AI tools for Image
Related Jobs:
Related Tools:
ImageSorter.io
ImageSorter.io is a free online tool designed to help users sort and organize their images efficiently. Users can easily add images and use drag-and-drop functionality to rearrange them. The tool also offers a Pro version with additional features such as setting confidence thresholds and predicting image sorting based on tags. ImageSorter.io simplifies the image organization process and provides a user-friendly interface for managing image collections.
imagetomp3.com
imagetomp3.com is a website that allows users to convert images to MP3 files. Users can upload an image, and the website will convert it into an audio file. The site provides a simple and convenient way to create audio files from images, which can be useful for various purposes such as creating audio versions of visual content or generating unique sound effects. imagetomp3.com offers a user-friendly interface and quick conversion process, making it a handy tool for those looking to convert images to audio effortlessly.
Room AI
Room AI is an AI interior design tool that allows users to design their dream home with professional interior designs using easy-to-use AI software. Users can restyle existing rooms or generate new room designs from scratch, choose colors and materials, and visualize different design possibilities. The tool caters to homeowners, interior designers, real estate agents, and architects, offering a user-friendly interface with customization options and suggestions. Room AI collaborates with users and industry experts to provide a comprehensive interior design solution.
AI Image to Music Generator
AI Image to Music Generator is a tool that uses artificial intelligence to convert images into music. It analyzes various visual elements in the image using computer vision and generates diverse musical compositions in different genres and styles. The tool offers a simple operation interface, fast generation process, and no login requirement, providing users with the freedom to experiment with music creation. AI Image to Music Generator has applications in media & entertainment, advertising & marketing, personalized gifts, therapeutic tools, education, and casual creativity.
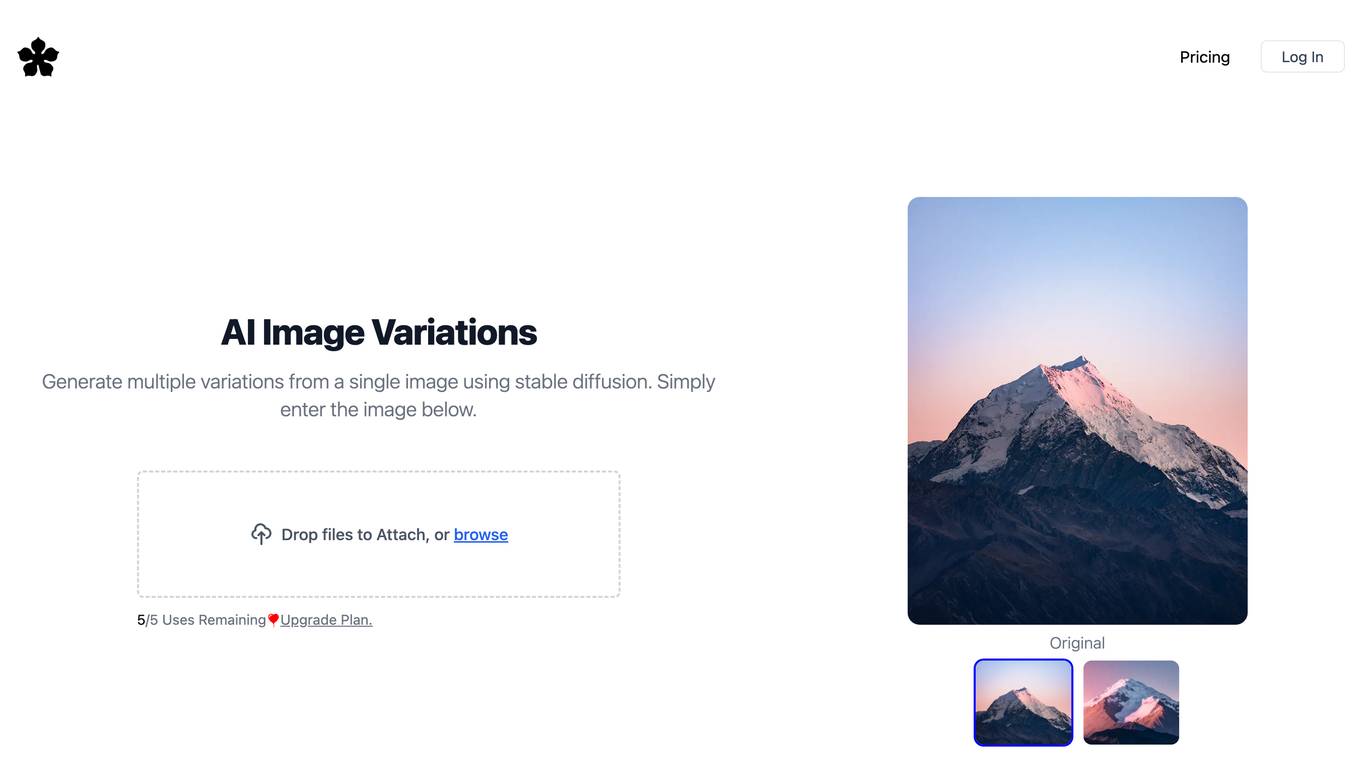
Image Variations
Image Variations is an AI image generator tool that allows users to create multiple variations from a single image using stable diffusion. It helps users generate unique and copyright-free images for their projects by adding noise to replicate the style of the original image. The tool is designed to be user-friendly and efficient, providing endless design possibilities for creative projects.
