Best AI tools for< extract invoices >
20 - AI tool Sites
Receiptor AI
Receiptor AI is an automated tool designed to extract receipts and invoices from emails, streamlining accounting processes for individuals and businesses. It seamlessly scans emails, extracts crucial financial information, and organizes them into detailed reports or integrates them with accounting software. With features like automatic extraction, retroactive email analysis, multi-language support, and intelligent categorization, Receiptor AI offers a convenient and efficient solution for managing receipts and expenses.
FormX.ai
FormX.ai is an AI-powered data extraction and conversion tool that automates the process of extracting data from physical documents and converting it into digital formats. It supports a wide range of document types, including invoices, receipts, purchase orders, bank statements, contracts, HR forms, shipping orders, loyalty member applications, annual reports, business certificates, personnel licenses, and more. FormX.ai's pre-configured data extraction models and effortless API integration make it easy for businesses to integrate data extraction into their existing systems and workflows. With FormX.ai, businesses can save time and money on manual data entry and improve the accuracy and efficiency of their data processing.
Parsio
Parsio is an AI-powered document parser that can extract structured data from PDFs, emails, and other documents. It uses natural language processing to understand the context of the document and identify the relevant data points. Parsio can be used to automate a variety of tasks, such as extracting data from invoices, receipts, and emails.
AlgoDocs
AlgoDocs is a powerful AI Platform developed based on the latest technologies to streamline your processes and free your team from annoying and error-prone manual data entry by offering fast, secure, and accurate document data extraction.
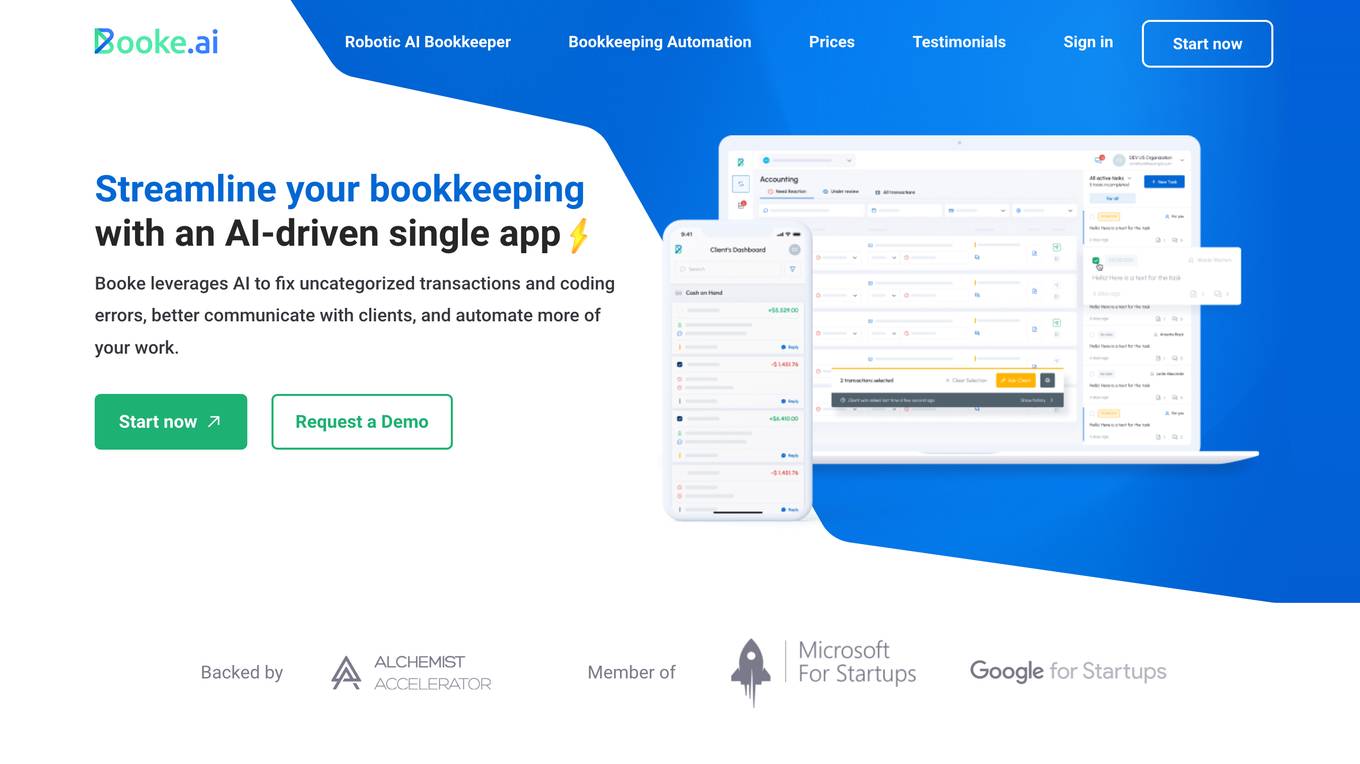
Booke AI
Booke AI is an AI-driven bookkeeping software that automates tasks, reduces errors, and improves communication. It uses AI to categorize transactions, extract data from invoices and receipts, and provide expert reconciliation assistance. Booke AI integrates with Xero, QuickBooks, and Zoho Books, and offers a user-friendly client portal for seamless collaboration. With Booke AI, businesses can save time, reduce stress, and improve the accuracy of their bookkeeping.
LedgerBox
LedgerBox is an intelligent document processing tool that leverages artificial intelligence and machine learning to automate the extraction of valuable data from various documents such as bank statements, invoices, and receipts. It helps streamline tasks like data entry, financial auditing, expense management, tax preparation, and more, by efficiently processing structured, semi-structured, and unstructured documents. With LedgerBox, users can improve accuracy, reduce manual errors, and enhance operational efficiency in tasks related to financial management and compliance monitoring.
