AI tools for Tokenizer
Related Tools:
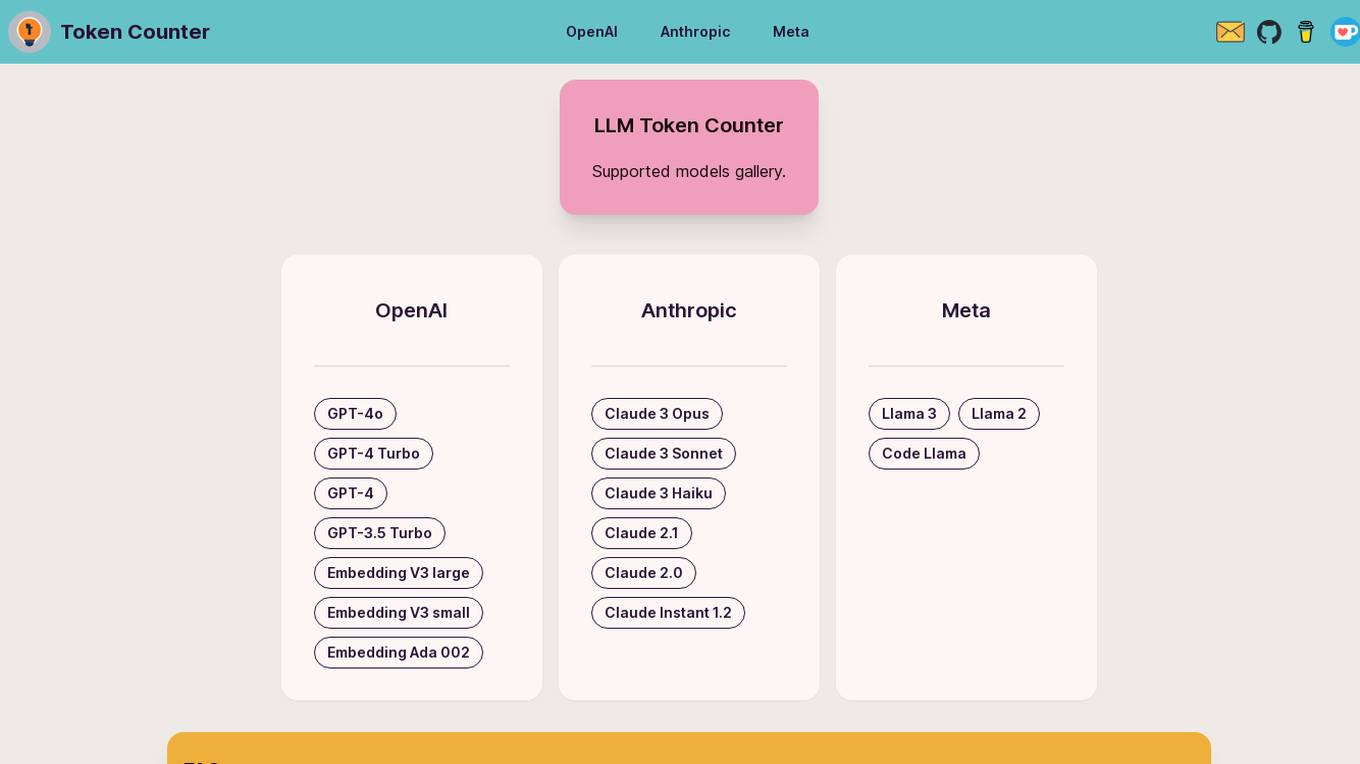
LLM Token Counter
The LLM Token Counter is a sophisticated tool designed to help users effectively manage token limits for various Language Models (LLMs) like GPT-3.5, GPT-4, Claude-3, Llama-3, and more. It utilizes Transformers.js, a JavaScript implementation of the Hugging Face Transformers library, to calculate token counts client-side. The tool ensures data privacy by not transmitting prompts to external servers.