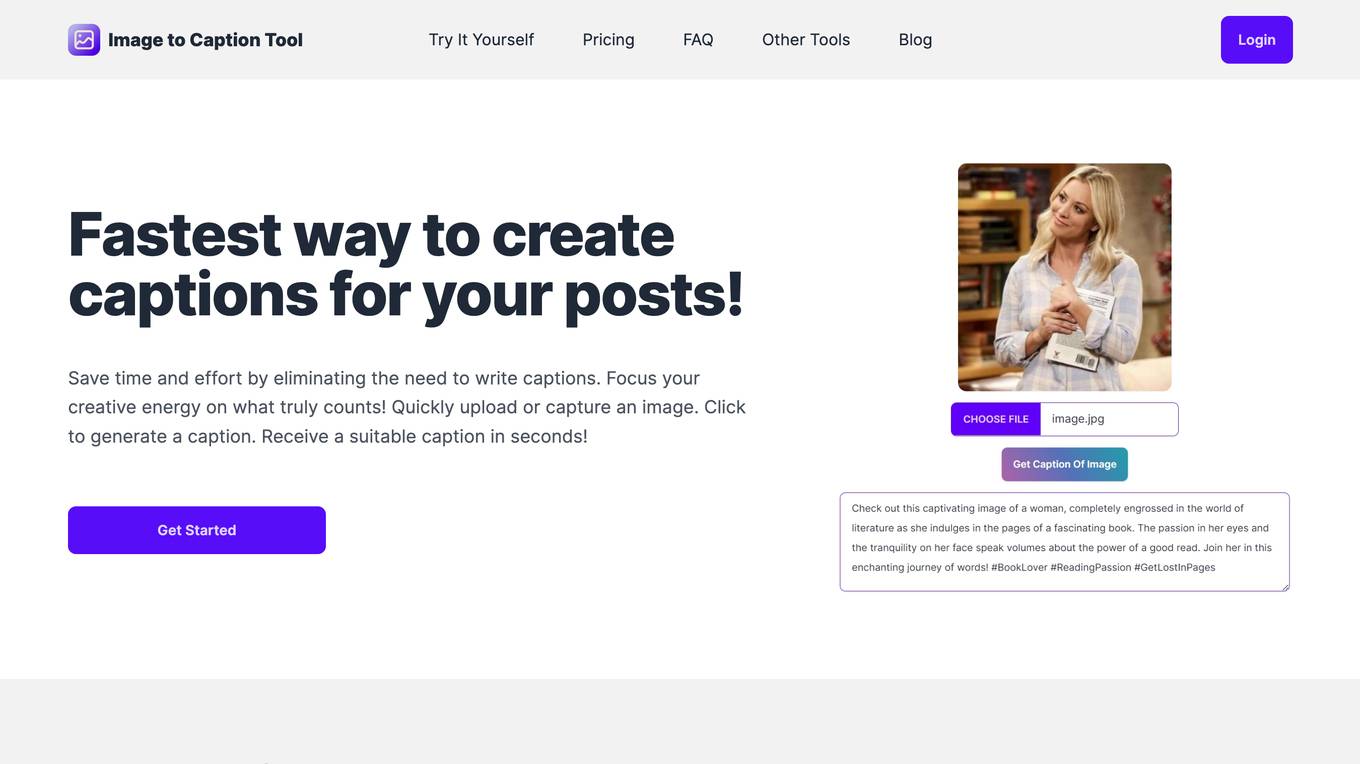
Image to Caption Tool
Image to Caption Tool is an AI application that provides a fast and efficient way to generate captions for images. Users can easily upload or capture an image and receive a suitable caption in seconds, saving time and effort. The tool offers different pricing plans to cater to various user needs and provides 24/7 email support. Currently supporting only English, the tool aims to enhance user experience by continuously adding more languages. With a user-friendly interface, Image to Caption Tool is designed to streamline the caption generation process for social media posts and other content.