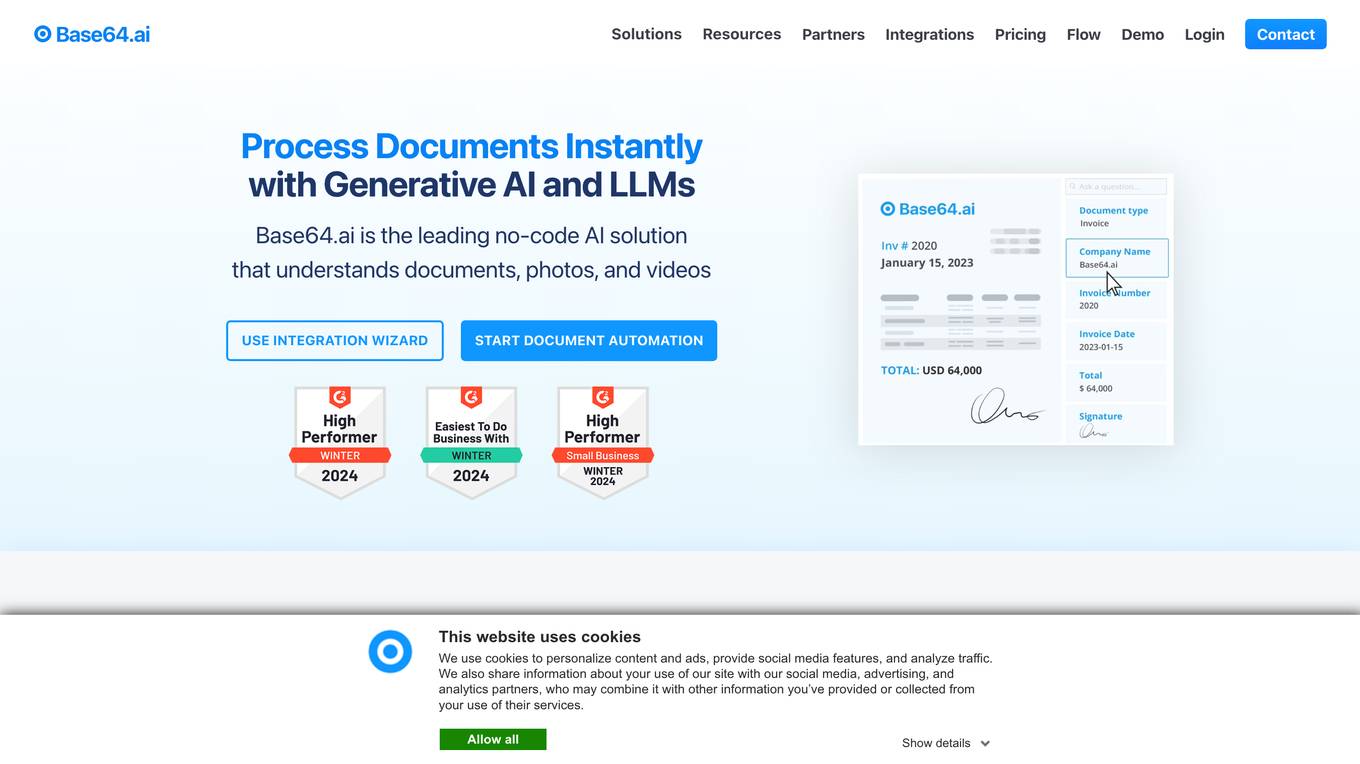
Base64.ai
Base64.ai is an automated document processing API that offers a leading no-code AI solution for understanding documents, photos, and videos. It provides a wide range of AI document processing features and solutions for various industries. With over 400+ integrations, Base64.ai ensures fast, secure, and accurate data extraction, certified for ISO, HIPAA, SOC 2 Type 1 & 2, and GDPR compliance. The platform allows users to add new document types, integrations, and business rules, commanding the AI to meet specific needs. Base64.ai also offers PII redaction, human-in-the-loop verification, and is accessible via API, RPA systems, scanners, web, and mobile apps.
Kupiks
Kupiks is an automated email parsing tool designed to simplify data entry processes by extracting key information from emails such as customer inquiries, leads, invoices, and more. By automating the data entry process, Kupiks helps save valuable time and reduce errors. The tool is user-friendly and streamlines workflow by providing a seamless solution for customer support, order management, and expense management.
Airparser
Airparser is an AI-powered email and document parser that revolutionizes data extraction by automatically extracting structured data from various sources such as emails, PDFs, and documents. It offers a user-friendly interface and efficient data extraction capabilities, enabling users to streamline processes like extracting contact information, dates, work experience, and more from different types of content. With features like GPT-powered parser, OCR engine, and seamless integration with 6000+ apps, Airparser is a versatile tool for automating document data extraction and improving workflow efficiency.
Cradl AI
Cradl AI is a no-code AI-powered document workflow automation tool that helps organizations automate document-related tasks, such as data extraction, processing, and validation. It uses AI to automatically extract data from complex document layouts, regardless of layout or language. Cradl AI also integrates with other no-code tools, making it easy to build and deploy custom AI models.
super.AI
Super.AI provides Intelligent Document Processing (IDP) solutions powered by Large Language Models (LLMs) and human-in-the-loop (HITL) capabilities. It automates document processing tasks such as data extraction, classification, and redaction, enabling businesses to streamline their workflows and improve accuracy. Super.AI's platform leverages cutting-edge AI models from providers like Amazon, Google, and OpenAI to handle complex documents, ensuring high-quality outputs. With its focus on accuracy, flexibility, and scalability, Super.AI caters to various industries, including financial services, insurance, logistics, and healthcare.
