
awesome-turkish-language-models
A curated list of Turkish AI models, datasets, papers
Stars: 66
A curated list of Turkish AI models, datasets, and papers aimed at sharing and spreading information about Turkish AI resources. The repository brings together a selection of Turkish AI resources, focusing on unique elements like model performance, task uniqueness, and highlighting groups/companies. It includes various types of models such as LLMs, VLMs, NLP models, speech models, multi-modal models, datasets, live leaderboards, benchmark datasets, papers, tutorials, tools and APIs, MCPs, state of AI in Türkiye, and miscellaneous resources.
README:
A curated list of Turkish AI models, datasets, papers
The purpose of this repo to share and spread the information of Turkish AI models, datasets and papers. The amount of these Turkish resources are low and spread across the web. This repo aims to bring a curated selection of these resources together. This is not a list of all Turkish NLP/LLM models or datasets but a selection. So not all BERT or LLaMA based models are gonna make it here. The same applies to low quality Google translate translations of datasets. We aim each entry to have some kind of unique element to its own. This can be model performance, uniqueness in the task, highlighting the groups/companies (not everyone share their stuff so why not appreciate it!) etc. If you want to add anything you are welcomed 😏 , please check out the contributing section.
- ytu-ce-cosmos/Turkish-Llama
- Trendyol/Llama-3-Trendyol-LLM-8b-chat-v2.0
- Trendyol/Trendyol-LLM-7B-chat-v4.1.0
- TURKCELL/Turkcell-LLM-7b-v1
- KOCDIGITAL/Kocdigital-LLM-8b-v0.1
- WiroAI/OpenR1-Qwen-7B-Turkish Reasoning model
- WiroAI/wiroai-turkish-llm-9b
- ytu-ce-cosmos/Turkish-Gemma-9b-v0.1
- Trendyol/Trendyol-LLM-8B-T1 Qwen3 finetune, has thinking mode
- ytu-ce-cosmos/Turkish-Gemma-9b-T1
- vngrs-ai/Kumru-2B Kumru model has the architecture of Mistral. Its a model trained from scratch (not a finetune).
- Trendyol/tybert
- Trendyol/tyroberta
- ytu-ce-cosmos/turkish-base-bert-uncased
- ytu-ce-cosmos/turkish-colbert
- ytu-ce-cosmos/turkish-gpt2-large
- dbmdz/bert-base-turkish-128k-uncased
- TURKCELL/bert-offensive-lang-detection-tr
- asafaya/kanarya-2b
- boun-tabi-LMG/TURNA
- Helsinki-NLP group Lots of translation models for turkish
- VRLLab/TurkishBERTweet Tweet sentiment analysis
- akdeniz27/bert-base-turkish-cased-ner
- Trendyol/TY-ecomm-embed-multilingual-base-v1.2.0 Turkish and multilingual embeddings
- artiwise-ai/modernbert-base-tr-uncased
- ytu-ce-cosmos/turkish-e5-large Turkish retrieval model
To be added
- kesimeg/lora-turkish-clip CLIP model finetuned on turkish dataset
- merve/turkish_instructions Instruction tuning dataset
- BrewInteractive/alpaca-tr Instruction tuning dataset
- Metin/WikiRAG-TR
- MBZUAI/Bactrian-X
- Helsinki-NLP group Lots of translation models datasets for turkish
- turkish-nlp-suite/turkish-wikiNER
- turkish-nlp-suite/InstrucTurca
- WiroAI/dolphin-r1-turkish Reasoning dataset
- allenai/c4 Web scrape
- HPLT/HPLT2.0_cleaned Web scrape
- unimelb-nlp/wikiann NER
- TUR2SQL Text to SQL query dataset
- dolphin-r1-turkish Reasoning dataset
- emre/ct_tree_of_thought_turkish Turkish Tree of Thoughts (ToT) dataset
- evreny/prompt_injection_tr Turkish prompts for prompt injection
- HuggingFaceFW/fineweb-2 Has ~95 million turkish text
- TURSpider Text-to-SQL dataset
