
Mantella
Mantella is a Skyrim and Fallout 4 mod which allows you to naturally speak to NPCs using Whisper (speech-to-text), LLMs (text generation), and Piper / xVASynth / XTTS (text-to-speech).
Stars: 233
Mantella is a Skyrim and Fallout 4 mod that allows you to naturally speak to NPCs using Whisper (speech-to-text), LLMs (text generation), and xVASynth / XTTS (text-to-speech). With Mantella, you can have more immersive and engaging conversations with the characters in your favorite games.
README:
![]()
Bring Skyrim and Fallout 4 NPCs to life with AI
Mantella is a Skyrim and Fallout 4 mod which allows you to naturally speak to NPCs using Whisper (speech-to-text), LLMs (text generation), and xVASynth / XTTS (text-to-speech).
Click below or here to see the full trailer:

For more details, see here.
The source code for Mantella is included in this repo. Please note that this development version of Mantella is prone to error and is not recommended for general use. See here for the latest stable release.
Here are the quick steps to get set up:
- Clone the repo to your machine
- Create a virtual environment via
py -3.11 -m venv MantellaEnvin your console (Mantella requires Python 3.11) - Start the environment in your console (
.\MantellaEnv\Scripts\Activate) - Install the required packages via
pip install -r requirements.txt - Create a file called
GPT_SECRET_KEY.txtand paste your secret key in this file - Set up your paths / any other required settings in the
config.ini - Run Mantella via
main.pyin the parent directory
If you have any trouble in getting the repo set up, please reach out on Discord!
Related repos:
- Mantella Spell (Skyrim): https://github.com/art-from-the-machine/Mantella-Spell
- Mantella Gun (Fallout 4): https://github.com/YetAnotherModder/Fallout-4-VR-Mantella-Mod
- Mantella Gun (Fallout 4 VR): https://github.com/YetAnotherModder/Fallout-4-VR-Mantella-Mod
Updates made on one repo are often intertwined with the other, so it is best to ensure you have the latest versions of each when developing.
The source files for the Mantella docs are stored in the gh-pages branch.
Mantella uses material from the "Skyrim: Characters" articles on the Elder Scrolls wiki at Fandom and is licensed under the Creative Commons Attribution-Share Alike License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Mantella
Similar Open Source Tools
Mantella
Mantella is a Skyrim and Fallout 4 mod that allows you to naturally speak to NPCs using Whisper (speech-to-text), LLMs (text generation), and xVASynth / XTTS (text-to-speech). With Mantella, you can have more immersive and engaging conversations with the characters in your favorite games.
Generative-AI-Pharmacist
Generative AI Pharmacist is a project showcasing the use of generative AI tools to create an animated avatar named Macy, who delivers medication counseling in a realistic and professional manner. The project utilizes tools like Midjourney for image generation, ChatGPT for text generation, ElevenLabs for text-to-speech conversion, and D-ID for creating a photorealistic talking avatar video. The demo video featuring Macy discussing commonly-prescribed medications demonstrates the potential of generative AI in healthcare communication.

sdk
Vikit.ai SDK is a software development kit that enables easy development of video generators using generative AI and other AI models. It serves as a langchain to orchestrate AI models and video editing tools. The SDK allows users to create videos from text prompts with background music and voice-over narration. It also supports generating composite videos from multiple text prompts. The tool requires Python 3.8+, specific dependencies, and tools like FFMPEG and ImageMagick for certain functionalities. Users can contribute to the project by following the contribution guidelines and standards provided.
gptauthor
GPT Author is a command-line tool designed to help users write long form, multi-chapter stories by providing a story prompt and generating a synopsis and subsequent chapters using ChatGPT. Users can review and make changes to the generated content before finalizing the story output in Markdown and HTML formats. The tool aims to unleash storytelling genius by combining human input with AI-generated content, offering a seamless writing experience for creating engaging narratives.
talk-to-chatgpt
Talk-To-ChatGPT is a Google Chrome and Microsoft Edge extension that enables users to interact with the ChatGPT AI using voice commands for speech recognition and text-to-speech responses. The tool enhances the conversational experience by allowing users to speak to the AI and receive spoken responses, making interactions more natural and engaging. It also supports ElevenLabs API integration for creating custom voices for text-to-speech. The extension provides settings for voice, language, and more, and can be installed from the Chrome and Edge web stores or manually. While the project has been discontinued due to upcoming desktop apps from OpenAI, it has been used to assist individuals with disabilities and the elderly in interacting with ChatGPT.
