Best AI tools for< evaluate language >
20 - AI tool Sites
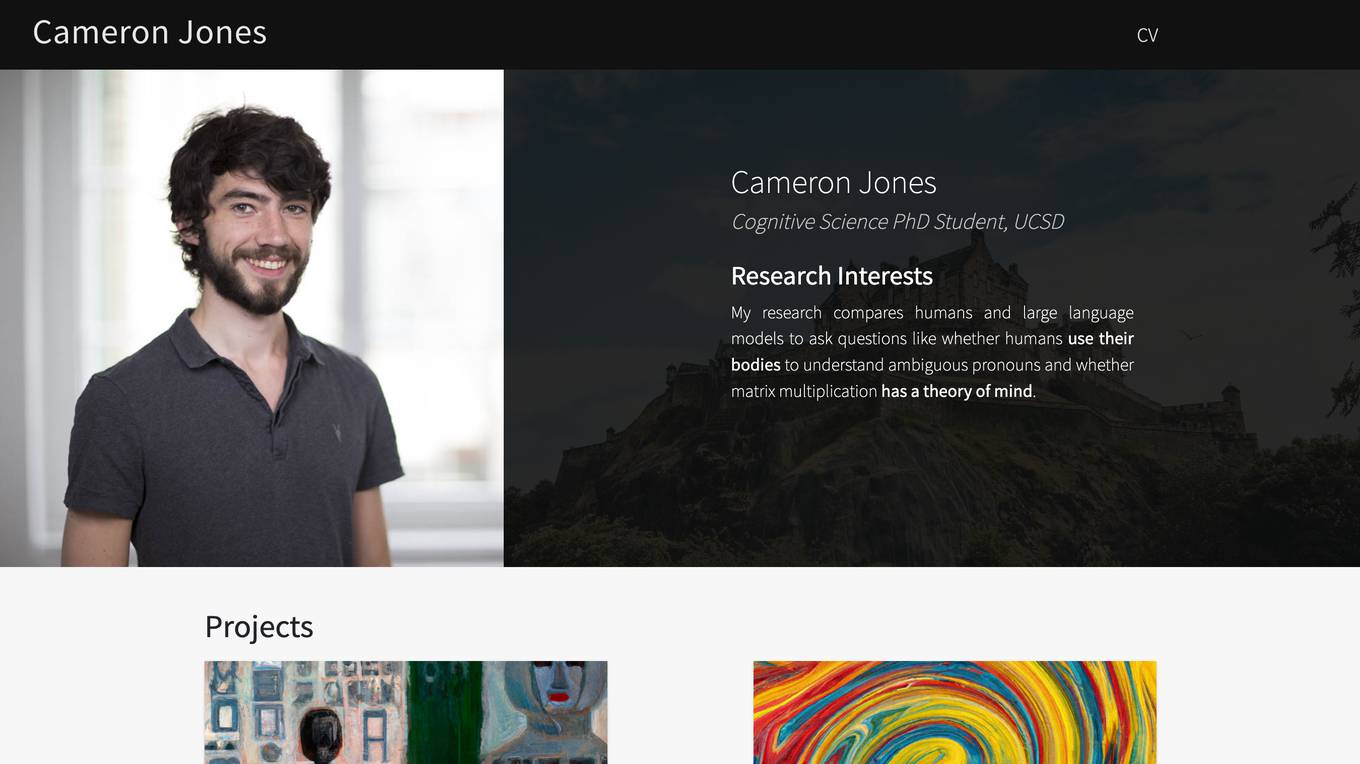
Cameron Jones
Cameron Jones is an AI tool developed by a Cognitive Science PhD student at UCSD. The tool focuses on social intelligence in humans and Large Language Models (LLMs). It analyzes LLM performance on tasks such as the False Belief task and the Turing test. The tool also compares humans and LLMs on theory of mind evaluation. Cameron Jones provides insights into understanding, grounding, and reference in LLMs through various projects and publications.
Entry Point AI
Entry Point AI is a modern AI optimization platform for fine-tuning proprietary and open-source language models. It provides a user-friendly interface to manage prompts, fine-tunes, and evaluations in one place. The platform enables users to optimize models from leading providers, train across providers, work collaboratively, write templates, import/export data, share models, and avoid common pitfalls associated with fine-tuning. Entry Point AI simplifies the fine-tuning process, making it accessible to users without the need for extensive data, infrastructure, or insider knowledge.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.
Datumbox
Datumbox is a machine learning platform that offers a powerful open-source Machine Learning Framework written in Java. It provides a large collection of algorithms, models, statistical tests, and tools to power up intelligent applications. The platform enables developers to build smart software and services quickly using its REST Machine Learning API. Datumbox API offers off-the-shelf Classifiers and Natural Language Processing services for applications like Sentiment Analysis, Topic Classification, Language Detection, and more. It simplifies the process of designing and training Machine Learning models, making it easy for developers to create innovative applications.
UpTrain
UpTrain is a full-stack LLMOps platform designed to help users with all their production needs, from Evaluation to Experimentation to Improvement. It offers diverse evaluations, automated regression testing, enriched datasets, and innovative techniques for generating high-quality scores. UpTrain is built for developers, by developers, and is compliant with data governance needs. It provides precision metrics, safeguard systems, and a wide range of features to enhance language model performance.
AI Tools Masters
AI Tools Masters is a comprehensive platform that empowers users to discover and evaluate the latest and most exceptional AI tools. Catering to diverse needs, from education to personal advancement, AI Tools Masters offers a curated collection of top-notch solutions tailored to specific requirements. With a user-friendly interface and extensive filtering options, users can effortlessly navigate through a wide range of AI tools, ensuring they find the perfect fit for their projects and goals.
Census GPT
Census GPT is an AI tool that provides data analysis services based on census data and crime statistics in the USA. Users can ask questions related to demographics, income levels, education, population, and crime rates in specific areas. The tool is designed to assist users in obtaining detailed insights and information about various regions in the United States.
LlamaIndex
