Best AI tools for< Offload Cpu Tasks >
5 - AI tool Sites
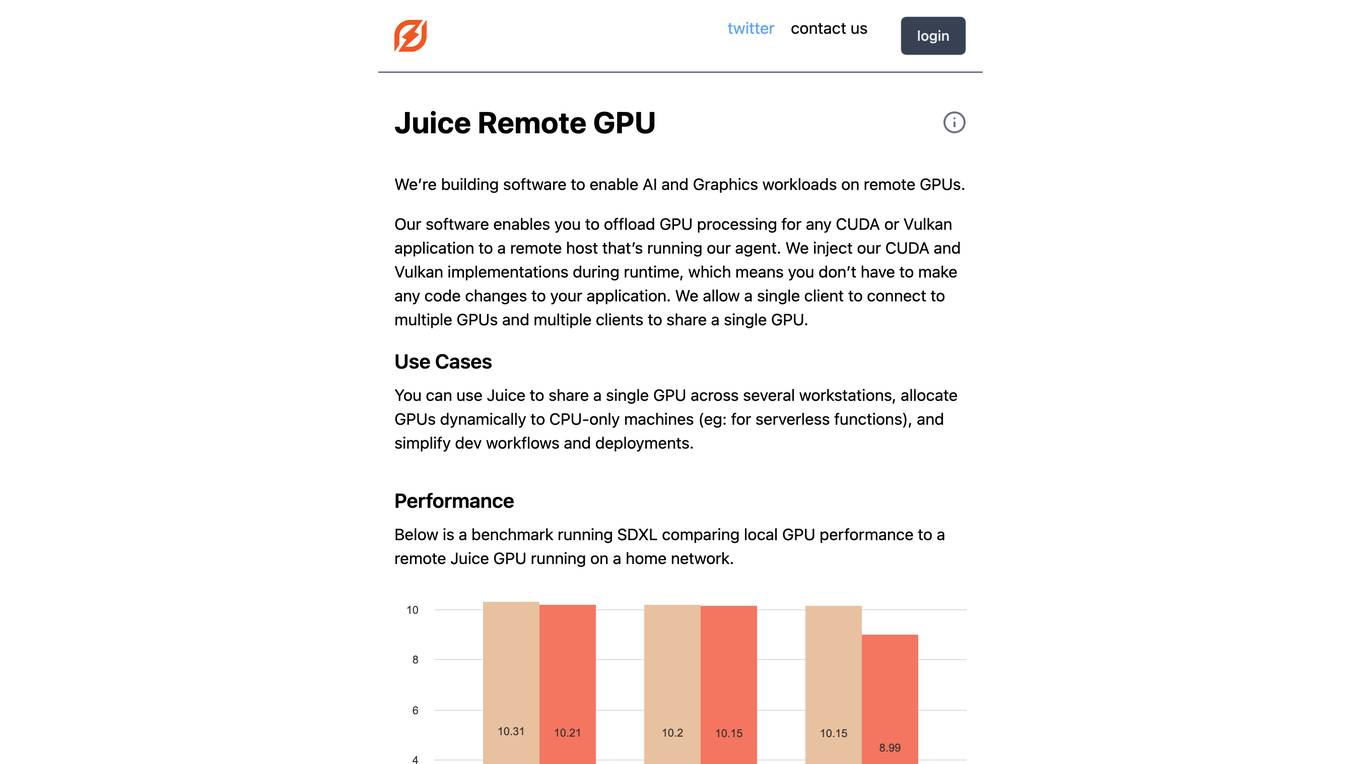
Juice Remote GPU
Juice Remote GPU is a software that enables AI and Graphics workloads on remote GPUs. It allows users to offload GPU processing for any CUDA or Vulkan application to a remote host running the Juice agent. The software injects CUDA and Vulkan implementations during runtime, eliminating the need for code changes in the application. Juice supports multiple clients connecting to multiple GPUs and multiple clients sharing a single GPU. It is useful for sharing a single GPU across multiple workstations, allocating GPUs dynamically to CPU-only machines, and simplifying development workflows and deployments. Juice Remote GPU performs within 5% of a local GPU when running in the same datacenter. It supports various APIs, including CUDA, Vulkan, DirectX, and OpenGL, and is compatible with PyTorch and TensorFlow. The team behind Juice Remote GPU consists of engineers from Meta, Intel, and the gaming industry.

Kindo
Kindo is an AI-powered platform designed for DevSecOps teams to automate tasks, write doctrine, and orchestrate infrastructure responses. It offers AI-powered Runbook automations to streamline workflows, automate tedious tasks, and enhance security controls. Kindo enables users to offload time-consuming tasks to AI Agents, prioritize critical tasks, and monitor AI-related activities for compliance and informed decision-making. The platform provides a comprehensive vantage point for modern infrastructure defense and instrumentation, allowing users to create repeatable processes, automate vulnerability assessment and remediation, and secure multi-cloud IAM configurations.

Cykel AI
Cykel AI is an AI co-pilot designed to assist users in automating various digital tasks. It interacts with any website to complete complex tasks based on user instructions, allowing users to offload 50% of their to-do list to AI. From sending emails to updating spreadsheets, Cykel offers a seamless way to streamline digital workflows and boost productivity. With features like autonomous learning, scalable parallel tasking, and the ability to create and share shortcuts, Cykel aims to revolutionize task automation for individuals and teams across different industries.
Botowski
Botowski is an AI-powered content generation tool designed to assist users in creating high-quality content quickly and easily. It offers a range of features such as article generation, product description generation, chatbot creation, slogan making, and more. With Botowski, users can offload some of their content creation work to an AI-powered buddy, ensuring original and polished content in minutes. The tool is user-friendly and can be used by copywriters, business owners, bloggers, students, and professionals to enhance their content creation process.
SmileDial
SmileDial is a natural dental AI receptionist designed for Canadian dental practices. It offers a 24/7 AI receptionist system to help dentists save time, reduce costs, and enhance patient satisfaction. The AI-driven receptionist, named Susan, assists in real-time scheduling, automated reminders, insurance checks, and PHIPA compliance. SmileDial aims to maximize bookings, decrease no-shows, and offload time-consuming tasks, ultimately improving the efficiency and patient experience in dental offices.
1 - Open Source AI Tools
prime
Prime is a framework for efficient, globally distributed training of AI models over the internet. It includes features such as fault-tolerant training with ElasticDeviceMesh, asynchronous distributed checkpointing, live checkpoint recovery, custom Int8 All-Reduce Kernel, maximizing bandwidth utilization, PyTorch FSDP2/DTensor ZeRO-3 implementation, and CPU off-loading. The framework aims to optimize communication, checkpointing, and bandwidth utilization for large-scale AI model training.