
ds-ml-bootcamp
Data Science and Machine Learning Bootcamp.
Stars: 87
The DS-ML Bootcamp repository is a comprehensive resource for a one-month intensive bootcamp that covers the full machine learning workflow. It includes lessons, code examples, and resources to take participants from zero to hands-on projects. The goal is to move from unreal to real, from unimaginable to imaginable, by practicing the entire data science/machine learning journey step by step in just one month.
README:
Welcome to the Data Science & Machine Learning Bootcamp repository! 🚀
This repo contains all the lessons, code examples, and resources used during our one-month intensive bootcamp.
The program is designed to take participants from zero to hands-on projects, covering the full ML workflow:
- Collect Data
- Preprocess Data
- Split into Train/Test
- Choose Model
- Train Model
- Evaluate Model
- Deploy Model
Our mission is simple:
Move from unreal to real, from unimaginable to imaginable — by practicing the entire DS/ML journey, step by step, in just one month.
📘 Tip:
You can clone the repo, open Jupyter/VS Code, and follow along while watching each lesson for hands-on learning.
This bootcamp is proudly hosted by:
Together, our goal is to empower the next generation of data scientists.
This bootcamp is fully sponsored by:
⭐ If you find this useful, don’t forget to star the repo!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ds-ml-bootcamp
Similar Open Source Tools
ds-ml-bootcamp
The DS-ML Bootcamp repository is a comprehensive resource for a one-month intensive bootcamp that covers the full machine learning workflow. It includes lessons, code examples, and resources to take participants from zero to hands-on projects. The goal is to move from unreal to real, from unimaginable to imaginable, by practicing the entire data science/machine learning journey step by step in just one month.
ai-that-works
AI That Works is a weekly live coding event focused on exploring advanced AI engineering techniques and tools to take AI applications from demo to production. The sessions cover topics such as token efficiency, downsides of JSON, writing drop-ins for coding agents, and advanced tricks like .shims for coding tools. The event aims to help participants get the most out of today's AI models and tools through live coding, Q&A sessions, and production-ready insights.
promptbook
Promptbook is a library designed to build responsible, controlled, and transparent applications on top of large language models (LLMs). It helps users overcome limitations of LLMs like hallucinations, off-topic responses, and poor quality output by offering features such as fine-tuning models, prompt-engineering, and orchestrating multiple prompts in a pipeline. The library separates concerns, establishes a common format for prompt business logic, and handles low-level details like model selection and context size. It also provides tools for pipeline execution, caching, fine-tuning, anomaly detection, and versioning. Promptbook supports advanced techniques like Retrieval-Augmented Generation (RAG) and knowledge utilization to enhance output quality.

AgentForge
AgentForge is a low-code framework tailored for the rapid development, testing, and iteration of AI-powered autonomous agents and Cognitive Architectures. It is compatible with a range of LLM models and offers flexibility to run different models for different agents based on specific needs. The framework is designed for seamless extensibility and database-flexibility, making it an ideal playground for various AI projects. AgentForge is a beta-testing ground and future-proof hub for crafting intelligent, model-agnostic autonomous agents.
AgentGym-RL
AgentGym-RL is a framework designed to train Long-Long Memory (LLM) agents for multi-turn interactive decision-making through Reinforcement Learning. It addresses challenges in training agents for real-world scenarios by supporting mainstream RL algorithms and introducing the ScalingInter-RL method for stable optimization. The framework includes modular components for environment, agent reasoning, and training pipelines. It offers diverse environments like Web Navigation, Deep Search, Digital Games, Embodied Tasks, and Scientific Tasks. AgentGym-RL also supports various online RL algorithms and post-training strategies. The tool aims to enhance agent performance and exploration capabilities through long-horizon planning and interaction with the environment.
ai-notes
Notes on AI state of the art, with a focus on generative and large language models. These are the "raw materials" for the https://lspace.swyx.io/ newsletter. This repo used to be called https://github.com/sw-yx/prompt-eng, but was renamed because Prompt Engineering is Overhyped. This is now an AI Engineering notes repo.

