
unified-cache-management
Persist and reuse KV Cache to speedup your LLM.
Stars: 249

Unified Cache Manager (UCM) is a tool designed to persist the LLM KVCache and replace redundant computations through various retrieval mechanisms. It supports prefix caching and offers training-free sparse attention retrieval methods, enhancing performance for long sequence inference tasks. UCM also provides a PD disaggregation solution based on a storage-compute separation architecture, enabling easier management of heterogeneous computing resources. When integrated with vLLM, UCM significantly reduces inference latency in scenarios like multi-turn dialogue and long-context reasoning tasks.
README:

| Documentation | Website | RoadMap | 中文 |
The core principle of Unified Cache Manager (UCM) is to persist the LLM KVCache and replace redundant computations through multiple retrieval mechanisms. UCM not only supports prefix caching but also offers a variety of training-free sparse attention retrieval methods, delivering higher performance when handling extremely long sequence inference tasks. Additionally, UCM provides a PD disaggregation solution based on a storage-compute separation architecture, which enables more straightforward and flexible management of heterogeneous computing resources. When integrated with vLLM, UCM achieves a 3-10x reduction in inference latency across various scenarios, including multi-turn dialogue and long-context reasoning tasks.
With the increase of model size, the KV cache became larger and sparser, especially for long sequence requests. To reduce the GPU memory used, offload full KV to external storage and only keep partial or compressed KV in GPU memory became the popular direction. This can also reduce the GPU calculation, increase the sequence length and batch size of decoding.
Sparse KV cache have many different choices. Recently paper point out that there is no common way can fit all scenarios and all models. So better to build a common framework then different sparse algorithms can be plugin to it like KV connector for PC.
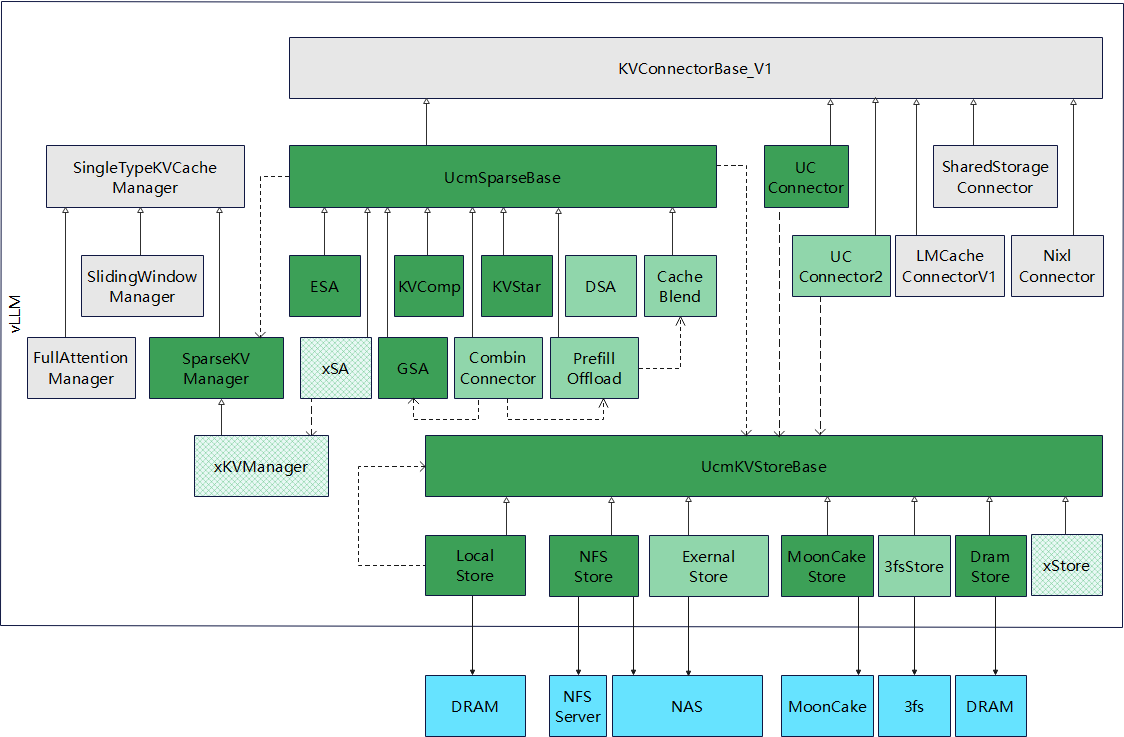
All gray boxes in the diagram represent existing classes in vLLM version 0.9.2, while the green boxes indicate newly added components by UCM. The light green boxes demonstrate potential future subclass extensions based on this framework.
UcmSparseBase is the base class of different sparse algorithms. Just like KV connector design, it will hook few places of scheduler and layer.py to do additional load, dump and calculate sparse KV blocks.
SparseKVManager allows users to define custom KV block allocations for different algorithms. To keep all implementations unified under the SparseKVBase framework, the system calls the SparseKVBase base class, while the actual implementation occurs in subclasses of sparse algorithms.
KVStoreBase helps decouple sparse algorithms from external storage. It defines methods for communicating with external storage, enabling any sparse algorithm to work seamlessly with any external storage system. The core concept here involves identifying blocks through IDs and offsets. This approach is not only suitable for sparse scenarios but also naturally accommodates prefix caching. The KVStoreConnector links it with the current KVConnectorBase_V1 to provide PC (Prefix Caching) functionality. For example, NFSStore serves as a reference implementation that provides the capability to store KVCache in either a local filesystem for single-machine scenarios or through NFS mount points in multi-server environments.
- Prefix Cache
- Cache Blend
- Model Window Extrapolation
- Prefill Offload
- Sparse Attention
- Sparse Attention Offload
- Heterogeneous PD Disaggregation
please refer to Quick Start for vLLM and Quick Start for vLLM-Ascend.
| Branch | Status | vLLM version |
|---|---|---|
| main | Maintained | v0.9.2 |
| develop | Maintained | v0.9.2 |
- For technical questions and feature requests, please use GitHub Issues.
- WeChat technical discussion group: Scan the QR code below.

