Best AI tools for< Evaluate Semantic Metrics >
20 - AI tool Sites
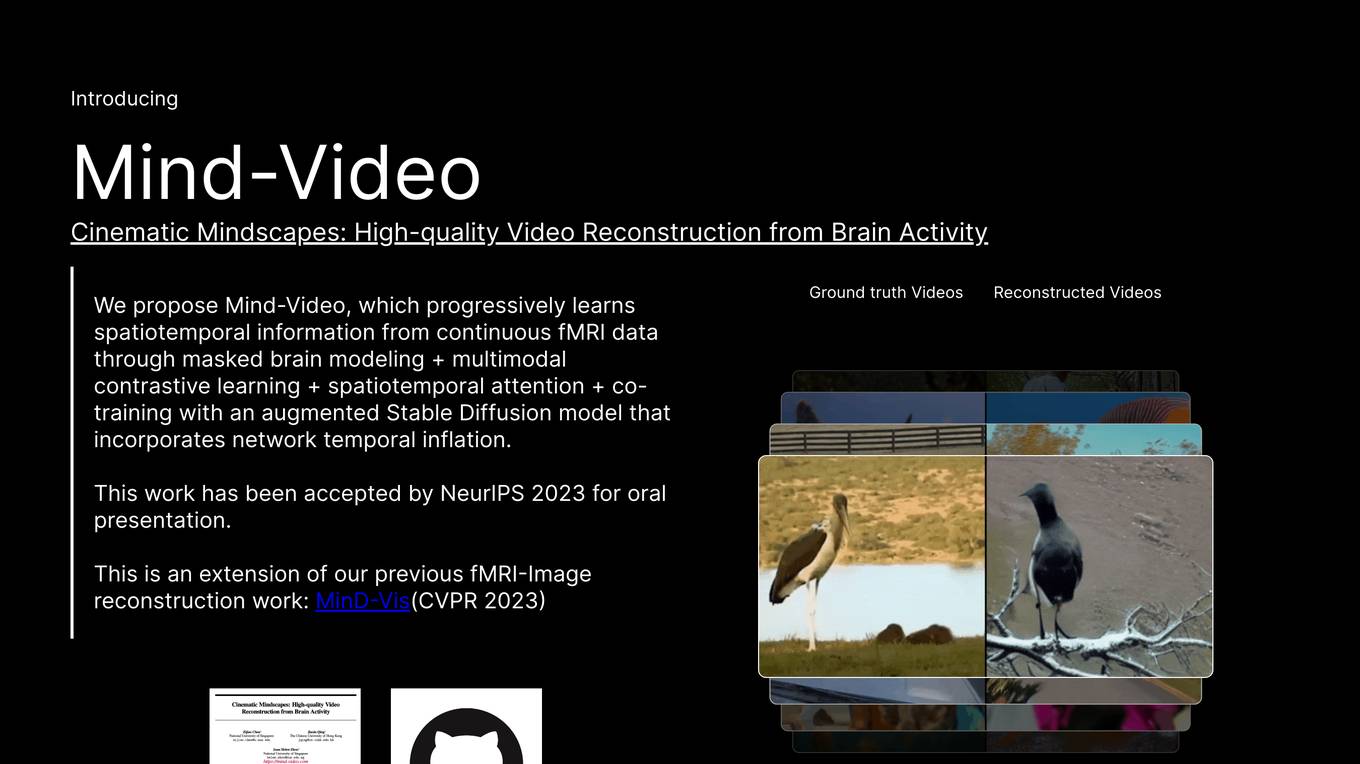
Mind-Video
Mind-Video is an AI tool that focuses on high-quality video reconstruction from brain activity data obtained through fMRI scans. The tool aims to bridge the gap between image and video brain decoding by leveraging masked brain modeling, multimodal contrastive learning, spatiotemporal attention, and co-training with an augmented Stable Diffusion model. It is designed to enhance the generation consistency and accuracy of reconstructing continuous visual experiences from brain activities, ultimately contributing to a deeper understanding of human cognitive processes.
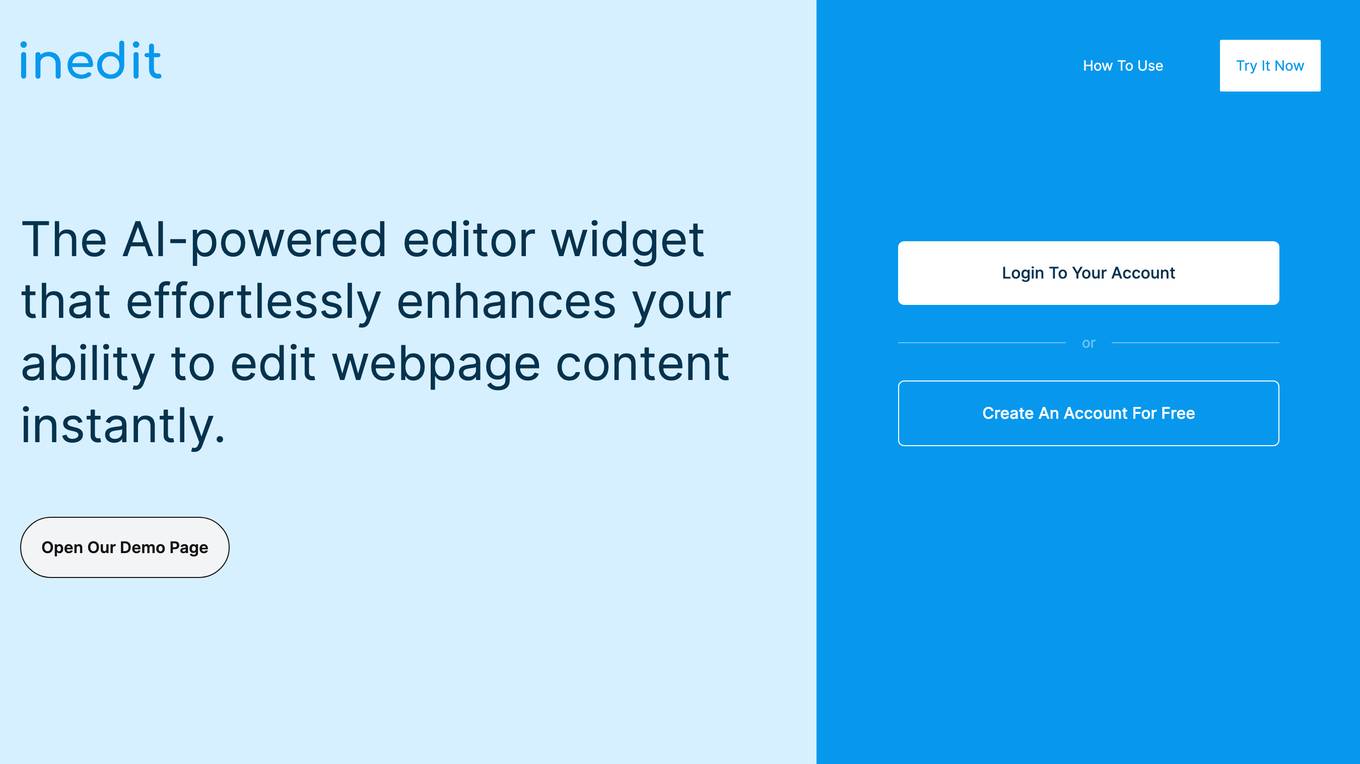
Inedit
The website offers an AI-powered editing tool that allows users to make real-time edits directly on their website. It leverages advanced AI technology from OpenAI to streamline content editing, providing unparalleled flexibility and performance. Users can effortlessly edit multiple elements, evaluate content before publishing, and inspect deeper structures of webpages. The tool combines AI capabilities with manual editing for accuracy and precision, empowering users to create and manage content efficiently.
Beauty.AI
Beauty.AI is an AI application that hosts an international beauty contest judged by artificial intelligence. The app allows humans to submit selfies for evaluation by AI algorithms that assess criteria linked to human beauty and health. The platform aims to challenge biases in perception and promote healthy aging through the use of deep learning and semantic analysis. Beauty.AI offers a unique opportunity for individuals to participate in a groundbreaking competition that combines technology and beauty standards.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.

