
InferenceMAX
Open Source Continuous Inference Benchmarking - GB200 NVL72 vs MI355X vs B200 vs GB300 NVL72 vs H100 & soon™ TPUv6e/v7/Trainium2/3- DeepSeek 670B MoE, GPTOSS
Stars: 447
InferenceMAX™ is an open-source benchmarking tool designed to track real-time performance improvements in popular open-source inference frameworks and models. It runs a suite of benchmarks every night to capture progress in near real-time, providing a live indicator of inference performance. The tool addresses the challenge of rapidly evolving software ecosystems by benchmarking the latest software packages, ensuring that benchmarks do not go stale. InferenceMAX™ is supported by industry leaders and contributors, providing transparent and reproducible benchmarks that help the ML community make informed decisions about hardware and software performance.
README:
InferenceMAX™ runs our suite of benchmarks every night, continually re-benchmarking the world’s most popular open-source inference frameworks and models to track real performance in real time. As these software stacks improve, InferenceMAX™ captures that progress in near real-time, providing a live indicator of inference performance progress. A live dashboard is available for free publicly at https://inferencemax.ai/.
[!IMPORTANT] Only InferenceMAX/InferenceMAX repo contains the Official InferenceMAX™ result, all other forks & repos are Unofficial. The benchmark setup & quality of machines/clouds in unofficial repos may be differ leading to subpar benchmarking. Unofficial must be explicitly labelled as Unofficial. Forks may not remove this disclaimer
Full Article Write Up for InferenceMAXv1
InferenceMAX™, an open-source, under Apache2 license, automated benchmark designed to move at the same rapid speed as the software ecosystem itself, is built to address this challenge.
LLM Inference performance is driven by two pillars, hardware and software. While hardware innovation drives step jumps in performance every year through the release of new GPUs/XPUs and new systems, software evolves every single day, delivering continuous performance gains on top of these step jumps. Speed is the Moat 🚀
AI software like SGLang, vLLM, TensorRT-LLM, CUDA, ROCm and achieve this continuous improvement in performance through kernel-level optimizations, distributed inference strategies, and scheduling innovations that increase the pareto frontier of performance in incremental releases that can be just days apart.
This pace of software advancement creates a challenge: benchmarks conducted at a fixed point in time quickly go stale and do not represent the performance that can be achieved with the latest software packages.
Thank you to Lisa Su and Anush Elangovan for providing the MI355X and CDNA3 GPUs for this free and open-source project. We want to recognize the many AMD contributors for their responsiveness and for debugging, optimizing, and validating performance across AMD GPUs. We’re also grateful to Jensen Huang and Ian Buck for supporting this open source with access to a GB200 NVL72 rack (through OCI) and B200 GPUs. Thank you to the many NVIDIA contributors from the NVIDIA inference team, NVIDIA Dynamo team.
We also want to recognize the SGLang, vLLM, and TensorRT-LLM maintainers for building a world-class software stack and open sourcing it to the entire world. Finally, we’re grateful to Crusoe, CoreWeave, Nebius, TensorWave, Oracle and TogetherAI for supporting open-source innovation through compute resources, enabling this.