UCM is licensed under the MIT with additional conditions. Please read the LICENSE file for details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for unified-cache-management
Similar Open Source Tools
unified-cache-management
Unified Cache Manager (UCM) is a tool designed to persist the LLM KVCache and replace redundant computations through various retrieval mechanisms. It supports prefix caching and offers training-free sparse attention retrieval methods, enhancing performance for long sequence inference tasks. UCM also provides a PD disaggregation solution based on a storage-compute separation architecture, enabling easier management of heterogeneous computing resources. When integrated with vLLM, UCM significantly reduces inference latency in scenarios like multi-turn dialogue and long-context reasoning tasks.

MemoryBear
MemoryBear is a next-generation AI memory system developed by RedBear AI, focusing on overcoming limitations in knowledge storage and multi-agent collaboration. It empowers AI with human-like memory capabilities, enabling deep knowledge understanding and cognitive collaboration. The system addresses challenges such as knowledge forgetting, memory gaps in multi-agent collaboration, and semantic ambiguity during reasoning. MemoryBear's core features include memory extraction engine, graph storage, hybrid search, memory forgetting engine, self-reflection engine, and FastAPI services. It offers a standardized service architecture for efficient integration and invocation across applications.

doris
Doris is a lightweight and user-friendly data visualization tool designed for quick and easy exploration of datasets. It provides a simple interface for users to upload their data and generate interactive visualizations without the need for coding. With Doris, users can easily create charts, graphs, and dashboards to analyze and present their data in a visually appealing way. The tool supports various data formats and offers customization options to tailor visualizations to specific needs. Whether you are a data analyst, researcher, or student, Doris simplifies the process of data exploration and presentation.
Nanoflow
NanoFlow is a throughput-oriented high-performance serving framework for Large Language Models (LLMs) that consistently delivers superior throughput compared to other frameworks by utilizing key techniques such as intra-device parallelism, asynchronous CPU scheduling, and SSD offloading. The framework proposes nano-batching to schedule compute-, memory-, and network-bound operations for simultaneous execution, leading to increased resource utilization. NanoFlow also adopts an asynchronous control flow to optimize CPU overhead and eagerly offloads KV-Cache to SSDs for multi-round conversations. The open-source codebase integrates state-of-the-art kernel libraries and provides necessary scripts for environment setup and experiment reproduction.

