
kazam
Kazam2 - Linux Screen Recorder, Broadcaster, Capture and OCR with AI in mind
Stars: 153
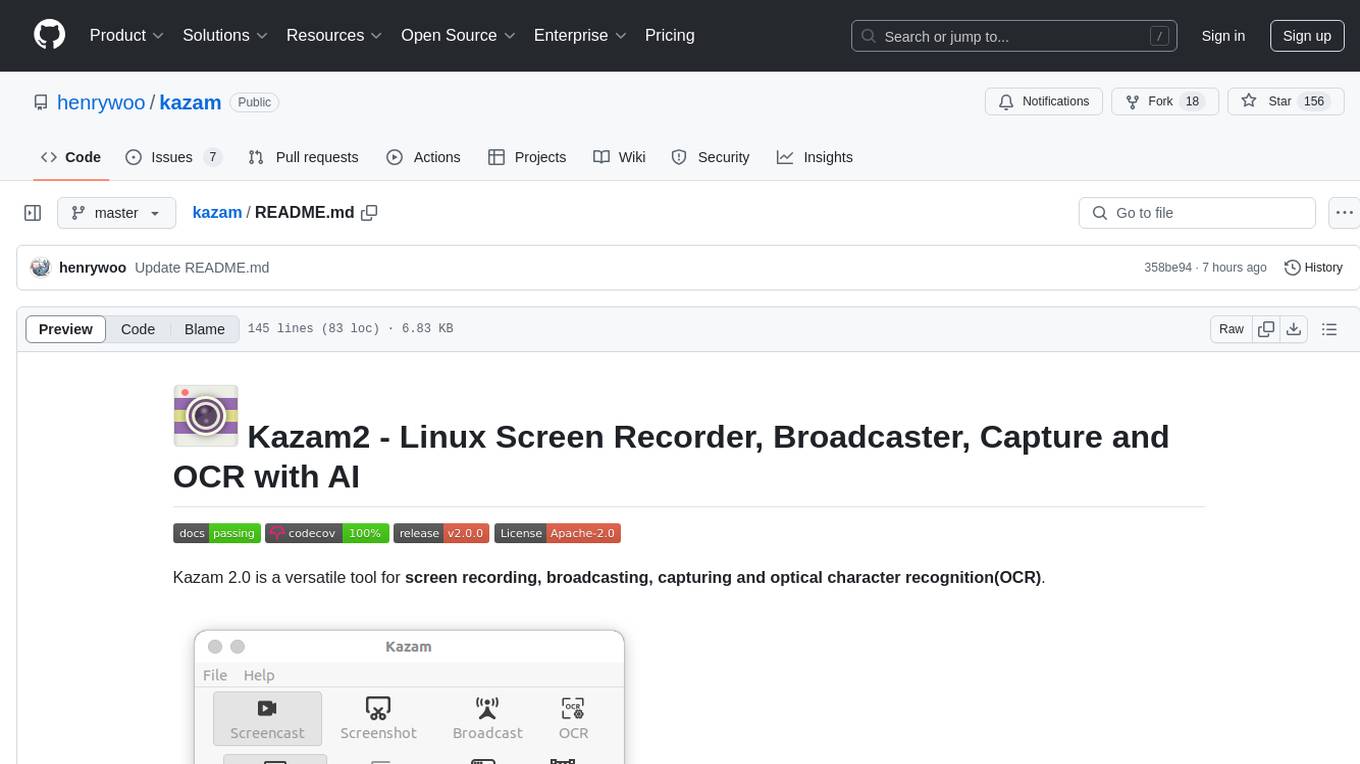
Kazam 2.0 is a versatile tool for screen recording, broadcasting, capturing, and optical character recognition (OCR). It allows users to capture screen content, broadcast live over the internet, extract text from captured content, record audio, and use a web camera for recording. The tool supports full screen, window, and area modes, and offers features like keyboard shortcuts, live broadcasting with Twitch and YouTube, and tips for recording quality. Users can install Kazam on Ubuntu and use it for various recording and broadcasting needs.
README:

Kazam 2.0 is a versatile tool for screen recording, broadcasting, capturing and optical character recognition(OCR).
Main Features:
-
Screen Recording: Kazam allows you to capture everything displayed on your screen and save it as a video file. The recorded video is saved in a format compatible with any media player that supports H264, VP8 codec and WebM video format.