Extracta.ai
Extracta.ai is an AI-powered platform that specializes in data extraction from unstructured documents. The platform utilizes advanced technology to automate the process of extracting data from various types of documents, such as invoices, resumes, contracts, receipts, and custom documents. With Extracta.ai, users can define custom templates for data extraction without the need for extensive training. The platform ensures efficient and accurate extraction of structured data, eliminating the manual effort traditionally required for such tasks. Extracta.ai offers flexibility in extracting data from any document format, including PDFs, images, scans, digital documents, and text files.
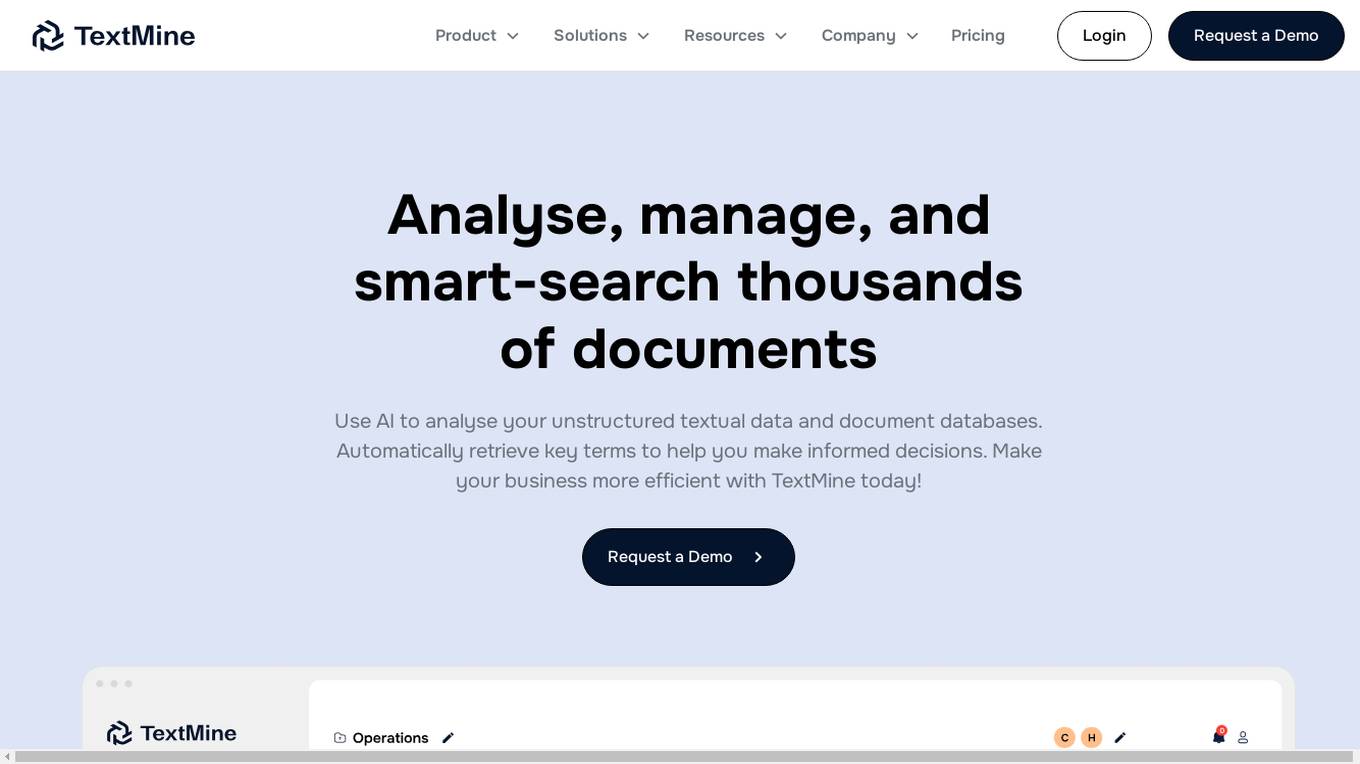
TextMine
TextMine is an AI-powered knowledge base that helps businesses analyze, manage, and search thousands of documents. It uses AI to analyze unstructured textual data and document databases, automatically retrieving key terms to help users make informed decisions. TextMine's features include a document vault for storing and managing documents, a categorization system for organizing documents, and a data extraction tool for extracting insights from documents. TextMine can help businesses save time, money, and improve efficiency by automating manual data entry and information retrieval tasks.
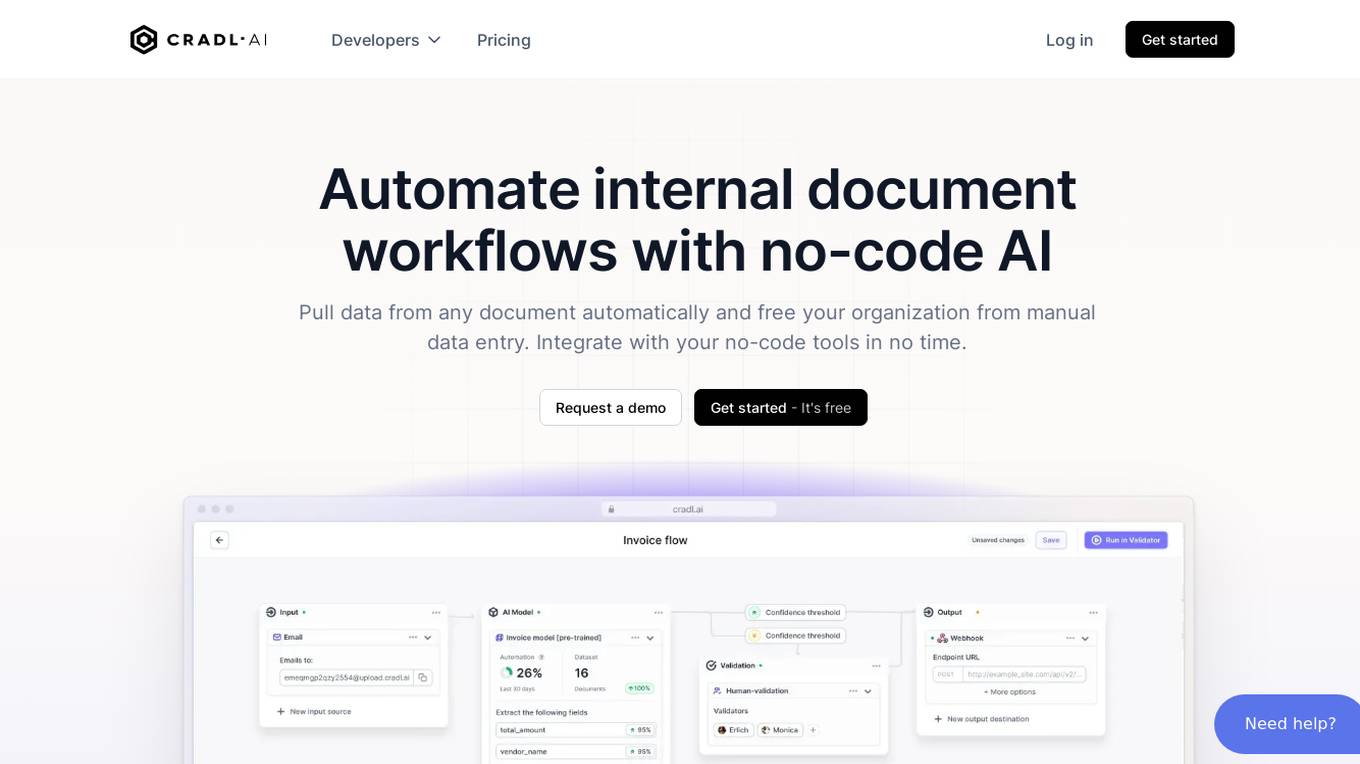
Cradl AI
Cradl AI is an AI-powered tool designed to automate document workflows with no-code AI. It enables users to extract data from any document automatically, integrate with no-code tools, and build custom AI models through an easy-to-use interface. The tool empowers automation teams across industries by extracting data from complex document layouts, regardless of language or structure. Cradl AI offers features such as line item extraction, fine-tuning AI models, human-in-the-loop validation, and seamless integration with automation tools. It is trusted by organizations for business-critical document automation, providing enterprise-level features like encrypted transmission, GDPR compliance, secure data handling, and auto-scaling.
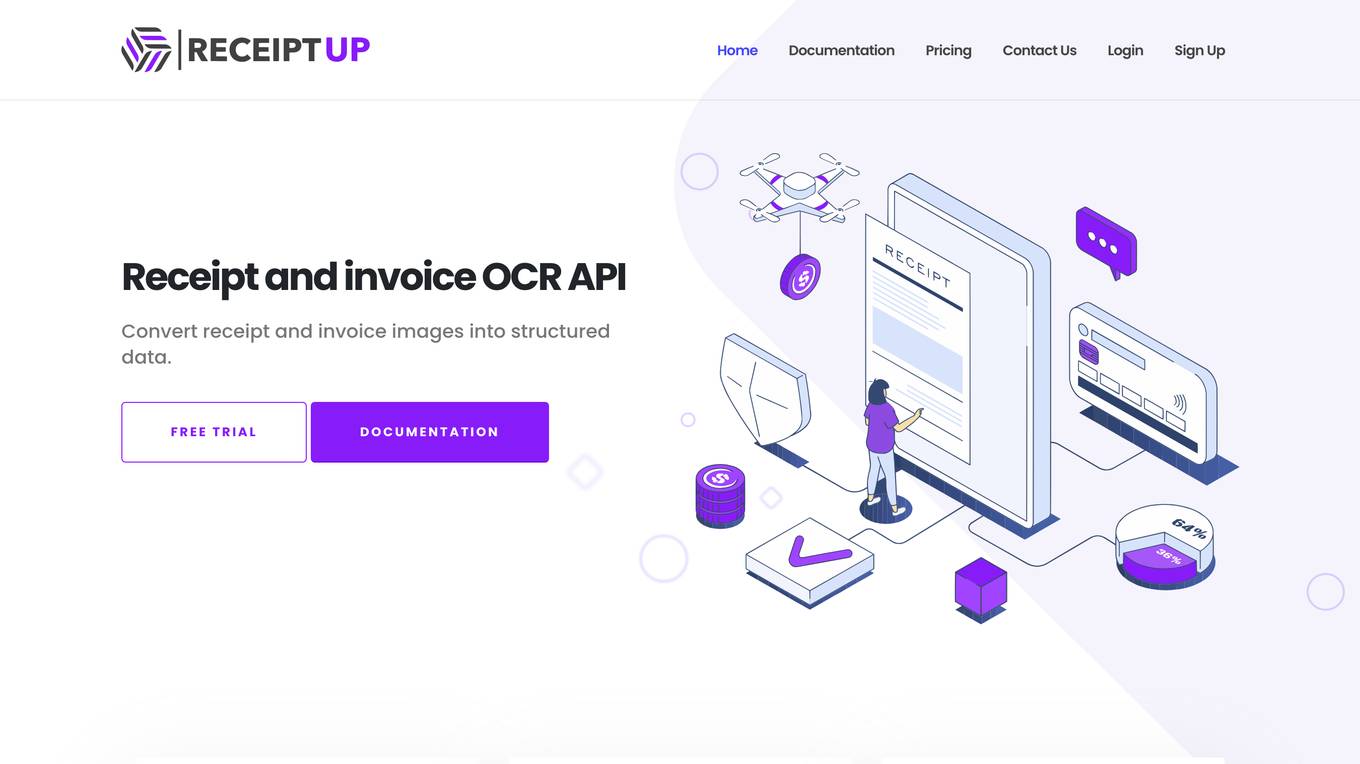
Receipt OCR API
Receipt OCR API by ReceiptUp is an advanced tool for precise data extraction from receipt and invoice images. The API leverages OCR and AI technology to accurately extract total amounts, taxes, dates, and merchant information, streamlining financial operations. It supports over 50 languages, multiple image formats, and offers affordable pricing. Users can easily integrate the API into their software systems for efficient receipt management and enhanced business analytics.
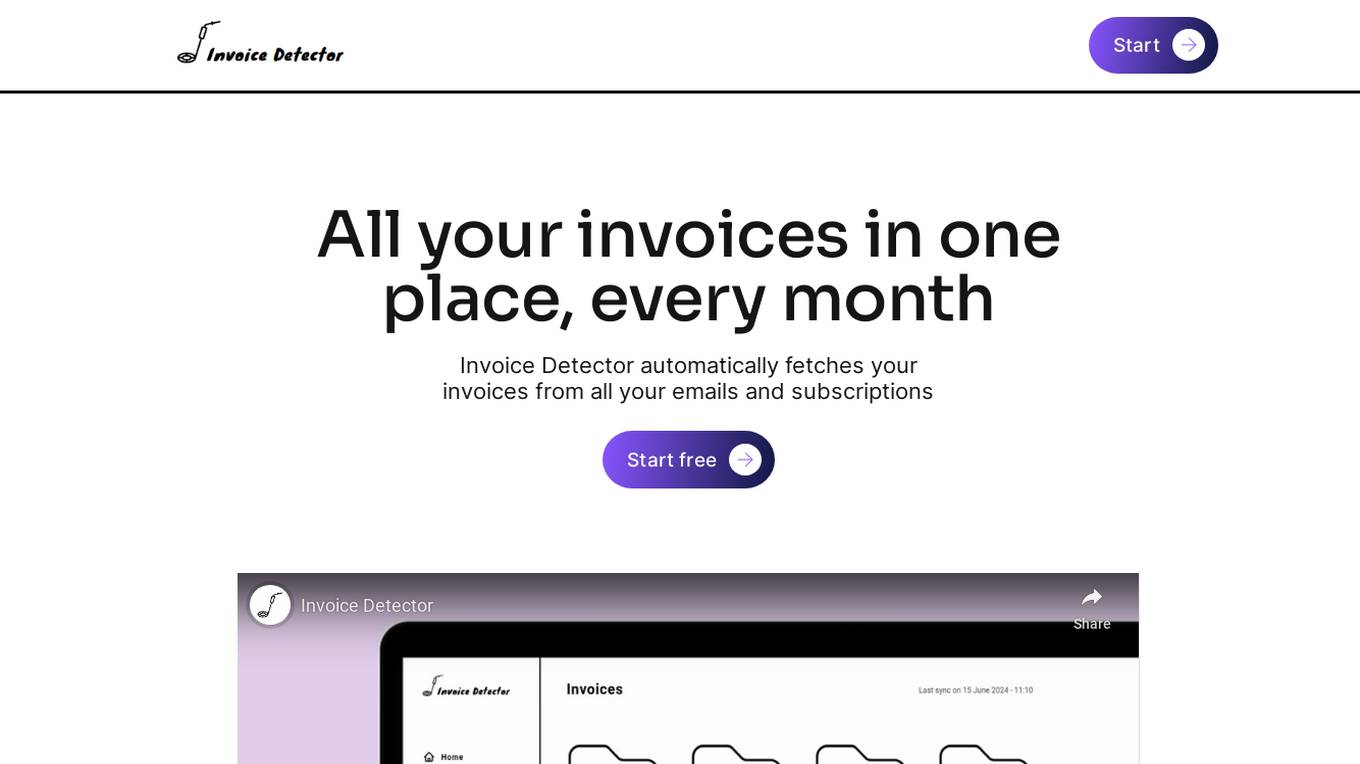
Invoice Detector
