
amazon-kendra-langchain-extensions
Samples to build Generative AI applications with LangChain and Amazon Kendra
Stars: 146
This directory contains samples for a QA chain using an AmazonKendraRetriever class. For more info see the samples README. Note : If you are using an older version of the repo which contains the aws_langchain package, please clone this repo in a new location to avoid any conflicts with the older environment. We are deprecating the aws_langchain package, since the kendra retriever class is available in LangChain starting v0.0.213.
README:
This directory contains samples for a QA chain using an AmazonKendraRetriever class. For more info see the samples README.
Note: If you are using an older version of the repo which contains the aws_langchain package, please clone this repo in a new location to avoid any conflicts with the older environment. We are deprecating the aws_langchain package, since the kendra retriever class is available in LangChain starting v0.0.213.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for amazon-kendra-langchain-extensions
Similar Open Source Tools
amazon-kendra-langchain-extensions
This directory contains samples for a QA chain using an AmazonKendraRetriever class. For more info see the samples README. Note : If you are using an older version of the repo which contains the aws_langchain package, please clone this repo in a new location to avoid any conflicts with the older environment. We are deprecating the aws_langchain package, since the kendra retriever class is available in LangChain starting v0.0.213.
nanoPerplexityAI
nanoPerplexityAI is an open-source implementation of a large language model service that fetches information from Google. It involves a simple architecture where the user query is checked by the language model, reformulated for Google search, and an answer is generated and saved in a markdown file. The tool requires minimal setup and is designed for easy visualization of answers.

PromptAgent
PromptAgent is a repository for a novel automatic prompt optimization method that crafts expert-level prompts using language models. It provides a principled framework for prompt optimization by unifying prompt sampling and rewarding using MCTS algorithm. The tool supports different models like openai, palm, and huggingface models. Users can run PromptAgent to optimize prompts for specific tasks by strategically sampling model errors, generating error feedbacks, simulating future rewards, and searching for high-reward paths leading to expert prompts.

lumigator
Lumigator is an open-source platform developed by Mozilla.ai to help users select the most suitable language model for their specific needs. It supports the evaluation of summarization tasks using sequence-to-sequence models such as BART and BERT, as well as causal models like GPT and Mistral. The platform aims to make model selection transparent, efficient, and empowering by providing a framework for comparing LLMs using task-specific metrics to evaluate how well a model fits a project's needs. Lumigator is in the early stages of development and plans to expand support to additional machine learning tasks and use cases in the future.
cluster-toolkit
Cluster Toolkit is an open-source software by Google Cloud for deploying AI/ML and HPC environments on Google Cloud. It allows easy deployment following best practices, with high customization and extensibility. The toolkit includes tutorials, examples, and documentation for various modules designed for AI/ML and HPC use cases.

eureka-ml-insights
The Eureka ML Insights Framework is a repository containing code designed to help researchers and practitioners run reproducible evaluations of generative models efficiently. Users can define custom pipelines for data processing, inference, and evaluation, as well as utilize pre-defined evaluation pipelines for key benchmarks. The framework provides a structured approach to conducting experiments and analyzing model performance across various tasks and modalities.

