
models
This repository contains comprehensive pricing and configuration data for LLMs. It powers cost attribution for 200+ enterprises running 400B+ tokens through Portkey AI Gateway every day.
Stars: 52
This repository contains comprehensive pricing and configuration data for LLMs, providing accurate pricing for 2,000+ models across 40+ providers. It addresses the challenges of LLM pricing, such as naming inconsistencies, varied pricing units, hidden dimensions, and rapid pricing changes. The repository offers a free API without authentication requirements, enabling users to access model configurations and pricing information easily. It aims to create a community-maintained database to streamline cost attribution for enterprises utilizing LLMs.
README:
Accurate pricing for 2,000+ models across 40+ providers. Free API, no auth required.
Explorer · Rankings · API · Contributing · Discord



This repository contains comprehensive pricing and configuration data for LLMs. It powers cost attribution for 200+ enterprises running 400B+ tokens through Portkey AI Gateway every day.
LLM pricing is a mess. Every team building on LLMs ends up maintaining its own spreadsheet — and it's stale by Friday.
-
The Naming Problem —
gpt-5,gpt-5.2-pro-2025-12-11,o1,o3-miniare all different models with different prices - The Units Problem — OpenAI charges tokens, Google charges characters, Cohere uses "generations" and "summarization units"
- The Hidden Dimensions Problem — Thinking tokens, cache writes vs. reads, context thresholds, per-request fees, multimodal surcharges
- The Velocity Problem — DeepSeek dropped R1 pricing 75% in weeks. Google releases new tiers mid-quarter with no announcement
We built this as an open, community-maintained database to solve that problem.
🔓 Free API. No authentication required.
curl https://api.portkey.ai/model-configs/pricing/{provider}/{model}# Examples
curl https://api.portkey.ai/model-configs/pricing/openai/gpt-5
curl https://api.portkey.ai/model-configs/pricing/anthropic/claude-sonnet-4-5-20250514
curl https://api.portkey.ai/model-configs/pricing/google/gemini-3.0-pro📖 Full API Documentation — Response schema, model configuration endpoints, and more.
⚠️ Prices are in cents per token, not dollars.
| JSON | Per 1K | Per 1M |
|---|---|---|
0.003 |
$0.03 | $30 |
0.00025 |
$0.0025 | $2.50 |
1 |
$10 | $10,000 |
const costDollars = (tokens * price) / 100;{
"model-name": {
"pricing_config": {
"pay_as_you_go": {
"request_token": { "price": 0.00025 },
"response_token": { "price": 0.001 },
"cache_write_input_token": { "price": 0 },
"cache_read_input_token": { "price": 0.000125 },
"additional_units": {
"web_search": { "price": 1 }
}
},
"currency": "USD"
}
}
}| Field | Description |
|---|---|
request_token |
Input |
response_token |
Output |
cache_write_input_token |
Cache write |
cache_read_input_token |
Cache read |
request_audio_token |
Audio input |
response_audio_token |
Audio output |
image |
Image gen (by quality/size) |
additional_units |
Provider-specific (see below) |
| Unit | Providers | Price (¢) |
|---|---|---|
web_search |
openai, azure-openai, azure-ai, google, vertex-ai, perplexity-ai | 0.5 - 3.5 |
file_search |
openai, azure-openai, azure-ai | 0.25 |
search |
google, vertex-ai | 1.4 - 3.5 |
thinking_token |
google, vertex-ai | 0.00004 - 0.0012 |
image_token |
google, vertex-ai | 0.003 |
image_1k |
3.9 | |
megapixels |
together-ai | 0.0027 - 0.08 |
video_seconds |
vertex-ai | 10 - 50 |
video_duration_seconds_720_1280 |
openai, azure-openai | 10 - 30 |
video_duration_seconds_1280_720 |
openai, azure-openai | 10 - 30 |
video_duration_seconds_1024_1792 |
openai, azure-openai | 50 |
video_duration_seconds_1792_1024 |
openai, azure-openai | 50 |
request_audio_token |
openai, azure-openai | 0 - 0.6 |
response_audio_token |
openai, azure-openai | 0 - 1.5 |
routing_units |
azure-openai | 0.000014 |
input_image |
vertex-ai | 0.01 |
input_video_essential |
vertex-ai | 0.05 |
input_video_standard |
vertex-ai | 0.1 |
input_video_plus |
vertex-ai | 0.2 |
| Unit | Price (¢) |
|---|---|
web_search_low_context |
0.5 - 0.6 |
web_search_medium_context |
0.8 - 1.0 |
web_search_high_context |
1.2 - 1.4 |
// OpenAI (gpt-5, o3, o4-mini)
"additional_units": {
"web_search": { "price": 1 },
"file_search": { "price": 0.25 }
}
// Google (gemini-3.0-pro)
"additional_units": {
"thinking_token": { "price": 0.001 },
"web_search": { "price": 3.5 }
}
// OpenAI Sora
"additional_units": {
"video_duration_seconds_720_1280": { "price": 10 }
}
// Together AI (image models)
"additional_units": {
"megapixels": { "price": 0.05 }
}Batch API pricing is defined in a separate batch_config section at the same level as pay_as_you_go. Prices are specified as exact values matching the provider's published batch pricing.