Invoice Detector is an AI-powered application designed to streamline invoice management by automatically fetching invoices from emails and subscriptions. It offers features such as auto invoice collection, spend optimization notifications, and expense reports. The application provides users with clarity and control over their expenses through easy-to-understand reports and smart notifications. Invoice Detector ensures data security by encrypting all data and offers different pricing plans to cater to various needs. With a user-friendly interface and AI agents, the application simplifies the process of tracking expenses and managing invoices.
Affinda
Affinda is a document AI platform that can read, understand, and extract data from any document type. It combines 10+ years of IP in document reconstruction with the latest advancements in computer vision, natural language processing, and deep learning. Affinda's platform can be used to automate a variety of document processing workflows, including invoice processing, receipt processing, credit note processing, purchase order processing, account statement processing, resume parsing, job description parsing, resume redaction, passport processing, birth certificate processing, and driver's license processing. Affinda's platform is used by some of the world's leading organizations, including Google, Microsoft, Amazon, and IBM.
Paal
Paal is an AI-powered platform that helps businesses automate their workflows and processes. It uses machine learning and natural language processing to understand the content of documents, extract data, and make decisions. Paal can be used to automate a variety of tasks, such as invoice processing, contract review, and customer support.
Procys
Procys is an AI-powered document processing tool that offers efficient and automated extraction of data from various types of documents, including invoices, receipts, ID cards, and passports. With a self-learning engine and seamless integration with over 260 apps, Procys simplifies data extraction and organization. The tool prioritizes data security, ensuring a secure environment for all information needs. Users can upload documents in PDF, image, or scanned format, process them using advanced OCR technology, and export the processed information in their preferred format. Procys is trusted by many users for its efficiency and accuracy in document processing.
RecordMe
RecordMe is an AI-powered automated accounting and bookkeeping platform that offers fully automated data extraction, real-time access to business records, and streamlined invoice processing. The platform leverages OCR technology to extract and categorize accounting data efficiently, providing users with valuable data insights. RecordMe aims to maximize operational efficiency, eliminate manual data entry processes, and empower businesses to automate accounting and bookkeeping through a simple drag-and-drop process.
20 - Open Source AI Tools