- vngrs-ai/vngrs-web-corpus Pretraining data which is a collection of different datasets crawled from the internet
- HuggingFaceFW/finetranslations Has 58 Million Turkish-English text pairs for translation. Translations were generated with Gemma3-27B (From original Turkish dataset to English)
- ytu-ce-cosmos/Cosmos-Turkish-Corpus-v1.0 Pretraining data which is a collection of different datasets crawled from the internet
- ytu-ce-cosmos/Turkish-LLaVA-Finetune
- ytu-ce-cosmos/Turkish-LLaVA-Pretrain
- ytu-ce-cosmos/turkce-kitap
- 99eren99/LLaVA1.5-Data-Turkish
- TasvirEt
- nezahatkorkmaz/turkish-medical-vqa-evaluated Medical image question and answer dataset
- nezahatkorkmaz/unsloth-pmc-vqa-tr Medical image question answering dataset. Translted from PMC-VQA dataset. Reiquires access to images from original dataset.
- BosphorusSign22k Sign recognition
- FinePDFs Has 1.7 million Turkish entries. A PDF dataset that can be great for pretraining, RAG benchmark curation.
- ituperceptron/image-captioning-turkish Image captioning dataset. 200k long, 100k short captions
- mozilla-foundation/common_voice_17_0 This dataset also has older versions v16,v15, etc.
- malhajar/OpenLLMTurkishLeaderboard_v0.2
- KUIS-AI/Cetvel
- kesimeg/Turkish-rewardbench Reward model comparison
- TurkBench/TurkBench
- newmindai/Mezura Has RAG, Human evaluation (ELO score) and other benchmark scores. It also includes benchmarks in malhajar/OpenLLMTurkishLeaderboard_v0.2
- newmindai/Mizan Embedding model leaderboard. Compares abilities of embedding models on tasks such as retrieval, clustering etc.
- AYueksel/TurkishMMLU
- alibayram/turkish_mmlu
- ytu-ce-cosmos/gsm8k_tr
- Holmeister's Collections A collection of 17 datasets for 11 different tasks (Truthfulness, fairness, summarization etc.). For more see the paper
- CohereLabs/Global-MMLU MMLU for multiple languages including Turkish
- mrlbenchmarks/global-piqa-nonparallel Cultural commonsense benchmark.
- ytu-ce-cosmos/gpqa-extended_tr Graduate level science questions.
- CohereLabsCommunity/multilingual-reward-bench Reward benchmark (preference prediction)
- CohereLabs/m-WildVision
- CohereLabs/AyaVisionBench
- kesimeg/MMStar_tr
- metu-yks/yksbench A visual benchmark based on university entrance exam. Questions include visuals related to mathematics, geometry, physics, chemistry, biology, and geography
- Cosmos-LLaVA: Chatting with the Visual
- Introducing cosmosGPT: Monolingual Training for Turkish Language Models
- TurkishMMLU: Measuring Massive Multitask Language Understanding in Turkish
- TURSpider: A Turkish Text-to-SQL Dataset and LLM-Based Study
- How do LLMs perform on Turkish? A multi-faceted multi-prompt evaluation Performances of various LLMs in Turkish
- Evaluating the Quality of Benchmark Datasets for Low-Resource Languages: A Case Study on Turkish
- YKSBench: Stress-Testing Multimodal Models with Exam-Style Questions Paper of YKSBench benchmark.
- TurkBench: A Benchmark for Evaluating Turkish Large Language Models Paper of TurkBench benchmark
- Glosbe
- Wiktionary
- Zemberek Some turkish NLP tools
- 3rt4nm4n/turkish-apis A list of turkish-apis
- THY-MCP
- borsa-mcp MCP Server for Istanbul Stock Exchange and Turkish Investment Fund Data
- yargi-cmp MCP Server For Turkish Legal Databases
- mezuat-mcp MCP Server for Searching Turkish Legislation
- yoktez-mcp MCP Server for Turkish Thesis Database
- yokatlas-mcp MCP Server for YOK Atlas
