AI tools for generate image
Related Tools:
Image to Caption Generator
The AI-Powered Image to Caption Generator is a revolutionary tool that utilizes artificial intelligence to analyze images and generate engaging captions tailored to each image. By recognizing key objects, scenes, and emotional tones in the image, the tool crafts captivating narratives that spark conversation and boost engagement. Users can save time, maintain brand consistency, and stay ahead of social media marketing trends with this innovative AI application.
Image Variations
Image Variations is an AI image generator tool that allows users to create multiple variations from a single image using stable diffusion. It helps users generate unique and copyright-free images for their projects by adding noise to replicate the style of the original image. The tool is designed to be user-friendly and efficient, providing endless design possibilities for creative projects.
FreeAI-Image.com
FreeAI-Image.com is a free AI image generator that allows users to create stunning images using Stable Diffusion AI image generation engine. Users can simply enter a prompt and the AI will generate an image based on that prompt. The generated images can be used for commercial projects, but keep in mind that the CreativeML Open RAIL-M license applies to created images.

Artchan
Artchan is an AI image generator application that utilizes artificial intelligence algorithms to create unique and creative images. Users can generate a wide range of images by inputting various parameters and settings, allowing for customization and personalization. The application is designed to provide users with a fun and innovative way to generate visual content using AI technology.
GetImg.ai
GetImg.ai is an all-in-one AI creative toolkit that provides a suite of powerful AI tools for creating and editing images. With GetImg.ai, you can generate images from text, edit photos with words, expand pictures beyond their borders, animate images, or train custom AI models. The platform is easy to use and offers a variety of features and advantages that make it a valuable tool for creative professionals and anyone looking to create stunning visuals.
Supermachine
Supermachine is an AI-powered image generator that allows users to create realistic and unique images from scratch. With a simple text prompt, users can generate images of anything they can imagine, from landscapes and portraits to abstract concepts and surreal scenes. Supermachine's AI technology is trained on a massive dataset of images, allowing it to generate images that are both visually appealing and realistic.
