Best AI tools for< Share Audio >
20 - AI tool Sites
Voice Embed
Voice Embed is an AI tool that allows users to convert any text into audio using AI technology. Users can easily embed the generated audio into their websites, making the content more engaging and interactive. Voice Embed provides a one-click solution to create and share audio from articles, with free cloud storage for all generated audio files. The tool simplifies the process of adding audio to blogs and websites, offering a user-friendly experience for content creators.
Article.Audio
Article.Audio is a web application that allows users to convert written articles into audio format. Users can listen to articles instead of reading them, making it convenient for those who prefer audio content consumption. The application is powered by Thundercontent and offers features such as converting articles to audio, listening without limits, managing audio tags, and more. Users can sign up to create or add tags to audio files and share them with others. Article.Audio supports multiple languages and voice styles, providing a personalized experience for users.
Wave
Wave is an AI-powered transcription and summarization application designed for iOS and Android devices. It allows users to effortlessly record audio, transcribe it into text, and generate concise summaries. With features like multilingual support, phone call capture, and Siri shortcut compatibility, Wave aims to streamline note-taking during meetings, walk and talks, and other important moments. Users can customize the length and format of summaries, share audio recordings easily, and enjoy unlimited recording capabilities. Wave prioritizes user privacy and offers different pricing plans based on recording needs.

Voicera
Voicera is a text-to-speech tool that allows users to convert written content into natural-sounding speech. With Voicera, users can create audio versions of their articles, blog posts, and other written content, making it more accessible to a wider audience. Voicera offers a variety of features to help users create high-quality audio content, including a library of natural-sounding voices, advanced audio editing tools, and the ability to add music and sound effects.
imagetomp3.com
imagetomp3.com is a website that allows users to convert images to MP3 audio files. Users can easily upload an image, and the platform will convert it into an MP3 file, which can be downloaded or shared. The website provides a simple and convenient way to create audio files from images, making it useful for various purposes such as creating audio versions of visual content, generating audio memes, or converting text to speech. imagetomp3.com offers a user-friendly interface and quick conversion process, making it a handy tool for those looking to convert images to audio effortlessly.
Trint
Trint is an AI transcription software that converts video, audio, and speech to text in over 40 languages with up to 99% accuracy. It allows users to transcribe, translate, edit, and collaborate seamlessly in a single workflow. Trint is trusted by professionals in various industries for its efficiency and accuracy in transcription tasks.
Gan.AI
