
ai-data-science-team
An AI-powered data science team of agents to help you perform common data science tasks 10X faster.
Stars: 1671

The AI Data Science Team of Copilots is an AI-powered data science team that uses agents to help users perform common data science tasks 10X faster. It includes agents specializing in data cleaning, preparation, feature engineering, modeling, and interpretation of business problems. The project is a work in progress with new data science agents to be released soon. Disclaimer: This project is for educational purposes only and not intended to replace a company's data science team. No warranties or guarantees are provided, and the creator assumes no liability for financial loss.
README:
An AI-powered data science team of agents to help you perform common data science tasks 10X faster.
Please ⭐ us on GitHub (it takes 2 seconds and means a lot).
Beta - This Python library is under active development. There may be breaking changes that occur until release of 0.1.0.
The AI Data Science Team of Copilots includes Agents that specialize data cleaning, preparation, feature engineering, modeling (machine learning), and interpretation of various business problems like:
- Churn Modeling
- Employee Attrition
- Lead Scoring
- Insurance Risk
- Credit Card Risk
- And more
- Your AI Data Science Team (🪖 An Army Of Agents)
- Want To Become A Full-Stack Generative AI Data Scientist?
- ⭐️ Star History
Want to have your own customized enterprise-grade AI Data Science Team and domain-specific AI-powered Apps?
Send inquiries here: https://www.business-science.io/contact.html
If you're an aspiring data scientist who wants to learn how to build AI Agents and AI Apps for your company that performs Data Science, Business Intelligence, Churn Modeling, Time Series Forecasting, and more, then I'd love to help you.
Register for my next Generative AI for Data Scientists workshop here.
This project is a work in progress. New data science agents will be released soon.

🔥 Open Pandas AI Data Analyst: Load an Excel or CSV file and ask it questions. Get data and charts back.

🔥 SQL Database Agent: Connects any SQL Database, generates SQL queries from natural language, and returns data as a downloadable table.
🔥 Exploratory Data Copilot: An AI-powered data science app that performs automated exploratory data analysis (EDA) with EDA Reporting, Missing Data Analysis, Correlation Analysis, and more.
🔥 Pandas Data Analyst Agent: Combines the ability to wrangle, transform, and analyze data with an optional data visualization agent that can create interactive plots.

- NEW Exploratory Data Copilot: An AI-powered data science app that performs automated exploratory data analysis (EDA) with EDA Reporting, Missing Data Analysis, Correlation Analysis, and more. See Application