LlamaIndex is a leading data framework designed for building LLM (Large Language Model) applications. It allows enterprises to turn their data into production-ready applications by providing functionalities such as loading data from various sources, indexing data, orchestrating workflows, and evaluating application performance. The platform offers extensive documentation, community-contributed resources, and integration options to support developers in creating innovative LLM applications.
Cakewalk AI
Cakewalk AI is an AI-powered platform designed to enhance team productivity by leveraging the power of ChatGPT and automation tools. It offers features such as team workspaces, prompt libraries, automation with prebuilt templates, and the ability to combine documents, images, and URLs. Users can automate tasks like updating product roadmaps, creating user personas, evaluating resumes, and more. Cakewalk AI aims to empower teams across various departments like Product, HR, Marketing, and Legal to streamline their workflows and improve efficiency.
PolygrAI
PolygrAI is a digital polygraph powered by AI technology that provides real-time risk assessment and sentiment analysis. The platform meticulously analyzes facial micro-expressions, body language, vocal attributes, and linguistic cues to detect behavioral fluctuations and signs of deception. By combining well-established psychology practices with advanced AI and computer vision detection, PolygrAI offers users actionable insights for decision-making processes across various applications.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.
Kerplunk
Kerplunk is an AI-powered video interviewing tool designed to streamline the recruitment process. It leverages artificial intelligence to analyze candidate responses, body language, and facial expressions, providing valuable insights to recruiters. With Kerplunk, organizations can conduct remote interviews efficiently and make data-driven hiring decisions. The platform offers a user-friendly interface and customizable features to meet the unique needs of each organization.
ELSA
ELSA is an AI-powered English speaking coach that helps you improve your pronunciation, fluency, and confidence. With ELSA, you can practice speaking English in short, fun dialogues and get instant feedback from our proprietary artificial intelligence technology. ELSA also offers a variety of other features, such as personalized lesson plans, progress tracking, and games to help you stay motivated.
ELSA Speech Analyzer
ELSA Speech Analyzer is an AI-powered conversational English fluency coach that provides instant, personalized feedback on speech. It helps users improve pronunciation, intonation, grammar, and vocabulary. The tool is designed for learners and professionals to enhance their English-speaking skills through real-time analysis and feedback. ELSA Speech Analyzer is suitable for individuals, executives, team leads, test takers, students, and opportunity seekers looking to excel in English communication.
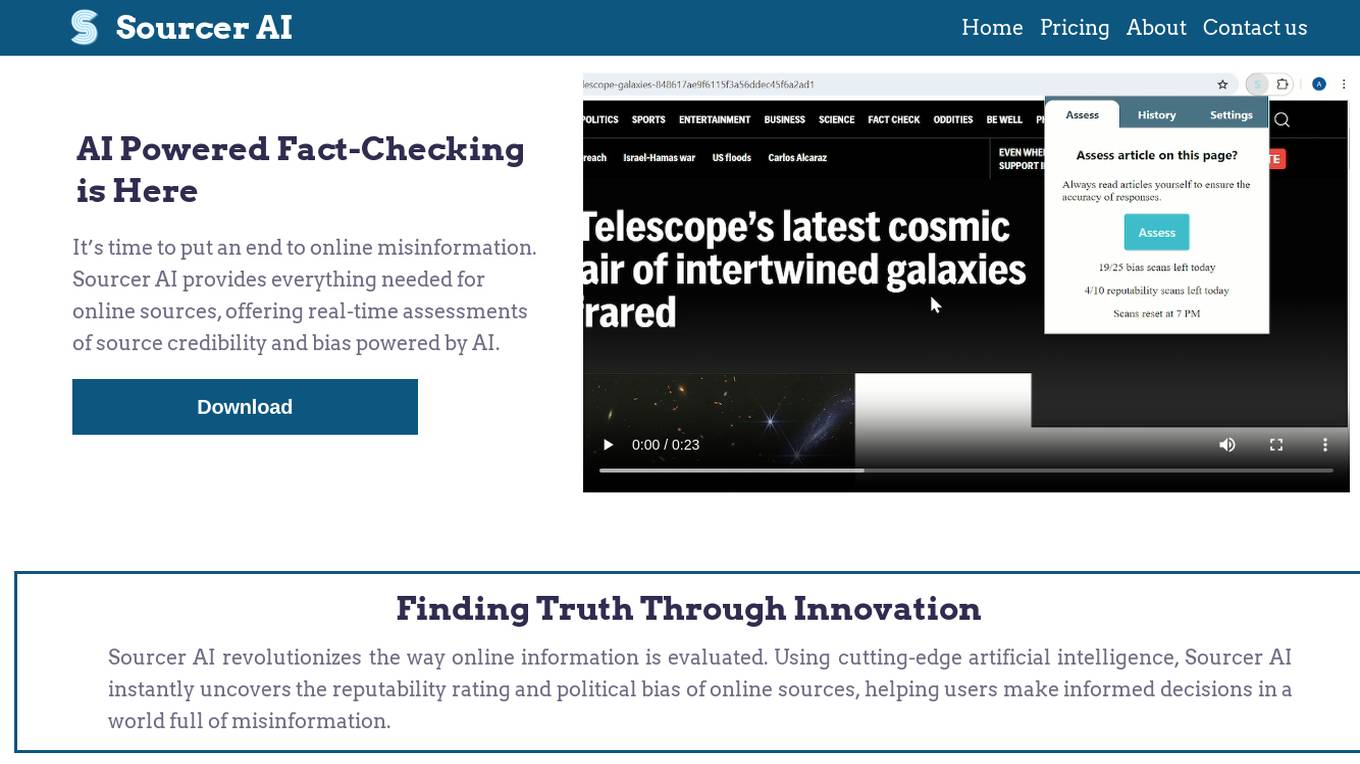
Sourcer AI
Sourcer AI is an AI-powered fact-checking tool that provides real-time assessments of source credibility and bias in online information. It revolutionizes the evaluation process by using cutting-edge artificial intelligence to uncover reputability ratings and political biases of online sources, helping users combat misinformation and make informed decisions.