Gan.AI is an AI-powered platform revolutionizing communication through video personalization, text-to-speech, avatar creation, and more. It offers advanced features like voice cloning, lipsync, and dubbing to enhance human representation in digital content. With a focus on authentic human expression, Gan.AI enables users to create personalized videos at scale, connect with global audiences, and drive engagement rates significantly. The platform caters to various industries, including marketing, entertainment, and customer engagement, providing powerful APIs for seamless integration and customization.
OneAudio
OneAudio is an AI-powered tool that allows users to summarize, transcribe, and convert audio files into notes. With features like recording, summarization, and language selection, OneAudio helps users organize and transform their ideas efficiently. The tool leverages OpenAI GPT-4 and GPT-4o models to provide accurate transcriptions and summaries. Users can choose from different pricing plans based on their needs, from a free tier to a premium plan with unlimited features. OneAudio is designed to streamline the process of converting audio content into written notes, making it ideal for students, professionals, and anyone looking to enhance their productivity.
Audionotes
Audionotes is an AI-powered note-taking app that uses speech-to-text technology to transcribe and summarize audio recordings. It also offers a variety of features to help users organize and manage their notes, including the ability to create to-do lists, set reminders, and share notes with others. Audionotes is available as a web app, a mobile app, and a Chrome extension.
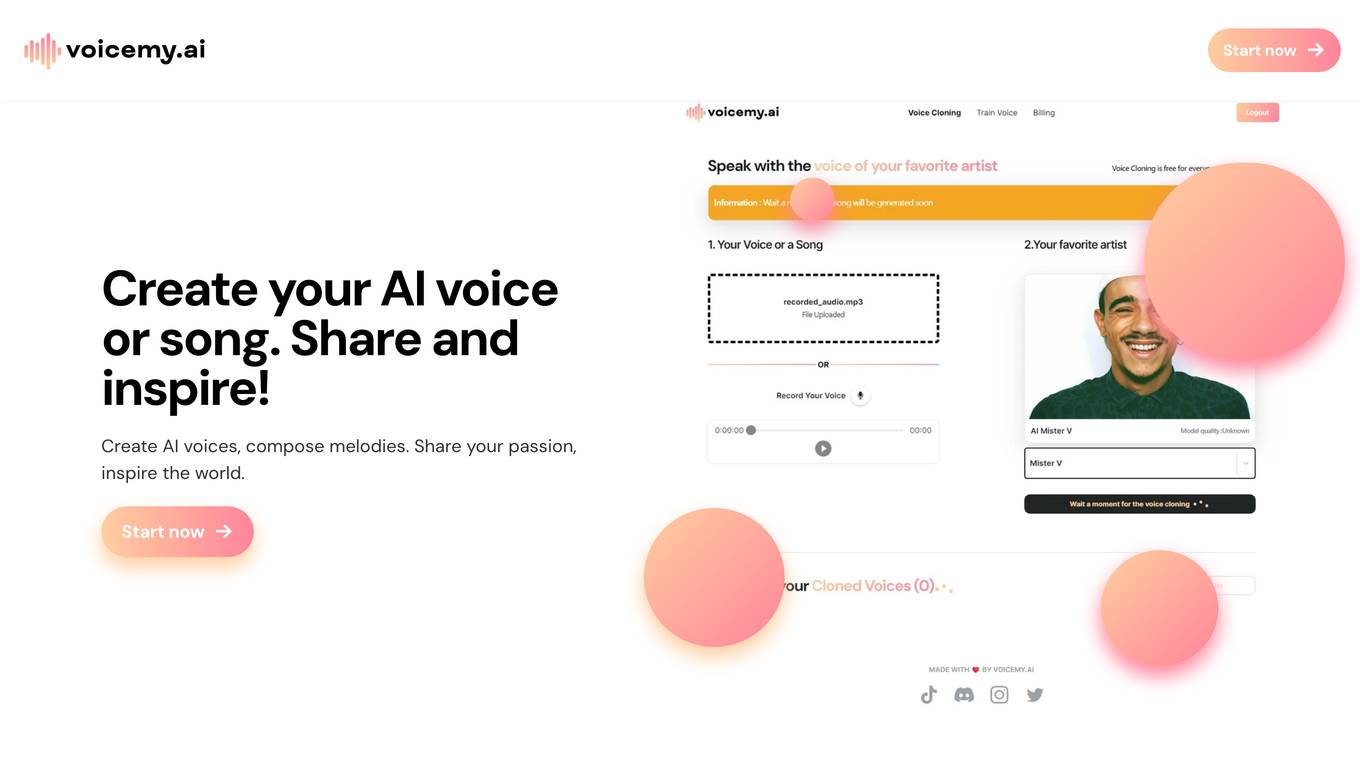
Voicemy.ai
Voicemy.ai is an AI application that allows users to create AI voices and songs. Users can clone voices of famous personalities, compose melodies, and convert text into spoken words using chosen voice models. The platform aims to inspire creativity and enable users to share their passion with the world.

TheStoryGPT
TheStoryGPT is an AI-powered interactive storytelling tool that allows users to create personalized interactive stories. With a focus on immersive storytelling, users can engage with a variety of stories that respond to their choices. The tool offers high-quality audio experiences by allowing users to choose from a list of narrators. TheStoryGPT provides both free and paid plans, with the option to purchase credits for advanced choices. Users can contact the team for any questions or feedback via email.

ExperAI
ExperAI is an AI tool that allows users to share knowledge using chatbots and create digital personalities capable of answering questions, expressing emotions, and providing fun experiences. It offers a new way to engage audiences by giving content a voice through personality-enabled chatbots that are easily shareable with just one click.
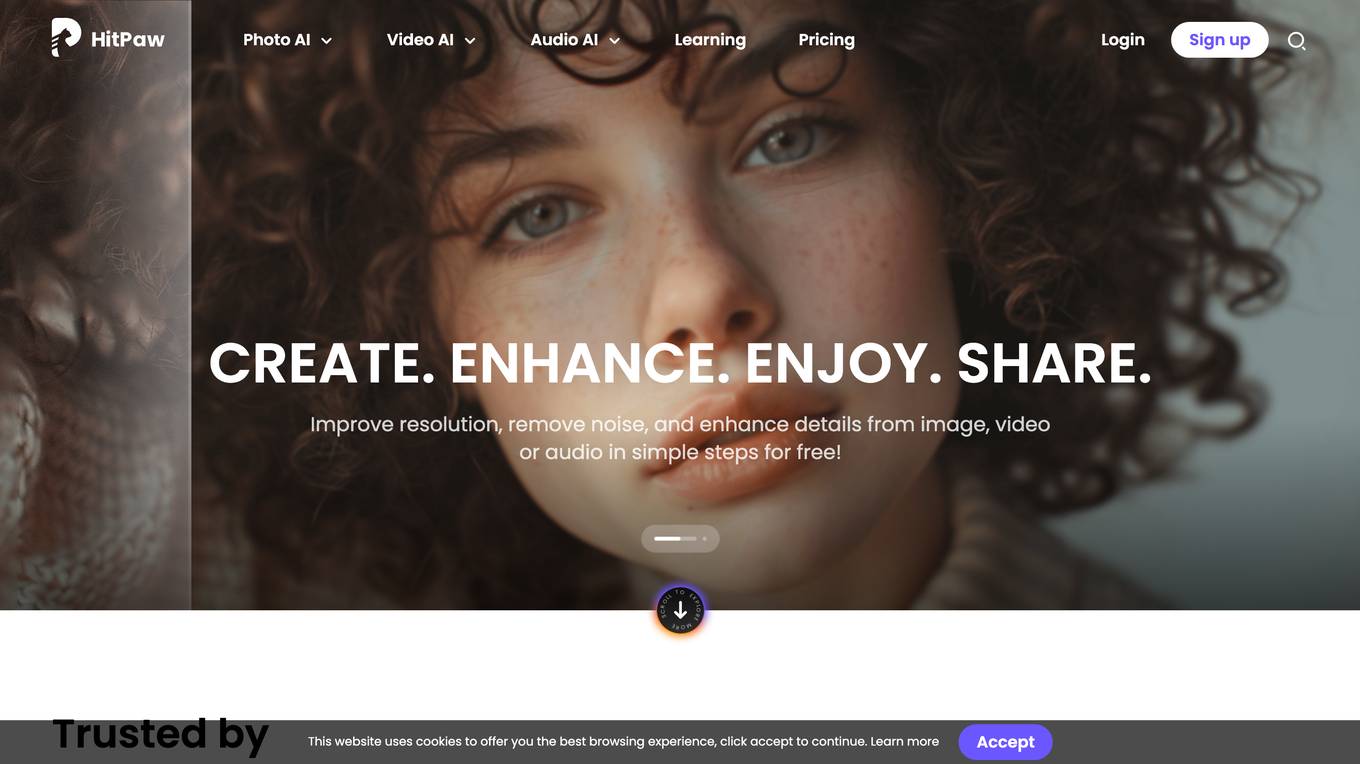
HitPaw Online
HitPaw Online is a website that provides a suite of AI-powered editing tools for photos, videos, and audio. The tools are easy to use and can be accessed online without the need to install any software. HitPaw Online's tools are powered by advanced AI algorithms that can automatically enhance the quality of your media files. For example, the Photo Enhancer tool can improve the resolution of images, remove noise, and adjust the colors. The Video Enhancer tool can upscale videos to 4K resolution, remove watermarks, and add subtitles. The Audio Enhancer tool can reduce background noise, extract audio from videos, and convert audio formats.