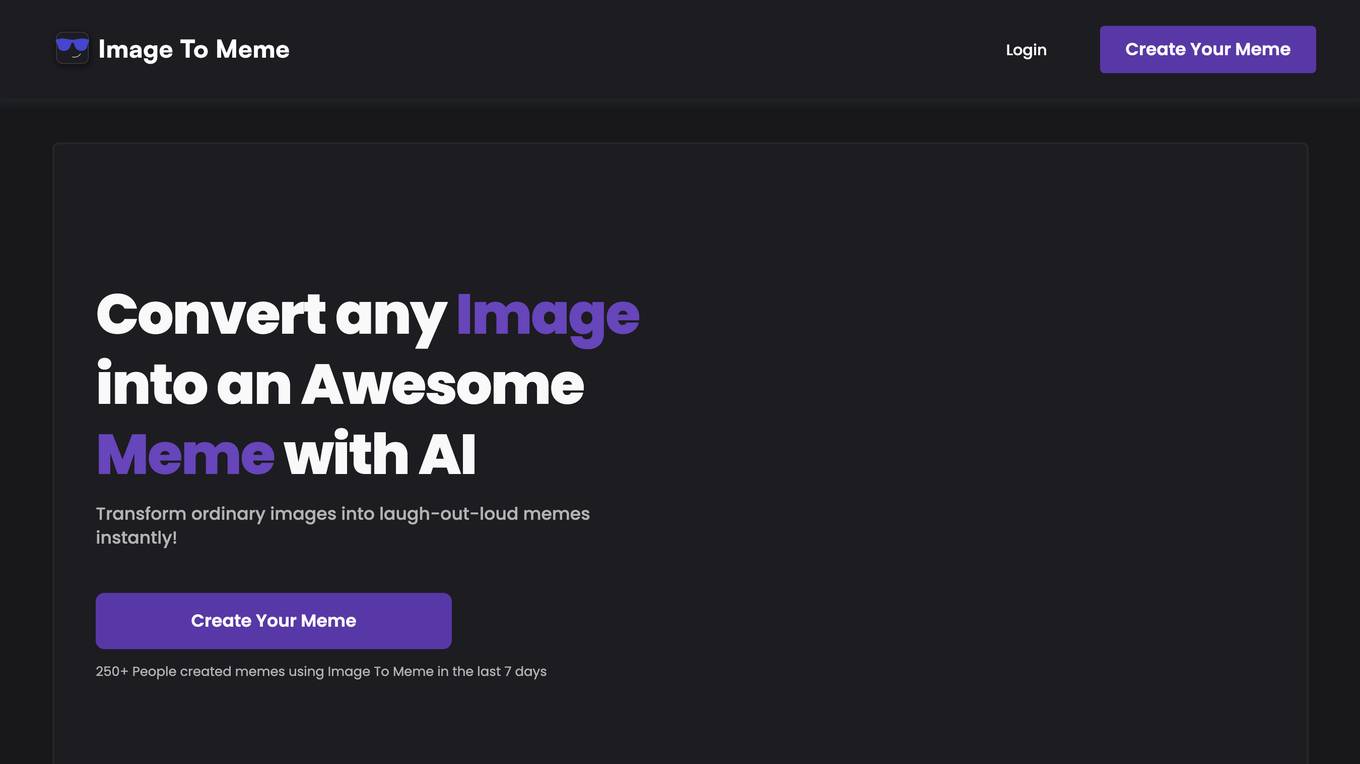
Image To Meme
Image To Meme is an online tool that allows users to convert any image into a meme. The tool uses artificial intelligence to generate memes that are both funny and relevant to the image. Image To Meme is easy to use and can be used to create memes for any occasion. The tool is free to use and offers a variety of features, including the ability to customize the text, colors, and alignment of the meme. Image To Meme is a great way to create funny and shareable memes with friends and family.