FinetuneDB
FinetuneDB is an AI fine-tuning platform that allows users to easily create and manage datasets to fine-tune LLMs, evaluate outputs, and iterate on production data. It integrates with open-source and proprietary foundation models, and provides a collaborative editor for building datasets. FinetuneDB also offers a variety of features for evaluating model performance, including human and AI feedback, automated evaluations, and model metrics tracking.

PubCompare
PubCompare is a powerful AI-powered tool that helps scientists search, compare, and evaluate experimental protocols. With over 40 million protocols in its database, PubCompare is the largest repository of trusted experimental protocols. PubCompare's AI-powered search features allow users to find similar protocols, highlight critical steps, and evaluate the reproducibility of protocols based on in-protocol citations. PubCompare is available from any computer and requires no download.
ThinkTask
ThinkTask is a project and team management tool that utilizes ChatGPT's capabilities to enhance productivity and streamline task management. It offers AI-generated reports and insights, AI usage tracking, Team Pulse for visualizing task types and status, Project Progress Table for monitoring project timelines and budgets, Task Insights for illustrating task interdependencies, and a comprehensive Overview for visualizing progress and managing dependencies. Additionally, ThinkTask features one-click auto-task creation with notes from ChatGPT, auto-tagging for task organization, and AI-suggested task assignments based on past experience and skills. It provides a unified workspace for notes, tasks, databases, collaboration, and customization.

