AI tools for ocr
Related Jobs:
Related Tools:
Ocrolus
Ocrolus is an intelligent document automation software that leverages AI-driven document processing automation with Human-in-the-Loop. It offers capabilities such as classifying, capturing, detecting, and analyzing documents, with use cases in cash flow, income, address, employment, and identity verification. Ocrolus caters to various industries like small business lending, mortgage, consumer finance, and multifamily housing. The platform provides resources for developers, including guides on income verification, fraud detection, and business process automation. Users can explore the API to build innovative customer experiences and make faster and more accurate financial decisions.
Receipt OCR API
Receipt OCR API by ReceiptUp is an advanced tool that leverages OCR and AI technology to extract structured data from receipt and invoice images. The API offers high accuracy and multilingual support, making it ideal for businesses worldwide to streamline financial operations. With features like multilingual support, high accuracy, support for multiple formats, accounting downloads, and affordability, Receipt OCR API is a powerful tool for efficient receipt management and data extraction.
GrabText
GrabText is an online OCR tool that allows users to convert handwritten or printed text from photos, graphics, or documents into editable text. It uses ChatGPT to automatically correct spelling, grammar, and other illegal writings. The tool also supports math equations and offers flexible output options such as txt, latex, doc, and pdf.
Picture to Text Converter
Picture to Text Converter is an online tool that uses Optical Character Recognition (OCR) technology to extract text from images. It can process various image formats like JPG, PNG, GIF, scanned documents (PDFs), and even photos taken with your phone's camera. The extracted text can be copied to the clipboard or downloaded as a TXT file. Picture to Text Converter is free to use and does not require any registration or installation. It is a convenient and efficient way to convert images into editable text.

Veryfi
Veryfi is an OCR API tool for invoice and receipt data extraction. It offers fast, accurate, and secure document capture and data extraction on any type of document. Veryfi empowers users to process documents efficiently, automate manual data entry, and implement AI into various business processes. The tool is designed to streamline workflows, enhance accuracy, and unlock new levels of efficiency across industries such as finance, insurance, and more.

Doc2cart
Doc2cart is an AI-powered platform that automates the extraction of product information from various documents such as invoices, price lists, and catalogs. It utilizes advanced OCR technology to convert paper or digital documents into structured e-commerce data that can be seamlessly integrated into popular e-commerce platforms and shopping carts. The platform focuses on data extraction and processing, providing users with the flexibility to utilize the extracted data in their systems efficiently.
Koncile
Koncile is an AI-powered OCR solution that automates data extraction from various documents. It combines advanced OCR technology with large language models to transform unstructured data into structured information. Koncile can extract data from invoices, accounting documents, identity documents, and more, offering features like categorization, enrichment, and database integration. The tool is designed to streamline document management processes and accelerate data processing. Koncile is suitable for businesses of all sizes, providing flexible subscription plans and enterprise solutions tailored to specific needs.
Base64.ai
Base64.ai is an AI-powered document intelligence platform that offers a comprehensive solution for document processing and data extraction. It leverages advanced AI technology to automate business decisions, improve efficiency, accuracy, and digital transformation. Base64.ai provides features such as GenAI models, Semantic AI, Custom Model Builder, Question & Answer capabilities, and Large Action Models to streamline document processing. The platform supports over 50 file formats and offers integrations with scanners, RPA platforms, and third-party software.
InvoiceClip
InvoiceClip is an AI-powered application designed to streamline the process of managing invoices and receipts. It utilizes advanced artificial intelligence algorithms to accurately scan and extract information from invoices and receipts, eliminating the need for manual data entry. With InvoiceClip, users can easily organize and store their financial documents, track expenses, and generate reports with just a few clicks. The application offers a user-friendly interface and robust features to simplify the invoicing process for individuals and businesses alike.
AI Manga Translate
AI Manga Translate is an AI-powered manga translation tool that offers fast, accurate, and multilingual OCR services. It allows users to understand the original manga content in seconds and translates it into various languages while preserving context and layout. The tool supports over 50 languages with a high translation accuracy rate. Users can upload images or PDFs, choose the target language and model, and review/download the translated content easily. AI Manga Translate provides a full-stack AIGC solution for manga translation, combining offline and cloud language models to ensure high-fidelity output and controllable layout.
