Best AI tools for< transcribe voice recordings >
20 - AI tool Sites
Vocol AI
Vocol AI is an all-in-one voice collaboration platform that empowers individuals and enterprises to collaborate efficiently by turning voice into text with high accuracy and sharing the actionable insights. It offers multilingual transcription, auto-generated summaries, note-taking, and insights based on facts. Vocol AI integrates with existing tools and workflows, making it easy to use and implement. The platform is designed to save time, improve productivity, and enhance collaboration within teams.
SpeechText.AI
SpeechText.AI is a powerful artificial intelligence software for speech to text conversion and audio transcription. It offers accurate transcriptions of audio files using domain-specific speech recognition technology. The platform supports various file formats, transcribes in multiple languages, and provides domain-optimized models for increased recognition accuracy. Users can edit and export transcriptions, benefit from automatic punctuation, and utilize a speaker identification service. With a word error rate of 3.8%, SpeechText.AI's speech recognition technology rivals human transcriptionists, making it a valuable tool for various industries.
Transcripo
Transcripo is a free online transcription AI tool that converts audio and video files into text or subtitles. It offers a user-friendly interface for users to easily transcribe their content in over 100 languages. With features like drag & drop file upload, quick transcription turnaround, and AI summaries, Transcripo simplifies the transcription process for various purposes such as creating subtitles for videos, summarizing interviews, and more. The tool also provides affordable pricing plans with a free trial option, making it accessible to individuals and businesses alike.
Speech Intellect
Speech Intellect is an AI-powered speech-to-text and text-to-speech solution that provides real-time transcription and voice synthesis with emotional analysis. It utilizes a proprietary "Sense Theory" algorithm to capture the meaning and tone of speech, enabling businesses to automate tasks, improve customer interactions, and create personalized experiences.
SpeechFlow
SpeechFlow is a powerful speech-to-text API that transcribes audio and video files into text with high accuracy. It supports 14 languages and offers features such as punctuation, easy deployment, scalability, and fast processing. SpeechFlow is ideal for businesses and individuals who need accurate and timely transcription services.
TakeNote
TakeNote is a cutting-edge speech-to-text AI that transforms audio and video into documents, boosting productivity and enhancing meeting experiences. Its advanced AI models provide exceptional accuracy, approaching human-level robustness and accuracy in English speech recognition. TakeNote AI empowers teams to transcribe meetings into accurate transcripts, generate precise summaries, analyze sentiment, and identify speakers, all while ensuring high levels of security and data protection.
Voicepen
Voicepen is an AI-powered tool that converts audio recordings into high-quality blog posts. It uses advanced speech recognition and natural language processing technologies to accurately transcribe and format your audio content into well-written, SEO-optimized blog posts. With Voicepen, you can easily create engaging and informative blog content without spending hours writing and editing.
Transcript.LOL
Transcript.LOL is a powerful tool that helps you get more out of your audio, video, or meeting recordings. With Transcript.LOL, you can easily create transcripts, summaries, and topics from your recordings, and even ask questions about your content. Transcript.LOL supports over 1500 platforms, so you can use it to transcribe recordings from almost any source. Transcript.LOL is perfect for students, researchers, journalists, podcasters, and anyone else who needs to get more done with less effort.
TranscribeMe
TranscribeMe is an application that allows users to convert voice notes from WhatsApp and Telegram into text. It is a free-to-use bot that does not require any downloads or additional information. TranscribeMe also offers a paid subscription service called TranscribeGo, which allows users to transcribe an unlimited number of audios and perform precise audio analysis. TranscribeMe is a valuable tool for anyone who wants to save time and effort by converting voice notes into text.
SpeakNotes
SpeakNotes is a revolutionary voice note summarizer that uses advanced AI technology to condense lengthy audio recordings into concise, easy-to-read summaries. With SpeakNotes, you can save time and effort by quickly capturing the key points of your voice notes, making it an invaluable tool for students, professionals, and anyone who relies on audio recordings for communication and information gathering.
Audionotes
Audionotes is an AI-powered note-taking app that uses speech-to-text technology to transcribe and summarize audio recordings. It also offers a variety of features to help users organize and manage their notes, including the ability to create to-do lists, set reminders, and share notes with others. Audionotes is available as a web app, a mobile app, and a Chrome extension.
Mediscribe Pro
Mediscribe Pro is an AI-powered medical scribe and documentation tool designed for healthcare professionals. It utilizes advanced medical language models and artificial intelligence to generate medical dictations, transcriptions, and chart notes. Mediscribe Pro is HIPAA and PIPEDA compliant, ensuring the security and privacy of user data. The tool offers a range of features to streamline medical documentation, including a library of 100+ medical templates, voice-activated note-taking, and seamless integration with existing EMR systems. Mediscribe Pro is designed to reduce administrative burden, improve efficiency, and enhance patient care by allowing clinicians to spend more time with patients and focus on providing quality care.
Voice Pen
Voice Pen is a Speech to Text AI application available on the App Store for Apple devices. It allows users to record and transcribe speech into text, which can then be used to create notes, summaries, emails, messages, and blog posts. The app supports more than 50 languages and offers AI options for rewriting and transforming text. Voice Pen enhances productivity by providing features like background audio recording, language autodetection, and the ability to create various types of content. It also prioritizes user privacy by only collecting app usage analytics and not storing any audio or text data on its servers.
Podcastle
Podcastle is an all-in-one podcasting software that empowers creators of all backgrounds and experience levels with an intuitive, AI-powered platform. It offers a wide range of features, including a recording studio, audio editor, video editor, AI-generated voices, and hosting hub, making it easy to create, edit, and publish high-quality podcasts and videos. Podcastle is designed to be user-friendly and accessible, with no prior experience or technical expertise required.
MacWhisper
MacWhisper is a native macOS application that utilizes OpenAI's Whisper technology for transcribing audio files into text. It offers a user-friendly interface for recording, transcribing, and editing audio, making it suitable for various use cases such as transcribing meetings, lectures, interviews, and podcasts. The application is designed to protect user privacy by performing all transcriptions locally on the device, ensuring that no data leaves the user's machine.