serena
Serena is a powerful coding agent that integrates with existing LLMs to provide essential semantic code retrieval and editing tools. It is free to use and does not require API keys or subscriptions. Serena can be used for coding tasks such as analyzing, planning, and editing code directly on your codebase. It supports various programming languages and offers semantic code analysis capabilities through language servers. Serena can be integrated with different LLMs using the model context protocol (MCP) or Agno framework. The tool provides a range of functionalities for code retrieval, editing, and execution, making it a versatile coding assistant for developers.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.
llms-txt
The llms-txt repository proposes a standardization on using an `/llms.txt` file to provide information to help large language models (LLMs) use a website at inference time. The `llms.txt` file is a markdown file that offers brief background information, guidance, and links to more detailed information in markdown files. It aims to provide concise and structured information for LLMs to access easily, helping users interact with websites via AI helpers. The repository also includes tools like a CLI and Python module for parsing `llms.txt` files and generating LLM context from them, along with a sample JavaScript implementation. The proposal suggests adding clean markdown versions of web pages alongside the original HTML pages to facilitate LLM readability and access to essential information.
BentoDiffusion
BentoDiffusion is a BentoML example project that demonstrates how to serve and deploy diffusion models in the Stable Diffusion (SD) family. These models are specialized in generating and manipulating images based on text prompts. The project provides a guide on using SDXL Turbo as an example, along with instructions on prerequisites, installing dependencies, running the BentoML service, and deploying to BentoCloud. Users can interact with the deployed service using Swagger UI or other methods. Additionally, the project offers the option to choose from various diffusion models available in the repository for deployment.
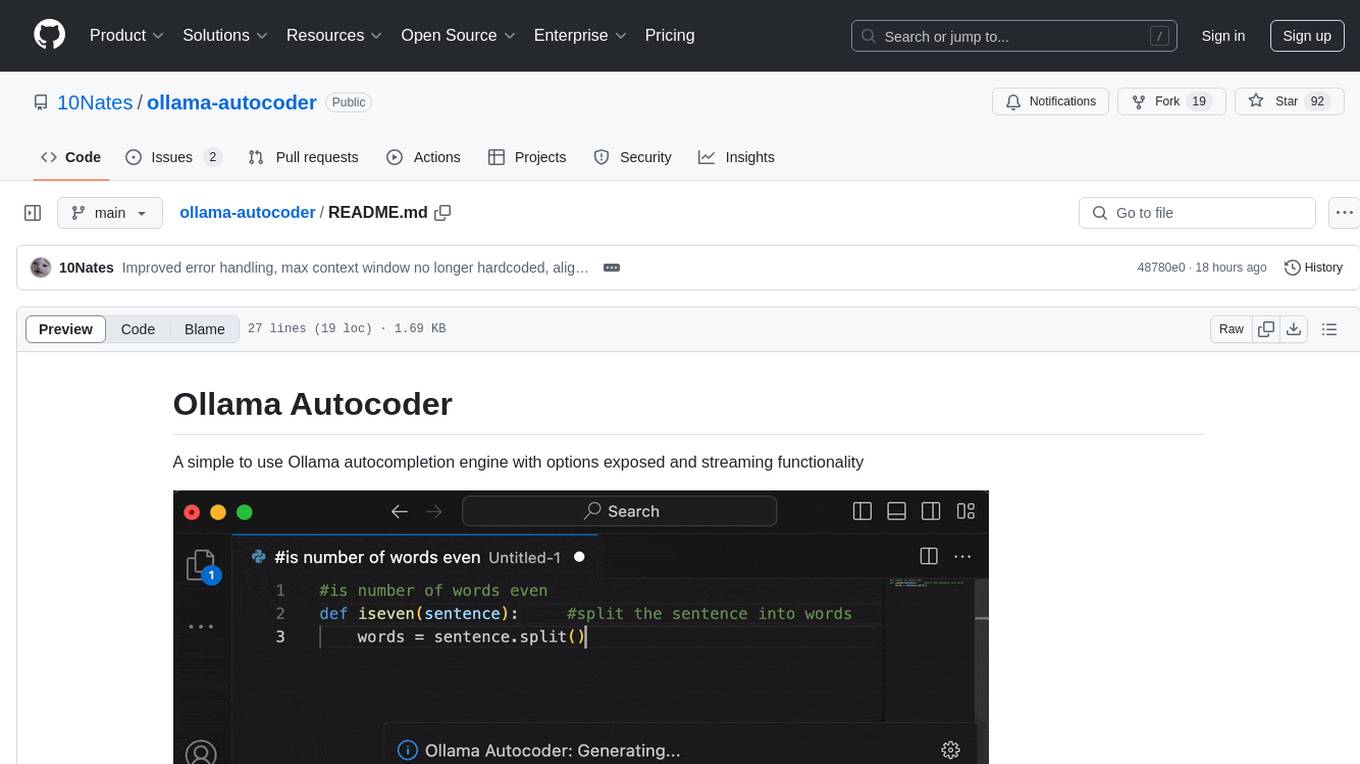
ollama-autocoder
Ollama Autocoder is a simple to use autocompletion engine that integrates with Ollama AI. It provides options for streaming functionality and requires specific settings for optimal performance. Users can easily generate text completions by pressing a key or using a command pallete. The tool is designed to work with Ollama API and a specified model, offering real-time generation of text suggestions.

GlaDOS
This project aims to create a real-life version of GLaDOS, an aware, interactive, and embodied AI entity. It involves training a voice generator, developing a 'Personality Core,' implementing a memory system, providing vision capabilities, creating 3D-printable parts, and designing an animatronics system. The software architecture focuses on low-latency voice interactions, utilizing a circular buffer for data recording, text streaming for quick transcription, and a text-to-speech system. The project also emphasizes minimal dependencies for running on constrained hardware. The hardware system includes servo- and stepper-motors, 3D-printable parts for GLaDOS's body, animations for expression, and a vision system for tracking and interaction. Installation instructions cover setting up the TTS engine, required Python packages, compiling llama.cpp, installing an inference backend, and voice recognition setup. GLaDOS can be run using 'python glados.py' and tested using 'demo.ipynb'.

atomic_agents
Atomic Agents is a modular and extensible framework designed for creating powerful applications. It follows the principles of Atomic Design, emphasizing small and single-purpose components. Leveraging Pydantic for data validation and serialization, the framework offers a set of tools and agents that can be combined to build AI applications. It depends on the Instructor package and supports various APIs like OpenAI, Cohere, Anthropic, and Gemini. Atomic Agents is suitable for developers looking to create AI agents with a focus on modularity and flexibility.
trackmania_rl_public
This repository contains the reinforcement learning training code for Trackmania AI with Reinforcement Learning. It is a research work-in-progress project that aims to apply reinforcement learning principles to play Trackmania. The code is constantly evolving and may not be clean or easily usable. The training hyperparameters are intentionally changed in the public repository to encourage understanding of reinforcement learning principles. The project may not receive active support for setup or usage at the moment.

