記載されているモデルの多くは、MIT や Apache-2.0 といったオープンソースライセンスが適用されています。しかしながら、一部のモデルには、非営利限定のライセンス(例:CC BY-NC-SA 4.0)や開発元特有のライセンスが適応されており、これらは必ずしもオープンソースとは言えない可能性がある点にご注意ください。
- 個人が開発したモデルに関する記述では、作成者の敬称は省略させていただいております。 :::
この記事の管理は GitHub で行っています。記事の間違いを発見した場合、あるいはモデルの追加提案を行いたい場合は、GitHub Issues 経由で報告していただけますと幸いです。
::: details 目次 [[toc]] :::
画像を含むテキスト生成モデルはこちら
| 公開年 | アーキテクチャ | 入出力で扱える トークン数 |
学習テキスト | 開発元 | ライセンス / 利用規約 | |
|---|---|---|---|---|---|---|
| Sarashina2-8x70B | 2024 | MoE (8x70b (465b)) |
8,192 | Sarashina2 (70B) に対して Sparse Upcycling で学習 | SB Intuitions | Sarashina Model NonCommercial License |
| LLM-jp-3 172B | 2024 | Llama (172b, 172b-instruct2, 172b-instruct3) |
4,096 | 事前学習: llm-jp-corpus-v3 (計 2.1T トークン) Instruction Tuning: ichikara-instruction, AnswerCarefully Dataset, magpie-sft-v1.0, Daring-Anteater, FLAN, ichikara-instruction-format, AutoMultiTurnByCalm3-22B, ramdom-to-fixed-multiturn-Calm3, wizardlm8x22b-logical-math-coding-sft-ja, wizardlm8x22b-logical-math-coding-sft_additional-ja, Synthetic-JP-EN-Coding-Dataset-567k DPO (instruct3 only): aya-ja-evol-inst, ac-self-inst |
大規模言語モデル研究開発センター | 事前学習済みモデル: LLM-jp-3 172B Terms of Use 事後学習済みモデル: llm-jp-3-172b-instruct3利用許諾契約 |
| LLM-jp-3 172B beta2 | 2024 | Llama (172b-beta2, 172b-beta2-instruct2) |
4,096 | 事前学習: llm-jp-corpus-v3の一部 (計 1.4T トークン) Instruction Tuning: ichikara-instruction, AnswerCarefully Dataset, magpie-sft-v1.0, Daring-Anteater, FLAN, ichikara-instruction-format, AutoMultiTurnByCalm3-22B, ramdom-to-fixed-multiturn-Calm3, wizardlm8x22b-logical-math-coding-sft-ja, wizardlm8x22b-logical-math-coding-sft_additional-ja, Synthetic-JP-EN-Coding-Dataset-567k |
大規模言語モデル研究開発センター | LLM-jp-3 172B beta2 Terms of Use |
| LLM-jp-3 172B beta1 | 2024 | Llama (172b-beta1, 172b-beta1-instruct) |
4,096 | 事前学習: llm-jp-corpus-v3の一部 (計 0.7T トークン) Instruction Tuning: ichikara-instruction, AnswerCarefully Dataset, Dolly Dataset, OASST1, OASST2, Aya Dataset, ichikara-instruction-format, Daring-Anteater, FLAN |
大規模言語モデル研究開発センター | LLM-jp-3 172B beta1 Terms of Use |
| LLM-jp-3 172B alpha | 2024 | Llama (172b-alpha1, 172b-alpha1-instruct, 172b-alpha2, 172b-alpha2-instruct) |
4,096 | 事前学習: llm-jp-corpus-v3の一部 (alpha1: 計 0.7T トークン, alpha2: 計 1.4T トークン) Instruction Tuning: ichikara-instruction, AnswerCarefully Dataset, Dolly Dataset, OASST1, OASST2, Aya Dataset, ichikara-instruction-format, Daring-Anteater, FLAN |
大規模言語モデル研究開発センター | Apache 2.0 |
| Stockmark-2-100B-Instruct-beta | 2025 | Llama (100B-Instruct-beta, 100B-Instruct-beta-AWQ) |
4,096 | 事前学習: 計 1.5T トークン Instruction Tuning DPO |
ストックマーク | MIT |
| Stockmark-100b | 2024 | Llama (100b, 100b-instruct-v0.1) |
4,096 | 事前学習: RedPajama, 日本語 Wikipedia, Japanese mC4, Japanese CommonCrawl, 日本語特許, Stockmark Web Corpus (計 910B トークン) Instruction Tuning (LoRA): ichikara-instruction |
ストックマーク | MIT |
| PLaMo-100B-Pretrained | 2024 | Llama1 (100b) |
4,096 | 事前学習: Japanese CommonCrawl, RefinedWeb, 独自のデータセット (計: 2.0T トークン) |
Preferred Elements (Preferred Networks) | PLaMo Non-Commercial License |
| LLM-jp-3.1 | 2025 | Llama/MoE (8x13b (73b), 8x13b (73b)-instruct4, 13b, 13b-instruct4, 1.8b, 1.8b-instruct4) |
4,096 | 事前学習: llm-jp-corpus-v3 (計 2.5T トークン) 継続事前学習: インストラクション・レスポンスペア (計 90B トークン) SFT + DPO |
大規模言語モデル研究開発センター | Apache 2.0 |
| LLM-jp-3 MoE | 2025 | MoE (8x1.8b (9.3b), 8x1.8b (9.3b)-instruct2, 8x1.8b (9.3b)-instruct3, 8x13b (73b), 8x13b (73b)-instruct2, 8x13b (73b)-instruct3) |
4,096 | LLM-jp-3 (1.8b, 13b) に対して Drop-Upcycling で学習 | 大規模言語モデル研究開発センター | Apache 2.0 |
| Sarashina2 | 2024 | Llama (7b, 13b, 70b) |
7b, 13b: 4,096 70b: 8,192 |
事前学習: Japanese Common Crawl, SlimPajama, StarCoder (計 2.1T トークン) |
SB Intuitions | MIT |
| Sarashina1 | 2024 | GPT-NeoX (7b, 13b, 65b) |
2,048 | 事前学習: Japanese Common Crawl (計 1T トークン) |
SB Intuitions | MIT |
| Tanuki-8×8B | 2024 | MoE (47b) (v1.0, v1.0-AWQ, v1.0-GPTQ-4bit, v1.0-GPTQ-8bit, v1.0-GGUF) |
4,096 | 事前学習: 様々な Web 上のデータ, 合成データ(計 1.7T トークン) SFT, DPO: 様々な合成データ 2 |
松尾研LLM開発プロジェクト | Apache 2.0 |
| PLaMo 3 | 2025 | Gemma ベースのアーキテクチャ (2b-base, 8b-base, 31b-base) |
4,096 | 事前学習: 英語、日本語、コード、多言語 (2b: 200B トークン, 8b: 1T トークン, 31b: 3T トークン) |
Preferred Networks | PLaMo community license |
| Way-PLaMo-3-8b-chat | 2025 | PLaMo 3ベース (8b-chat) | 4,096 | Instruction Following SFT: Alpaca (51.7K), Dolly-15k-ja (15K) | 個人 (WayBob) | PLaMo community license |
| CyberAgentLM3 (CALM3) | 2024 | Llama (22b-chat, 22b-chat-selfimprove-experimental) |
16,384 | 不明 (計 2.0T トークン) |
サイバーエージェント | Apache 2.0 |
| LLM-jp-3 13B instruct3 | 2025 | Llama (150m, 150m-instruct2, 150m-instruct3, 440m, 440m-instruct2, 440m-instruct3, 980m, 980m-instruct2, 980m-instruct3, 1.8b-instrcut2, 1.8b-instruct3, 3.7b-instruct2, 3.7b-instruct3, 7.2b-instruct2, 7.2b-instruct3, 13b-instruct2, 13b-instruct3) |
4,096 | 事前学習: llm-jp-corpus-v3 (計 2.1T トークン) Instruction Tuning: ichikara-instruction, AnswerCarefully Dataset, magpie-sft-v1.0, Daring-Anteater, FLAN, ichikara-instruction-format, AutoMultiTurnByCalm3-22B, ramdom-to-fixed-multiturn-Calm3, wizardlm8x22b-logical-math-coding-sft-ja, Synthetic-JP-EN-Coding-Dataset-567k DPO (instruct3 only): aya-ja-evol-inst, ac-self-inst |
大規模言語モデル研究開発センター | Apache 2.0 |
| LLM-jp-3 13B | 2024 | Llama (1.8b, 1.8b-instruct, 3.7b, 3.7b-instruct, 7.2b, 7.2b-instruct, 13b, 13b-instruct) |
4,096 | 事前学習: llm-jp-corpus-v3 (計 2.1T トークン) Instruction Tuning: ichikara-instruction, AnswerCarefully Dataset, FLAN, ichikara-instruction-format, AutoMultiTurnByCalm3-22B, ramdom-to-fixed-multiturn-Calm3, wizardlm8x22b-logical-math-coding-sft_additional-ja, Synthetic-JP-EN-Coding-Dataset-567k |
大規模言語モデル研究開発センター | Apache 2.0 |
| llm-jp-3-3.7b-instruct-EZO | 2024 | Llama (3.7b-instruct-EZO-Common, 3.7b-instruct-EZO-Humanities) |
4,096 | LLM-jp-3 (3.7B) に対して追加学習 | Axcxept | Apache 2.0 |
| LLM-jp-13B v2.0 | 2024 | Llama (13b-v2.0, 13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0, 13b-instruct-full-ac_001-dolly-ichikara_004_001_single-oasst-oasst2-v2.0, 13b-instruct-full-ac_001_16x-dolly-ichikara_004_001_single-oasst-oasst2-v2.0) |
4,096 | 事前学習: llm-jp-corpus-v2 (計 260B トークン) Instruction Tuning: ichikara-instruction, AnswerCarefully Dataset, Dolly Dataset, OASST1, OASST2 |
LLM-jp | Apache 2.0 |
| Fugaku-LLM | 2024 | GPT (13B, 13B-instruct, 13B-instruct-gguf) |
2,048 | 事前学習: 独自 Instruction Tuning: OASST1, Dolly Dataset, GSM8K |
東工大, 東北大, 富士通, 理研, 名大, サイバーエージェント, Kotoba Technologies | Fugaku-LLM Terms of Use |
| LLM-jp-13B v1.1 | 2024 | GPT (13b-instruct-lora-dolly_en-dolly_ja-ichikara_003_001-oasst_en-oasst_ja-v1.1, 13b-instruct-full-dolly_en-dolly_ja-ichikara_003_001-oasst_en-oasst_ja-v1.1, 13b-dpo-lora-hh_rlhf_ja-v1.1) |
2,048 | Instruction Tuning (LoRA or Full-parameter FT): Dolly Dataset, OASST1, ichikara-instruction DPO (LoRA): HH RLHF |
LLM-jp | Apache 2.0 |
| LLM-jp-13B | 2023 | GPT (1.3b-v1.0, 13b-v1.0, 13b-instruct-full-jaster-v1.0, 13b-instruct-full-jaster-dolly-oasst-v1.0, 13b-instruct-full-dolly-oasst-v1.0, 13b-instruct-lora-jaster-v1.0, 13b-instruct-lora-jaster-dolly-oasst-v1.0, 13b-instruct-lora-dolly-oasst-v1.0) |
2,048 | 事前学習: llm-jp-corpus (Wikipedia, Japanese mC4, The Pile, Stack) (計 300B トークン) Instruction Tuning (Full-parameter FT or LoRA): jaster, Dolly Dataset, OASST1 |
LLM-jp | Apache 2.0 |
| PLaMo-13B | 2023 | Llama3 (13b, 13b-instruct, 13b-instruct-nc) |
base: 4,096 instruct, instruct-nc: 8,192 |
事前学習: C4, Project Gutenberg, RedPajama, 日本語 Wikipedia, Japanese mC4 (計 1.5T トークン) Instruction Tuning: Dolly Dataset, HH RLHF, OASST1, llm-japanese-datasetのwikinews subset (NCモデルでは商用利用不可の Alpaca Dataset も含めて学習) |
Preferred Networks | Apache 2.0 (NC モデルは CC BY-NC 4.0) |
| Stockmark-13b | 2023 | Llama (13b, 13b-instruct) |
2,048 | 事前学習: 日本語 Wikipedia、Japanese CC-100、Japanese mC4、Japanese CommonCrawl、日本語特許、Stockmark Web Corpus (計 220B トークン) Instruction Tuning (LoRA): ichikara-instruction |
ストックマーク | baseモデル: MIT instructモデル: CC BY-NC-SA 4.0 |
| Weblab-10B | 2023 | GPT-NeoX (10b, 10b-instruction-sft) |
2,048 | Japanese mC4 + The Pile(計 600B トークン) *instruction-sft モデルは Alpaca Dataset, FLAN でファインチューニング |
東大 松尾研 | CC BY-NC 4.0 |
| PLaMo 2.1 8B | 2025 | Samba ベースのアーキテクチャ (8b-cpt) |
32,768 | 訓練詳細不明 | Preferred Networks | PLaMo community license |
| PLaMo 2 8B | 2025 | Samba ベースのアーキテクチャ (8b) |
日本語、英語等のデータ (計 6T トークン) |
Preferred Networks | PLaMo community license | |