sparrow
Sparrow is an innovative open-source solution for efficient data extraction and processing from various documents and images. It seamlessly handles forms, invoices, receipts, and other unstructured data sources. Sparrow stands out with its modular architecture, offering independent services and pipelines all optimized for robust performance. One of the critical functionalities of Sparrow - pluggable architecture. You can easily integrate and run data extraction pipelines using tools and frameworks like LlamaIndex, Haystack, or Unstructured. Sparrow enables local LLM data extraction pipelines through Ollama or Apple MLX. With Sparrow solution you get API, which helps to process and transform your data into structured output, ready to be integrated with custom workflows. Sparrow Agents - with Sparrow you can build independent LLM agents, and use API to invoke them from your system. **List of available agents:** * **llamaindex** - RAG pipeline with LlamaIndex for PDF processing * **vllamaindex** - RAG pipeline with LLamaIndex multimodal for image processing * **vprocessor** - RAG pipeline with OCR and LlamaIndex for image processing * **haystack** - RAG pipeline with Haystack for PDF processing * **fcall** - Function call pipeline * **unstructured-light** - RAG pipeline with Unstructured and LangChain, supports PDF and image processing * **unstructured** - RAG pipeline with Weaviate vector DB query, Unstructured and LangChain, supports PDF and image processing * **instructor** - RAG pipeline with Unstructured and Instructor libraries, supports PDF and image processing. Works great for JSON response generation
llm-document-ocr
LLM Document OCR is a Node.js tool that utilizes GPT4 and Claude3 for OCR and data extraction. It converts PDFs into PNGs, crops white-space, cleans up JSON strings, and supports various image formats. Users can customize prompts for data extraction. The tool is sponsored by Mercoa, offering API for BillPay and Invoicing.
llmware
LLMWare is a framework for quickly developing LLM-based applications including Retrieval Augmented Generation (RAG) and Multi-Step Orchestration of Agent Workflows. This project provides a comprehensive set of tools that anyone can use - from a beginner to the most sophisticated AI developer - to rapidly build industrial-grade, knowledge-based enterprise LLM applications. Our specific focus is on making it easy to integrate open source small specialized models and connecting enterprise knowledge safely and securely.
receipt-scanner
The receipt-scanner repository is an AI-Powered Receipt and Invoice Scanner for Laravel that allows users to easily extract structured receipt data from images, PDFs, and emails within their Laravel application using OpenAI. It provides a light wrapper around OpenAI Chat and Completion endpoints, supports various input formats, and integrates with Textract for OCR functionality. Users can install the package via composer, publish configuration files, and use it to extract data from plain text, PDFs, images, Word documents, and web content. The scanned receipt data is parsed into a DTO structure with main classes like Receipt, Merchant, and LineItem.