-
Broadcasting: Kazam offers the ability to broadcast your screen content live over the internet, making it suitable for live streaming sessions. It supports Twitch and Youtube live broadcasting at the time of this writing.
-
Optical Character Recognition (OCR): Kazam includes OCR functionality, enabling it to detect and extract text from the captured screen content, which can then be edited or saved.
-
Audio Recording: In addition to screen content, Kazam can record audio from any sound input device that is recognized and supported by the PulseAudio sound system. This allows you to capture both the screen and accompanying audio, such as voice narration or system sounds, in your recordings.
-
Web Camera: Kazam support web camera recording and users can drag and drop webcam window anywhere in the screen to suit the recording need.
-
Full Screen, Window and Area Mode: Kazam support full screen, window and area modes.
📌 Please use the latest version kazam 2.0.0. Make sure the version is the latest when you report issues.
🍄 Tested in: Ubuntu 20.04, 22.04, and 24.04 with Python 3.8 - 3.12.pip install -U kazamKazam needs some dependency libraries like dbus, cairo to work. In Ubuntu, you can use the following command to install them:
sudo apt install build-essential libpython3-dev \
libdbus-1-dev libcairo2-dev libgirepository1.0-dev \
gir1.2-gudev-1.0 gir1.2-keybinder-3.0 python3-gi python3-gst-1.0 xdotool -yIn Ubuntu, make sure the PulseAudio GStreamer plugin is installed. If not, run:
sudo apt reinstall gstreamer1.0-pulseaudio -y- To use OCR features, please install:
sudo apt-get install tesseract-ocr -y
pip install pytesseract pillow rapidocr-onnxruntime- Live Broadcasting
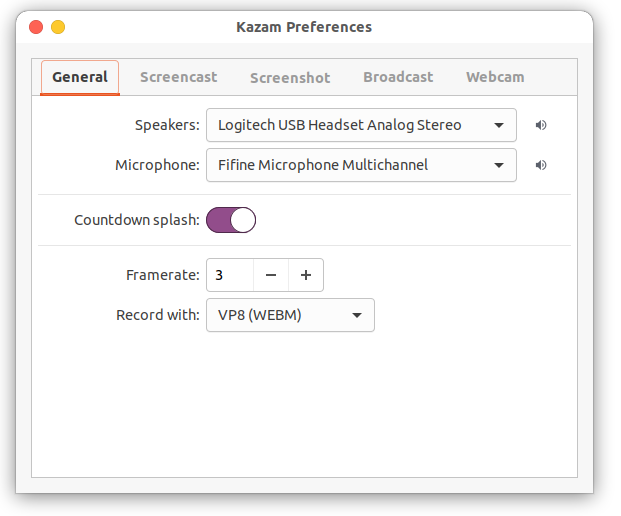
- Preferences Window
If you want to run Kazam from the source tree, there are a few limitations that you have to take into account. Every icon has to be taken from the currently installed icon theme. Toolbars will not show any icons, and you will not see Unity AppIndicator.
To run Kazam, simply execute the following commands in the source tree:
pip install -r requirements.txt
cd bin
./kazamMake sure ~/.local/bin is in your PATH, and running kazam in your terminal should work.
If you already have Kazam installed, then Kazam icons will be displayed properly.
SUPER-CTRL-Q - Quit
SUPER-CTRL-W - Show/Hide main window
SUPER-CTRL-R - Start Recording
SUPER-CTRL-F - Finish RecordingOn a normal Logitech keyboard, SUPER-CTRL is Ctrl+CMD.
-
Choose a small framerate. My personal setup is framerate equal to 3. Framerates above 20fps are unlikely to work well because of software and hardware limitations. If you increase the framerate and the resulting video framerate drops, that is because the encoder can't keep up.
-
Always do a sound check, especially if you are recording live commentary with background sound. I got the best results when I used earphones to listen to the audio while recording. This way, your mic will not pick up any audio coming from the speakers.
-
If you really want lossless quality, then you will have to record in RAW format. This is possible, but without an SSD with a lot of free space, your results will be terrible. 1920x1080 at 15 frames per second will need around 45 MB of disk space per second. Most people will want to record at 20 or 25 frames per second. Most disks will not handle that, and your system will start to crawl.
-
Your next best bet is HUFFYUV format, which is a little bit friendlier on disk bandwidth with 28 MB per second at 15 frames per second. The problem? Not many video editors and players can handle HUFFYUV, let alone video sharing services.