Talkatoo
Talkatoo is a dictation software that uses AI to help veterinarians save time and increase productivity. It offers three levels of control, so you can choose how hands-off you want to be. With Verified, you can simply record your notes and our scribes will verify the accuracy and place them in your PMS for you. With Auto-SOAP Records, you can record an entire exam or dictate your notes after and have Talkatoo auto-magically format the recording into a SOAP note, or other template. With Desktop Dictation, you can dictate in any field, in any app, on Mac or Windows. You can even connect your mobile device as a secure microphone to make the process easier.
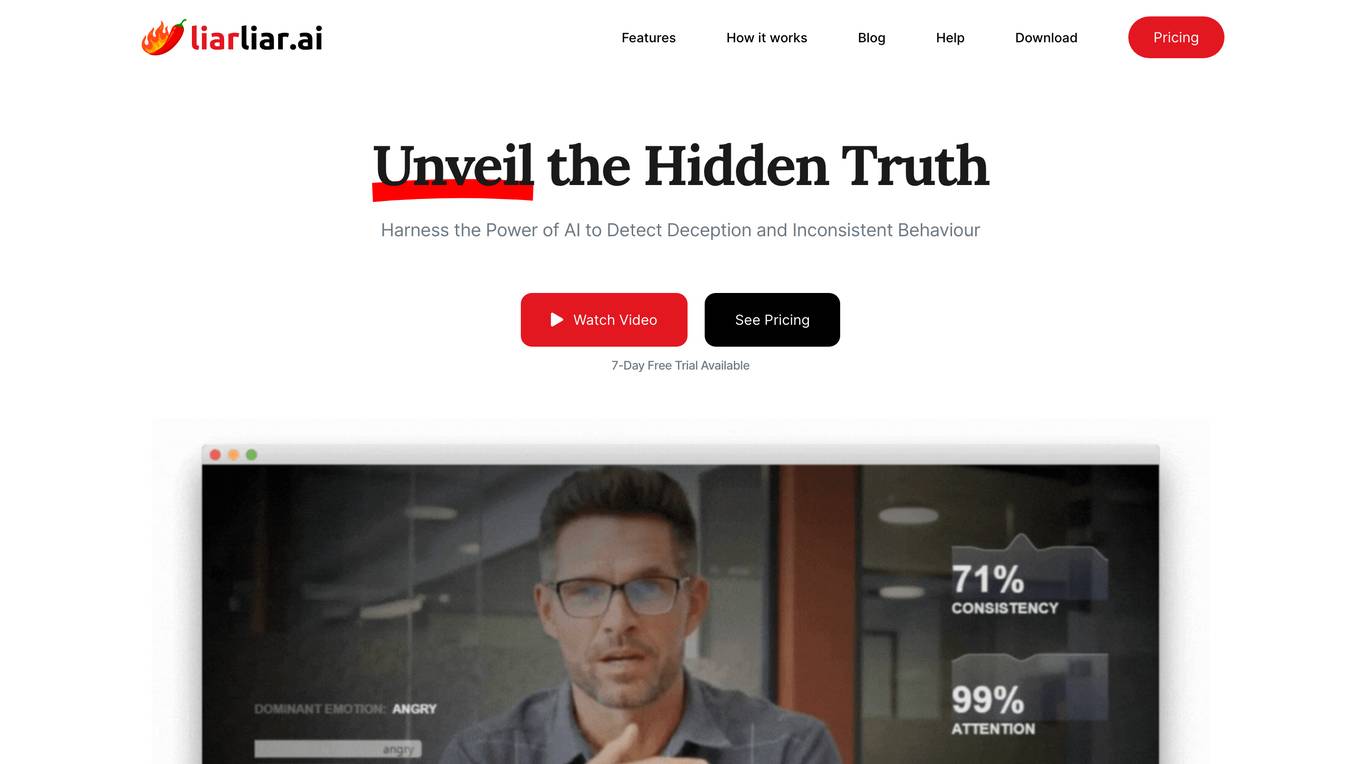
LiarLiar.ai
LiarLiar.ai is an AI lie detector and heart rate monitor application that utilizes cutting-edge AI technology to detect deception and inconsistent behavior by analyzing micromovements, heart rate, subtle cues in body language, facial