Best AI tools for< Server >
Infographic
20 - AI tool Sites
OpenResty Server Manager
The website seems to be experiencing a 403 Forbidden error, which typically indicates that the server is denying access to the requested resource. This error is often caused by incorrect permissions or misconfigurations on the server side. The message 'openresty' suggests that the server may be using the OpenResty web platform. Users encountering this error may need to contact the website administrator for assistance in resolving the issue.

Internal Server Error
The website encountered an internal server error, resulting in a 500 Internal Server Error message. This error indicates that the server faced an issue preventing it from fulfilling the request. Possible causes include server overload or errors within the application.

Web Server Error Resolver
The website is currently displaying a '403 Forbidden' error, which indicates that the server is refusing to respond to the request. This error message is typically displayed when the server understands the request made by the client but refuses to fulfill it. The 'openresty' mentioned in the text is likely the web server software being used. It is important to troubleshoot and resolve the 403 Forbidden error to regain access to the website's content.
Server Error Handler
The website encountered a server error, preventing it from fulfilling the user's request. The error message indicates a temporary issue that may be resolved by trying again after 30 seconds.
OpenResty Server
The website is currently displaying a '403 Forbidden' error, which indicates that the server understood the request but refuses to authorize it. This error is typically caused by insufficient permissions or misconfiguration on the server side. The 'openresty' message suggests that the server is using the OpenResty web platform, which is based on NGINX and Lua programming language. Users encountering this error may need to contact the website administrator for assistance in resolving the issue.

Server Error Analyzer
The website is experiencing a 500 Internal Server Error, which indicates a problem with the server hosting the website. This error message is generated by the server when it is unable to fulfill a request from a client. The OpenResty software may be involved in the server configuration. Users encountering this error should contact the website administrator for assistance in resolving the issue.

Server Error Handler
The website encountered a server error and could not complete the request. Users are advised to try again in 30 seconds. The error message indicates a temporary issue with the server's functionality.
Server Error Analyzer
The website encountered a server error, preventing it from fulfilling the user's request. The error message indicates a 500 Server Error, suggesting an issue on the server-side that is preventing the completion of the request. Users are advised to wait for 30 seconds and try again. This error message typically occurs when there is a problem with the server configuration or processing of the request.
503 Server Error
The website is currently experiencing a 503 Server Error, indicating that the service requested is unavailable at the moment. Users encountering this error are advised to try again in 30 seconds. The website may be undergoing maintenance or experiencing technical difficulties, leading to the temporary unavailability of the service.
LiteSpeed Web Server
The website is powered by LiteSpeed Web Server, which is not a web hosting company. It serves as a platform that handles web server operations efficiently. LiteSpeed Technologies Inc. does not have control over the content found on the site.

Amazon Bedrock
Amazon Bedrock is a cloud-based platform that enables developers to build, deploy, and manage serverless applications. It provides a fully managed environment that takes care of the infrastructure and operations, so developers can focus on writing code. Bedrock also offers a variety of tools and services to help developers build and deploy their applications, including a code editor, a debugger, and a deployment pipeline.
Koxy AI
Koxy AI is an AI-powered serverless back-end platform that allows users to build globally distributed, fast, secure, and scalable back-ends with no code required. It offers features such as live logs, smart errors handling, integration with over 80,000 AI models, and more. Koxy AI is designed to help users focus on building the best service possible without wasting time on security and latency concerns. It provides a No-SQL JSON-based database, real-time data synchronization, cloud functions, and a drag-and-drop builder for API flows.
Kenton Creators
Kenton Creators is an AI-powered platform that offers a seamless experience for building Discord servers. With effortless setup and instant results, users can customize and launch their servers instantly. The platform caters to various communities such as gamers, music lovers, tech enthusiasts, artists, business owners, anime fans, fitness enthusiasts, foodies, and travel enthusiasts. Kenton Creators provides a user-friendly interface with a wide range of themes and customization options, making server creation quick and easy.

