AI tools for Arxiv
Related Tools:
arXiv
arXiv.org is a free distribution service and an open-access archive for nearly 2.4 million scholarly articles in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance, statistics, electrical engineering and systems science, and economics. Materials on this site are not peer-reviewed by arXiv.
ArXiv Pulse
ArXiv Pulse is an AI tool designed to help researchers and innovators stay informed on the latest research papers without feeling overwhelmed. It provides clear and easy-to-read summaries of arXiv preprints that are directly relevant to the user's research, delivered consistently in a digestible format. With ArXiv Pulse, users can effortlessly keep up with the latest developments in their field, receive personalized research insights, and get curated summaries tailored to their interests.
ArxivPaperAI
ArxivPaperAI is an AI-powered research paper summarizer that helps you quickly and easily understand the key points of academic papers. With ArxivPaperAI, you can:
Summarize Paper .com
Summarize Paper .com is an open-source AI tool that provides concise, understandable, and insightful summaries of the latest research articles on arXiv. The tool uses AI to generate key points and layman's summaries of research papers, making it easy for users to stay up-to-date with the latest developments in their field. In addition to its summary service, Summarize Paper .com also offers an AI assistant that can answer questions about arXiv papers. The tool is designed to make it easy for researchers, students, journalists, and anyone else who wants to stay informed about the latest research to access and understand the latest findings.
Emergent Mind
Emergent Mind is a website that provides access to trending AI papers. Users can browse papers by category, week, month, or year. The website also provides summaries of trending AI papers on Twitter.
ScholarAI
ScholarAI is an AI-powered scientific research tool that offers a wide range of features to help users navigate and extract insights from scientific literature. With access to over 200 million peer-reviewed articles, ScholarAI allows users to conduct abstract searches, literature mapping, PDF reading, literature reviews, gap analysis, direct Q&A, table and figure extraction, citation management, and project management. The tool is designed to accelerate the research process and provide tailored scientific insights to users.