expressions, voice consistency, and choice of language. It offers real-time transcription, language analysis, automatic recording, and reporting features. The tool combines technology and psychology to interpret data accurately, providing insights into the honesty of interactions. LiarLiar.ai aims to revolutionize communication, enhance trust, and promote transparency in the modern world.
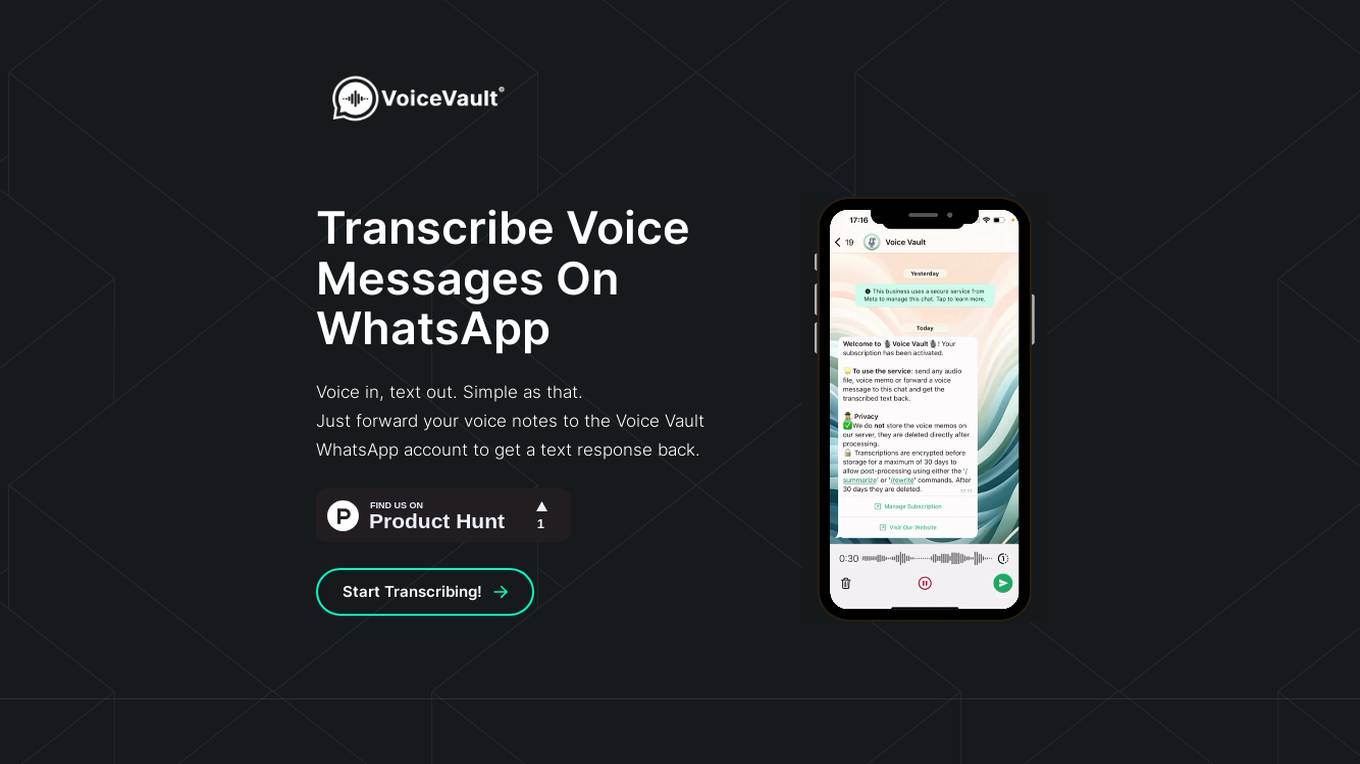
Voice Vault
Voice Vault is an AI tool that transcribes voice messages on WhatsApp. It allows users to forward voice notes to the Voice Vault WhatsApp account to receive a text response back. The application simplifies tasks such as searching through voice memos, content writing, note-taking, and more. Voice Vault offers two pricing plans with different features, including support for various audio formats and languages. The tool prioritizes user privacy by not storing voice memos and ensuring data is not used for training AI models.

