Best AI tools for< Formalize Task >
3 - AI tool Sites
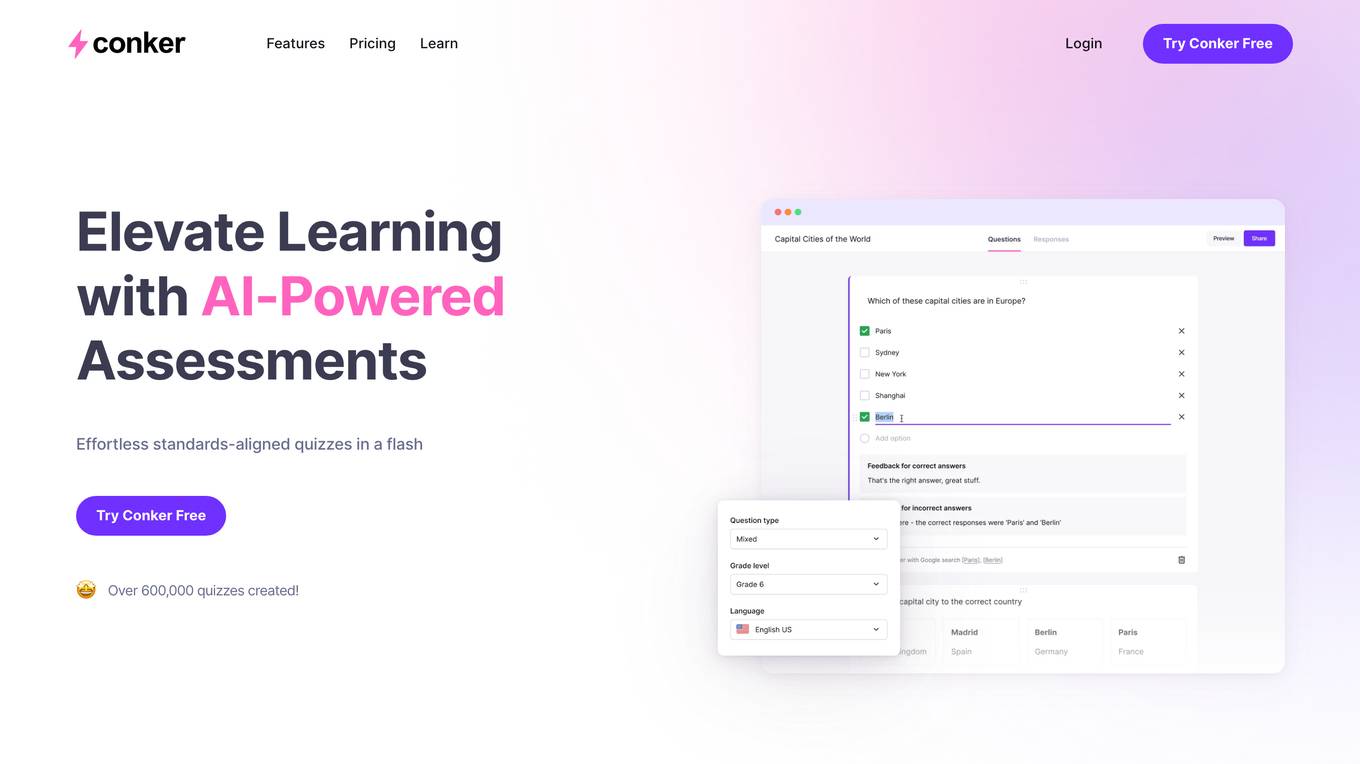
Conker
Conker is an AI-powered platform designed to elevate learning through effortless standards-aligned quizzes. With over 600,000 quizzes created, Conker offers powerful tools for classrooms, creating unique quizzes with engaging question types, customizable features, and integrated read-aloud for accessibility support. Teachers can easily tailor quizzes to match student needs, explore ready-made assessments, and seamlessly integrate Conker into their teaching workflow. The platform aims to maximize teaching time, ensure educational targets are met, streamline teaching processes, and capture student interest through interactive and captivating learning experiences.