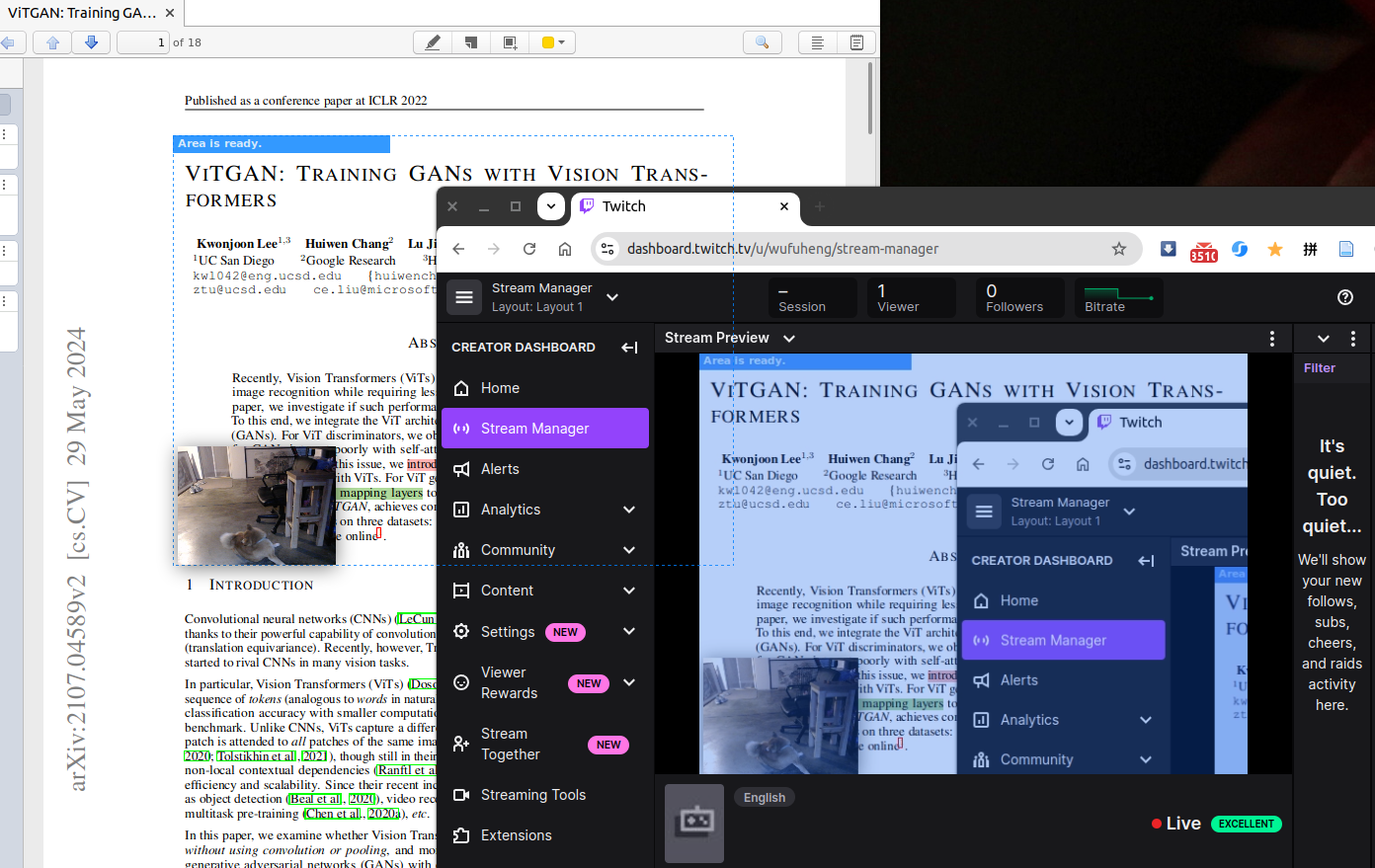
Kazam 2 support live broadcasting with Twitch and YouTube.
Click File -> Preferences, and then click Broadcast tab. In Server URL, input rtmp://live.twitch.tv/app/.
For Stream Key, please login https://www.twitch.tv/ with your twitch account. Then go to Creator Dashboard -> Settings -> Stream, Click Copy button to copy the Primary Stream key, which is your Stream Key.
And then paste it into the Stream Key in your Kazam preferences window.
(Do not use the keys displayed above which are invalid. Use your own ones, please.)