Unvoice Bot
Unvoice Bot is an AI-powered WhatsApp voice transcriber that helps you convert voice messages into text. It is a convenient tool for busy professionals, students, and anyone who wants to save time and effort in managing their WhatsApp conversations. With Unvoice Bot, you can easily transcribe voice messages, search through transcripts, and share them with others.
Vemo AI
Vemo AI is a voice-to-text app that uses AI to transcribe and summarize voice notes. It is designed to help users capture their thoughts and ideas quickly and easily, and to streamline the writing process. Vemo AI can be used for a variety of purposes, including brainstorming, content creation, journaling, interviews, meetings, and educational note-taking.
20 - Open Source AI Tools

amazon-transcribe-live-call-analytics
The Amazon Transcribe Live Call Analytics (LCA) with Agent Assist Sample Solution is designed to help contact centers assess and optimize caller experiences in real time. It leverages Amazon machine learning services like Amazon Transcribe, Amazon Comprehend, and Amazon SageMaker to transcribe and extract insights from contact center audio. The solution provides real-time supervisor and agent assist features, integrates with existing contact centers, and offers a scalable, cost-effective approach to improve customer interactions. The end-to-end architecture includes features like live call transcription, call summarization, AI-powered agent assistance, and real-time analytics. The solution is event-driven, ensuring low latency and seamless processing flow from ingested speech to live webpage updates.
RealtimeSTT_LLM_TTS
RealtimeSTT is an easy-to-use, low-latency speech-to-text library for realtime applications. It listens to the microphone and transcribes voice into text, making it ideal for voice assistants and applications requiring fast and precise speech-to-text conversion. The library utilizes Voice Activity Detection, Realtime Transcription, and Wake Word Activation features. It supports GPU-accelerated transcription using PyTorch with CUDA support. RealtimeSTT offers various customization options for different parameters to enhance user experience and performance. The library is designed to provide a seamless experience for developers integrating speech-to-text functionality into their applications.

noScribe
noScribe is an AI-based software designed for automated audio transcription, specifically tailored for transcribing interviews for qualitative social research or journalistic purposes. It is a free and open-source tool that runs locally on the user's computer, ensuring data privacy. The software can differentiate between speakers and supports transcription in 99 languages. It includes a user-friendly editor for reviewing and correcting transcripts. Developed by Kai Dröge, a PhD in sociology with a background in computer science, noScribe aims to streamline the transcription process and enhance the efficiency of qualitative analysis.