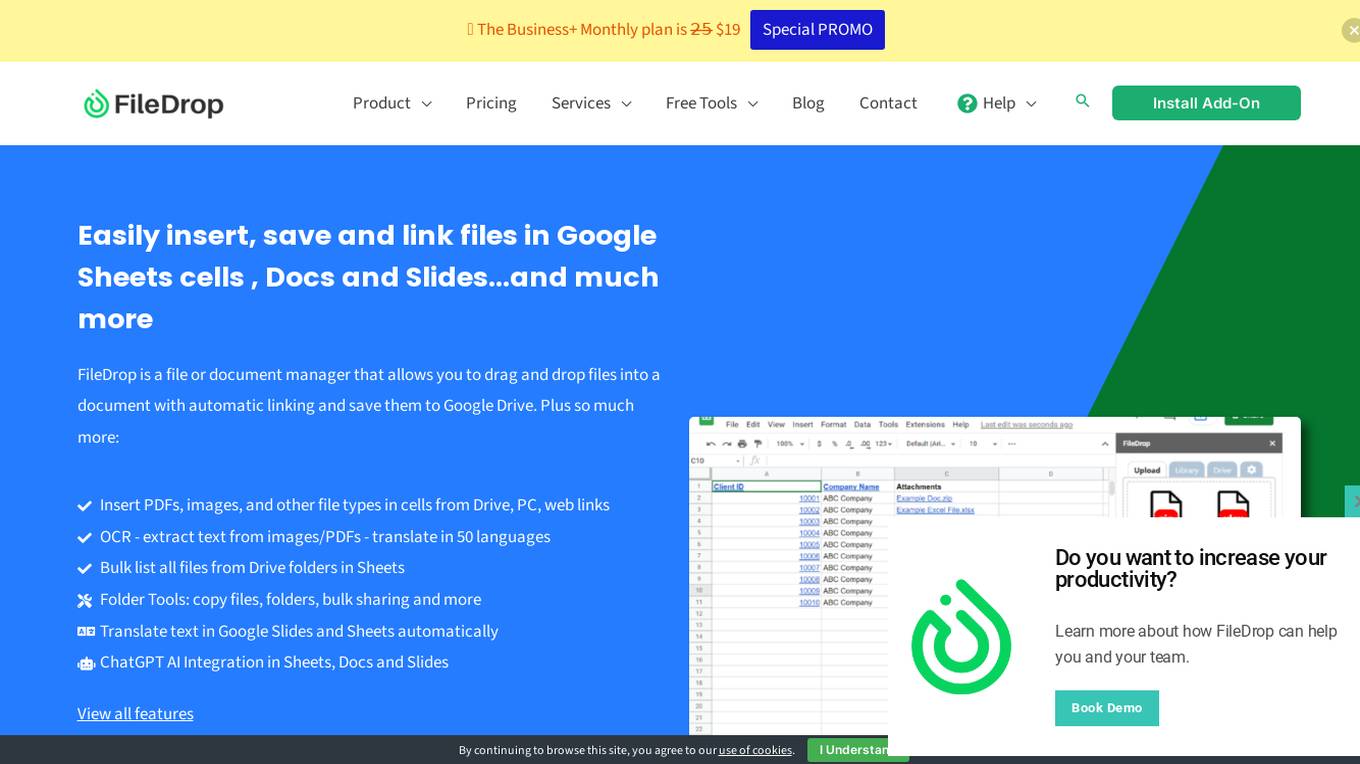
FileDrop
FileDrop is a file or document manager that allows you to drag and drop files into a document with automatic linking and save them to Google Drive. It also offers features like OCR, translation, and AI integration. With FileDrop, you can easily insert, save, and link files in Google Sheets cells, Docs, and Slides.
api4ai
api4ai is a cloud-native AI application that offers image processing APIs powered by artificial intelligence. It provides affordable and personalized solutions for businesses, empowering them with computer vision and machine learning capabilities. The application allows users to monitor visitor statistics, expand product identification apps, integrate background removal algorithms, estimate marketing campaign effectiveness, automate production processes, manage clothing stocktaking, enhance car dealership ads, ensure workplace safety, and extract information for enterprises, startups, and developers. With a wide range of ready-to-use APIs and customization options, api4ai simplifies the implementation of AI solutions across various industries.