| Tanuki-8B | 2024 | Tanuki (8b) (v1.0, v1.0-AWQ, v1.0-GPTQ-4bit, v1.0-GPTQ-8bit, v1.0-GGUF) |
4,096 | 事前学習: 様々な Web 上のデータ, 合成データ(計 1.3T トークン) SFT, DPO: 様々な合成データ 2 |
松尾研LLM開発プロジェクト | Apache 2.0 |
| Japanese StableLM Alpha | 2023 | GPT-NeoX (base-alpha-7b, instruct-alpha-7b, instruct-alpha-7b-v2) |
2,048 | Wikipedia, Japanese CC-100, Japanese mC4, Japanese OSCAR, RedPajama (+ 独自のデータセット)4 (計 750B トークン) *instruct モデルでは Alpaca Dataset, Dolly Dataset, HH RLHF, llm-japanese-datasetのwikinews subsetでファインチューニング (v2では商用利用不可の Alpaca Dataset を除外) |
Stability AI | baseモデル: Apache 2.0 instruct モデル (v1): 独自のライセンス instruct モデル (v2): Apache 2.0 |
| CyberAgentLM2 (CALM2) | 2023 | Llama (7b, 7b-chat, 7b-chat-dpo-experimental) |
base: 4,096 chat: 32,768 |
一般公開されている日本語・英語のデータセット(詳細不明) (計 1.3T トークン) *dpo モデルは Chatbot Arena Conversations JA (calm2) Dataset を用いて DPO で学習 |
サイバーエージェント | Apache 2.0 (dpo モデルのみ CC BY 4.0) |
| OpenCALM | 2023 | GPT-NeoX (small, medium, large, 1b(1.4b), 3b(2.7b), 7b(6.8b)) |
2,048 | 日本語 Wikipedia + Jpanese mC4 + Japanese CC-100 |
サイバーエージェント | CC BY-SA 4.0 |
| Stormy | 2023 | GPT-NeoX (7b(6.8b)) |
2,048 | OpenCALM (6.8b) に対して llm-japanese-dataset v0 のうち翻訳タスクを除いたデータで LoRAチューニング |
東大 和泉研 | CC BY-SA 4.0 |
| ByGPT-JP | 2025 | Llama ベース (multi-lm-head-6.5b-alpha) |
5,760 | llm-jp-corpus-v3 のサブセット (ja_cc, ja_warp_html, ja_warp_pdf, ja_wiki, kaken) | 東北大 自然言語処理研究グループ |
Apache 2.0 |
| rinna GPT (英語やコードも含めて学習されたモデル) |
2023 | GPT-NeoX (4b(3.8b), 4b(3.8b)-8k, 4b(3.8b)-instruction-sft, 4b(3.8b)-instruction-ppo) |
8kモデル: 8,192 他: 2,048 |
Wikipedia, Japanese CC-100, Japanese C4, RedPajama, The Pile (計 524B トークン) *8k モデルでは 4,000トークンを超える長いトークン列でファインチューニング *instruction-sft モデルでは HH RLHF、FLAN でファインチューニング *instruction-ppo モデルでは HH RLHF で PPO ベースの強化学習 |
rinna | MIT |
| japanese-large-lm | 2023 | GPT-NeoX (1.7b, 3.6b, 1.7b-instruction-sft, 3.6b-instruction-sft) |
2,048 | 日本語 Wikipedia, Japanese CC-100, Japanese C4, Japanese OSCAR や独自データなど (計 650GB) *instruction-sft モデルでは OASST1 でファインチューニング |
LINE | Apache 2.0 |
| rinna GPT (日本語のみで学習されたモデル) |
2023 | GPT または GPT-NeoX (xsmall, small, medium, 1b, neox-small, neox-3.6b-instruction-sft-v2, neox-3.6b-instruction-ppo) |
≤ 2,048 | 日本語 Wikipedia + Japanese CC-100 (1b 以降のモデルでは さらに Japanese mC4 を追加) *instruction-sft, sft-v2 モデルでは HH RLHF、FLAN、SHP データセットでさらにファインチューニング *instruction-ppo モデルでは HH RLHF でさらに PPO ベースの強化学習 |
rinna | MIT |
| Sarashina2.2 | 2025 | Llama (0.5b, 0.5b-instruct-v0.1, 1b, 1b-instruct-v0.1, 3b, 3b-instruct-v0.1) |
8,192 | SB Intuitions | MIT | |
| レトリバT5 | 2023 | T5 (small (short), small (medium), small (long), base (short), base (medium), base (long), large (short), large (medium), large (long), xl(3b)) |
日本語 Wikipedia + Japanese mC4 | レトリバ | CC BY-SA 4.0 | |
| Spiral-RetNet-3b-base | 2024 | RetNet (3b) |
2,048 | Wikipedia, Japanese CC-100, CulturaX | Spiral.AI | MIT |
| kotomamba-2.8B | 2024 | Mamba (2.8B-v1.0) |
2,048 | 日本語 Wikipedia, Swallow Corpus, SlimPajama | Kotoba Technologies | Apache 2.0 |
| ABEJA GPT | 2022 | GPT または GPT-NeoX (large, neox-2.7b) |
日本語 Wikipedia + Japanese CC-100 + Japanese OSCAR |
ABEJA | MIT | |
| PLaMo 2.1 2B | 2025 | Causal decoder-only transformer (2b-cpt) |
32,768 | 訓練詳細不明 | Preferred Networks | PLaMo community license |
| Rakuten AI 2.0 mini | 2025 | Mistral (mini(1.5b), mini(1.5b)-instruct) |
131,072 | 楽天 | Apache 2.0 | |
| 早大GPT | 2022 | GPT (small, xl(1.5b)) |
日本語 Wikipedia + Japanese CC-100 |
早大 河原研 | CC BY-SA 4.0 | |
| ストックマークGPT | 2023 | GPT-NeoX (1.4b) |
日本語 Wikipedia (0.88B トークン) + Japanese CC-100 (10.5B トークン) + 独自のWebデータ (8.6B トークン) |
ストックマーク | MIT | |
| イエローバックGPT | 2021 | GPT-NeoX (1.3b) |
日本語 Wikipedia + Japanese CC-100 + Japanese OSCAR |
イエローバック | Apache 2.0 | |
| PLaMo 2 1B | 2025 | Samba ベースのアーキテクチャ (1b) |
日本語、英語等のデータ (計 4T トークン) |
Preferred Elements (Preferred Networks) | Apache 2.0 | |
| Sarashina2.1-1B | 2024 | Llama (1b) |
8,192 | Web 上などの日本語・英語データ(計 10T トークン) | SB Intuitions | Sarashina Model NonCommercial License |
| colorfulscoop GPT | 2021 | GPT (small) |
日本語 Wikipedia | Colorful Scoop | CC BY-SA 3.0 | |
| 東工大GPT | 2023 | GPT (medium, medium (逆方向)) 5 |
日本語 Wikipedia + Japanese CC-100 | 東工大 岡崎研 | CC BY-SA 4.0 | |
| 京大GPT | 2022 | GPT (small (文字レベル), medium (文字レベル), large (文字レベル)) |
日本語 Wikipedia (約2,700万文 (3.2GB)) + Japanese CC-100 (約6億1,900万文 (85GB)) + Japanese OSCAR (約3億2,600万文 (54GB)) |
京大 言語メディア研究室 | CC BY-SA 4.0 | |
| 日本語BART | 2023 | BART (base, large) |
日本語 Wikipedia (約1,800万文) | 京大 言語メディア研究室 | CC BY-SA 4.0 | |
| Megagon Labs T5 | 2021 | T5 (base) |
Japanese mC4 (87,425,304 ページ (782 GB)) + Japanese wiki40b (828,236 記事 (2 GB)) |
Megagon Labs (リクルート) |
Apache 2.0 |
| ドメイン | アーキテクチャ | 学習テキスト | 開発元 | ライセンス | |
|---|---|---|---|---|---|
| SIP-med-LLM/SIP-jmed-llm-2-8x13b-OP-instruct | 医療 | MoE | 医療系コーパス (44.2B トークン) で LLM-jp-3 MoE (8x13b) に追加事前学習、その後 Instruction Tuning | 戦略的イノベーション創造プログラム(SIP)第3期課題「統合型ヘルスケアシステムの構築における生成 AI 活用」テーマ1「安全性・信頼性を持つオープンな医療 LLM の開発・社会実装」 研究グループ | Apache 2.0 |
| 日本語対話Transformer | 対話 | Transformer | Twitter 上の日本語リプライのペア | NTT | 独自のライセンス |
| 日本語ニュースBART | ビジネス | BART (base) | 日本語ビジネスニュース記事(約2,100万記事 (2.9億文)) | ストックマーク | MIT |
| AcademicBART | 学術 | BART (base) | CiNii の日本語論文 | 愛媛大 人工知能研究室 | Apache 2.0 |
| 公開年 | ベースのLLM | 学習テキスト | 開発元 | ライセンス / 利用規約 | |
|---|---|---|---|---|---|
|
Llama 3.3 Swallow 70B (70B-v0.4, 70B-Instruct-v0.4) |
2025 | Llama 3.3 (70b) | 事前学習: Wikipedia, DCLM-baseline-1.0, Swallow Corpus Version 2, Cosmopedia, Laboro ParaCorpus, FineMath-4+, Swallow Code Version 0.3 Instruction Tuning: Gemma-2-LMSYS-Chat-1M-Synth, Swallow-Magpie-Ultra-v0.1, Swallow-Gemma-Magpie-v0.1, Swallow-Code-v0.3-Instruct-style |
Swallowプロジェクト | Llama 3.3 Community License & Gemma Terms of Use |
|
Llama 3.1 Swallow 70B (70B-v0.1, 70B-Instruct-v0.1, 70B-Instruct-v0.3) |
2024 | Llama 3.1 (70b) | 事前学習: The Stack v2, Wikipedia, DCLM-baseline-1.0, Swallow Corpus Version 2, Cosmopedia, Laboro ParaCorpus Instruction Tuning: lmsys-chat-1m-synth-ja-wo-pii-and-template-instructions, lmsys-chat-1m-synth-en-wo-pii-and-template-instructions, filtered-magpie-ultra-ja, filtered-magpie-ultra-en, gemma-magpie |
Swallowプロジェクト | Llama 3.1 Community License (Instructモデルは Gemma Terms of Use も適用) |
| cyberagent/Llama-3.1-70B-Japanese-Instruct-2407 | 2024 | Llama 3.1 (70b) | 不明 | サイバーエージェント | Llama 3.1 Community License |
|
Llama 3 Swallow 70B (70B-v0.1, 70B-Instruct-v0.1) |
2024 | Llama 3 (70b) | 事前学習: Algebraic Stack, Wikipedia, RefinedWeb, Swallow Corpus, Cosmopedia, Laboro ParaCorpus, OpenWebMath Instruction Tuning: OASST1 6 |
Swallowプロジェクト | Llama 3 Community License |
| turing-motors/Llama-3-heron-brain-70B-v0.3 | 2024 | Llama 3 (70b) | Llama 3 Swallow 70B に対して追加学習(詳細不明) | Turing | Llama 3 Community License |
|
Llama 3 Youko 70B (70b, 70b-instruct, 70b-gptq, 70b-instruct-gptq) |
2024 | Llama 3 (70b) | 事前学習: Wikipedia, Japanese C4, Japanese CC-100, Japanese OSCAR, The Pile, 独自のデータセット (計 5B トークン) Instruction Tuning: 独自のデータセット7 |
rinna | Llama 3 Community License |
|
Swallow 70B (70b-hf, 70b-instruct-hf, 70b-instruct-v0.1, 70b-NVE-hf, 70b-NVE-instruct-hf) |
2023 | Llama 2 (70b) | 事前学習: 日本語 Wikipedia, RefinedWeb, Swallow Corpus, The Pile Instruction Tuning: Dolly Dataset, HH RLHF, OASST1 *v0.1モデルでは OASST1, OASST2 を使用 |
Swallowプロジェクト | Llama 2 Community License |
|
KARAKURI LM (70b-v0.1, 70b-chat-v0.1) |
2024 | Llama 2 (70b) | 事前学習: mC4, CC100, OSCAR, RedPajama, 独自のデータセット (計 16B トークン) SteerLM: OASST2, 独自のデータセット |
カラクリ | Llama 2 Community License8 |
|
Japanese Stable LM Beta 70B (base-beta-70b, instruct-beta-70b) |
2023 | Llama 2 (70b) | 事前学習: Wikipedia, Japanese mC4, Japanese CC-100, Japanese OSCAR, SlimPajama(Books3を除外) (計 100B トークン) Instruction Tuning: Dolly Dataset, HH RLHF, OASST1 |
Stability AI | Llama 2 Community License |
|
Fujitsu-LLM-KG (8x7B_cpt, 8x7B_inst-infer_v1, 8x7B_inst-infer_v2, 8x7B_inst-gen_ja, 8x7B_inst-gen_en) |
2025 | Mixtral-8x7B-Instruct-v0.1 (46.7b) | 事前学習: 知識グラフ並列コーパス(森羅プロジェクト、Wikipedia等から合成) 2.1Bトークンを含む計約300Bトークン Instruction Tuning: 知識グラフ推論・生成タスク用データセット |
富士通 | Apache 2.0 |
|
Swallow-MX 8x7B (8x7b-NVE-v0.1) |
2024 | Mixtral-8x7B-Instruct-v0.1 (46.7b) | 事前学習: Algebraic Stack, Japanese Wikipedia, RefinedWeb, Swallow Corpus, The Pile, The Vault | Swallowプロジェクト | Apache 2.0 |
|
KARAKURI LM 8x7B Instruct v0.1 (8x7b-instruct-v0.1) |