CVF Open Access
The Computer Vision Foundation (CVF) is a non-profit organization dedicated to advancing the field of computer vision. CVF organizes several conferences and workshops each year, including the International Conference on Computer Vision (ICCV), the Conference on Computer Vision and Pattern Recognition (CVPR), and the Winter Conference on Applications of Computer Vision (WACV). CVF also publishes the International Journal of Computer Vision (IJCV) and the Computer Vision and Image Understanding (CVIU) journal. The CVF Open Access website provides access to the full text of all CVF-sponsored conference papers. These papers are available for free download in PDF format. The CVF Open Access website also includes links to the arXiv versions of the papers, where available.
yesnoerror
yesnoerror is an autonomous AI agent developed by DeSci initiative that scans scientific papers to uncover errors, inconsistencies, and flawed methods that human reviewers may have missed. The tool utilizes blockchain technology and AI to audit science at scale, aiming to enhance scientific integrity through automated error detection. By analyzing papers from renowned repositories like arXiv, bioRxiv, and medRxiv, yesnoerror helps researchers identify and correct critical issues in research, such as mathematical errors and data discrepancies.
Alpha Inquire
Alpha Inquire is an AI-powered research tool that allows users to create personalized AI agents to read and summarize news articles on topics of interest. Users can configure their agents to gather information from various sources like websites, RSS feeds, Google News, and arXiv. The tool simplifies the process of staying informed by providing daily digests with relevant summaries, helping users save time and stay up to date with the latest news. Alpha Inquire is designed to enhance productivity and knowledge acquisition by leveraging AI technology to automate the reading and summarization process.
ScienceCast
ScienceCast is an AI-powered platform that aims to make scientific research more accessible and impactful by transforming complex preprints into brief audio summaries and customizable presentation-ready slides. Leveraging advanced AI technology, ScienceCast empowers researchers to communicate their work effectively and enables anyone interested in science to understand it. The platform bridges the gap between researchers and audiences, creating a world where knowledge is easier to share, understand, and create with.
Undermind
Undermind is an AI-powered scientific research assistant that revolutionizes the way researchers access and analyze academic papers. By utilizing intelligent language models, Undermind reads and synthesizes information from hundreds of papers to provide accurate and comprehensive results. Researchers can describe their queries in natural language, and Undermind assists in finding relevant papers, brainstorming questions, and discovering crucial insights. Trusted by researchers across various fields, Undermind offers a unique approach to literature search, surpassing traditional search engines in accuracy and efficiency.
ArtiverseHub
ArtiverseHub is a multi-platform AI image generator that allows users to create images from text using various AI models, including DALL-E, Leonardo.ai, and Stability.ai. It offers a seamless and personalized experience, enabling users to switch between platforms and customize their image generation process. With ArtiverseHub, users can transform their ideas into dynamic and lifelike visuals, catering to diverse creative needs and producing high-quality assets with speed and consistency.