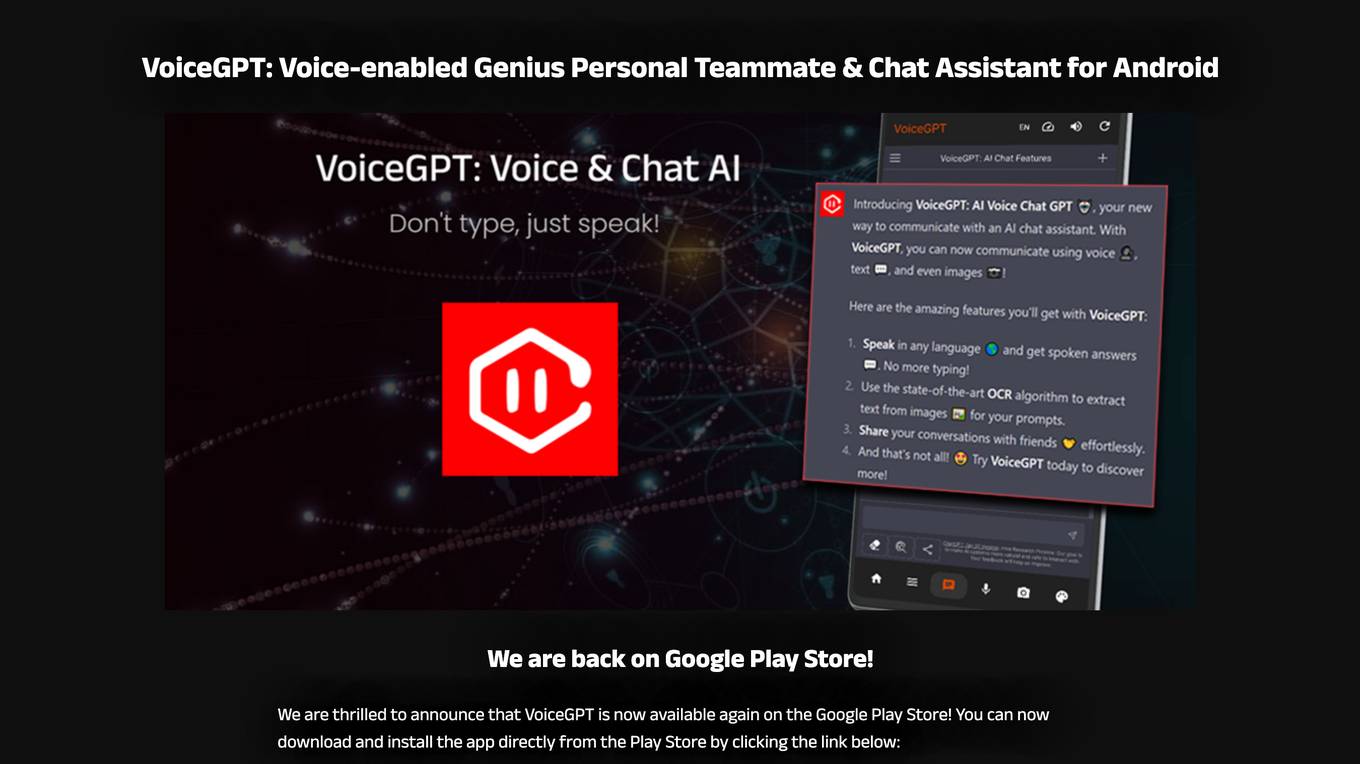
VoiceGPT
VoiceGPT is an Android app that provides a voice-based interface to interact with AI language models like ChatGPT, Bing AI, and Bard. It offers features such as unlimited free messages, voice input and output in 67+ languages, a floating bubble for easy switching between apps, OCR text recognition, code execution, image generation with DALL-E 2, and support for ChatGPT Plus accounts. VoiceGPT is designed to be accessible for users with visual impairments, dyslexia, or other conditions, and it can be set as the default assistant to be activated hands-free with a custom hotword.
Pen2txt
Pen2txt is an AI-powered tool that converts handwritten notes and sketches into digital text and images. It uses advanced image recognition and natural language processing to accurately transcribe handwriting, making it easy to digitize and share your notes. Pen2txt is designed to be user-friendly and accessible, with a simple interface and a variety of features to help you get the most out of your notes.
UPDF
UPDF is an AI-integrated PDF editor, converter, annotator, and reader that offers a comprehensive set of features for seamless PDF editing. It provides cross-platform support on Windows, Mac, iOS, and Android devices. With UPDF AI capabilities, users can summarize, translate, and chat with PDF, making it a versatile tool for various tasks. The application is user-friendly, well-priced, and reliable, catering to both individual and enterprise needs. UPDF also offers localized interface in 11 languages and responsive customer support.
ABBYY
ABBYY is an intelligent automation company that offers purpose-built AI document processing solutions for efficient business process automation. Their products include ABBYY Vantage, ABBYY Timeline, ABBYY Cloud OCR SDK, and ABBYY FlexiCapture Cloud Platform. ABBYY provides tools for document input, classification, splitting, data extraction, validation, quality analytics, OCR/ICR, and IDP analytics. They also offer solutions for process understanding, optimization, monitoring, prediction, and simulation. ABBYY Marketplace offers pre-trained AI extraction models for limitless automation. The company caters to various industries like financial services, public sector, insurance, transportation & logistics, and offers solutions for accounts payable automation, enterprise automation, process intelligence, and customer onboarding.