Login https://studio.youtube.com/ with your account and find the Go live icon as below (it should be on the right side of the page below your account avatar):
Or you can click Create and then Go live at the top right side of the page.
You will be directed to this page below:
You can find your Stream Key and Stream URL as above. Copy-paste them into your Kazam Preferences window's YouTube Live Settings section, then you can close the window and go to Kazam main window, click Broadcast and select Fullscreen, Window or Area to start live broadcasting.
If you encounter a bug or any kind of unexpected behavior, please try to reproduce it while running Kazam from a standard terminal with the --debug option. Please report bugs at https://github.com/henrywoo/kazam/issues and include the generated output.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for kazam
Similar Open Source Tools
kazam
Kazam 2.0 is a versatile tool for screen recording, broadcasting, capturing, and optical character recognition (OCR). It allows users to capture screen content, broadcast live over the internet, extract text from captured content, record audio, and use a web camera for recording. The tool supports full screen, window, and area modes, and offers features like keyboard shortcuts, live broadcasting with Twitch and YouTube, and tips for recording quality. Users can install Kazam on Ubuntu and use it for various recording and broadcasting needs.
voice-chat-ai
Voice Chat AI is a project that allows users to interact with different AI characters using speech. Users can choose from various characters with unique personalities and voices, and have conversations or role play with them. The project supports OpenAI, xAI, or Ollama language models for chat, and provides text-to-speech synthesis using XTTS, OpenAI TTS, or ElevenLabs. Users can seamlessly integrate visual context into conversations by having the AI analyze their screen. The project offers easy configuration through environment variables and can be run via WebUI or Terminal. It also includes a huge selection of built-in characters for engaging conversations.

MITSUHA
OneReality is a virtual waifu/assistant that you can speak to through your mic and it'll speak back to you! It has many features such as: * You can speak to her with a mic * It can speak back to you * Has short-term memory and long-term memory * Can open apps * Smarter than you * Fluent in English, Japanese, Korean, and Chinese * Can control your smart home like Alexa if you set up Tuya (more info in Prerequisites) It is built with Python, Llama-cpp-python, Whisper, SpeechRecognition, PocketSphinx, VITS-fast-fine-tuning, VITS-simple-api, HyperDB, Sentence Transformers, and Tuya Cloud IoT.
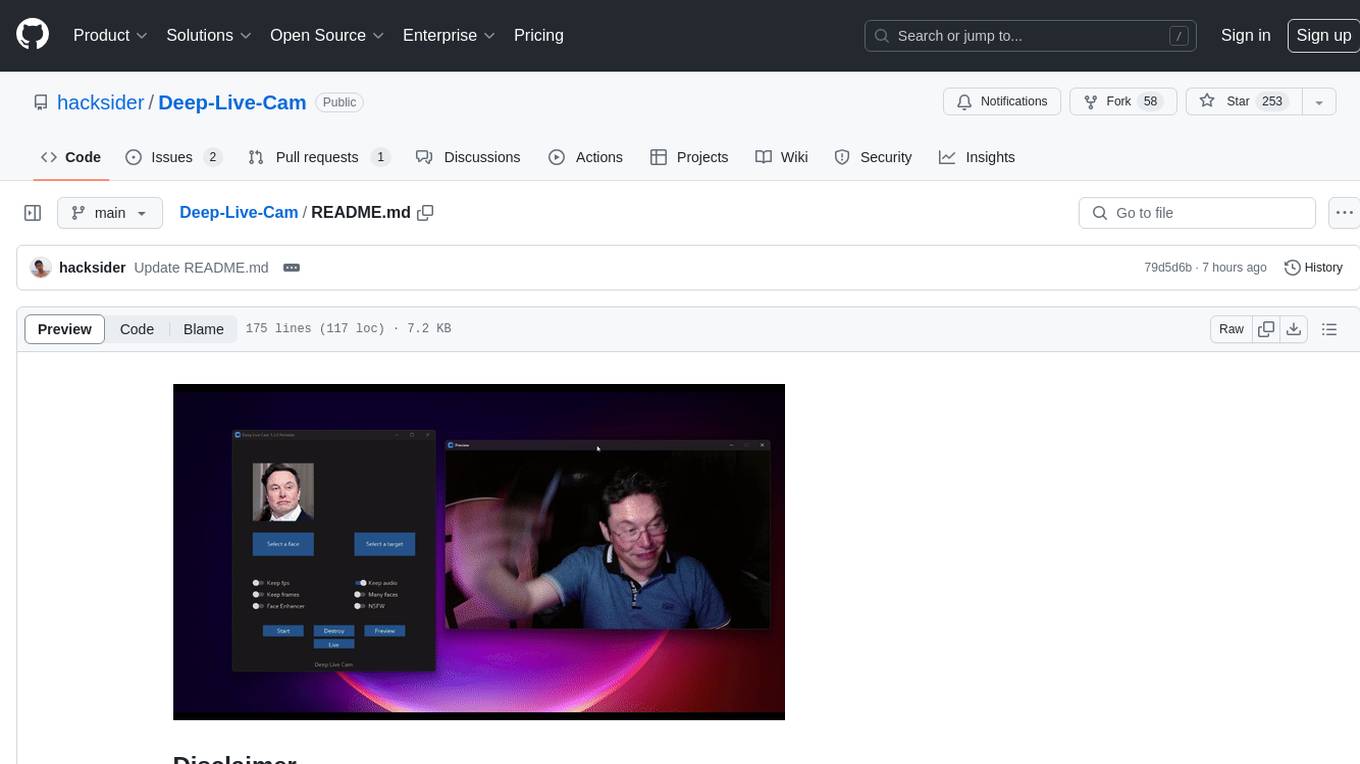
Deep-Live-Cam
Deep-Live-Cam is a software tool designed to assist artists in tasks such as animating custom characters or using characters as models for clothing. The tool includes built-in checks to prevent unethical applications, such as working on inappropriate media. Users are expected to use the tool responsibly and adhere to local laws, especially when using real faces for deepfake content. The tool supports both CPU and GPU acceleration for faster processing and provides a user-friendly GUI for swapping faces in images or videos.

