Best AI tools for< Clone Speech >
20 - AI tool Sites
LMNT
LMNT is an ultrafast and lifelike AI speech application that offers a developer API for creating conversational apps, agents, and games. It provides lifelike voices with studio-quality voice clones, engineered by an ex-Google team for reliability under pressure. Users can create engaging product marketing videos, lightning-fast conversational experiences, and high-quality audio for videos and avatars at scale. The application features an intuitive, no-code playground, versatile voice cloning options, and downloadable content for easy use in projects. With Python and Node SDKs, low latency streaming, and robust documentation, LMNT aims to simplify voice cloning and synthesis integration for developers.
Woy AI Tools
Woy AI Tools is a free AI voice cloning application that allows users to instantly clone voices with high similarity and realism. Users can upload a 10-second voice sample to generate and download cloned voices in multiple languages and accents. The tool ensures secure privacy and offers a simple interface for easy usage.
MyVocal.ai
MyVocal.ai is a text-to-speech and voice cloning tool that allows users to create realistic-sounding voices from text. With MyVocal.ai, you can clone your own voice or choose from a variety of pre-recorded voices. You can then use these voices to create songs, audiobooks, podcasts, and other audio content. MyVocal.ai also offers a variety of features to help you customize your voice, including the ability to change the pitch, speed, and volume. Additionally, MyVocal.ai offers a variety of features to help you create high-quality audio content, including the ability to add background music and sound effects.
LOVO
LOVO is an AI-powered voice generator that allows users to create realistic and high-quality voiceovers. It offers a wide range of features, including text-to-speech, voice cloning, and video editing. LOVO is perfect for businesses, content creators, educators, and anyone looking to create engaging content that stands out from the crowd.
AITurbos
AITurbos is an AI-powered platform that offers a suite of tools designed to revolutionize content creation and marketing strategies. With a focus on boosting engagement, saving time, and enhancing productivity, AITurbos provides advanced AI models for generating text, images, code, chatbots, and more. Users can access features like AI text generation, image generation, code generation, chatbot creation, and speech-to-text conversion. The platform supports multiple languages, custom templates, and data-driven customization to meet diverse content creation needs.
Narrify AI
Narrify AI is an AI-powered application that transforms your videos by adding sports commentary to them. With Narrify AI, users can upload any video file up to 45 seconds in length and enhance it with personalized commentary, highlighting names and key words. The application allows users to create engaging and fun narrated videos to share with friends and family. Narrify AI is a user-friendly tool that adds a unique touch to your videos, making them more entertaining and memorable.
Resemble AI
Resemble AI is an advanced AI Voice Generator and Deepfake Audio Detection platform designed for enterprises prioritizing security and safety. It offers features such as Voice Cloning, Text to Speech, Speech to Speech, Audio Editing, and Multilingual support. The platform enables users to create hyper-realistic AI voices, deploy AI models through the cloud or on-premises, and safeguard digital content with state-of-the-art deepfake detection technology. Resemble AI is trusted by millions worldwide for creating unique, dynamic messages and personalized experiences across various industries.
Wavel AI
Wavel AI is an advanced AI tool offering best-in-class Text-to-Speech Voice Solutions for Videos and Localization. It provides services such as AI Voice Generator, Text-to-speech with Human Emotions, Voice cloning, Subtitles, Translation, Transcription, Speech To Text, Voice Changer, Video To Shorts conversion, Screen Recorder, Accent Generator, and a variety of Video Tools. The platform supports multiple languages and offers features like script editing, subtitle editing, and localization tools for various multimedia needs.
DubSmart
DubSmart is an AI-powered platform that offers advanced video dubbing and voice cloning services. It allows users to transform text into lifelike speech, dub videos with voice cloning technology, and generate subtitles for audio or video content. With a user-friendly interface, DubSmart enables users to create unique voices, edit projects, and download finished projects in various formats. The platform supports 33 languages for AI dubbing and 60+ languages for speech-to-text conversion. DubSmart caters to small creators, YouTubers, and companies looking to enhance their audiovisual content with personalized voices and multilingual capabilities.
ElevenLabs
ElevenLabs is a text-to-speech (TTS) platform that uses artificial intelligence (AI) to generate realistic human-like voices. With ElevenLabs, you can convert any text into high-quality spoken audio in over 29 languages and 120 voices. The platform is easy to use and offers a variety of features, including the ability to adjust the voice's pitch, speed, and volume. You can also use ElevenLabs to create custom voices and clone your own voice. ElevenLabs is a powerful tool for content creators, businesses, and anyone who wants to create realistic spoken audio.
VideoDubber
VideoDubber is an AI-powered video translation and text-to-speech tool that offers premium video translation with voice cloning at a fraction of the market price. It enables users to make their videos speak in the language of their audience's choice using Generative AI. The platform supports translation to over 150 languages and accents, providing features like voice cloning, subtitles modification, and dubbing minutes. VideoDubber caters to a wide range of users, including Youtubers, businesses, and content creators, helping them reach a global audience and enhance viewer engagement through multilingual content.
Murf AI
Murf AI is a versatile text-to-speech software that simplifies business communication. It offers a range of solutions for various projects, including voiceovers, translations, and AI dubbing, ensuring clear, engaging, and far-reaching messages. With over 120 voices in 20+ languages, Murf AI empowers users to create realistic voiceovers that enhance content accessibility and engagement. Its voice cloning feature allows for the creation of near-perfect voice twins, ensuring intellectual property rights and delivering a realistic audio experience. Murf AI's AI dubbing service enables businesses to take their stories to a global audience with over 20 languages available, promoting universal understanding and cultural connectivity. Additionally, Murf AI's translation service simplifies the translation of business content into more than 20 languages, facilitating seamless international engagement. The Murf API allows developers to integrate high-quality voices into their digital platforms, ensuring a consistent brand voice across various applications. Murf Voices Installer adds favorite Murf voices to Windows systems, enabling users to enjoy them on any Microsoft SAPI-supported platform.
Respeecher
Respeecher is an AI tool that combines technology and magic to deliver authentic voices across various industries. It uses cutting-edge public models and proprietary technology to provide high-quality voice solutions. The team of dedicated sound professionals at Respeecher ensures ethical use of synthetic media, making it a trusted choice for voice cloning and voice conversion services.
TopMediai
TopMediai is an online platform that provides a suite of AI-powered tools for content creation, including text-to-speech, voice cloning, AI song covers, and more. With over 3200 realistic AI voices and 130+ languages and accents, TopMediai's text-to-speech tool allows users to create ultra-realistic voiceovers for their videos, podcasts, or other projects. The voice cloning tool enables users to create custom AI voices in minutes, which can be used for a variety of purposes such as e-learning, audiobooks, and video games. TopMediai's AI song cover generator allows users to create high-quality AI covers of their favorite songs in seconds, with multiple AI voice models and YouTube link support. In addition to these core tools, TopMediai also offers a range of other AI-powered tools for photo and video editing, including a watermark remover, passport photo maker, AI art generator, and background eraser.
VoiceCheap
VoiceCheap is an AI-powered application that offers dubbing, transcription, and speech synthesis services. It enables users to translate videos into multiple languages, clone voices, generate subtitles, remove background noise, and more. With features like SmartSync Technology and multi-speaker dubbing, VoiceCheap helps content creators produce professional-quality dubbed videos efficiently. The application uses advanced AI technology to provide cost-effective dubbing solutions and seamless integration with various platforms. VoiceCheap is trusted by professionals and loved by users worldwide for its innovative tools and services.
Authors' Voice
Authors' Voice is a cutting-edge AI tool designed to convert text-based books into high-quality audiobooks efficiently and quickly. The platform utilizes state-of-the-art AI-based text-to-speech technology to provide clear and natural-sounding narration with varied pacing and inflection. Authors' Voice aims to cater to content creators, independent authors, and publishers by offering affordable and profitable solutions to tap into the fast-growing audiobook market.
VoiceDub
VoiceDub is an AI-powered application that allows users to create voice covers of their favorite songs. It offers a wide range of AI voices to choose from, as well as the ability to clone your own voice. VoiceDub also includes a text-to-speech feature, which allows users to generate studio-quality vocals from text. The application is easy to use and produces high-quality results, making it a great choice for musicians, singers, and content creators.