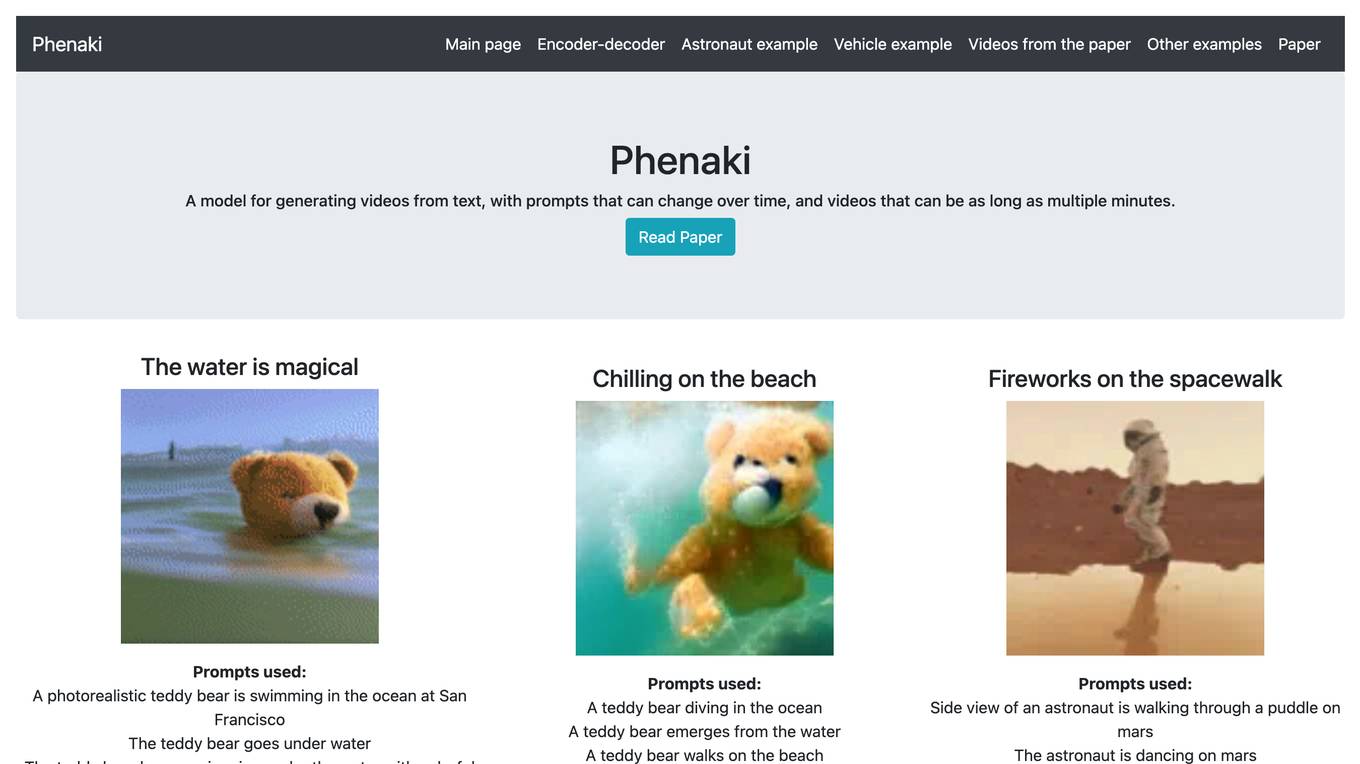
Phenaki
Phenaki is a model capable of generating realistic videos from a sequence of textual prompts. It is particularly challenging to generate videos from text due to the computational cost, limited quantities of high-quality text-video data, and variable length of videos. To address these issues, Phenaki introduces a new causal model for learning video representation, which compresses the video to a small representation of discrete tokens. This tokenizer uses causal attention in time, which allows it to work with variable-length videos. To generate video tokens from text, Phenaki uses a bidirectional masked transformer conditioned on pre-computed text tokens. The generated video tokens are subsequently de-tokenized to create the actual video. To address data issues, Phenaki demonstrates how joint training on a large corpus of image-text pairs as well as a smaller number of video-text examples can result in generalization beyond what is available in the video datasets. Compared to previous video generation methods, Phenaki can generate arbitrarily long videos conditioned on a sequence of prompts (i.e., time-variable text or a story) in an open domain. To the best of our knowledge, this is the first time a paper studies generating videos from time-variable prompts. In addition, the proposed video encoder-decoder outperforms all per-frame baselines currently used in the literature in terms of spatio-temporal quality and the number of tokens per video.
Token Counter
Token Counter is an AI tool designed to convert text input into tokens for various AI models. It helps users accurately determine the token count and associated costs when working with AI models. By providing insights into tokenization strategies and cost structures, Token Counter streamlines the process of utilizing advanced technologies.
The Institute for the Advancement of Legal and Ethical AI (ALEA)
The Institute for the Advancement of Legal and Ethical AI (ALEA) is a platform dedicated to supporting socially, economically, and environmentally sustainable futures through open research and education. They focus on developing legal and ethical frameworks to ensure that AI systems benefit society while minimizing harm to the economy and the environment. ALEA engages in activities such as open data collection, model training, technical and policy research, education, and community building to promote the responsible use of AI.

Basis Theory
Basis Theory is a token orchestration platform that helps businesses route transactions through multiple payment service providers (PSPs) and partners, enabling seamless subscription payments while maintaining PCI compliance. The platform offers secure and transparent payment flows, allowing users to connect to any partner or platform, collect and store card data securely, and customize payment strategies for various use cases. Basis Theory empowers high-risk merchants, subscription platforms, marketplaces, fintechs, and other businesses to optimize their payment processes and enhance customer experiences.