FunClip
FunClip is an open-source, locally deployed automated video clipping tool that leverages Alibaba TONGYI speech lab's FunASR Paraformer series models for speech recognition on videos. Users can select text segments or speakers from recognition results to obtain corresponding video clips. It integrates industrial-grade models for accurate predictions and offers hotword customization and speaker recognition features. The tool is user-friendly with Gradio interaction, supporting multi-segment clipping and providing full video and target segment subtitles. FunClip is suitable for users looking to automate video clipping tasks with advanced AI capabilities.
UltraSinger
UltraSinger is a tool under development that automatically creates UltraStar.txt, midi, and notes from music. It pitches UltraStar files, adds text and tapping, creates separate UltraStar karaoke files, re-pitches current UltraStar files, and calculates in-game score. It uses multiple AI models to extract text from voice and determine pitch. Users should mention UltraSinger in UltraStar.txt files and only use it on Creative Commons licensed songs.
Helios
Helios is a powerful open-source tool for managing and monitoring your Kubernetes clusters. It provides a user-friendly interface to easily visualize and control your cluster resources, including pods, deployments, services, and more. With Helios, you can efficiently manage your containerized applications and ensure high availability and performance of your Kubernetes infrastructure.

obs-cleanstream
CleanStream is an OBS plugin that utilizes real-time local AI to clean live audio streams by removing unwanted words and utterances, such as 'uh' and 'um', and configurable words like profanity. It employs a neural network (OpenAI Whisper) to predict speech in real-time and eliminate undesired words. The plugin runs efficiently using the Whisper.cpp project from ggerganov. CleanStream offers users the ability to adjust settings and add the plugin to any audio-generating source in OBS, providing a seamless experience for content creators looking to enhance the quality of their live audio streams.
obs-cleanstream
CleanStream is an OBS plugin that utilizes AI to clean live audio streams by removing unwanted words and utterances, such as 'uh's and 'um's, and configurable words like profanity. It uses a neural network (OpenAI Whisper) in real-time to predict speech and eliminate unwanted words. The plugin is still experimental and not recommended for live production use, but it is functional for testing purposes. Users can adjust settings and configure the plugin to enhance audio quality during live streams.
TerminalGPT
TerminalGPT is a terminal-based ChatGPT personal assistant app that allows users to interact with OpenAI GPT-3.5 and GPT-4 language models. It offers advantages over browser-based apps, such as continuous availability, faster replies, and tailored answers. Users can use TerminalGPT in their IDE terminal, ensuring seamless integration with their workflow. The tool prioritizes user privacy by not using conversation data for model training and storing conversations locally on the user's machine.