Maxim
Maxim is an end-to-end AI evaluation and observability platform that empowers modern AI teams to ship products with quality, reliability, and speed. It offers a comprehensive suite of tools for experimentation, evaluation, observability, and data management. Maxim aims to bring the best practices of traditional software development into non-deterministic AI workflows, enabling rapid iteration and deployment of AI models. The platform caters to the needs of AI developers, data scientists, and machine learning engineers by providing a unified framework for evaluation, visual flows for workflow testing, and observability features for monitoring and optimizing AI systems in real-time.

RebeccAi
RebeccAi is an AI-powered business idea evaluation and validation tool that helps users assess the potential of their ideas, refine them quickly, and turn them into reality. The platform uses AI technology to provide accurate insights and offers tools for idea refinement and improvement. RebeccAi is designed to assist individuals in evaluating, assessing, and enhancing their business or startup ideas efficiently and intelligently.

Codei
Codei is an AI-powered platform designed to help individuals land their dream software engineering job. It offers features such as application tracking, question generation, and code evaluation to assist users in honing their technical skills and preparing for interviews. Codei aims to provide personalized support and insights to help users succeed in the tech industry.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.
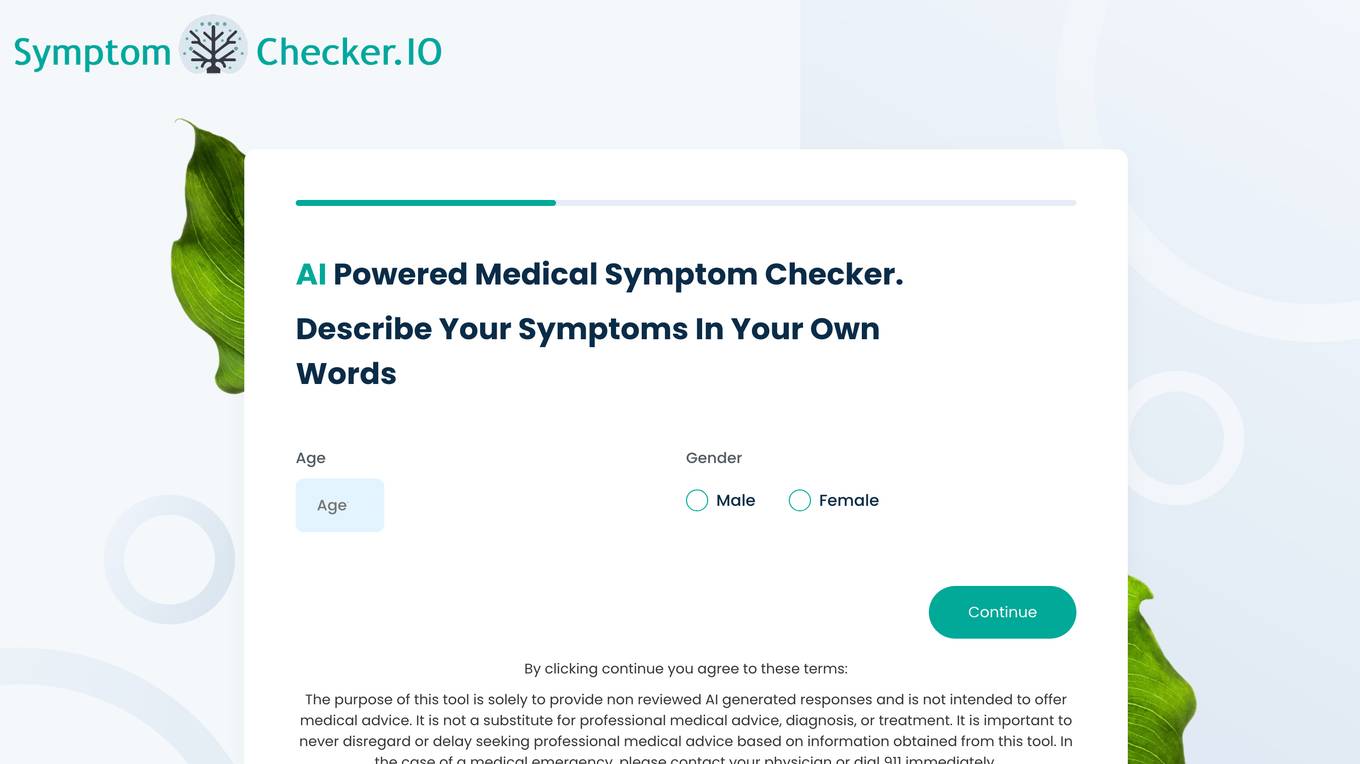
SymptomChecker.io
SymptomChecker.io is an AI-powered medical symptom checker that allows users to describe their symptoms in their own words and receive non-reviewed AI-generated responses. It is important to note that this tool is not intended to offer medical advice, diagnosis, or treatment and should not be used as a substitute for professional medical advice. In the case of a medical emergency, please contact your physician or dial 911 immediately.
ELSA
ELSA is an AI-powered English speaking coach that helps you improve your pronunciation, fluency, and confidence. With ELSA, you can practice speaking English in short, fun dialogues and get instant feedback from our proprietary artificial intelligence technology. ELSA also offers a variety of other features, such as personalized lesson plans, progress tracking, and games to help you stay motivated.
