Best AI tools for< Config Llm Engine >
5 - AI tool Sites
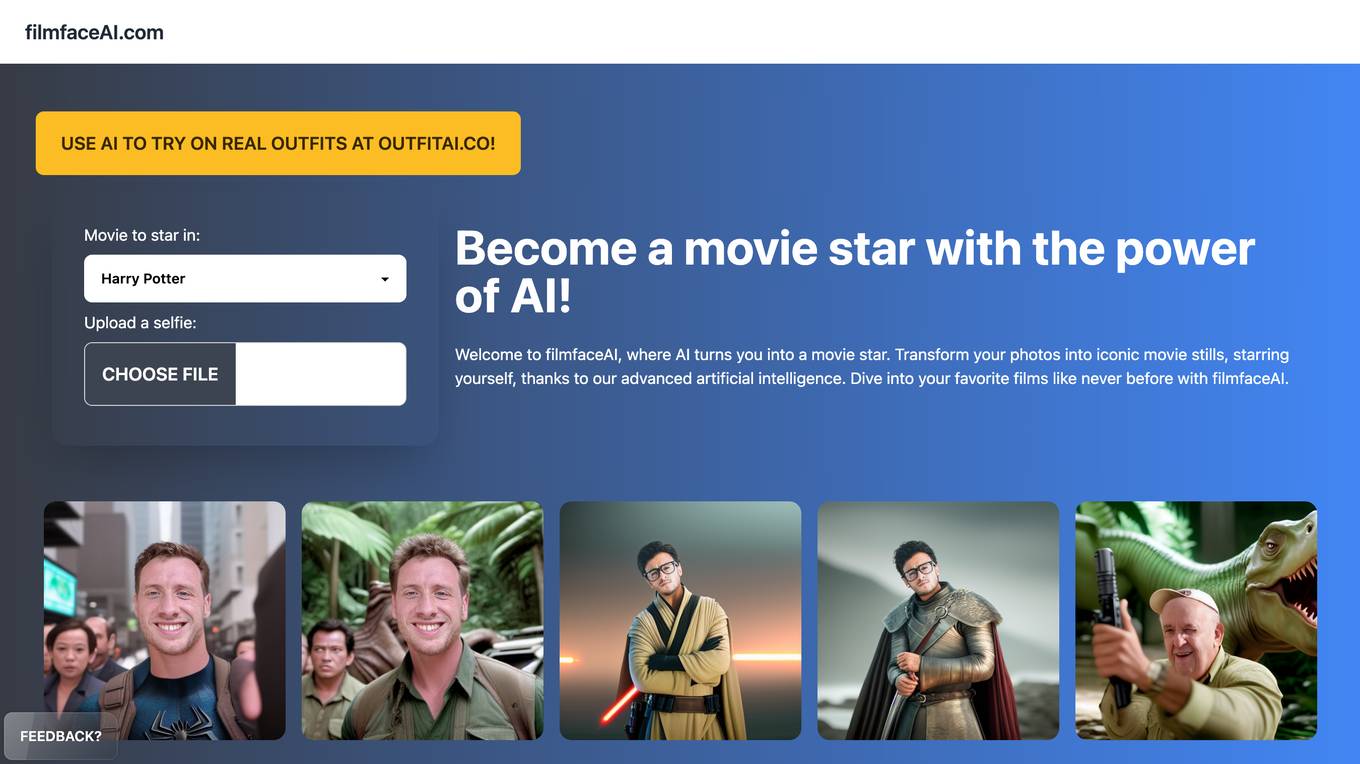
FilmfaceAI
FilmfaceAI is an AI application that allows users to transform their photos into iconic movie stills, starring themselves. The platform uses advanced artificial intelligence to create personalized AI gifts and turn users into movie stars. Users can dive into their favorite films like Harry Potter, The Lord of the Rings, and Fight Club by uploading a selfie. FilmfaceAI is designed to provide a fun and creative way for users to experience the magic of AI in the world of cinema.