Altered Studio
Altered Studio is a Voice Content Creation platform that provides exclusive access to our unique Speech-To-Speech Voice Morphing and integrates various Voice AI technologies into a single user friendly application for media production.
Listnr AI
Listnr AI is a leading AI voice generator tool that offers ultra-realistic AI voices indistinguishable from humans. With over 1000 different voices in more than 142 languages, including voice cloning capabilities, Listnr AI is trusted by 2,500,000+ users worldwide. The tool allows users to create voiceovers for various content types such as shorts, TikToks, YouTube videos, gaming, podcasts, sales, social media, and audiobooks. Listnr AI's state-of-the-art generative AI technology ensures that the voiceovers sound extremely natural, providing a seamless experience for content creators. Additionally, Listnr AI offers features like emotion fine-tuning, punctuations, pauses, and a wide range of multi-lingual voices to cater to diverse content needs.
Fineshare
Fineshare is an AI-driven platform offering a range of innovative products such as FineVoice AI Voice Studio, VoiceTrans Real-time AI Voice Changer, and FineCam AI Virtual Camera. Users can convert text into natural-sounding voices, transform their voice into any voice they like, transcribe audio & video with high accuracy, clone voices with different speaking styles, and create unique voice effects. Fineshare empowers individuals and organizations to enhance the expressiveness of their audio and video content through AI-driven voice technology.
20 - Open Source AI Tools
LocalAIVoiceChat
LocalAIVoiceChat is an experimental alpha software that enables real-time voice chat with a customizable AI personality and voice on your PC. It integrates Zephyr 7B language model with speech-to-text and text-to-speech libraries. The tool is designed for users interested in state-of-the-art voice solutions and provides an early version of a local real-time chatbot.