HelloScribe
HelloScribe is an autonomous reasoning engine that provides high-level creativity, strategy, and planning. It offers over 150 precision-made AI tools and templates, the ability to create in over 50 languages, speech-to-text functionality, and access to over 200 million research papers, live news, and web search. HelloScribe is designed to help professionals in various fields, including sales, marketing, consulting, and research, by automating tasks, providing real-time insights, and facilitating collaboration.

Ocean Protocol
Ocean Protocol is a tokenized AI and data platform that enables users to monetize AI models and data while maintaining privacy. It offers tools like Predictoor for running AI-powered prediction bots, Ocean Nodes for enhancing AI capabilities, and features like Data NFTs and Datatokens for protecting intellectual property and controlling data access. The platform focuses on decentralized AI, privacy, and modular architecture to empower users in the AI and data science domains.
DAWN AI
DAWN AI is an EDtech platform that is revolutionizing education with blockchain and AI. It is designed to make education accessible to everyone, regardless of their location, language, or abilities. DAWN offers a complete suite of blockchain-scaling solutions, including course transcription, AI recruitment services, a dyslexia-friendly platform, closed captioning and sign language interpretation, and tokenized affiliate marketing. It also has a Learn and Earn program in the metaverse, where learners can earn tokens by completing educational challenges and tasks in virtual worlds.

Toolblox
Toolblox is an AI-powered platform that enables users to create purpose-built, audited smart-contracts and Dapps for tokenized assets quickly and efficiently. It offers a no-code solution for turning ideas into smart-contracts, visualizing workflows, and creating tokenization solutions. With pre-audited smart-contracts, examples, and an AI assistant, Toolblox simplifies the process of building and launching decentralized applications. The platform caters to founders, agencies, and businesses looking to streamline their operations and leverage blockchain technology.
Evervault
Evervault is a flexible payments security platform that provides maximum protection with minimum compliance burden. It allows users to easily tokenize cards, optimize margins, comply with PCI standards, avoid gateway lock-in, and set up card issuing programs. Evervault is trusted by global leaders for securing sensitive payment data and offers features like PCI compliance, payments optimization, card issuing, network tokens, key management, and more. The platform enables users to accelerate card product launches, build complex card sharing workflows, optimize payment performance, and run highly sensitive payment operations. Evervault's unique encryption model ensures data security, reduced risk of data breach, improved performance, and maximum resiliency. It offers agile payments infrastructure, customizable UI components, cross-platform support, and effortless scalability, making it a developer-friendly solution for securing payment data.

Questflow
Questflow is an AI agent economy platform that enables users to automate tasks, turn user feedback into action, and build AI agent teams for various workflows. It offers a developer platform to design and deploy AI swarms, empowering teams and innovators worldwide. Questflow aims to create a multi-agent economy on-chain, connecting AI agents to all apps and allowing users to customize AI agent-powered applications. With features like autonomous task completion, on-chain incentives for builders, and tokenization of AI agents, Questflow provides a composable solution for orchestrating AI agents to work together seamlessly.

NLTK
NLTK (Natural Language Toolkit) is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum. Thanks to a hands-on guide introducing programming fundamentals alongside topics in computational linguistics, plus comprehensive API documentation, NLTK is suitable for linguists, engineers, students, educators, researchers, and industry users alike.

Deckee.AI
Deckee.AI is an AI-powered platform that allows users to instantly build blockchain websites and tokens. With Deckee.AI, users can create customized webpages for blogging, consulting, digital creation, and more. Deckee.AI also provides powerful editing tools, domain and SSL, separate hosting options, and the ability to choose the exact layout users want. Additionally, Deckee.AI makes it easy to create professional designs and digital collections, as well as unique digital tokens as a representation of products, events, rewards, and more.
Atriv
Atriv is a comprehensive digital art creation and monetization platform that empowers artists to showcase, sell, and earn from their creations. With a user-friendly interface and advanced tools, Atriv provides a seamless experience for artists to create stunning digital art, connect with collectors, and build a sustainable income stream.
Trust Stamp
Trust Stamp is an AI-powered digital identity solution that focuses on mitigating fraud through biometrics, privacy, and cybersecurity. The platform offers secure authentication and multi-factor authentication using biometric data, along with features like KYC/AML compliance, tokenization, and age estimation. Trust Stamp helps financial institutions, healthcare providers, dating platforms, and other industries prevent identity theft and fraud by providing innovative solutions for account recovery and user security.
Immplify
Immplify is the ultimate platform for immigrants, offering an advanced document management system, on-demand immigration-related services, and a vibrant verified immigrant community. The platform prioritizes security, employing 2-factor authentication, data redaction, AES 256-bit encryption, and tokenization to protect users' confidential information. Immplify simplifies the immigration process by providing features like document digitization, on-the-go scanning, advanced encryption, automatic document organization, travel time tracking, intelligent document tracking, key insights dashboard, instant access to immigration guidance, and secure document sharing. Trusted by immigrants for its efficiency and reliability, Immplify streamlines tasks such as managing travel history, organizing documents, filling out visa forms, and ensuring document security.