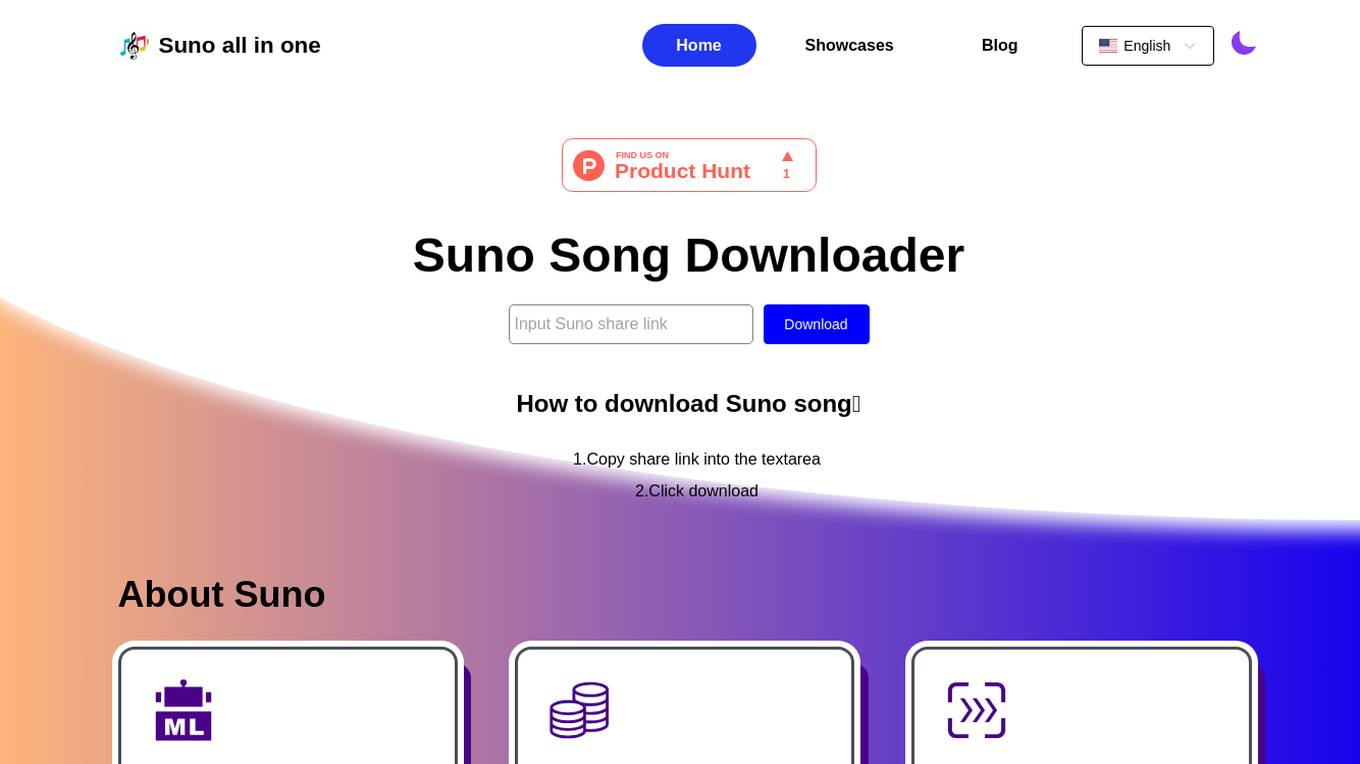
Suno
Suno is an all-in-one AI music generation tool that allows users to create, edit, and share music with ease. With Suno, you can generate music from scratch, add lyrics, and even collaborate with other musicians. Suno is perfect for musicians of all levels, from beginners to professionals.
