
repo2txt
Web-based tool converts GitHub repository contents into a single formatted text file
Stars: 703
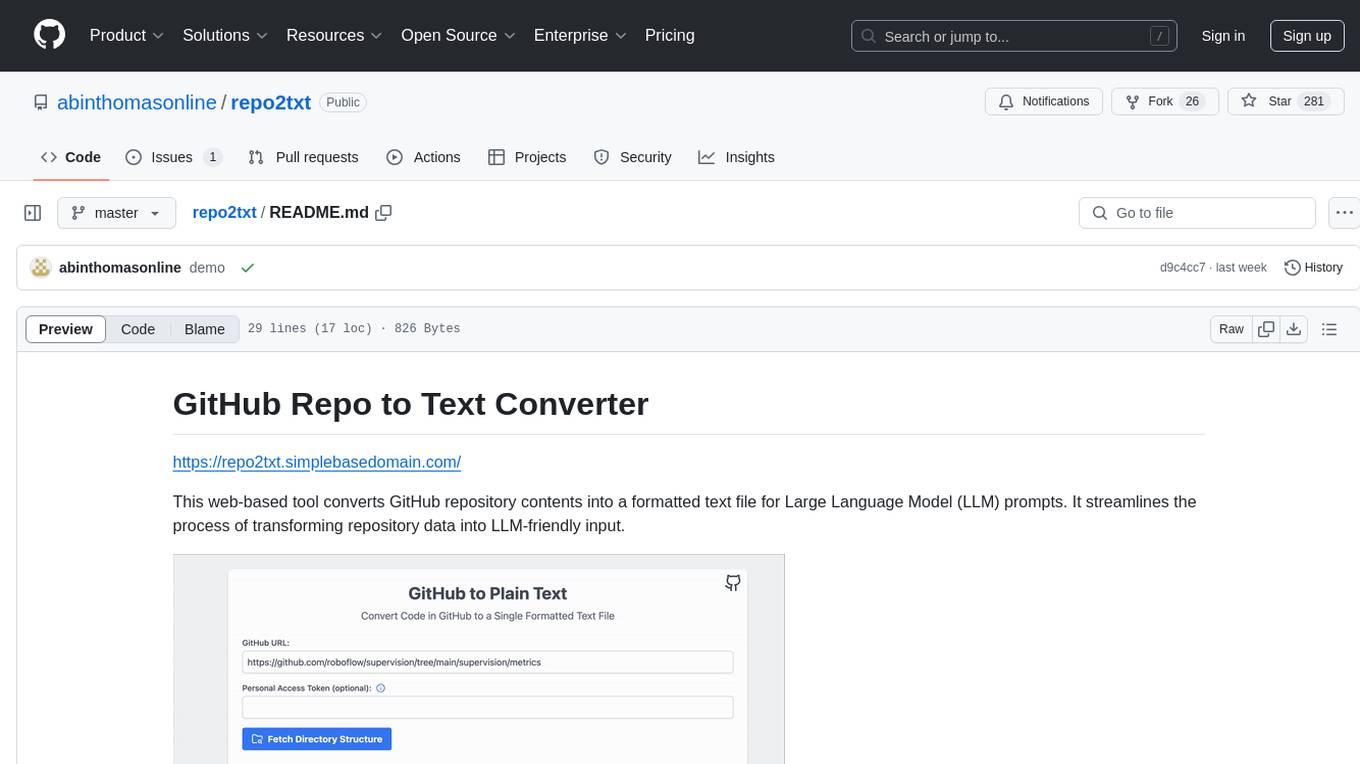
The GitHub Repo to Text Converter is a web-based tool that converts GitHub repository contents into a formatted text file for Large Language Model (LLM) prompts. It streamlines the process of transforming repository data into LLM-friendly input. The tool displays the GitHub repository structure, allows users to select files/directories to include, generates a formatted text file, enables copying text to clipboard, supports downloading generated text, and works with private repositories. It ensures data security by running entirely in the browser without server-side processing.
README:
https://repo2txt.simplebasedomain.com/
This web-based tool converts GitHub repository (or local directory) contents into a formatted text file for Large Language Model (LLM) prompts. It streamlines the process of transforming repository data into LLM-friendly input.