ReaLHF
ReaLHF is a distributed system designed for efficient RLHF training with Large Language Models (LLMs). It introduces a novel approach called parameter reallocation to dynamically redistribute LLM parameters across the cluster, optimizing allocations and parallelism for each computation workload. ReaL minimizes redundant communication while maximizing GPU utilization, achieving significantly higher Proximal Policy Optimization (PPO) training throughput compared to other systems. It supports large-scale training with various parallelism strategies and enables memory-efficient training with parameter and optimizer offloading. The system seamlessly integrates with HuggingFace checkpoints and inference frameworks, allowing for easy launching of local or distributed experiments. ReaLHF offers flexibility through versatile configuration customization and supports various RLHF algorithms, including DPO, PPO, RAFT, and more, while allowing the addition of custom algorithms for high efficiency.
algebraic-nnhw
This repository contains the source code for a GEMM & deep learning hardware accelerator system used to validate proposed systolic array hardware architectures implementing efficient matrix multiplication algorithms to increase performance-per-area limits of GEMM & AI accelerators. Achieved results include up to 3× faster CNN inference, >2× higher mults/multiplier/clock cycle, and low area with high clock frequency. The system is specialized for inference of non-sparse DNN models with fixed-point/quantized inputs, fully accelerating all DNN layers in hardware, and highly optimizing GEMM acceleration.
llumnix
Llumnix is a cross-instance request scheduling layer built on top of LLM inference engines such as vLLM, providing optimized multi-instance serving performance with low latency, reduced time-to-first-token (TTFT) and queuing delays, reduced time-between-tokens (TBT) and preemption stalls, and high throughput. It achieves this through dynamic, fine-grained, KV-cache-aware scheduling, continuous rescheduling across instances, KV cache migration mechanism, and seamless integration with existing multi-instance deployment platforms. Llumnix is easy to use, fault-tolerant, elastic, and extensible to more inference engines and scheduling policies.


cube
Cube is a semantic layer for building data applications, helping data engineers and application developers access data from modern data stores, organize it into consistent definitions, and deliver it to every application. It works with SQL-enabled data sources, providing sub-second latency and high concurrency for API requests. Cube addresses SQL code organization, performance, and access control issues in data applications, enabling efficient data modeling, access control, and performance optimizations for various tools like embedded analytics, dashboarding, reporting, and data notebooks.

CSGHub
CSGHub is an open source, trustworthy large model asset management platform that can assist users in governing the assets involved in the lifecycle of LLM and LLM applications (datasets, model files, codes, etc). With CSGHub, users can perform operations on LLM assets, including uploading, downloading, storing, verifying, and distributing, through Web interface, Git command line, or natural language Chatbot. Meanwhile, the platform provides microservice submodules and standardized OpenAPIs, which could be easily integrated with users' own systems. CSGHub is committed to bringing users an asset management platform that is natively designed for large models and can be deployed On-Premise for fully offline operation. CSGHub offers functionalities similar to a privatized Huggingface(on-premise Huggingface), managing LLM assets in a manner akin to how OpenStack Glance manages virtual machine images, Harbor manages container images, and Sonatype Nexus manages artifacts.

llm-on-ray
LLM-on-Ray is a comprehensive solution for building, customizing, and deploying Large Language Models (LLMs). It simplifies complex processes into manageable steps by leveraging the power of Ray for distributed computing. The tool supports pretraining, finetuning, and serving LLMs across various hardware setups, incorporating industry and Intel optimizations for performance. It offers modular workflows with intuitive configurations, robust fault tolerance, and scalability. Additionally, it provides an Interactive Web UI for enhanced usability, including a chatbot application for testing and refining models.

postgresml
PostgresML is a powerful Postgres extension that seamlessly combines data storage and machine learning inference within your database. It enables running machine learning and AI operations directly within PostgreSQL, leveraging GPU acceleration for faster computations, integrating state-of-the-art large language models, providing built-in functions for text processing, enabling efficient similarity search, offering diverse ML algorithms, ensuring high performance, scalability, and security, supporting a wide range of NLP tasks, and seamlessly integrating with existing PostgreSQL tools and client libraries.

