AI tools for yank
Related Tools:
Song Parody Generator
🎶 generate song parodies for 🎤 karaoke night, 👰🤵 wedding toasts, 💸 retirement send-offs, or 🎺 riff like Weird Al Yankovic! brought to you by 🐙 jambubble.com and ⛵ sloop.ai
yn
Yank Note is a highly extensible Markdown editor designed for productivity. It offers features like easy-to-use interface, powerful support for version control and various embedded content, high compatibility with local Markdown files, plug-in extension support, and encryption for saving private files. Users can write their own plug-ins to expand the editor's functionality. However, for more extendability, security protection is sacrificed. The tool supports sync scrolling, outline navigation, version control, encryption, auto-save, editing assistance, image pasting, attachment embedding, code running, to-do list management, quick file opening, integrated terminal, Katex expression, GitHub-style Markdown, multiple data locations, external link conversion, HTML resolving, multiple formats export, TOC generation, table cell editing, title link copying, embedded applets, various graphics embedding, mind map display, custom container support, macro replacement, image hosting service, OpenAI auto completion, and custom plug-ins development.

llama.vim
llama.vim is a plugin that provides local LLM-assisted text completion for Vim users. It offers features such as auto-suggest on cursor movement, manual suggestion toggling, suggestion acceptance with Tab and Shift+Tab, control over text generation time, context configuration, ring context with chunks from open and edited files, and performance stats display. The plugin requires a llama.cpp server instance to be running and supports FIM-compatible models. It aims to be simple, lightweight, and provide high-quality and performant local FIM completions even on consumer-grade hardware.
llama.vscode
llama.vscode is a local LLM-assisted text completion extension for Visual Studio Code. It provides auto-suggestions on input, allows accepting suggestions with shortcuts, and offers various features to enhance text completion. The extension is designed to be lightweight and efficient, enabling high-quality completions even on low-end hardware. Users can configure the scope of context around the cursor and control text generation time. It supports very large contexts and displays performance statistics for better user experience.
shellgpt
ShellGPT is a tool that allows users to chat with a large language model (LLM) in the terminal. It can be used for various purposes such as generating shell commands, telling stories, and interacting with Linux terminal. The tool provides different modes of usage including direct mode for asking questions, REPL mode for chatting with LLM, and TUI mode tailored for inferring shell commands. Users can customize the tool by setting up different language model backends such as Ollama or using OpenAI compatible API endpoints. Additionally, ShellGPT comes with built-in system contents for general questions, correcting typos, generating URL slugs, programming questions, shell command inference, and git commit message generation. Users can define their own content or share customized contents in the discuss section.
LLMAgentPapers
LLM Agents Papers is a repository containing must-read papers on Large Language Model Agents. It covers a wide range of topics related to language model agents, including interactive natural language processing, large language model-based autonomous agents, personality traits in large language models, memory enhancements, planning capabilities, tool use, multi-agent communication, and more. The repository also provides resources such as benchmarks, types of tools, and a tool list for building and evaluating language model agents. Contributors are encouraged to add important works to the repository.

HackBot
HackBot is an AI-powered cybersecurity chatbot designed to provide accurate answers to cybersecurity-related queries, conduct code analysis, and scan analysis. It utilizes the Meta-LLama2 AI model through the 'LlamaCpp' library to respond coherently. The chatbot offers features like local AI/Runpod deployment support, cybersecurity chat assistance, interactive interface, clear output presentation, static code analysis, and vulnerability analysis. Users can interact with HackBot through a command-line interface and utilize it for various cybersecurity tasks.
tenere
Tenere is a TUI interface for Language Model Libraries (LLMs) written in Rust. It provides syntax highlighting, chat history, saving chats to files, Vim keybindings, copying text from/to clipboard, and supports multiple backends. Users can configure Tenere using a TOML configuration file, set key bindings, and use different LLMs such as ChatGPT, llama.cpp, and ollama. Tenere offers default key bindings for global and prompt modes, with features like starting a new chat, saving chats, scrolling, showing chat history, and quitting the app. Users can interact with the prompt in different modes like Normal, Visual, and Insert, with various key bindings for navigation, editing, and text manipulation.
ogpt.nvim
OGPT.nvim is a Neovim plugin that enables users to interact with various language models (LLMs) such as Ollama, OpenAI, TextGenUI, and more. Users can engage in interactive question-and-answer sessions, have persona-based conversations, and execute customizable actions like grammar correction, translation, keyword generation, docstring creation, test addition, code optimization, summarization, bug fixing, code explanation, and code readability analysis. The plugin allows users to define custom actions using a JSON file or plugin configurations.