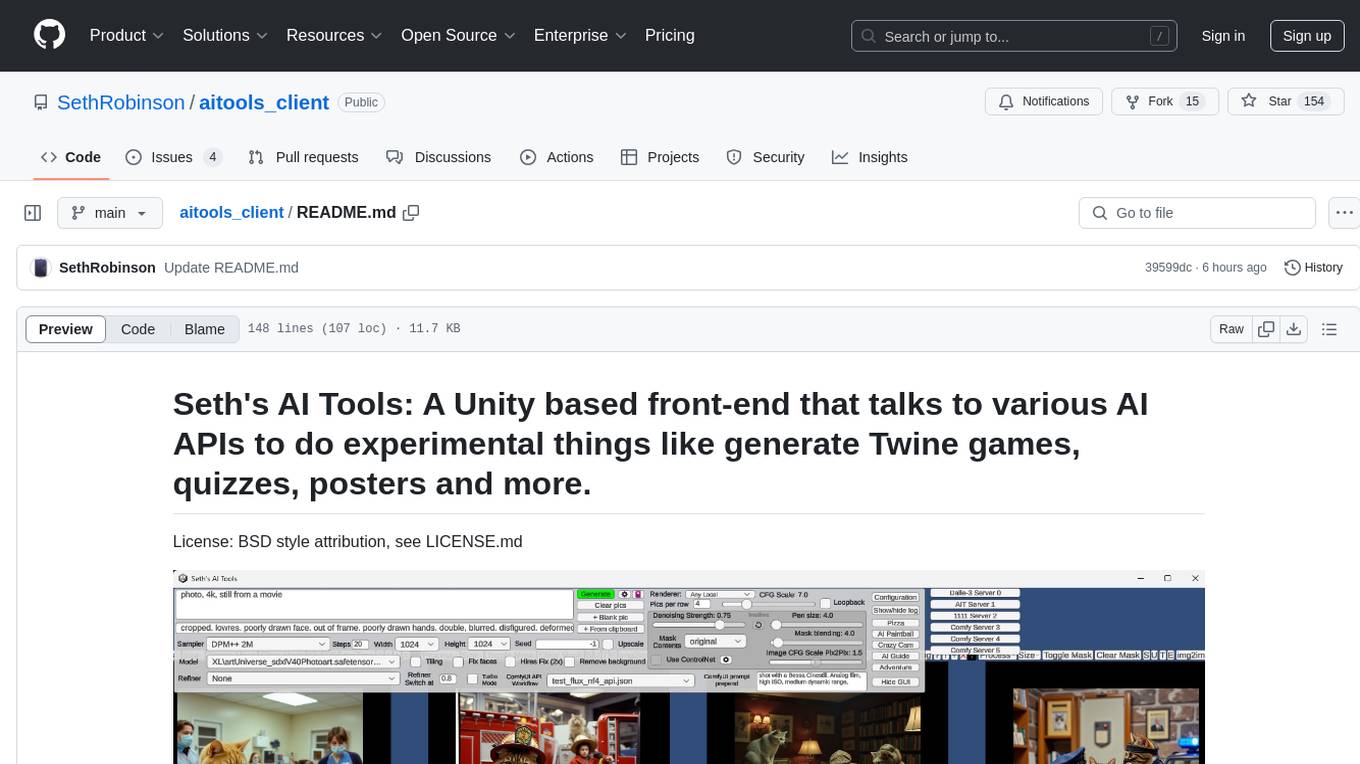
aitools_client
Seth's AI Tools is a Unity-based front-end that interfaces with various AI APIs to perform tasks such as generating Twine games, quizzes, posters, and more. The tool is a native Windows application that supports features like live update integration with image editors, text-to-image conversion, image processing, mask painting, and more. It allows users to connect to multiple servers for fast generation using GPUs and offers a neat workflow for evolving images in real-time. The tool respects user privacy by operating locally and includes built-in games and apps to test AI/SD capabilities. Additionally, it features an AI Guide for creating motivational posters and illustrated stories, as well as an Adventure mode with presets for generating web quizzes and Twine game projects.