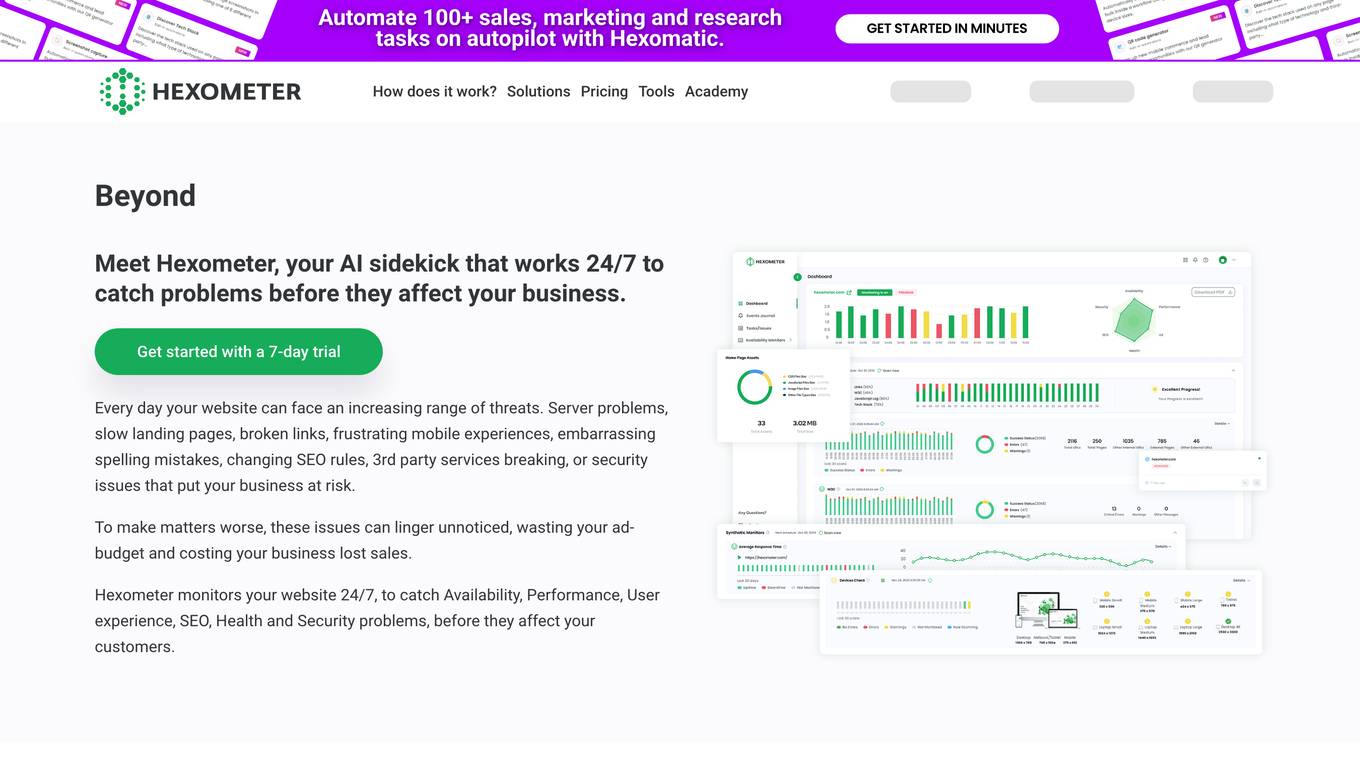
Hexometer
Hexometer is an AI-powered website monitoring tool that helps businesses protect and grow their online presence. It continuously monitors websites for availability, performance, user experience, SEO, health, and security issues, and alerts businesses when problems are detected. Hexometer also provides businesses with insights into their website's performance and helps them identify opportunities for improvement.
Cursor
Cursor is an AI-powered coding tool designed to make developers extraordinarily productive. It offers features such as AI-powered coding assistance in the IDE and CLI, mixed precision training, learning rate scheduling, and an experiment config system. Cursor is trusted by millions of professional developers for its accuracy, speed, and efficiency in coding tasks. It provides a seamless integration with popular platforms like GitHub and Slack, enhancing team collaboration and code review processes.
Sacred
Sacred is a tool to configure, organize, log and reproduce computational experiments. It is designed to introduce only minimal overhead, while encouraging modularity and configurability of experiments. The ability to conveniently make experiments configurable is at the heart of Sacred. If the parameters of an experiment are exposed in this way, it will help you to: keep track of all the parameters of your experiment easily run your experiment for different settings save configurations for individual runs in files or a database reproduce your results In Sacred we achieve this through the following main mechanisms: Config Scopes are functions with a @ex.config decorator, that turn all local variables into configuration entries. This helps to set up your configuration really easily. Those entries can then be used in captured functions via dependency injection. That way the system takes care of passing parameters around for you, which makes using your config values really easy. The command-line interface can be used to change the parameters, which makes it really easy to run your experiment with modified parameters. Observers log every information about your experiment and the configuration you used, and saves them for example to a Database. This helps to keep track of all your experiments. Automatic seeding helps controlling the randomness in your experiments, such that they stay reproducible.
EZClaws
EZClaws is an AI tool designed for one-click OpenClaw hosting, allowing users to deploy and manage OpenClaw instances with ease. It offers a fully managed platform for hosting AI agents, powered by world-class AI models like GPT-4 and Claude. EZClaws simplifies the deployment process by handling server setup, SSH keys, Docker configs, and more, all through a user-friendly interface. With features such as automated provisioning, isolated and encrypted environments, built-in usage tracking, and quick deployment times, EZClaws streamlines the hosting experience for AI enthusiasts and developers.
1 - Open Source AI Tools
UMbreLLa
UMbreLLa is a tool designed for deploying Large Language Models (LLMs) for personal agents. It combines offloading, speculative decoding, and quantization to optimize single-user LLM deployment scenarios. With UMbreLLa, 70B-level models can achieve performance comparable to human reading speed on an RTX 4070Ti, delivering exceptional efficiency and responsiveness, especially for coding tasks. The tool supports deploying models on various GPUs and offers features like code completion and CLI/Gradio chatbots. Users can configure the LLM engine for optimal performance based on their hardware setup.
1 - OpenAI Gpts