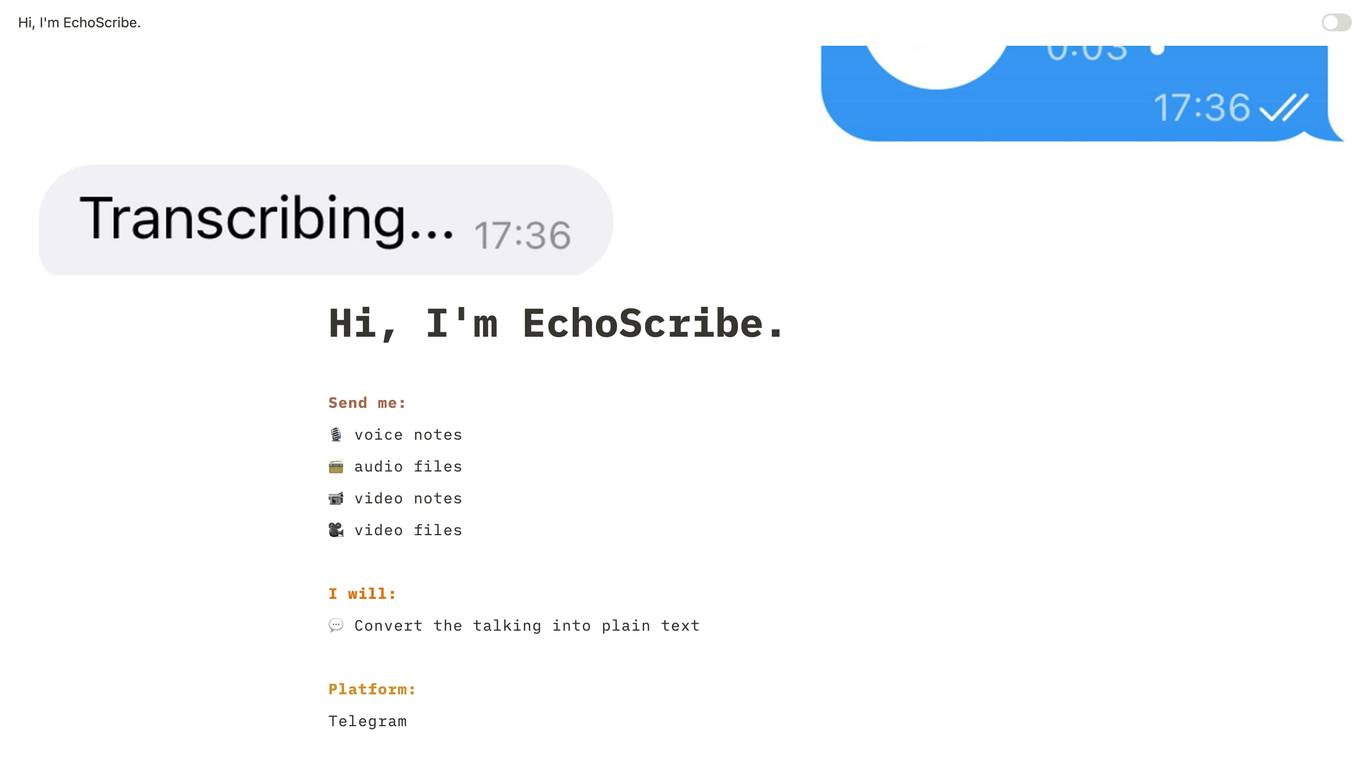
EchoScribe
EchoScribe is an AI-powered transcription and note-taking tool that helps you capture, organize, and share your ideas and conversations. With EchoScribe, you can easily record and transcribe audio and video, add notes and annotations, and collaborate with others in real-time. EchoScribe is perfect for students, journalists, researchers, and anyone who needs to capture and share information efficiently.
Transkriptor
Transkriptor is an AI-powered tool that allows users to convert audio or video files into text with high accuracy and efficiency. It supports over 100 languages and offers features like automatic transcription, translation, rich export options, and collaboration tools. With state-of-the-art AI technology, Transkriptor simplifies the transcription process for various purposes such as meetings, interviews, lectures, and more. The platform ensures fast, accurate, and affordable transcription services, making it a valuable tool for professionals and students across different industries.
Adobe Labs
Adobe Labs is a platform where Adobe showcases its latest explorations and innovations in the fields of creativity, expression, and communication. It features a variety of projects that utilize artificial intelligence (AI) and other cutting-edge technologies to enhance creative workflows and push the boundaries of digital art and design.
Adobe Podcast
Adobe Podcast is an AI-powered audio recording and editing tool that allows users to create and edit podcasts entirely on the web. With Adobe Podcast, users can record high-quality audio, add music and sound effects, and edit their recordings with ease. Adobe Podcast also offers a variety of features to help users promote and distribute their podcasts.
Gradio