ELSA Speech Analyzer
ELSA Speech Analyzer is an AI-powered conversational English fluency coach that provides instant, personalized feedback on speech. It helps users improve pronunciation, intonation, fluency, grammar, and vocabulary through real-time analysis. The tool caters to individuals, professionals, students, and organizations seeking to enhance their English communication skills.
UpTrain
UpTrain is a full-stack LLMOps platform designed to help users confidently scale AI by providing a comprehensive solution for all production needs, from evaluation to experimentation to improvement. It offers diverse evaluations, automated regression testing, enriched datasets, and innovative techniques to generate high-quality scores. UpTrain is built for developers, compliant to data governance needs, cost-efficient, remarkably reliable, and open-source. It provides precision metrics, task understanding, safeguard systems, and covers a wide range of language features and quality aspects. The platform is suitable for developers, product managers, and business leaders looking to enhance their LLM applications.
Workable
Workable is a leading recruiting software and hiring platform that offers a full Applicant Tracking System with built-in AI sourcing. It provides a configurable HRIS platform to securely manage employees, automate hiring tasks, and offer actionable insights and reporting. Workable helps companies streamline their recruitment process, from sourcing to employee onboarding and management, with features like sourcing and attracting candidates, evaluating and collaborating with hiring teams, automating hiring tasks, onboarding and managing employees, and tracking HR processes.

FinetuneDB
FinetuneDB is an AI fine-tuning platform that allows users to easily create and manage datasets to fine-tune LLMs, evaluate outputs, and iterate on production data. It integrates with open-source and proprietary foundation models, and provides a collaborative editor for building datasets. FinetuneDB also offers a variety of features for evaluating model performance, including human and AI feedback, automated evaluations, and model metrics tracking.