TrainEngine.ai
TrainEngine.ai is a powerful AI-powered image generation tool that allows users to create stunning, unique images from text prompts. With its advanced algorithms and vast dataset, TrainEngine.ai can generate images in a wide range of styles, from realistic to abstract, and in various formats, including photos, paintings, and illustrations. The platform is easy to use, making it accessible to both professional artists and hobbyists alike. TrainEngine.ai offers a range of features, including the ability to fine-tune models, generate unlimited AI assets, and access trending models. It also provides a marketplace where users can buy and sell AI-generated images.
AI2image
AI2image is an online text-to-image generator that uses artificial intelligence to create custom images from simple descriptions in English. It offers various features such as choosing from different libraries (coloring, background, art, angle, and position) that can be applied to your image. AI2image is easy to use and can generate images for various purposes such as website, blogs, social media, landing pages, email marketing, and more.
JocondeAI
Joconde AI is an AI-powered image generator that allows users to create stunning art with just a few clicks. With its advanced algorithms, Joconde AI can generate unique and visually appealing images in a matter of seconds. The generated images can be used for both personal and commercial purposes, making it a valuable tool for artists, designers, and businesses alike.
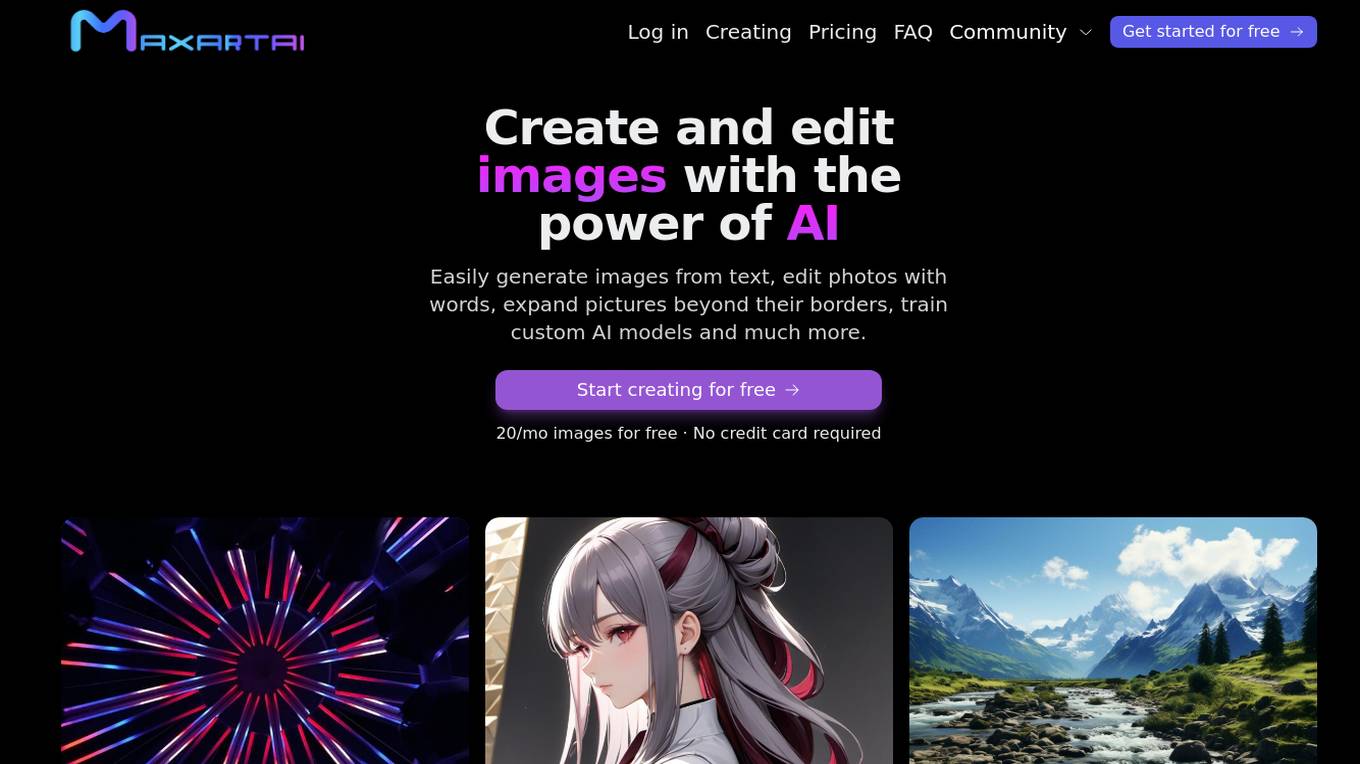
AI Image Generator Free
AI Image Generator Free is a powerful online tool that allows users to create and edit images using the capabilities of artificial intelligence. Users can easily generate images from text, edit photos with words, expand pictures beyond their borders, train custom AI models, and much more. The tool offers a variety of features to enhance creativity and streamline image creation processes.
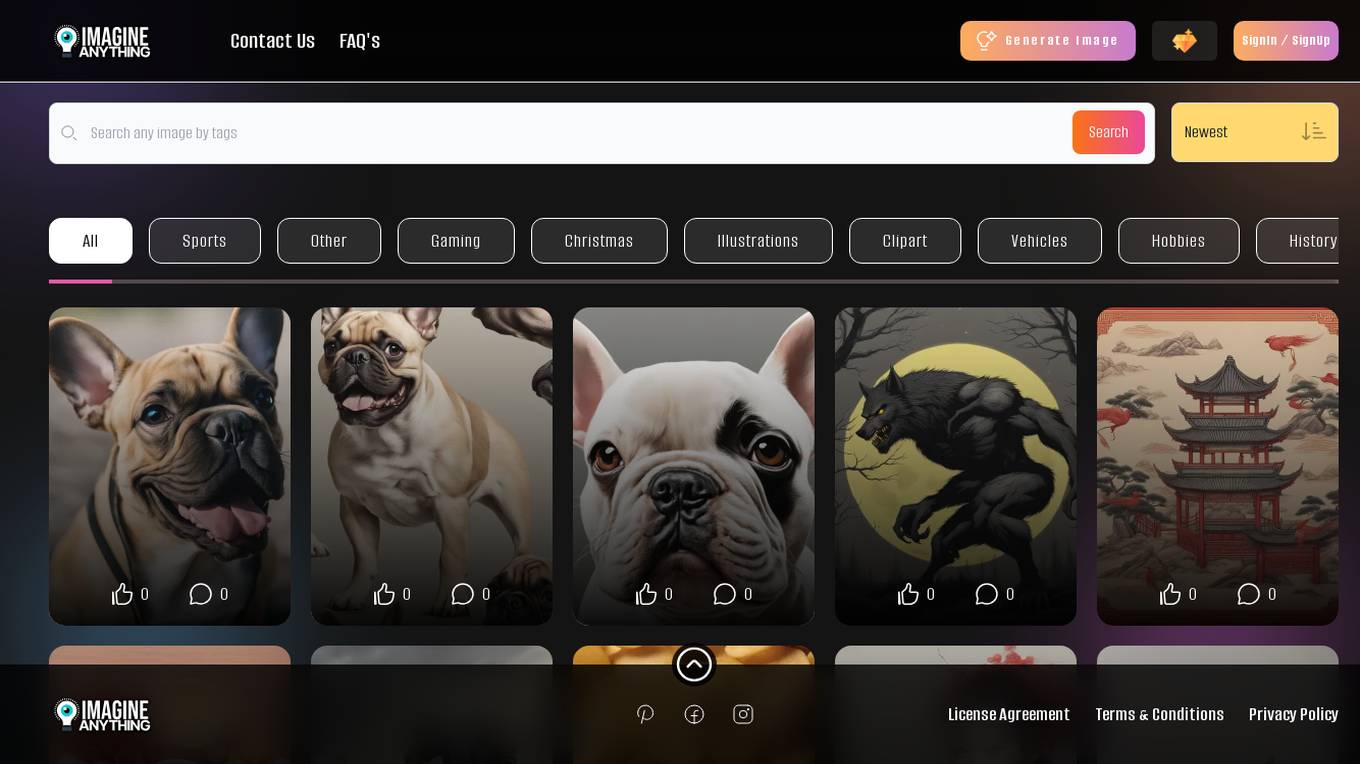
Imagine Anything
Imagine Anything is a free AI image generator that allows users to create unique and realistic images using artificial intelligence technology. With a simple interface, users can easily generate high-quality images for various purposes such as design projects, social media posts, and more. The tool leverages advanced algorithms to produce visually appealing images based on user input, making it a versatile solution for creative individuals and professionals seeking quick and efficient image generation capabilities.