Gradio is a tool that allows users to quickly and easily create web-based interfaces for their machine learning models. With Gradio, users can share their models with others, allowing them to interact with and use the models remotely. Gradio is easy to use and can be integrated with any Python library. It can be used to create a variety of different types of interfaces, including those for image classification, natural language processing, and time series analysis.
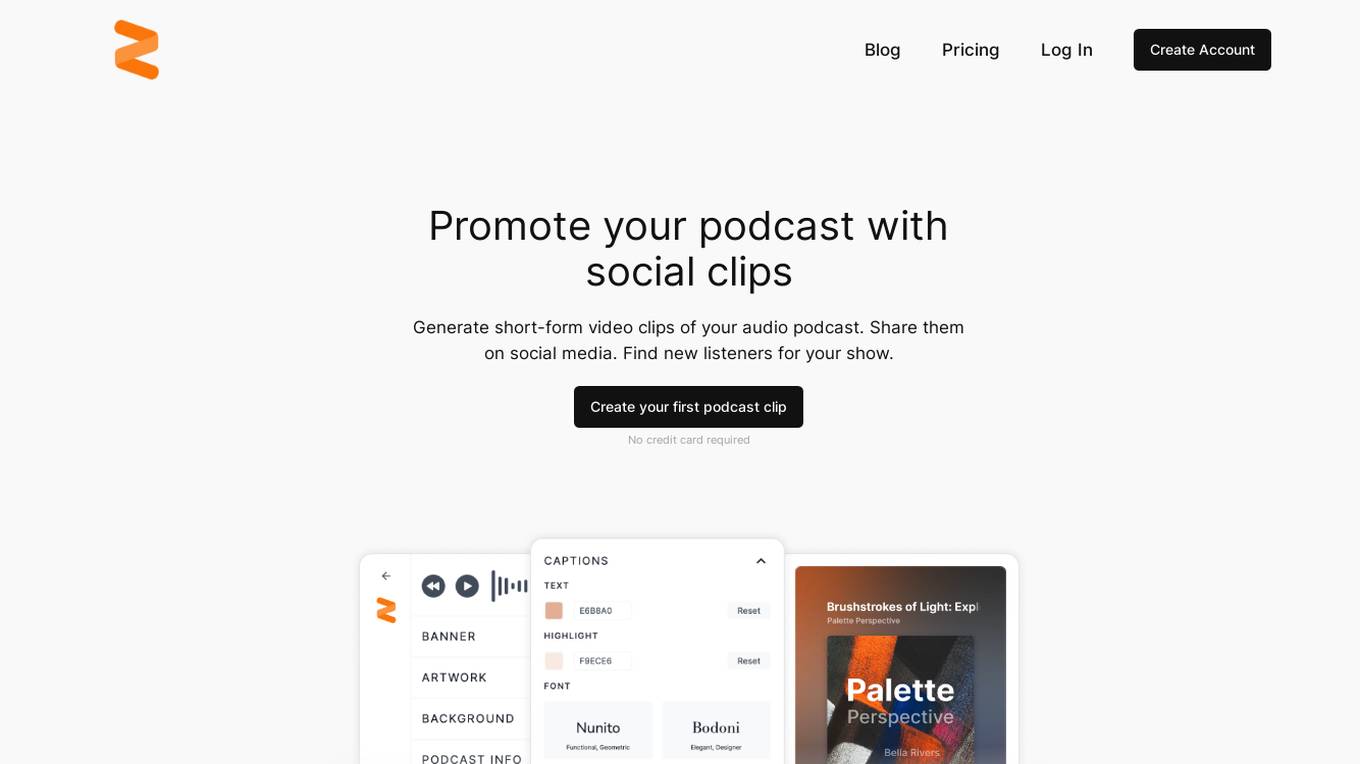
Reverb Street
Reverb Street is an AI-powered tool that helps podcasters create short-form video clips from their audio content. These clips can then be shared on social media to promote the podcast and reach a wider audience. Reverb Street is easy to use and requires no technical expertise. Simply connect your podcast feed, select the episode you want to promote, and choose the style of your clip. Reverb Street will automatically generate a video clip that is optimized for social media. You can then customize the clip with your own branding and messaging. Reverb Street is a valuable tool for podcasters who want to grow their audience and reach more listeners.
20 - Open Source AI Tools
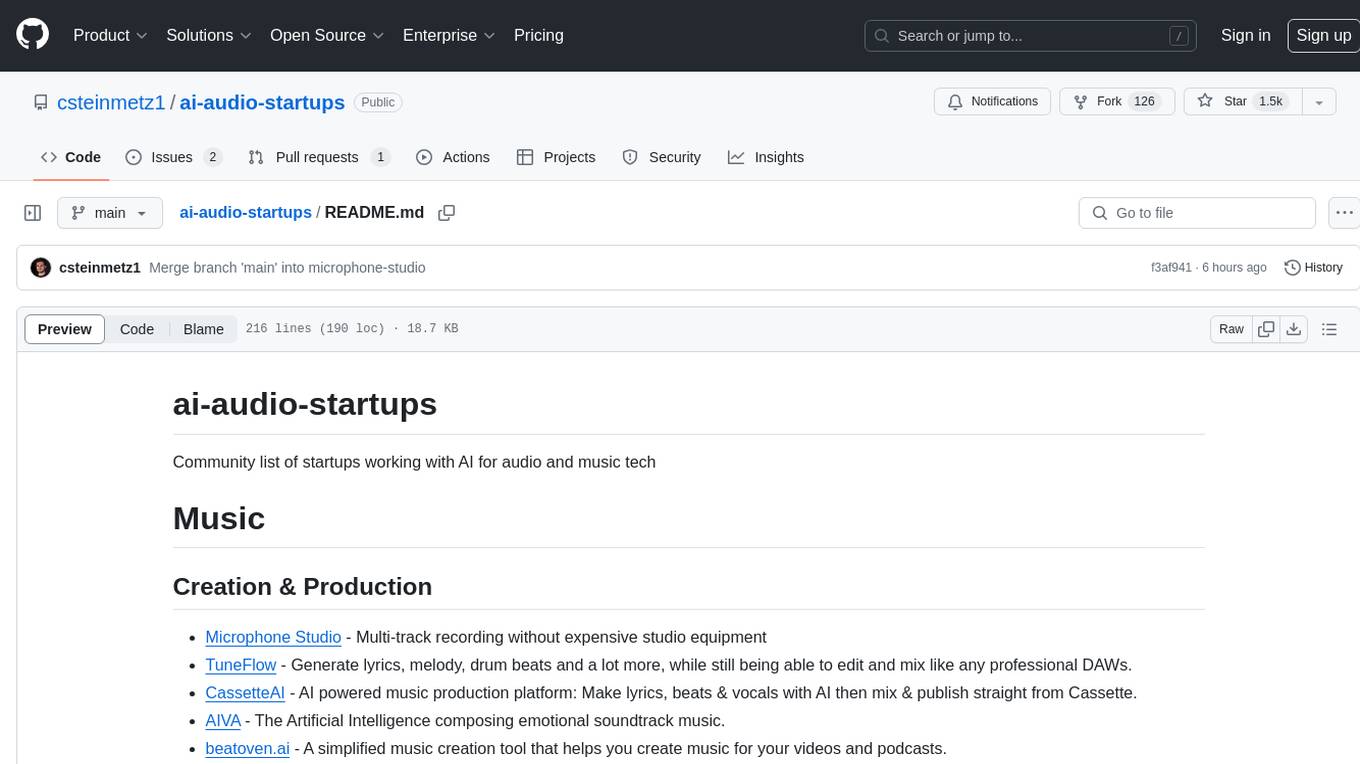
ai-audio-startups
The 'ai-audio-startups' repository is a community list of startups working with AI for audio and music tech. It includes a comprehensive collection of tools and platforms that leverage artificial intelligence to enhance various aspects of music creation, production, source separation, analysis, recommendation, health & wellbeing, radio/podcast, hearing, sound detection, speech transcription, synthesis, enhancement, and manipulation. The repository serves as a valuable resource for individuals interested in exploring innovative AI applications in the audio and music industry.