Klarity
Klarity is an AI-powered platform that automates accounting and compliance workflows traditionally offshored. It leverages AI to streamline documentation processes, enhance compliance, and drive real-world impact and sustainable scaling. Klarity helps businesses evolve into Exponential Organizations by optimizing functions, scaling efficiently, and driving innovation with AI-powered automation.
Booke AI
Booke AI is an AI-driven bookkeeping software that automates tasks, reduces errors, and improves communication. It uses AI to categorize transactions, extract data from invoices and receipts, and provide expert reconciliation assistance. Booke AI integrates with Xero, QuickBooks, and Zoho Books, and offers a user-friendly client portal for seamless collaboration. With Booke AI, businesses can save time, reduce stress, and improve the accuracy of their bookkeeping.
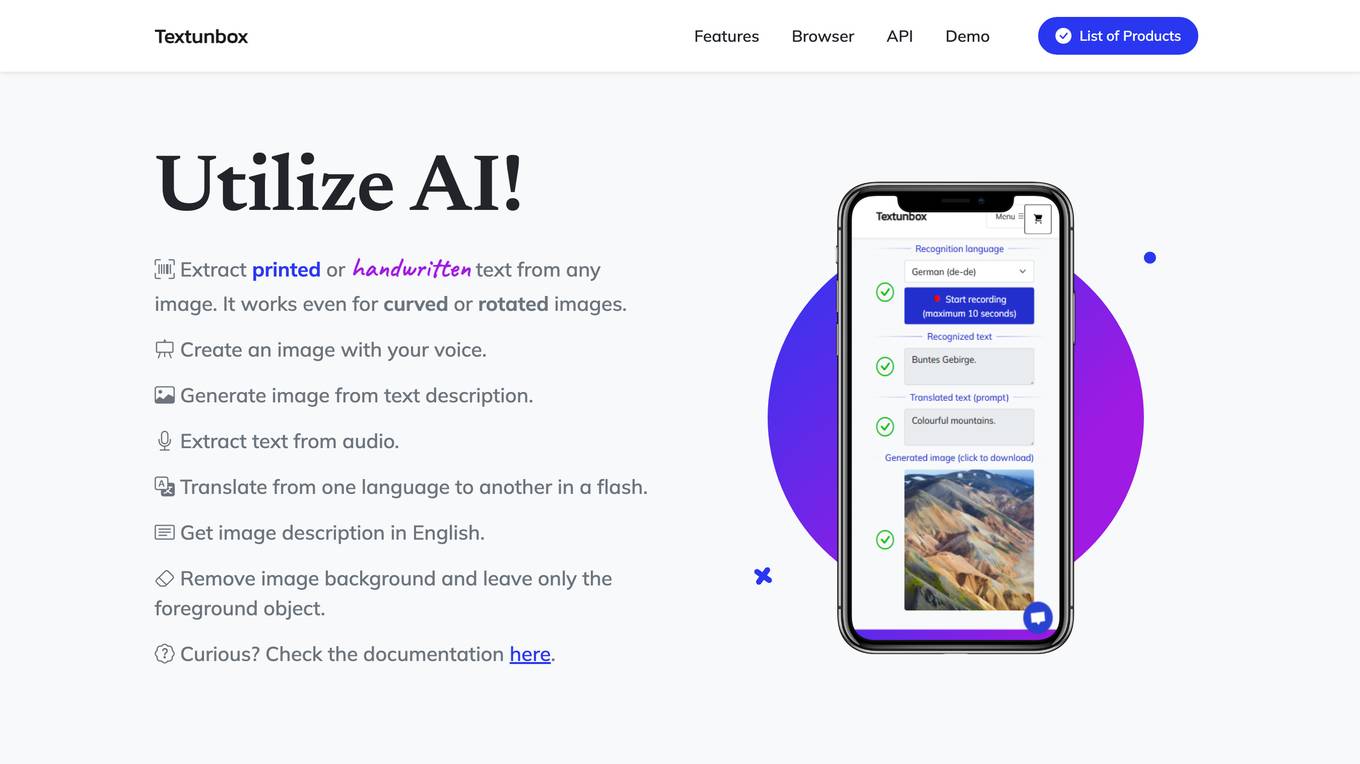
TextUnbox
TextUnbox is an AI-powered tool that allows users to extract text from images, generate images from text descriptions, translate text, remove image backgrounds, and more. It supports over 20 languages and can be used in the browser or integrated into custom solutions using its REST API.