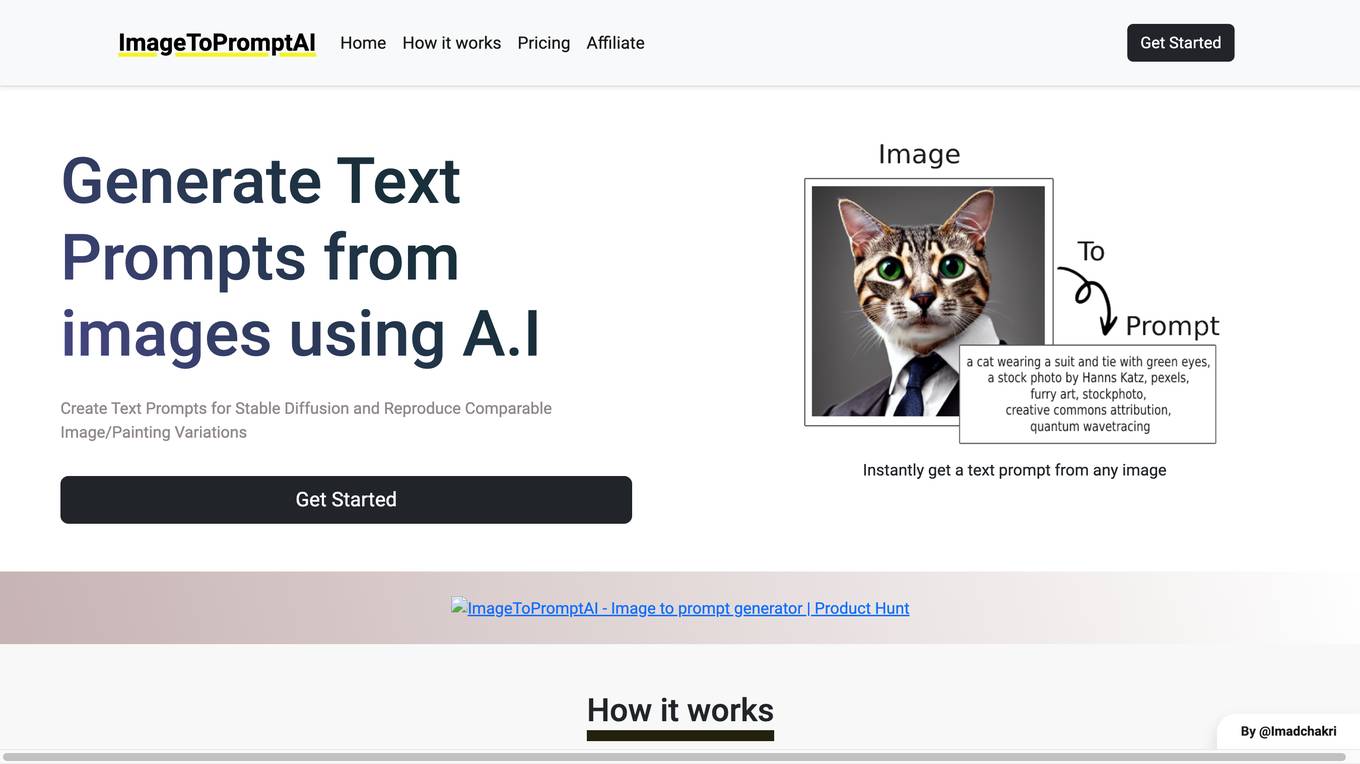
ImageToPromptAI
ImageToPromptAI is an AI tool that generates text prompts from images. Users can upload images and receive text prompts instantly. The tool aims to assist in creating stable diffusion and reproducing comparable image/painting variations. With a user-friendly interface, ImageToPromptAI offers different pricing tiers based on the number of images users want to transform into text prompts. The tool does not require any subscriptions, allowing users to pay only for what they need. Overall, ImageToPromptAI simplifies the process of generating text prompts from images using artificial intelligence.
Image to Caption Generator
The AI-Powered Image to Caption Generator is a revolutionary tool that utilizes artificial intelligence to analyze images and generate engaging captions tailored to each image. By recognizing key objects, scenes, and emotional tones in the image, the tool crafts captivating narratives that spark conversation and boost engagement. Users can save time, maintain brand consistency, and stay ahead of social media marketing trends with this innovative AI application.
Image Caption Generator
Image Caption Generator is a free online tool that uses AI to create compelling captions for images. It offers instant results, requires no login, is completely free, and supports multiple languages. Ideal for social media enthusiasts, bloggers, marketers, and content creators, the tool enhances storytelling through visuals by providing engaging and relevant captions. It helps in enhancing context, boosting engagement, improving accessibility, and SEO optimization. The AI-powered technology ensures accurate and impactful caption generation, making visual content more memorable and effective.
Image+
Image+ is a free AI image generator tool that allows users to create stunning and unique images effortlessly. With various options like generating negative prompts, selecting different models, and choosing from a wide range of styles, users can easily enhance their images with artistic effects. The tool provides high-quality image generation capabilities, making it ideal for artists, designers, and anyone looking to create visually appealing content.
Image Caption Generator
Image Caption Generator is a free online tool that uses artificial intelligence to generate captions for any image. With this tool, you can quickly and easily create engaging and informative captions for your social media posts, website content, or any other purpose. Simply upload an image, select a vibe, and add an optional prompt. The tool will then generate a list of captions that you can use. You can also use the tool to generate image descriptions, translate emojis, convert images to text, and generate hashtags for TikTok.
Image Editor AI
Image Editor AI is a web-based application that allows users to edit or create images using artificial intelligence. The application offers a variety of features, including the ability to remove backgrounds, upscale images, and create photorealistic images from scratch. Image Editor AI is easy to use and does not require any prior experience with image editing. The application is available for free and can be used on any device with an internet connection.