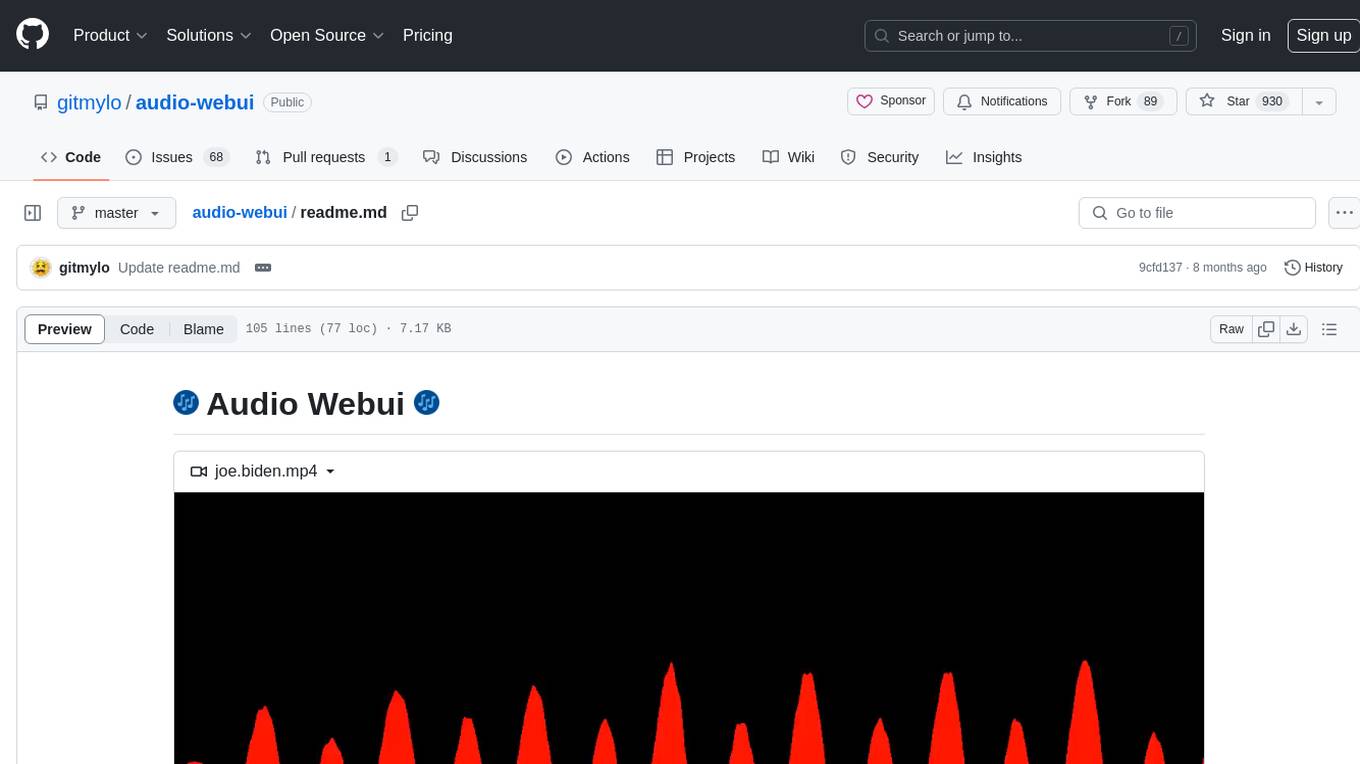
audio-webui
Audio Webui is a tool designed to provide a user-friendly interface for audio processing tasks. It supports automatic installers, Docker deployment, local manual installation, Google Colab integration, and common command line flags. Users can easily download, install, update, and run the tool for various audio-related tasks. The tool requires Python 3.10, Git, and ffmpeg for certain features. It also offers extensions for additional functionalities.

ai-audio-datasets
AI Audio Datasets List (AI-ADL) is a comprehensive collection of datasets consisting of speech, music, and sound effects, used for Generative AI, AIGC, AI model training, and audio applications. It includes datasets for speech recognition, speech synthesis, music information retrieval, music generation, audio processing, sound synthesis, and more. The repository provides a curated list of diverse datasets suitable for various AI audio tasks.
