Best AI tools for< Allocate Resources >
8 - AI tool Sites
FYLD
FYLD is a fieldwork execution platform powered by AI that revolutionizes the way work is done. It provides true visibility into fieldwork operations, enabling smarter and faster decision-making that impacts productivity, safety, sustainability, and revenue for organizations worldwide.
Likely.AI
Likely.AI is an AI-powered platform designed for the real estate industry, offering innovative solutions to enhance database management, marketing content creation, and predictive analytics. The platform utilizes advanced AI models to predict likely sellers, update contact information, and trigger automated notifications, ensuring real estate professionals stay ahead of the competition. With features like contact enrichment, predictive modeling, 24/7 contact monitoring, and AI-driven marketing content generation, Likely.AI revolutionizes how real estate businesses operate and engage with their clients. The platform aims to streamline workflows, improve lead generation, and maximize ROI for users in the residential real estate sector.
Epicflow
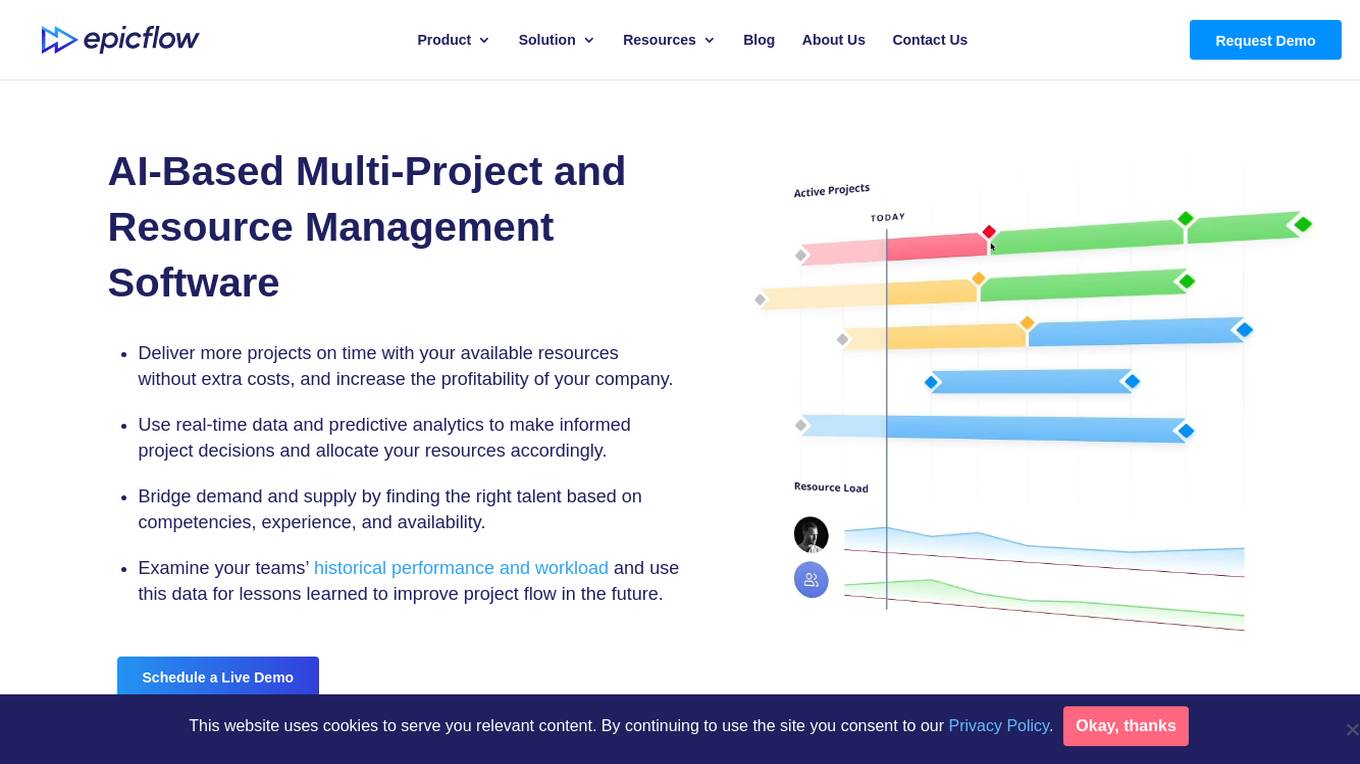
Epicflow is an AI-based multi-project and resource management software designed to help organizations deliver more projects on time with available resources, increase profitability, and make informed project decisions using real-time data and predictive analytics. The software bridges demand and supply by matching talent based on competencies, experience, and availability. It offers features like AI assistant, What-If Analysis, Future Load Graph, Historical Load Graph, Task List, and Competence Management Pipeline. Epicflow is trusted by leading companies in various industries for high performance and flawless project delivery.
Connected-Stories
Connected-Stories is the next generation of Creative Management Platforms powered by AI. It is a cloud-based platform that helps creative teams to manage their projects, collaborate with each other, and track their progress. Connected-Stories uses AI to automate many of the tasks that are typically associated with creative management, such as scheduling, budgeting, and resource allocation. This allows creative teams to focus on their work and be more productive.