Image Variations
Image Variations is an AI-powered tool that allows you to generate variations of any input image. With just a few clicks, you can create unique and interesting variations of your photos, perfect for social media, marketing, or design projects.
Image Colorizer
Image Colorizer is an AI-powered photo editing tool that allows users to colorize, restore, enhance, retouch, and repair old photos. It uses advanced AI technology to automatically and instantly restore old photos, bringing them back to life. The tool is easy to use and offers a wide range of features to help users improve and restore their old pictures.
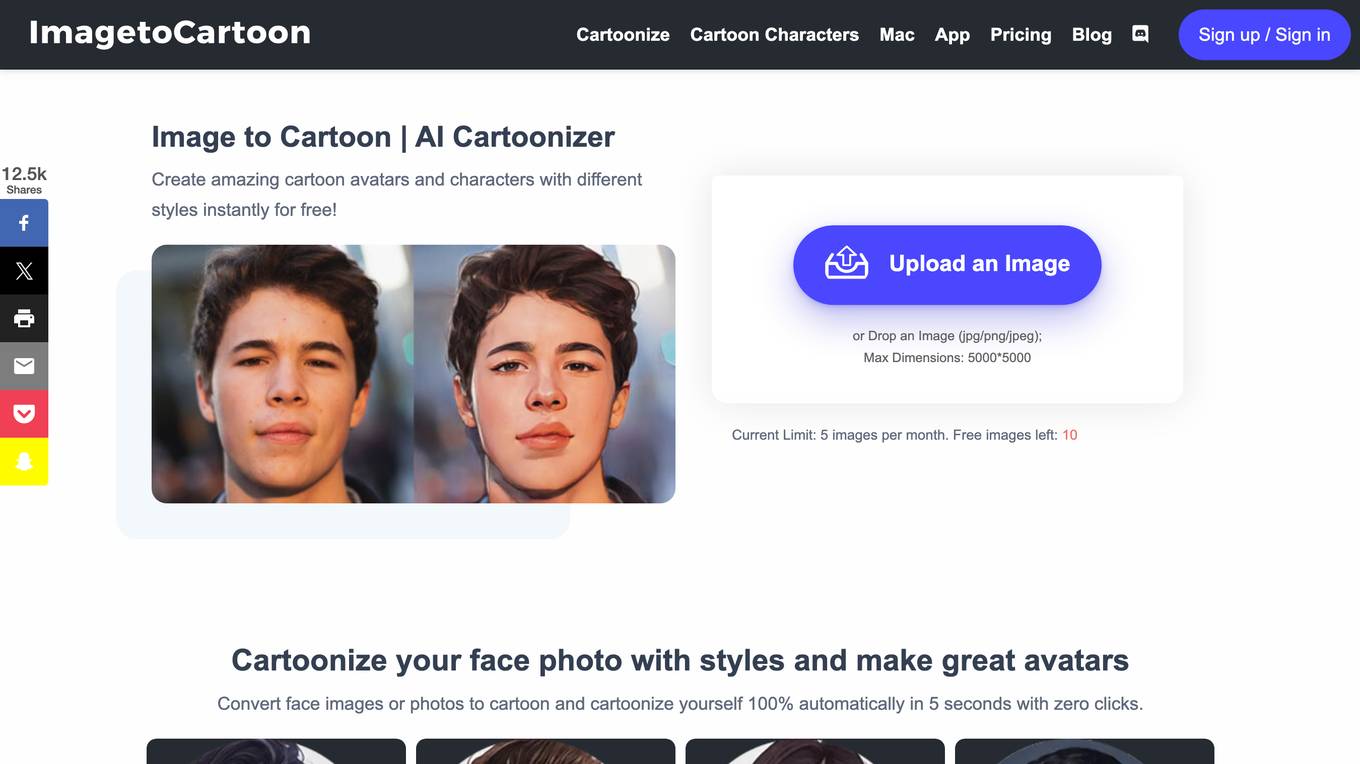
ImagetoCartoon
ImagetoCartoon is an AI-powered tool that allows users to convert images into cartoon avatars and characters. It offers a variety of styles and themes to choose from, making it suitable for various scenarios such as business, career, festival, lifestyle, sports, and superheroes. The tool is free to use, with a limit of 5 images per month. It provides free credits each month, allowing users to experiment with the tool without creating an account or making any payments. ImagetoCartoon ensures that no images are stored, and all images are cleared within 3 hours.