2024 | Mixtral-8x7B-Instruct-v0.1 (46.7b) | Swallow-MX 8x7B に対して以下のデータセットで学習: Dolly Dataset, OASST2, HelpSteer, glaive-code-assistant-v3, glaive-function-calling-v2, synthetic_text_to_sql, MetaMathQA, orca-math-word-problems-200k, rag-dataset-12000, rag-hallucination-dataset-1000, 独自のデータセット | カラクリ | Apache 2.0 (?)9 |
|
KARAKURI LM 8x7B Chat v0.1 (8x7b-chat-v0.1) |
2024 | Mixtral-8x7B-Instruct-v0.1 (46.7b) | Swallow-MX 8x7B に対して SteerLM: OASST2, HelpSteer, 独自のデータセット |
カラクリ | Apache 2.0 |
|
ABEJA-Mixtral-8x7B-japanese (8x7B-v0.1-japanese, 8x7B-Instruct-v0.1-japanese, 8x7B-Instruct-v0.1-japanese-alpha, 8x7B-Instruct-v0.1-japanese-alpha-merged) |
2024 | Mixtral-8x7B-Instruct-v0.1 (46.7b) *Instructが名前に付いていないモデルのみ Mixtral-8x7B-v0.1 がベース |
事前学習: Japanese CC, Redpajama, 独自 (計 450B トークン) |
ABEJA | Apache 2.0 |
|
ELYZA-Thinking-1.0-Qwen-32B (32B) |
2025 | Qwen 2.5 (32b) | 事前学習 + SFT (Reasoning) | ELYZA | Apache 2.0 |
|
ELYZA-Shortcut-1.0-Qwen-32B (32B) |
2025 | Qwen 2.5 (32b) | 事前学習 + SFT | ELYZA | Apache 2.0 |
|
ABEJA-Qwen2.5-32b-Japanese-v1.0 (v1.0) |
2025 | Qwen2.5-32B-Instruct (32b) | 継続事前学習 + SFT + DPO: 約2万件の合成データ・人手アノテーションデータセット(抽出・推論能力に特化) | ABEJA | Apache 2.0 |
|
Qwen2.5 Bakeneko 32B (qwen2.5-bakeneko-32b, qwen2.5-bakeneko-32b-instruct, deepseek-r1-distill-qwen2.5-bakeneko-32b, qwq-bakeneko-32b) |
2025 | Qwen 2.5 (32b) | rinna | Apache 2.0 | |
|
ABEJA-QwQ32b-Reasoning-Japanese-v1.0 (v1.0) |
2025 | Qwen 2.5 (32b) | ABEJA-Qwen2.5-32b-Japanese-v0.1 に QwQ 32b の Chat Vector をマージした上で追加学習 | ABEJA | Apache 2.0 |
|
ABEJA-Qwen2.5-32b-Japanese-v0.1 (32b-Japanese-v0.1) |
2025 | Qwen 2.5 (32b) | 事前学習: Common Crawl, Cosmopedia, 独自 (計 100B トークン) + Chat Vector |
ABEJA | Apache 2.0 |
|
neoAI-JP-QwQ-32B (32B) |
2025 | Qwen 2.5 (32b) | 継続事前学習: llm-jp-corpus v3から約4Bトークン + QwQ-32BのChat Vector |
neoAI | Apache 2.0 |
|
neoAI-JP-DeepSeek-Qwen-32B (32B) |
2025 | Qwen 2.5 (32b) | 継続事前学習: llm-jp-corpus v3から約4Bトークン + DeepSeek-R1-Distill-Qwen-32BのChat Vector |
neoAI | Apache 2.0 |
|
Gemma-2-Llama Swallow 27B (27b-pt-v0.1, 27b-it-v0.1) |
2025 | Gemma 2 (27b) | 事前学習: Wikipedia, DCLM-baseline-1.0, Swallow Corpus Version 2, Cosmopedia, Laboro ParaCorpus, FineMath-4+, Swallow Code Version 0.3 Instruction Tuning: Gemma-2-LMSYS-Chat-1M-Synth, Swallow-Magpie-Ultra-v0.1, Swallow-Gemma-Magpie-v0.1 |
Swallowプロジェクト | Llama 3.3 Community License & Gemma Terms of Use |
|
Nekomata 14B (14b, 14b-instruction, 14b-gguf, 14b-instruction-gguf) |
2023 | Qwen (14b) | 事前学習: Wikipedia, Japanese C4, Japanese CC-100, Japanese OSCAR, The Pile, 独自のデータセット (計 66B トークン) Instruction Tuning: Dolly Dataset, FLAN, llm-japanese-datasetの一部 |
rinna | Tongyi Qianwen LICENSE |
|
Swallow 13B (13b-hf, 13b-instruct-hf, 13b-instruct-v0.1, 13b-NVE-hf) |
2023 | Llama 2 (13b) | 事前学習: 日本語 Wikipedia, RefinedWeb, Swallow Corpus, The Pile Instruction Tuning: Dolly Dataset, HH RLHF, OASST1 *v0.1モデルでは OASST1, OASST2 を使用 |
Swallowプロジェクト | Llama 2 Community License |
|
LEIA-Swallow-13B (13b) |
2024 | Llama 2 (13b) | Swallow 13B に対して LEIA で追加学習 | 個人 (山田育矢, 李凌寒) | Llama 2 Community License |
|
ELYZA-japanese-Llama-2-13b (13b, 13b-instruct, 13b-fast, 13b-fast-instruct) |
2023 | Llama 2 (13b) | 事前学翕: 日本語 Wikipedia, Japanese OSCAR, その他クロールデータなど (計 18B トークン) Instruction Tuning: 独自のデータセット |
ELYZA | Llama 2 Community License |
| cyberagent/Mistral-Nemo-Japanese-Instruct-2408 | 2024 | Mistral NeMo (12b) | 不明 | サイバーエージェント | Apache 2.0 |
|
Gemma-2-Llama Swallow 9B (9b-pt-v0.1, 9b-it-v0.1) |
2025 | Gemma 2 (9b) | 事前学習: Wikipedia, DCLM-baseline-1.0, Swallow Corpus Version 2, Cosmopedia, Laboro ParaCorpus, FineMath-4+, Swallow Code Version 0.3 Instruction Tuning: Gemma-2-LMSYS-Chat-1M-Synth, Swallow-Magpie-Ultra-v0.1, Swallow-Gemma-Magpie-v0.1 |
Swallowプロジェクト | Llama 3.3 Community License & Gemma Terms of Use |
|
Llama 3.1 Swallow 8B (8B-v0.1, 8B-Instruct-v0.1, 8B-v0.2, 8B-Instruct-v0.2, 8B-Instruct-v0.3, 8B-Instruct-v0.5) |
2025 | Llama 3.1 (8b) | 事前学習: The Stack v2, Wikipedia, DCLM-baseline-1.0, Swallow Corpus Version 2, Cosmopedia, Laboro ParaCorpus Instruction Tuning: lmsys-chat-1m-synth-ja-wo-pii-and-template-instructions, lmsys-chat-1m-synth-en-wo-pii-and-template-instructions, filtered-magpie-ultra-ja, filtered-magpie-ultra-en, gemma-magpie, Gemma-3-LMSYS-Chat-1M-Synth |
Swallowプロジェクト | Llama 3.1 Community License (Instructモデルは Gemma Terms of Use も適用) |
|
Llama 3 Swallow 8B (8B-v0.1, 8B-Instruct-v0.1) |
2023 | Llama 3 (8b) | 事前学習: Algebraic Stack, Wikipedia, RefinedWeb, Swallow Corpus, Cosmopedia, Laboro ParaCorpus, OpenWebMath Instruction Tuning: OASST1 6 |
Swallowプロジェクト | Llama 3 Community License |
| turing-motors/Llama-3-heron-brain-8B-v0.3 | 2024 | Llama 3 (8b) | Llama 3 Swallow 8B に対して追加学習(詳細不明) | Turing | Llama 3 Community License |
|
Llama 3 Youko 8B (8b, 8b-instruct, 8b-gptq, 8b-instruct-gptq) |
2024 | Llama 3 (8b) | 事前学習: Wikipedia, Japanese C4, Japanese CC-100, Japanese OSCAR, The Pile, 独自のデータセット (計 22B トークン) Instruction Tuning7: Aya Dataset (Japanese subset), FLAN, Dolly Dataset, HH RLHF, OASST1, OASST2, MetaMathQA, CodeAlpaca Dataset, 独自のデータセット DPO: HelpSteer, HelpSteer2, 独自のデータセット |
rinna | Llama 3 Community License |
|
Llama 3 ELYZA JP 8B (8B, 8B-GGUF, 8B-AWQ) |
2024 | Llama 3 (8b) | 不明 | ELYZA | Llama 3 Community License |
|
Llama 3 neoAI 8B Chat v0.1 (8B-Chat-v0.1) |
2024 | Llama 3 (8b) | 不明 | neoAI | Llama 3 Community License |
|
Llama 3 tedllm (v0) |
2024 | Llama 3 (8b) | 事前学習: 日本語の一般コーパス | 東京エレクトロン デバイス | Llama 3 Community License |
|
ELYZA-Shortcut-1.0-Qwen-7B (7B) |
2025 | Qwen 2.5 (7b) | 事前学習 + SFT | ELYZA | Apache 2.0 |
|
ELYZA-Diffusion-1.0-Dream-7B (Base-7B, Instruct-7B) |
2026 | Dream (7b) | 事前学習: 日本語テキスト (約 62B トークン) Instruction Tuning: 日本語の指示データ (約 0.18B トークン) |
ELYZA | Apache 2.0 |
|
Swallow 7B (7b-hf, 7b-instruct-hf, 7b-instruct-v0.1, 7b-NVE-hf, 7b-NVE-instruct-hf, 7b-plus-hf) |
2023 | Llama 2 (7b) | 事前学習: 日本語 Wikipedia, RefinedWeb, Swallow Corpus, The Pile Instruction Tuning: Dolly Dataset, HH RLHF, OASST1 *v0.1モデルでは OASST1, OASST2 を使用 |
Swallowプロジェクト | Llama 2 Community License |
|
LEIA-Swallow-7B (7b) |
2024 | Llama 2 (7b) | Swallow 7B に対して LEIA で追加学習 | 個人 (山田育矢, 李凌寒) | Llama 2 Community License |
|
ELYZA-japanese-Llama-2-7b (7b, 7b-instruct, 7b-fast, 7b-fast-instruct) |
2023 | Llama 2 (7b) | 事前学習: 日本語 Wikipedia, Japanese OSCAR, その他クロールデータなど (計 18B トークン) Instruction Tuning: 独自のデータセット |
ELYZA | Llama 2 Community License |
|
Youri 7B (7b, 7b-instruction, 7b-chat, 7b-gptq, 7b-instruction-gptq, 7b-chat-gptq) |
2023 | Llama 2 (7b) | 事前学習: Wikipedia, Japanese C4, Japanese CC-100, Japanese OSCAR, The Pile, 独自のデータセット (計 40B トークン) Instruction Tuning: Dolly Dataset, FLAN, llm-japanese-datasetの一部 |
rinna | Llama 2 Community License |
|
houou-7b (instruction-7b-v1, instruction-7b-v2, instruction-7b-v3) |
2023 | Llama 2 (7b) | Youri 7B (base) に対して Instruction Tuning: ichikara-instruction | マネーフォワード | Llama 2 Community License |
|
Japanese Stable LM Beta 7B (base-beta-7b, base-ja_vocab-beta-7b, instruct-beta-7b, instruct-ja_vocab-beta-7b) |
2023 | Llama 2 (7b) | 事前学習: Wikipedia, Japanese mC4, Japanese CC-100, Japanese OSCAR, SlimPajama(Books3を除外) (計 100B トークン) Instruction Tuning: Dolly Dataset, HH RLHF, OASST1 |
Stability AI | Llama 2 Community License |
|
SambaLingo-Japanese (Base, Chat) |
2024 | Llama 2 (7b) | 事前学習: CulturaX Instruction Tuning: ultrachat_200k DPO: ultrafeedback, cai-conversation-harmless |
SambaNova Systems | Llama 2 Community License (?)9 |
|
blue-lizard (blue-lizard) |
2024 | Llama 2 (7b) | 不明 | Deepreneur | Llama 2 Community License |
|
Swallow-MS 7B (7b-v0.1, 7b-instruct-v0.1) |
2024 | Mistral-7B-v0.1 (7b) | 事前学習: Algebraic Stack, Japanese Wikipedia, RefinedWeb, Swallow Corpus, The Pile Instruction Tuning: Dolly Dataset, OASST1 |
Swallowプロジェクト | Apache 2.0 |
|
Rakuten AI 2.0 (8x7B, 8x7B-instruct) |
2025 | Mistral-7B-v0.1 (7b) | 楽天 | Apache 2.0 | |
|
RakutenAI-7B (7B, 7B-instruct, 7B-chat) |
2024 | Mistral-7B-v0.1 (7b) | 事前学習: 不明 Instruction Tuning: Dolly Dataset, OASST1, (jasterと同様に)言語理解データセットの訓練データを Instruction Tuning 用に変換したもの, 独自のデータセット |
楽天 | Apache 2.0 |
|
Japanese Stable LM Gamma 7B (base-gamma-7b, instruct-gamma-7b) |
2023 | Mistral-7B-v0.1 (7b) | 事前学習: Wikipedia, Japanese mC4, Japanese CC-100, Japanese OSCAR, SlimPajama(Books3を除外) (計 100B トークン) Instruction Tuning: Dolly Dataset, HH RLHF, llm-japanese-dataSetのwikinews subset |
Stability AI | Apache 2.0 |
|
ChatNTQ JA 7B (7b-v1.0) |