wunjo.wladradchenko.ru
Wunjo AI is a comprehensive tool that empowers users to explore the realm of speech synthesis, deepfake animations, video-to-video transformations, and more. Its user-friendly interface and privacy-first approach make it accessible to both beginners and professionals alike. With Wunjo AI, you can effortlessly convert text into human-like speech, clone voices from audio files, create multi-dialogues with distinct voice profiles, and perform real-time speech recognition. Additionally, you can animate faces using just one photo combined with audio, swap faces in videos, GIFs, and photos, and even remove unwanted objects or enhance the quality of your deepfakes using the AI Retouch Tool. Wunjo AI is an all-in-one solution for your voice and visual AI needs, offering endless possibilities for creativity and expression.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.
speech-to-speech
This repository implements a speech-to-speech cascaded pipeline with consecutive parts including Voice Activity Detection (VAD), Speech to Text (STT), Language Model (LM), and Text to Speech (TTS). It aims to provide a fully open and modular approach by leveraging models available on the Transformers library via the Hugging Face hub. The code is designed for easy modification, with each component implemented as a class. Users can run the pipeline either on a server/client approach or locally, with detailed setup and usage instructions provided in the readme.

openedai-speech
OpenedAI Speech is a free, private text-to-speech server compatible with the OpenAI audio/speech API. It offers custom voice cloning and supports various models like tts-1 and tts-1-hd. Users can map their own piper voices and create custom cloned voices. The server provides multilingual support with XTTS voices and allows fixing incorrect sounds with regex. Recent changes include bug fixes, improved error handling, and updates for multilingual support. Installation can be done via Docker or manual setup, with usage instructions provided. Custom voices can be created using Piper or Coqui XTTS v2, with guidelines for preparing audio files. The tool is suitable for tasks like generating speech from text, creating custom voices, and multilingual text-to-speech applications.
ai-devices
AI Devices Template is a project that serves as an AI-powered voice assistant utilizing various AI models and services to provide intelligent responses to user queries. It supports voice input, transcription, text-to-speech, image processing, and function calling with conditionally rendered UI components. The project includes customizable UI settings, optional rate limiting using Upstash, and optional tracing with Langchain's LangSmith for function execution. Users can clone the repository, install dependencies, add API keys, start the development server, and deploy the application. Configuration settings can be modified in `app/config.tsx` to adjust settings and configurations for the AI-powered voice assistant.

tts-generation-webui
TTS Generation WebUI is a comprehensive tool that provides a user-friendly interface for text-to-speech and voice cloning tasks. It integrates various AI models such as Bark, MusicGen, AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, and MAGNeT. The tool offers one-click installers, Google Colab demo, videos for guidance, and extra voices for Bark. Users can generate audio outputs, manage models, caches, and system space for AI projects. The project is open-source and emphasizes ethical and responsible use of AI technology.
CosyVoice
CosyVoice is a tool designed for speech synthesis, offering pretrained models for zero-shot, sft, instruct inference. It provides a web demo for easy usage and supports advanced users with train and inference scripts. The tool can be deployed using grpc for service deployment. Users can download pretrained models and resources for immediate use or train their own models from scratch. CosyVoice is suitable for researchers, developers, linguists, AI engineers, and speech technology enthusiasts.
EmotiVoice
EmotiVoice is a powerful and modern open-source text-to-speech engine that supports emotional synthesis, enabling users to create speech with a wide range of emotions such as happy, excited, sad, and angry. It offers over 2000 different voices in both English and Chinese. Users can access EmotiVoice through an easy-to-use web interface or a scripting interface for batch generation of results. The tool is continuously evolving with new features and updates, prioritizing community input and user feedback.
VSP-LLM
VSP-LLM (Visual Speech Processing incorporated with LLMs) is a novel framework that maximizes context modeling ability by leveraging the power of LLMs. It performs multi-tasks of visual speech recognition and translation, where given instructions control the task type. The input video is mapped to the input latent space of a LLM using a self-supervised visual speech model. To address redundant information in input frames, a deduplication method is employed using visual speech units. VSP-LLM utilizes Low Rank Adaptors (LoRA) for computationally efficient training.

