
flyte
Scalable and flexible workflow orchestration platform that seamlessly unifies data, ML and analytics stacks.
Stars: 6490
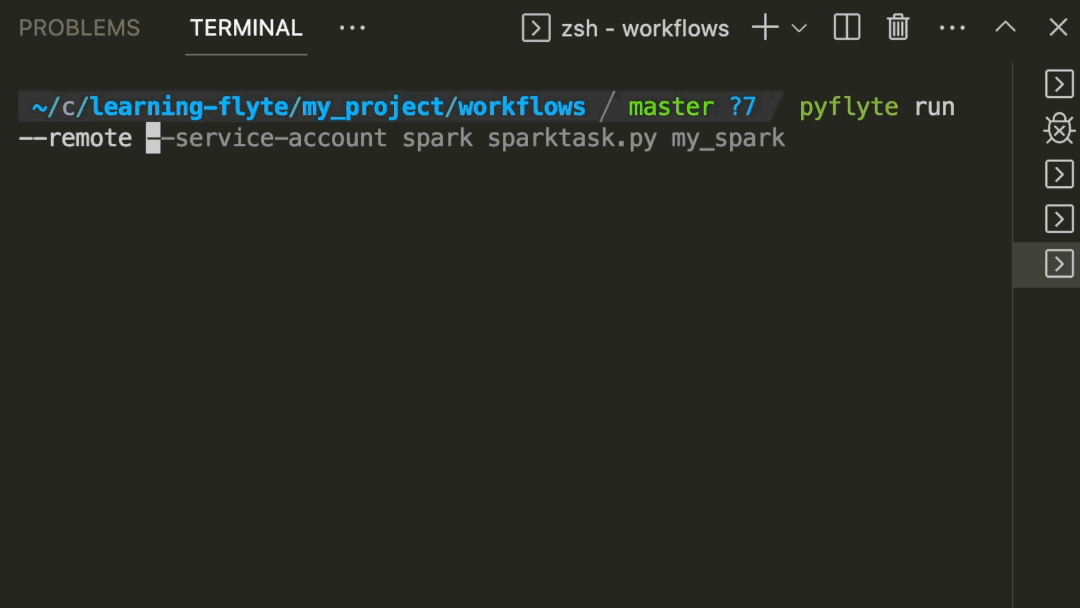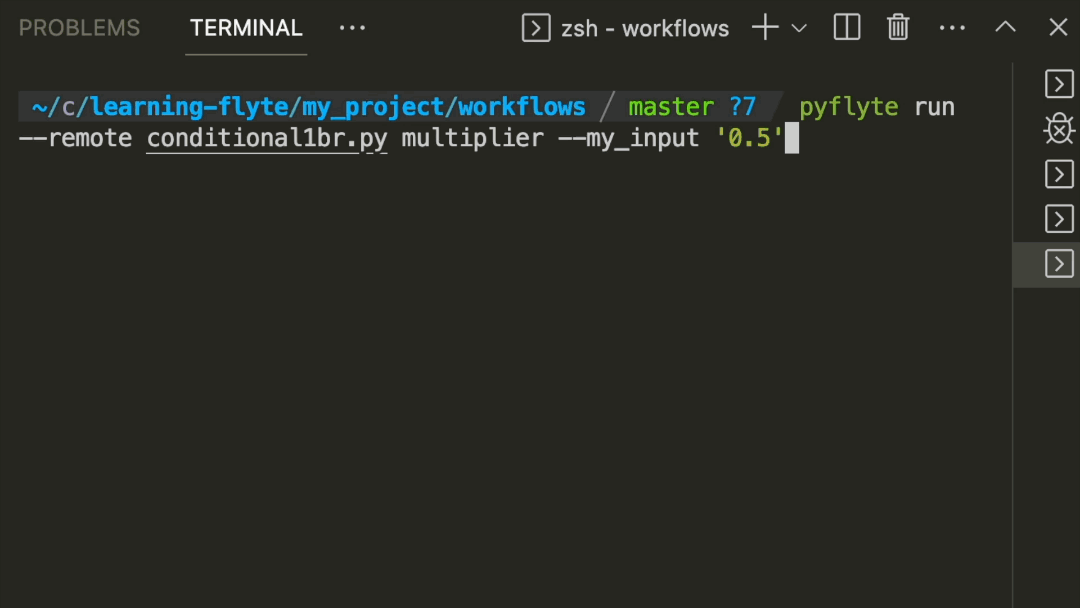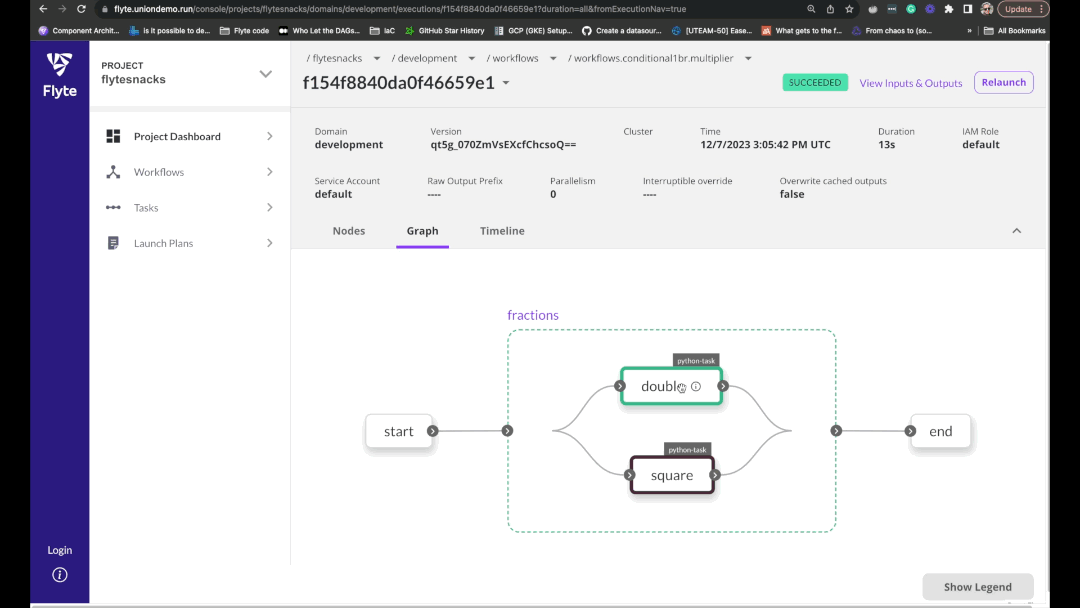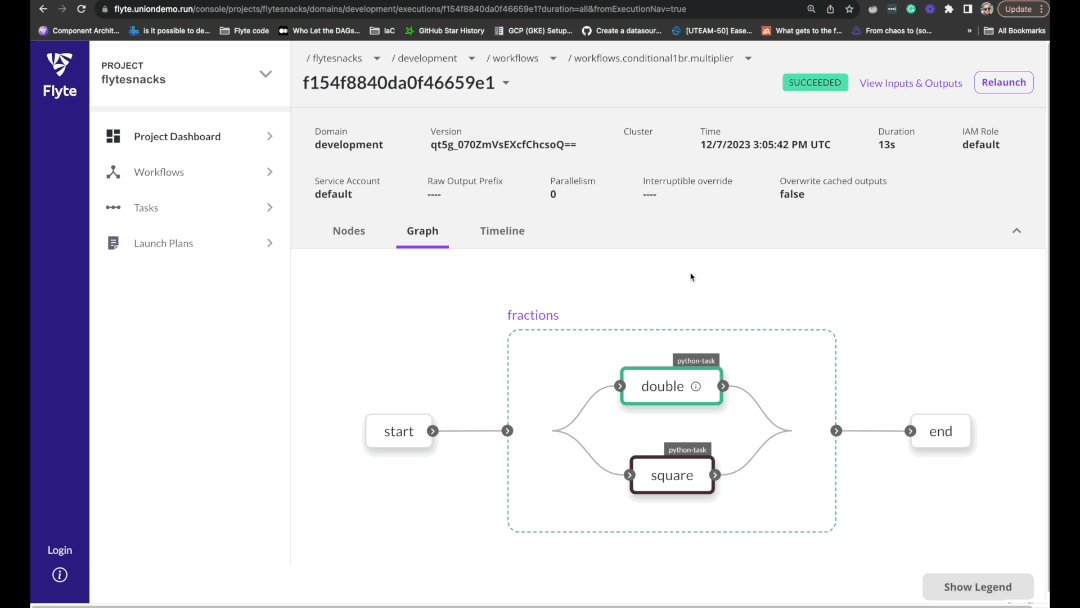
Flyte is an open-source orchestrator that facilitates building production-grade data and ML pipelines. It is built for scalability and reproducibility, leveraging Kubernetes as its underlying platform. With Flyte, user teams can construct pipelines using the Python SDK, and seamlessly deploy them on both cloud and on-premises environments, enabling distributed processing and efficient resource utilization.