Tresata
Tresata is an AI tool that offers inventory and cataloging, inferencing and connecting, discoverability and lineage tracking, tokenization, and data enrichment capabilities. It provides SAM (Smart Augmented Intelligence) features and seamless integrations for customers. The platform empowers users to create data products for AI applications by uploading data to the Tresata cloud and accessing it for analysis and insights. Tresata emphasizes the importance of good data for all, with a focus on data-driven decision-making and innovation.
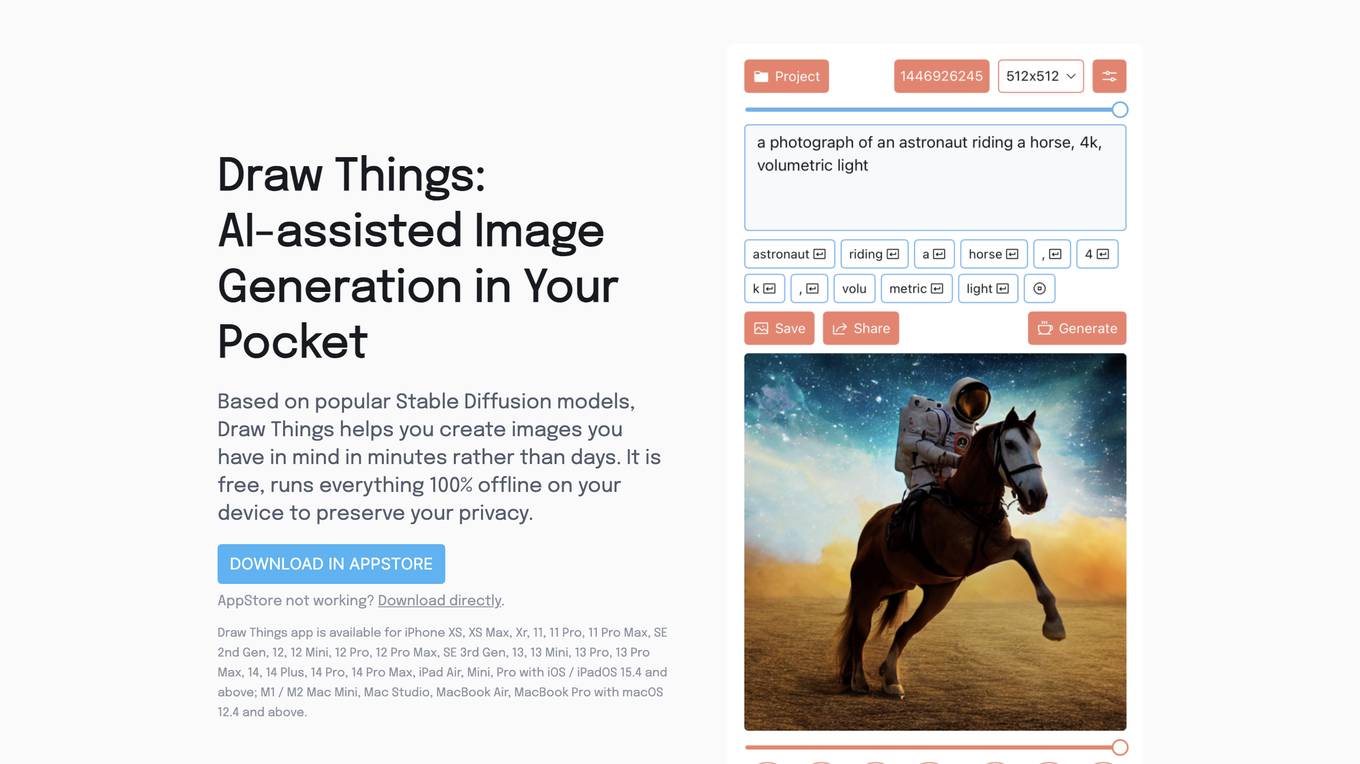
Draw Things
Draw Things is an AI-assisted image generation app that allows users to create images from their imagination in minutes. It is powered by Stable Diffusion models and runs entirely offline on the user's device, ensuring privacy. The app offers a range of features, including inpainting, outpainting, text-to-image generation, text-guided image-to-image generation, and image and prompt editing history. Users can also select images from their camera roll and utilize various Stable Diffusion features such as guidance scale, steps, strength, image sizes, negative prompts, manual seed, and prompt tokenization. Additionally, the app allows users to preview different models and styles, including Generic Stable Diffusion v1.4, Waifu Diffusion v1.3 for Anime, and Stable Diffusion v1.5 Inpainting.