- KUIS-AI Youtube channel
- TR-AI Youtube channel
- Trendyol Tech Youtube channel Has videos related to their AI products and how they integrate AI
- Mukayese: Turkish NLP Strikes Back
- Mukayese github repo
- Wikipedia dumps Can be used as a dataset
- Turkish Encoder-only Models List A collection of encoder only turkish models
- Turkish Instruction Datasets List A collection of turkish instruction datasets
- Turkish Vision-Language Datasets List A collection of turkish vision language datasets
- Cosmos App The app of Cosmos AI Research group hosting their cosmos model. (Also has an iOS version)
- ITU NLP Research Tools and Resources
If you got anything to be added here just make a pull request! Before making a pull request please consider if a model/dataset/etc. has enough quality/uniqueness. Huggingface is crowded with finetuning of LLama and BERT, same applies to dataset. Many datasets have multiple machine translation version. This makes it hard to find good quality sources. We want to keep this list as curated as possible but still be able to cover enough sources.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for awesome-turkish-language-models
Similar Open Source Tools
awesome-turkish-language-models
A curated list of Turkish AI models, datasets, and papers aimed at sharing and spreading information about Turkish AI resources. The repository brings together a selection of Turkish AI resources, focusing on unique elements like model performance, task uniqueness, and highlighting groups/companies. It includes various types of models such as LLMs, VLMs, NLP models, speech models, multi-modal models, datasets, live leaderboards, benchmark datasets, papers, tutorials, tools and APIs, MCPs, state of AI in Türkiye, and miscellaneous resources.
video-SALMONN-2
video-SALMONN 2 is a powerful audio-visual large language model that generates high-quality audio-visual video captions. Developed by the Department of Electronic Engineering at Tsinghua University and ByteDance, it offers various models achieving state-of-the-art results on audio-visual QA benchmarks and visual-only benchmarks. Users can train the model, evaluate checkpoints, and access different versions of video-SALMONN 2 for enhanced audio-visual understanding.
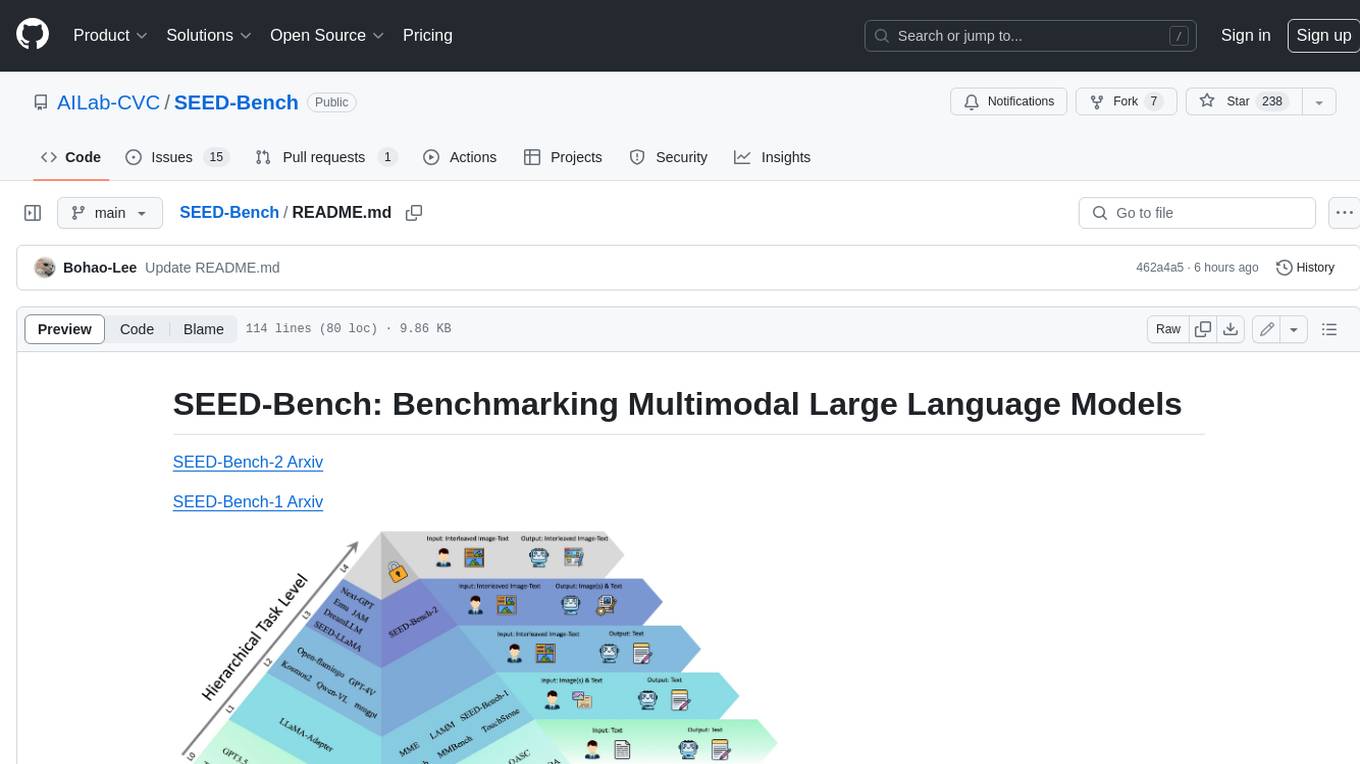
SEED-Bench
SEED-Bench is a comprehensive benchmark for evaluating the performance of multimodal large language models (LLMs) on a wide range of tasks that require both text and image understanding. It consists of two versions: SEED-Bench-1 and SEED-Bench-2. SEED-Bench-1 focuses on evaluating the spatial and temporal understanding of LLMs, while SEED-Bench-2 extends the evaluation to include text and image generation tasks. Both versions of SEED-Bench provide a diverse set of tasks that cover different aspects of multimodal understanding, making it a valuable tool for researchers and practitioners working on LLMs.
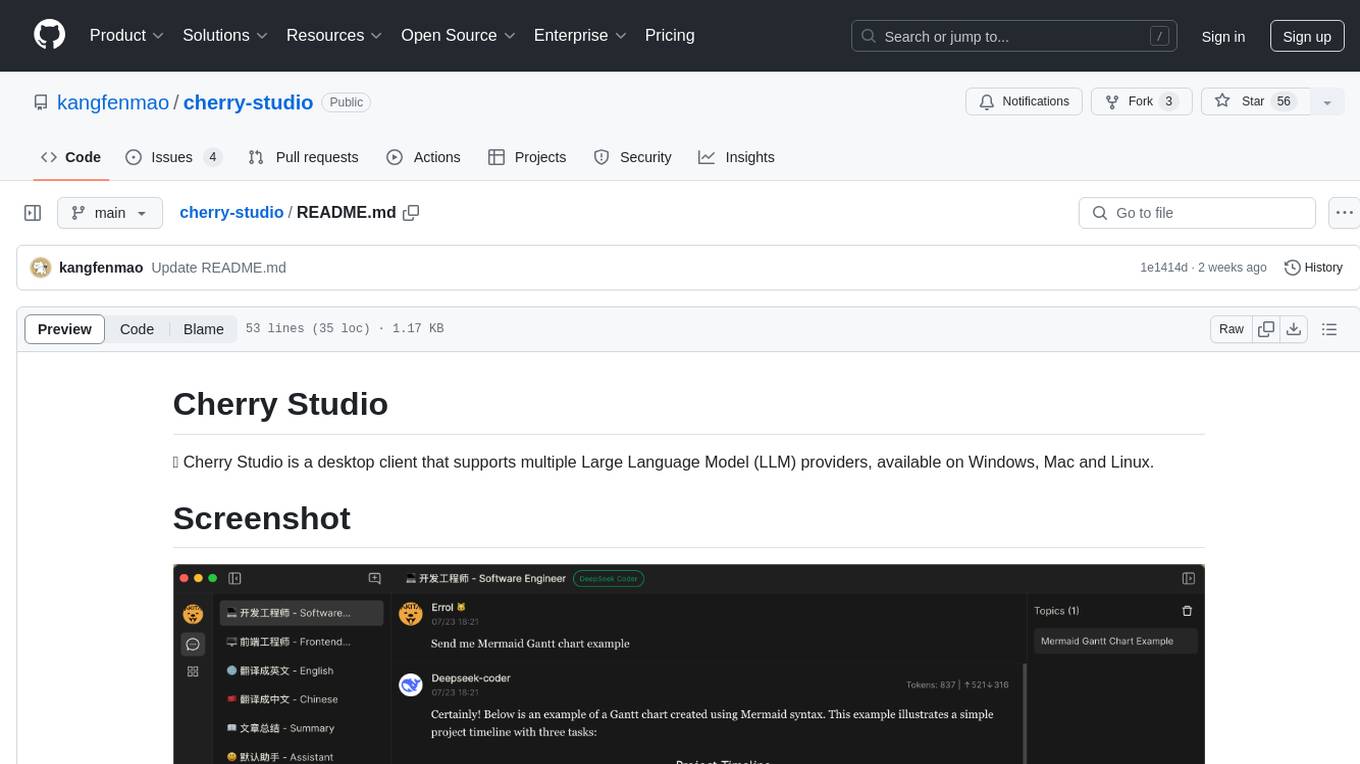
cherry-studio
Cherry Studio is a desktop client that supports multiple Large Language Model (LLM) providers, available on Windows, Mac, and Linux. It allows users to create multiple Assistants and topics, use multiple models to answer questions in the same conversation, and supports drag-and-drop sorting, code highlighting, and Mermaid chart. The tool is designed to enhance productivity and streamline the process of interacting with various language models.