| Field | Description |
|---|---|
request_token |
Batch API input price |
response_token |
Batch API output price |
cache_read_input_token |
Batch API cache read price |
Schema:
{
"pricing_config": {
"pay_as_you_go": {
"request_token": { "price": 0.00025 },
"response_token": { "price": 0.001 }
},
"batch_config": {
"request_token": { "price": 0.000125 },
"response_token": { "price": 0.0005 }
}
}
}Notes:
- Batch prices are typically 50% of standard pricing for text models
- Embedding models typically have 20% discount for batch
Supported Providers: OpenAI, Anthropic, Google (Vertex AI)
The easiest way to contribute is to pick an issue with the good first issue tag 💪.
- Fork this repo
- Edit
pricing/{provider}.json - Submit a PR with source link
Remember: Prices are in cents per token: $0.03/1K → 0.003
40+ providers
AI21, Anthropic, Anyscale, Azure AI, Azure OpenAI, AWS Bedrock, Cerebras, Cohere, Dashscope, Deepbricks, DeepInfra, DeepSeek, Fireworks AI, GitHub, Google, Groq, Inference.net, Jina, Lambda, Lemonfox AI, Mistral AI, MonsterAPI, Nebius, Nomic, Novita AI, OpenAI, OpenRouter, Oracle, PaLM, Perplexity AI, Predibase, Reka AI, Sagemaker, Segmind, Stability AI, Together AI, Vertex AI, Workers AI, X.AI, Zhipu
Join our growing community around the world, for help, ideas, and discussions on AI.
- Chat with us on Discord
- Follow us on Twitter
- Connect with us on LinkedIn
- Visit us on YouTube
- Read our Blog
- View our official Documentation
Built by Portkey
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for models
Similar Open Source Tools
models
This repository contains comprehensive pricing and configuration data for LLMs, providing accurate pricing for 2,000+ models across 40+ providers. It addresses the challenges of LLM pricing, such as naming inconsistencies, varied pricing units, hidden dimensions, and rapid pricing changes. The repository offers a free API without authentication requirements, enabling users to access model configurations and pricing information easily. It aims to create a community-maintained database to streamline cost attribution for enterprises utilizing LLMs.

llm.nvim
llm.nvim is a universal plugin for a large language model (LLM) designed to enable users to interact with LLM within neovim. Users can customize various LLMs such as gpt, glm, kimi, and local LLM. The plugin provides tools for optimizing code, comparing code, translating text, and more. It also supports integration with free models from Cloudflare, Github models, siliconflow, and others. Users can customize tools, chat with LLM, quickly translate text, and explain code snippets. The plugin offers a flexible window interface for easy interaction and customization.
shodh-memory
Shodh-Memory is a cognitive memory system designed for AI agents to persist memory across sessions, learn from experience, and run entirely offline. It features Hebbian learning, activation decay, and semantic consolidation, packed into a single ~17MB binary. Users can deploy it on cloud, edge devices, or air-gapped systems to enhance the memory capabilities of AI agents.