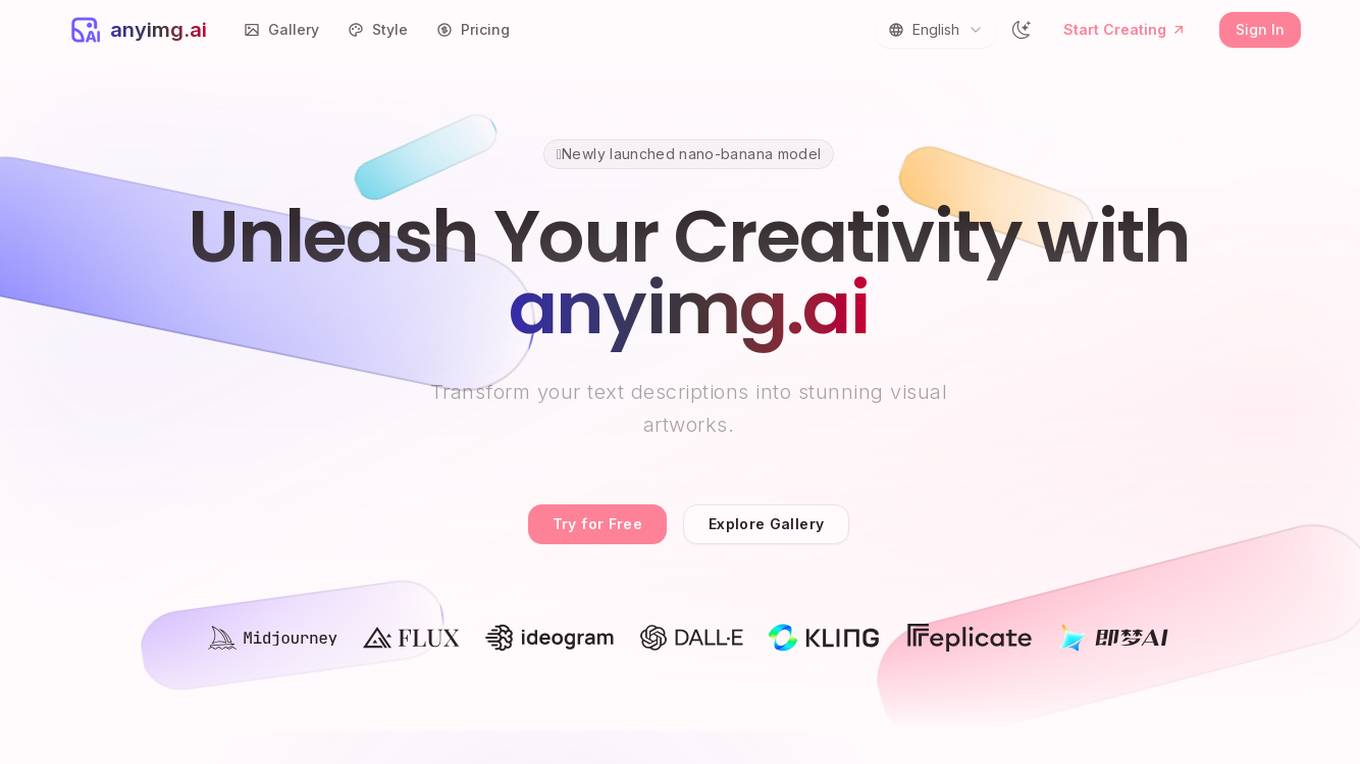
anyimg.ai
anyimg.ai is a powerful AI image generation platform that transforms ideas into stunning visual artworks using cutting-edge AI models. It offers access to various AI models optimized for different artistic styles and use cases. The platform is trusted by over 50,000 artists and has generated over 1 million images. Users can create professional-grade art styles for games, marketing visuals, concept art, product visuals, social media content, and more. With commercial licensing and high-quality outputs, anyimg.ai revolutionizes the creative process for designers, artists, and creators.