- Display GitHub repository structure
- Select files/directories to include
- Filter files by extensions
- Generate formatted text file
- Copy text to clipboard
- Download generated text
- Support for private repositories
- Browser-based for privacy and security
- Download zip of selected files
- Local directory support
This tool runs entirely in the browser, ensuring data security without server-side processing.
- Compile tailwind css (gh action maybe?)
- python bindings
Contributions are welcome! Please feel free to submit a Pull Request.
This project is open source and available under the MIT License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for repo2txt
Similar Open Source Tools
repo2txt
The GitHub Repo to Text Converter is a web-based tool that converts GitHub repository contents into a formatted text file for Large Language Model (LLM) prompts. It streamlines the process of transforming repository data into LLM-friendly input. The tool displays the GitHub repository structure, allows users to select files/directories to include, generates a formatted text file, enables copying text to clipboard, supports downloading generated text, and works with private repositories. It ensures data security by running entirely in the browser without server-side processing.
llmstxt-generator
llms.txt Generator is a tool designed for LLM (Legal Language Model) training and inference. It crawls websites to combine content into consolidated text files, offering both standard and full versions. Users can access the tool through a web interface or API without requiring an API key. Powered by Firecrawl for web crawling and GPT-4-mini for text processing.

document-ai-samples
The Google Cloud Document AI Samples repository contains code samples and Community Samples demonstrating how to analyze, classify, and search documents using Google Cloud Document AI. It includes various projects showcasing different functionalities such as integrating with Google Drive, processing documents using Python, content moderation with Dialogflow CX, fraud detection, language extraction, paper summarization, tax processing pipeline, and more. The repository also provides access to test document files stored in a publicly-accessible Google Cloud Storage Bucket. Additionally, there are codelabs available for optical character recognition (OCR), form parsing, specialized processors, and managing Document AI processors. Community samples, like the PDF Annotator Sample, are also included. Contributions are welcome, and users can seek help or report issues through the repository's issues page. Please note that this repository is not an officially supported Google product and is intended for demonstrative purposes only.
tools
This repository contains a collection of various tools and utilities that can be used for different purposes. It includes scripts, programs, and resources to assist with tasks related to software development, data analysis, automation, and more. The tools are designed to be versatile and easy to use, providing solutions for common challenges faced by developers and users alike.
airdcpp-webclient
AirDC++ Web Client is a locally installed application designed for flexible file sharing within groups over a local network or the internet. It utilizes the Advanced Direct Connect protocol to create file sharing communities with thousands of users. The application offers a responsive web user interface, allows sharing local directories, searching for shared files, saving files, chatting capabilities, browsing shared directories, extension support, and a web API for HTTP REST and WebSockets.
vulnrepo
VULNRΞPO is a vulnerability report generator and repository tool that prioritizes security by using browser-based encryption and storing data locally. It offers features such as custom templates for pentesters, importing issues from various security scanners, multiple report formats (TXT, HTML, DOCX, PDF), attachment support with checksum verification, changelog tracking, issue export to bugtrackers, AES encryption for report sharing, API integration for backend storage, report template customization, audit tool for research completeness, and local LLM model usage. The tool is designed for efficient vulnerability management and secure report generation.
OpenContracts
OpenContracts is an Apache-2 licensed enterprise document analytics tool that supports multiple formats, including PDF and txt-based formats. It features multiple document ingestion pipelines with a pluggable architecture for easy format and ingestion engine support. Users can create custom document analytics tools with beautiful result displays, support mass document data extraction with a LlamaIndex wrapper, and manage document collections, layout parsing, automatic vector embeddings, and human annotation. The tool also offers pluggable parsing pipelines, human annotation interface, LlamaIndex integration, data extraction capabilities, and custom data extract pipelines for bulk document querying.
file-organizer-2000
AI File Organizer 2000 is an Obsidian Plugin that uses AI to transcribe audio, annotate images, and automatically organize files by moving them to the most likely folders. It supports text, audio, and images, with upcoming local-first LLM support. Users can simply place unorganized files into the 'Inbox' folder for automatic organization. The tool renames and moves files quickly, providing a seamless file organization experience. Self-hosting is also possible by running the server and enabling the 'Self-hosted' option in the plugin settings. Join the community Discord server for more information and use the provided iOS shortcut for easy access on mobile devices.
bedrock-engineer
Bedrock Engineer is an autonomous software development agent application that utilizes Amazon Bedrock. It allows users to customize, create/edit files, execute commands, search the web, use a knowledge base, utilize multi-agents, generate images, and more. The tool provides an interactive chat interface with AI agents, file system operations, web search capabilities, project structure management, code analysis, code generation, data analysis, agent and tool customization, chat history management, and multi-language support. Users can select and customize agents, choose from various tools like file system operations, web search, Amazon Bedrock integration, and system command execution. Additionally, the tool offers features for website generation, connecting to design system data sources, AWS Step Functions ASL definition generation, diagram creation using natural language descriptions, and multi-language support.