AnyCrawl
AnyCrawl is a high-performance crawling and scraping toolkit designed for SERP crawling, web scraping, site crawling, and batch tasks. It offers multi-threading and multi-process capabilities for high performance. The tool also provides AI extraction for structured data extraction from pages, making it LLM-friendly and easy to integrate and use.
api-for-open-llm
This project provides a unified backend interface for open large language models (LLMs), offering a consistent experience with OpenAI's ChatGPT API. It supports various open-source LLMs, enabling developers to seamlessly integrate them into their applications. The interface features streaming responses, text embedding capabilities, and support for LangChain, a tool for developing LLM-based applications. By modifying environment variables, developers can easily use open-source models as alternatives to ChatGPT, providing a cost-effective and customizable solution for various use cases.
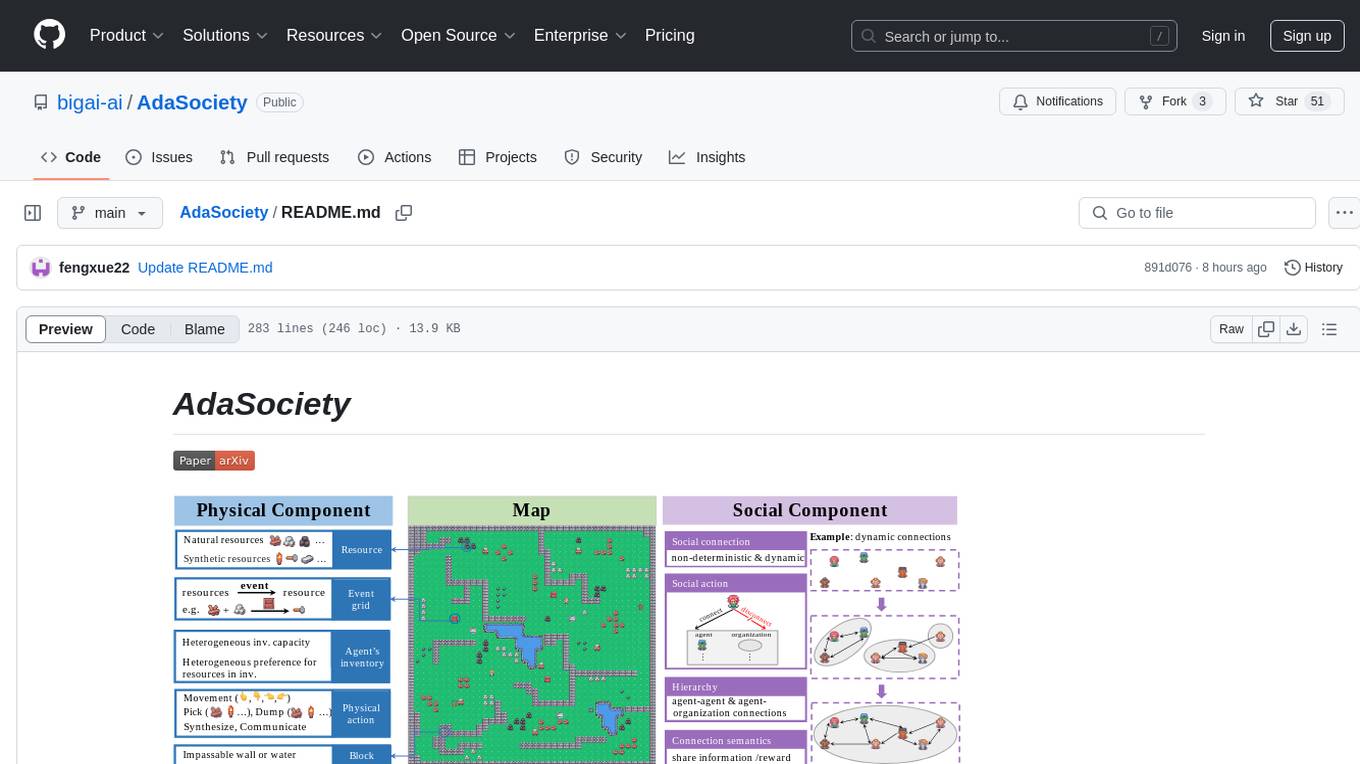
AdaSociety
AdaSociety is a multi-agent environment designed for simulating social structures and decision-making processes. It offers built-in resources, events, and player interactions. Users can customize the environment through JSON configuration or custom Python code. The environment supports training agents using RLlib and LLM frameworks. It provides a platform for studying multi-agent systems and social dynamics.