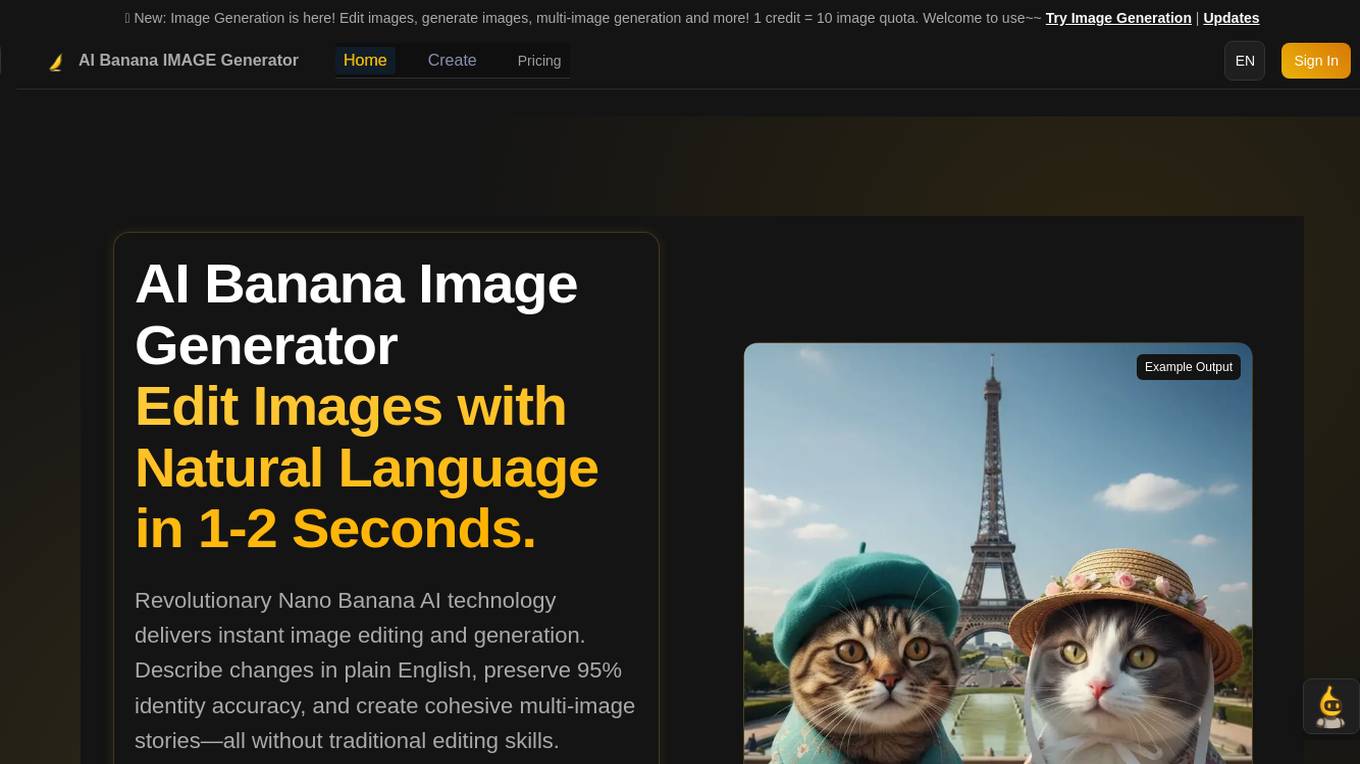
AI Banana Image Generator
AI Banana Image Generator is an advanced image editing platform powered by revolutionary Nano Banana AI technology. It allows users to edit and generate images with natural language in 1-2 seconds, preserving 95% identity accuracy. The tool offers features like multi-image support, lightning-fast processing, and professional-grade image enhancement without the need for traditional editing skills. AI Banana is perfect for creators looking to boost productivity and create stunning visuals effortlessly.
Albus
Albus is an AI-powered platform designed to assist professionals such as creatives, journalists, researchers, consultants, tutors, writers, and freelancers in their daily tasks by providing a real-time voice assistant and a multi-modal canvas. The platform leverages large language models and machine learning services to help users wire ideas, surface relations and connections within a context, and spark new ideas, ultimately saving time and attention.
AI Avatar Generator
AI Avatar Generator is a free tool that allows you to create amazing profile pictures and headshots in any setting using AI technology. With just a text prompt describing the image you want, the tool will generate a high-quality image that you can use for your social media profiles, website, or other purposes. You can also select from a variety of preset filters or create your own custom prompts to get the perfect image. AI Avatar Generator is a quick and easy way to create unique and professional-looking images for any occasion.