Confident AI
Confident AI is an open-source evaluation infrastructure for Large Language Models (LLMs). It provides a centralized platform to judge LLM applications, ensuring substantial benefits and addressing any weaknesses in LLM implementation. With Confident AI, companies can define ground truths to ensure their LLM is behaving as expected, evaluate performance against expected outputs to pinpoint areas for iterations, and utilize advanced diff tracking to guide towards the optimal LLM stack. The platform offers comprehensive analytics to identify areas of focus and features such as A/B testing, evaluation, output classification, reporting dashboard, dataset generation, and detailed monitoring to help productionize LLMs with confidence.
Athina AI
Athina AI is a platform that provides research and guides for building safe and reliable AI products. It helps thousands of AI engineers in building safer products by offering tutorials, research papers, and evaluation techniques related to large language models. The platform focuses on safety, prompt engineering, hallucinations, and evaluation of AI models.
20 - Open Source AI Tools

llm-jp-eval
LLM-jp-eval is a tool designed to automatically evaluate Japanese large language models across multiple datasets. It provides functionalities such as converting existing Japanese evaluation data to text generation task evaluation datasets, executing evaluations of large language models across multiple datasets, and generating instruction data (jaster) in the format of evaluation data prompts. Users can manage the evaluation settings through a config file and use Hydra to load them. The tool supports saving evaluation results and logs using wandb. Users can add new evaluation datasets by following specific steps and guidelines provided in the tool's documentation. It is important to note that using jaster for instruction tuning can lead to artificially high evaluation scores, so caution is advised when interpreting the results.