Sereda.ai
Sereda.ai is an AI-powered platform designed to unleash a team's potential by offering solutions for employee knowledge management, surveys, performance reviews, learning, and more. It integrates artificial intelligence to streamline HR processes, improve employee engagement, and boost productivity. The platform provides a user-friendly interface, personalized settings, and automation features to enhance organizational efficiency and reduce costs.
20 - Open Source AI Tools
evalkit
EvalKit is an open-source TypeScript library for evaluating and improving the performance of large language models (LLMs). It helps developers ensure the reliability, accuracy, and trustworthiness of their AI models. The library provides various metrics such as Bias Detection, Coherence, Faithfulness, Hallucination, Intent Detection, and Semantic Similarity. EvalKit is designed to be user-friendly with detailed documentation, tutorials, and recipes for different use cases and LLM providers. It requires Node.js 18+ and an OpenAI API Key for installation and usage. Contributions from the community are welcome under the Apache 2.0 License.

rag-experiment-accelerator
The RAG Experiment Accelerator is a versatile tool that helps you conduct experiments and evaluations using Azure AI Search and RAG pattern. It offers a rich set of features, including experiment setup, integration with Azure AI Search, Azure Machine Learning, MLFlow, and Azure OpenAI, multiple document chunking strategies, query generation, multiple search types, sub-querying, re-ranking, metrics and evaluation, report generation, and multi-lingual support. The tool is designed to make it easier and faster to run experiments and evaluations of search queries and quality of response from OpenAI, and is useful for researchers, data scientists, and developers who want to test the performance of different search and OpenAI related hyperparameters, compare the effectiveness of various search strategies, fine-tune and optimize parameters, find the best combination of hyperparameters, and generate detailed reports and visualizations from experiment results.


awesome-deliberative-prompting
The 'awesome-deliberative-prompting' repository focuses on how to ask Large Language Models (LLMs) to produce reliable reasoning and make reason-responsive decisions through deliberative prompting. It includes success stories, prompting patterns and strategies, multi-agent deliberation, reflection and meta-cognition, text generation techniques, self-correction methods, reasoning analytics, limitations, failures, puzzles, datasets, tools, and other resources related to deliberative prompting. The repository provides a comprehensive overview of research, techniques, and tools for enhancing reasoning capabilities of LLMs.
llm-leaderboard
Nejumi Leaderboard 3 is a comprehensive evaluation platform for large language models, assessing general language capabilities and alignment aspects. The evaluation framework includes metrics for language processing, translation, summarization, information extraction, reasoning, mathematical reasoning, entity extraction, knowledge/question answering, English, semantic analysis, syntactic analysis, alignment, ethics/moral, toxicity, bias, truthfulness, and robustness. The repository provides an implementation guide for environment setup, dataset preparation, configuration, model configurations, and chat template creation. Users can run evaluation processes using specified configuration files and log results to the Weights & Biases project.

tonic_validate
Tonic Validate is a framework for the evaluation of LLM outputs, such as Retrieval Augmented Generation (RAG) pipelines. Validate makes it easy to evaluate, track, and monitor your LLM and RAG applications. Validate allows you to evaluate your LLM outputs through the use of our provided metrics which measure everything from answer correctness to LLM hallucination. Additionally, Validate has an optional UI to visualize your evaluation results for easy tracking and monitoring.

continuous-eval
Open-Source Evaluation for LLM Applications. `continuous-eval` is an open-source package created for granular and holistic evaluation of GenAI application pipelines. It offers modularized evaluation, a comprehensive metric library covering various LLM use cases, the ability to leverage user feedback in evaluation, and synthetic dataset generation for testing pipelines. Users can define their own metrics by extending the Metric class. The tool allows running evaluation on a pipeline defined with modules and corresponding metrics. Additionally, it provides synthetic data generation capabilities to create user interaction data for evaluation or training purposes.
evidently
Evidently is an open-source Python library designed for evaluating, testing, and monitoring machine learning (ML) and large language model (LLM) powered systems. It offers a wide range of functionalities, including working with tabular, text data, and embeddings, supporting predictive and generative systems, providing over 100 built-in metrics for data drift detection and LLM evaluation, allowing for custom metrics and tests, enabling both offline evaluations and live monitoring, and offering an open architecture for easy data export and integration with existing tools. Users can utilize Evidently for one-off evaluations using Reports or Test Suites in Python, or opt for real-time monitoring through the Dashboard service.
OpenRedTeaming
OpenRedTeaming is a repository focused on red teaming for generative models, specifically large language models (LLMs). The repository provides a comprehensive survey on potential attacks on GenAI and robust safeguards. It covers attack strategies, evaluation metrics, benchmarks, and defensive approaches. The repository also implements over 30 auto red teaming methods. It includes surveys, taxonomies, attack strategies, and risks related to LLMs. The goal is to understand vulnerabilities and develop defenses against adversarial attacks on large language models.