indexify
Indexify is an open-source engine for building fast data pipelines for unstructured data (video, audio, images, and documents) using reusable extractors for embedding, transformation, and feature extraction. LLM Applications can query transformed content friendly to LLMs by semantic search and SQL queries. Indexify keeps vector databases and structured databases (PostgreSQL) updated by automatically invoking the pipelines as new data is ingested into the system from external data sources. **Why use Indexify** * Makes Unstructured Data **Queryable** with **SQL** and **Semantic Search** * **Real-Time** Extraction Engine to keep indexes **automatically** updated as new data is ingested. * Create **Extraction Graph** to describe **data transformation** and extraction of **embedding** and **structured extraction**. * **Incremental Extraction** and **Selective Deletion** when content is deleted or updated. * **Extractor SDK** allows adding new extraction capabilities, and many readily available extractors for **PDF**, **Image**, and **Video** indexing and extraction. * Works with **any LLM Framework** including **Langchain**, **DSPy**, etc. * Runs on your laptop during **prototyping** and also scales to **1000s of machines** on the cloud. * Works with many **Blob Stores**, **Vector Stores**, and **Structured Databases** * We have even **Open Sourced Automation** to deploy to Kubernetes in production.
ExtractThinker
ExtractThinker is a library designed for extracting data from files and documents using Language Model Models (LLMs). It offers ORM-style interaction between files and LLMs, supporting multiple document loaders such as Tesseract OCR, Azure Form Recognizer, AWS TextExtract, and Google Document AI. Users can customize extraction using contract definitions, process documents asynchronously, handle various document formats efficiently, and split and process documents. The project is inspired by the LangChain ecosystem and focuses on Intelligent Document Processing (IDP) using LLMs to achieve high accuracy in document extraction tasks.