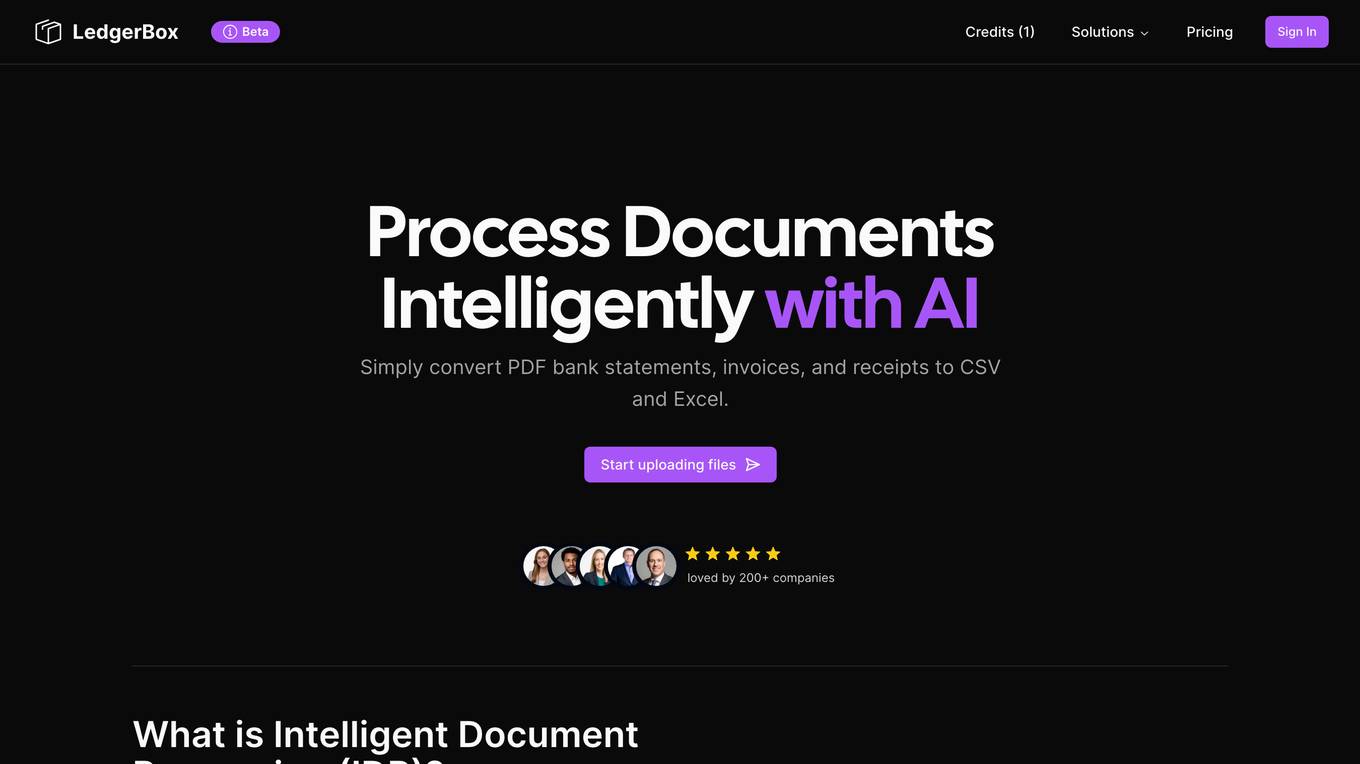
AI Bank Statement Converter
The AI Bank Statement Converter is an industry-leading tool designed for accountants and bookkeepers to extract data from financial documents using artificial intelligence technology. It offers features such as automated data extraction, integration with accounting software, enhanced security, streamlined workflow, and multi-format conversion capabilities. The tool revolutionizes financial document processing by providing high-precision data extraction, tailored for accounting businesses, and ensuring data security through bank-level encryption. It also offers Intelligent Document Processing (IDP) using AI and machine learning techniques to process structured, semi-structured, and unstructured documents.

Journal Recognizer OCR
Optimized OCR for Handwritten Notebooks, up to 10 image transcript copy w/1-click. No text prompt necessary. Reads journals, reports, notes. All handwriting transcribed verbatim, then text summarized, graphic image features described. Ask to change any behavior.

Assistente Codificação TUSS Exames com OCR
Portuguese OCR for medical test coding, outputs in table format.
kz image 2 typescript 2 image
Generate a Structured description in typescript format from the image and generate an image from that description. and OCR

Photo of a business card 2 Contacts
Wizard to business card photos to CSV files for Google Contacts.