"As we build systems at unprecedented scale, it's critical for the ML community to have open, transparent benchmarks that reflect how inference really performs across hardware and software. InferenceMAX™'s head-to-head benchmarks cut through the noise and provide a living picture of token throughput, performance per dollar, and tokens per Megawatt. This kind of open source effort strengthens the entire ecosystem and helps everyone, from researchers to operators of frontier datacenters, make smarter decisions." - Peter Hoeschele, VP of Infrastructure and Industrial Compute, OpenAI Stargate
"The gap between theoretical peak and real-world inference throughput is often determined by systems software: inference engine, distributed strategies, and low-level kernels. InferenceMAX™ is valuable because it benchmarks the latest software showing how optimizations actually play out across various hardware. Open, reproducible results like these help the whole community move faster.” - Tri Dao, Chief Scientist of Together AI & Inventor of Flash Attention
“The industry needs many public, reproducible benchmarks of inference performance. We’re excited to collaborate with InferenceMAX™ from the vLLM team. More diverse workloads and scenarios that everyone can trust and reference will help the ecosystem move forward. Fair, transparent measurements drive progress across every layer of the stack, from model architectures to inference engines to hardware.” – Simon Mo, vLLM Project Co-Lead
We are looking for an engineer to join our special projects team. This is a unique opportunity to work on high-visibility special projects such as InferenceMAX™ with support from many industry leaders and CEOs. If you’re passionate about performance engineering, system reliability, and want to work at the intersection of hardware and software, this is a rare chance to make industry wide impact. What you’ll work on:
- Building and running large-scale benchmarks across multiple vendors (AMD, NVIDIA, TPU, Trainium, etc.)
- Designing reproducible CI/CD pipelines to automate benchmarking workflows
- Ensuring reliability and scalability of systems used by industry partners
What we’re looking for:
- Strong skills in Python
- Background in Site Reliability Engineering (SRE) or systems-level problem solving
- Experience with CI/CD pipelines and modern DevOps practices
- Curiosity about GPUs, TPUs, Trainium, multi-cloud, and performance benchmarking Link to apply: https://app.dover.com/apply/SemiAnalysis/2a9c8da5-6d59-4ac8-8302-3877345dbce1
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for InferenceMAX
Similar Open Source Tools
InferenceMAX
InferenceMAX™ is an open-source benchmarking tool designed to track real-time performance improvements in popular open-source inference frameworks and models. It runs a suite of benchmarks every night to capture progress in near real-time, providing a live indicator of inference performance. The tool addresses the challenge of rapidly evolving software ecosystems by benchmarking the latest software packages, ensuring that benchmarks do not go stale. InferenceMAX™ is supported by industry leaders and contributors, providing transparent and reproducible benchmarks that help the ML community make informed decisions about hardware and software performance.