LightMem
LightMem is a lightweight and efficient memory management framework designed for Large Language Models and AI Agents. It provides a simple yet powerful memory storage, retrieval, and update mechanism to help you quickly build intelligent applications with long-term memory capabilities. The framework is minimalist in design, ensuring minimal resource consumption and fast response times. It offers a simple API for easy integration into applications with just a few lines of code. LightMem's modular architecture supports custom storage engines and retrieval strategies, making it flexible and extensible. It is compatible with various cloud APIs like OpenAI and DeepSeek, as well as local models such as Ollama and vLLM.
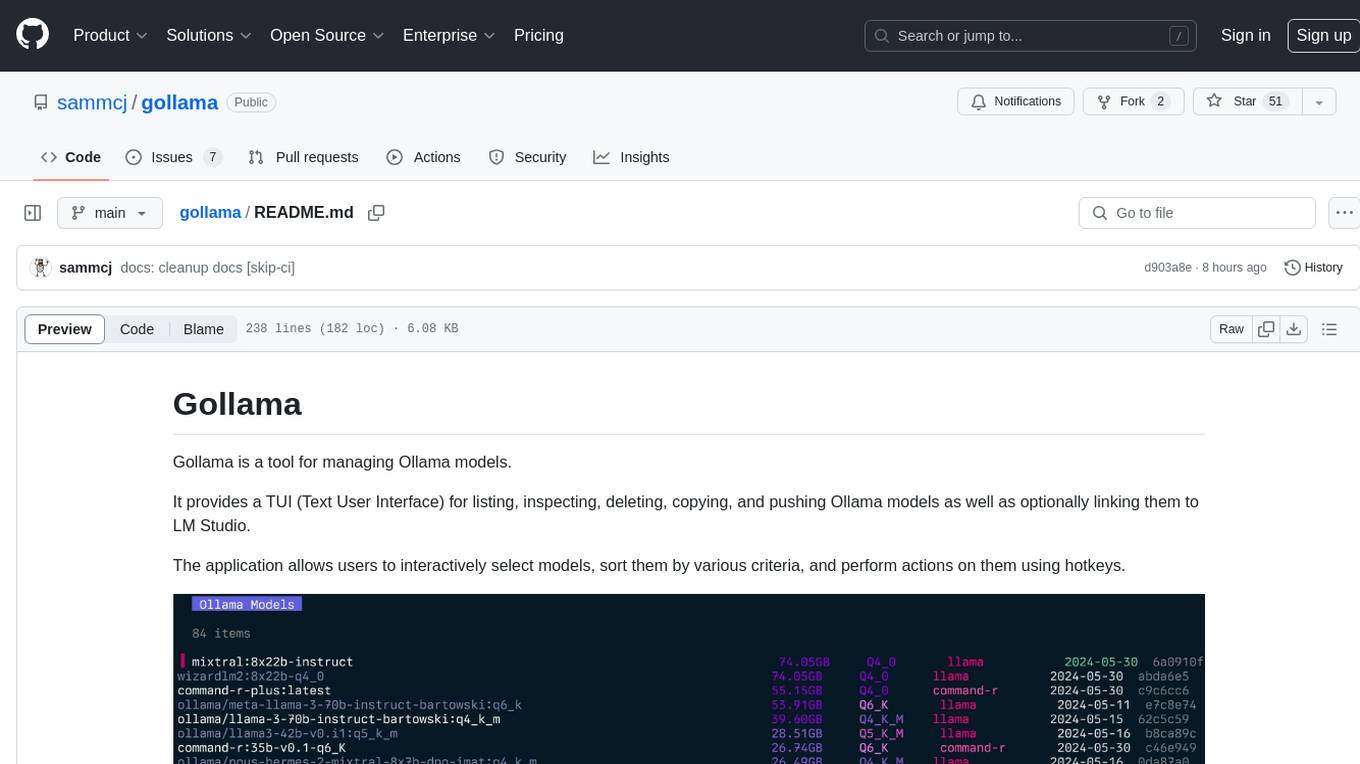
gollama
Gollama is a tool designed for managing Ollama models through a Text User Interface (TUI). Users can list, inspect, delete, copy, and push Ollama models, as well as link them to LM Studio. The application offers interactive model selection, sorting by various criteria, and actions using hotkeys. It provides features like sorting and filtering capabilities, displaying model metadata, model linking, copying, pushing, and more. Gollama aims to be user-friendly and useful for managing models, especially for cleaning up old models.