README:

🏗️ 🚀 📈
Flyte is an open-source orchestrator that facilitates building production-grade data and ML pipelines. It is built for scalability and reproducibility, leveraging Kubernetes as its underlying platform. With Flyte, user teams can construct pipelines using the Python SDK, and seamlessly deploy them on both cloud and on-premises environments, enabling distributed processing and efficient resource utilization.
Write code in Python or any other language and leverage a robust type engine.
Either locally or on a remote cluster, execute your models with ease.
- Install Flyte's Python SDK
pip install flytekit- Create a workflow (see example)
- Run it locally with:
pyflyte run hello_world.py hello_world_wfReady to try a Flyte cluster?
- Create a new sandbox cluster, running as a Docker container:
flytectl demo start- Now execute your workflows on the cluster:
pyflyte run --remote hello_world.py hello_world_wf
Do you want to see more but don't want to install anything?
Try out the Union platform built on top of Flyte, and get free access to GPUs, data lineage, and more!
Ready to productionize?
Go to the Deployment guide for instructions to install Flyte on different environments
- Fine-tune Code Llama on the Flyte codebase
- Forecast sales with Horovod and Spark
- Nucleotide Sequence Querying with BLASTX
🚀 Strongly typed interfaces: Validate your data at every step of the workflow by defining data guardrails using Flyte types.
🌐 Any language: Write code in any language using raw containers, or choose Python, Java, Scala or JavaScript SDKs to develop your Flyte workflows.
🔒 Immutability: Immutable executions help ensure reproducibility by preventing any changes to the state of an execution.
🧬 Data lineage: Track the movement and transformation of data throughout the lifecycle of your data and ML workflows.
📊 Map tasks: Achieve parallel code execution with minimal configuration using map tasks.
🌎 Multi-tenancy: Multiple users can share the same platform while maintaining their own distinct data and configurations.
🌟 Dynamic workflows: Build flexible and adaptable workflows that can change and evolve as needed, making it easier to respond to changing requirements.
⏯️ Wait for external inputs before proceeding with the execution.
🌳 Branching: Selectively execute branches of your workflow based on static or dynamic data produced by other tasks or input data.
📈 Data visualization: Visualize data, monitor models and view training history through plots.
📂 FlyteFile & FlyteDirectory: Transfer files and directories between local and cloud storage.
🗃️ Structured dataset: Convert dataframes between types and enforce column-level type checking using the abstract 2D representation provided by Structured Dataset.
🛡️ Recover from failures: Recover only the failed tasks.
🔁 Rerun a single task: Rerun workflows at the most granular level without modifying the previous state of a data/ML workflow.
🔍 Cache outputs: Cache task outputs by passing cache=True to the task decorator.
🚩 Intra-task checkpointing: Checkpoint progress within a task execution.
⏰ Timeout: Define a timeout period, after which the task is marked as failure.
🏭 Dev to prod: As simple as changing your domain from development or staging to production.
💸 Spot or preemptible instances: Schedule your workflows on spot instances by setting interruptible to True in the task decorator.
☁️ Cloud-native deployment: Deploy Flyte on AWS, GCP, Azure and other cloud services.
📅 Scheduling: Schedule your data and ML workflows to run at a specific time.
📢 Notifications: Stay informed about changes to your workflow's state by configuring notifications through Slack, PagerDuty or email.
⌛️ Timeline view: Evaluate the duration of each of your Flyte tasks and identify potential bottlenecks.
💨 GPU acceleration: Enable and control your tasks’ GPU demands by requesting resources in the task decorator.
🐳 Dependency isolation via containers: Maintain separate sets of dependencies for your tasks so no dependency conflicts arise.
🔀 Parallelism: Flyte tasks are inherently parallel to optimize resource consumption and improve performance.
💾 Allocate resources dynamically at the task level.