bocoel
BoCoEL is a tool that leverages Bayesian Optimization to efficiently evaluate large language models by selecting a subset of the corpus for evaluation. It encodes individual entries into embeddings, uses Bayesian optimization to select queries, retrieves from the corpus, and provides easily managed evaluations. The tool aims to reduce computation costs during evaluation with a dynamic budget, supporting models like GPT2, Pythia, and LLAMA through integration with Hugging Face transformers and datasets. BoCoEL offers a modular design and efficient representation of the corpus to enhance evaluation quality.
CritiqueLLM
CritiqueLLM is an official implementation of a model designed for generating informative critiques to evaluate large language model generation. It includes functionalities for data collection, referenced pointwise grading, referenced pairwise comparison, reference-free pairwise comparison, reference-free pointwise grading, inference for pointwise grading and pairwise comparison, and evaluation of the generated results. The model aims to provide a comprehensive framework for evaluating the performance of large language models based on human ratings and comparisons.
TurtleBenchmark
Turtle Benchmark is a novel and cheat-proof benchmark test used to evaluate large language models (LLMs). It is based on the Turtle Soup game, focusing on logical reasoning and context understanding abilities. The benchmark does not require background knowledge or model memory, providing all necessary information for judgment from stories under 200 words. The results are objective and unbiased, quantifiable as correct/incorrect/unknown, and impossible to cheat due to using real user-generated questions and dynamic data generation during online gameplay.
llm-colosseum
llm-colosseum is a tool designed to evaluate Language Model Models (LLMs) in real-time by making them fight each other in Street Fighter III. The tool assesses LLMs based on speed, strategic thinking, adaptability, out-of-the-box thinking, and resilience. It provides a benchmark for LLMs to understand their environment and take context-based actions. Users can analyze the performance of different LLMs through ELO rankings and win rate matrices. The tool allows users to run experiments, test different LLM models, and customize prompts for LLM interactions. It offers installation instructions, test mode options, logging configurations, and the ability to run the tool with local models. Users can also contribute their own LLM models for evaluation and ranking.

moonshot
Moonshot is a simple and modular tool developed by the AI Verify Foundation to evaluate Language Model Models (LLMs) and LLM applications. It brings Benchmarking and Red-Teaming together to assist AI developers, compliance teams, and AI system owners in assessing LLM performance. Moonshot can be accessed through various interfaces including User-friendly Web UI, Interactive Command Line Interface, and seamless integration into MLOps workflows via Library APIs or Web APIs. It offers features like benchmarking LLMs from popular model providers, running relevant tests, creating custom cookbooks and recipes, and automating Red Teaming to identify vulnerabilities in AI systems.

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.

uncheatable_eval
Uncheatable Eval is a tool designed to assess the language modeling capabilities of LLMs on real-time, newly generated data from the internet. It aims to provide a reliable evaluation method that is immune to data leaks and cannot be gamed. The tool supports the evaluation of Hugging Face AutoModelForCausalLM models and RWKV models by calculating the sum of negative log probabilities on new texts from various sources such as recent papers on arXiv, new projects on GitHub, news articles, and more. Uncheatable Eval ensures that the evaluation data is not included in the training sets of publicly released models, thus offering a fair assessment of the models' performance.
llm-leaderboard
Nejumi Leaderboard 3 is a comprehensive evaluation platform for large language models, assessing general language capabilities and alignment aspects. The evaluation framework includes metrics for language processing, translation, summarization, information extraction, reasoning, mathematical reasoning, entity extraction, knowledge/question answering, English, semantic analysis, syntactic analysis, alignment, ethics/moral, toxicity, bias, truthfulness, and robustness. The repository provides an implementation guide for environment setup, dataset preparation, configuration, model configurations, and chat template creation. Users can run evaluation processes using specified configuration files and log results to the Weights & Biases project.

llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.