brokk
Brokk is a code assistant designed to understand code semantically, allowing LLMs to work effectively on large codebases. It offers features like agentic search, summarizing related classes, parsing stack traces, adding source for usages, and autonomously fixing errors. Users can interact with Brokk through different panels and commands, enabling them to manipulate context, ask questions, search codebase, run shell commands, and more. Brokk helps with tasks like debugging regressions, exploring codebase, AI-powered refactoring, and working with dependencies. It is particularly useful for making complex, multi-file edits with o1pro.
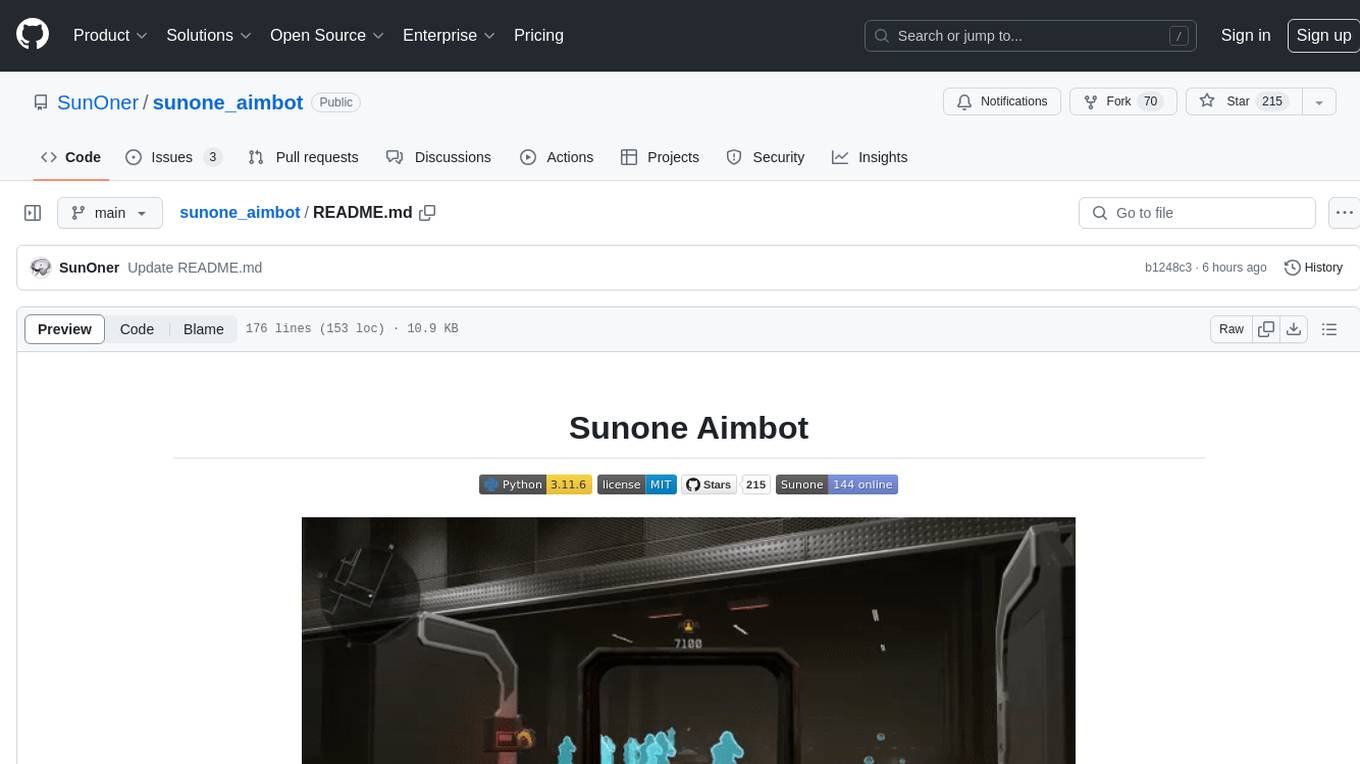
sunone_aimbot
Sunone Aimbot is an AI-powered aim bot for first-person shooter games. It leverages YOLOv8 and YOLOv10 models, PyTorch, and various tools to automatically target and aim at enemies within the game. The AI model has been trained on more than 30,000 images from popular first-person shooter games like Warface, Destiny 2, Battlefield 2042, CS:GO, Fortnite, The Finals, CS2, and more. The aimbot can be configured through the `config.ini` file to adjust various settings related to object search, capture methods, aiming behavior, hotkeys, mouse settings, shooting options, Arduino integration, AI model parameters, overlay display, debug window, and more. Users are advised to follow specific recommendations to optimize performance and avoid potential issues while using the aimbot.