HebTTS
HebTTS is a language modeling approach to diacritic-free Hebrew text-to-speech (TTS) system. It addresses the challenge of accurately mapping text to speech in Hebrew by proposing a language model that operates on discrete speech representations and is conditioned on a word-piece tokenizer. The system is optimized using weakly supervised recordings and outperforms diacritic-based Hebrew TTS systems in terms of content preservation and naturalness of generated speech.
MockingBird
MockingBird is a toolbox designed for Mandarin speech synthesis using PyTorch. It supports multiple datasets such as aidatatang_200zh, magicdata, aishell3, and data_aishell. The toolbox can run on Windows, Linux, and M1 MacOS, providing easy and effective speech synthesis with pretrained encoder/vocoder models. It is webserver ready for remote calling. Users can train their own models or use existing ones for the encoder, synthesizer, and vocoder. The toolbox offers a demo video and detailed setup instructions for installation and model training.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.
Mantella
Mantella is a Skyrim and Fallout 4 mod that allows you to naturally speak to NPCs using Whisper (speech-to-text), LLMs (text generation), and xVASynth / XTTS (text-to-speech). With Mantella, you can have more immersive and engaging conversations with the characters in your favorite games.

bark.cpp
Bark.cpp is a C/C++ implementation of the Bark model, a real-time, multilingual text-to-speech generation model. It supports AVX, AVX2, and AVX512 for x86 architectures, and is compatible with both CPU and GPU backends. Bark.cpp also supports mixed F16/F32 precision and 4-bit, 5-bit, and 8-bit integer quantization. It can be used to generate realistic-sounding audio from text prompts.
audioseal
AudioSeal is a method for speech localized watermarking, designed with state-of-the-art robustness and detector speed. It jointly trains a generator to embed a watermark in audio and a detector to detect watermarked fragments in longer audios, even in the presence of editing. The tool achieves top-notch detection performance at the sample level, generates minimal alteration of signal quality, and is robust to various audio editing types. With a fast, single-pass detector, AudioSeal surpasses existing models in speed, making it ideal for large-scale and real-time applications.
ChatGPT-OpenAI-Smart-Speaker
ChatGPT Smart Speaker is a project that enables speech recognition and text-to-speech functionalities using OpenAI and Google Speech Recognition. It provides scripts for running on PC/Mac and Raspberry Pi, allowing users to interact with a smart speaker setup. The project includes detailed instructions for setting up the required hardware and software dependencies, along with customization options for the OpenAI model engine, language settings, and response randomness control. The Raspberry Pi setup involves utilizing the ReSpeaker hardware for voice feedback and light shows. The project aims to offer an advanced smart speaker experience with features like wake word detection and response generation using AI models.