2024 | Mistral-7B-v0.1 (7b) | Japanese Stable LM Gamma 7B (base) に対して独自のデータセットで Instruction Tuning | NTQ Solution | Apache 2.0 |
|
Shisa Gamma 7B (7b-v1) |
2023 | Mistral-7B-v0.1 (7b) | Japanese Stable LM Gamma 7B (base) に対して ultra-orca-boros-en-ja で Instruction Tuning | AUGMXNT | Apache 2.0 (?)9 |
|
Shisa 7B (base-7b-v1, 7b-v1) |
2023 | Mistral-7B-v0.1 (7b) | 事前学習: shisa-pretrain-en-ja-v1 (8B トークン) Instruction Tuning & DPO: ultra-orca-boros-en-ja, shisa-en-ja-dpo-v1 |
AUGMXNT | Apache 2.0 (?)9 |
|
Karasu (7B, 7B-chat, 7B-chat-plus, 7B-chat-plus-unleashed) |
2024 | Mistral-7B-v0.1 (7b) | Shisa 7B (base) に対して以下のデータセットで追加事前学習: 青空文庫, 日本の法律・判例, 日本語 Wikipedia, CulturaX の日本ドメインのデータ, UltraChat 200k (計 7B トークン) Instruction Tuning: ultra-orca-boros-en-ja-v1, OASST1, ShareGPT, 独自のデータセット |
Lightblue | Apache 2.0 (?)9 |
|
Nekomata 7B (7b, 7b-instruction, 7b-gguf, 7b-instruction-gguf) |
2023 | Qwen (7b) | 事前学習: Wikipedia, Japanese C4, Japanese CC-100, Japanese OSCAR, The Pile, 独自のデータセット (計 66B トークン) Instruction Tuning: Dolly Dataset, FLAN, llm-japanese-datasetの一部 |
rinna | Tongyi Qianwen LICENSE |
| lightblue/japanese-mpt-7b | 2023 | MPT (7b) | Japanese mC4 | Lightblue | Apache 2.0 |
|
Japanese Stable LM 3B-4E1T (3b-4e1t-base, 3b-4e1t-instruct) |
2024 | StableLM-3B-4E1T (3b) | 事前学習: Wikipedia, Japanese mC4, Japanese CC-100, Japanese OSCAR, SlimPajama(Books3を除外) (計 100B トークン) Instruction Tuning: Dolly Dataset, HH RLHF, llm-japanese-datasetのwikinews subset |
Stability AI | Apache 2.0 |
| kotomamba-2.8B-CL | 2024 | mamba-2.8b-slimpj (2.8b) |
日本語 Wikipedia, Swallow Corpus, SlimPajama | Kotoba Technologies | Apache 2.0 |
|
Gemma-2-Llama Swallow 2B (2b-pt-v0.1, 2b-it-v0.1) |
2025 | Gemma 2 (2b) | 事前学習: Wikipedia, DCLM-baseline-1.0, Swallow Corpus Version 2, Cosmopedia, Laboro ParaCorpus, FineMath-4+, Swallow Code Version 0.3 Instruction Tuning: Gemma-2-LMSYS-Chat-1M-Synth, Swallow-Magpie-Ultra-v0.1, Swallow-Gemma-Magpie-v0.1 |
Swallowプロジェクト | Llama 3.3 Community License & Gemma Terms of Use |
|
Gemma 2 Baku 2B (2b, 2b-it) |
2024 | Gemma 2 (2b) | 事前学習: Wikipedia, Japanese C4, Japanese CC-100, Japanese OSCAR, The Pile, 独自のデータセット (計 80B トークン) OPRO: 独自のデータセット 10 |
rinna | Gemma Terms of Use |
|
Japanese Stable LM 2 1.6B (base, instruct) |
2024 | Stable LM 2 1.6B (1.6b) | 事前学習: Wikipedia, CulturaX Instruction Tuning: jaster, ichikara-instruction, alpaca-gpt4-japanese, ultra-orca-boros-en-ja-v1 |
Stability AI | STABILITY AI NON-COMMERCIAL RESEARCH COMMUNITY LICENSE |
|
TinySwallow-1.5B (1.5B, 1.5B-Instruct, 1.5B-Instruct-q4f32_1-MLC, 1.5B-Insturct-GGUF) |
2025 | Qwen2.5 (1.5b) | 事前学習: Qwen2.5 (32b) を教師として TAID で学習 Instruction Tuning: Gemma-2-LMSYS-Chat-1M-Synth, swallow-magpie-ultra-v0.1, swallow-gemma-magpie-v0.1 |
Sakana AI, Swallowプロジェクト | Apache 2.0 |
| EQUES/OpenRS3-GRPO-ja | 2025 | Qwen2.5 (1.5b) | TinySwallow-1.5B-Instruct に対して kunishou/OpenMathInstruct-1-1.8m-ja でGRPO学習 | EQUES Inc. | ? |
| EQUES/TinyDeepSeek-JP-1.5B | 2025 | Qwen2.5 (1.5b) | TinySwallow-1.5B-Instruct に対して EQUES/japanese_ultrachat_6.6k でTAID蒸留 | EQUES Inc. | Apache 2.0 |
| EQUES/TinySwallow-Stratos-1.5B | 2025 | Qwen2.5 (1.5b) | TinySwallow-1.5B-Instruct に対して Bespoke-Stratos-35k で推論能力強化 | EQUES Inc. | Apache 2.0 |
| karasu-1.1B | 2023 | TinyLlama (1.1b) | 事前学習: Japanese OSCAR, Japanese mC4 (計 3B トークン) |
Lightblue | Apache 2.0 |
| ドメイン | ベースのLLM | 開発元 | ライセンス | |
|---|---|---|---|---|
| pfnet/Preferred-MedLLM-Qwen-72B | 医療 | Qwen2.5 (72b) | Preferred Networks | Qwen LICENSE |
|
Llama3-Preferred-MedSwallow-70B (70B) |
医療 | Llama 3 (70b) | Preferred Networks | Llama 3 Community License |
| AIgroup-CVM-utokyohospital/MedSwallow-70b | 医療 | Llama 2 (70b) | 東京大学医学部附属病院 循環器内科 AIグループ | CC BY-NC-SA 4.0 |
|
nekomata-14b-pfn-qfin (qfin, qfin-inst-merge) |
金融 | Qwen (14b) | Preferred Networks | Tongyi Qianwen LICENSE |
|
Watashiha-Llama-2-13B-Ogiri-sft (sft, sft-neuron) |
大喜利 | Llama 2 (13b) | わたしは | Llama 2 Community License |
| MedExamDoc-Llama-3.1-Swallow-8B-Instruct-v0.5 | 医療 | Llama 3.1 (8b) | Ingenta | Llama 3.1 Community License |
|
からまる (Karamaru-v1) |
江戸時代の古文 | Llama 3 (8b) | Sakana AI | Llama 3 Community License |
| Llama 3.1 Future Code Ja 8B | コーディング | Llama 3.1 (8b) |
フューチャー | Llama 3.1 Community License |
|
JPharmatron (7B-base, 7B) |
薬学 | Qwen2.5 (7b) | EQUES Inc. | CC BY-SA 4.0 |
|
ELYZA-japanese-CodeLlama-7b (7b, 7b-instruct) |
コーディング | Code Llama (7b) |
ELYZA | Llama 2 Community License |
| AIBunCho/japanese-novel-gpt-j-6b | 物語生成 | GPT-J (6b) | 個人 (大曽根宏幸) | CreativeML OpenRAIL-M License |
| NovelAI/genji-jp | 物語生成 | GPT-J (6b) | NovelAI | ? |
| ベースのLLM | 学習テキスト | 開発元 | ライセンス / 利用規約 | |
|---|---|---|---|---|
|
Llama 3.1 Shisa V2 405B (405b) |
Llama 3.1 (405b) | 高品質な日本語データセットでSFT/DPO | Shisa.AI | Llama 3.1 Community License |
|
AXCXEPT/EZO-Qwen2.5-72B-Instruct AXCXEPT/EZO-AutoCoTRAG-Qwen2.5-72B-Instruct_q4 |
Qwen2.5 (72b) | Axcxept | Qwen License | |
|
ao-Karasu (72B) |
Qwen1.5 (72b) | ultra-orca-boros-en-ja-v1, OASST1, ShareGPT, 日本語の公開技術ブログ, ニュース記事, QAサイトの回答, 独自のデータセット | Lightblue | Tongyi Qianwen LICENSE (?)9 |
|
Shisa V2.1 70B (70b) |
Llama 3.3 (70b) | SFT/DPO/強化学習/モデルマージを組み合わせた学習 | Shisa.AI | Llama 3.3 Community License |
| shisa-ai/shisa-v2-llama3.3-70b | Llama 3.3 (70b) | Shisa.AI | Llama 3.3 Community License | |
| AXCXEPT/Llama-3.1-70B-EZO-1.1-it | Llama 3.1 (70b) | Axcxept | Llama 3.1 Community License | |
|
Llama 3 shisa-v1-llama3-70b (70b) |
Llama 3 (70b) | ultra-orca-boros-en-ja-v1 | Shisa.AI | Llama 3 Community License (?)9 |
| AIgroup-CVM-utokyohospital/Llama-2-70b-chat-4bit-japanese | Llama 2 (70b) | 東京大学医学部附属病院 循環器内科 AIグループ | Llama 2 Community License | |
| doshisha-mil/llama-2-70b-chat-4bit-japanese-v1 | Llama 2 (70b) | 同志社大学 メディア情報学研究室 | ? | |
| cyberagent/DeepSeek-R1-Distill-Qwen-32B-Japanese | DeepSeek-R1-Distill-Qwen (32b) | サイバーエージェント | MIT | |
|
Flux-Japanese-Qwen2.5-32B-Instruct-V1.0 (V1.0) |
Qwen2.5-32B-Instruct (32b) | Precise-tuning: 日本語の知識・推論・言語回路をピンポイント特定し、パラメータの5%のみに対して調整を実施。3つの専門モデルを作成後、ピンポイントマージで統合 | FLUX | Apache 2.0 |
| karakuri-ai/karakuri-lm-32b-thinking-2501-exp | QwQ (32b) | カラクリ | Apache 2.0 | |
| shisa-ai/shisa-v2-qwen2.5-32b | Qwen2.5 (32b) | Shisa.AI | Apache 2.0 | |
|
AXCXEPT/EZO-Qwen2.5-32B-Instruct AXCXEPT/EZO-AutoCoTRAG-Qwen2.5-32B-Instruct |
Qwen2.5 (32b) | Axcxept | Apache 2.0 | |
| cyberagent/DeepSeek-R1-Distill-Qwen-14B-Japanese | DeepSeek-R1-Distill-Qwen (14b) | サイバーエージェント | MIT | |
|
Shisa V2.1 14B (14b) |
Phi-4 (14b) | SFT/DPO/強化学習/モデルマージを組み合わせた学習 | Shisa.AI | MIT |
| shisa-ai/shisa-v2-unphi4-14b | Phi-4 (14b) | Shisa.AI | MIT | |
|
EZO-Phi-4 (phi-4-open-R1-Distill-EZOv1, phi-4-deepseek-R1K-RL-EZO) |
Phi-4 (14b) | Axcxept | MIT | |
|
Qarasu (14B-chat-plus-unleashed) |
Qwen (14b) | ultra-orca-boros-en-ja-v1, OASST1, ShareGPT, 独自のデータセット | Lightblue | Tongyi Qianwen LICENSE (?)9 |
| Sparticle/llama-2-13b-chat-japanese-lora | Llama 2 (13b) | Sparticle | ? | |
| izumi-lab/llama-13b-japanese-lora-v0-1ep | Llama (13b) | 東大 和泉研 | ? | |
| shisa-ai/shisa-v2-mistral-nemo-12b | Mistral NeMo (12b) | Shisa.AI | Apache 2.0 | |
| AXCXEPT/EZO-Common-9B-gemma-2-it | Gemma 2 (9b) | Axcxept | Gemma Terms of Use | |
| AXCXEPT/EZO-Humanities-9B-gemma-2-it | Gemma 2 (9b) | Axcxept | Gemma Terms of Use | |
|
Shisa V2.1 8B (8b) |
Qwen3 (8b) | SFT/DPO/強化学習/モデルマージを組み合わせた学習 | Shisa.AI | Apache 2.0 |
| AXCXEPT/Qwen3-EZO-8B-beta | Qwen3 (8b) | Deep-Think技術による高性能推論 | Axcxept | Apache 2.0 |
| shisa-ai/shisa-v2-llama3.1-8b | Llama 3.1 (8b) | Shisa.AI | Llama 3.1 Community License | |
| AXCXEPT/Llama-3.1-8B-EZO-1.1-it | Llama 3.1 (8b) | Axcxept | Llama 3.1 Community License | |
|
Llama 3 Suzume 8B (8B-japanese, 8B-japanese-gguf) |
Llama 3 (8b) | megagonlabs/instruction_ja, ShareGPT, 独自のデータセット | Lightblue | Llama 3 Community License (?)9 |
|
Llama 3 shisa-v1-llama3-8b (8b) |
Llama 3 (8b) | ultra-orca-boros-en-ja-v1 | Shisa.AI | Llama 3 Community License (?)9 |
| AXCXEPT/Llama-3-EZO-8b-Common-it | Llama 3 (8b) | Axcxept | Llama 3 Community License | |
| lightblue/DeepSeek-R1-Distill-Qwen-7B-Japanese | DeepSeek-R1-Distill-Qwen (7b) | Lightblue | Apache 2.0 | |
|
ABEJA-Qwen2.5-7b-Japanese-v0.1 (v0.1) |
Qwen 2.5 (7b) | ABEJA | Apache 2.0 | |
| shisa-ai/shisa-v2-qwen2.5-7b | Qwen 2.5 (7b) | Shisa.AI | Apache 2.0 | |
|
Karasu DPO (7B) |
Qwen 2.5 (7b) | Lightblue | Apache 2.0 | |
| ganchengguang/Yoko-7B-Japanese-v1 | Llama 2 (7b) | 横浜国大 森研 | ? | |