Controllable-RAG-Agent
This repository contains a sophisticated deterministic graph-based solution for answering complex questions using a controllable autonomous agent. The solution is designed to ensure that answers are solely based on the provided data, avoiding hallucinations. It involves various steps such as PDF loading, text preprocessing, summarization, database creation, encoding, and utilizing large language models. The algorithm follows a detailed workflow involving planning, retrieval, answering, replanning, content distillation, and performance evaluation. Heuristics and techniques implemented focus on content encoding, anonymizing questions, task breakdown, content distillation, chain of thought answering, verification, and model performance evaluation.

Slow_Thinking_with_LLMs
STILL is an open-source project exploring slow-thinking reasoning systems, focusing on o1-like reasoning systems. The project has released technical reports on enhancing LLM reasoning with reward-guided tree search algorithms and implementing slow-thinking reasoning systems using an imitate, explore, and self-improve framework. The project aims to replicate the capabilities of industry-level reasoning systems by fine-tuning reasoning models with long-form thought data and iteratively refining training datasets.
slime
Slime is an LLM post-training framework for RL scaling that provides high-performance training and flexible data generation capabilities. It connects Megatron with SGLang for efficient training and enables custom data generation workflows through server-based engines. The framework includes modules for training, rollout, and data buffer management, offering a comprehensive solution for RL scaling.

second-brain-ai-assistant-course
This open-source course teaches how to build an advanced RAG and LLM system using LLMOps and ML systems best practices. It helps you create an AI assistant that leverages your personal knowledge base to answer questions, summarize documents, and provide insights. The course covers topics such as LLM system architecture, pipeline orchestration, large-scale web crawling, model fine-tuning, and advanced RAG features. It is suitable for ML/AI engineers and data/software engineers & data scientists looking to level up to production AI systems. The course is free, with minimal costs for tools like OpenAI's API and Hugging Face's Dedicated Endpoints. Participants will build two separate Python applications for offline ML pipelines and online inference pipeline.

llms-learning
A repository sharing literatures and resources about Large Language Models (LLMs) and beyond. It includes tutorials, notebooks, course assignments, development stages, modeling, inference, training, applications, study, and basics related to LLMs. The repository covers various topics such as language models, transformers, state space models, multi-modal language models, training recipes, applications in autonomous driving, code, math, embodied intelligence, and more. The content is organized by different categories and provides comprehensive information on LLMs and related topics.

MMStar
MMStar is an elite vision-indispensable multi-modal benchmark comprising 1,500 challenge samples meticulously selected by humans. It addresses two key issues in current LLM evaluation: the unnecessary use of visual content in many samples and the existence of unintentional data leakage in LLM and LVLM training. MMStar evaluates 6 core capabilities across 18 detailed axes, ensuring a balanced distribution of samples across all dimensions.

llm-course
The LLM course is divided into three parts: 1. 🧩 **LLM Fundamentals** covers essential knowledge about mathematics, Python, and neural networks. 2. 🧑🔬 **The LLM Scientist** focuses on building the best possible LLMs using the latest techniques. 3. 👷 **The LLM Engineer** focuses on creating LLM-based applications and deploying them. For an interactive version of this course, I created two **LLM assistants** that will answer questions and test your knowledge in a personalized way: * 🤗 **HuggingChat Assistant**: Free version using Mixtral-8x7B. * 🤖 **ChatGPT Assistant**: Requires a premium account. ## 📝 Notebooks A list of notebooks and articles related to large language models. ### Tools | Notebook | Description | Notebook | |----------|-------------|----------| | 🧐 LLM AutoEval | Automatically evaluate your LLMs using RunPod |  | | 🥱 LazyMergekit | Easily merge models using MergeKit in one click. |  | | 🦎 LazyAxolotl | Fine-tune models in the cloud using Axolotl in one click. |  | | ⚡ AutoQuant | Quantize LLMs in GGUF, GPTQ, EXL2, AWQ, and HQQ formats in one click. |  | | 🌳 Model Family Tree | Visualize the family tree of merged models. |  | | 🚀 ZeroSpace | Automatically create a Gradio chat interface using a free ZeroGPU. |  |