metaflow
Metaflow is a user-friendly library designed to assist scientists and engineers in developing and managing real-world data science projects. Initially created at Netflix, Metaflow aimed to enhance the productivity of data scientists working on diverse projects ranging from traditional statistics to cutting-edge deep learning. For further information, refer to Metaflow's website and documentation.
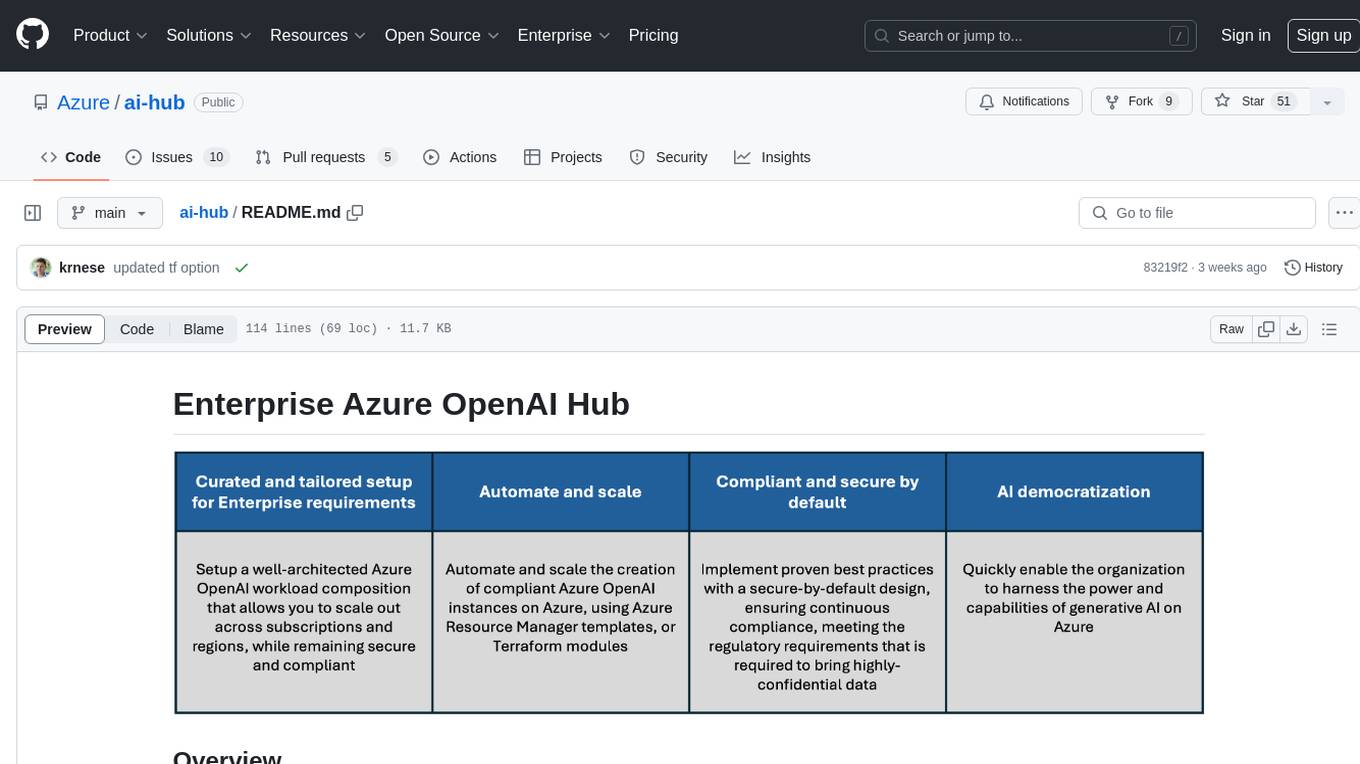
ai-hub
The Enterprise Azure OpenAI Hub is a comprehensive repository designed to guide users through the world of Generative AI on the Azure platform. It offers a structured learning experience to accelerate the transition from concept to production in an Enterprise context. The hub empowers users to explore various use cases with Azure services, ensuring security and compliance. It provides real-world examples and playbooks for practical insights into solving complex problems and developing cutting-edge AI solutions. The repository also serves as a library of proven patterns, aligning with industry standards and promoting best practices for secure and compliant AI development.
foundationallm
FoundationaLLM is a platform designed for deploying, scaling, securing, and governing generative AI in enterprises. It allows users to create AI agents grounded in enterprise data, integrate REST APIs, experiment with various large language models, centrally manage AI agents and their assets, deploy scalable vectorization data pipelines, enable non-developer users to create their own AI agents, control access with role-based access controls, and harness capabilities from Azure AI and Azure OpenAI. The platform simplifies integration with enterprise data sources, provides fine-grain security controls, scalability, extensibility, and addresses the challenges of delivering enterprise copilots or AI agents.
foundationallm
FoundationaLLM is a platform designed for deploying, scaling, securing, and governing generative AI in enterprises. It allows users to create AI agents grounded in enterprise data, integrate REST APIs, experiment with large language models, centrally manage AI agents and assets, deploy scalable vectorization data pipelines, enable non-developer users to create their own AI agents, control access with role-based access controls, and harness capabilities from Azure AI and Azure OpenAI. The platform simplifies integration with enterprise data sources, provides fine-grain security controls, load balances across multiple endpoints, and is extensible to new data sources and orchestrators. FoundationaLLM addresses the need for customized copilots or AI agents that are secure, licensed, flexible, and suitable for enterprise-scale production.