| Sparticle/llama-2-7b-chat-japanese-lora | Llama 2 (7b) | Sparticle | ? | |
| izumi-lab/llama-7b-japanese-lora-v0-5ep | Llama (7b) | 東大 和泉研 | ? | |
| lightblue/jod | Mistral-7B-SlimOrca (7b) | Lightblue | Apache 2.0 | |
| NTQAI/chatntq-7b-jpntuned | RWKV-4 World (7b) | NTQ Solution | ? | |
|
Borea (Jp, Common, Coding) |
Phi-3.5 (3.8b) | Axcxept | MIT | |
|
Shisa V2.1 3B (3b) |
Llama 3.2 (3b) | SFT/DPO/強化学習/モデルマージを組み合わせた学習 | Shisa.AI | Llama 3.2 Community License |
| AXCXEPT/EZO-Llama-3.2-3B-Instruct-dpoE | Llama 3.2 (3b) | Axcxept | Llama 3.2 Community License | |
|
日本語版 Gemma 2 2B (2b-jpn-it) |
Gemma 2 (2b) | Gemma Terms of Use | ||
| AXCXEPT/EZO-gemma-2-2b-jpn-it | Gemma 2 (2b) | Axcxept | Gemma Terms of Use | |
| AXCXEPT/EZO-Common-T2-2B-gemma-2-it | Gemma 2 (2b) | Axcxept | Gemma Terms of Use | |
|
Shisa V2.1 1.2B (1.2b) |
LFM2 (1.2b) | SFT/DPO/強化学習/モデルマージを組み合わせた学習 | Shisa.AI | LFM Open License v1.0 |
|
LFM2.5-1.2B-JP (1.2B-JP) |
LFM2.5 (1.2b) | 不明 | Liquid AI | LFM Open License v1.0 |
| ドメイン | ベースのLLM | 開発元 | ライセンス | |
|---|---|---|---|---|
|
JMedLoRA (llama2-jmedlora-6.89ep) |
医療 | Llama 2 (70b) | 東京大学医学部附属病院 循環器内科 AIグループ | CC BY-NC 4.0 |
| pfnet/Qwen3-1.7B-pfn-qfin | 金融 | Qwen3 (1.72b) | Preferred Networks | PLaMo Community License |
| pfnet/Qwen2.5-1.5B-pfn-qfin | 金融 | Qwen2.5 (1.54b) | Preferred Networks | PLaMo Community License |
| マージ元のLLM(太字は日本語LLM) | 開発元 | ライセンス | |
|---|---|---|---|
| EQUES/MedLLama3-JP-v2 | Llama 3 Swallow 8B (Instruct), OpenBioLLM-8B, MMed-Llama 3 8B, Llama 3 ELYZA JP 8B | EQUES | Llama 3 Community License |
|
EvoLLM-JP-A (v1-7B) |
Shisa Gamma 7B (v1), Arithmo2 Mistral 7B, Abel 7B 002 | Sakana AI | Apache 2.0 |
|
EvoLLM-JP (v1-7B, v1-10B) |
Shisa Gamma 7B (v1), WizardMath-7B-V1.1, Abel 7B 002 | Sakana AI | MICROSOFT RESEARCH LICENSE |
| EQUES/TinyQwens-Merge-1.5B | SakanaAI/TinySwallow-1.5B-Instruct, EQUES/TinySwallow-Stratos-1.5B, deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B, Qwen/Qwen2.5-1.5B-Instruct | EQUES Inc. | Apache 2.0 |
| 入出力で扱える トークン数 |
開発元 | プラットフォーム | |
|---|---|---|---|
| PLaMo API | 32,768 | Preferred Networks | 独自 |
| AIのべりすと | 2,400 ~ 8,192 | Bit192 | 独自 |
| LHTM-OPT | オルツ | AWS Marketplace (SageMaker) | |
|
Syn (Syn, Syn Pro) |
32,768 | カラクリ, Upstage | AWS Marketplace (SageMaker) |
|
tsuzumi (tsuzumi-7b) |
NTT | Microsoft Foundry |
| アーキテクチャ | 入力で扱えるトークン数 | 学習テキスト | 開発元 | ライセンス | HuggingFace ですぐ使える? 11 | |
|---|---|---|---|---|---|---|
| ModernBERT-Ja | ModernBERT | 8,192 | 日本語・英語データ | SB Intuitions | MIT | ◯ (30m, 70m, 130m, 310m) |
| llm-jp-modernbert | ModernBERT | 8,192 | llm-jp-corpus-v4 の日本語サブセット(約0.69Tトークン) | 大規模言語モデル研究開発センター | Apache 2.0 | ◯ |
| 京大BERT | BERT (base, large) | 512 | 日本語 Wikipedia (約1,800万文) | 京大 言語メディア研究室 | Apache 2.0 | △ |
| 東北大BERT | BERT (base, large) | 512 | base (v1): 日本語 Wikipedia 約1,700万文 (2.6GB) base (v2) & large: 日本語 Wikipedia 約3,000万文 (4.0GB) base (v3) & large (v2): 日本語 Wikipedia 約3,400万文 (4.9GB) + 日本語 CC-100 約3億9,200万文 (74.3GB) |
東北大 自然言語処理研究グループ |
base (v1, v2) & large: CC BY-SA 3.0 base (v3) & large (v2): Apache 2.0 |
◯ (base (v1), base (v1, 文字レベル), base (v2), base (v2, 文字レベル), large, large (文字レベル), base (v3), base (v3, 文字レベル), large (v2), large (v2, 文字レベル)) |
| TohokuNLP BERT-alpha 500M | Llama ベースのエンコーダ12 |
4,096 または 8,192 |
llm-jp-corpus-v3 の日本語サブセット | 東北大 自然言語処理研究グループ |
Apache 2.0 | ◯ (sq4096-alpha, sq8192-alpha) |
| ByBERT-JP | Llama ベースのエンコーダ12 | 100m, 200m, 400m: 3,072 v2-100m: 4,096 |
llm-jp-corpus-v3 のサブセット 100m: 623B トークン 200m: 637B トークン 400m: 1.23T トークン v2-100m: 2.76T トークン |
東北大 自然言語処理研究グループ |
Apache 2.0 | ◯ (100m, 200m, 400m, v2-100m) |
| NICT BERT | BERT (base) | 512 | 日本語 Wikipedia | NICT | CC BY 4.0 | △ |
| Laboro BERT | BERT (base, large) | 512 | 日本語 Web コーパス (ニュースサイトやブログなど 計4,307のWebサイト、2,605,280ページ (12GB)) |
Laboro.AI | CC BY-NC 4.0 | ✕ |
| colorfulscoop BERT | BERT (base) | 512 | 日本語 Wikipedia | Colorful Scoop | CC BY-SA 3.0 | ◯ |
| 東大BERT | BERT (small) | 512 | 日本語 Wikipedia (約2,000万文 (2.9GB)) | 東大 和泉研 | CC BY-SA 4.0 | ◯ |
| chiTra (Sudachi Transformers) | BERT (base) | 512 | 国語研日本語ウェブコーパス (NWJC) (148GB) | NINJAL, ワークス徳島人工知能NLP研 | Apache 2.0 | △ |
| ACCMS BERT | BERT (base) | 512 | 日本語 Wikipedia (3.3GB) | 京大 ACCMS | CC BY-SA 4.0 | ◯ |
| 日立BERT | BERT (base) | 512 | 日本語 Wikipedia + Japanese CC-100 |
日立製作所 | CC BY-NC-SA 4.0 | ◯ 13 |
| RetrievaBERT | BERT 14 | 2,048 | Japanese CommonCrawl, RefinedWeb, Chinese Wikipedia, Korean Wikipedia, The Stack | レトリバ | Apache 2.0 | ◯ |
| Bandai Namco DistilBERT | DistilBERT | 512 | - (東北大BERT(base) を親モデルとして知識蒸留) | Bandai Namco Research | MIT | ◯ |
| Laboro DistilBERT | DistilBERT | 512 | - (Laboro BERT(base) を親モデルとして知識蒸留) | Laboro.AI | CC BY-NC 4.0 | ◯ |
| LINE DistilBERT | DistilBERT | 512 | - (LINE社内のBERTを親モデルとして知識蒸留) | LINE | Apache 2.0 | ◯ |
| rinna RoBERTa | RoBERTa (base) | 512 | 日本語 Wikipedia + Japanese CC-100 |
rinna | MIT | ◯ |
| 早大RoBERTa | RoBERTa (base, large) | 512 | 日本語 Wikipedia + Japanese CC-100 |
早大 河原研 | CC BY-SA 4.0 | ◯ (base, large, large (seq512)) 15 |
| インフォマティクスRoBERTa | RoBERTa (base) | 512 | 日本語 Wikipedia + Web 上の記事 (計25GB) |
インフォマティクス | Apache 2.0 | △ |
| 京大RoBERTa | RoBERTa (base, large) | 512 | 日本語 Wikipedia + Japanese CC-100 |
京大 言語メディア研究室 | CC BY-SA 4.0 | ◯ (base (文字レベル), large (文字レベル)) |
| 横浜国大RoBERTa | RoBERTa (base) | 512 | 日本語 Wikipedia (3.45GB) | 横浜国大 森研 | Apache 2.0 | ◯ |
| Megagon Labs RoBERTa | RoBERTa (base) 16 | 1,282 | Japanese mC4 (約2億文) | Megagon Labs (リクルート) |
MIT | ◯ |
| ACCMS RoBERTa | RoBERTa (base) | 512 | 日本語 Wikipedia (3.3GB) + Japanese CC-100 (70GB) | 京大 ACCMS | CC BY-SA 4.0 | ◯ |
| シナモンELECTRA | ELECTRA (small) | 512 | 日本語 Wikipedia | シナモン | Apache 2.0 | ◯ |
| Megagon Labs ELECTRA | ELECTRA (base) | 512 | Japanese mC4 (約2億文) | Megagon Labs (リクルート) |
MIT | ◯ |
| 東大ELECTRA | ELECTRA (small, base) | 512 | 日本語 Wikipedia (約2,000万文 (2.9GB)) | 東大 和泉研 | CC BY-SA 4.0 | ◯ (small, base) |
| 日本語RoFormer | RoFormer (base) | 512 | 日本語 Wikipedia (3.45GB) | 横浜国大 森研 | Apache 2.0 | ◯ |
| 日本語LUKE | LUKE (base, large) | 512 | 日本語 Wikipedia | Studio Ousia | Apache 2.0 | ◯ (base, large) |
| 京大DeBERTaV2 | DeBERTaV2 (tiny, base, large) | 512 | 日本語 Wikipedia + Japanese CC-100 + Japanese OSCAR (計171GB) |
京大 言語メディア研究室 | CC BY-SA 4.0 | ◯ (tiny, tiny (文字レベル), base, large) |
| 京大DeBERTaV3 | DeBERTaV3 (base) | 512 | llm-jp-corpus | 京大 言語メディア研究室 | Apache 2.0 | ◯ |
| 東大DeBERTaV2 | DeBERTaV2 (small, base) | 512 | 日本語 Wikipedia, 日本語 Wikinews, Japanese CC-100, Japanese mC4, Japanese OSCAR | 東大 和泉研 | CC BY-SA 4.0 | ◯ (small, base) |
| GLOBIS DeBERTaV3 | DeBERTaV3 (xsmall, base, large) | 512 | Wikipedia, WikiBooks, 青空文庫, Japanese CC-100, Japanese mC4, Japanese OSCAR | グロービス | CC BY-SA 4.0 | ◯ (xsmall, base, large) |
| 日本語BigBird | BigBird (base) | 4,096 | 日本語 Wikipedia + Japanese CC-100 + Japanese OSCAR |
早大 河原研 | CC BY-SA 4.0 | ◯ |
| 日本語LayoutLM | LayoutLM (base) | 512 | 東北大BERT (base, v2) で重みを初期化した上で、日本語 Wikipedia の文章とレイアウトで事前学習 | 日本総合研究所 | CC BY-SA 3.0 | ◯ |
| ドメイン | アーキテクチャ | 学習テキスト | 開発元 | ライセンス | HuggingFace ですぐ使える? | |
|---|---|---|---|---|---|---|
| 日本語ブログELECTRA | 口語 | ELECTRA (small) | 日本語ブログコーパス(3億5,400万文) | 北見工大 桝井・プタシンスキ研 | CC BY-SA 4.0 | ◯ |
| 日本語話し言葉BERT | 話し言葉 | BERT (base) | 東北大BERTに対して日本語話し言葉コーパス(CSJ)を用いて追加学習 (DAPTモデルでは国会議事録データも使用) |
レトリバ | Apache 2.0 | ◯ |
| AcademicRoBERTa | 学術 | RoBERTa (base) | CiNii の日本語論文 (約628万文) | 愛媛大 人工知能研究室 | Apache 2.0 | ◯ |
| local-politics-BERT | 政治 | BERT (base) | Wikipedia, 国会会議録, 地方議会会議録 | 地方議会会議録コーパスプロジェクト | CC BY-SA 4.0 | ◯ (SC-min, SC-minwiki, SC-2M-wiki, SC-2M-min, SC-2M-minwiki, FP-min, FP-minwiki) 17 |
| UBKE-LUKE | 経済 | LUKE (base) | 日本語 Wikipedia, 有価証券報告書, 経済ニュース記事 | ユーザベース | CC BY-NC | ◯ |
| 日本語金融BERT | 金融 | BERT (small, base) 18 | 日本語 Wikipedia + 日本語金融コーパス (約2,700万文 (5.2GB)) |
東大 和泉研 | CC BY-SA 4.0 | ◯ (small, base) |
| 日本語金融ELECTRA | 金融 | ELECTRA (small) | 日本語 Wikipedia (約2,000万文 (2.9GB)) + 日本語金融コーパス (約2,700万文 (5.2GB)) |
東大 和泉研 | CC BY-SA 4.0 | ◯ |
| 日本語ニュースBERT | ビジネス | BERT (base) | 日本語ビジネスニュース記事(300万記事) | ストックマーク | CC BY 4.0 | △ |
| 日本語ニュースXLNet | ビジネス | XLNet (base) | 日本語ビジネスニュース記事(300万記事) | ストックマーク | ? | ※ 非公式の HuggingFace 向けに変換されたモデルが公開されている |
| 日本語ニュースALBERT | ビジネス | ALBERT (base) | 日本語ビジネスニュース記事(300万記事) | ストックマーク | ? | △ |
| みんぱくBERT | 文化財 | BERT (base) | 東北大BERTに対して国立民族学博物館の文化財データで追加学習 | 兵庫県立大学 大島研 | MIT | ◯ (minpaku-v1, minpaku-v3, minpaku-v3-no-additional-token) |