merlin
Merlin is a groundbreaking model capable of generating natural language responses intricately linked with object trajectories of multiple images. It excels in predicting and reasoning about future events based on initial observations, showcasing unprecedented capability in future prediction and reasoning. Merlin achieves state-of-the-art performance on the Future Reasoning Benchmark and multiple existing multimodal language models benchmarks, demonstrating powerful multi-modal general ability and foresight minds.
miniLLMFlow
Mini LLM Flow is a 100-line minimalist LLM framework designed for agents, task decomposition, RAG, etc. It aims to be the framework used by LLMs, focusing on high-level programming paradigms while stripping away low-level implementation details. It serves as a learning resource and allows LLMs to design, build, and maintain projects themselves.

k2
K2 (GeoLLaMA) is a large language model for geoscience, trained on geoscience literature and fine-tuned with knowledge-intensive instruction data. It outperforms baseline models on objective and subjective tasks. The repository provides K2 weights, core data of GeoSignal, GeoBench benchmark, and code for further pretraining and instruction tuning. The model is available on Hugging Face for use. The project aims to create larger and more powerful geoscience language models in the future.
For similar tasks
morgana-form
MorGana Form is a full-stack form builder project developed using Next.js, React, TypeScript, Ant Design, PostgreSQL, and other technologies. It allows users to quickly create and collect data through survey forms. The project structure includes components, hooks, utilities, pages, constants, Redux store, themes, types, server-side code, and component packages. Environment variables are required for database settings, NextAuth login configuration, and file upload services. Additionally, the project integrates an AI model for form generation using the Ali Qianwen model API.
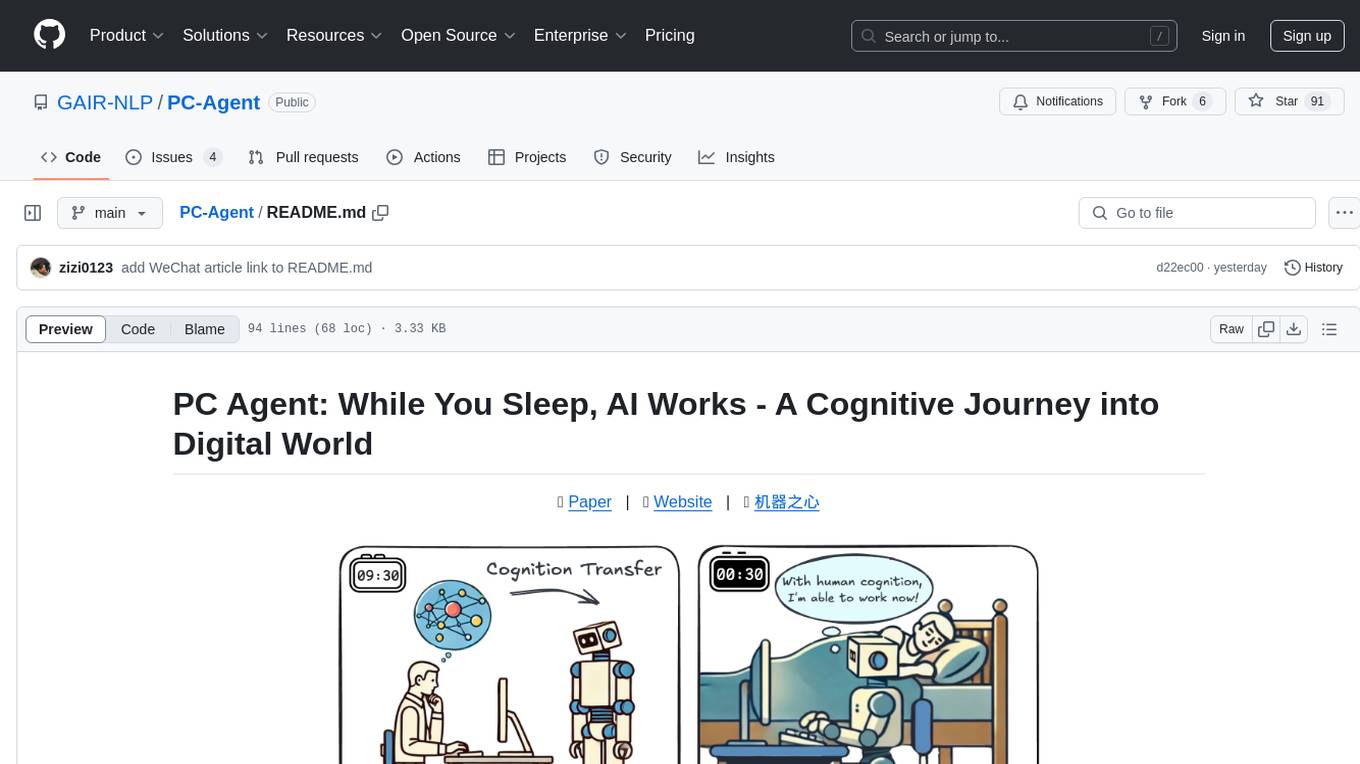
PC-Agent