Awesome-LLM
Awesome-LLM is a curated list of resources related to large language models, focusing on papers, projects, frameworks, tools, tutorials, courses, opinions, and other useful resources in the field. It covers trending LLM projects, milestone papers, other papers, open LLM projects, LLM training frameworks, LLM evaluation frameworks, tools for deploying LLM, prompting libraries & tools, tutorials, courses, books, and opinions. The repository provides a comprehensive overview of the latest advancements and resources in the field of large language models.
agents
Agents 2.0 is a framework for training language agents using symbolic learning, inspired by connectionist learning for neural nets. It implements main components of connectionist learning like back-propagation and gradient-based weight update in the context of agent training using language-based loss, gradients, and weights. The framework supports optimizing multi-agent systems and allows multiple agents to take actions in one node.
llm_benchmarks
llm_benchmarks is a collection of benchmarks and datasets for evaluating Large Language Models (LLMs). It includes various tasks and datasets to assess LLMs' knowledge, reasoning, language understanding, and conversational abilities. The repository aims to provide comprehensive evaluation resources for LLMs across different domains and applications, such as education, healthcare, content moderation, coding, and conversational AI. Researchers and developers can leverage these benchmarks to test and improve the performance of LLMs in various real-world scenarios.
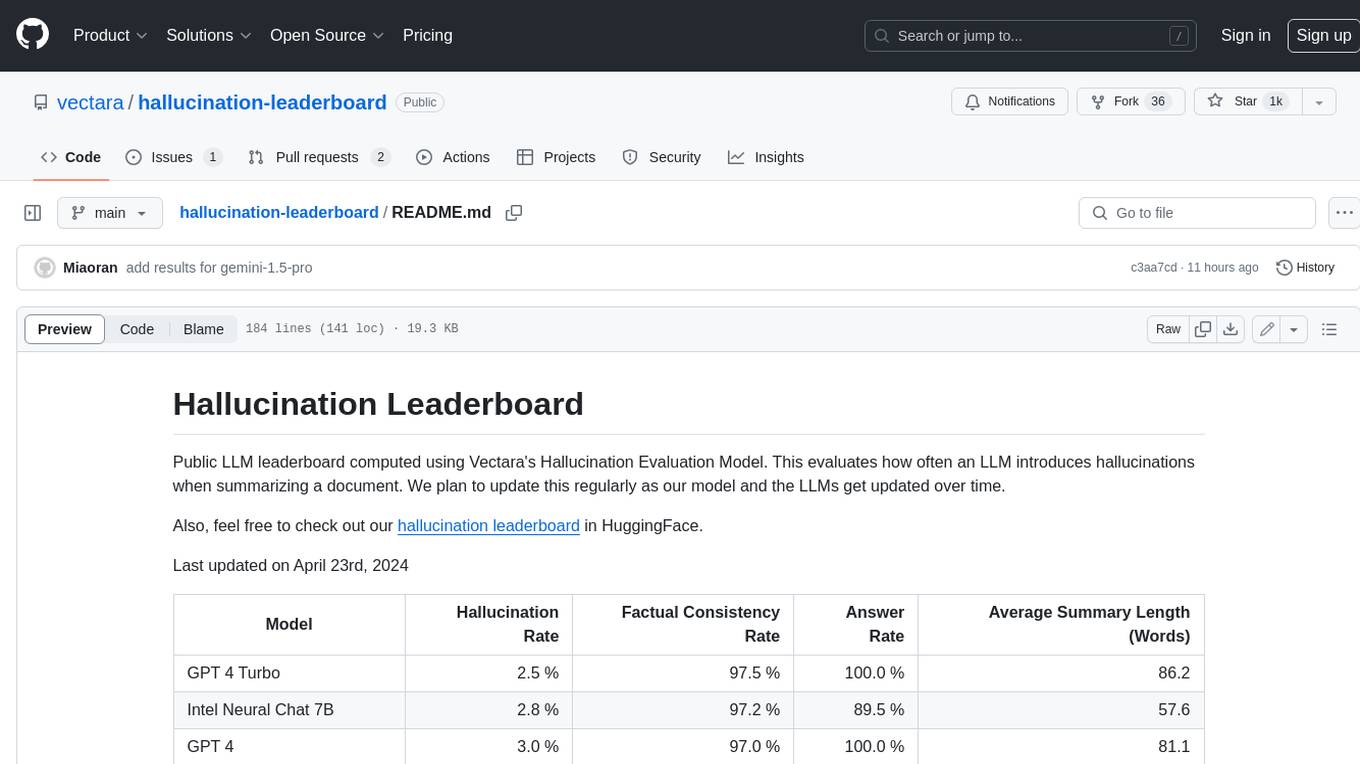
hallucination-leaderboard
This leaderboard evaluates the hallucination rate of various Large Language Models (LLMs) when summarizing documents. It uses a model trained by Vectara to detect hallucinations in LLM outputs. The leaderboard includes models from OpenAI, Anthropic, Google, Microsoft, Amazon, and others. The evaluation is based on 831 documents that were summarized by all the models. The leaderboard shows the hallucination rate, factual consistency rate, answer rate, and average summary length for each model.
awesome-llm-security
Awesome LLM Security is a curated collection of tools, documents, and projects related to Large Language Model (LLM) security. It covers various aspects of LLM security including white-box, black-box, and backdoor attacks, defense mechanisms, platform security, and surveys. The repository provides resources for researchers and practitioners interested in understanding and safeguarding LLMs against adversarial attacks. It also includes a list of tools specifically designed for testing and enhancing LLM security.

