Best AI tools for< image resizing >
20 - AI tool Sites
1PX.AI
1PX.AI is an AI-powered image resizing tool that allows users to easily resize images without compromising quality. The tool uses advanced algorithms to intelligently adjust image dimensions while preserving important details. With 1PX.AI, users can quickly optimize images for various platforms such as websites, social media, and e-commerce. The intuitive interface and fast processing make it a convenient solution for individuals and businesses looking to enhance their visual content effortlessly.
PixelBin
PixelBin is a cloud-based digital asset management and image optimization platform that uses artificial intelligence (AI) to automate and enhance image processing tasks. It offers a range of features such as bulk image uploading, real-time image transformations, and on-the-fly image delivery. PixelBin's AI-powered features include automatic image optimization, background removal, image resizing, and watermarking. The platform integrates with various third-party applications and provides APIs for developers to build custom integrations. PixelBin is designed to help businesses streamline their image workflows, improve website performance, and enhance the visual experience for their users.
Retouch4me
Retouch4me is a software that uses artificial intelligence (AI) to help photographers and retouchers edit their images. The software offers a variety of plugins that can be used to perform a variety of tasks, such as color correction, skin retouching, and object removal. Retouch4me is designed to be easy to use, even for beginners, and it can significantly reduce the amount of time it takes to edit photos.
Amplifi.io
Amplifi.io is a digital asset management (DAM) and product information management (PIM) solution that helps businesses manage their digital assets and product information in one place. With Amplifi.io, businesses can create a single source of truth for their brand, ensuring that all product information is up-to-date, managed, and delivered where it needs to go. Amplifi.io also offers a variety of features to help businesses automate their marketing and sales processes, such as content syndication, product marketing kits, and image resizing.
Colorcinch
Colorcinch is an online photo editor and AI cartoonizer that allows users to easily edit and transform their photos into artwork. It offers a wide range of features, including background removal, image cropping and resizing, color adjustment, and the ability to add filters and effects. Colorcinch also has a large library of stock photography, graphics, and icons that users can use to enhance their photos. The platform is available online and offline, making it easy for users to access their projects from anywhere.
Vectr
Vectr is a free online AI vector graphics editor and AI generator that allows users to design and edit vector graphics online without a steep learning curve. It offers features such as effortless background removal, text-to-image conversion, easy image vectorization, a low learning curve, real-time sharing, and blur-free resizing. Vectr is powered by AI, making graphic creation faster and simpler with time-saver tools and features. It is free to use forever and provides a chat feature for communication within the editor.
Coresel
Coresel is a website builder that uses artificial intelligence to help users create beautiful, professional websites without any coding or design experience. It offers a variety of features, including zero drag-and-drop editing, automatic resizing of images and other page elements, brand consistency, one-click publishing, forms, galleries, and SEO optimization. Coresel is perfect for individuals and small businesses who want to create a website quickly and easily.
Image Colorizer
Image Colorizer is an AI-powered photo editing tool that allows users to colorize, restore, enhance, retouch, and repair old photos. It uses advanced AI technology to automatically and instantly restore old photos, bringing them back to life. The tool is easy to use and offers a wide range of features to help users improve and restore their old pictures.
Image Editor AI
Image Editor AI is a web-based application that allows users to edit or create images using artificial intelligence. The application offers a variety of features, including the ability to remove backgrounds, upscale images, and create photorealistic images from scratch. Image Editor AI is easy to use and does not require any prior experience with image editing. The application is available for free and can be used on any device with an internet connection.
Image AI
Image AI is a powerful tool that allows you to generate unique and realistic images using artificial intelligence. With Image AI, you can create images of people, places, things, and even abstract concepts. The possibilities are endless! Image AI is perfect for artists, designers, writers, and anyone else who wants to create stunning visuals. With Image AI, you can:
AI-Powered Image To Caption Generator
This AI-powered image to caption generator is a tool that helps users create compelling and engaging captions for their images. It utilizes advanced artificial intelligence models to analyze the visual content of an image and generate descriptive text that accurately reflects the image's content. The tool is designed to save users time and effort in crafting captions, while also providing them with high-quality results that can enhance the impact of their visual content. Additionally, the tool offers multilingual support, allowing users to generate captions in multiple languages.