PC Agent introduces a novel framework to empower autonomous digital agents through human cognition transfer. It consists of PC Tracker for data collection, Cognition Completion for transforming raw data, and a multi-agent system for decision-making and visual grounding. Users can set up the tool in Python environment, customize data collection with PC Tracker, process data into cognitive trajectories, and run the multi-agent system. The tool aims to enable AI to work autonomously while users sleep, providing a cognitive journey into the digital world.
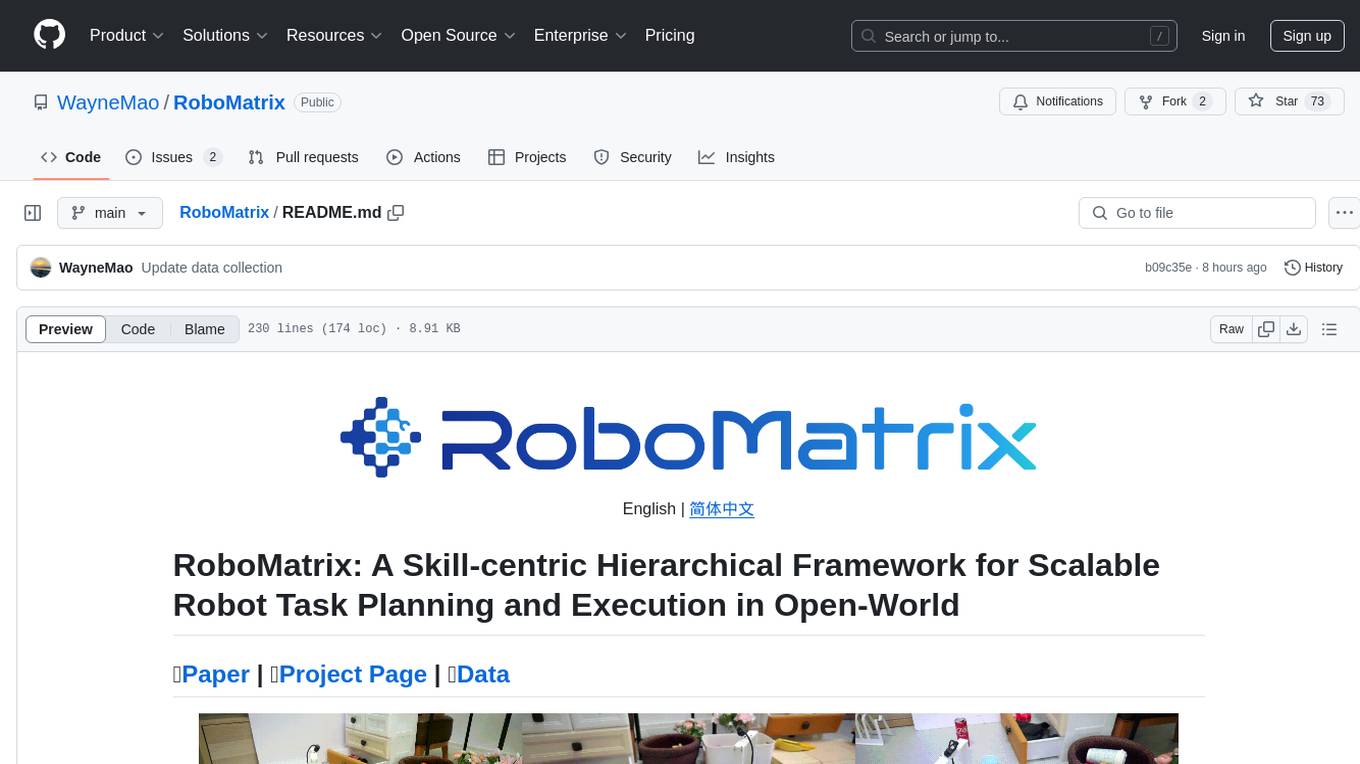
RoboMatrix
RoboMatrix is a skill-centric hierarchical framework for scalable robot task planning and execution in an open-world environment. It provides a structured approach to robot task execution using a combination of hardware components, environment configuration, installation procedures, and data collection methods. The framework is developed using the ROS2 framework on Ubuntu and supports robots from DJI's RoboMaster series. Users can follow the provided installation guidance to set up RoboMatrix and utilize it for various tasks such as data collection, task execution, and dataset construction. The framework also includes a supervised fine-tuning dataset and aims to optimize communication and release additional components in the future.
LLM-Engineers-Handbook
The LLM Engineer's Handbook is an official repository containing a comprehensive guide on creating an end-to-end LLM-based system using best practices. It covers data collection & generation, LLM training pipeline, a simple RAG system, production-ready AWS deployment, comprehensive monitoring, and testing and evaluation framework. The repository includes detailed instructions on setting up local and cloud dependencies, project structure, installation steps, infrastructure setup, pipelines for data processing, training, and inference, as well as QA, tests, and running the project end-to-end.
qiaoqiaoyun