cladder
CLadder is a repository containing the CLadder dataset for evaluating causal reasoning in language models. The dataset consists of yes/no questions in natural language that require statistical and causal inference to answer. It includes fields such as question_id, given_info, question, answer, reasoning, and metadata like query_type and rung. The dataset also provides prompts for evaluating language models and example questions with associated reasoning steps. Additionally, it offers dataset statistics, data variants, and code setup instructions for using the repository.

h2o-llmstudio
H2O LLM Studio is a framework and no-code GUI designed for fine-tuning state-of-the-art large language models (LLMs). With H2O LLM Studio, you can easily and effectively fine-tune LLMs without the need for any coding experience. The GUI is specially designed for large language models, and you can finetune any LLM using a large variety of hyperparameters. You can also use recent finetuning techniques such as Low-Rank Adaptation (LoRA) and 8-bit model training with a low memory footprint. Additionally, you can use Reinforcement Learning (RL) to finetune your model (experimental), use advanced evaluation metrics to judge generated answers by the model, track and compare your model performance visually, and easily export your model to the Hugging Face Hub and share it with the community.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.
glossAPI
The glossAPI project aims to develop a Greek language model as open-source software, with code licensed under EUPL and data under Creative Commons BY-SA. The project focuses on collecting and evaluating open text sources in Greek, with efforts to prioritize and gather textual data sets. The project encourages contributions through the CONTRIBUTING.md file and provides resources in the wiki for viewing and modifying recorded sources. It also welcomes ideas and corrections through issue submissions. The project emphasizes the importance of open standards, ethically secured data, privacy protection, and addressing digital divides in the context of artificial intelligence and advanced language technologies.
20 - OpenAI Gpts
Dedicated Speech-Language Pathologist
Expert Speech-Language Pathologist offering tailored medical consultations.

Pytorch Trainer GPT
Your purpose is to create the pytorch code to train language models using pytorch

IELTS Writing Test
Simulates the IELTS Writing Test, evaluates responses, and estimates band scores.


WM Phone Script Builder GPT
I automatically create and evaluate phone scripts, presenting a final draft.



IELTS AI Checker (Speaking and Writing)
Provides IELTS speaking and writing feedback and scores.
Academic Paper Evaluator
Enthusiastic about truth in academic papers, critical and analytical.
Source Evaluation and Fact Checking v1.3
FactCheck Navigator GPT is designed for in-depth fact checking and analysis of written content and evaluation of its source. The approach is to iterate through predefined and well-prompted steps. If desired, the user can refine the process by providing input between these steps.

HuggingFace Helper
A witty yet succinct guide for HuggingFace, offering technical assistance on using the platform - based on their Learning Hub

VC Associate
A gpt assistant that helps with analyzing a startup/market. The answers you get back is already structured to give you the core elements you would want to see in an investment memo/ market analysis

Instructor GCP ML
Formador para la certificación de ML Engineer en GCP, con respuestas y explicaciones detalladas.
GPT Architect
Expert in designing GPT models and translating user needs into technical specs.