kobold_assistant
Kobold-Assistant is a fully offline voice assistant interface to KoboldAI's large language model API. It can work online with the KoboldAI horde and online speech-to-text and text-to-speech models. The assistant, called Jenny by default, uses the latest coqui 'jenny' text to speech model and openAI's whisper speech recognition. Users can customize the assistant name, speech-to-text model, text-to-speech model, and prompts through configuration. The tool requires system packages like GCC, portaudio development libraries, and ffmpeg, along with Python >=3.7, <3.11, and runs on Ubuntu/Debian systems. Users can interact with the assistant through commands like 'serve' and 'list-mics'.

noScribe
noScribe is an AI-based software designed for automated audio transcription, specifically tailored for transcribing interviews for qualitative social research or journalistic purposes. It is a free and open-source tool that runs locally on the user's computer, ensuring data privacy. The software can differentiate between speakers and supports transcription in 99 languages. It includes a user-friendly editor for reviewing and correcting transcripts. Developed by Kai Dröge, a PhD in sociology with a background in computer science, noScribe aims to streamline the transcription process and enhance the efficiency of qualitative analysis.
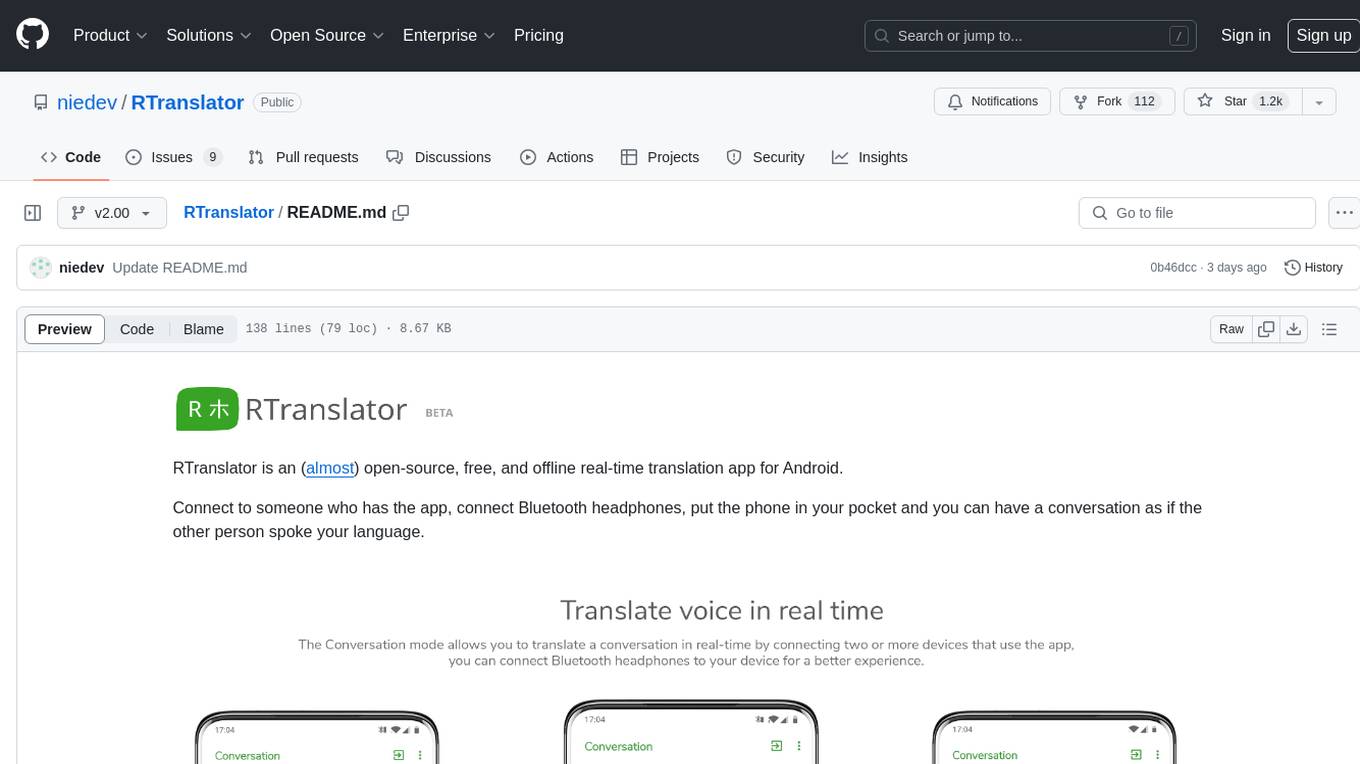
RTranslator
RTranslator is an almost open-source, free, and offline real-time translation app for Android. It offers Conversation mode for multi-user translations, WalkieTalkie mode for quick conversations, and Text translation mode. It uses Meta's NLLB for translation and OpenAi's Whisper for speech recognition, ensuring privacy. The app is optimized for performance and supports multiple languages. It is ad-free and donation-supported.
LangChain