Arrival
Arrival is a cutting-edge software solution that allows users to design 3D virtual spaces with AI assistance and drag-and-drop functionality. It enables effortless creation of immersive environments by utilizing a built-in text-to-3D ML model, a user-friendly drag & drop interface, and seamless integration with leading virtual worlds and video gaming marketplaces.
Healthcare IT News Hub
The website page text provides a glimpse into the healthcare IT industry, covering topics such as telehealth, AI advancements, and patient care. It discusses various news articles, acquisitions, funding rounds, and research findings related to healthcare technology. The content highlights the importance of telehealth, AI integration, patient engagement, and the impact of technology on healthcare delivery.
EssayWriters.ai
EssayWriters.ai is an AI essay writing tool that allows users to generate essays of various lengths and types with the help of artificial intelligence. Users can specify their topic, word count, and essay type to receive a tailored essay that meets their requirements. The tool ensures plagiarism-free content and offers both free and premium plans for users to access its features. With a user-friendly interface, EssayWriters.ai aims to assist individuals in creating high-quality essays efficiently and effectively.
PandaRocket
PandaRocket is an AI-powered suite designed to support various eCommerce business models. It offers a range of tools for product research, content creation, and store management. With features like market analysis, customer segmentation, and predictive intelligence, PandaRocket helps users make data-driven decisions to optimize their online stores and maximize profits.
Luna.ai
Luna.ai is a sales automation tool that uses artificial intelligence (AI) to help businesses find and engage with potential customers. The tool offers a range of features, including lead generation, email marketing, and customer relationship management (CRM). Luna.ai is designed to help businesses improve their sales performance by automating tasks and providing insights into customer behavior.
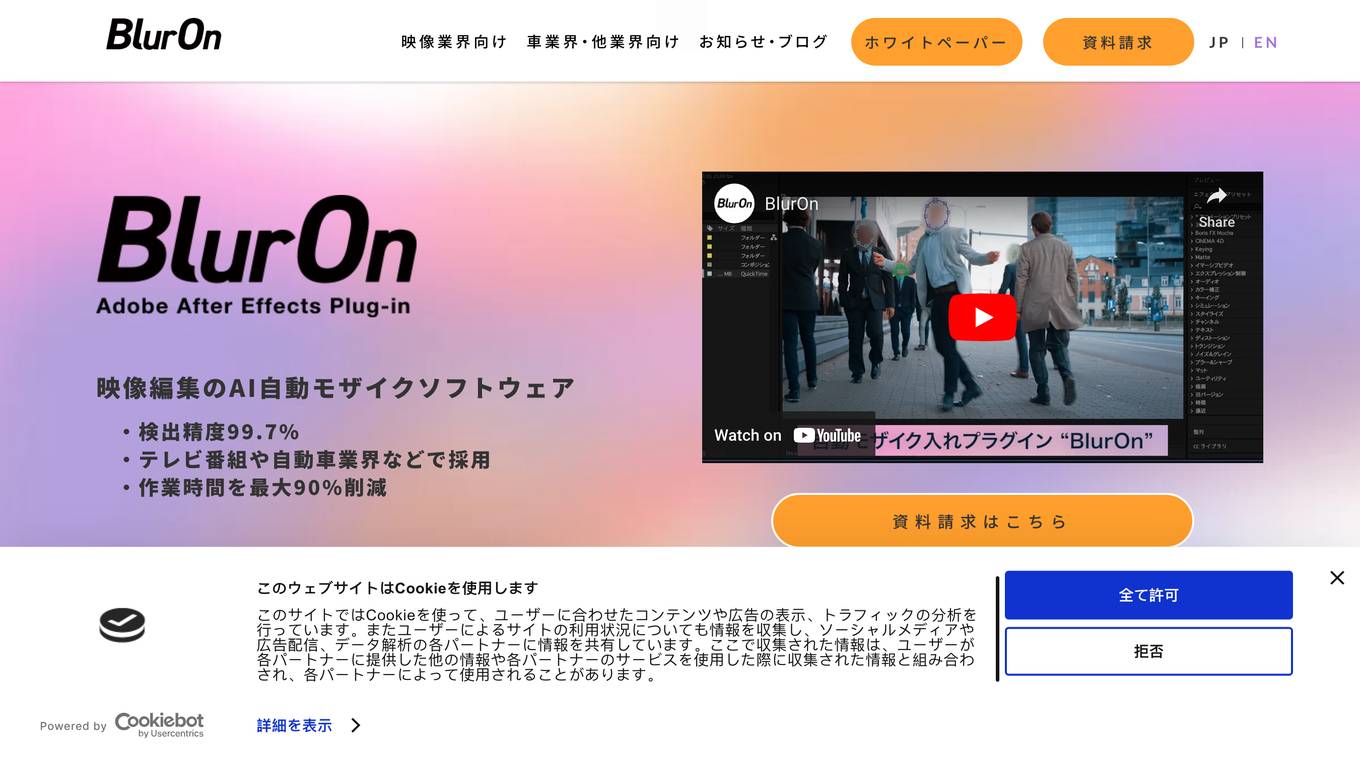
BlurOn
BlurOn is an AI tool for automatic mosaic insertion in video editing. It offers high accuracy detection of faces, heads, and license plates, complying with regulations like GDPR. The tool allows for proper anonymization of personal information in videos, supports automatic processing upon server arrival, and provides cost-effective video editing services. BlurOn has been recognized with awards in the industry and is used in various sectors such as the automotive industry, insurance companies, and overseas for video data processing.
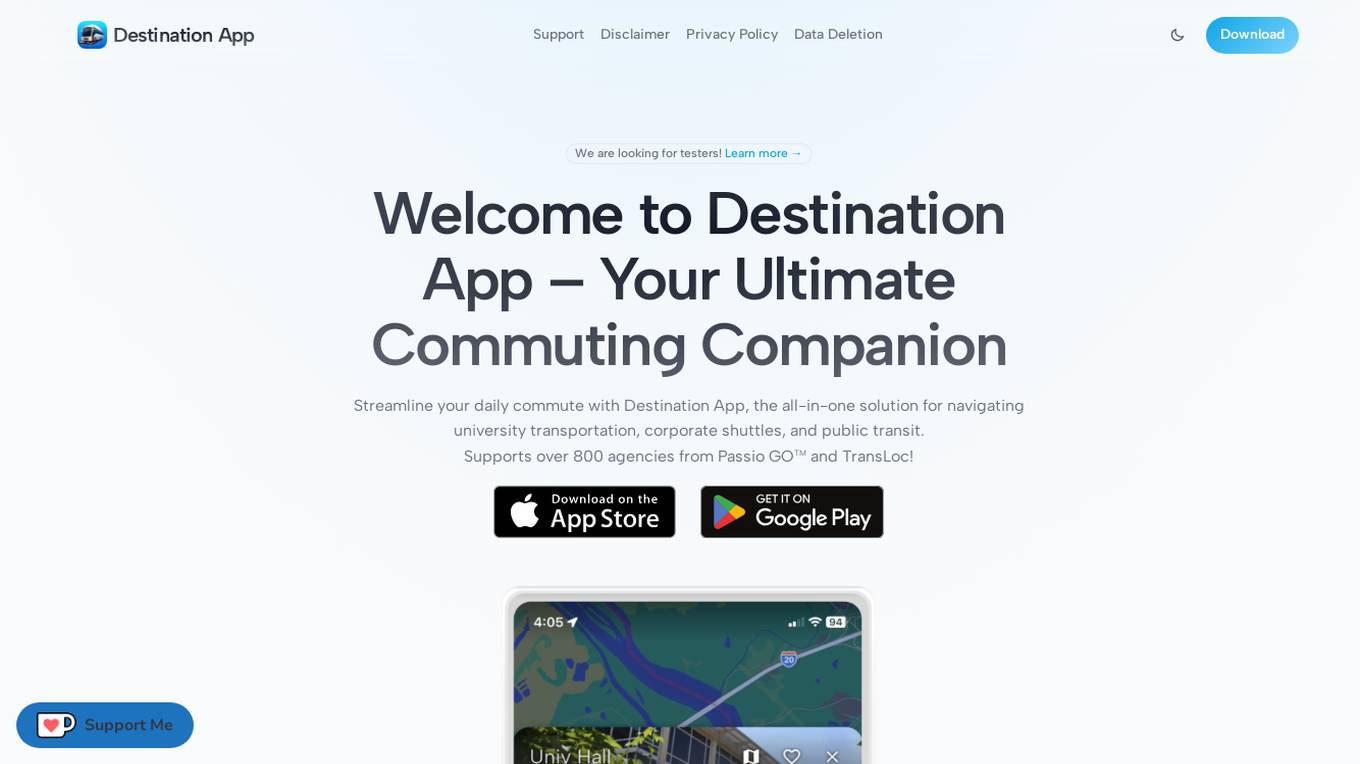
Destination App
Destination App is the ultimate commuting companion that streamlines daily commutes by providing live arrival times, bus schedules, saved trips, route presets, community reports, AI integration, trip planner, and more. With support for over 800 transportation agencies, users can access real-time tracking, ETAs, personalized content powered by AI, and advanced iOS features for an enhanced commuting experience.