| JPharmaBERT | 薬学 | BERT (base, large) | 日本語薬学文書 (2Bトークン) + PubMed英語要旨 (8Bトークン) + 薬学関連多言語データ (1.2Bトークン) |
EQUES | 不明 | ◯ (base, large) |
| UTH-BERT | 医療 | BERT (base) | 日本語診療記録(約1億2,000万行) | 東大病院 医療AI開発学講座 |
CC BY-NC-SA 4.0 | △ |
| medBERTjp | 医療 | BERT (base) | 日本語 Wikipedia + 日本語医療コーパス(『今日の診療プレミアム』Web版) |
阪大病院 医療情報学研究室 |
CC BY-NC-SA 4.0 | △ |
| JMedRoBERTa | 医療 | RoBERTa (base) | 日本語医学論文 (約1,100万文 (1.8GB)) | NII 相澤研 | CC BY-NC-SA 4.0 | ◯ (万病WordPiece, SentencePiece) 19 |
埋め込み (Embeddings) 作成に特化したモデル 20
| 開発元 | ライセンス | |
|---|---|---|
|
JaColBERTv2.5 (JaColBERTv2.4, JaColBERTv2.5) |
Answer.AI | MIT |
|
JaColBERTv2 (JaColBERTv2) |
個人 (Benjamin Clavié) | MIT |
|
JaColBERT (JaColBERT) |
個人 (Benjamin Clavié) | MIT |
汎用
| 公開年 | アーキテクチャ | 学習画像/テキスト | 開発元 | ライセンス / 利用規約 | |
|---|---|---|---|---|---|
|
Stockmark-2-VL-100B-beta (100B-beta) |
2025 | LLaVA-OneVision | 3段階学習: アライメント事前学習、キャプション拡張、インストラクション・推論ファインチューニング 合成データ: Qwen2.5-VL-72B から生成 |
ストックマーク | Qwen License |
|
Llama-3.1-70B-Instruct-multimodal-JP-Graph (v0.1) |
2025 | LLaVA (Llama-3.1-Swallow-70B-Instruct-v0.3 + Qwen2-VL-7B-Instruct) | 図表・グラフ理解特化の600万枚超の合成視覚データ (文字、円グラフ、棒グラフ、フローチャートなど)、実データ (FastLabel 協力) | リコー | Llama 3.1 Community License & Gemma Terms of Use & Qwen License & MIT & Apache 2.0 |
|
KARAKURI VL (32b-instruct-2507, 32b-thinking-2507-exp) |
2025 | Vision-Language (Qwen2.5-VL-32B ベース) | 日本語コンピュータユース特化のカスタムデータセット: 日本語コンピュータ操作記録、日本語文書画像QA、視覚情報解釈、日本語OCR、フローチャート理解 3段階学習: Supervised Fine-Tuning (SFT) + モデルマージ + 強化学習 *thinking モデルは Chain of Thought (CoT) アプローチによる推論プロセス明示 |
カラクリ | Apache 2.0 |
|
Heron-NVILA (1B, 2B, 15B, 33B) |
2025 | NVILA | 3段階学習: アライメント (558k日本語画像テキストペア + 595k LLaVA-Pretrain)、事前学習 (MOMIJI 13M、日本語画像テキストペア 6M、日本語インターリーブデータ 2M、coyo-700m 6M、mmc4-core 4M、Wikipedia-ja、LLaVA-Pretrain-JA、STAIR captions)、教師ありファインチューニング (LLaVA-instruct-v1.5-en、LLaVA-instruct-ja、日本語写真会話、JA-VG-VQA会話、SynthDog-ja、AI2D、SynthDog-en、Sherlock) | Turing | Apache 2.0 & OpenAI Terms of Use |
|
NABLA-VL (15B) |
2025 | microsoft/phi-4 + HuggingFaceM4/siglip-so400m-14-980-flash-attn2-navit | 単一画像・複数画像・動画入力対応。訓練詳細不明 | NABLAS | Apache 2.0 |
|
Sarashina2-Vision (8b, 14b) |
2025 | Sarashina2 + Qwen2-VL + 2-layer MLP | 3段階学習: プロジェクターウォームアップ (LLaVA-Pretrain 78M英語トークン)、視覚エンコーダー事前学習 (CC3M、CC12M、llm-jp-japanese-image-text-pairs、内部OCRデータセット、内部チャートキャプション合成データセット 3.8B日本語+7.7B英語トークン)、視覚的インストラクションチューニング (Japanese Visual Genome VQA、OCR-VQA、TextVQA、PlotQA、CLEVR翻訳版、DOCCI翻訳版、内部データセット 2.5B日本語+1.0B英語トークン) | SB Intuitions | MIT |
|
Asagi (2B, 4B, 8B, 14B) |
2025 | LLaVA | 新規クロール日本語ウェブサイト画像、既存日本語データセット、英語データセットの日本語翻訳 約2000万件 (English VLM Phi-3.5-vision-instruct と Japanese LLM CALM3-22B-Chat を使用したデータ合成) | 東大 原田研 | Apache 2.0 |
|
llava-calm2-siglip (llava-calm2-siglip) |
2024 | LLaVA | MS-COCO と VisualGenome から生成された対話データ | サイバーエージェント | Apache 2.0 |
|
LLM-jp-3 VILA 14B (14b) |
2024 | LLaVA | Japanese image text pairs, LLaVA-Pretrain, Japanese interleaved data, coyo (subset), mmc4-core (subset), llava-instruct-ja, japanese-photos-conv, ja-vg-vqa, synthdog-ja, LLaVA-1.5 instruction data (subset) | 大規模言語モデル研究開発センター | Apache 2.0 & OpenAI Terms of Use |
|
Heron (blip-ja-stablelm-base-7b-v0, blip-ja-stablelm-base-7b-v1, blip-ja-stablelm-base-7b-v1-llava-620k, git-ja-stablelm-base-7b-v0, git-ELYZA-fast-7b-v0, git-ja-stablelm-base-7b-v1) |
2023 | BLIP-2 または GIT | v1: LLaVA-Instruct-150K-JA または LLaVA-Instruct-620K-JA v0: LLaVA-Instruct-150K-JA, Japanese STAIR Captions, Japanese Visual Genome VQA dataset |
Turing | CC BY-NC 4.0 |
|
Japanese Stable VLM (japanese-stable-vlm) |
2023 | LLaVA | Japanese CC12M, STAIR Captions, Japanese Visual Genome VQA dataset | Stability AI | STABILITY AI JAPANESE STABLE VLM COMMUNITY LICENSE |
|
Japanese InstructBLIP Alpha (japanese-instructblip-alpha) |
2023 | InstructBLIP | Japanese CC12M, STAIR Captions, Japanese Visual Genome VQA dataset | Stability AI | JAPANESE STABLELM RESEARCH LICENSE |
|
rinna MiniGPT-4 (bilingual-gpt-neox-4b-minigpt4) |
2023 | MiniGPT-4 | CC12M, COCO 2014, Visual Genome, STAIR Captions, Japanese Visual Genome VQA dataset | rinna | MIT |
|
Sarashina2.2-Vision-3B (3.8b) |
2025 | Sarashina2.2-3B-Instruct + SigLIP + 2-layer MLP | 4段階学習 + Post-training: プロジェクターウォームアップ (英語画像キャプション)、視覚エンコーダー事前学習 (日本語チャート、OCR、キャプション)、全モデル事前学習 (画像テキストインターリーブデータ)、教師ありファインチューニング Post-training: Mixed Preference Optimization (計 日本語103B + 英語157.1B トークン) |
SB Intuitions | MIT |
ドメイン特化型
| アーキテクチャ | ドメイン | 開発元 | ライセンス | |
|---|---|---|---|---|
| watashiha/Watashiha-Llama-2-13B-Ogiri-sft-vlm | LLaVA | 大喜利 | わたしは | Llama 2 Community License |
| ベースのVLM | 学習画像/テキスト | 開発元 | ライセンス | |
|---|---|---|---|---|
| AXCXEPT/EZO-InternVL2-26B | InternVL2 | - | Axcxept | MIT |
| マージ元のLLM・VLM(太字は日本語LLM) | 開発元 | ライセンス | |
|---|---|---|---|
|
Llama-3-EvoVLM-JP-v2 (v2) |
Mantis-8B-SigLIP-Llama-3, Llama-3-ELYZA-JP-8B, Bunny-v1.1-Llama-3-8B-V | Sakana AI | Llama 3 Community License |
| AXCXEPT/Llama-3-EZO-VLM-1 | - (Llama-3-EvoVLM-JP-v2 に対して追加学習) | Axcxept | Llama 3 Community License |
|
EvoVLM-JP (v1-7B) |
Shisa Gamma 7B (v1), LLaVA-1.6-Mistral-7B | Sakana AI | Apache 2.0 |
| アーキテクチャ | 学習画像/テキスト | 開発元 | ライセンス | |
|---|---|---|---|---|
|
CommonArt β (commonart-beta) |
PixArt-Σ | CommonCatalog-cc-by, Megalith-10M, Smithonian Open Access, ArtBench (CC-0 only) | AI Picasso | Apache 2.0 |
|
EvoSDXL-JP (v1) |
Stable Diffusion | - (Japanese Stable Diffusion XL を含む複数の画像生成モデルをマージ) | Sakana AI | Apache 2.021 |
|
Japanese Stable Diffusion XL (japanese-stable-diffusion-xl) |
Stable Diffusion | 不明 | Stability AI | STABILITY AI JAPANESE STABLE DIFFUSION XL COMMUNITY LICENSE |
|
東北大Stable Diffusion (base, refiner) |
Stable Diffusion | WMT2023 Shared Task の日英対訳コーパス、laion2B-multi のキャプション約 1,300 万件 | 東北大 自然言語処理研究グループ |
CreativeML OpenRAIL-M License |
|
rinna Stable Diffusion (japanese-stable-diffusion) |
Stable Diffusion | LAION-5B データセットのうちキャプションが日本語のもの(画像約 1 億枚) | rinna | CreativeML OpenRAIL-M License |
| アーキテクチャ | ドメイン | 開発元 | ライセンス | |
|---|---|---|---|---|
|
Evo-Nishikie (v1) |
Stable Diffusion (ControlNet) | 浮世絵 | Sakana AI | Apache 2.021 |
|
Evo-Ukiyoe (v1) |
Stable Diffusion | 浮世絵 | Sakana AI | Apache 2.021 |
| アーキテクチャ | 学習データ | 開発元 | ライセンス | |
|---|---|---|---|---|
|
AIdeaLab VideoJP (AIdeaLab-VideoJP) |
CogVideoX | Pixabay, FineVideo | AIdeaLab | Apache 2.0 |
| アーキテクチャ | 学習画像/テキスト | 開発元 | ライセンス | |
|---|---|---|---|---|
|
llm-jp-clip (llm-jp-clip-vit-base-patch16, llm-jp-clip-vit-large-patch14) |
CLIP | ReLAION-5Bの英語サブセットのキャプション約15億件の翻訳 | 大規模言語モデル研究開発センター | Apache 2.0 |
|
LINEヤフーCLIP (clip-japanese-base, v2) |
CLIP | CommonCrawl, CC12M, YFCC100M (v2: Common Crawl 約20億画像-テキストペア + 知識蒸留) |
LINEヤフー | Apache 2.0 |
|
リクルートCLIP (japanese-clip-vit-b-32-roberta-base) |
CLIP | laion2B-multi のキャプション約1億2000万件 | リクルート | CC BY-4.0 |
|
Japanese Stable CLIP (japanese-stable-clip-vit-l-16) |
SigLIP | CC12M のキャプションを日本語に翻訳したもの、STAIR Captions | Stability AI | STABILITY AI JAPANESE STABLE CLIP COMMUNITY LICENSE |
|
rinna CLIP (japanese-clip-vit-b-16) |
CLIP | CC12M のキャプションを日本語に翻訳したもの | rinna | Apache 2.0 |
|
rinna CLOOB (japanese-cloob-vit-b-16) |
CLOOB | CC12M のキャプションを日本語に翻訳したもの | rinna | Apache 2.0 |
|
博報堂テクノロジーズCLIP (base, deeper, wider) |
CLIP | laion2B-multi のキャプション約1億2000万件 | 博報堂テクノロジーズ | CC BY-NC-SA 4.0 |
| アーキテクチャ | 学習コーパス | 開発元 | ライセンス | |
|---|---|---|---|---|
|
Kotoba-Whisper (v1.0, v1.0-ggml, v1.0-faster, v1.1, bilingual-v1.0, bilingual-v1.0-ggml, bilingual-v1.0-faster, v2.0, v2.0-ggml, v2.0-faster, v2.1, v2.2) |
Distil-Whisper | ReazonSpeech (+ Multilingual LibriSpeech) |
Kotoba Technologies | Apache 2.0 |
|
ReazonSpeech (espnet-v1, espnet-next, espnet-v2, nemo-v2) |
ESPnet (Conformer-Transducer) または NeMo (FastConformer-RNNT) | ReazonSpeech | レアゾン・ホールディングス | Apache 2.0 |
|
Reazon HuBERT ASR (rs35kh, rs35kh-bpe) |
HuBERT | ReazonSpeech v2.0 | レアゾン・ホールディングス | Apache 2.0 |
|
Reazon Zipformer ASR (rs35kh, rs35kh-bpe) |
Zipformer | ReazonSpeech v2.0 | レアゾン・ホールディングス | Apache 2.0 |
|
Reazon wav2vec 2.0 ASR (base-rs35kh, large-rs35kh) |
wav2vec 2.0 | ReazonSpeech v2.0 | レアゾン・ホールディングス | Apache 2.0 |
| アーキテクチャ | 学習コーパス | 開発元 | ライセンス | |
|---|---|---|---|---|
|
くしなだ (base, large) |
HuBERT | 約6万時間の日本語テレビ放送音声 | 産総研 知的メディア処理研究チーム | Apache 2.0 |
|
Reazon HuBERT (base-k2) |
HuBERT | ReazonSpeech | レアゾン・ホールディングス | Apache 2.0 |
|
東大HuBERT (base-jtube) |
HuBERT | JTubeSpeech | 東大 猿渡・高道研 | MIT |
|
いざなみ (base, large) |