Awesome-LLM-Reasoning
**Curated collection of papers and resources on how to unlock the reasoning ability of LLMs and MLLMs.** **Description in less than 400 words, no line breaks and quotation marks.** Large Language Models (LLMs) have revolutionized the NLP landscape, showing improved performance and sample efficiency over smaller models. However, increasing model size alone has not proved sufficient for high performance on challenging reasoning tasks, such as solving arithmetic or commonsense problems. This curated collection of papers and resources presents the latest advancements in unlocking the reasoning abilities of LLMs and Multimodal LLMs (MLLMs). It covers various techniques, benchmarks, and applications, providing a comprehensive overview of the field. **5 jobs suitable for this tool, in lowercase letters.** - content writer - researcher - data analyst - software engineer - product manager **Keywords of the tool, in lowercase letters.** - llm - reasoning - multimodal - chain-of-thought - prompt engineering **5 specific tasks user can use this tool to do, in less than 3 words, Verb + noun form, in daily spoken language.** - write a story - answer a question - translate a language - generate code - summarize a document
InfLLM
InfLLM is a training-free memory-based method that unveils the intrinsic ability of LLMs to process streaming long sequences. It stores distant contexts into additional memory units and employs an efficient mechanism to lookup token-relevant units for attention computation. Thereby, InfLLM allows LLMs to efficiently process long sequences while maintaining the ability to capture long-distance dependencies. Without any training, InfLLM enables LLMs pre-trained on sequences of a few thousand tokens to achieve superior performance than competitive baselines continually training these LLMs on long sequences. Even when the sequence length is scaled to 1, 024K, InfLLM still effectively captures long-distance dependencies.
Awesome-LLM-Long-Context-Modeling
This repository includes papers and blogs about Efficient Transformers, Length Extrapolation, Long Term Memory, Retrieval Augmented Generation(RAG), and Evaluation for Long Context Modeling.

LLM-Agent-Survey
Autonomous agents are designed to achieve specific objectives through self-guided instructions. With the emergence and growth of large language models (LLMs), there is a growing trend in utilizing LLMs as fundamental controllers for these autonomous agents. This repository conducts a comprehensive survey study on the construction, application, and evaluation of LLM-based autonomous agents. It explores essential components of AI agents, application domains in natural sciences, social sciences, and engineering, and evaluation strategies. The survey aims to be a resource for researchers and practitioners in this rapidly evolving field.
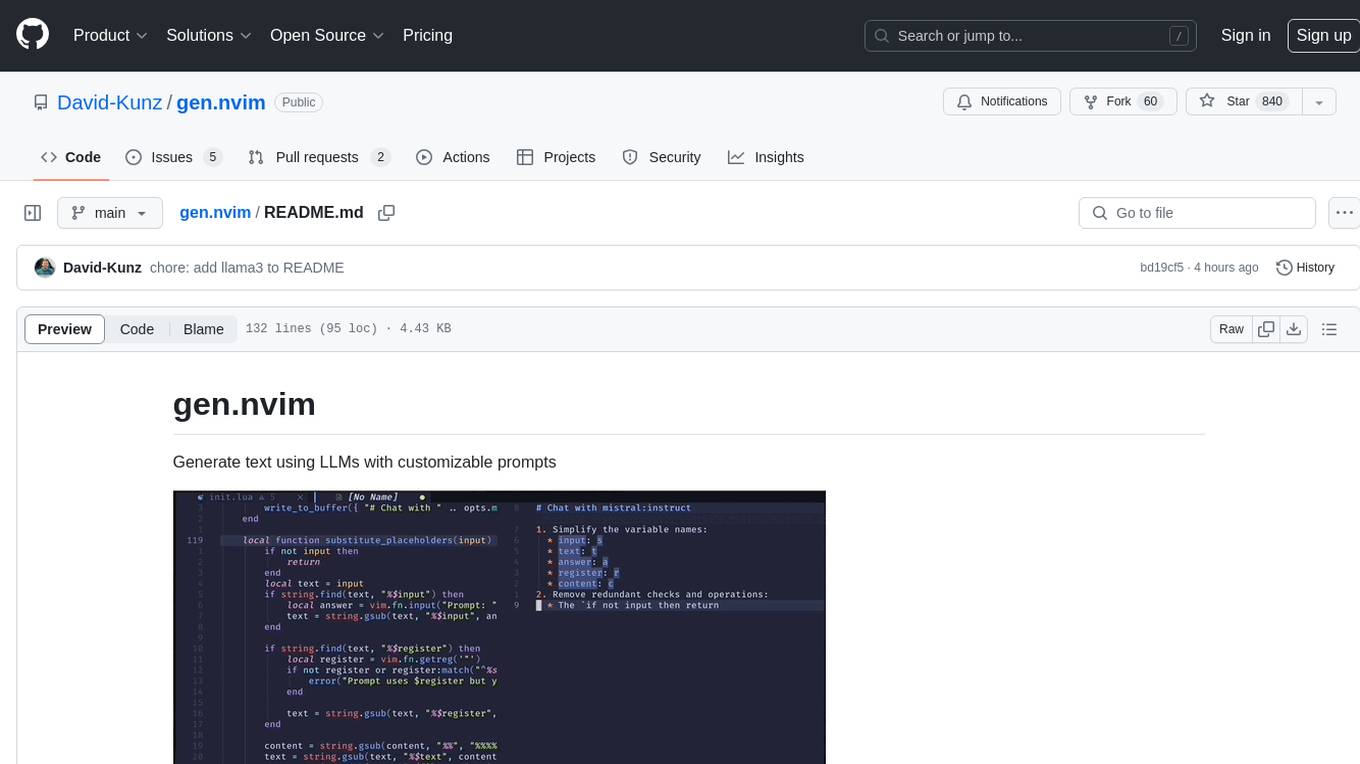
gen.nvim
gen.nvim is a tool that allows users to generate text using Language Models (LLMs) with customizable prompts. It requires Ollama with models like `llama3`, `mistral`, or `zephyr`, along with Curl for installation. Users can use the `Gen` command to generate text based on predefined or custom prompts. The tool provides key maps for easy invocation and allows for follow-up questions during conversations. Additionally, users can select a model from a list of installed models and customize prompts as needed.