Join the likes of LinkedIn, Spotify, Freenome, Pachama, Warner Bros. and many others in adopting Flyte for mission-critical use cases. For a full list of adopters and information on how to add your organization or project, please visit our ADOPTERS page.
👥 Monthly community sync: Happening the first Tuesday of every month, this is where the Flyte team provides updates on the project, and community members can share their progress and ask questions.
💬 Slack: Join the Flyte community on Slack to chat with other users, ask questions, and get help.
📹 Youtube: Tune into panel discussions, customer success stories, community updates and feature deep dives.
📄 Blog: Here, you can find tutorials and feature deep dives to help you learn more about Flyte.
💡 RFCs: RFCs are used for proposing new ideas and features to improve Flyte. You can refer to them to stay updated on the latest developments and contribute to the growth of the platform.
There are many ways to get involved in Flyte, including:
- Submitting bugs and feature requests for various components.
- Reviewing the documentation and submitting pull requests for anything from fixing typos to adding new content.
- Speaking or writing about Flyte or any other ecosystem integration and letting us know!
- Taking on a
help wantedorgood-first-issueand following the CONTRIBUTING guide to submit changes to the codebase. - Upvoting popular feature requests to show your support.




















































































































































































































































































































































































































































































































































































Flyte is available under the Apache License 2.0. Use it wisely.

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for flyte
Similar Open Source Tools
flyte
Flyte is an open-source orchestrator that facilitates building production-grade data and ML pipelines. It is built for scalability and reproducibility, leveraging Kubernetes as its underlying platform. With Flyte, user teams can construct pipelines using the Python SDK, and seamlessly deploy them on both cloud and on-premises environments, enabling distributed processing and efficient resource utilization.
ai-trend-publish
AI TrendPublish is an AI-based trend discovery and content publishing system that supports multi-source data collection, intelligent summarization, and automatic publishing to WeChat official accounts. It features data collection from various sources, AI-powered content processing using DeepseekAI Together, key information extraction, intelligent title generation, automatic article publishing to WeChat official accounts with custom templates and scheduled tasks, notification system integration with Bark for task status updates and error alerts. The tool offers multiple templates for content customization and is built using Node.js + TypeScript with AI services from DeepseekAI Together, data sources including Twitter/X API and FireCrawl, and uses node-cron for scheduling tasks and EJS as the template engine.
Hands-On-LLM-Applications-Development
Hands-On-LLM-Applications-Development is a repository focused on developing applications using Large Language Models (LLMs). The repository provides hands-on tutorials, guides, and resources for building various applications such as LangChain for LLM applications, Retrieval Augmented Generation (RAG) with LangChain, building LLM agents with LangGraph, and advanced LangChain with OpenAI. It covers topics like prompt engineering for LLMs, building applications using HuggingFace open-source models, LLM fine-tuning, and advanced RAG applications.
goodsKill
The 'goodsKill' project aims to build a complete project framework integrating good technologies and development techniques, mainly focusing on backend technologies. It provides a simulated flash sale project with unified flash sale simulation request interface. The project uses SpringMVC + Mybatis for the overall technology stack, Dubbo3.x for service intercommunication, Nacos for service registration and discovery, and Spring State Machine for data state transitions. It also integrates Spring AI service for simulating flash sale actions.