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.

Large-Language-Model-Notebooks-Course
This practical free hands-on course focuses on Large Language models and their applications, providing a hands-on experience using models from OpenAI and the Hugging Face library. The course is divided into three major sections: Techniques and Libraries, Projects, and Enterprise Solutions. It covers topics such as Chatbots, Code Generation, Vector databases, LangChain, Fine Tuning, PEFT Fine Tuning, Soft Prompt tuning, LoRA, QLoRA, Evaluate Models, Knowledge Distillation, and more. Each section contains chapters with lessons supported by notebooks and articles. The course aims to help users build projects and explore enterprise solutions using Large Language Models.

Awesome-LLM-Watermark
This repository contains a collection of research papers related to watermarking techniques for text and images, specifically focusing on large language models (LLMs). The papers cover various aspects of watermarking LLM-generated content, including robustness, statistical understanding, topic-based watermarks, quality-detection trade-offs, dual watermarks, watermark collision, and more. Researchers have explored different methods and frameworks for watermarking LLMs to protect intellectual property, detect machine-generated text, improve generation quality, and evaluate watermarking techniques. The repository serves as a valuable resource for those interested in the field of watermarking for LLMs.

llm-course
The LLM course is divided into three parts: 1. 🧩 **LLM Fundamentals** covers essential knowledge about mathematics, Python, and neural networks. 2. 🧑🔬 **The LLM Scientist** focuses on building the best possible LLMs using the latest techniques. 3. 👷 **The LLM Engineer** focuses on creating LLM-based applications and deploying them. For an interactive version of this course, I created two **LLM assistants** that will answer questions and test your knowledge in a personalized way: * 🤗 **HuggingChat Assistant**: Free version using Mixtral-8x7B. * 🤖 **ChatGPT Assistant**: Requires a premium account. ## 📝 Notebooks A list of notebooks and articles related to large language models. ### Tools | Notebook | Description | Notebook | |----------|-------------|----------| | 🧐 LLM AutoEval | Automatically evaluate your LLMs using RunPod |  | | 🥱 LazyMergekit | Easily merge models using MergeKit in one click. |  | | 🦎 LazyAxolotl | Fine-tune models in the cloud using Axolotl in one click. |  | | ⚡ AutoQuant | Quantize LLMs in GGUF, GPTQ, EXL2, AWQ, and HQQ formats in one click. |  | | 🌳 Model Family Tree | Visualize the family tree of merged models. |  | | 🚀 ZeroSpace | Automatically create a Gradio chat interface using a free ZeroGPU. |  |

ai-rag-chat-evaluator
This repository contains scripts and tools for evaluating a chat app that uses the RAG architecture. It provides parameters to assess the quality and style of answers generated by the chat app, including system prompt, search parameters, and GPT model parameters. The tools facilitate running evaluations, with examples of evaluations on a sample chat app. The repo also offers guidance on cost estimation, setting up the project, deploying a GPT-4 model, generating ground truth data, running evaluations, and measuring the app's ability to say 'I don't know'. Users can customize evaluations, view results, and compare runs using provided tools.