AceCoder
AceCoder is a tool that introduces a fully automated pipeline for synthesizing large-scale reliable tests used for reward model training and reinforcement learning in the coding scenario. It curates datasets, trains reward models, and performs RL training to improve coding abilities of language models. The tool aims to unlock the potential of RL training for code generation models and push the boundaries of LLM's coding abilities.
Awesome-AI-Data-GitHub-Repos
Awesome AI & Data GitHub-Repos is a curated list of essential GitHub repositories covering the AI & ML landscape. It includes resources for Natural Language Processing, Large Language Models, Computer Vision, Data Science, Machine Learning, MLOps, Data Engineering, SQL & Database, and Statistics. The repository aims to provide a comprehensive collection of projects and resources for individuals studying or working in the field of AI and data science.

Kiln
Kiln is an intuitive tool for fine-tuning LLM models, generating synthetic data, and collaborating on datasets. It offers desktop apps for Windows, MacOS, and Linux, zero-code fine-tuning for various models, interactive data generation, and Git-based version control. Users can easily collaborate with QA, PM, and subject matter experts, generate auto-prompts, and work with a wide range of models and providers. The tool is open-source, privacy-first, and supports structured data tasks in JSON format. Kiln is free to use and helps build high-quality AI products with datasets, facilitates collaboration between technical and non-technical teams, allows comparison of models and techniques without code, ensures structured data integrity, and prioritizes user privacy.