YuLan-Mini
YuLan-Mini is a lightweight language model with 2.4 billion parameters that achieves performance comparable to industry-leading models despite being pre-trained on only 1.08T tokens. It excels in mathematics and code domains. The repository provides pre-training resources, including data pipeline, optimization methods, and annealing approaches. Users can pre-train their own language models, perform learning rate annealing, fine-tune the model, research training dynamics, and synthesize data. The team behind YuLan-Mini is AI Box at Renmin University of China. The code is released under the MIT License with future updates on model weights usage policies. Users are advised on potential safety concerns and ethical use of the model.
fittencode.nvim
Fitten Code AI Programming Assistant for Neovim provides fast completion using AI, asynchronous I/O, and support for various actions like document code, edit code, explain code, find bugs, generate unit test, implement features, optimize code, refactor code, start chat, and more. It offers features like accepting suggestions with Tab, accepting line with Ctrl + Down, accepting word with Ctrl + Right, undoing accepted text, automatic scrolling, and multiple HTTP/REST backends. It can run as a coc.nvim source or nvim-cmp source.
roam-code
Roam is a tool that builds a semantic graph of your codebase and allows AI agents to query it with one shell command. It pre-indexes your codebase into a semantic graph stored in a local SQLite DB, providing architecture-level graph queries offline, cross-language, and compact. Roam understands functions, modules, tests coverage, and overall architecture structure. It is best suited for agent-assisted coding, large codebases, architecture governance, safe refactoring, and multi-repo projects. Roam is not suitable for real-time type checking, dynamic/runtime analysis, small scripts, or pure text search. It offers speed, dependency-awareness, LLM-optimized output, fully local operation, and CI readiness.

flute
FLUTE (Flexible Lookup Table Engine for LUT-quantized LLMs) is a tool designed for uniform quantization and lookup table quantization of weights in lower-precision intervals. It offers flexibility in mapping intervals to arbitrary values through a lookup table. FLUTE supports various quantization formats such as int4, int3, int2, fp4, fp3, fp2, nf4, nf3, nf2, and even custom tables. The tool also introduces new quantization algorithms like Learned Normal Float (NFL) for improved performance and calibration data learning. FLUTE provides benchmarks, model zoo, and integration with frameworks like vLLM and HuggingFace for easy deployment and usage.
PraisonAI
Praison AI is a low-code, centralised framework that simplifies the creation and orchestration of multi-agent systems for various LLM applications. It emphasizes ease of use, customization, and human-agent interaction. The tool leverages AutoGen and CrewAI frameworks to facilitate the development of AI-generated scripts and movie concepts. Users can easily create, run, test, and deploy agents for scriptwriting and movie concept development. Praison AI also provides options for full automatic mode and integration with OpenAI models for enhanced AI capabilities.
ReGraph
ReGraph is a decentralized AI compute marketplace that connects hardware providers with developers who need inference and training resources. It democratizes access to AI computing power by creating a global network of distributed compute nodes. It is cost-effective, decentralized, easy to integrate, supports multiple models, and offers pay-as-you-go pricing.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students
headroom
Headroom is a tool designed to optimize the context layer for Large Language Models (LLMs) applications by compressing redundant boilerplate outputs. It intercepts context from tool outputs, logs, search results, and intermediate agent steps, stabilizes dynamic content like timestamps and UUIDs, removes low-signal content, and preserves original data for retrieval only when needed by the LLM. It ensures provider caching works efficiently by aligning prompts for cache hits. The tool works as a transparent proxy with zero code changes, offering significant savings in token count and enabling reversible compression for various types of content like code, logs, JSON, and images. Headroom integrates seamlessly with frameworks like LangChain, Agno, and MCP, supporting features like memory, retrievers, agents, and more.
For similar tasks
models
This repository contains comprehensive pricing and configuration data for LLMs, providing accurate pricing for 2,000+ models across 40+ providers. It addresses the challenges of LLM pricing, such as naming inconsistencies, varied pricing units, hidden dimensions, and rapid pricing changes. The repository offers a free API without authentication requirements, enabling users to access model configurations and pricing information easily. It aims to create a community-maintained database to streamline cost attribution for enterprises utilizing LLMs.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.