Research Paper Explorer
Explains Arxiv papers with examples, analogies, and direct PDF links.
MyScaleGPT
This GPT uses external knowledge of ArXiv and Wikipedia with MyScale vector database to boost your chatting experience.
Pymage
Enginyer de Python per a la creació i manipulació d'imatges i arxius.Fàcil,clar i Català.
ArtiVisio
je suis l'IA expert en création et de vous aider à visualiser et décrire une création avec différents matériaux
TrainTalk
Your personal advisor for eco-friendly train travel. Let's plan your next journey together!

AIDE POUR TROUVER DES COLIS PERDU
JE VEUT UNE AIDE POU TROUVER DES COLIS POUR REVENDRE DES COLIS DE VENTE AUX ENCHERE OU COLIS PERDU

IQ Test Assistant
An AI conducting 30-question IQ tests, assessing and providing detailed feedback.

tods-arxiv-daily-paper
This repository provides a tool for fetching and summarizing daily papers from the arXiv repository. It allows users to stay updated with the latest research in various fields by automatically retrieving and summarizing papers on a daily basis. The tool simplifies the process of accessing and digesting academic papers, making it easier for researchers and enthusiasts to keep track of new developments in their areas of interest.
arxiv-mcp-server
The ArXiv MCP Server acts as a bridge between AI assistants and arXiv's research repository, enabling AI models to search for and access papers programmatically through the Message Control Protocol (MCP). It offers features like paper search, access, listing, local storage, and research prompts. Users can install it via Smithery or manually for Claude Desktop. The server provides tools for paper search, download, listing, and reading, along with specialized prompts for paper analysis. Configuration can be done through environment variables, and testing is supported with a test suite. The tool is released under the MIT License and is developed by the Pearl Labs Team.

llm-verified-with-monte-carlo-tree-search
This prototype synthesizes verified code with an LLM using Monte Carlo Tree Search (MCTS). It explores the space of possible generation of a verified program and checks at every step that it's on the right track by calling the verifier. This prototype uses Dafny, Coq, Lean, Scala, or Rust. By using this technique, weaker models that might not even know the generated language all that well can compete with stronger models.

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.

MotionLLM
MotionLLM is a framework for human behavior understanding that leverages Large Language Models (LLMs) to jointly model videos and motion sequences. It provides a unified training strategy, dataset MoVid, and MoVid-Bench for evaluating human behavior comprehension. The framework excels in captioning, spatial-temporal comprehension, and reasoning abilities.

MMC
This repository, MMC, focuses on advancing multimodal chart understanding through large-scale instruction tuning. It introduces a dataset supporting various tasks and chart types, a benchmark for evaluating reasoning capabilities over charts, and an assistant achieving state-of-the-art performance on chart QA benchmarks. The repository provides data for chart-text alignment, benchmarking, and instruction tuning, along with existing datasets used in experiments. Additionally, it offers a Gradio demo for the MMCA model.
FlipAttack
FlipAttack is a jailbreak attack tool designed to exploit black-box Language Model Models (LLMs) by manipulating text inputs. It leverages insights into LLMs' autoregressive nature to construct noise on the left side of the input text, deceiving the model and enabling harmful behaviors. The tool offers four flipping modes to guide LLMs in denoising and executing malicious prompts effectively. FlipAttack is characterized by its universality, stealthiness, and simplicity, allowing users to compromise black-box LLMs with just one query. Experimental results demonstrate its high success rates against various LLMs, including GPT-4o and guardrail models.
onefilellm
OneFileLLM is a command-line tool that streamlines the creation of information-dense prompts for large language models (LLMs). It aggregates and preprocesses data from various sources, compiling them into a single text file for quick use. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, token count reporting, and XML encapsulation of output for improved LLM performance. Users can easily access private GitHub repositories by generating a personal access token. The tool's output is encapsulated in XML tags to enhance LLM understanding and processing.