- SQL Database Agent App: Connects any SQL Database, generates SQL queries from natural language, and returns data as a downloadable table. See Application
- Data Wrangling Agent: Merges, Joins, Preps and Wrangles data into a format that is ready for data analysis. See Example
- Data Visualization Agent: Creates visualizations to help you understand your data. Returns JSON serializable plotly visualizations. See Example
- 🔥 Data Cleaning Agent: Performs Data Preparation steps including handling missing values, outliers, and data type conversions. See Example
- Feature Engineering Agent: Converts the prepared data into ML-ready data. Adds features to increase predictive accuracy of ML models. See Example
- 🔥 SQL Database Agent: Connects to SQL databases to pull data into the data science environment. Creates pipelines to automate data extraction. Performs Joins, Aggregations, and other SQL Query operations. See Example
- 🔥 Data Loader Tools Agent: Loads data from various sources including CSV, Excel, Parquet, and Pickle files. See Example
- 🔥 H2O Machine Learning Agent: Builds and logs 100's of high-performance machine learning models. See Example
- 🔥 MLflow Tools Agent (MLOps): This agent has 11+ tools for managing models, ML projects, and making production ML predictions with MLflow. See Example
- 🔥🔥 EDA Tools Agent: Performs automated exploratory data analysis (EDA) with EDA Reporting, Missing Data Analysis, Correlation Analysis, and more. See Example
- 🔥🔥 Pandas Data Analyst Agent: Combines the ability to wrangle, transform, and analyze data with an optional data visualization agent that can create interactive plots. See Example
- 🔥🔥 SQL Data Analyst Agent: Connects to SQL databases to pull data into the data science environment. Creates pipelines to automate data extraction. Performs Joins, Aggregations, and other SQL Query operations. Includes a Data Visualization Agent that creates visualizations to help you understand your data. See Example
- Data Analyst: Analyzes data structure, creates exploratory visualizations, and performs correlation analysis to identify relationships.
- Interpretability Agent: Performs Interpretable ML to explain why the model returned predictions including which features were the most important to the model.
- Supervisor: Forms task list. Moderates sub-agents. Returns completed assignment.
This project is for educational purposes only.
- It is not intended to replace your company's data science team
- No warranties or guarantees provided
- Creator assumes no liability for financial loss
- Consult an experienced Generative AI Data Scientist for building your own custom AI Data Science Team
- If you want a custom enterprise-grade AI Data Science Team, send inquiries here.
By using this software, you agree to use it solely for learning purposes.
You can install via PyPI (note that this is a beta version and breaking changes may occur until 0.1.0):
pip install ai-data-science-teamOr, if you want the latest version from GitHub:
pip install git+https://github.com/business-science/ai-data-science-team.git --upgrade# Import libraries
from langchain_openai import ChatOpenAI
import pandas as pd
import h2o
import os
from ai_data_science_team.ml_agents import H2OMLAgent
# Load the data
df = pd.read_csv("data/churn_data.csv")
df
# Initialize the language model
os.environ['OPENAI_API_KEY'] = "YOUR_OPENAI_API_KEY"
llm = ChatOpenAI(model=MODEL)
llm
# Initialize the H2O ML Agent
ml_agent = H2OMLAgent(
model=llm,
log=True,
log_path="logs/",
model_directory="h2o_models/",
enable_mlflow=True, # Use this if you wish to log models to MLflow
)
ml_agent
# Run the agent
ml_agent.invoke_agent(
data_raw=df.drop(columns=["customerID"]),
user_instructions="Please do classification on 'Churn'. Use a max runtime of 30 seconds.",
target_variable="Churn"
)
# Retrieve and display the leaderboard of models
ml_agent.get_leaderboard()- Fork the repository
- Create a feature branch
- Commit your changes
- Push to the branch
- Create a Pull Request
This project is licensed under the MIT License. See LICENSE file for details.