Mudder AI
Mudder AI is a data-powered coordination platform designed for resilient emergency response. The platform offers intelligent solutions for faster community recovery by uniting data, optimizing disaster response, and empowering emergency management through integrated intelligence. It combines data integration and harmonization, real-time situational awareness, predictive analytics and modeling, intelligent resource allocation and deployment, collaborative decision support, and post-disaster assessment and recovery. Mudder AI provides a comprehensive suite of professional services for a diverse clientele, from homeowners to commercial developers, to enhance disaster management capabilities and ensure efficient resource allocation during emergencies.
Mosaic
Mosaic is a modern, automated, and AI-powered resource planning, management, and forecasting software designed to maximize profitability by providing a fast, easy, and visual way to plan resource allocation, assemble project teams, and understand workload capacity. It offers features such as AI team building, workload forecasting, headcount planning, and capacity planning. Mosaic helps organizations improve planning efficiency, drive profitability, and reduce burnout by visualizing workload, managing people together, and building project schedules around actual capacity. The software provides real-time reports, out-of-the-box reporting, and dashboard analytics for better decision-making. Mosaic is collaborative, intuitive, and automated, making complex processes visual and easy to use.
Fuel50
Fuel50 is an AI Talent Marketplace that offers personalized skill development paths and growth opportunities for employees. It leverages expert-driven skills ontology to align individual aspirations with organizational goals, enhance internal mobility, boost employee engagement, and increase retention. Fuel50 provides deep insights into workforce capabilities, enabling data-driven decisions for creating agile, resilient teams. The platform offers features like automated skill to role mapping, talent allocation, employee-driven career pathways, and holistic employee growth.
BrightBid
BrightBid is an AI-powered advertising optimization tool that helps users maximize the performance of their ad campaigns. By leveraging AI and automation, BrightBid enables users to make data-driven decisions, automate bids, find keywords, create ad copy, and allocate budgets easily. The tool provides intuitive dashboards for tracking ad performance, monitoring targets and metrics, controlling budget spend, and gaining competitive insights by tracking competitors. BrightBid aims to supercharge ads and boost ROI by utilizing AI technology to optimize advertising strategies and increase return on investment.
3 - Open Source AI Tools

timefold-solver
Timefold Solver is an optimization engine evolved from OptaPlanner. Developed by the original OptaPlanner team, our aim is to free the world of wasteful planning.
incubator-kie-optaplanner
A fast, easy-to-use, open source AI constraint solver for software developers. OptaPlanner is a powerful tool that helps developers solve complex optimization problems by providing a constraint satisfaction solver. It allows users to model and solve planning and scheduling problems efficiently, improving decision-making processes and resource allocation. With OptaPlanner, developers can easily integrate optimization capabilities into their applications, leading to better performance and cost-effectiveness.
KAI-Scheduler
KAI Scheduler is a robust, efficient, and scalable Kubernetes scheduler optimized for GPU resource allocation in AI and machine learning workloads. It supports batch scheduling, bin packing, spread scheduling, workload priority, hierarchical queues, resource distribution, fairness policies, workload consolidation, elastic workloads, dynamic resource allocation, GPU sharing, and works in both cloud and on-premise environments.
5 - OpenAI Gpts

Project Scheduling Advisor
Coordinates project timelines ensuring efficient workflow and productivity.

Prioritization Matrix Pro
Structured process for prioritizing marketing tasks based on strategic alignment. Outputs in Eisenhower, RACI and other methodologies.
Project Resource Planning Advisor
Optimizes project resources to ensure efficient delivery.