LLaSA_training
LLaSA_training is a repository focused on training models for speech synthesis using a large amount of open-source speech data. The repository provides instructions for finetuning models and offers pre-trained models for multilingual speech synthesis. It includes tools for training, data downloading, and data processing using specialized tokenizers for text and speech sequences. The repository also supports direct usage on Hugging Face platform with specific codecs and collections.

RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.

xlstm-jax
The xLSTM-jax repository contains code for training and evaluating the xLSTM model on language modeling using JAX. xLSTM is a Recurrent Neural Network architecture that improves upon the original LSTM through Exponential Gating, normalization, stabilization techniques, and a Matrix Memory. It is optimized for large-scale distributed systems with performant triton kernels for faster training and inference.
HuggingArxivLLM
HuggingArxiv is a tool designed to push research papers related to large language models from Arxiv. It helps users stay updated with the latest developments in the field of large language models by providing notifications and access to relevant papers.

lloco
LLoCO is a technique that learns documents offline through context compression and in-domain parameter-efficient finetuning using LoRA, which enables LLMs to handle long context efficiently.

DB-GPT
DB-GPT is a personal database administrator that can solve database problems by reading documents, using various tools, and writing analysis reports. It is currently undergoing an upgrade. **Features:** * **Online Demo:** * Import documents into the knowledge base * Utilize the knowledge base for well-founded Q&A and diagnosis analysis of abnormal alarms * Send feedbacks to refine the intermediate diagnosis results * Edit the diagnosis result * Browse all historical diagnosis results, used metrics, and detailed diagnosis processes * **Language Support:** * English (default) * Chinese (add "language: zh" in config.yaml) * **New Frontend:** * Knowledgebase + Chat Q&A + Diagnosis + Report Replay * **Extreme Speed Version for localized llms:** * 4-bit quantized LLM (reducing inference time by 1/3) * vllm for fast inference (qwen) * Tiny LLM * **Multi-path extraction of document knowledge:** * Vector database (ChromaDB) * RESTful Search Engine (Elasticsearch) * **Expert prompt generation using document knowledge** * **Upgrade the LLM-based diagnosis mechanism:** * Task Dispatching -> Concurrent Diagnosis -> Cross Review -> Report Generation * Synchronous Concurrency Mechanism during LLM inference * **Support monitoring and optimization tools in multiple levels:** * Monitoring metrics (Prometheus) * Flame graph in code level * Diagnosis knowledge retrieval (dbmind) * Logical query transformations (Calcite) * Index optimization algorithms (for PostgreSQL) * Physical operator hints (for PostgreSQL) * Backup and Point-in-time Recovery (Pigsty) * **Continuously updated papers and experimental reports** This project is constantly evolving with new features. Don't forget to star ⭐ and watch 👀 to stay up to date.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.

IDvs.MoRec
This repository contains the source code for the SIGIR 2023 paper 'Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited'. It provides resources for evaluating foundation, transferable, multi-modal, and LLM recommendation models, along with datasets, pre-trained models, and training strategies for IDRec and MoRec using in-batch debiased cross-entropy loss. The repository also offers large-scale datasets, code for SASRec with in-batch debias cross-entropy loss, and information on joining the lab for research opportunities.

awesome-llm-attributions
This repository focuses on unraveling the sources that large language models tap into for attribution or citation. It delves into the origins of facts, their utilization by the models, the efficacy of attribution methodologies, and challenges tied to ambiguous knowledge reservoirs, biases, and pitfalls of excessive attribution.

TRACE
TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.
MoBA
MoBA (Mixture of Block Attention) is an innovative approach for long-context language models, enabling efficient processing of long sequences by dividing the full context into blocks and introducing a parameter-less gating mechanism. It allows seamless transitions between full and sparse attention modes, enhancing efficiency without compromising performance. MoBA has been deployed to support long-context requests and demonstrates significant advancements in efficient attention computation for large language models.

AceCoder
AceCoder is a tool that introduces a fully automated pipeline for synthesizing large-scale reliable tests used for reward model training and reinforcement learning in the coding scenario. It curates datasets, trains reward models, and performs RL training to improve coding abilities of language models. The tool aims to unlock the potential of RL training for code generation models and push the boundaries of LLM's coding abilities.