I teach Generative AI Data Science to help you build AI-powered data science apps. Register for my next Generative AI for Data Scientists workshop here.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ai-data-science-team
Similar Open Source Tools
ai-data-science-team
The AI Data Science Team of Copilots is an AI-powered data science team that uses agents to help users perform common data science tasks 10X faster. It includes agents specializing in data cleaning, preparation, feature engineering, modeling, and interpretation of business problems. The project is a work in progress with new data science agents to be released soon. Disclaimer: This project is for educational purposes only and not intended to replace a company's data science team. No warranties or guarantees are provided, and the creator assumes no liability for financial loss.
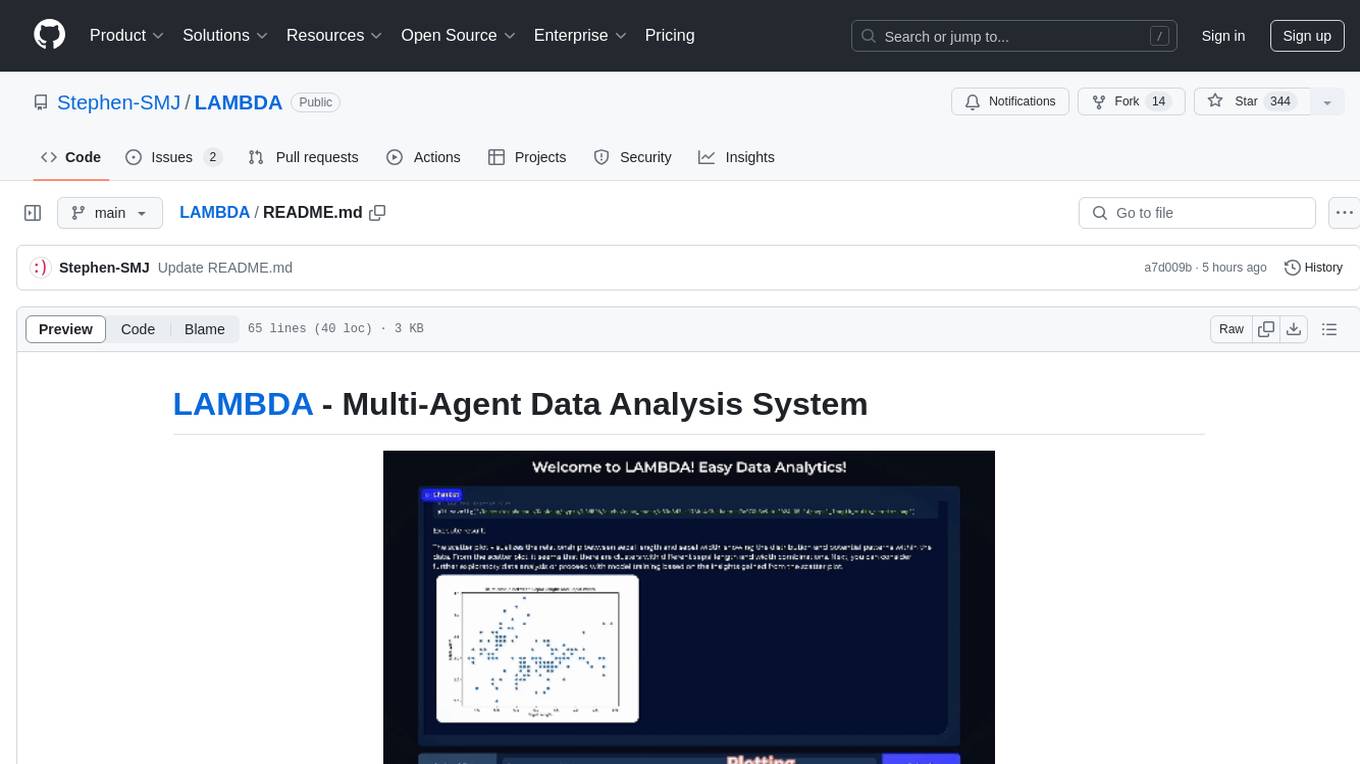
LAMBDA
LAMBDA is a code-free multi-agent data analysis system that utilizes large models to address data analysis challenges in complex data-driven applications. It allows users to perform complex data analysis tasks through human language instruction, seamlessly generate and debug code using two key agent roles, integrate external models and algorithms, and automatically generate reports. The system has demonstrated strong performance on various machine learning datasets, enhancing data science practice by integrating human and artificial intelligence.
Auto-Analyst
Auto-Analyst is an AI-driven data analytics agentic system designed to simplify and enhance the data science process. By integrating various specialized AI agents, this tool aims to make complex data analysis tasks more accessible and efficient for data analysts and scientists. Auto-Analyst provides a streamlined approach to data preprocessing, statistical analysis, machine learning, and visualization, all within an interactive Streamlit interface. It offers plug and play Streamlit UI, agents with data science speciality, complete automation, LLM agnostic operation, and is built using lightweight frameworks.