Image AI
Image AI is a powerful tool that allows you to generate unique and realistic images using artificial intelligence. With Image AI, you can create images of people, places, things, and even abstract concepts. The possibilities are endless! Image AI is perfect for artists, designers, writers, and anyone else who wants to create stunning visuals. With Image AI, you can:
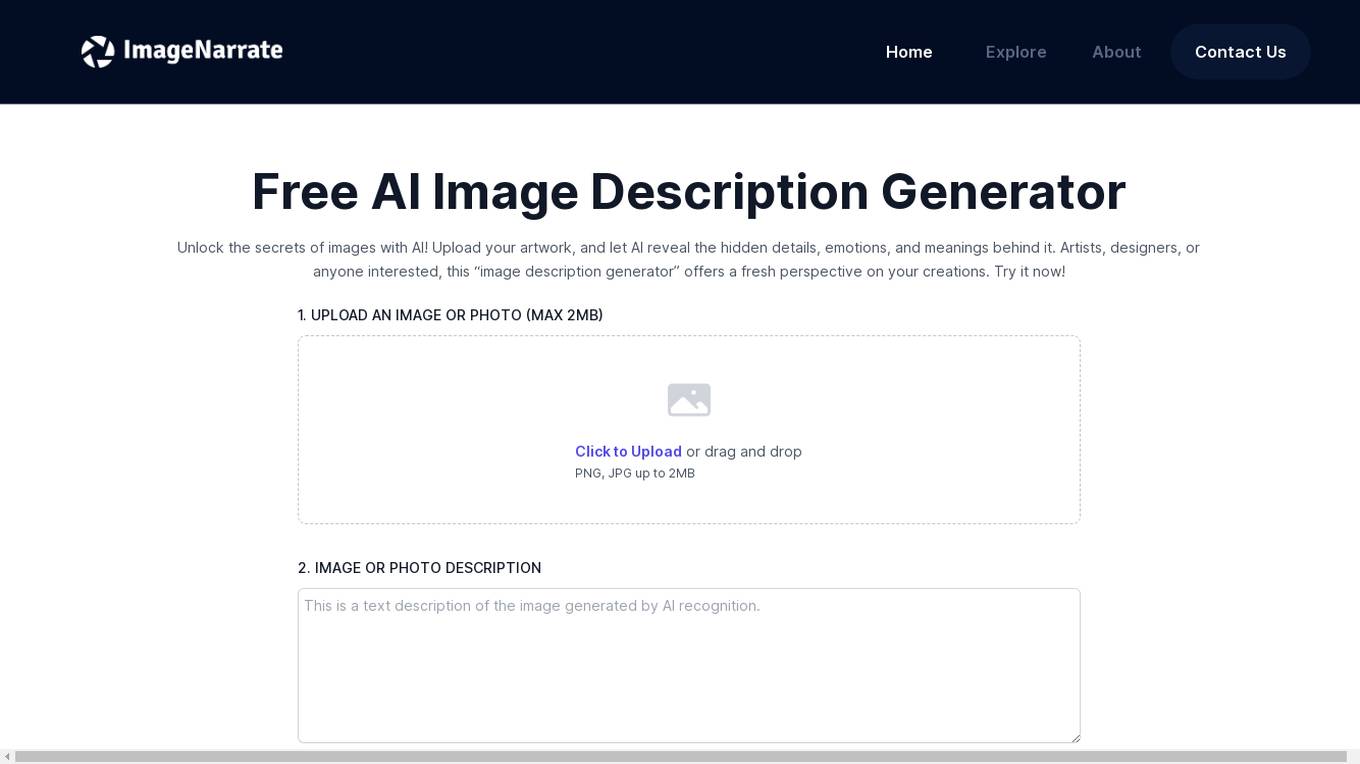
Image Narrate
This free AI image description generator tool allows users to upload an image and receive a detailed description of its contents. The tool utilizes advanced AI algorithms to analyze the image's elements, including color, shape, and texture, to generate a comprehensive description that captures the hidden meanings and emotions conveyed by the image. The tool is particularly useful for artists, designers, and anyone interested in gaining a deeper understanding of their own creations or exploring the hidden narratives within images.