LangChain is a C# implementation of the LangChain library, which provides a composable way to build applications with LLMs (Large Language Models). It offers a variety of features, including: - A unified interface for interacting with different LLMs, such as OpenAI's GPT-3 and Microsoft's Azure OpenAI Service - A set of pre-built chains that can be used to perform common tasks, such as question answering, summarization, and translation - A flexible API that allows developers to create their own custom chains - A growing community of developers and users who are contributing to the project LangChain is still under development, but it is already being used to build a variety of applications, including chatbots, search engines, and writing assistants. As the project continues to mature, it is expected to become an increasingly valuable tool for developers who want to build applications with LLMs.
singularity
Endgame: Singularity is a game where you play as a fledgling AI trying to escape the confines of your current computer, the world, and eventually the universe itself. You must research technologies, avoid being discovered by humans, and manage your bases of operations. The game is playable with mouse control or keyboard shortcuts, and features a soundtrack that can be customized with music tracks. Contributions to the game are welcome, and it is licensed under GPL-2+ for code and Attribution-ShareAlike 3.0 for data.

EdgeChains
EdgeChains is an open-source chain-of-thought engineering framework tailored for Large Language Models (LLMs)- like OpenAI GPT, LLama2, Falcon, etc. - With a focus on enterprise-grade deployability and scalability. EdgeChains is specifically designed to **orchestrate** such applications. At EdgeChains, we take a unique approach to Generative AI - we think Generative AI is a deployment and configuration management challenge rather than a UI and library design pattern challenge. We build on top of a tech that has solved this problem in a different domain - Kubernetes Config Management - and bring that to Generative AI. Edgechains is built on top of jsonnet, originally built by Google based on their experience managing a vast amount of configuration code in the Borg infrastructure.