MiniCPM-V
MiniCPM-V is a series of end-side multimodal LLMs designed for vision-language understanding. The models take image and text inputs to provide high-quality text outputs. The series includes models like MiniCPM-Llama3-V 2.5 with 8B parameters surpassing proprietary models, and MiniCPM-V 2.0, a lighter model with 2B parameters. The models support over 30 languages, efficient deployment on end-side devices, and have strong OCR capabilities. They achieve state-of-the-art performance on various benchmarks and prevent hallucinations in text generation. The models can process high-resolution images efficiently and support multilingual capabilities.

Awesome-LLM-Watermark
This repository contains a collection of research papers related to watermarking techniques for text and images, specifically focusing on large language models (LLMs). The papers cover various aspects of watermarking LLM-generated content, including robustness, statistical understanding, topic-based watermarks, quality-detection trade-offs, dual watermarks, watermark collision, and more. Researchers have explored different methods and frameworks for watermarking LLMs to protect intellectual property, detect machine-generated text, improve generation quality, and evaluate watermarking techniques. The repository serves as a valuable resource for those interested in the field of watermarking for LLMs.
Prompt4ReasoningPapers
Prompt4ReasoningPapers is a repository dedicated to reasoning with language model prompting. It provides a comprehensive survey of cutting-edge research on reasoning abilities with language models. The repository includes papers, methods, analysis, resources, and tools related to reasoning tasks. It aims to support various real-world applications such as medical diagnosis, negotiation, etc.

RepoAgent
RepoAgent is an LLM-powered framework designed for repository-level code documentation generation. It automates the process of detecting changes in Git repositories, analyzing code structure through AST, identifying inter-object relationships, replacing Markdown content, and executing multi-threaded operations. The tool aims to assist developers in understanding and maintaining codebases by providing comprehensive documentation, ultimately improving efficiency and saving time.

Awesome-LLM-Preference-Learning
The repository 'Awesome-LLM-Preference-Learning' is the official repository of a survey paper titled 'Towards a Unified View of Preference Learning for Large Language Models: A Survey'. It contains a curated list of papers related to preference learning for Large Language Models (LLMs). The repository covers various aspects of preference learning, including on-policy and off-policy methods, feedback mechanisms, reward models, algorithms, evaluation techniques, and more. The papers included in the repository explore different approaches to aligning LLMs with human preferences, improving mathematical reasoning in LLMs, enhancing code generation, and optimizing language model performance.