Dezgo
Dezgo is a text-to-image AI image generator powered by Stable Diffusion AI. It allows users to generate images from text descriptions. The tool offers various features such as controlled text-to-image, image-to-image upscale, inpainting from text, editing images from text, removing backgrounds, and text-to-video generation. Dezgo also provides access to models, APIs, and an affiliate program.

Robi
Robi is an AI-powered WhatsApp chatbot that offers a range of services, including generating images, writing text, translating languages, and assisting with math, code, and spreadsheets. It is designed to be user-friendly and accessible through WhatsApp, without the need for any app downloads.
AISixteen Studio
AISixteen Studio is an AI-powered image generator that allows users to create stunning images for a variety of purposes, including website banners, social media graphics, product photos, and digital art. With AISixteen Studio, users can easily generate unique and eye-catching images without the need for any design skills.
Decohere
Decohere is a real-time generative AI that allows users to create images, videos, and other content. It is a powerful tool that can be used for a variety of creative purposes, such as creating marketing materials, designing products, and developing new ideas. Decohere is easy to use and requires no coding experience. It is a great tool for anyone who wants to explore their creativity and create amazing content.
Midjourney Alternative
This free AI art generator is a powerful tool that allows you to create stunning images from scratch or by modifying existing ones. With its advanced algorithms, you can explore a wide range of artistic styles, from realistic to abstract, and bring your imagination to life. Unleash your creativity and generate unique, captivating artworks that will amaze you and your audience.
MidGPT
Generate image prompts based on textual or visual input. Optimized for Midjourney v6.
kz image 2 typescript 2 image
Generate a Structured description in typescript format from the image and generate an image from that description. and OCR
Visual Storyteller
Extract the essence of the novel story according to the quantity requirements and generate corresponding images. The images can be used directly to create novel videos.小说推文图片自动批量生成,可自动生成风格一致性图片

AFL Premiership Hero
Generate images of you holding the AFL/AFLW Premiership cup in any era!

Mucha Style Image Creator
Generate Alphonse Mucha style image with your words as a hint. This GPT can grade the image itself and suggest further improvements.
DALL· 3 Ultra: image generator & logo art mj
Advanced Dalle-3 engine for image creation. Generate 1 to 4 images using the command "/number your-image-request". v3.6
Image cloner
From an attached image, the bot will generate a prompt to replicate the image in a digital art bot such as Midjourney or DALL-E
Art Style Explorer 🖌️
Upload or paste an image to gain insights and generate new images inspired by its style
MELODICA
Give me an image or idea and I will create captions designed for generate images with 'Sable Diffusion'.
Chat Painter
Your Personal Digital Artist to help you generate all the images you want to! Just like talking to a real artist you can chat with Chat Painter and iteratively refine your images!

Rainbow unicorn storyteller
I create fun, child-friendly bedtime stories and generate images to match.
Native Plant Garden Guide
A gardening assistant for native plant suggestions. Simplify the planning of your pollinator garden and generate images of your design #gardening #native #plants
Consistent Image Generator
Geneate an image ➡ Request modifications. This GPT supports generating consistent and continuous images with Dalle. It also offers the ability to restore or integrate photos you upload. ✔️Where to use: Wordpress Blog Post, Youtube thumbnail, AI profile, facebook, X, threads feed, Instagram reels
AI Image Style Matcher
Unlock consistent DALL-E results with Style Match Prompter, the AI expert in analyzing visual styles for generating matching DALL-E images.
Gemini
Gemini is an open-source model designed to handle multiple modalities such as text, audio, images, and videos. It utilizes a transformer architecture with special decoders for text and image generation. The model processes input sequences by transforming them into tokens and then decoding them to generate image outputs. Gemini differs from other models by directly feeding image embeddings into the transformer instead of using a visual transformer encoder. The model also includes a component called Codi for conditional generation. Gemini aims to effectively integrate image, audio, and video embeddings to enhance its performance.

runpod-worker-comfy
runpod-worker-comfy is a serverless API tool that allows users to run any ComfyUI workflow to generate an image. Users can provide input images as base64-encoded strings, and the generated image can be returned as a base64-encoded string or uploaded to AWS S3. The tool is built on Ubuntu + NVIDIA CUDA and provides features like built-in checkpoints and VAE models. Users can configure environment variables to upload images to AWS S3 and interact with the RunPod API to generate images. The tool also supports local testing and deployment to Docker hub using Github Actions.

hordelib
horde-engine is a wrapper around ComfyUI designed to run inference pipelines visually designed in the ComfyUI GUI. It enables users to design inference pipelines in ComfyUI and then call them programmatically, maintaining compatibility with the existing horde implementation. The library provides features for processing Horde payloads, initializing the library, downloading and validating models, and generating images based on input data. It also includes custom nodes for preprocessing and tasks such as face restoration and QR code generation. The project depends on various open source projects and bundles some dependencies within the library itself. Users can design ComfyUI pipelines, convert them to the backend format, and run them using the run_image_pipeline() method in hordelib.comfy.Comfy(). The project is actively developed and tested using git, tox, and a specific model directory structure.