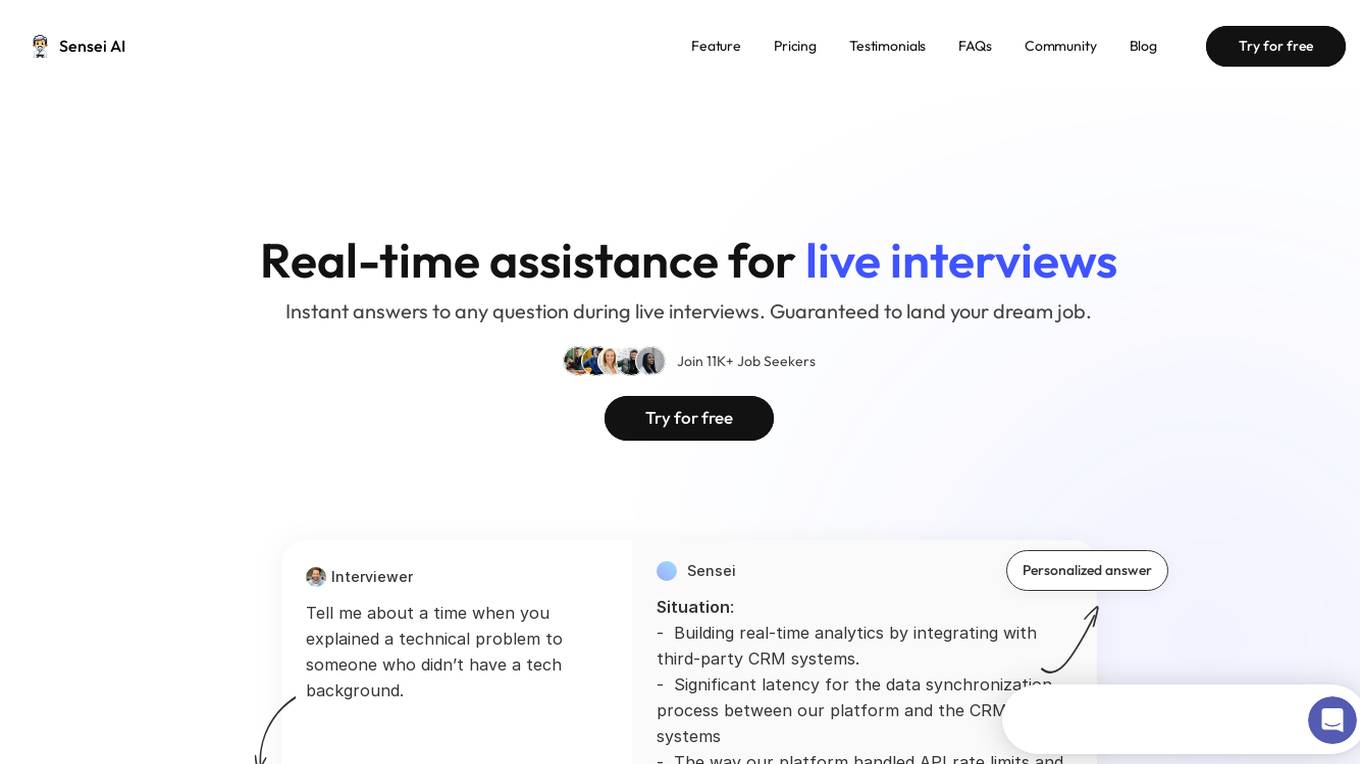
Sensei AI
Sensei AI is a real-time interview copilot application designed to provide assistance during live interviews. It offers instant answers to questions, personalized responses, and aims to help users land their dream job. The application uses advanced AI insights to understand the true intent behind interview questions, tailoring responses based on tone, word choices, keywords, timing, formality level, and context. Sensei AI also offers a hands-free experience, robust privacy features, and a personalized interview experience by tailoring answers to the user's job role, resume, and personal stories.