TechFlow
TechFlow is a platform that allows users to build their own AI workflows through drag-and-drop functionality. It features a visually appealing interface with clear layout and intuitive navigation. TechFlow supports multiple models beyond Language Models (LLM) and offers flexible integration capabilities. It provides a powerful SDK for developers to easily integrate generated workflows into existing systems, enhancing flexibility and scalability. The platform aims to embed AI capabilities as modules into existing functionalities to enhance business competitiveness.
HuaTuoAI
HuaTuoAI is an artificial intelligence image classification system specifically designed for traditional Chinese medicine. It utilizes deep learning techniques, such as Convolutional Neural Networks (CNN), to accurately classify Chinese herbs and ingredients based on input images. The project aims to unlock the secrets of plants, depict the unknown realm of Chinese medicine using technology and intelligence, and perpetuate ancient cultural heritage.
unity-AI-Chat-Toolkit
The Unity-AI-Chat-Toolkit is a toolset for Unity developers to quickly implement AI chat-related functions. Currently, this library includes code implementations for API calls to large language models such as ChatGPT, RKV, and ChatGLM, as well as web API access to Microsoft Azure and Baidu AI for speech synthesis and speech recognition. With this library, we can quickly implement cross-platform applications on Unity.
Awesome-LLMOps
Awesome-LLMOps is a curated list of the best LLMOps tools, providing a comprehensive collection of frameworks and tools for building, deploying, and managing large language models (LLMs) and AI agents. The repository includes a wide range of tools for tasks such as building multimodal AI agents, fine-tuning models, orchestrating applications, evaluating models, and serving models for inference. It covers various aspects of the machine learning operations (MLOps) lifecycle, from training to deployment and observability. The tools listed in this repository cater to the needs of developers, data scientists, and machine learning engineers working with large language models and AI applications.
Thor
Thor is a powerful AI model management tool designed for unified management and usage of various AI models. It offers features such as user, channel, and token management, data statistics preview, log viewing, system settings, external chat link integration, and Alipay account balance purchase. Thor supports multiple AI models including OpenAI, Kimi, Starfire, Claudia, Zhilu AI, Ollama, Tongyi Qianwen, AzureOpenAI, and Tencent Hybrid models. It also supports various databases like SqlServer, PostgreSql, Sqlite, and MySql, allowing users to choose the appropriate database based on their needs.
KouriChat
KouriChat is a project that seamlessly integrates virtual and real interactions, providing eternal gentle bonds. It offers features like WeChat integration, immersive role-playing, intelligent conversation segmentation, emotion-based emojis, image generation, image recognition, voice messages, and more. The project is focused on technical research and learning exchanges, with a strong emphasis on ethical and legal guidelines. Users are required to take full responsibility for their actions, especially minors who should use the tool under supervision. The project architecture includes avatar configurations, data storage, handlers, AI service interfaces, a web UI, and utility libraries.
Awesome-Segment-Anything
The Segment Anything Model (SAM) is a powerful tool that allows users to segment any object in an image with just a few clicks. This makes it a great tool for a variety of tasks, such as object detection, tracking, and editing. SAM is also very easy to use, making it a great option for both beginners and experienced users.
XianTu
XianTu is an AI-driven immersive cultivation text adventure game that features dynamic storytelling with multiple large models, a complete cultivation system including realm breakthroughs, cultivation of techniques, equipment refining, and NPC interactions, intelligent decision-making system based on multiple dimensions, multiple save file management with cloud sync support, open world exploration with character relationship networks, cross-platform compatibility with dual themes, and compatibility with SillyTavern embedded environment and standalone web version.
ophel
Ophel Atlas is a tool that transforms AI conversations into readable, navigable, and reusable documents. It organizes conversations into a structured workflow, allowing users to easily navigate and reuse valuable insights. It offers features such as intelligent outlining, conversation management, prompt libraries, theme customization, interface optimization, reading experience enhancements, efficiency tools, and privacy-focused data storage. Ophel Atlas is designed for various use cases including learning and research, daily work tasks, development and technical writing, content creation, and frequent AI users seeking structured and reusable capabilities.
ddddocr
ddddocr is a Rust version of a simple OCR API server that provides easy deployment for captcha recognition without relying on the OpenCV library. It offers a user-friendly general-purpose captcha recognition Rust library. The tool supports recognizing various types of captchas, including single-line text, transparent black PNG images, target detection, and slider matching algorithms. Users can also import custom OCR training models and utilize the OCR API server for flexible OCR result control and range limitation. The tool is cross-platform and can be easily deployed.