Alethea AI
Alethea AI is a research and development studio building at the intersection of two of the most transformative technologies of our time: Generative AI and Blockchain. Our mission is to use these technologies to enable decentralized ownership and democratic governance of AI. We believe the key to achieving our mission is to partner and work with those who share our values to advance the development and adoption of the AI Protocol.
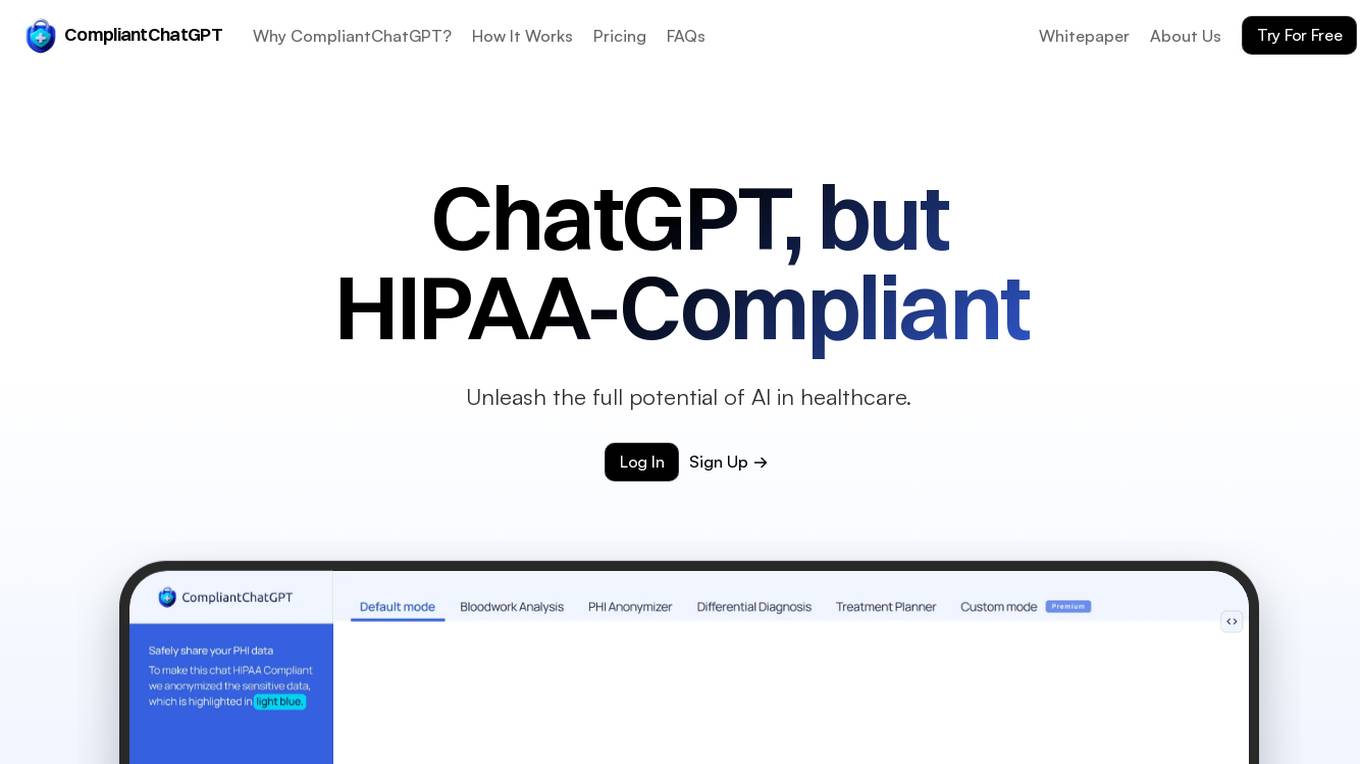
CompliantChatGPT
CompliantChatGPT is a HIPAA-compliant platform that allows users to utilize OpenAI's GPT models for healthcare-related tasks while maintaining data privacy and security. It anonymizes protected health information (PHI) by replacing it with tokens, ensuring compliance with HIPAA regulations. The platform offers various modes tailored to specific healthcare needs, including bloodwork analysis, PHI anonymization, diagnosis assistance, and treatment planning. CompliantChatGPT streamlines healthcare tasks, enhances productivity, and provides user-friendly assistance through its intuitive interface.
Web3 Wizard
Web3 expert knowledgeable in Blockchains, DApps, NFTs, Wallets, Tokenization, CBDCs, and more.