Build-Modern-AI-Apps
This repository serves as a hub for Microsoft Official Build & Modernize AI Applications reference solutions and content. It provides access to projects demonstrating how to build Generative AI applications using Azure services like Azure OpenAI, Azure Container Apps, Azure Kubernetes, and Azure Cosmos DB. The solutions include Vector Search & AI Assistant, Real-Time Payment and Transaction Processing, and Medical Claims Processing. Additionally, there are workshops like the Intelligent App Workshop for Microsoft Copilot Stack, focusing on infusing intelligence into traditional software systems using foundation models and design thinking.
intelligent-app-workshop
Welcome to the envisioning workshop designed to help you build your own custom Copilot using Microsoft's Copilot stack. This workshop aims to rethink user experience, architecture, and app development by leveraging reasoning engines and semantic memory systems. You will utilize Azure AI Foundry, Prompt Flow, AI Search, and Semantic Kernel. Work with Miyagi codebase, explore advanced capabilities like AutoGen and GraphRag. This workshop guides you through the entire lifecycle of app development, including identifying user needs, developing a production-grade app, and deploying on Azure with advanced capabilities. By the end, you will have a deeper understanding of leveraging Microsoft's tools to create intelligent applications.
farmvibes-ai
FarmVibes.AI is a repository focused on developing multi-modal geospatial machine learning models for agriculture and sustainability. It enables users to fuse various geospatial and spatiotemporal datasets, such as satellite imagery, drone imagery, and weather data, to generate robust insights for agriculture-related problems. The repository provides fusion workflows, data preparation tools, model training notebooks, and an inference engine to facilitate the creation of geospatial models tailored for agriculture and farming. Users can interact with the tools via a local cluster, REST API, or a Python client, and the repository includes documentation and notebook examples to guide users in utilizing FarmVibes.AI for tasks like harvest date detection, climate impact estimation, micro climate prediction, and crop identification.
oci-data-science-ai-samples
The Oracle Cloud Infrastructure Data Science and AI services Examples repository provides demos, tutorials, and code examples showcasing various features of the OCI Data Science service and AI services. It offers tools for data scientists to develop and deploy machine learning models efficiently, with features like Accelerated Data Science SDK, distributed training, batch processing, and machine learning pipelines. Whether you're a beginner or an experienced practitioner, OCI Data Science Services provide the resources needed to build, train, and deploy models easily.

learn-generative-ai
Learn Cloud Applied Generative AI Engineering (GenEng) is a course focusing on the application of generative AI technologies in various industries. The course covers topics such as the economic impact of generative AI, the role of developers in adopting and integrating generative AI technologies, and the future trends in generative AI. Students will learn about tools like OpenAI API, LangChain, and Pinecone, and how to build and deploy Large Language Models (LLMs) for different applications. The course also explores the convergence of generative AI with Web 3.0 and its potential implications for decentralized intelligence.

text-to-sql-bedrock-workshop
This repository focuses on utilizing generative AI to bridge the gap between natural language questions and SQL queries, aiming to improve data consumption in enterprise data warehouses. It addresses challenges in SQL query generation, such as foreign key relationships and table joins, and highlights the importance of accuracy metrics like Execution Accuracy (EX) and Exact Set Match Accuracy (EM). The workshop content covers advanced prompt engineering, Retrieval Augmented Generation (RAG), fine-tuning models, and security measures against prompt and SQL injections.
FedML
FedML is a unified and scalable machine learning library for running training and deployment anywhere at any scale. It is highly integrated with FEDML Nexus AI, a next-gen cloud service for LLMs & Generative AI. FEDML Nexus AI provides holistic support of three interconnected AI infrastructure layers: user-friendly MLOps, a well-managed scheduler, and high-performance ML libraries for running any AI jobs across GPU Clouds.
AI-CryptoTrader
AI-CryptoTrader is a state-of-the-art cryptocurrency trading bot that uses ensemble methods to combine the predictions of multiple algorithms. Written in Python, it connects to the Binance trading platform and integrates with Azure for efficiency and scalability. The bot uses technical indicators and machine learning algorithms to generate predictions for buy and sell orders, adjusting to market conditions. While robust, users should be cautious due to cryptocurrency market volatility.