CyberScraper-2077
CyberScraper 2077 is an advanced web scraping tool powered by AI, designed to extract data from websites with precision and style. It offers a user-friendly interface, supports multiple data export formats, operates in stealth mode to avoid detection, and promises lightning-fast scraping. The tool respects ethical scraping practices, including robots.txt and site policies. With upcoming features like proxy support and page navigation, CyberScraper 2077 is a futuristic solution for data extraction in the digital realm.
Whisper-TikTok
Discover Whisper-TikTok, an innovative AI-powered tool that leverages the prowess of Edge TTS, OpenAI-Whisper, and FFMPEG to craft captivating TikTok videos. Whisper-TikTok effortlessly generates accurate transcriptions from audio files and integrates Microsoft Edge Cloud Text-to-Speech API for vibrant voiceovers. The program orchestrates the synthesis of videos using a structured JSON dataset, generating mesmerizing TikTok content in minutes.

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.
Upscaler
Holloway's Upscaler is a consolidation of various compiled open-source AI image/video upscaling products for a CLI-friendly image and video upscaling program. It provides low-cost AI upscaling software that can run locally on a laptop, programmable for albums and videos, reliable for large video files, and works without GUI overheads. The repository supports hardware testing on various systems and provides important notes on GPU compatibility, video types, and image decoding bugs. Dependencies include ffmpeg and ffprobe for video processing. The user manual covers installation, setup pathing, calling for help, upscaling images and videos, and contributing back to the project. Benchmarks are provided for performance evaluation on different hardware setups.

Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.
merlinn
Merlinn is an open-source AI-powered on-call engineer that automatically jumps into incidents & alerts, providing useful insights and RCA in real time. It integrates with popular observability tools, lives inside Slack, offers an intuitive UX, and prioritizes security. Users can self-host Merlinn, use it for free, and benefit from automatic RCA, Slack integration, integrations with various tools, intuitive UX, and security features.
For similar tasks
kazam
Kazam 2.0 is a versatile tool for screen recording, broadcasting, capturing, and optical character recognition (OCR). It allows users to capture screen content, broadcast live over the internet, extract text from captured content, record audio, and use a web camera for recording. The tool supports full screen, window, and area modes, and offers features like keyboard shortcuts, live broadcasting with Twitch and YouTube, and tips for recording quality. Users can install Kazam on Ubuntu and use it for various recording and broadcasting needs.

airunner
AI Runner is a multi-modal AI interface that allows users to run open-source large language models and AI image generators on their own hardware. The tool provides features such as voice-based chatbot conversations, text-to-speech, speech-to-text, vision-to-text, text generation with large language models, image generation capabilities, image manipulation tools, utility functions, and more. It aims to provide a stable and user-friendly experience with security updates, a new UI, and a streamlined installation process. The application is designed to run offline on users' hardware without relying on a web server, offering a smooth and responsive user experience.
tb1
A Telegram bot for accessing Google Gemini, MS Bing, etc. The bot responds to the keywords 'bot' and 'google' to provide information. It can handle voice messages, text files, images, and links. It can generate images based on descriptions, extract text from images, and summarize content. The bot can interact with various AI models and perform tasks like voice control, text-to-speech, and text recognition. It supports long texts, large responses, and file transfers. Users can interact with the bot using voice commands and text. The bot can be customized for different AI providers and has features for both users and administrators.
Edit-Banana
Edit Banana is a universal content re-editor that allows users to transform fixed content into fully manipulatable assets. Powered by SAM 3 and multimodal large models, it enables high-fidelity reconstruction while preserving original diagram details and logical relationships. The platform offers advanced segmentation, fixed multi-round VLM scanning, high-quality OCR, user system with credits, multi-user concurrency, and a web interface. Users can upload images or PDFs to get editable DrawIO (XML) or PPTX files in seconds. The project structure includes components for segmentation, text extraction, frontend, models, and scripts, with detailed installation and setup instructions provided. The tool is open-source under the Apache License 2.0, allowing commercial use and secondary development.
manga-translator
Manga Translator is a tool designed to help users translate manga pages from Japanese to English. It utilizes optical character recognition (OCR) technology to extract text from images and provides a user-friendly interface for translating and editing the text. The tool supports various manga formats and allows users to customize the translation process by adjusting settings such as language preferences and text alignment. With Manga Translator, users can easily translate manga pages for personal use or sharing with others.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.