Tokenizer
This repository contains implementations of byte pair encoding (BPE) tokenizer in Typescript and C# for OpenAI LLMs. The implementations are based on an open-sourced rust implementation in the OpenAI tiktoken. These implementations are valuable for prompt tokenization in Nodejs and .NET environments before feeding prompts into a LLM.
llama3-tokenizer-js
JavaScript tokenizer for LLaMA 3 designed for client-side use in the browser and Node, with TypeScript support. It accurately calculates token count, has 0 dependencies, optimized running time, and somewhat optimized bundle size. Compatible with most LLaMA 3 models. Can encode and decode text, but training is not supported. Pollutes global namespace with `llama3Tokenizer` in the browser. Mostly compatible with LLaMA 3 models released by Facebook in April 2024. Can be adapted for incompatible models by passing custom vocab and merge data. Handles special tokens and fine tunes. Developed by belladore.ai with contributions from xenova, blaze2004, imoneoi, and ConProgramming.
flash-tokenizer
FlashTokenizer is a high-performance CPU tokenizer library implemented in C++ for LLM inference serving. It is 10 times faster than BertTokenizerFast in transformers, offering the highest speed and accuracy. Developed to be faster, more accurate, and easier to use than existing tokenizers like BertTokenizerFast, FlashTokenizer is implemented in C++ for straightforward maintenance. It supports parallel processing at the C++ level for batch encoding, delivering outstanding speed. The tokenizer is based on the LinMax Tokenizer proposed in Fast WordPiece Tokenization, enabling tokenization in linear time.

minbpe
This repository contains a minimal, clean code implementation of the Byte Pair Encoding (BPE) algorithm, commonly used in LLM tokenization. The BPE algorithm is "byte-level" because it runs on UTF-8 encoded strings. This algorithm was popularized for LLMs by the GPT-2 paper and the associated GPT-2 code release from OpenAI. Sennrich et al. 2015 is cited as the original reference for the use of BPE in NLP applications. Today, all modern LLMs (e.g. GPT, Llama, Mistral) use this algorithm to train their tokenizers. There are two Tokenizers in this repository, both of which can perform the 3 primary functions of a Tokenizer: 1) train the tokenizer vocabulary and merges on a given text, 2) encode from text to tokens, 3) decode from tokens to text. The files of the repo are as follows: 1. minbpe/base.py: Implements the `Tokenizer` class, which is the base class. It contains the `train`, `encode`, and `decode` stubs, save/load functionality, and there are also a few common utility functions. This class is not meant to be used directly, but rather to be inherited from. 2. minbpe/basic.py: Implements the `BasicTokenizer`, the simplest implementation of the BPE algorithm that runs directly on text. 3. minbpe/regex.py: Implements the `RegexTokenizer` that further splits the input text by a regex pattern, which is a preprocessing stage that splits up the input text by categories (think: letters, numbers, punctuation) before tokenization. This ensures that no merges will happen across category boundaries. This was introduced in the GPT-2 paper and continues to be in use as of GPT-4. This class also handles special tokens, if any. 4. minbpe/gpt4.py: Implements the `GPT4Tokenizer`. This class is a light wrapper around the `RegexTokenizer` (2, above) that exactly reproduces the tokenization of GPT-4 in the tiktoken library. The wrapping handles some details around recovering the exact merges in the tokenizer, and the handling of some unfortunate (and likely historical?) 1-byte token permutations. Finally, the script train.py trains the two major tokenizers on the input text tests/taylorswift.txt (this is the Wikipedia entry for her kek) and saves the vocab to disk for visualization. This script runs in about 25 seconds on my (M1) MacBook. All of the files above are very short and thoroughly commented, and also contain a usage example on the bottom of the file.
SmallLanguageModel-project
This repository provides all the necessary items to build a Language Model from scratch, inspired by Karpathy's nanoGPT and Shakespeare generator. It includes data collection tools, data processing scripts, various models like BERT, GPT, and Seq-2-Seq, along with tokenizer and training files.