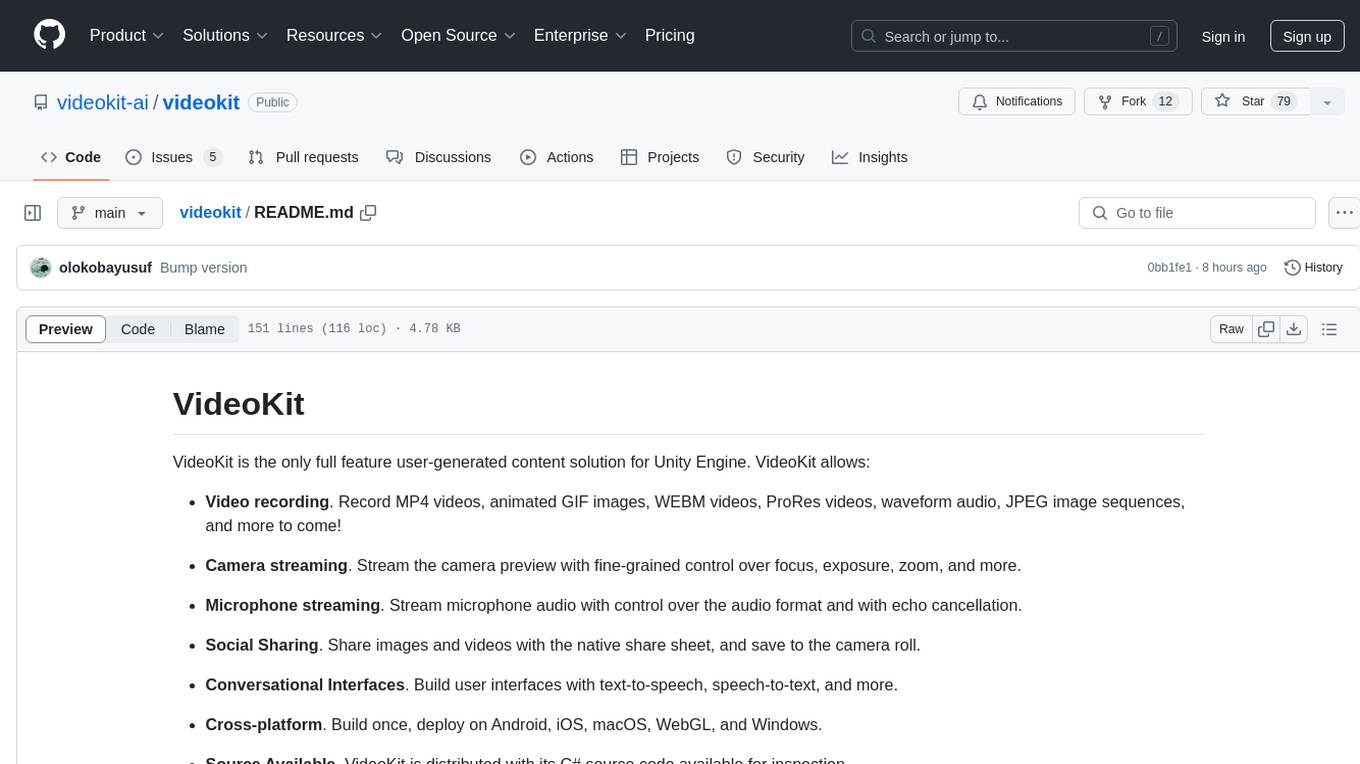
videokit
VideoKit is a full-featured user-generated content solution for Unity Engine, enabling video recording, camera streaming, microphone streaming, social sharing, and conversational interfaces. It is cross-platform, with C# source code available for inspection. Users can share media, save to camera roll, pick from camera roll, stream camera preview, record videos, remove background, caption audio, and convert text commands. VideoKit requires Unity 2022.3+ and supports Android, iOS, macOS, Windows, and WebGL platforms.
gemini-2-live-api-demo
A lightweight vanilla JavaScript implementation of the Gemini 2.0 Flash Multimodal Live API client, providing real-time interaction with Gemini's API through text, audio, video, and screen sharing capabilities. Built with vanilla JavaScript, it offers features like real-time text chat, audio input/output with visualization, motion-detected video streaming, and screen sharing. Users can connect to the API, send text messages, toggle microphone for audio input, enable webcam for video streaming, share screen, and monitor real-time feedback in the logs panel. Custom tools can be added for extending functionality.
ragdoll-studio
Ragdoll Studio is a platform offering web apps and libraries for interacting with Ragdoll, enabling users to go beyond fine-tuning and create flawless creative deliverables, rich multimedia, and engaging experiences. It provides various modes such as Story Mode for creating and chatting with characters, Vector Mode for producing vector art, Raster Mode for producing raster art, Video Mode for producing videos, Audio Mode for producing audio, and 3D Mode for producing 3D objects. Users can export their content in various formats and share their creations on the community site. The platform consists of a Ragdoll API and a front-end React application for seamless usage.
RAVE
RAVE is a variational autoencoder for fast and high-quality neural audio synthesis. It can be used to generate new audio samples from a given dataset, or to modify the style of existing audio samples. RAVE is easy to use and can be trained on a variety of audio datasets. It is also computationally efficient, making it suitable for real-time applications.

TeroSubtitler
Tero Subtitler is an open source, cross-platform, and free subtitle editing software with a user-friendly interface. It offers fully fledged editing with SMPTE and MEDIA modes, support for various subtitle formats, multi-level undo/redo, search and replace, auto-backup, source and transcription modes, translation memory, audiovisual preview, timeline with waveform visualizer, manipulation tools, formatting options, quality control features, translation and transcription capabilities, validation tools, automation for correcting errors, and more. It also includes features like exporting subtitles to MP3, importing/exporting Blu-ray SUP format, generating blank video, generating video with hardcoded subtitles, video dubbing, and more. The tool utilizes powerful multimedia playback engines like mpv, advanced audio/video manipulation tools like FFmpeg, tools for automatic transcription like whisper.cpp/Faster-Whisper, auto-translation API like Google Translate, and ElevenLabs TTS for video dubbing.

VoiceStreamAI
VoiceStreamAI is a Python 3-based server and JavaScript client solution for near-realtime audio streaming and transcription using WebSocket. It employs Huggingface's Voice Activity Detection (VAD) and OpenAI's Whisper model for accurate speech recognition. The system features real-time audio streaming, modular design for easy integration of VAD and ASR technologies, customizable audio chunk processing strategies, support for multilingual transcription, and secure sockets support. It uses a factory and strategy pattern implementation for flexible component management and provides a unit testing framework for robust development.
pyht
pyht is a Python SDK for the PlayHT's AI Text-to-Speech API, allowing users to convert text into high-quality audio streams in humanlike voice. It supports real-time text-to-speech streaming, pre-built and custom voices, various audio formats, and different sample rates.