Awesome-LLM
Awesome-LLM is a curated list of resources related to large language models, focusing on papers, projects, frameworks, tools, tutorials, courses, opinions, and other useful resources in the field. It covers trending LLM projects, milestone papers, other papers, open LLM projects, LLM training frameworks, LLM evaluation frameworks, tools for deploying LLM, prompting libraries & tools, tutorials, courses, books, and opinions. The repository provides a comprehensive overview of the latest advancements and resources in the field of large language models.

FAV0
FAV0 Weekly is a repository that records weekly updates on front-end, AI, and computer-related content. It provides light and dark mode switching, bilingual interface, RSS subscription function, Giscus comment system, high-definition image preview, font settings customization, and SEO optimization. Users can stay updated with the latest weekly releases by starring/watching the repository. The repository is dual-licensed under the MIT License and CC-BY-4.0 License.

axolotl
Axolotl is a lightweight and efficient tool for managing and analyzing large datasets. It provides a user-friendly interface for data manipulation, visualization, and statistical analysis. With Axolotl, users can easily import, clean, and explore data to gain valuable insights and make informed decisions. The tool supports various data formats and offers a wide range of functions for data processing and modeling. Whether you are a data scientist, researcher, or business analyst, Axolotl can help streamline your data workflows and enhance your data analysis capabilities.

serverless-rag-demo
The serverless-rag-demo repository showcases a solution for building a Retrieval Augmented Generation (RAG) system using Amazon Opensearch Serverless Vector DB, Amazon Bedrock, Llama2 LLM, and Falcon LLM. The solution leverages generative AI powered by large language models to generate domain-specific text outputs by incorporating external data sources. Users can augment prompts with relevant context from documents within a knowledge library, enabling the creation of AI applications without managing vector database infrastructure. The repository provides detailed instructions on deploying the RAG-based solution, including prerequisites, architecture, and step-by-step deployment process using AWS Cloudshell.
rllm
rLLM is an open-source framework for post-training language agents via reinforcement learning. With rLLM, you can easily build your custom agents and environments, train them with reinforcement learning, and deploy them for real-world workloads. The framework provides tools for training coding models, software engineering agents, and language agents using reinforcement learning techniques. It supports various models of different sizes and capabilities, enabling users to achieve state-of-the-art performance in coding and language-related tasks. rLLM is designed to be user-friendly, scalable, and efficient for training and deploying language agents in diverse applications.

ERNIE
ERNIE 4.5 is a family of large-scale multimodal models with 10 distinct variants, including Mixture-of-Experts (MoE) models with 47B and 3B active parameters. The models feature a novel heterogeneous modality structure supporting parameter sharing across modalities while allowing dedicated parameters for each individual modality. Trained with optimal efficiency using PaddlePaddle deep learning framework, ERNIE 4.5 models achieve state-of-the-art performance across text and multimodal benchmarks, enhancing multimodal understanding without compromising performance on text-related tasks. The open-source development toolkits for ERNIE 4.5 offer industrial-grade capabilities, resource-efficient training and inference workflows, and multi-hardware compatibility.
aws-ai-ml-workshop-kr
AWS AI/ML Workshop & example collection in Korean. The example codes in this repository are divided into 4 categories: AI services, Applied AI, SageMaker, Integration, Generative AI, and AWS Neuron. Each directory has its own Readme file. This repository also provides useful information for self-studying SageMaker.
Qing-Digital-Self
Qing-Digital-Self is a project that creates a personal digital twin by fine-tuning a large language model on your chat history. The aim is to replicate your unique style of expression and conversational behavior accurately. The project includes bilingual support and comprehensive tutorials covering data extraction, chat data cleaning and conversion, LlamaFactory fine-tuning process, and testing and usage of the fine-tuned model. It offers a different perspective and assistance compared to similar projects. The project is currently in development with version v0.1.6, and welcomes contributions and issue reports from developers.
For similar tasks