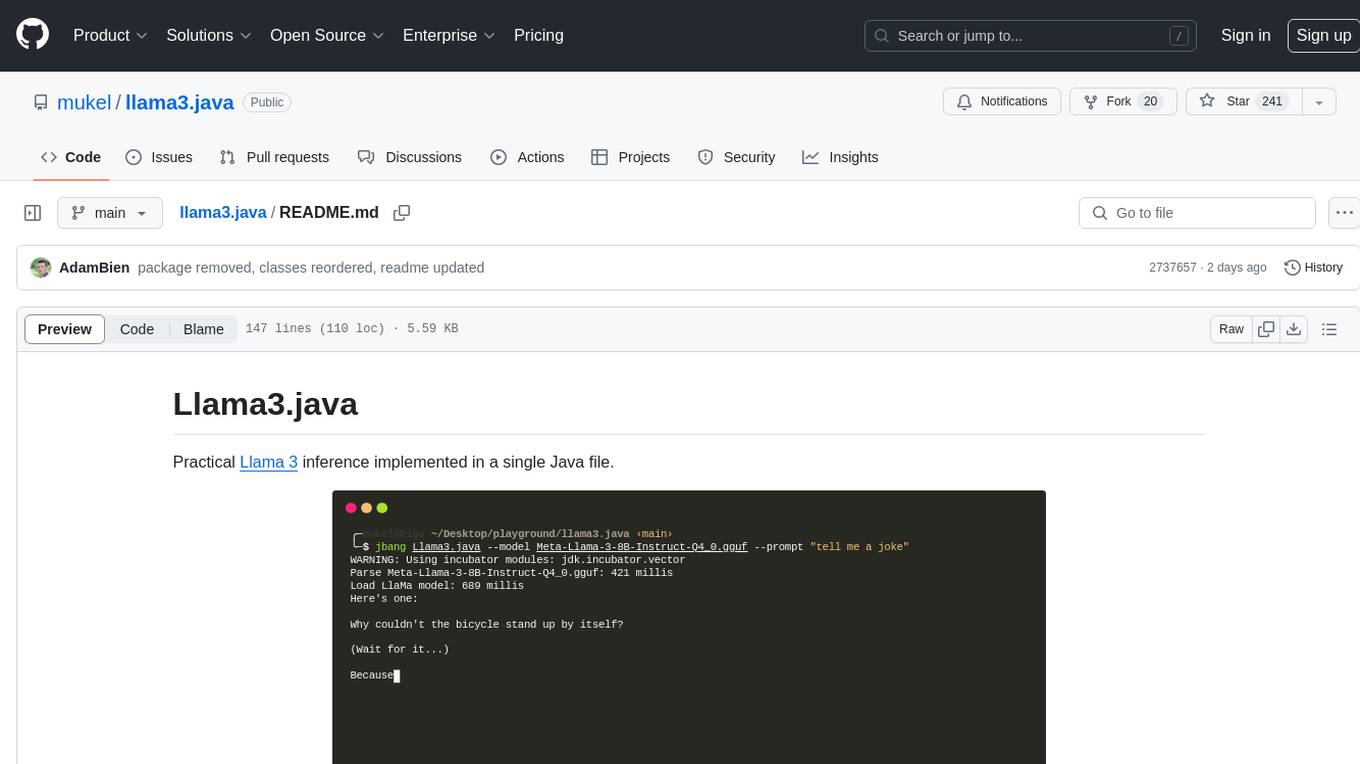
llama3.java
Llama3.java is a practical Llama 3 inference tool implemented in a single Java file. It serves as the successor of llama2.java and is designed for testing and tuning compiler optimizations and features on the JVM, especially for the Graal compiler. The tool features a GGUF format parser, Llama 3 tokenizer, Grouped-Query Attention inference, support for Q8_0 and Q4_0 quantizations, fast matrix-vector multiplication routines using Java's Vector API, and a simple CLI with 'chat' and 'instruct' modes. Users can download quantized .gguf files from huggingface.co for model usage and can also manually quantize to pure 'Q4_0'. The tool requires Java 21+ and supports running from source or building a JAR file for execution. Performance benchmarks show varying tokens/s rates for different models and implementations on different hardware setups.

hezar
Hezar is an all-in-one AI library designed specifically for the Persian community. It brings together various AI models and tools, making it easy to use AI with just a few lines of code. The library seamlessly integrates with Hugging Face Hub, offering a developer-friendly interface and task-based model interface. In addition to models, Hezar provides tools like word embeddings, tokenizers, feature extractors, and more. It also includes supplementary ML tools for deployment, benchmarking, and optimization.
abliterator
abliterator.py is a simple Python library/structure designed to ablate features in large language models (LLMs) supported by TransformerLens. It provides capabilities to enter temporary contexts, cache activations with N samples, calculate refusal directions, and includes tokenizer utilities. The library aims to streamline the process of experimenting with ablation direction turns by encapsulating useful logic and minimizing code complexity. While currently basic and lacking comprehensive documentation, the library serves well for personal workflows and aims to expand beyond feature ablation to augmentation and additional features over time with community support.

tiny-llm-zh
Tiny LLM zh is a project aimed at building a small-parameter Chinese language large model for quick entry into learning large model-related knowledge. The project implements a two-stage training process for large models and subsequent human alignment, including tokenization, pre-training, instruction fine-tuning, human alignment, evaluation, and deployment. It is deployed on ModeScope Tiny LLM website and features open access to all data and code, including pre-training data and tokenizer. The project trains a tokenizer using 10GB of Chinese encyclopedia text to build a Tiny LLM vocabulary. It supports training with Transformers deepspeed, multiple machine and card support, and Zero optimization techniques. The project has three main branches: llama2_torch, main tiny_llm, and tiny_llm_moe, each with specific modifications and features.
Train-llm-from-scratch
Train-llm-from-scratch is a repository that guides users through training a Large Language Model (LLM) from scratch. The model size can be adjusted based on available computing power. The repository utilizes deepspeed for distributed training and includes detailed explanations of the code and key steps at each stage to facilitate learning. Users can train their own tokenizer or use pre-trained tokenizers like ChatGLM2-6B. The repository provides information on preparing pre-training data, processing training data, and recommended SFT data for fine-tuning. It also references other projects and books related to LLM training.