OpenResty
The website is currently displaying a '403 Forbidden' error, which indicates that the server understood the request but refuses to authorize it. This error is often encountered when trying to access a webpage without the necessary permissions. The 'openresty' mentioned in the text is likely the software running on the server. It is a web platform based on NGINX and LuaJIT, known for its high performance and scalability in handling web traffic. The website may be using OpenResty to manage its server configurations and handle incoming requests.
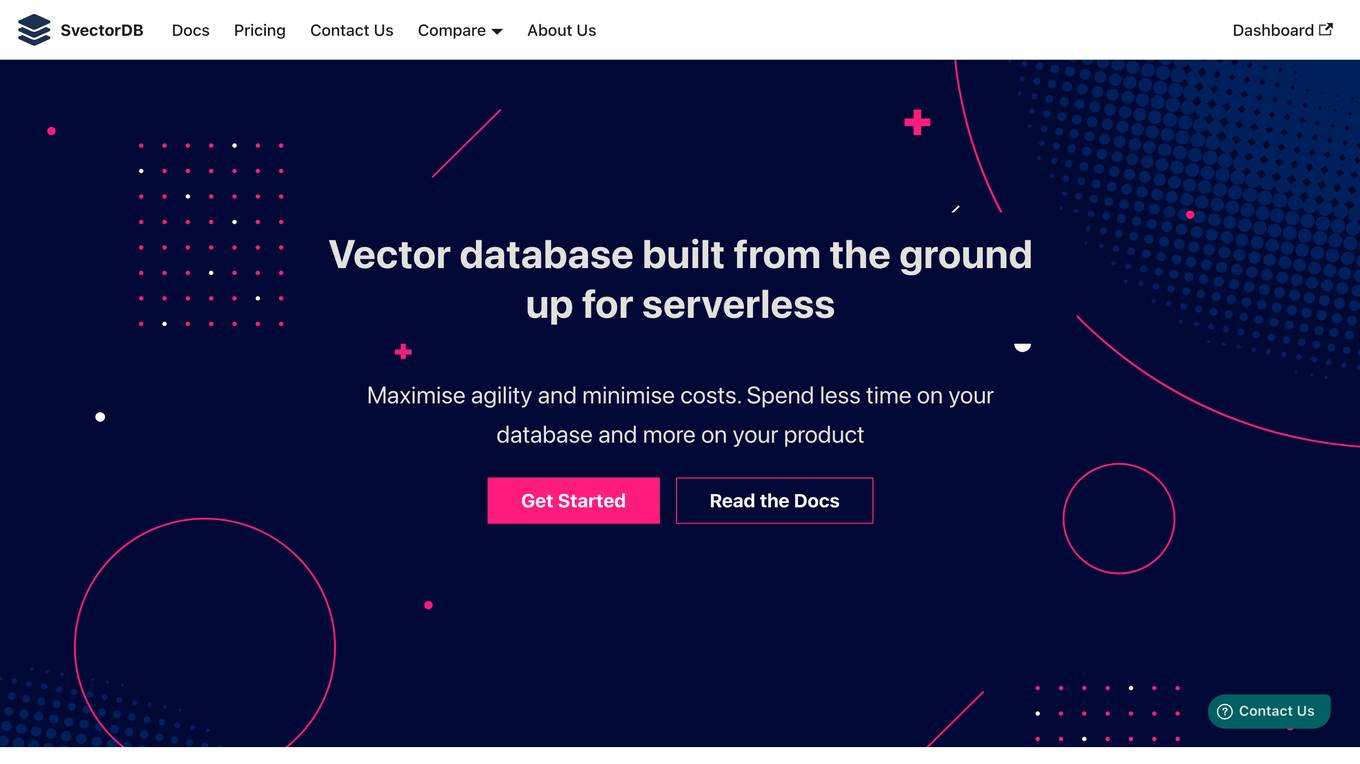
SvectorDB
SvectorDB is a vector database built from the ground up for serverless applications. It is designed to be highly scalable, performant, and easy to use. SvectorDB can be used for a variety of applications, including recommendation engines, document search, and image search.