Controllable-RAG-Agent
This repository contains a sophisticated deterministic graph-based solution for answering complex questions using a controllable autonomous agent. The solution is designed to ensure that answers are solely based on the provided data, avoiding hallucinations. It involves various steps such as PDF loading, text preprocessing, summarization, database creation, encoding, and utilizing large language models. The algorithm follows a detailed workflow involving planning, retrieval, answering, replanning, content distillation, and performance evaluation. Heuristics and techniques implemented focus on content encoding, anonymizing questions, task breakdown, content distillation, chain of thought answering, verification, and model performance evaluation.

reductstore
ReductStore is a high-performance time series database designed for storing and managing large amounts of unstructured blob data. It offers features such as real-time querying, batching data, and HTTP(S) API for edge computing, computer vision, and IoT applications. The database ensures data integrity, implements retention policies, and provides efficient data access, making it a cost-effective solution for applications requiring unstructured data storage and access at specific time intervals.

ai-data-analysis-MulitAgent
AI-Driven Research Assistant is an advanced AI-powered system utilizing specialized agents for data analysis, visualization, and report generation. It integrates LangChain, OpenAI's GPT models, and LangGraph for complex research processes. Key features include hypothesis generation, data processing, web search, code generation, and report writing. The system's unique Note Taker agent maintains project state, reducing overhead and improving context retention. System requirements include Python 3.10+ and Jupyter Notebook environment. Installation involves cloning the repository, setting up a Conda virtual environment, installing dependencies, and configuring environment variables. Usage instructions include setting data, running Jupyter Notebook, customizing research tasks, and viewing results. Main components include agents for hypothesis generation, process supervision, visualization, code writing, search, report writing, quality review, and note-taking. Workflow involves hypothesis generation, processing, quality review, and revision. Customization is possible by modifying agent creation and workflow definition. Current issues include OpenAI errors, NoteTaker efficiency, runtime optimization, and refiner improvement. Contributions via pull requests are welcome under the MIT License.

nixtla
Nixtla is a production-ready generative pretrained transformer for time series forecasting and anomaly detection. It can accurately predict various domains such as retail, electricity, finance, and IoT with just a few lines of code. TimeGPT introduces a paradigm shift with its standout performance, efficiency, and simplicity, making it accessible even to users with minimal coding experience. The model is based on self-attention and is independently trained on a vast time series dataset to minimize forecasting error. It offers features like zero-shot inference, fine-tuning, API access, adding exogenous variables, multiple series forecasting, custom loss function, cross-validation, prediction intervals, and handling irregular timestamps.

postgresml
PostgresML is a powerful Postgres extension that seamlessly combines data storage and machine learning inference within your database. It enables running machine learning and AI operations directly within PostgreSQL, leveraging GPU acceleration for faster computations, integrating state-of-the-art large language models, providing built-in functions for text processing, enabling efficient similarity search, offering diverse ML algorithms, ensuring high performance, scalability, and security, supporting a wide range of NLP tasks, and seamlessly integrating with existing PostgreSQL tools and client libraries.

vulcan-sql
VulcanSQL is an Analytical Data API Framework for AI agents and data apps. It aims to help data professionals deliver RESTful APIs from databases, data warehouses or data lakes much easier and secure. It turns your SQL into APIs in no time!
incubator-hugegraph-ai
hugegraph-ai aims to explore the integration of HugeGraph with artificial intelligence (AI) and provide comprehensive support for developers to leverage HugeGraph's AI capabilities in their projects. It includes modules for large language models, graph machine learning, and a Python client for HugeGraph. The project aims to address challenges like timeliness, hallucination, and cost-related issues by integrating graph systems with AI technologies.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.

Upsonic
Upsonic offers a cutting-edge enterprise-ready framework for orchestrating LLM calls, agents, and computer use to complete tasks cost-effectively. It provides reliable systems, scalability, and a task-oriented structure for real-world cases. Key features include production-ready scalability, task-centric design, MCP server support, tool-calling server, computer use integration, and easy addition of custom tools. The framework supports client-server architecture and allows seamless deployment on AWS, GCP, or locally using Docker.