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.

adata
AData is a free and open-source A-share database that focuses on transaction-related data. It provides comprehensive data on stocks, including basic information, market data, and sentiment analysis. AData is designed to be easy to use and integrate with other applications, making it a valuable tool for quantitative trading and AI training.

PIXIU
PIXIU is a project designed to support the development, fine-tuning, and evaluation of Large Language Models (LLMs) in the financial domain. It includes components like FinBen, a Financial Language Understanding and Prediction Evaluation Benchmark, FIT, a Financial Instruction Dataset, and FinMA, a Financial Large Language Model. The project provides open resources, multi-task and multi-modal financial data, and diverse financial tasks for training and evaluation. It aims to encourage open research and transparency in the financial NLP field.

hezar
Hezar is an all-in-one AI library designed specifically for the Persian community. It brings together various AI models and tools, making it easy to use AI with just a few lines of code. The library seamlessly integrates with Hugging Face Hub, offering a developer-friendly interface and task-based model interface. In addition to models, Hezar provides tools like word embeddings, tokenizers, feature extractors, and more. It also includes supplementary ML tools for deployment, benchmarking, and optimization.

text-embeddings-inference
Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for popular models like FlagEmbedding, Ember, GTE, and E5. It implements features such as no model graph compilation step, Metal support for local execution on Macs, small docker images with fast boot times, token-based dynamic batching, optimized transformers code for inference using Flash Attention, Candle, and cuBLASLt, Safetensors weight loading, and production-ready features like distributed tracing with Open Telemetry and Prometheus metrics.

CodeProject.AI-Server
CodeProject.AI Server is a standalone, self-hosted, fast, free, and open-source Artificial Intelligence microserver designed for any platform and language. It can be installed locally without the need for off-device or out-of-network data transfer, providing an easy-to-use solution for developers interested in AI programming. The server includes a HTTP REST API server, backend analysis services, and the source code, enabling users to perform various AI tasks locally without relying on external services or cloud computing. Current capabilities include object detection, face detection, scene recognition, sentiment analysis, and more, with ongoing feature expansions planned. The project aims to promote AI development, simplify AI implementation, focus on core use-cases, and leverage the expertise of the developer community.

spark-nlp
Spark NLP is a state-of-the-art Natural Language Processing library built on top of Apache Spark. It provides simple, performant, and accurate NLP annotations for machine learning pipelines that scale easily in a distributed environment. Spark NLP comes with 36000+ pretrained pipelines and models in more than 200+ languages. It offers tasks such as Tokenization, Word Segmentation, Part-of-Speech Tagging, Named Entity Recognition, Dependency Parsing, Spell Checking, Text Classification, Sentiment Analysis, Token Classification, Machine Translation, Summarization, Question Answering, Table Question Answering, Text Generation, Image Classification, Image to Text (captioning), Automatic Speech Recognition, Zero-Shot Learning, and many more NLP tasks. Spark NLP is the only open-source NLP library in production that offers state-of-the-art transformers such as BERT, CamemBERT, ALBERT, ELECTRA, XLNet, DistilBERT, RoBERTa, DeBERTa, XLM-RoBERTa, Longformer, ELMO, Universal Sentence Encoder, Llama-2, M2M100, BART, Instructor, E5, Google T5, MarianMT, OpenAI GPT2, Vision Transformers (ViT), OpenAI Whisper, and many more not only to Python and R, but also to JVM ecosystem (Java, Scala, and Kotlin) at scale by extending Apache Spark natively.

scikit-llm
Scikit-LLM is a tool that seamlessly integrates powerful language models like ChatGPT into scikit-learn for enhanced text analysis tasks. It allows users to leverage large language models for various text analysis applications within the familiar scikit-learn framework. The tool simplifies the process of incorporating advanced language processing capabilities into machine learning pipelines, enabling users to benefit from the latest advancements in natural language processing.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.