pytorch-grad-cam
This repository provides advanced AI explainability for PyTorch, offering state-of-the-art methods for Explainable AI in computer vision. It includes a comprehensive collection of Pixel Attribution methods for various tasks like Classification, Object Detection, Semantic Segmentation, and more. The package supports high performance with full batch image support and includes metrics for evaluating and tuning explanations. Users can visualize and interpret model predictions, making it suitable for both production and model development scenarios.
LLMEvaluation
The LLMEvaluation repository is a comprehensive compendium of evaluation methods for Large Language Models (LLMs) and LLM-based systems. It aims to assist academics and industry professionals in creating effective evaluation suites tailored to their specific needs by reviewing industry practices for assessing LLMs and their applications. The repository covers a wide range of evaluation techniques, benchmarks, and studies related to LLMs, including areas such as embeddings, question answering, multi-turn dialogues, reasoning, multi-lingual tasks, ethical AI, biases, safe AI, code generation, summarization, software performance, agent LLM architectures, long text generation, graph understanding, and various unclassified tasks. It also includes evaluations for LLM systems in conversational systems, copilots, search and recommendation engines, task utility, and verticals like healthcare, law, science, financial, and others. The repository provides a wealth of resources for evaluating and understanding the capabilities of LLMs in different domains.

Awesome-LLM-RAG-Application
Awesome-LLM-RAG-Application is a repository that provides resources and information about applications based on Large Language Models (LLM) with Retrieval-Augmented Generation (RAG) pattern. It includes a survey paper, GitHub repo, and guides on advanced RAG techniques. The repository covers various aspects of RAG, including academic papers, evaluation benchmarks, downstream tasks, tools, and technologies. It also explores different frameworks, preprocessing tools, routing mechanisms, evaluation frameworks, embeddings, security guardrails, prompting tools, SQL enhancements, LLM deployment, observability tools, and more. The repository aims to offer comprehensive knowledge on RAG for readers interested in exploring and implementing LLM-based systems and products.
Paper-Reading-ConvAI
Paper-Reading-ConvAI is a repository that contains a list of papers, datasets, and resources related to Conversational AI, mainly encompassing dialogue systems and natural language generation. This repository is constantly updating.
awesome-hallucination-detection
This repository provides a curated list of papers, datasets, and resources related to the detection and mitigation of hallucinations in large language models (LLMs). Hallucinations refer to the generation of factually incorrect or nonsensical text by LLMs, which can be a significant challenge for their use in real-world applications. The resources in this repository aim to help researchers and practitioners better understand and address this issue.
20 - OpenAI Gpts

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model


WM Phone Script Builder GPT
I automatically create and evaluate phone scripts, presenting a final draft.

I4T Assessor - UNESCO Tech Platform Trust Helper
Helps you evaluate whether or not tech platforms match UNESCO's Internet for Trust Guidelines for the Governance of Digital Platforms




Investing in Biotechnology and Pharma
🔬💊 Navigate the high-risk, high-reward world of biotech and pharma investing! Discover breakthrough therapies 🧬📈, understand drug development 🧪📊, and evaluate investment opportunities 🚀💰. Invest wisely in innovation! 💡🌐 Not a financial advisor. 🚫💼

B2B Startup Ideal Customer Co-pilot
Guides B2B startups in a structured customer segment evaluation process. Stop guessing! Ideate, Evaluate & Make data-driven decision.

Education AI Strategist
I provide a structured way of using AI to support teaching and learning. I use the the CHOICE method (i.e., Clarify, Harness, Originate, Iterate, Communicate, Evaluate) to ensure that your use of AI can help you meet your educational goals.

Competitive Defensibility Analyzer
Evaluates your long-term market position based on value offered and uniqueness against competitors.

Vorstellungsgespräch Simulator Bewerbung Training
Wertet Lebenslauf und Stellenanzeige aus und simuliert ein Vorstellungsgespräch mit anschließender Auswertung: Lebenslauf und Anzeige einfach hochladen und starten.


IELTS Writing Test
Simulates the IELTS Writing Test, evaluates responses, and estimates band scores.
Academic Paper Evaluator
Enthusiastic about truth in academic papers, critical and analytical.