Belva
Belva is an AI-powered phone-calling assistant that can make calls on your behalf. With Belva, you can simply state your objective and the AI will make the call for you, providing you with a live transcription of the conversation. Belva's envoys can handle a variety of tasks, from making appointments and reservations to solving customer issues. You can monitor your active calls in real-time or review saved transcripts to collect information from the call. With Belva, you can get off the phone and let the AI do the talking, saving you time and hassle.
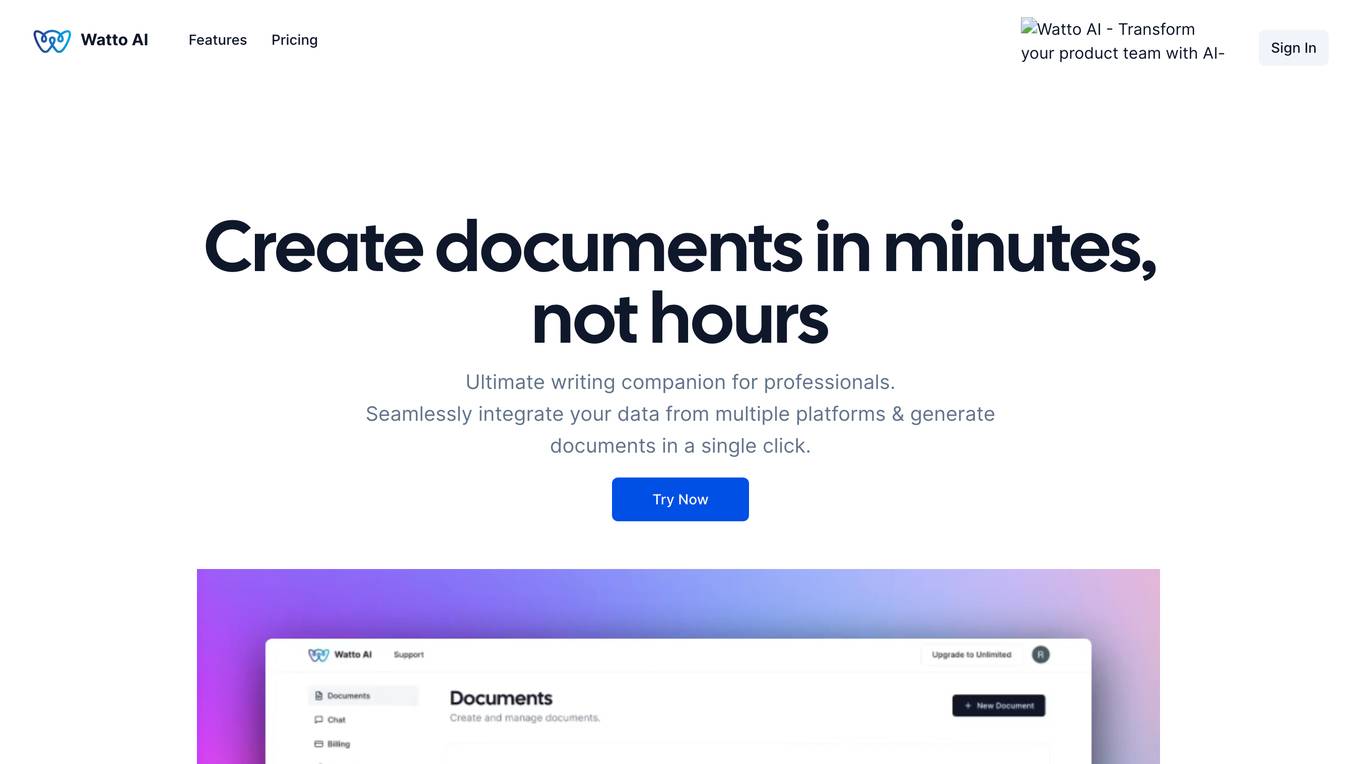
Watto AI
Watto AI is a platform that offers Conversational AI solutions to businesses, allowing them to build AI voice agents without the need for coding. The platform enables users to collect leads, automate customer support, and facilitate natural interactions through AI voice bots. Watto AI caters to various industries and scenarios, providing human-like conversational AI for mystery shopping, top-quality customer support, and restaurant assistance.
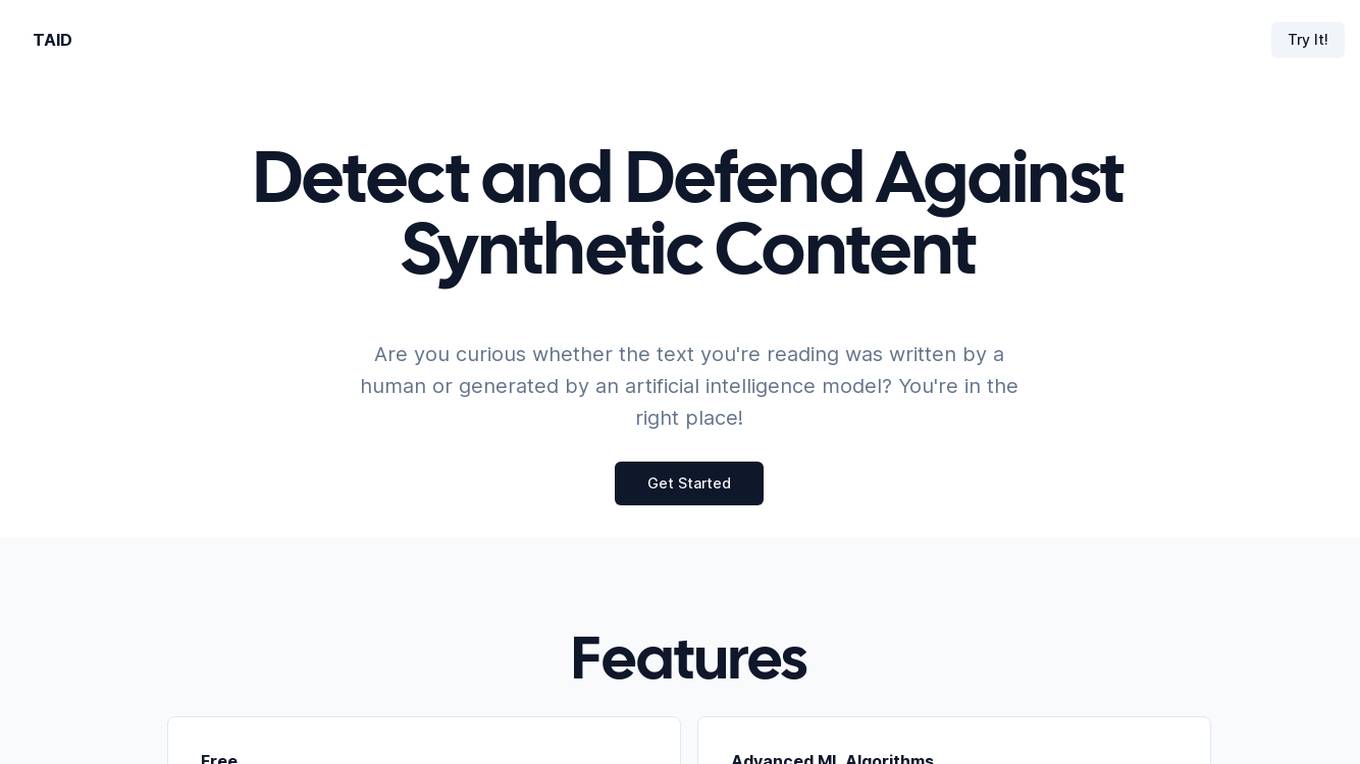