DeepBI
DeepBI is an AI-native data analysis platform that leverages the power of large language models to explore, query, visualize, and share data from any data source. Users can use DeepBI to gain data insight and make data-driven decisions.
rowfill
Rowfill is an open-source document processing platform designed for knowledge workers. It offers advanced AI capabilities to extract, analyze, and process data from complex documents, images, and PDFs. The platform features advanced OCR and processing functionalities, auto-schema generation, and custom actions for creating tailored workflows. It prioritizes privacy and security by supporting Local LLMs like Llama and Mistral, syncing with company data while maintaining privacy, and being open source with AGPLv3 licensing. Rowfill is a versatile tool that aims to streamline document processing tasks for users in various industries.

quantizr
Quanta is a new kind of Content Management platform, with powerful features including: Wikis & micro-blogging, ChatGPT Question Answering, Document collaboration and publishing, PDF Generation, Secure messaging with (E2E Encryption), Video/audio recording & sharing, File sharing, Podcatcher (RSS Reader), and many other features related to managing hierarchical content.
The-Creator-AI
The Creator AI is a VS Code extension that integrates a coding assistant allowing users to choose files/folders through UI and describe code changes for AI-generated implementation plans. It requires an API key for Gemini or OpenAI. The extension follows VS Code guidelines and best practices, providing functionalities like basic chat, change plan, and file explorer. Users can edit the README using Visual Studio Code with useful keyboard shortcuts. Enjoy enhanced coding experience with The Creator AI.
awesome-limitless
A curated list of amazing projects and resources built with the Limitless AI Pendant API. It includes applications, CLI tools, data visualization tools, integrations with plugins and extensions, utilities for server conversion and data ingestion, SDKs and libraries for Go and TypeScript, learning resources, and official API documentation.
fast-wiki
FastWiki is an enterprise-level artificial intelligence customer service management system. It is a high-performance knowledge base system designed for large-scale information retrieval and intelligent search. Leveraging Microsoft's Semantic Kernel for deep learning and natural language processing, combined with .NET 8 and React framework, it provides an efficient, user-friendly, and scalable intelligent vector search platform. The system aims to offer an intelligent search solution that can understand and process complex queries, assisting users in quickly and accurately obtaining the needed information.
Visual-Code-Space
Visual Code Space is a modern code editor designed specifically for Android devices. It offers a seamless and efficient coding environment with features like blazing fast file explorer, multi-language syntax highlighting, tabbed editor, integrated terminal emulator, ad-free experience, and plugin support. Users can enhance their mobile coding experience with this cutting-edge editor that allows customization through custom plugins written in BeanShell. The tool aims to simplify coding on the go by providing a user-friendly interface and powerful functionalities.
For similar tasks
repo2txt
The GitHub Repo to Text Converter is a web-based tool that converts GitHub repository contents into a formatted text file for Large Language Model (LLM) prompts. It streamlines the process of transforming repository data into LLM-friendly input. The tool displays the GitHub repository structure, allows users to select files/directories to include, generates a formatted text file, enables copying text to clipboard, supports downloading generated text, and works with private repositories. It ensures data security by running entirely in the browser without server-side processing.

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.
RepoToText
RepoToText is a web app that scrapes a GitHub repository and converts its files into a single organized .txt. It allows users to enter the URL of a GitHub repository and an optional documentation URL, retrieves the contents of the repository and documentation, and saves them in a structured text file. The tool can be used to interact with the repository using chatbots like GPT-4 or Claude Opus. Users can run the application with Docker, set up environment variables, choose specific file types for scraping, and copy the generated text to the clipboard. Additionally, FolderToText.py script allows converting local folders or files into a .txt file with customizable options.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.