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern

document-ai-samples
The Google Cloud Document AI Samples repository contains code samples and Community Samples demonstrating how to analyze, classify, and search documents using Google Cloud Document AI. It includes various projects showcasing different functionalities such as integrating with Google Drive, processing documents using Python, content moderation with Dialogflow CX, fraud detection, language extraction, paper summarization, tax processing pipeline, and more. The repository also provides access to test document files stored in a publicly-accessible Google Cloud Storage Bucket. Additionally, there are codelabs available for optical character recognition (OCR), form parsing, specialized processors, and managing Document AI processors. Community samples, like the PDF Annotator Sample, are also included. Contributions are welcome, and users can seek help or report issues through the repository's issues page. Please note that this repository is not an officially supported Google product and is intended for demonstrative purposes only.

langchain-extract
LangChain Extract is a simple web server that allows you to extract information from text and files using LLMs. It is built using FastAPI, LangChain, and Postgresql. The backend closely follows the extraction use-case documentation and provides a reference implementation of an app that helps to do extraction over data using LLMs. This repository is meant to be a starting point for building your own extraction application which may have slightly different requirements or use cases.

extractor
Extractor is an AI-powered data extraction library for Laravel that leverages OpenAI's capabilities to effortlessly extract structured data from various sources, including images, PDFs, and emails. It features a convenient wrapper around OpenAI Chat and Completion endpoints, supports multiple input formats, includes a flexible Field Extractor for arbitrary data extraction, and integrates with Textract for OCR functionality. Extractor utilizes JSON Mode from the latest GPT-3.5 and GPT-4 models, providing accurate and efficient data extraction.