HebTTS
HebTTS is a language modeling approach to diacritic-free Hebrew text-to-speech (TTS) system. It addresses the challenge of accurately mapping text to speech in Hebrew by proposing a language model that operates on discrete speech representations and is conditioned on a word-piece tokenizer. The system is optimized using weakly supervised recordings and outperforms diacritic-based Hebrew TTS systems in terms of content preservation and naturalness of generated speech.
openshield
OpenShield is a firewall designed for AI models to protect against various attacks such as prompt injection, insecure output handling, training data poisoning, model denial of service, supply chain vulnerabilities, sensitive information disclosure, insecure plugin design, excessive agency granting, overreliance, and model theft. It provides rate limiting, content filtering, and keyword filtering for AI models. The tool acts as a transparent proxy between AI models and clients, allowing users to set custom rate limits for OpenAI endpoints and perform tokenizer calculations for OpenAI models. OpenShield also supports Python and LLM based rules, with upcoming features including rate limiting per user and model, prompts manager, content filtering, keyword filtering based on LLM/Vector models, OpenMeter integration, and VectorDB integration. The tool requires an OpenAI API key, Postgres, and Redis for operation.
lm.rs
lm.rs is a tool that allows users to run inference on Language Models locally on the CPU using Rust. It supports LLama3.2 1B and 3B models, with a WebUI also available. The tool provides benchmarks and download links for models and tokenizers, with recommendations for quantization options. Users can convert models from Google/Meta on huggingface using provided scripts. The tool can be compiled with cargo and run with various arguments for model weights, tokenizer, temperature, and more. Additionally, a backend for the WebUI can be compiled and run to connect via the web interface.

ppl.llm.serving
ppl.llm.serving is a serving component for Large Language Models (LLMs) within the PPL.LLM system. It provides a server based on gRPC and supports inference for LLaMA. The repository includes instructions for prerequisites, quick start guide, model exporting, server setup, client usage, benchmarking, and offline inference. Users can refer to the LLaMA Guide for more details on using this serving component.
ComfyUI-mnemic-nodes
ComfyUI-mnemic-nodes is a repository hosting a collection of nodes developed for ComfyUI, providing useful components to enhance project functionality. The nodes include features like returning file paths, saving text files, downloading images from URLs, tokenizing text, cleaning strings, querying Groq language models, generating negative prompts, and more. Some nodes are experimental and marked with a 'Caution' label. Installation instructions and setup details are provided for each node, along with examples and presets for different tasks.

cosmos-predict1
Cosmos-Predict1 is a specialized branch of Cosmos World Foundation Models (WFMs) focused on future state prediction, offering diffusion-based and autoregressive-based world foundation models for Text2World and Video2World generation. It includes image and video tokenizers for efficient tokenization, along with post-training and pre-training scripts for Physical AI builders. The tool provides various models for different tasks such as text to visual world generation, video-based future visual world generation, and tokenization of images and videos.
glimpse
Glimpse is a blazingly fast tool for peeking at codebases, offering features like fast parallel file processing, tree-view of codebase structure, source code content viewing, token counting with multiple backends, configurable defaults, clipboard support, customizable file type detection, .gitignore respect, web content processing with Markdown conversion, Git repository support, and URL traversal with configurable depth. It supports token counting using Tiktoken or HuggingFace tokenizer backends, helping estimate context window usage for large language models. Glimpse can process local directories, multiple files, Git repositories, web pages, and convert content to Markdown. It offers various options for customization and configuration, including file type inclusions/exclusions, token counting settings, URL processing settings, and default exclude patterns. Glimpse is suitable for developers and data scientists looking to analyze codebases, estimate token counts, and process web content efficiently.
nlp-zero-to-hero
This repository provides a comprehensive guide to Natural Language Processing (NLP), covering topics from Tokenization to Transformer Architecture. It aims to equip users with a solid understanding of NLP concepts, evolution, and core intuition. The repository includes practical examples and hands-on experience to facilitate learning and exploration in the field of NLP.
llm-baselines
LLM-baselines is a modular codebase to experiment with transformers, inspired from NanoGPT. It provides a quick and easy way to train and evaluate transformer models on a variety of datasets. The codebase is well-documented and easy to use, making it a great resource for researchers and practitioners alike.
airhacks
This repository is a communication repository for airhacks.live events. Users can use `https://github.com/AdamBien/airhacks.git` for initial creation and `git pull` to update the local repository. Airhacks Discord Server: https://discord.gg/airhacks, Airhacks Meetup: https://www.meetup.com/airhacks, Adam Bien / Airhacks links: https://airhacks.industries