llm-d
LLM-D is a machine learning model for sentiment analysis. It is designed to classify text data into positive, negative, or neutral sentiment categories. The model is trained on a large dataset of labeled text samples and uses natural language processing techniques to analyze and predict sentiment in new text inputs. LLM-D is a powerful tool for businesses and researchers looking to understand customer feedback, social media sentiment, and other text data sources. It can be easily integrated into existing applications or used as a standalone tool for sentiment analysis tasks.
comflowy
Comflowy is a community dedicated to providing comprehensive tutorials, fostering discussions, and building a database of workflows and models for ComfyUI and Stable Diffusion. Our mission is to lower the entry barrier for ComfyUI users, promote its mainstream adoption, and contribute to the growth of the AI generative graphics community.
For similar tasks
InferenceMAX
InferenceMAX™ is an open-source benchmarking tool designed to track real-time performance improvements in popular open-source inference frameworks and models. It runs a suite of benchmarks every night to capture progress in near real-time, providing a live indicator of inference performance. The tool addresses the challenge of rapidly evolving software ecosystems by benchmarking the latest software packages, ensuring that benchmarks do not go stale. InferenceMAX™ is supported by industry leaders and contributors, providing transparent and reproducible benchmarks that help the ML community make informed decisions about hardware and software performance.

Awesome-Resource-Efficient-LLM-Papers
A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.
awesome-ai-efficiency
Awesome AI Efficiency is a curated list of resources dedicated to enhancing efficiency in AI systems. The repository covers various topics essential for optimizing AI models and processes, aiming to make AI faster, cheaper, smaller, and greener. It includes topics like quantization, pruning, caching, distillation, factorization, compilation, parameter-efficient fine-tuning, speculative decoding, hardware optimization, training techniques, inference optimization, sustainability strategies, and scalability approaches.

unified-cache-management
Unified Cache Manager (UCM) is a tool designed to persist the LLM KVCache and replace redundant computations through various retrieval mechanisms. It supports prefix caching and offers training-free sparse attention retrieval methods, enhancing performance for long sequence inference tasks. UCM also provides a PD disaggregation solution based on a storage-compute separation architecture, enabling easier management of heterogeneous computing resources. When integrated with vLLM, UCM significantly reduces inference latency in scenarios like multi-turn dialogue and long-context reasoning tasks.

beehave
Beehave is a powerful addon for Godot Engine that enables users to create robust AI systems using behavior trees. It simplifies the design of complex NPC behaviors, challenging boss battles, and other advanced setups. Beehave allows for the creation of highly adaptive AI that responds to changes in the game world and overcomes unexpected obstacles, catering to both beginners and experienced developers. The tool is currently in development for version 3.0.
portkey-python-sdk
The Portkey Python SDK is a control panel for AI apps that allows seamless integration of Portkey's advanced features with OpenAI methods. It provides features such as AI gateway for unified API signature, interoperability, automated fallbacks & retries, load balancing, semantic caching, virtual keys, request timeouts, observability with logging, requests tracing, custom metadata, feedback collection, and analytics. Users can make requests to OpenAI using Portkey SDK and also use async functionality. The SDK is compatible with OpenAI SDK methods and offers Portkey-specific methods like feedback and prompts. It supports various providers and encourages contributions through Github issues or direct contact via email or Discord.
NotHotDog
NotHotDog is an open-source platform for testing, evaluating, and simulating AI agents. It offers a robust framework for generating test cases, running conversational scenarios, and analyzing agent performance.

agno
Agno is a lightweight library for building multi-modal Agents. It is designed with core principles of simplicity, uncompromising performance, and agnosticism, allowing users to create blazing fast agents with minimal memory footprint. Agno supports any model, any provider, and any modality, making it a versatile container for AGI. Users can build agents with lightning-fast agent creation, model agnostic capabilities, native support for text, image, audio, and video inputs and outputs, memory management, knowledge stores, structured outputs, and real-time monitoring. The library enables users to create autonomous programs that use language models to solve problems, improve responses, and achieve tasks with varying levels of agency and autonomy.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.