supersonic
SuperSonic is a next-generation BI platform that integrates Chat BI (powered by LLM) and Headless BI (powered by semantic layer) paradigms. This integration ensures that Chat BI has access to the same curated and governed semantic data models as traditional BI. Furthermore, the implementation of both paradigms benefits from the integration: * Chat BI's Text2SQL gets augmented with context-retrieval from semantic models. * Headless BI's query interface gets extended with natural language API. SuperSonic provides a Chat BI interface that empowers users to query data using natural language and visualize the results with suitable charts. To enable such experience, the only thing necessary is to build logical semantic models (definition of metric/dimension/tag, along with their meaning and relationships) through a Headless BI interface. Meanwhile, SuperSonic is designed to be extensible and composable, allowing custom implementations to be added and configured with Java SPI. The integration of Chat BI and Headless BI has the potential to enhance the Text2SQL generation in two dimensions: 1. Incorporate data semantics (such as business terms, column values, etc.) into the prompt, enabling LLM to better understand the semantics and reduce hallucination. 2. Offload the generation of advanced SQL syntax (such as join, formula, etc.) from LLM to the semantic layer to reduce complexity. With these ideas in mind, we develop SuperSonic as a practical reference implementation and use it to power our real-world products. Additionally, to facilitate further development we decide to open source SuperSonic as an extensible framework.
glake
GLake is an acceleration library and utilities designed to optimize GPU memory management and IO transmission for AI large model training and inference. It addresses challenges such as GPU memory bottleneck and IO transmission bottleneck by providing efficient memory pooling, sharing, and tiering, as well as multi-path acceleration for CPU-GPU transmission. GLake is easy to use, open for extension, and focuses on improving training throughput, saving inference memory, and accelerating IO transmission. It offers features like memory fragmentation reduction, memory deduplication, and built-in security mechanisms for troubleshooting GPU memory issues.
knavigator
Knavigator is a project designed to analyze, optimize, and compare scheduling systems, with a focus on AI/ML workloads. It addresses various needs, including testing, troubleshooting, benchmarking, chaos engineering, performance analysis, and optimization. Knavigator interfaces with Kubernetes clusters to manage tasks such as manipulating with Kubernetes objects, evaluating PromQL queries, as well as executing specific operations. It can operate both outside and inside a Kubernetes cluster, leveraging the Kubernetes API for task management. To facilitate large-scale experiments without the overhead of running actual user workloads, Knavigator utilizes KWOK for creating virtual nodes in extensive clusters.
awesome-openvino
Awesome OpenVINO is a curated list of AI projects based on the OpenVINO toolkit, offering a rich assortment of projects, libraries, and tutorials covering various topics like model optimization, deployment, and real-world applications across industries. It serves as a valuable resource continuously updated to maximize the potential of OpenVINO in projects, featuring projects like Stable Diffusion web UI, Visioncom, FastSD CPU, OpenVINO AI Plugins for GIMP, and more.
For similar tasks
unified-cache-management
Unified Cache Manager (UCM) is a tool designed to persist the LLM KVCache and replace redundant computations through various retrieval mechanisms. It supports prefix caching and offers training-free sparse attention retrieval methods, enhancing performance for long sequence inference tasks. UCM also provides a PD disaggregation solution based on a storage-compute separation architecture, enabling easier management of heterogeneous computing resources. When integrated with vLLM, UCM significantly reduces inference latency in scenarios like multi-turn dialogue and long-context reasoning tasks.

Awesome-Resource-Efficient-LLM-Papers
A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.
awesome-ai-efficiency
Awesome AI Efficiency is a curated list of resources dedicated to enhancing efficiency in AI systems. The repository covers various topics essential for optimizing AI models and processes, aiming to make AI faster, cheaper, smaller, and greener. It includes topics like quantization, pruning, caching, distillation, factorization, compilation, parameter-efficient fine-tuning, speculative decoding, hardware optimization, training techniques, inference optimization, sustainability strategies, and scalability approaches.
InferenceMAX
InferenceMAX™ is an open-source benchmarking tool designed to track real-time performance improvements in popular open-source inference frameworks and models. It runs a suite of benchmarks every night to capture progress in near real-time, providing a live indicator of inference performance. The tool addresses the challenge of rapidly evolving software ecosystems by benchmarking the latest software packages, ensuring that benchmarks do not go stale. InferenceMAX™ is supported by industry leaders and contributors, providing transparent and reproducible benchmarks that help the ML community make informed decisions about hardware and software performance.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.