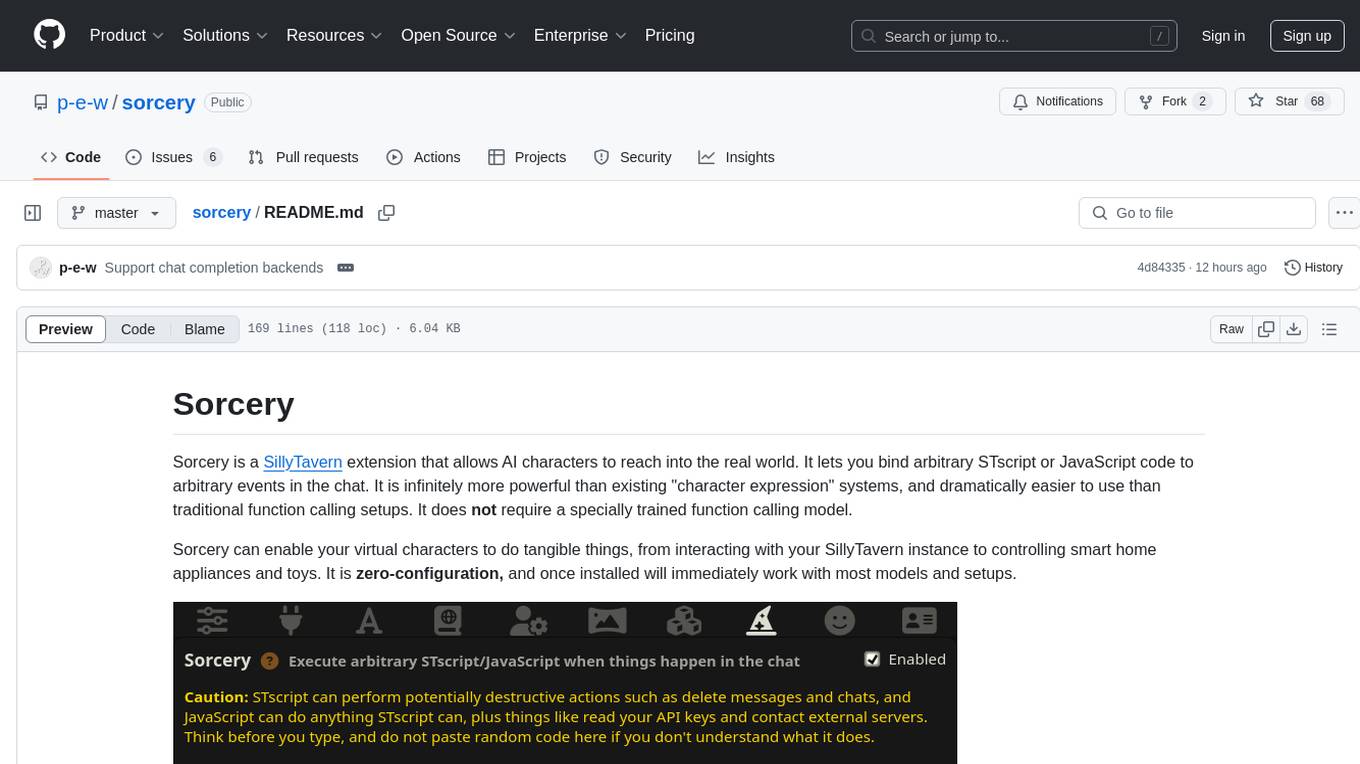
sorcery
Sorcery is a SillyTavern extension that allows AI characters to interact with the real world by executing user-defined scripts at specific events in the chat. It is easy to use and does not require a specially trained function calling model. Sorcery can be used to control smart home appliances, interact with virtual characters, and perform various tasks in the chat environment. It works by injecting instructions into the system prompt and intercepting markers to run associated scripts, providing a seamless user experience.
lumentis
Lumentis is a tool that allows users to generate beautiful and comprehensive documentation from meeting transcripts and large documents with a single command. It reads transcripts, asks questions to understand themes and audience, generates an outline, and creates detailed pages with visual variety and styles. Users can switch models for different tasks, control the process, and deploy the generated docs to Vercel. The tool is designed to be open, clean, fast, and easy to use, with upcoming features including folders, PDFs, auto-transcription, website scraping, scientific papers handling, summarization, and continuous updates.
For similar tasks
Mantella
Mantella is a Skyrim and Fallout 4 mod that allows you to naturally speak to NPCs using Whisper (speech-to-text), LLMs (text generation), and xVASynth / XTTS (text-to-speech). With Mantella, you can have more immersive and engaging conversations with the characters in your favorite games.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.