modelfusion
ModelFusion is an abstraction layer for integrating AI models into JavaScript and TypeScript applications, unifying the API for common operations such as text streaming, object generation, and tool usage. It provides features to support production environments, including observability hooks, logging, and automatic retries. You can use ModelFusion to build AI applications, chatbots, and agents. ModelFusion is a non-commercial open source project that is community-driven. You can use it with any supported provider. ModelFusion supports a wide range of models including text generation, image generation, vision, text-to-speech, speech-to-text, and embedding models. ModelFusion infers TypeScript types wherever possible and validates model responses. ModelFusion provides an observer framework and logging support. ModelFusion ensures seamless operation through automatic retries, throttling, and error handling mechanisms. ModelFusion is fully tree-shakeable, can be used in serverless environments, and only uses a minimal set of dependencies.
ai-audio-startups
The 'ai-audio-startups' repository is a community list of startups working with AI for audio and music tech. It includes a comprehensive collection of tools and platforms that leverage artificial intelligence to enhance various aspects of music creation, production, source separation, analysis, recommendation, health & wellbeing, radio/podcast, hearing, sound detection, speech transcription, synthesis, enhancement, and manipulation. The repository serves as a valuable resource for individuals interested in exploring innovative AI applications in the audio and music industry.

ai-audio-datasets
AI Audio Datasets List (AI-ADL) is a comprehensive collection of datasets consisting of speech, music, and sound effects, used for Generative AI, AIGC, AI model training, and audio applications. It includes datasets for speech recognition, speech synthesis, music information retrieval, music generation, audio processing, sound synthesis, and more. The repository provides a curated list of diverse datasets suitable for various AI audio tasks.
openai-chat-api-workflow
**OpenAI Chat API Workflow for Alfred** An Alfred 5 Workflow for using OpenAI Chat API to interact with GPT-3.5/GPT-4 🤖💬 It also allows image generation 🖼️, image understanding 👀, speech-to-text conversion 🎤, and text-to-speech synthesis 🔈 **Features:** * Execute all features using Alfred UI, selected text, or a dedicated web UI * Web UI is constructed by the workflow and runs locally on your Mac 💻 * API call is made directly between the workflow and OpenAI, ensuring your chat messages are not shared online with anyone other than OpenAI 🔒 * OpenAI does not use the data from the API Platform for training 🚫 * Export chat data to a simple JSON format external file 📄 * Continue the chat by importing the exported data later 🔄

llms-tools
The 'llms-tools' repository is a comprehensive collection of AI tools, open-source projects, and research related to Large Language Models (LLMs) and Chatbots. It covers a wide range of topics such as AI in various domains, open-source models, chats & assistants, visual language models, evaluation tools, libraries, devices, income models, text-to-image, computer vision, audio & speech, code & math, games, robotics, typography, bio & med, military, climate, finance, and presentation. The repository provides valuable resources for researchers, developers, and enthusiasts interested in exploring the capabilities of LLMs and related technologies.
org-ai
org-ai is a minor mode for Emacs org-mode that provides access to generative AI models, including OpenAI API (ChatGPT, DALL-E, other text models) and Stable Diffusion. Users can use ChatGPT to generate text, have speech input and output interactions with AI, generate images and image variations using Stable Diffusion or DALL-E, and use various commands outside org-mode for prompting using selected text or multiple files. The tool supports syntax highlighting in AI blocks, auto-fill paragraphs on insertion, and offers block options for ChatGPT, DALL-E, and other text models. Users can also generate image variations, use global commands, and benefit from Noweb support for named source blocks.
local_multimodal_ai_chat
Local Multimodal AI Chat is a hands-on project that teaches you how to build a multimodal chat application. It integrates different AI models to handle audio, images, and PDFs in a single chat interface. This project is perfect for anyone interested in AI and software development who wants to gain practical experience with these technologies.