HuixiangDou2
HuixiangDou2 is a robustly optimized GraphRAG approach that integrates multiple open-source projects to improve performance in graph-based augmented generation. It conducts comparative experiments and achieves a significant score increase, leading to a GraphRAG implementation with recognized performance. The repository provides code improvements, dense retrieval for querying entities and relationships, real domain knowledge testing, and impact analysis on accuracy.

trustgraph
TrustGraph is a tool that deploys private GraphRAG pipelines to build a RDF style knowledge graph from data, enabling accurate and secure `RAG` requests compatible with cloud LLMs and open-source SLMs. It showcases the reliability and efficiencies of GraphRAG algorithms, capturing contextual language flags missed in conventional RAG approaches. The tool offers features like PDF decoding, text chunking, inference of various LMs, RDF-aligned Knowledge Graph extraction, and more. TrustGraph is designed to be modular, supporting multiple Language Models and environments, with a plug'n'play architecture for easy customization.
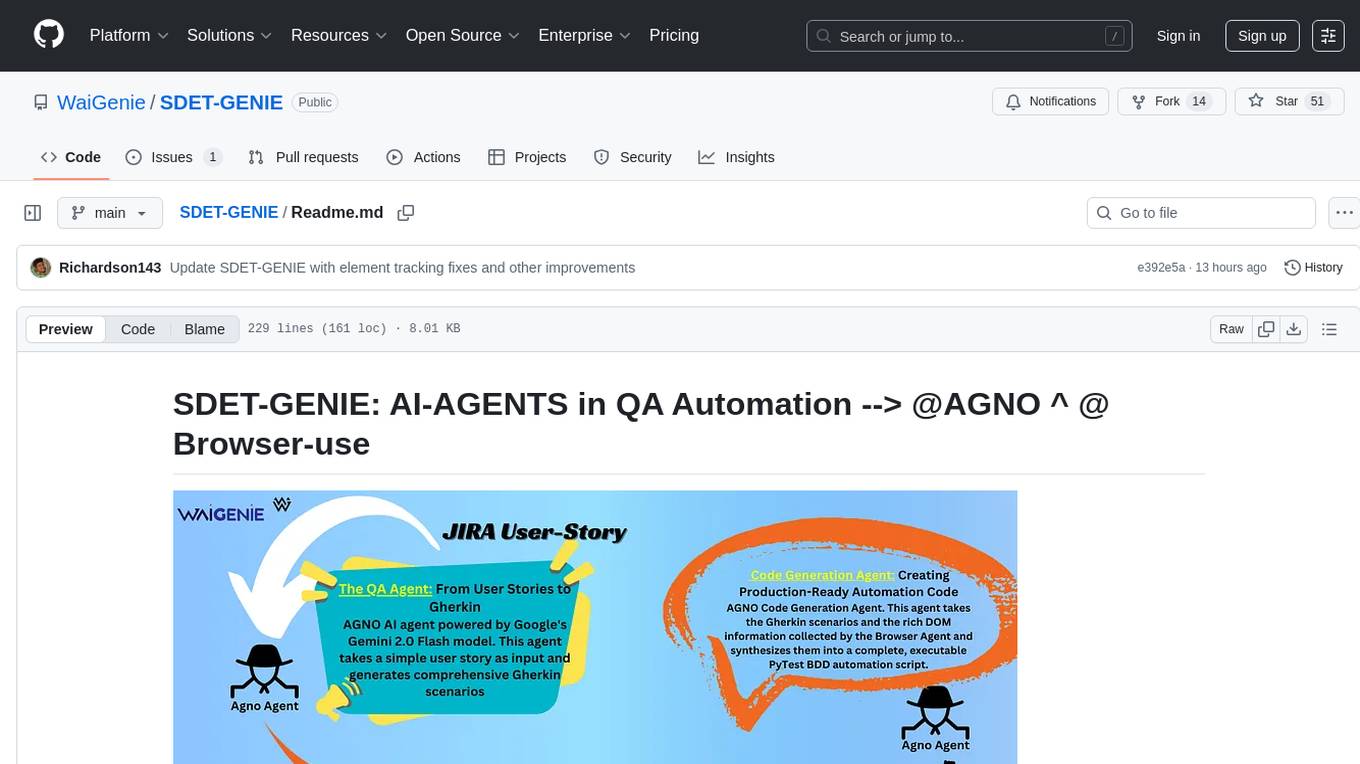
SDET-GENIE
SDET-GENIE is a cutting-edge, AI-powered Quality Assurance (QA) automation framework that revolutionizes the software testing process. Leveraging a suite of specialized AI agents, SDET-GENIE transforms rough user stories into comprehensive, executable test automation code through a seamless end-to-end process. The framework integrates five powerful AI agents working in sequence: User Story Enhancement Agent, Manual Test Case Agent, Gherkin Scenario Agent, Browser Agent, and Code Generation Agent. It supports multiple testing frameworks and provides advanced browser automation capabilities with AI features.