Lector de recetas médicas
Ayuda a descifrar la indescifrable caligrafía de las recetas de los médicos

DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages

llm-document-ocr
LLM Document OCR is a Node.js tool that utilizes GPT4 and Claude3 for OCR and data extraction. It converts PDFs into PNGs, crops white-space, cleans up JSON strings, and supports various image formats. Users can customize prompts for data extraction. The tool is sponsored by Mercoa, offering API for BillPay and Invoicing.
swift-ocr-llm-powered-pdf-to-markdown
Swift OCR is a powerful tool for extracting text from PDF files using OpenAI's GPT-4 Turbo with Vision model. It offers flexible input options, advanced OCR processing, performance optimizations, structured output, robust error handling, and scalable architecture. The tool ensures accurate text extraction, resilience against failures, and efficient handling of multiple requests.
Old-Persian-Cuneiform-OCR
This repository aims to create an OCR model for Old Persian Cuneiform. It includes three OCR models: yolo_cnn_old_persian, tesseract_old_persian, and easyocr_old_persian. The status of these models varies from incomplete to completed but needing optimization. Users can train and use the models for converting Old Persian Cuneiform images to text. The repository also provides resources such as trainer notebooks and pre-trained models for easy access and implementation.
llm_aided_ocr
The LLM-Aided OCR Project is an advanced system that enhances Optical Character Recognition (OCR) output by leveraging natural language processing techniques and large language models. It offers features like PDF to image conversion, OCR using Tesseract, error correction using LLMs, smart text chunking, markdown formatting, duplicate content removal, quality assessment, support for local and cloud-based LLMs, asynchronous processing, detailed logging, and GPU acceleration. The project provides detailed technical overview, text processing pipeline, LLM integration, token management, quality assessment, logging, configuration, and customization. It requires Python 3.12+, Tesseract OCR engine, PDF2Image library, PyTesseract, and optional OpenAI or Anthropic API support for cloud-based LLMs. The installation process involves setting up the project, installing dependencies, and configuring environment variables. Users can place a PDF file in the project directory, update input file path, and run the script to generate post-processed text. The project optimizes processing with concurrent processing, context preservation, and adaptive token management. Configuration settings include choosing between local or API-based LLMs, selecting API provider, specifying models, and setting context size for local LLMs. Output files include raw OCR output and LLM-corrected text. Limitations include performance dependency on LLM quality and time-consuming processing for large documents.

Open-DocLLM
Open-DocLLM is an open-source project that addresses data extraction and processing challenges using OCR and LLM technologies. It consists of two main layers: OCR for reading document content and LLM for extracting specific content in a structured manner. The project offers a larger context window size compared to JP Morgan's DocLLM and integrates tools like Tesseract OCR and Mistral for efficient data analysis. Users can run the models on-premises using LLM studio or Ollama, and the project includes a FastAPI app for testing purposes.
text-extract-api
The text-extract-api is a powerful tool that allows users to convert images, PDFs, or Office documents to Markdown text or JSON structured documents with high accuracy. It is built using FastAPI and utilizes Celery for asynchronous task processing, with Redis for caching OCR results. The tool provides features such as PDF/Office to Markdown and JSON conversion, improving OCR results with LLama, removing Personally Identifiable Information from documents, distributed queue processing, caching using Redis, switchable storage strategies, and a CLI tool for task management. Users can run the tool locally or on cloud services, with support for GPU processing. The tool also offers an online demo for testing purposes.
Documents-Parsing-Lab
A curated collection of Jupyter notebooks for experimenting with state-of-the-art OCR, document parsing, table extraction, and chart understanding techniques. This repository enables easy benchmarking and practical usage of the latest open-source and cloud-based solutions for document image processing.
PaddleOCR
PaddleOCR is an easy-to-use and scalable OCR toolkit based on PaddlePaddle. It provides a series of text detection and recognition models, supporting multiple languages and various scenarios. With PaddleOCR, users can perform accurate and efficient text extraction from images and videos, making it suitable for tasks such as document scanning, text recognition, and information extraction.
terraform-genai-doc-summarization
This solution showcases how to summarize a large corpus of documents using Generative AI. It provides an end-to-end demonstration of document summarization going all the way from raw documents, detecting text in the documents and summarizing the documents on-demand using Vertex AI LLM APIs, Cloud Vision Optical Character Recognition (OCR) and BigQuery.
ddddocr
ddddocr is a Rust version of a simple OCR API server that provides easy deployment for captcha recognition without relying on the OpenCV library. It offers a user-friendly general-purpose captcha recognition Rust library. The tool supports recognizing various types of captchas, including single-line text, transparent black PNG images, target detection, and slider matching algorithms. Users can also import custom OCR training models and utilize the OCR API server for flexible OCR result control and range limitation. The tool is cross-platform and can be easily deployed.