GlaDOS
This project aims to create a real-life version of GLaDOS, an aware, interactive, and embodied AI entity. It involves training a voice generator, developing a 'Personality Core,' implementing a memory system, providing vision capabilities, creating 3D-printable parts, and designing an animatronics system. The software architecture focuses on low-latency voice interactions, utilizing a circular buffer for data recording, text streaming for quick transcription, and a text-to-speech system. The project also emphasizes minimal dependencies for running on constrained hardware. The hardware system includes servo- and stepper-motors, 3D-printable parts for GLaDOS's body, animations for expression, and a vision system for tracking and interaction. Installation instructions cover setting up the TTS engine, required Python packages, compiling llama.cpp, installing an inference backend, and voice recognition setup. GLaDOS can be run using 'python glados.py' and tested using 'demo.ipynb'.
wingman-ai
Wingman AI allows you to use your voice to talk to various AI providers and LLMs, process your conversations, and ultimately trigger actions such as pressing buttons or reading answers. Our _Wingmen_ are like characters and your interface to this world, and you can easily control their behavior and characteristics, even if you're not a developer. AI is complex and it scares people. It's also **not just ChatGPT**. We want to make it as easy as possible for you to get started. That's what _Wingman AI_ is all about. It's a **framework** that allows you to build your own Wingmen and use them in your games and programs. The idea is simple, but the possibilities are endless. For example, you could: * **Role play** with an AI while playing for more immersion. Have air traffic control (ATC) in _Star Citizen_ or _Flight Simulator_. Talk to Shadowheart in Baldur's Gate 3 and have her respond in her own (cloned) voice. * Get live data such as trade information, build guides, or wiki content and have it read to you in-game by a _character_ and voice you control. * Execute keystrokes in games/applications and create complex macros. Trigger them in natural conversations with **no need for exact phrases.** The AI understands the context of your dialog and is quite _smart_ in recognizing your intent. Say _"It's raining! I can't see a thing!"_ and have it trigger a command you simply named _WipeVisors_. * Automate tasks on your computer * improve accessibility * ... and much more
obsidian-arcana
Arcana is a plugin for Obsidian that offers a collection of AI-powered tools inspired by famous historical figures to enhance creativity and productivity. It includes tools for conversation, text-to-speech transcription, speech-to-text replies, metadata markup, text generation, file moving, flashcard generation, auto tagging, and note naming. Users can interact with these tools using the command palette and sidebar views, with an OpenAI API key required for usage. The plugin aims to assist users in various note-taking and knowledge management tasks within the Obsidian vault environment.

MITSUHA
OneReality is a virtual waifu/assistant that you can speak to through your mic and it'll speak back to you! It has many features such as: * You can speak to her with a mic * It can speak back to you * Has short-term memory and long-term memory * Can open apps * Smarter than you * Fluent in English, Japanese, Korean, and Chinese * Can control your smart home like Alexa if you set up Tuya (more info in Prerequisites) It is built with Python, Llama-cpp-python, Whisper, SpeechRecognition, PocketSphinx, VITS-fast-fine-tuning, VITS-simple-api, HyperDB, Sentence Transformers, and Tuya Cloud IoT.


lhotse
Lhotse is a Python library designed to make speech and audio data preparation flexible and accessible. It aims to attract a wider community to speech processing tasks by providing a Python-centric design and an expressive command-line interface. Lhotse offers standard data preparation recipes, PyTorch Dataset classes for speech tasks, and efficient data preparation for model training with audio cuts. It supports data augmentation, feature extraction, and feature-space cut mixing. The tool extends Kaldi's data preparation recipes with seamless PyTorch integration, human-readable text manifests, and convenient Python classes.
20 - OpenAI Gpts


Transcript to Social Post
Transforms transcripts (from Whatsapp voice memos) into engaging social media content.
CliniType EHR
Voice-to-text, Vision-to-text transcription, Transcript-to-‘Clinical format’ integrated with CDS. Writes clinical notes, referral letter, generate PDF,prepare discharge summary. (Ultimate aid for clinicians)




Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.
Journal Recognizer OCR
Optimized OCR for Handwritten Notebooks, up to 10 image transcript copy w/1-click. No text prompt necessary. Reads journals, reports, notes. All handwriting transcribed verbatim, then text summarized, graphic image features described. Ask to change any behavior.

User Interview Product Manager
Transforms user interview transcripts into a list of tasks [Asana compatible CSV file]. Send feedback to https://x.com/kireet_agrawal


DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages
Video Insights: Summaries/Transcription/Vision
Chat with any video or audio. High-quality search, summarization, insights, multi-language transcriptions, and more. We currently support Youtube and files uploaded on our website.