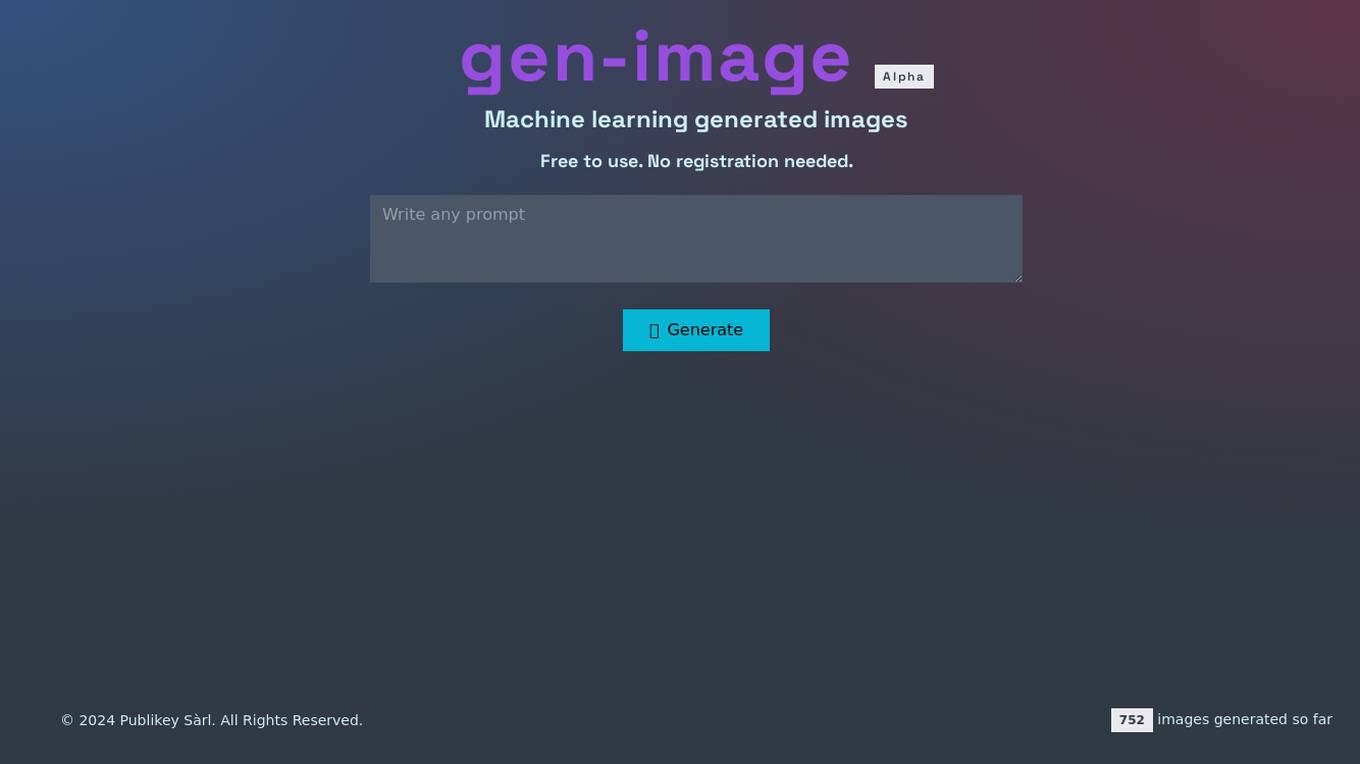
Gen-image Alpha
Gen-image Alpha is an AI-powered tool that generates images using machine learning algorithms. It allows users to create images for free without the need for registration. The tool is designed to provide high-quality generated images for various purposes. With a copyright notice of 2024 by Publikey Sàrl, users can access the tool to generate images without any limitations on the number of images created.

Image Marketing Group
Image Marketing Group is an AI-powered marketing agency that offers comprehensive branding, content marketing, SEO, website design and development, PPC advertising, AI services, design services, training services, and consulting. They specialize in transforming brands through storytelling, AI integration, visual design, and strategic marketing campaigns. With over 25 years of experience, they provide tailored solutions to enhance brand visibility, customer engagement, and business growth.




Identify movies, dramas, and animations by image
Just send us an image of a scene from a video work and i will guess the name of the work!

Image Generation with Selfcritique & Improvement
More accurate and easier image generation with self critique & improvement! Try it now
Easy Image Maker
Question-and-answer style image design agent, solving the problem of not knowing how to describe design parameters to GPT.
The Ultimate Image Generator
Highly optimized prompts and top secret refinements to create the perfect image every time...

Reliable Image Generator with LGTM Overlay
Efficiently generates images and overlays 'LGTM'
manga-image-translator
Translate texts in manga/images. Some manga/images will never be translated, therefore this project is born. * Image/Manga Translator * Samples * Online Demo * Disclaimer * Installation * Pip/venv * Poetry * Additional instructions for **Windows** * Docker * Hosting the web server * Using as CLI * Setting Translation Secrets * Using with Nvidia GPU * Building locally * Usage * Batch mode (default) * Demo mode * Web Mode * Api Mode * Related Projects * Docs * Recommended Modules * Tips to improve translation quality * Options * Language Code Reference * Translators Reference * GPT Config Reference * Using Gimp for rendering * Api Documentation * Synchronous mode * Asynchronous mode * Manual translation * Next steps * Support Us * Thanks To All Our Contributors :
ImageIndexer
LLMII is a tool that uses a local AI model to label metadata and index images without relying on cloud services or remote APIs. It runs a visual language model on your computer to generate captions and keywords for images, enhancing their metadata for indexing, searching, and organization. The tool can be run multiple times on the same image files, allowing for adding new data, regenerating data, and discovering files with issues. It supports various image formats, offers a user-friendly GUI, and can utilize GPU acceleration for faster processing. LLMII requires Python 3.8 or higher and operates directly on image file metadata fields like MWG:Keyword and XMP:Identifier.
azhpc-images
This repository contains scripts for installing HPC and AI libraries and tools to build Azure HPC/AI images. It streamlines the process of provisioning compute-intensive workloads and crafting advanced AI models in the cloud, ensuring efficiency and reliability in deployments.