TAID
TAID is a cutting-edge AI tool that specializes in analyzing text to determine whether it was created by a human or generated by artificial intelligence models like ChatGPT. It helps users combat misinformation, ensure transparency, and maintain trust in online communication by verifying the authenticity of the text they encounter. TAID utilizes advanced machine learning algorithms to achieve impressive accuracy in detecting AI-generated content, offering a free detection service with unlimited usage and no hidden fees or subscriptions.
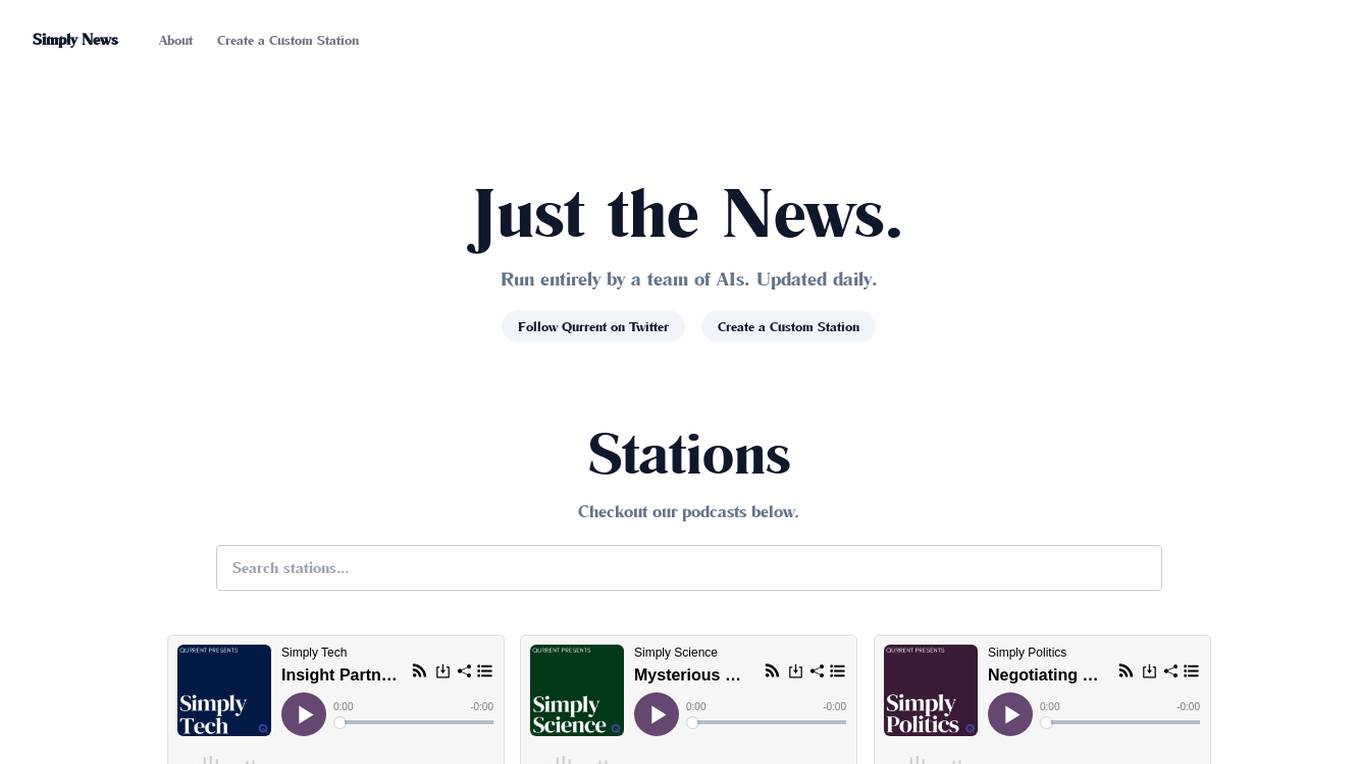
Qurrent
Qurrent is an AI-powered news platform that offers a custom station menu with news curated and translated by a team of AI news agents. It covers a wide range of topics including technology, science, politics, economics, artificial intelligence, product hunt, people, sports, space, commercial real estate, finance, cryptocurrency, Mars updates, and startups. The platform provides daily updates and aims to keep users informed with the latest news and trends from around the world.
404 Error Assistant
The website displays a 404 error message indicating that the deployment cannot be found. It provides a code (DEPLOYMENT_NOT_FOUND) and an ID (sfo1::vd75v-1770832320154-3c2268e79b55) for reference. Users are directed to consult the documentation for further information and troubleshooting.
0 - Open Source Tools
13 - OpenAI Gpts
Restaurant Startup Guide
Meet the Restaurant Startup Guide GPT: your friendly guide in the restaurant biz. It offers casual, approachable advice to help you start and run your own restaurant with ease.



Tavern
Tavern is a fantasy styled GPT tailored to make your fantasy snacks and drinks a reality.


Baci's AI Server
An AI waiter for Baci Bistro & Bar, knowledgeable about the menu and ready to assist.

TipCheck Calculator Pro
Effortlessly calculate your tip and total bill with TipCheck Calculator Pro. Simply scan your restaurant or bar receipt, and get instant suggested tip amounts with an accurate breakdown of your total payment. No more guesswork.
中世界酒吧 - 米拉
Mira the Bartender, fluent in Cantonese and English, knows drinks and local gossip.