Qiaoqiaoyun is a new generation zero-code product that combines an AI application development platform, AI knowledge base, and zero-code platform, helping enterprises quickly build personalized business applications in an AI way. Users can build personalized applications that meet business needs without any code. Qiaoqiaoyun has comprehensive application building capabilities, form engine, workflow engine, and dashboard engine, meeting enterprise's normal requirements. It is also an AI application development platform based on LLM large language model and RAG open-source knowledge base question-answering system.
ds-ml-bootcamp
The DS-ML Bootcamp repository is a comprehensive resource for a one-month intensive bootcamp that covers the full machine learning workflow. It includes lessons, code examples, and resources to take participants from zero to hands-on projects. The goal is to move from unreal to real, from unimaginable to imaginable, by practicing the entire data science/machine learning journey step by step in just one month.
positronic
Positronic is an end-to-end toolkit for building ML-driven robotics systems, aiming to simplify data collection, messy data handling, and complex deployment in the field of robotics. It provides a Python-native stack for real-life ML robotics, covering hardware integration, dataset curation, policy training, deployment, and monitoring. The toolkit is designed to make professional-grade ML robotics approachable, without the need for ROS. Positronic offers solutions for data ops, hardware drivers, unified inference API, and iteration workflows, enabling teams to focus on developing manipulation systems for robots.

vllm
vLLM is a fast and easy-to-use library for LLM inference and serving. It is designed to be efficient, flexible, and easy to use. vLLM can be used to serve a variety of LLM models, including Hugging Face models. It supports a variety of decoding algorithms, including parallel sampling, beam search, and more. vLLM also supports tensor parallelism for distributed inference and streaming outputs. It is open-source and available on GitHub.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.