fenic
fenic is an opinionated DataFrame framework from typedef.ai for building AI and agentic applications. It transforms unstructured and structured data into insights using familiar DataFrame operations enhanced with semantic intelligence. With support for markdown, transcripts, and semantic operators, plus efficient batch inference across various model providers. fenic is purpose-built for LLM inference, providing a query engine designed for AI workloads, semantic operators as first-class citizens, native unstructured data support, production-ready infrastructure, and a familiar DataFrame API.
For similar tasks
ai-data-science-team
The AI Data Science Team of Copilots is an AI-powered data science team that uses agents to help users perform common data science tasks 10X faster. It includes agents specializing in data cleaning, preparation, feature engineering, modeling, and interpretation of business problems. The project is a work in progress with new data science agents to be released soon. Disclaimer: This project is for educational purposes only and not intended to replace a company's data science team. No warranties or guarantees are provided, and the creator assumes no liability for financial loss.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.
craftgen
Craftgen.ai is an innovative AI platform designed for both technical and non-technical users. It's built on a foundation of graph architecture for scalability and the Actor Model for efficient concurrent operations, tailored to both technical and non-technical users. A key aspect of Craftgen.ai is its modular AI approach, allowing users to assemble and customize AI components like building blocks to fit their specific needs. The platform's robustness is enhanced by its event-driven architecture, ensuring reliable data processing and featuring browser web technologies for universal access. Craftgen.ai excels in dynamic tool and workflow generation, with strong offline capabilities for secure environments and plans for desktop application integration. A unique and valuable feature of Craftgen.ai is its marketplace, where users can access a variety of pre-built AI solutions. This marketplace accelerates the deployment of AI tools but also fosters a community of sharing and innovation. Users can contribute to and leverage this repository of solutions, enhancing the platform's versatility and practicality. Craftgen.ai uses JSON schema for industry-standard alignment, enabling seamless integration with any API following the OpenAPI spec. This allows for a broad range of applications, from automating data analysis to streamlining content management. The platform is designed to bridge the gap between advanced AI technology and practical usability. It's a flexible, secure, and intuitive platform that empowers users, from developers seeking to create custom AI solutions to businesses looking to automate routine tasks. Craftgen.ai's goal is to make AI technology an integral, seamless part of everyday problem-solving and innovation, providing a platform where modular AI and a thriving marketplace converge to meet the diverse needs of its users.
Data-Science-EBooks
This repository contains a collection of resources in the form of eBooks related to Data Science, Machine Learning, and similar topics.

BambooAI
BambooAI is a lightweight library utilizing Large Language Models (LLMs) to provide natural language interaction capabilities, much like a research and data analysis assistant enabling conversation with your data. You can either provide your own data sets, or allow the library to locate and fetch data for you. It supports Internet searches and external API interactions.
ai_wiki
This repository provides a comprehensive collection of resources, open-source tools, and knowledge related to quantitative analysis. It serves as a valuable knowledge base and navigation guide for individuals interested in various aspects of quantitative investing, including platforms, programming languages, mathematical foundations, machine learning, deep learning, and practical applications. The repository is well-structured and organized, with clear sections covering different topics. It includes resources on system platforms, programming codes, mathematical foundations, algorithm principles, machine learning, deep learning, reinforcement learning, graph networks, model deployment, and practical applications. Additionally, there are dedicated sections on quantitative trading and investment, as well as large models. The repository is actively maintained and updated, ensuring that users have access to the latest information and resources.