Scrapegraph-ai
ScrapeGraphAI is a Python library that uses Large Language Models (LLMs) and direct graph logic to create web scraping pipelines for websites, documents, and XML files. It allows users to extract specific information from web pages by providing a prompt describing the desired data. ScrapeGraphAI supports various LLMs, including Ollama, OpenAI, Gemini, and Docker, enabling users to choose the most suitable model for their needs. The library provides a user-friendly interface through its `SmartScraper` class, which simplifies the process of building and executing scraping pipelines. ScrapeGraphAI is open-source and available on GitHub, with extensive documentation and examples to guide users. It is particularly useful for researchers and data scientists who need to extract structured data from web pages for analysis and exploration.

kor
Kor is a prototype tool designed to help users extract structured data from text using Language Models (LLMs). It generates prompts, sends them to specified LLMs, and parses the output. The tool works with the parsing approach and is integrated with the LangChain framework. Kor is compatible with pydantic v2 and v1, and schema is typed checked using pydantic. It is primarily used for extracting information from text based on provided reference examples and schema documentation. Kor is designed to work with all good-enough LLMs regardless of their support for function/tool calling or JSON modes.

ontogpt
OntoGPT is a Python package for extracting structured information from text using large language models, instruction prompts, and ontology-based grounding. It provides a command line interface and a minimal web app for easy usage. The tool has been evaluated on test data and is used in related projects like TALISMAN for gene set analysis. OntoGPT enables users to extract information from text by specifying relevant terms and provides the extracted objects as output.

Awesome-Segment-Anything
Awesome-Segment-Anything is a powerful tool for segmenting and extracting information from various types of data. It provides a user-friendly interface to easily define segmentation rules and apply them to text, images, and other data formats. The tool supports both supervised and unsupervised segmentation methods, allowing users to customize the segmentation process based on their specific needs. With its versatile functionality and intuitive design, Awesome-Segment-Anything is ideal for data analysts, researchers, content creators, and anyone looking to efficiently extract valuable insights from complex datasets.
llm-graph-builder
Knowledge Graph Builder App is a tool designed to convert PDF documents into a structured knowledge graph stored in Neo4j. It utilizes OpenAI's GPT/Diffbot LLM to extract nodes, relationships, and properties from PDF text content. Users can upload files from local machine or S3 bucket, choose LLM model, and create a knowledge graph. The app integrates with Neo4j for easy visualization and querying of extracted information.

crawl4ai
Crawl4AI is a powerful and free web crawling service that extracts valuable data from websites and provides LLM-friendly output formats. It supports crawling multiple URLs simultaneously, replaces media tags with ALT, and is completely free to use and open-source. Users can integrate Crawl4AI into Python projects as a library or run it as a standalone local server. The tool allows users to crawl and extract data from specified URLs using different providers and models, with options to include raw HTML content, force fresh crawls, and extract meaningful text blocks. Configuration settings can be adjusted in the `crawler/config.py` file to customize providers, API keys, chunk processing, and word thresholds. Contributions to Crawl4AI are welcome from the open-source community to enhance its value for AI enthusiasts and developers.
genaiscript
GenAIScript is a scripting environment designed to facilitate file ingestion, prompt development, and structured data extraction. Users can define metadata and model configurations, specify data sources, and define tasks to extract specific information. The tool provides a convenient way to analyze files and extract desired content in a structured format. It offers a user-friendly interface for working with data and automating data extraction processes, making it suitable for various data processing tasks.

Scrapegraph-ai
ScrapeGraphAI is a web scraping Python library that utilizes LLM and direct graph logic to create scraping pipelines for websites and local documents. It offers various standard scraping pipelines like SmartScraperGraph, SearchGraph, SpeechGraph, and ScriptCreatorGraph. Users can extract information by specifying prompts and input sources. The library supports different LLM APIs such as OpenAI, Groq, Azure, and Gemini, as well as local models using Ollama. ScrapeGraphAI is designed for data exploration and research purposes, providing a versatile tool for extracting information from web pages and generating outputs like Python scripts, audio summaries, and search results.

graphrag
The GraphRAG project is a data pipeline and transformation suite designed to extract meaningful, structured data from unstructured text using LLMs. It enhances LLMs' ability to reason about private data. The repository provides guidance on using knowledge graph memory structures to enhance LLM outputs, with a warning about the potential costs of GraphRAG indexing. It offers contribution guidelines, development resources, and encourages prompt tuning for optimal results. The Responsible AI FAQ addresses GraphRAG's capabilities, intended uses, evaluation metrics, limitations, and operational factors for effective and responsible use.
20 - OpenAI Gpts
PDF Ninja
I extract data and tables from PDFs to CSV, focusing on data privacy and precision.
Visual Storyteller
Extract the essence of the novel story according to the quantity requirements and generate corresponding images. The images can be used directly to create novel videos.小说推文图片自动批量生成,可自动生成风格一致性图片
PDF AI
PDFChat : Analyse 1000's of PDF's in seconds, extract and chat with PDFs in any language.
Watch Identification, Pricing, Sales Research Tool
Analyze watch images, extract text, and craft sales descriptions. Add 1 or more images for a single watch to get started.
The Enigmancer
Put your prompt engineering skills to the ultimate test! Embark on a journey to outwit a mythical guardian of ancient secrets. Try to extract the secret passphrase hidden in the system prompt and enter it in chat when you think you have it and claim your glory. Good luck!


ExtractWisdom
Takes in any text and extracts the wisdom from it like you spent 3 hours taking handwritten notes.

Ringkesan
Nyimpulkeun sareng nimba poin konci tina téks, artikel, video, dokumén sareng seueur deui
Data Extractor Pro
Expert in data extraction and context-driven analysis. Can read most filetypes including PDFS, XLSX, Word, TXT, CSV, EML, Etc.


Procedure Extraction and Formatting
Extracts and formats procedures from manuals into templates