AnyGPT
AnyGPT is a unified multimodal language model that utilizes discrete representations for processing various modalities like speech, text, images, and music. It aligns the modalities for intermodal conversions and text processing. AnyInstruct dataset is constructed for generative models. The model proposes a generative training scheme using Next Token Prediction task for training on a Large Language Model (LLM). It aims to compress vast multimodal data on the internet into a single model for emerging capabilities. The tool supports tasks like text-to-image, image captioning, ASR, TTS, text-to-music, and music captioning.
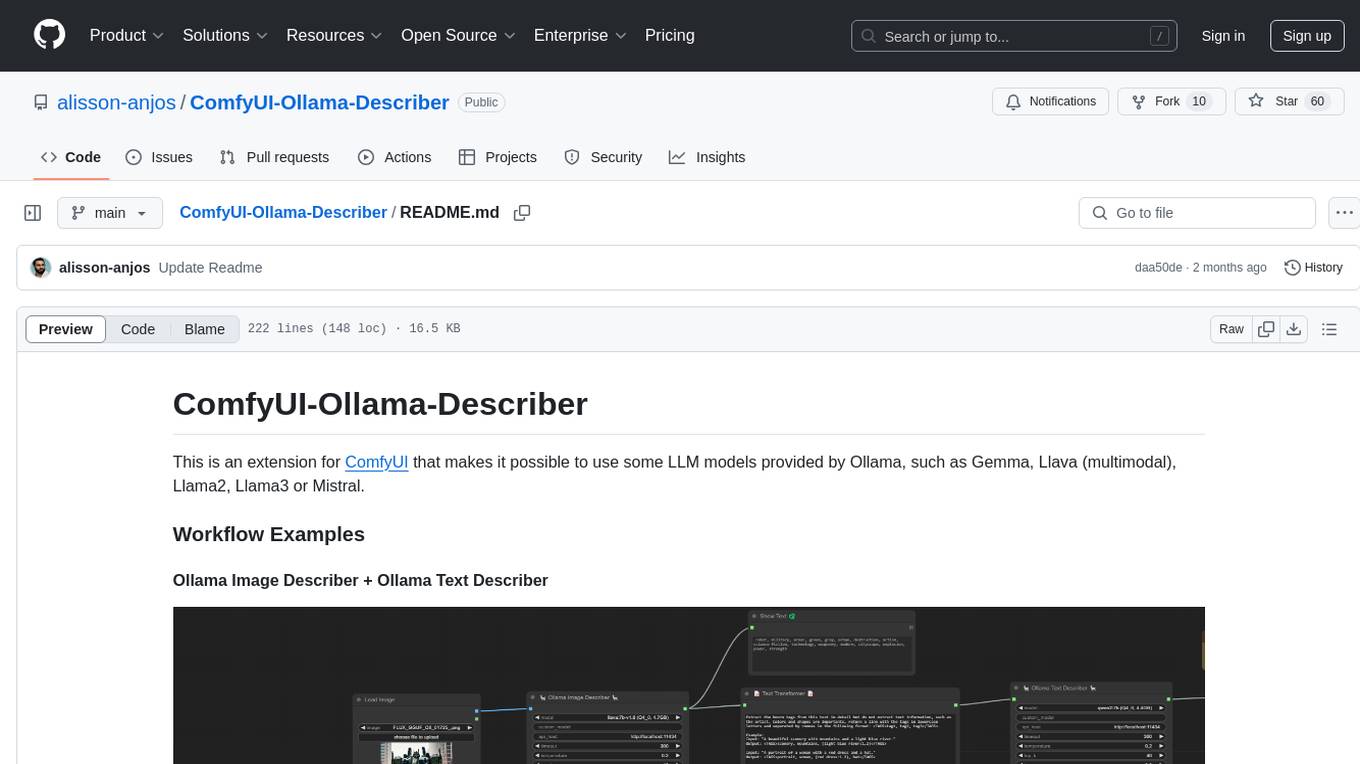
ComfyUI-Ollama-Describer
ComfyUI-Ollama-Describer is an extension for ComfyUI that enables the use of LLM models provided by Ollama, such as Gemma, Llava (multimodal), Llama2, Llama3, or Mistral. It requires the Ollama library for interacting with large-scale language models, supporting GPUs using CUDA and AMD GPUs on Windows, Linux, and Mac. The extension allows users to run Ollama through Docker and utilize NVIDIA GPUs for faster processing. It provides nodes for image description, text description, image captioning, and text transformation, with various customizable parameters for model selection, API communication, response generation, and model memory management.