Medical_Image_Analysis
The Medical_Image_Analysis repository focuses on X-ray image-based medical report generation using large language models. It provides pre-trained models and benchmarks for CheXpert Plus dataset, context sample retrieval for X-ray report generation, and pre-training on high-definition X-ray images. The goal is to enhance diagnostic accuracy and reduce patient wait times by improving X-ray report generation through advanced AI techniques.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.
dstoolkit-text2sql-and-imageprocessing
This repository provides sample code for improving RAG applications with rich data sources including SQL Warehouses and documents analysed with Azure Document Intelligence. It includes components for Text2SQL generation and querying, linking Azure Document Intelligence with AI Search for processing complex documents, and deploying AI search indexes. The plugins and skills aim to enhance response quality in RAG applications by accessing and pulling data from SQL tables, drawing insights from complex charts and images, and intelligently grouping similar sentences.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.

civitai
Civitai is a platform where people can share their stable diffusion models (textual inversions, hypernetworks, aesthetic gradients, VAEs, and any other crazy stuff people do to customize their AI generations), collaborate with others to improve them, and learn from each other's work. The platform allows users to create an account, upload their models, and browse models that have been shared by others. Users can also leave comments and feedback on each other's models to facilitate collaboration and knowledge sharing.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.
djl-demo
The Deep Java Library (DJL) is a framework-agnostic Java API for deep learning. It provides a unified interface to popular deep learning frameworks such as TensorFlow, PyTorch, and MXNet. DJL makes it easy to develop deep learning applications in Java, and it can be used for a variety of tasks, including image classification, object detection, natural language processing, and speech recognition.

kaapana
Kaapana is an open-source toolkit for state-of-the-art platform provisioning in the field of medical data analysis. The applications comprise AI-based workflows and federated learning scenarios with a focus on radiological and radiotherapeutic imaging. Obtaining large amounts of medical data necessary for developing and training modern machine learning methods is an extremely challenging effort that often fails in a multi-center setting, e.g. due to technical, organizational and legal hurdles. A federated approach where the data remains under the authority of the individual institutions and is only processed on-site is, in contrast, a promising approach ideally suited to overcome these difficulties. Following this federated concept, the goal of Kaapana is to provide a framework and a set of tools for sharing data processing algorithms, for standardized workflow design and execution as well as for performing distributed method development. This will facilitate data analysis in a compliant way enabling researchers and clinicians to perform large-scale multi-center studies. By adhering to established standards and by adopting widely used open technologies for private cloud development and containerized data processing, Kaapana integrates seamlessly with the existing clinical IT infrastructure, such as the Picture Archiving and Communication System (PACS), and ensures modularity and easy extensibility.

emgucv
Emgu CV is a cross-platform .Net wrapper for the OpenCV image-processing library. It allows OpenCV functions to be called from .NET compatible languages. The wrapper can be compiled by Visual Studio, Unity, and "dotnet" command, and it can run on Windows, Mac OS, Linux, iOS, and Android.
Awesome-Segment-Anything
The Segment Anything Model (SAM) is a powerful tool that allows users to segment any object in an image with just a few clicks. This makes it a great tool for a variety of tasks, such as object detection, tracking, and editing. SAM is also very easy to use, making it a great option for both beginners and experienced users.

ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.
albumentations
Albumentations is a Python library for image augmentation. Image augmentation is used in deep learning and computer vision tasks to increase the quality of trained models. The purpose of image augmentation is to create new training samples from the existing data.

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.

chaiNNer
ChaiNNer is a node-based image processing GUI aimed at making chaining image processing tasks easy and customizable. It gives users a high level of control over their processing pipeline and allows them to perform complex tasks by connecting nodes together. ChaiNNer is cross-platform, supporting Windows, MacOS, and Linux. It features an intuitive drag-and-drop interface, making it easy to create and modify processing chains. Additionally, ChaiNNer offers a wide range of nodes for various image processing tasks, including upscaling, denoising, sharpening, and color correction. It also supports batch processing, allowing users to process multiple images or videos at once.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.