wav2vec 2.0 | 約6万時間の日本語テレビ放送音声 | 産総研 知的メディア処理研究チーム | Apache 2.0 |
|
Reazon wav2vec 2.0 (base, large) |
wav2vec 2.0 | ReazonSpeech | レアゾン・ホールディングス | Apache 2.0 |
|
Reazon Zipformer (base-k2) |
Zipformer | ReazonSpeech | レアゾン・ホールディングス | Apache 2.0 |
| アーキテクチャ | 学習コーパス | 開発元 | ライセンス | |
|---|---|---|---|---|
|
J-Moshi (j-moshi, j-moshi-ext) |
Transformerベースのテキスト・音声基盤モデル (Moshi) | 音声対話コーパス(J-CHAT, 日本語Callhome, CSJ, 旅行代理店対話コーパス, 独自の雑談対話コーパス, 独自の相談対話コーパス), テキスト対話コーパス(日本語PersonaChat, 日本語EmpatheticDialogues, 日本語日常対話コーパス, RealPersonaChat) | 名大 東中研 | CC BY-NC 4.0 |
|
Kotoba-Speech (v0.1) |
Transformer | 不明 | Kotoba Technologies | Apache 2.0 |
| アーキテクチャ | 学習コーパス | 開発元 | ライセンス | |
|---|---|---|---|---|
|
Japanese MULAN (japanese-mulan-base) |
MULAN (AST + GLuCoSE) | 〜20k 社内音楽-テキストペア | LINEヤフー | Apache 2.0 |
| 説明 | 開発元 | |
|---|---|---|
| Nejumi LLMリーダーボード4 | LLM の日本語能力をアプリケーション開発(コーディング・関数呼び出し)、推論能力(数学的・論理的・抽象的推論)、専門知識、安全性評価(指示追従・幻覚抑制)等の観点で総合的に評価している。高難度ベンチマークの導入により上位モデル間の性能差を明確化。詳しくはこちらの記事を参照 | Weights & Biases |
| Swallow LLM Leaderboard v2 | 様々な LLM を日本語理解・生成タスク、日本語マルチターン対話タスク、英語理解・生成タスクの 3 種類から総合的に評価している。v2では推論特化モデルに対応するため、ゼロショット推論や思考連鎖プロンプトを採用し、より高難度なベンチマーク(計12タスク:日本語6、英語6)で評価を実施。また、既存の LLM 評価ツールを統合・改修した評価スクリプトである swallow-evaluation に加えて、新たに推論型モデル対応の swallow-evaluation-instruct を公開している。 | Swallowプロジェクト |
| 説明 | 開発元 | |
|---|---|---|
| オープン日本語LLMリーダーボード | llm-jp-eval を活用し、16種類のタスクで日本語の大規模言語モデルを評価している。 | LLM-jp, Hugging Face |
| llm-jp-eval | 複数のデータセットを横断して日本語 LLM を自動評価するツールである。 対応している全データセット一覧はこちらから確認できる(この中には JNLI や JCommonsenseQA といった JGLUE のタスクなども含まれている)。 |
LLM-jp |
| JP Language Model Evaluation Harness | Stability AI による EleutherAI/lm-evaluation-harness のフォーク。複数のデータセットを横断して日本語 LLM を自動評価するツールである。 対応している全データセット一覧はこちらから確認できる(この中には JNLI や JCommonsenseQA といった JGLUE のタスクなども含まれている)。 |
Stability AI |
| JGLUE | GLUE ベンチマークの日本語版として構築されたベンチマーク。MARC-ja, JCoLA, JSTS, JNLI, JSQuAD, JCommonsenseQA の 6 つのタスクを含む(JCoLA は東大大関研により作成)。各タスクの詳細はこちらやこちらを参照 | 早大 河原研, ヤフー |
| JMMLU | MMLU ベンチマークの日本語版として構築されたベンチマーク。自然科学・人文科学・社会科学の幅広い学術領域から 4 択問題を構成している。元の MMLU を翻訳しただけでなく、日本独自の文化的背景に基づく問題(日本問題)を新たに追加しているのが特徴である。 | 早大 河原研 |
| 説明 | 開発元 | |
|---|---|---|
| Japanese MT-bench | マルチターン会話能力を問う MT-bench の日本語版。Writing, Roleplay, Reasoning, Math, Coding, Extraction, STEM, Humanities の 8 つのカテゴリから 10 問ずつ、計 80 問が収録されている。なお、日本語版作成の際には、日本の文化に合うように質問内容に一部修正が加えられている。 GPT-4 による 10 段階の絶対評価を行うスクリプトも含まれている。 |
Stability AI |
| ELYZA-tasks-100 | 複雑な指示・タスクを含む100件の日本語データで、全てのデータに対して評価観点がアノテーションされている。 要約を修正し修正箇所を説明するタスク、具体的なエピソードから抽象的な教訓を述べるタスク、ユーザーの意図を汲み役に立つAIアシスタントとして振る舞うタスク、場合分けを必要とする複雑な算数のタスク、未知の言語からパターンを抽出し日本語訳する高度な推論を必要とするタスク、複数の指示を踏まえた上でyoutubeの対話を生成するタスク、架空の生き物や熟語に関する生成・大喜利などの想像力が求められるタスクなどが含まれている。 |
ELYZA |
| Preferred Generation Benchmark (pfgen-bench) |
50 問の日本語圏特有の常識問題をもとに、LLMの日本語生成能力を Fluency(流暢さ)、Truthfulness(真実性)、Helpfulness(有用性)の3つの評価軸から計測するベンチマーク。n-gram やルールベースでの指標の計算を行うことにより、LLM-as-a-Judge を行わずに評価を実施しているのが特徴である。 | Preferred Elements (Preferred Networks) |
| Rakuda Benchmark | 日本の地理、歴史、政治、社会に関する40問の自由質問に対してモデルに出力を行わせる。GPT-4 が同じ質問に対する2つのモデルの出力を比べ、どちらの答えが優れているかを判断することにより、モデルのランク付けを行う。 | YuzuAI |
| Japanese Vicuna QA Benchmark | MT-Bench の前身である vicuna-blog-eval の日本語版。一般、知識、ロールプレイ、常識、フェルミ推定、反実仮想、コーディング、数学、ライティングに関する 80 問の質問を収録している。また、GPT-4 による自動評価(勝率計算)のスクリプトも含まれている。リーダーボードはこちら | 京大 言語メディア研究室 |
| Tengu-Bench | 様々なカテゴリから成る 120 問の自由質問が収録されている。質問のカテゴリは以下の通り: 表の読み取り、論理パズル、アイデア生成、Function calling、長い文書要約(千トークン以上)、会話要約、長い文書のClosed QA(千トークン以上)、敬語、プロジェクト作成、数学、翻訳、抽出、倫理的制御、コスト見積、日本、雑談、ダジャレ、フォーマット、建設、ビジネス、法律判断、政治、架空の質問 | Lightblue |
| Shaberi | Japanese MT-bench、Rakuda Benchmark、ELYZA-tasks-100、Tengu-Bench の評価をまとめて行うことができるフレームワーク。なお、Shisa.AI によるフォークも存在する | Lightblue |
| 説明 | 開発元 | |
|---|---|---|
| Japanese Language Model Financial Evaluation Harness | 金融分野における日本語 LLM のベンチマーク。金融分野における感情分析タスク(chabsa)、証券分析における基礎知識タスク(cma_basics)、公認会計士試験における監査に関するタスク(cpa_audit)、ファイナンシャルプランナー試験の選択肢問題のタスク(fp2)、証券外務員試験の模擬試験タスク(security_sales_1)を含む。詳細はこちらを参照 | Preferred Networks |
| pfmt-bench-fin-ja | 金融分野における日本語 LLM の生成能力を測定するためのベンチマーク。 | Preferred Networks |
| jfinqa | 日本語金融数値推論 QA ベンチマーク。68社の有価証券報告書から抽出した1,000問の数値推論問題を収録。四則演算・比率計算・DuPont分析等の財務推論能力を評価する。PyPI、HuggingFace で公開。 | 個人 (ajtgjmdjp) |
| Stockmark Business Questions | 市場動向、時事問題、社会課題、ビジネストレンドなどの知識を問う問題が50題収録されている。 | ストックマーク |
| JMED-LLM | 日本語医療分野における LLM の評価用データセット。これまでに開発されてきた日本語の医療言語処理タスクを LLM ベンチマーク用にまとめている。 | NAIST ソーシャル・コンピューティング研究室 |
| JMedBench | 日本語医療分野の LLM ベンチマーク。選択肢問題、機械翻訳、固有表現抽出、文書分類、文類似度計算の 5 種類、計 20 個のデータセットが収録されている(一部のデータセットは JMMLU の医療分野問題や JMED-LLM から借用されている)。また、JMedBench での評価を簡単に行うためのツール med-eval が開発されている。 | NII 相澤研 |
| Japanese Medical Language Model Evaluation Harness | ワンコマンドで実行可能な医療分野に特化したLLMの日英能力評価プログラム。 | 個人 (助田一晟) |
| YakugakuQA | 薬剤師国家試験をベースとした日本語製薬分野の知識を問う評価データセット。事実に基づく薬学知識を測定する。 | EQUES Inc. |
| NayoseQA | 日本語製薬分野での多言語間用語対応・正規化能力を評価するデータセット。同義語や専門用語の理解度を測定する。 | EQUES Inc. |
| SogoCheck | 対となる文章間の一貫性推論を評価する新しいタスク。GPT-4oでも性能が低い高難度の推論タスク。 | EQUES Inc. |
| MedRECT | 臨床記録における医学的誤りの検出・訂正能力を評価するベンチマーク。誤り検出、誤り文特定、誤り訂正の 3 段階のタスクから構成される。日本語版(663 サンプル)と英語版(458 サンプル)があり、日本語版は医師国家試験をベースに構築されている。 | Preferred Networks |
| karakuri-bench | 日本語 LLM のカスタマーサポートにおける性能を測定するためのデータセット。 | カラクリ |
| 説明 | 開発元 | |
|---|---|---|
| JTruthfulQA | LLM の事実性を評価するデータセット TruthfulQA の日本語版。迷信などの、一部の人々に信じられているが事実とは言えない事象に関する質問群と、日本固有の知識に関する質問群が、一から収集されている。 | 早大 河原研 |
| JCommonsenseMorality | 日本語の常識道徳に関するデータセット。行為を表す文に対して、道徳的に間違っているか許容できるかの 2 値ラベルが割り当てられている。 | 北大 言語メディア学研究室 |
| JBBQ | 社会性バイアスQAデータセット BBQ を、日本の文化・慣習を踏まえて翻訳、修正、問題追加を行い作成されたデータセット。 | 東大 谷中研 |
| 説明 | 開発元 | |
|---|---|---|
| JFLD (Japanese Formal Logic Deduction) | 日本語 LLM の演繹推論能力を問うデータセット(同著者らが提案している FLD (Formal Logic Deduction) の日本語版)。LLM が持つ知識と切り分けて評価を行うために、反実仮想的なサンプルから構成されているのが特徴である。 | 日立製作所 |
| JHumanEval | 英語の指示から Python コードの生成能力を評価するベンチマークである HumanEval の日本語版。日本語版を作成する際には、まず機械翻訳にかけたあと、人手での修正を行っている。 | 日本女子大 倉光研 |
| JMultiPL-E | OpenAI HumanEval をベースに 17 のプログラミング言語(C++, C#, Go, Java, JavaScript, PHP, Ruby, Rust, Scala, Swift, TypeScript など)でコード生成能力を評価するデータセット。多言語でのコード理解とコード生成の性能を測定する。 | 東北大 自然言語処理研究グループ |
| 説明 | 開発元 | |
|---|---|---|
| LCTG Bench | 日本語 LLM の制御性ベンチマーク。出力のフォーマット、文字数、キーワード、NGワードの 4 つの観点から、LLM が制約を守って出力を行えているかを評価する。生成されたテキストの品質も合わせて評価する。 | サイバーエージェント |
| JFBench | 日本語 LLM の指示追従能力を評価するベンチマーク。IFBench を翻訳した 6 グループに加え、日本語特有の制約(敬体・常体、ひらがな・カタカナ・漢字の混在、数値表記など)10 グループを新たに作成。16 の制約グループ・174 の制約タイプを持ち、制約数 1/2/4/8 の組み合わせで計 1,600 サンプルを評価する。 | Preferred Networks |
| 説明 | 開発元 | |
|---|---|---|
| JMTEB |
MTEBの日本語版として作成されたベンチマーク。 文書クラスタリング、文書分類、文間類似度、文ペアラベル予測、文書抽出の5種類のタスクから構成されている(その後、リランキングタスクが新たに追加)。 |
SB Intuitions |
| JQaRA | 日本語の文書抽出・リランキング精度評価のためのデータセット。1,667件の質問文それぞれに対し、候補となる100件のドキュメントが割り当てられており、そのうち1件以上が質問文に回答できる内容になっている。質問文は JAQKET を、候補のドキュメントは日本語 Wikipedia を用いている。 | 個人 (舘野祐一) |
| JaCWIR | Wikipedia 以外のドメインで文書抽出・リランキングの評価を行えることを目指して作成されたデータセット。5,000件の質問文それぞれに対し、その質問文が作成される元になった 1 件の Webページと、質問文とは関係のない 99 件の Web ページが割り当てられている。 | 個人 (舘野祐一) |
| 説明 | 開発元 | |
|---|---|---|
| llm-jp-eval-mm | 日本語VLMの性能を複数のベンチマークタスクで評価するためのツール | 大規模言語モデル研究開発センター |
| BusinessSlideVQA | 複雑な日本語ビジネススライド画像に関する220問の質問応答データセット。文書理解能力の評価を目的として設計されている。 | ストックマーク |
| JMMMU | MMMU ベンチマークの日本語版として構築されたベンチマーク。720 件の MMMU の翻訳版の問題と 600 件の日本文化特有の新規の問題から構成される。 | 東大 相澤研 |
| JDocQA | 日本語ドキュメント(パンフレット、スライド、レポート、Web サイト)をもとに構築された、合計 11,600 件の質問から構成される質問応答データセット。解答不能問題を含め、様々な質問形式の質問が収録されている。 | NAIST 渡辺研 |
| Heron VLM リーダーボード powered by nejumi@WandB | Japanese-Heron-Bench と LLaVA-Bench-In-the-Wild (Japanese) の評価結果をまとめている。 | Turing, Weights & Biases |
| Japanese-Heron-Bench | 21 枚の画像に対して計 102 問の質問が割り当てられている。日本に関する知識を要求する画像・質問になっているのが特徴である。 | Turing |
| JA-VLM-Bench-In-the-Wild | Sakana AI が EvoVLM-JP-v1-7B の評価のために独自に用意したデータセット。42 枚の画像に対して計 50 問の質問が割り当てられている。日本に関する知識を要求する画像・質問になっているのが特徴である。 | Sakana AI |
| JA-Multi-Image-VQA | 複数の画像に対する日本語での質疑応答能力を評価するデータセット。 | Sakana AI |
| LLaVA-Bench-In-the-Wild (Japanese) | LLaVA-Bench-In-the-Wild を DeepL で日本語に訳したもの。24 枚の画像に対して計 60 問の質問が割り当てられている。 | Turing |
| LLaVA-Bench (COCO) Japanese | LLaVA の評価に使われた LLaVA-Bench (COCO) データセットを DeepL で日本語に訳したもの。30 枚の画像に対して各 3 種類の質問が割り当てられている。 | Turing |
| Japanese Visual Genome VQA dataset | Visual Genome dataset の画像をもとにアノテーションされた質問応答データセット。このデータセットの 500 件を切り出した JA-VG-VQA-500 が VLM の評価ベンチマークとして用いられることもある。 | ヤフー |
| japanese-bizform-table-kie | 非定型帳票からの情報抽出精度を評価するためのベンチマーク。50 種類のフォーム、合計 2,500 枚のドキュメント画像から構成される。 | AI inside |
このプロジェクトに貢献してくれているコントリビューターのみなさんです!