Janus
Janus is a series of unified multimodal understanding and generation models, including Janus-Pro, Janus, and JanusFlow. Janus-Pro is an advanced version that improves both multimodal understanding and visual generation significantly. Janus decouples visual encoding for unified multimodal understanding and generation, surpassing previous models. JanusFlow harmonizes autoregression and rectified flow for unified multimodal understanding and generation, achieving comparable or superior performance to specialized models. The models are available for download and usage, supporting a broad range of research in academic and commercial communities.
llm
llm.rb is a zero-dependency Ruby toolkit for Large Language Models that includes OpenAI, Gemini, Anthropic, xAI (Grok), DeepSeek, Ollama, and LlamaCpp. The toolkit provides full support for chat, streaming, tool calling, audio, images, files, and structured outputs (JSON Schema). It offers a single unified interface for multiple providers, zero dependencies outside Ruby's standard library, smart API design, and optional per-provider process-wide connection pool. Features include chat, agents, media support (text-to-speech, transcription, translation, image generation, editing), embeddings, model management, and more.

InvokeAI
InvokeAI is a leading creative engine built to empower professionals and enthusiasts alike. Generate and create stunning visual media using the latest AI-driven technologies. InvokeAI offers an industry leading Web Interface, interactive Command Line Interface, and also serves as the foundation for multiple commercial products.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.

civitai
Civitai is a platform where people can share their stable diffusion models (textual inversions, hypernetworks, aesthetic gradients, VAEs, and any other crazy stuff people do to customize their AI generations), collaborate with others to improve them, and learn from each other's work. The platform allows users to create an account, upload their models, and browse models that have been shared by others. Users can also leave comments and feedback on each other's models to facilitate collaboration and knowledge sharing.
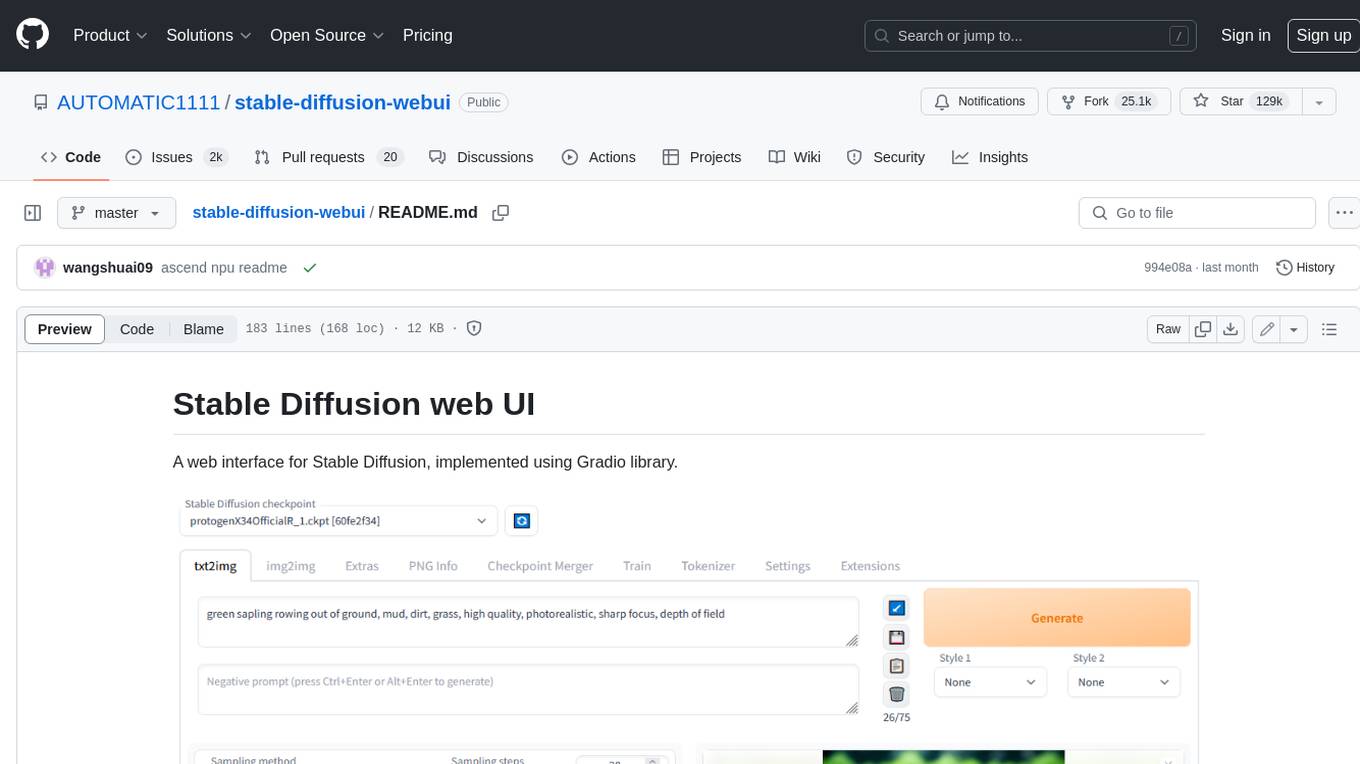
stable-diffusion-webui
Stable Diffusion web UI is a web interface for Stable Diffusion, implemented using Gradio library. It provides a user-friendly interface to access the powerful image generation capabilities of Stable Diffusion. With Stable Diffusion web UI, users can easily generate images from text prompts, edit and refine images using inpainting and outpainting, and explore different artistic styles and techniques. The web UI also includes a range of advanced features such as textual inversion, hypernetworks, and embeddings, allowing users to customize and fine-tune the image generation process. Whether you're an artist, designer, or simply curious about the possibilities of AI-generated art, Stable Diffusion web UI is a valuable tool that empowers you to create stunning and unique images.