screenpipe
24/7 Screen & Audio Capture Library to build personalized AI powered by what you've seen, said, or heard. Works with Ollama. Alternative to Rewind.ai. Open. Secure. You own your data. Rust. We are shipping daily, make suggestions, post bugs, give feedback. Building a reliable stream of audio and screenshot data, simplifying life for developers by solving non-trivial problems. Multiple installation options available. Experimental tool with various integrations and features for screen and audio capture, OCR, STT, and more. Open source project focused on enabling tooling & infrastructure for a wide range of applications.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.
simple-openai
Simple-OpenAI is a Java library that provides a simple way to interact with the OpenAI API. It offers consistent interfaces for various OpenAI services like Audio, Chat Completion, Image Generation, and more. The library uses CleverClient for HTTP communication, Jackson for JSON parsing, and Lombok to reduce boilerplate code. It supports asynchronous requests and provides methods for synchronous calls as well. Users can easily create objects to communicate with the OpenAI API and perform tasks like text-to-speech, transcription, image generation, and chat completions.
obs-localvocal
LocalVocal is a Speech AI assistant OBS Plugin that enables users to transcribe speech into text and translate it into any language locally on their machine. The plugin runs OpenAI's Whisper for real-time speech processing and prediction. It supports features like transcribing audio in real-time, displaying captions on screen, sending captions to files, syncing captions with recordings, and translating captions to major languages. Users can bring their own Whisper model, filter or replace captions, and experience partial transcriptions for streaming. The plugin is privacy-focused, requiring no GPU, cloud costs, network, or downtime.

ebook2audiobook
ebook2audiobook is a CPU/GPU converter tool that converts eBooks to audiobooks with chapters and metadata using tools like Calibre, ffmpeg, XTTSv2, and Fairseq. It supports voice cloning and a wide range of languages. The tool is designed to run on 4GB RAM and provides a new v2.0 Web GUI interface for user-friendly interaction. Users can convert eBooks to text format, split eBooks into chapters, and utilize high-quality text-to-speech functionalities. Supported languages include Arabic, Chinese, English, French, German, Hindi, and many more. The tool can be used for legal, non-DRM eBooks only and should be used responsibly in compliance with applicable laws.
EasyAIVtuber
EasyAIVtuber is a tool designed to animate 2D waifus by providing features like automatic idle actions, speaking animations, head nodding, singing animations, and sleeping mode. It also offers API endpoints and a web UI for interaction. The tool requires dependencies like torch and pre-trained models for optimal performance. Users can easily test the tool using OBS and UnityCapture, with options to customize character input, output size, simplification level, webcam output, model selection, port configuration, sleep interval, and movement extension. The tool also provides an API using Flask for actions like speaking based on audio, rhythmic movements, singing based on music and voice, stopping current actions, and changing images.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.

wunjo.wladradchenko.ru
Wunjo AI is a comprehensive tool that empowers users to explore the realm of speech synthesis, deepfake animations, video-to-video transformations, and more. Its user-friendly interface and privacy-first approach make it accessible to both beginners and professionals alike. With Wunjo AI, you can effortlessly convert text into human-like speech, clone voices from audio files, create multi-dialogues with distinct voice profiles, and perform real-time speech recognition. Additionally, you can animate faces using just one photo combined with audio, swap faces in videos, GIFs, and photos, and even remove unwanted objects or enhance the quality of your deepfakes using the AI Retouch Tool. Wunjo AI is an all-in-one solution for your voice and visual AI needs, offering endless possibilities for creativity and expression.
NeuroSandboxWebUI
A simple and convenient interface for using various neural network models. Users can interact with LLM using text, voice, and image input to generate images, videos, 3D objects, music, and audio. The tool supports a wide range of models for different tasks such as image generation, video generation, audio file separation, voice conversion, and more. Users can also view files from the outputs directory in a gallery, download models, change application settings, and check system sensors. The goal of the project is to create an easy-to-use application for utilizing neural network models.

Macaw-LLM
Macaw-LLM is a pioneering multi-modal language modeling tool that seamlessly integrates image, audio, video, and text data. It builds upon CLIP, Whisper, and LLaMA models to process and analyze multi-modal information effectively. The tool boasts features like simple and fast alignment, one-stage instruction fine-tuning, and a new multi-modal instruction dataset. It enables users to align multi-modal features efficiently, encode instructions, and generate responses across different data types.
20 - OpenAI Gpts
Medium Muse 2.0
I create Medium posts tailored to your brand and audience. Provide the following: [BRAND CONTEXT], [AUDIENCE CONTEXT], [POST TOPIC] | UPDATE #1 - Added SEO optimization


Log Analyzer
I'm designed to help You analyze any logs like Linux system logs, Windows logs, any security logs, access logs, error logs, etc. Please do not share information that You would like to keep private. The author does not collect or process any personal data.
Californian Classics
Social media content creator for Californian Classics specialising in air-cooled VW parts, restorations, and sales, focusing primarily on the Volkswagen Karmann Ghia
Memer 3000
Yo! I'm bout to blow the roof with deez memes! * plays never gonna give you up * Get rick rolled!
LI Article Share
Writes LI posts from article links you share, and you give tone and style for personalization, Then copy and paste to LI social profile, or via sharing tool
Cloudy with a Chance of Creation
Share a shape and 3 colours and I will generate a beautiful generative art.



Past Year Highlights
I share well-documented global news events from the same date last year, in a friendly, professional tone.



Geo Explorer
I'm a geography enthusiast eager to share fun and interesting facts about our world!