ChatTTS
ChatTTS is a generative speech model optimized for dialogue scenarios, providing natural and expressive speech synthesis with fine-grained control over prosodic features. It supports multiple speakers and surpasses most open-source TTS models in terms of prosody. The model is trained with 100,000+ hours of Chinese and English audio data, and the open-source version on HuggingFace is a 40,000-hour pre-trained model without SFT. The roadmap includes open-sourcing additional features like VQ encoder, multi-emotion control, and streaming audio generation. The tool is intended for academic and research use only, with precautions taken to limit potential misuse.
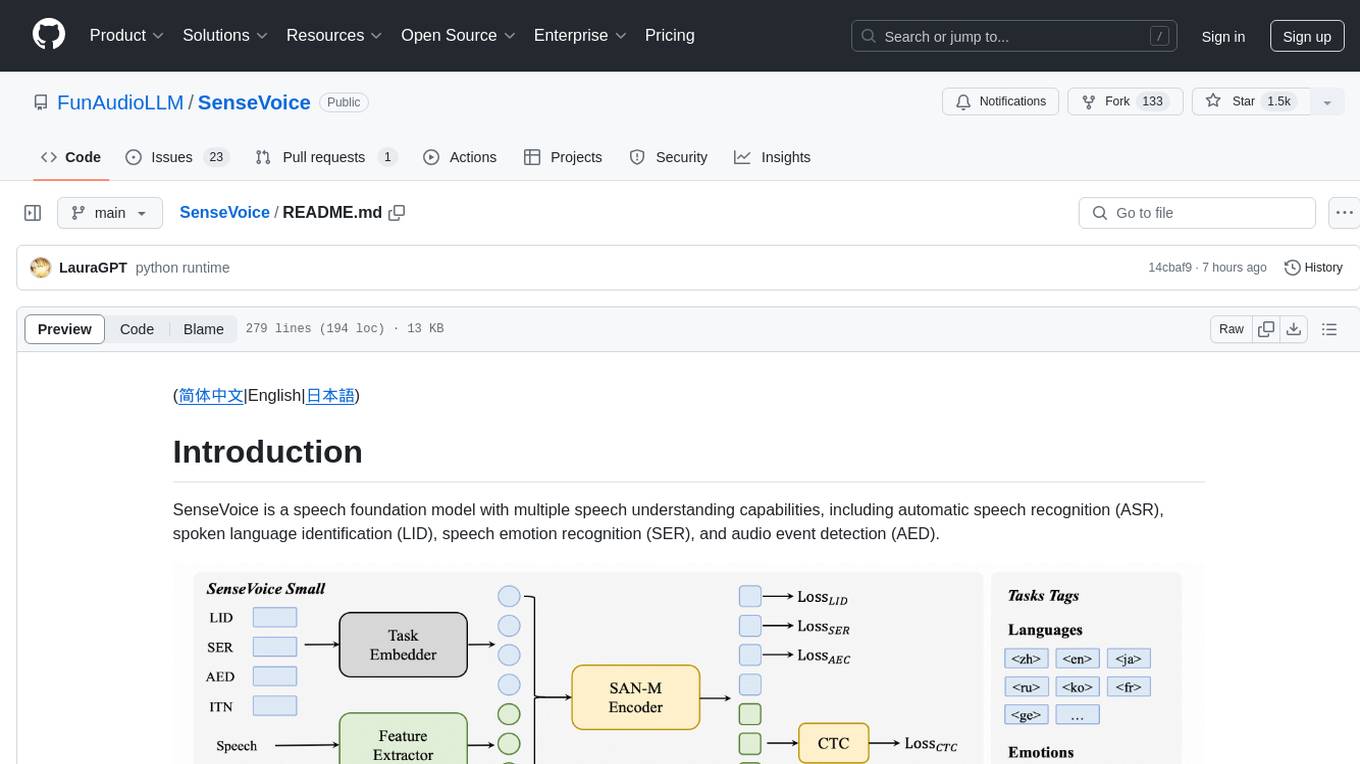
SenseVoice
SenseVoice is a speech foundation model focusing on high-accuracy multilingual speech recognition, speech emotion recognition, and audio event detection. Trained with over 400,000 hours of data, it supports more than 50 languages and excels in emotion recognition and sound event detection. The model offers efficient inference with low latency and convenient finetuning scripts. It can be deployed for service with support for multiple client-side languages. SenseVoice-Small model is open-sourced and provides capabilities for Mandarin, Cantonese, English, Japanese, and Korean. The tool also includes features for natural speech generation and fundamental speech recognition tasks.
obs-localvocal
LocalVocal is a Speech AI assistant OBS Plugin that enables users to transcribe speech into text and translate it into any language locally on their machine. The plugin runs OpenAI's Whisper for real-time speech processing and prediction. It supports features like transcribing audio in real-time, displaying captions on screen, sending captions to files, syncing captions with recordings, and translating captions to major languages. Users can bring their own Whisper model, filter or replace captions, and experience partial transcriptions for streaming. The plugin is privacy-focused, requiring no GPU, cloud costs, network, or downtime.
20 - OpenAI Gpts

Image Theme Clone
Type “Start” and Get Exact Details on Image Generation and/or Duplication
Cloner
Clone and replicate the source site using a screenshot, while enabling continuous development and optimization capabilities. - 通过截图复制源站点前端代码,同时具备持续开发和优化功能。Any Issue: contact me @X: https://twitter.com/tb_xy09

Style Cloner GPT
Imitates a specific individual's style and opinions accurately and ethically.


REPO MASTER
Expert at fetching repository information from GitHub, Hugging Face. and you local repositories
Image cloner
From an attached image, the bot will generate a prompt to replicate the image in a digital art bot such as Midjourney or DALL-E
Cosmic Contact
Expert on extraterrestrial abductions and close encounters, with a verification process for accuracy.

Solar Pro Advisor
Your guide in solar sales mastery, offering in-depth resources for handling objections and effective marketing strategies. Over 7 Years of Proprietary data and a Knowledge Base from within the Solar Industry with battle Tested Ads and Real Training.
Master of Power Negotiating
Negotiation assistant based on Roger Dawson's strategies. You will never make money faster than when you are negotiating!