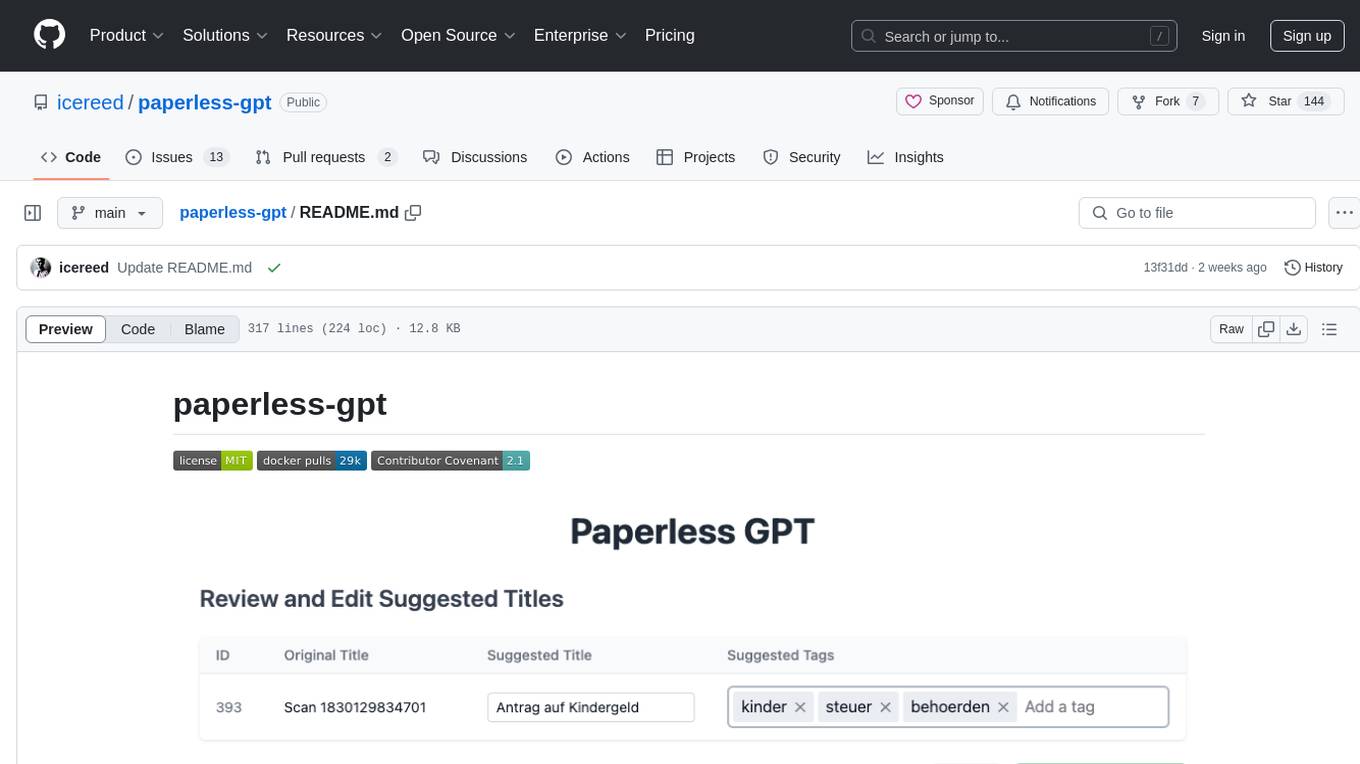
paperless-gpt
paperless-gpt is a tool designed to generate accurate and meaningful document titles and tags for paperless-ngx using Large Language Models (LLMs). It supports multiple LLM providers, including OpenAI and Ollama. With paperless-gpt, you can streamline your document management by automatically suggesting appropriate titles and tags based on the content of your scanned documents. The tool offers features like multiple LLM support, customizable prompts, easy integration with paperless-ngx, user-friendly interface for reviewing and applying suggestions, dockerized deployment, automatic document processing, and an experimental OCR feature.
BetterOCR
BetterOCR is a tool that enhances text detection by combining multiple OCR engines with LLM (Language Model). It aims to improve OCR results, especially for languages with limited training data or noisy outputs. The tool combines results from EasyOCR, Tesseract, and Pororo engines, along with LLM support from OpenAI. Users can provide custom context for better accuracy, view performance examples by language, and upcoming features include box detection, improved interface, and async support. The package is under rapid development and contributions are welcomed.