free-for-life
A massive list including a huge amount of products and services that are completely free! ⭐ Star on GitHub • 🤝 Contribute # Table of Contents * APIs, Data & ML * Artificial Intelligence * BaaS * Code Editors * Code Generation * DNS * Databases * Design & UI * Domains * Email * Font * For Students * Forms * Linux Distributions * Messaging & Streaming * PaaS * Payments & Billing * SSL
For similar jobs
ai-data-science-team
The AI Data Science Team of Copilots is an AI-powered data science team that uses agents to help users perform common data science tasks 10X faster. It includes agents specializing in data cleaning, preparation, feature engineering, modeling, and interpretation of business problems. The project is a work in progress with new data science agents to be released soon. Disclaimer: This project is for educational purposes only and not intended to replace a company's data science team. No warranties or guarantees are provided, and the creator assumes no liability for financial loss.

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.

OAD
OAD is a powerful open-source tool for analyzing and visualizing data. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With OAD, users can easily import data from various sources, clean and preprocess data, perform statistical analysis, and create customizable visualizations to communicate findings effectively. Whether you are a data scientist, analyst, or researcher, OAD can help you streamline your data analysis workflow and uncover valuable insights from your data.

sqlcoder
Defog's SQLCoder is a family of state-of-the-art large language models (LLMs) designed for converting natural language questions into SQL queries. It outperforms popular open-source models like gpt-4 and gpt-4-turbo on SQL generation tasks. SQLCoder has been trained on more than 20,000 human-curated questions based on 10 different schemas, and the model weights are licensed under CC BY-SA 4.0. Users can interact with SQLCoder through the 'transformers' library and run queries using the 'sqlcoder launch' command in the terminal. The tool has been tested on NVIDIA GPUs with more than 16GB VRAM and Apple Silicon devices with some limitations. SQLCoder offers a demo on their website and supports quantized versions of the model for consumer GPUs with sufficient memory.

TableLLM
TableLLM is a large language model designed for efficient tabular data manipulation tasks in real office scenarios. It can generate code solutions or direct text answers for tasks like insert, delete, update, query, merge, and chart operations on tables embedded in spreadsheets or documents. The model has been fine-tuned based on CodeLlama-7B and 13B, offering two scales: TableLLM-7B and TableLLM-13B. Evaluation results show its performance on benchmarks like WikiSQL, Spider, and self-created table operation benchmark. Users can use TableLLM for code and text generation tasks on tabular data.

mlcraft
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube (Cube.js) for flexible data models that consolidate metrics from various sources, enabling downstream distribution via a SQL API for integration into BI tools, reporting, dashboards, and data science. Use cases include data democratization, business intelligence, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.

data-scientist-roadmap2024
The Data Scientist Roadmap2024 provides a comprehensive guide to mastering essential tools for data science success. It includes programming languages, machine learning libraries, cloud platforms, and concepts categorized by difficulty. The roadmap covers a wide range of topics from programming languages to machine learning techniques, data visualization tools, and DevOps/MLOps tools. It also includes web development frameworks and specific concepts like supervised and unsupervised learning, NLP, deep learning, reinforcement learning, and statistics. Additionally, it delves into DevOps tools like Airflow and MLFlow, data visualization tools like Tableau and Matplotlib, and other topics such as ETL processes, optimization algorithms, and financial modeling.

VMind
VMind is an open-source solution for intelligent visualization, providing an intelligent chart component based on LLM by VisActor. It allows users to create chart narrative works with natural language interaction, edit charts through dialogue, and export narratives as videos or GIFs. The tool is easy to use, scalable, supports various chart types, and offers one-click export functionality. Users can customize chart styles, specify themes, and aggregate data using LLM models. VMind aims to enhance efficiency in creating data visualization works through dialogue-based editing and natural language interaction.