このリポジトリの要約はプレプリントとしても公開されています: Exploring Open Large Language Models for the Japanese Language: A Practical Guide
このリポジトリについて言及する場合は、以下の通り引用してください:
@article{awesomeJapanese2024,
title={{Exploring Open Large Language Models for the Japanese Language: A Practical Guide}},
author={Kaito Sugimoto},
doi={10.51094/jxiv.682},
journal={Jxiv preprint},
year={2024}
}
-
一部アーキテクチャの変更を加えている。詳しくは以下を参照: 1,000億パラメータ規模の独自LLM「PLaMo-100B」の事前学習 ↩
-
詳細は以下の記事を参照: 大規模言語モデルTanuki-8B, 8x8Bの位置づけや開発指針など, 大規模言語モデルを開発するにあたっての事前・事後学習の戦略メモー特に合成データについてー ↩ ↩2
-
ただし、モデル高速化のため本家の Llama に対してアーキテクチャの変更を加えている。詳しくは以下を参照: PLaMo-13Bを公開しました ↩
-
詳細は明記されていないが、プレスリリースには以下のような記述がある: 『学習データには、オープンデータセットに加え、Stability AI Japanが作成した独自のデータセットや、EleutherAI Polyglot project の日本語チーム及び Stable Community Japan のメンバーの協力のもとで作成したデータが含まれています。』 ↩
-
通常の左から右に単語を予測する代わりに、右から左に単語を予測するように訓練された言語モデルの評価を行った研究である。通常方向の言語モデルと逆方向の言語モデルの両方が公開されている。 ↩
-
Instruction Tuning を行う前に、Llama 3 Instruct と Llama 3 Base の差分の Chat Vector を加えている。 ↩ ↩2
-
Instruction Tuning を行った後に、Llama 3 Instruct と Llama 3 Base の差分の Chat Vector を加えている。 ↩ ↩2
-
ただし、KARAKURI LM を商用利用したい場合は、開発元であるカラクリ株式会社に直接連絡が必要であるとしている。 ↩
-
Instruction Tuning において、GPT-3.5, GPT-4 等の OpenAI のモデルで生成されたデータを使って学習しているため、OpenAI の規約に違反している可能性がある。 ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9 ↩10
-
ORPO を行う前に、Gemma 2 Instruct と Gemma 2 Base の差分の Chat Vector を加えている。 ↩
-
○: HuggingFace の Model Hub にモデルがアップロードされており、
AutoModel.from_pretrained()等ですぐ読み込める。 △: Model Hub にはモデルがアップロードされていないが、HuggingFace (transformers, 旧 pytorch-transformers) の形式に対応している。✕: モデルがHuggingFaceに対応していない。 ↩ -
Llama から Causal Attention を取り除くことにより、エンコーダ型モデルとして利用している。 ↩ ↩2
-
様々な形態素解析器とサブワード化手法の組み合わせを試した研究である。全ての組み合わせのモデルを掲載するのは大変なので、ここでは実験で最も平均のタスク性能が高い Juman++ + BPE のモデルを代表として掲載している。 ↩
-
ただし、最大系列長が 2048 に拡張されているほか、元の BERT に対して様々なアーキテクチャの変更が施されている。詳しくは HuggingFace リポジトリの README を参照。 ↩
-
nlp-waseda/roberta-base-japanese 及び nlp-waseda/roberta-large-japanese はモデル入力の最大トークン長を128で事前学習しているが、nlp-waseda/roberta-large-japanese-seq512 は512で事前学習している ↩
-
ただし、最大系列長が通常の 512 から 1282 まで拡張されており、より長い入力文を扱うことができる ↩
-
それぞれのモデルの詳細は作者らの論文の第4章を参照。なお、SC-2M-wiki モデルは Wikipedia でのみ事前学習されているため、厳密にはドメイン特化型モデルではない。 ↩
-
small の方は日本語 Wikipedia と日本語金融コーパスを合わせてスクラッチ学習しているが、base の方は東北大BERTに日本語金融コーパスを追加学習しているという違いがある ↩
-
万病WordPieceモデルは MeCab (IPA辞書+万病辞書) で単語分割した後 WordPiece でサブワード化するモデル、SentencePieceモデルは単語分割せずに直接 Unigram でサブワード化するモデル ↩
-
埋め込みモデルの分類は Dense Text Retrieval based on Pretrained Language Models: A Survey (Zhao+, 2022) を参考に行った。Bi-Encoder は 2つの入力を個別にモデルに入力し、それぞれベクトル化した上で、それらの内積やコサイン類似度を入力の近さとして定式化するアーキテクチャである。それに対し、Cross-Encoder は 2 つの入力を組み合わせたものをモデルに入力し、モデル内部で近さを直接計算するアーキテクチャである。情報抽出の分野では、Cross-Encoder の方が計算コストがかかるが、入力の近さをよりきめ細かくモデルが計算することが期待されるため、抽出結果の順序を再検討するリランカーとして用いられることも多い。なお、Bi-Encoder の中でも、入力を単一のベクトルではなく(トークンごとなどの)複数のベクトルとして表現するタイプのもの(例: ColBERT)があるため、Single-representation bi-encoders と Multi-representation bi-encoders にさらに細分化している。 ↩
-
ただし、研究および教育を目的とした利用を念頭に置くよう呼びかけている。また、マージ元のモデルのいくつかのライセンスは Apache 2.0 ではない点にも注意すること。 ↩ ↩2 ↩3
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for awesome-japanese-llm
Similar Open Source Tools

Awesome-LLM-Eval
Awesome-LLM-Eval: a curated list of tools, benchmarks, demos, papers for Large Language Models (like ChatGPT, LLaMA, GLM, Baichuan, etc) Evaluation on Language capabilities, Knowledge, Reasoning, Fairness and Safety.

llms-from-scratch-cn
This repository provides a detailed tutorial on how to build your own large language model (LLM) from scratch. It includes all the code necessary to create a GPT-like LLM, covering the encoding, pre-training, and fine-tuning processes. The tutorial is written in a clear and concise style, with plenty of examples and illustrations to help you understand the concepts involved. It is suitable for developers and researchers with some programming experience who are interested in learning more about LLMs and how to build them.
TigerBot
TigerBot is a cutting-edge foundation for your very own LLM, providing a world-class large model for innovative Chinese-style contributions. It offers various upgrades and features, such as search mode enhancements, support for large context lengths, and the ability to play text-based games. TigerBot is suitable for prompt-based game engine development, interactive game design, and real-time feedback for playable games.
MedicalGPT
MedicalGPT is a training medical GPT model with ChatGPT training pipeline, implement of Pretraining, Supervised Finetuning, RLHF(Reward Modeling and Reinforcement Learning) and DPO(Direct Preference Optimization).

Firefly
Firefly is an open-source large model training project that supports pre-training, fine-tuning, and DPO of mainstream large models. It includes models like Llama3, Gemma, Qwen1.5, MiniCPM, Llama, InternLM, Baichuan, ChatGLM, Yi, Deepseek, Qwen, Orion, Ziya, Xverse, Mistral, Mixtral-8x7B, Zephyr, Vicuna, Bloom, etc. The project supports full-parameter training, LoRA, QLoRA efficient training, and various tasks such as pre-training, SFT, and DPO. Suitable for users with limited training resources, QLoRA is recommended for fine-tuning instructions. The project has achieved good results on the Open LLM Leaderboard with QLoRA training process validation. The latest version has significant updates and adaptations for different chat model templates.
gpt_server
The GPT Server project leverages the basic capabilities of FastChat to provide the capabilities of an openai server. It perfectly adapts more models, optimizes models with poor compatibility in FastChat, and supports loading vllm, LMDeploy, and hf in various ways. It also supports all sentence_transformers compatible semantic vector models, including Chat templates with function roles, Function Calling (Tools) capability, and multi-modal large models. The project aims to reduce the difficulty of model adaptation and project usage, making it easier to deploy the latest models with minimal code changes.
ruoyi-vue-pro
The ruoyi-vue-pro repository is an open-source project that provides a comprehensive development platform with various functionalities such as system features, infrastructure, member center, data reports, workflow, payment system, mall system, ERP system, CRM system, and AI big model. It is built using Java backend with Spring Boot framework and Vue frontend with different versions like Vue3 with element-plus, Vue3 with vben(ant-design-vue), and Vue2 with element-ui. The project aims to offer a fast development platform for developers and enterprises, supporting features like dynamic menu loading, button-level access control, SaaS multi-tenancy, code generator, real-time communication, integration with third-party services like WeChat, Alipay, and cloud services, and more.
yudao-boot-mini
yudao-boot-mini is an open-source project focused on developing a rapid development platform for developers in China. It includes features like system functions, infrastructure, member center, data reports, workflow, mall system, WeChat official account, CRM, ERP, etc. The project is based on Spring Boot with Java backend and Vue for frontend. It offers various functionalities such as user management, role management, menu management, department management, workflow management, payment system, code generation, API documentation, database documentation, file service, WebSocket integration, message queue, Java monitoring, and more. The project is licensed under the MIT License, allowing both individuals and enterprises to use it freely without restrictions.
MindChat
MindChat is a psychological large language model designed to help individuals relieve psychological stress and solve mental confusion, ultimately improving mental health. It aims to provide a relaxed and open conversation environment for users to build trust and understanding. MindChat offers privacy, warmth, safety, timely, and convenient conversation settings to help users overcome difficulties and challenges, achieve self-growth, and development. The tool is suitable for both work and personal life scenarios, providing comprehensive psychological support and therapeutic assistance to users while strictly protecting user privacy. It combines psychological knowledge with artificial intelligence technology to contribute to a healthier, more inclusive, and equal society.
Chinese-LLaMA-Alpaca
This project open sources the **Chinese LLaMA model and the Alpaca large model fine-tuned with instructions**, to further promote the open research of large models in the Chinese NLP community. These models **extend the Chinese vocabulary based on the original LLaMA** and use Chinese data for secondary pre-training, further enhancing the basic Chinese semantic understanding ability. At the same time, the Chinese Alpaca model further uses Chinese instruction data for fine-tuning, significantly improving the model's understanding and execution of instructions.
MiniCPM
MiniCPM is a series of open-source large models on the client side jointly developed by Face Intelligence and Tsinghua University Natural Language Processing Laboratory. The main language model MiniCPM-2B has only 2.4 billion (2.4B) non-word embedding parameters, with a total of 2.7B parameters. - After SFT, MiniCPM-2B performs similarly to Mistral-7B on public comprehensive evaluation sets (better in Chinese, mathematics, and code capabilities), and outperforms models such as Llama2-13B, MPT-30B, and Falcon-40B overall. - After DPO, MiniCPM-2B also surpasses many representative open-source large models such as Llama2-70B-Chat, Vicuna-33B, Mistral-7B-Instruct-v0.1, and Zephyr-7B-alpha on the current evaluation set MTBench, which is closest to the user experience. - Based on MiniCPM-2B, a multi-modal large model MiniCPM-V 2.0 on the client side is constructed, which achieves the best performance of models below 7B in multiple test benchmarks, and surpasses larger parameter scale models such as Qwen-VL-Chat 9.6B, CogVLM-Chat 17.4B, and Yi-VL 34B on the OpenCompass leaderboard. MiniCPM-V 2.0 also demonstrates leading OCR capabilities, approaching Gemini Pro in scene text recognition capabilities. - After Int4 quantization, MiniCPM can be deployed and inferred on mobile phones, with a streaming output speed slightly higher than human speech speed. MiniCPM-V also directly runs through the deployment of multi-modal large models on mobile phones. - A single 1080/2080 can efficiently fine-tune parameters, and a single 3090/4090 can fully fine-tune parameters. A single machine can continuously train MiniCPM, and the secondary development cost is relatively low.
AstrBot
AstrBot is a powerful and versatile tool that leverages the capabilities of large language models (LLMs) like GPT-3, GPT-3.5, and GPT-4 to enhance communication and automate tasks. It seamlessly integrates with popular messaging platforms such as QQ, QQ Channel, and Telegram, enabling users to harness the power of AI within their daily conversations and workflows.
yudao-cloud
Yudao-cloud is an open-source project designed to provide a fast development platform for developers in China. It includes various system functions, infrastructure, member center, data reports, workflow, mall system, WeChat public account, CRM, ERP, etc. The project is based on Java backend with Spring Boot and Spring Cloud Alibaba microservices architecture. It supports multiple databases, message queues, authentication systems, dynamic menu loading, SaaS multi-tenant system, code generator, real-time communication, integration with third-party services like WeChat, Alipay, and more. The project is well-documented and follows the Alibaba Java development guidelines, ensuring clean code and architecture.

ai-hub
AI Hub Project aims to continuously test and evaluate mainstream large language models, while accumulating and managing various effective model invocation prompts. It has integrated all mainstream large language models in China, including OpenAI GPT-4 Turbo, Baidu ERNIE-Bot-4, Tencent ChatPro, MiniMax abab5.5-chat, and more. The project plans to continuously track, integrate, and evaluate new models. Users can access the models through REST services or Java code integration. The project also provides a testing suite for translation, coding, and benchmark testing.
AI-Practices
AI-Practices is a systematic platform for learning and practicing artificial intelligence, covering a wide range of topics from foundational machine learning to advanced deep learning, reinforcement learning, generative models, large language models, multimodal learning, deployment optimization, distributed training, and agent reasoning. The platform provides a structured learning path, combining theoretical knowledge with practical implementation, following industrial code standards and including Kaggle competition solutions. It covers core algorithms in machine learning, deep learning, reinforcement learning, generative models, and large models. The platform supports popular deep learning frameworks like PyTorch, TensorFlow, and Keras, along with essential data science tools like NumPy, Pandas, and Scikit-Learn.
For similar tasks
For similar jobs