RSTGameTranslation
RSTGameTranslation is a tool designed for translating game text into multiple languages efficiently. It provides a user-friendly interface for game developers to easily manage and localize their game content. With RSTGameTranslation, developers can streamline the translation process, ensuring consistency and accuracy across different language versions of their games. The tool supports various file formats commonly used in game development, making it versatile and adaptable to different project requirements. Whether you are working on a small indie game or a large-scale production, RSTGameTranslation can help you reach a global audience by making localization a seamless and hassle-free experience.
Windrecorder
Windrecorder is an open-source tool that helps you retrieve memory cues by recording everything on your screen. It can search based on OCR text or image descriptions and provides a summary of your activities. All of its capabilities run entirely locally, without the need for an internet connection or uploading any data, giving you complete ownership of your data.
MouseTooltipTranslator
MouseTooltipTranslator is a Chrome extension that allows users to translate any text on a webpage by simply hovering over it. It supports both Google Translate and Bing Translate, and can also be used to listen to the pronunciation of words and phrases. Additionally, the extension can be used to translate text in input boxes and highlighted text, and to display translated tooltips for PDFs and YouTube videos. It also supports OCR, allowing users to translate text in images by holding down the left shift key and hovering over the image.
generative-fusion-decoding
Generative Fusion Decoding (GFD) is a novel shallow fusion framework that integrates Large Language Models (LLMs) into multi-modal text recognition systems such as automatic speech recognition (ASR) and optical character recognition (OCR). GFD operates across mismatched token spaces of different models by mapping text token space to byte token space, enabling seamless fusion during the decoding process. It simplifies the complexity of aligning different model sample spaces, allows LLMs to correct errors in tandem with the recognition model, increases robustness in long-form speech recognition, and enables fusing recognition models deficient in Chinese text recognition with LLMs extensively trained on Chinese. GFD significantly improves performance in ASR and OCR tasks, offering a unified solution for leveraging existing pre-trained models through step-by-step fusion.
yomitoku
YomiToku is a Japanese-focused AI document image analysis engine that provides full-text OCR and layout analysis capabilities for images. It recognizes, extracts, and converts text information and figures in images. It includes 4 AI models trained on Japanese datasets for tasks such as detecting text positions, recognizing text strings, analyzing layouts, and recognizing table structures. The models are specialized for Japanese document images, supporting recognition of over 7000 Japanese characters and analyzing layout structures specific to Japanese documents. It offers features like layout analysis, table structure analysis, and reading order estimation to extract information from document images without disrupting their semantic structure. YomiToku supports various output formats such as HTML, markdown, JSON, and CSV, and can also extract figures, tables, and images from documents. It operates efficiently in GPU environments, enabling fast and effective analysis of document transcriptions without requiring high-end GPUs.
rowfill
Rowfill is an open-source document processing platform designed for knowledge workers. It offers advanced AI capabilities to extract, analyze, and process data from complex documents, images, and PDFs. The platform features advanced OCR and processing functionalities, auto-schema generation, and custom actions for creating tailored workflows. It prioritizes privacy and security by supporting Local LLMs like Llama and Mistral, syncing with company data while maintaining privacy, and being open source with AGPLv3 licensing. Rowfill is a versatile tool that aims to streamline document processing tasks for users in various industries.

document-ai-samples
The Google Cloud Document AI Samples repository contains code samples and Community Samples demonstrating how to analyze, classify, and search documents using Google Cloud Document AI. It includes various projects showcasing different functionalities such as integrating with Google Drive, processing documents using Python, content moderation with Dialogflow CX, fraud detection, language extraction, paper summarization, tax processing pipeline, and more. The repository also provides access to test document files stored in a publicly-accessible Google Cloud Storage Bucket. Additionally, there are codelabs available for optical character recognition (OCR), form parsing, specialized processors, and managing Document AI processors. Community samples, like the PDF Annotator Sample, are also included. Contributions are welcome, and users can seek help or report issues through the repository's issues page. Please note that this repository is not an officially supported Google product and is intended for demonstrative purposes only.

PanelCleaner
Panel Cleaner is a tool that uses machine learning to find text in images and generate masks to cover it up with high accuracy. It is designed to clean text bubbles without leaving artifacts, avoiding painting over non-text parts, and inpainting bubbles that can't be masked out. The tool offers various customization options, detailed analytics on the cleaning process, supports batch processing, and can run OCR on pages. It supports CUDA acceleration, multiple themes, and can handle bubbles on any solid grayscale background color. Panel Cleaner is aimed at saving time for cleaners by automating monotonous work and providing precise cleaning of text bubbles.