FlagPerf
FlagPerf is an integrated AI hardware evaluation engine jointly built by the Institute of Intelligence and AI hardware manufacturers. It aims to establish an industry-oriented metric system to evaluate the actual capabilities of AI hardware under software stack combinations (model + framework + compiler). FlagPerf features a multidimensional evaluation metric system that goes beyond just measuring 'whether the chip can support specific model training.' It covers various scenarios and tasks, including computer vision, natural language processing, speech, multimodal, with support for multiple training frameworks and inference engines to connect AI hardware with software ecosystems. It also supports various testing environments to comprehensively assess the performance of domestic AI chips in different scenarios.
Chenyme-AAVT
Chenyme-AAVT is a user-friendly tool that provides automatic video and audio recognition and translation. It leverages the capabilities of Whisper, a powerful speech recognition model, to accurately identify speech in videos and audios. The recognized speech is then translated using ChatGPT or KIMI, ensuring high-quality translations. With Chenyme-AAVT, you can quickly generate字幕 files and merge them with the original video, making video translation a breeze. The tool supports various languages, allowing you to translate videos and audios into your desired language. Additionally, Chenyme-AAVT offers features such as VAD (Voice Activity Detection) to enhance recognition accuracy, GPU acceleration for faster processing, and support for multiple字幕 formats. Whether you're a content creator, translator, or anyone looking to make video translation more efficient, Chenyme-AAVT is an invaluable tool.
For similar tasks
flyte
Flyte is an open-source orchestrator that facilitates building production-grade data and ML pipelines. It is built for scalability and reproducibility, leveraging Kubernetes as its underlying platform. With Flyte, user teams can construct pipelines using the Python SDK, and seamlessly deploy them on both cloud and on-premises environments, enabling distributed processing and efficient resource utilization.

project_alice
Alice is an agentic workflow framework that integrates task execution and intelligent chat capabilities. It provides a flexible environment for creating, managing, and deploying AI agents for various purposes, leveraging a microservices architecture with MongoDB for data persistence. The framework consists of components like APIs, agents, tasks, and chats that interact to produce outputs through files, messages, task results, and URL references. Users can create, test, and deploy agentic solutions in a human-language framework, making it easy to engage with by both users and agents. The tool offers an open-source option, user management, flexible model deployment, and programmatic access to tasks and chats.
trigger.dev
Trigger.dev is an open source platform and SDK for creating long-running background jobs. It provides features like JavaScript and TypeScript SDK, no timeouts, retries, queues, schedules, observability, React hooks, Realtime API, custom alerts, elastic scaling, and works with existing tech stack. Users can create tasks in their codebase, deploy tasks using the SDK, manage tasks in different environments, and have full visibility of job runs. The platform offers a trace view of every task run for detailed monitoring. Getting started is easy with account creation, project setup, and onboarding instructions. Self-hosting and development guides are available for users interested in contributing or hosting Trigger.dev.
MeeseeksAI
MeeseeksAI is a framework designed to orchestrate AI agents using a mermaid graph and networkx. It provides a structured approach to managing and coordinating multiple AI agents within a system. The framework allows users to define the interactions and dependencies between agents through a visual representation, making it easier to understand and modify the behavior of the AI system. By leveraging the power of networkx, MeeseeksAI enables efficient graph-based computations and optimizations, enhancing the overall performance of AI workflows. With its intuitive design and flexible architecture, MeeseeksAI simplifies the process of building and deploying complex AI systems, empowering users to create sophisticated agent interactions with ease.
For similar jobs
flyte
Flyte is an open-source orchestrator that facilitates building production-grade data and ML pipelines. It is built for scalability and reproducibility, leveraging Kubernetes as its underlying platform. With Flyte, user teams can construct pipelines using the Python SDK, and seamlessly deploy them on both cloud and on-premises environments, enabling distributed processing and efficient resource utilization.