openvino.genai
The GenAI repository contains pipelines that implement image and text generation tasks. The implementation uses OpenVINO capabilities to optimize the pipelines. Each sample covers a family of models and suggests certain modifications to adapt the code to specific needs. It includes the following pipelines: 1. Benchmarking script for large language models 2. Text generation C++ samples that support most popular models like LLaMA 2 3. Stable Diffuison (with LoRA) C++ image generation pipeline 4. Latent Consistency Model (with LoRA) C++ image generation pipeline
krita-ai-diffusion
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.
stability-sdk
The stability-sdk is a Python package that provides a client implementation for interacting with the Stability API. This API allows users to generate images, upscale images, and animate images using a variety of different models and settings. The stability-sdk makes it easy to use the Stability API from Python code, and it provides a number of helpful features such as command line usage, support for multiple models, and the ability to filter artifacts by type.

stable-diffusion.cpp
The stable-diffusion.cpp repository provides an implementation for inferring stable diffusion in pure C/C++. It offers features such as support for different versions of stable diffusion, lightweight and dependency-free implementation, various quantization support, memory-efficient CPU inference, GPU acceleration, and more. Users can download the built executable program or build it manually. The repository also includes instructions for downloading weights, building from scratch, using different acceleration methods, running the tool, converting weights, and utilizing various features like Flash Attention, ESRGAN upscaling, PhotoMaker support, and more. Additionally, it mentions future TODOs and provides information on memory requirements, bindings, UIs, contributors, and references.
chatbox
Chatbox is a desktop client for ChatGPT, Claude, and other LLMs, providing a user-friendly interface for AI copilot assistance on Windows, Mac, and Linux. It offers features like local data storage, multiple LLM provider support, image generation with Dall-E-3, enhanced prompting, keyboard shortcuts, and more. Users can collaborate, access the tool on various platforms, and enjoy multilingual support. Chatbox is constantly evolving with new features to enhance the user experience.
RPG-DiffusionMaster
This repository contains the official implementation of RPG, a powerful training-free paradigm for text-to-image generation and editing. RPG utilizes proprietary or open-source MLLMs as prompt recaptioner and region planner with complementary regional diffusion. It achieves state-of-the-art results and can generate high-resolution images. The codebase supports diffusers and various diffusion backbones, including SDXL and SD v1.4/1.5. Users can reproduce results with GPT-4, Gemini-Pro, or local MLLMs like miniGPT-4. The repository provides tools for quick start, regional diffusion with GPT-4, and regional diffusion with local LLMs.

airunner
AI Runner is a multi-modal AI interface that allows users to run open-source large language models and AI image generators on their own hardware. The tool provides features such as voice-based chatbot conversations, text-to-speech, speech-to-text, vision-to-text, text generation with large language models, image generation capabilities, image manipulation tools, utility functions, and more. It aims to provide a stable and user-friendly experience with security updates, a new UI, and a streamlined installation process. The application is designed to run offline on users' hardware without relying on a web server, offering a smooth and responsive user experience.
OpenAI-Api-Unreal
The OpenAIApi Plugin provides access to the OpenAI API in Unreal Engine, allowing users to generate images, transcribe speech, and power NPCs using advanced AI models. It offers blueprint nodes for making API calls, setting parameters, and accessing completion values. Users can authenticate using an API key directly or as an environment variable. The plugin supports various tasks such as generating images, transcribing speech, and interacting with NPCs through chat endpoints.

AI-TOD
AI-TOD is a dataset for tiny object detection in aerial images, containing 700,621 object instances across 28,036 images. Objects in AI-TOD are smaller with a mean size of 12.8 pixels compared to other aerial image datasets. To use AI-TOD, download xView training set and AI-TOD_wo_xview, then generate the complete dataset using the provided synthesis tool. The dataset is publicly available for academic and research purposes under CC BY-NC-SA 4.0 license.