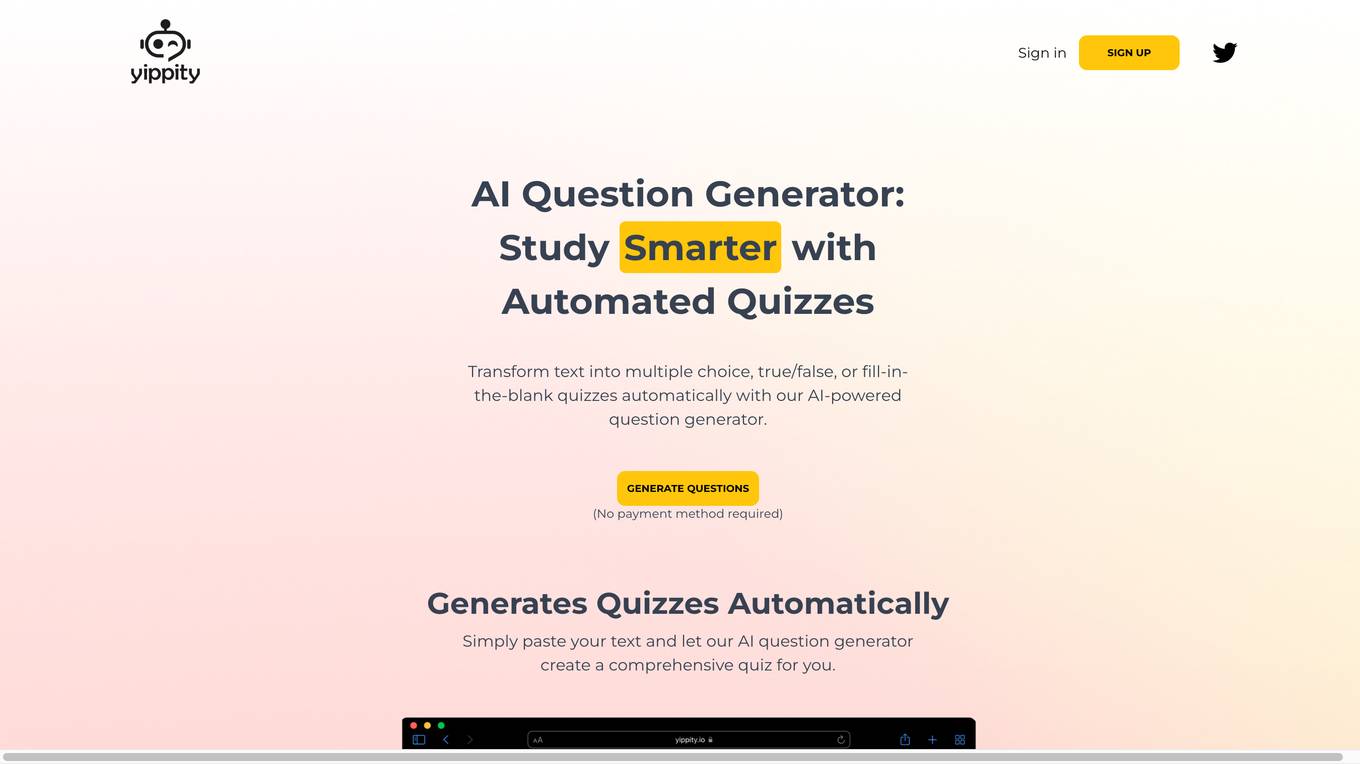
Yippity
Yippity is an AI-powered question generator that helps educators and trainers create engaging and interactive assessments. With Yippity, you can easily create multiple choice, true/false, fill-in-the-blank, and short answer questions. You can also add images, videos, and audio to your questions to make them more engaging. Yippity is a great tool for creating formative assessments, quizzes, and tests. It can also be used to create practice questions for students who are preparing for standardized tests.
0 - Open Source AI Tools
6 - OpenAI Gpts

Heroes Bounty Draftsman
I turn vague tasks into clear, formal bounties, asking for clarification when needed.
Prehistory Researcher
Engaging and informative guide on Prehistorical Ages, with a touch of formality.
电商文案大师
A versatile creator of e-commerce copy for all product types, balancing formality and approachability.
Text to DB Schema
Convert application descriptions to consumable DB schemas or create-table SQL statements