airbroke
Airbroke is an open-source error catcher tool designed for modern web applications. It provides a PostgreSQL-based backend with an Airbrake-compatible HTTP collector endpoint and a React-based frontend for error management. The tool focuses on simplicity, maintaining a small database footprint even under heavy data ingestion. Users can ask AI about issues, replay HTTP exceptions, and save/manage bookmarks for important occurrences. Airbroke supports multiple OAuth providers for secure user authentication and offers occurrence charts for better insights into error occurrences. The tool can be deployed in various ways, including building from source, using Docker images, deploying on Vercel, Render.com, Kubernetes with Helm, or Docker Compose. It requires Node.js, PostgreSQL, and specific system resources for deployment.
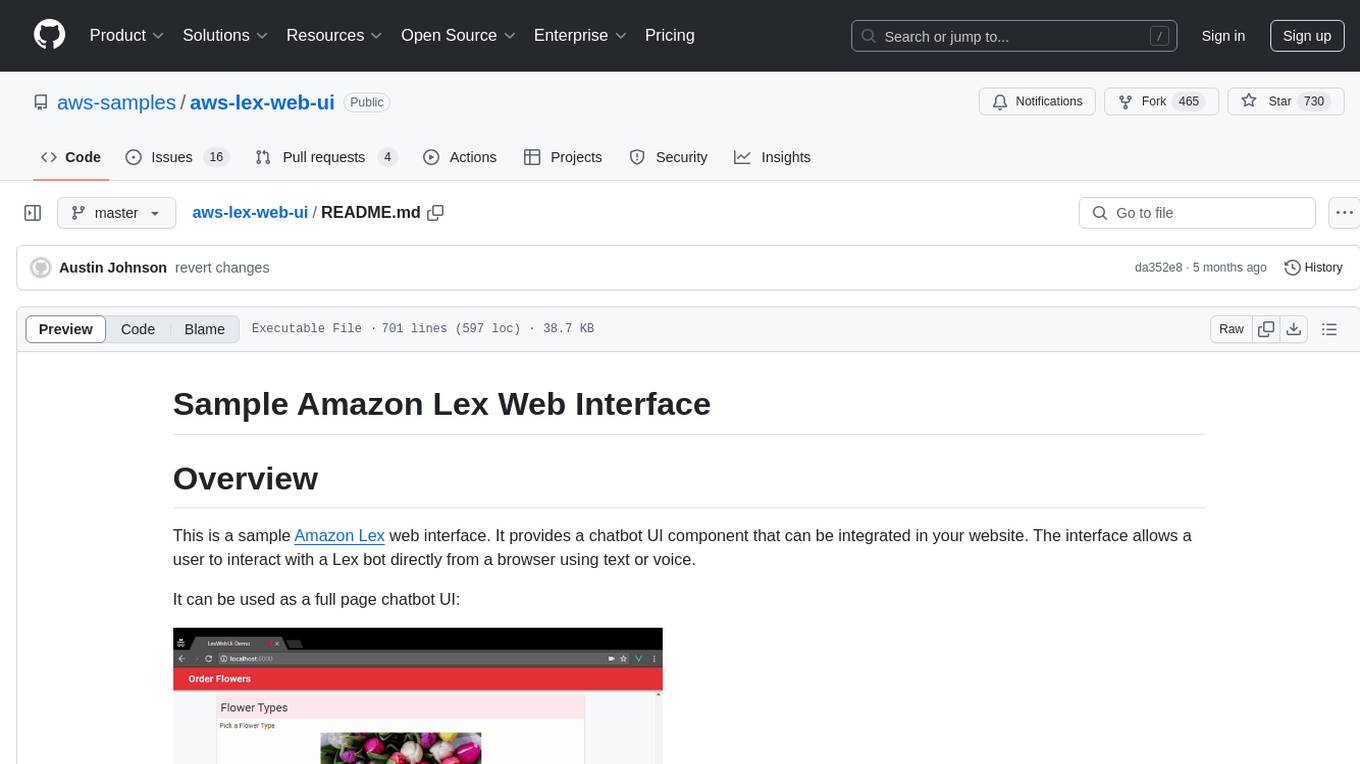
aws-lex-web-ui
The AWS Lex Web UI is a sample Amazon Lex web interface that provides a chatbot UI component for integration into websites. It supports voice and text interactions, Lex response cards, and programmable configuration using JavaScript. The interface can be used as a full-page chatbot UI or embedded as a widget. It offers mobile-ready responsive UI, seamless voice-text switching, and interactive messaging support. The project includes CloudFormation templates for easy deployment and customization. Users can modify configurations, integrate the UI into existing sites, and deploy using various methods like CloudFormation, pre-built libraries, or npm installation.