Image Caption Generator
The Image Caption Generator is an advanced tool that utilizes artificial intelligence to automatically generate captions for images. It offers a seamless experience in creating informative and engaging descriptions, ensuring your audience comprehends the story your images tell. Remarkably, this tool is free, requires no login, and is designed for easy accessibility. Captions are essential in creating a bridge between your visual content and your audience. They add context, enhance comprehension, and foster an emotional connection. Ideal for bloggers, marketers, educators, and business owners, compelling captions make your images more impactful. The Image Caption Generator creates pertinent, captivating, and descriptive captions using advanced neural networks, aligning perfectly with your audience's interests.
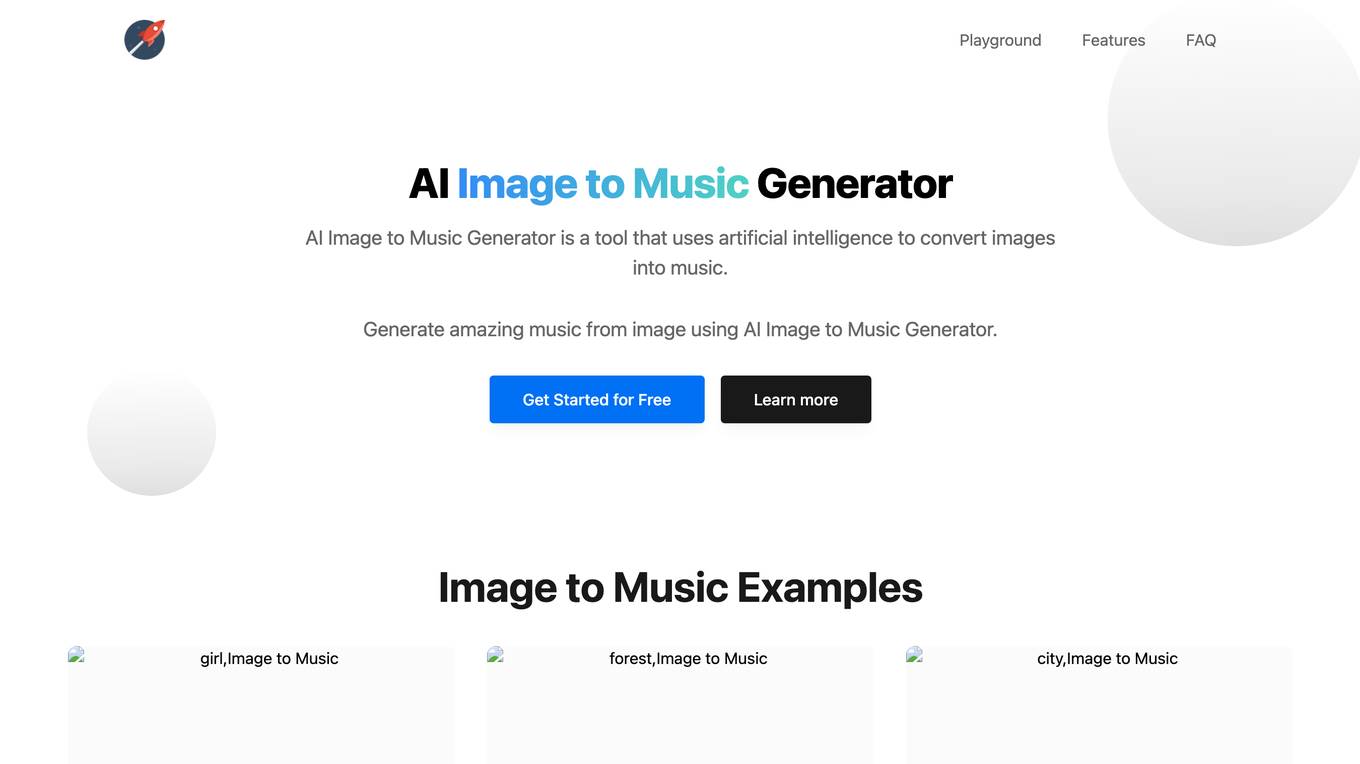
AI Image to Music Generator
AI Image to Music Generator is a tool that uses artificial intelligence to convert images into music. It analyzes various visual elements in the image using computer vision and generates diverse musical compositions in different genres and styles. Users can upload images, select from multiple models, and quickly create music without the need to log in. The application has applications in media & entertainment, advertising & marketing, personalized gifts, therapeutic tools, education, and casual creativity.
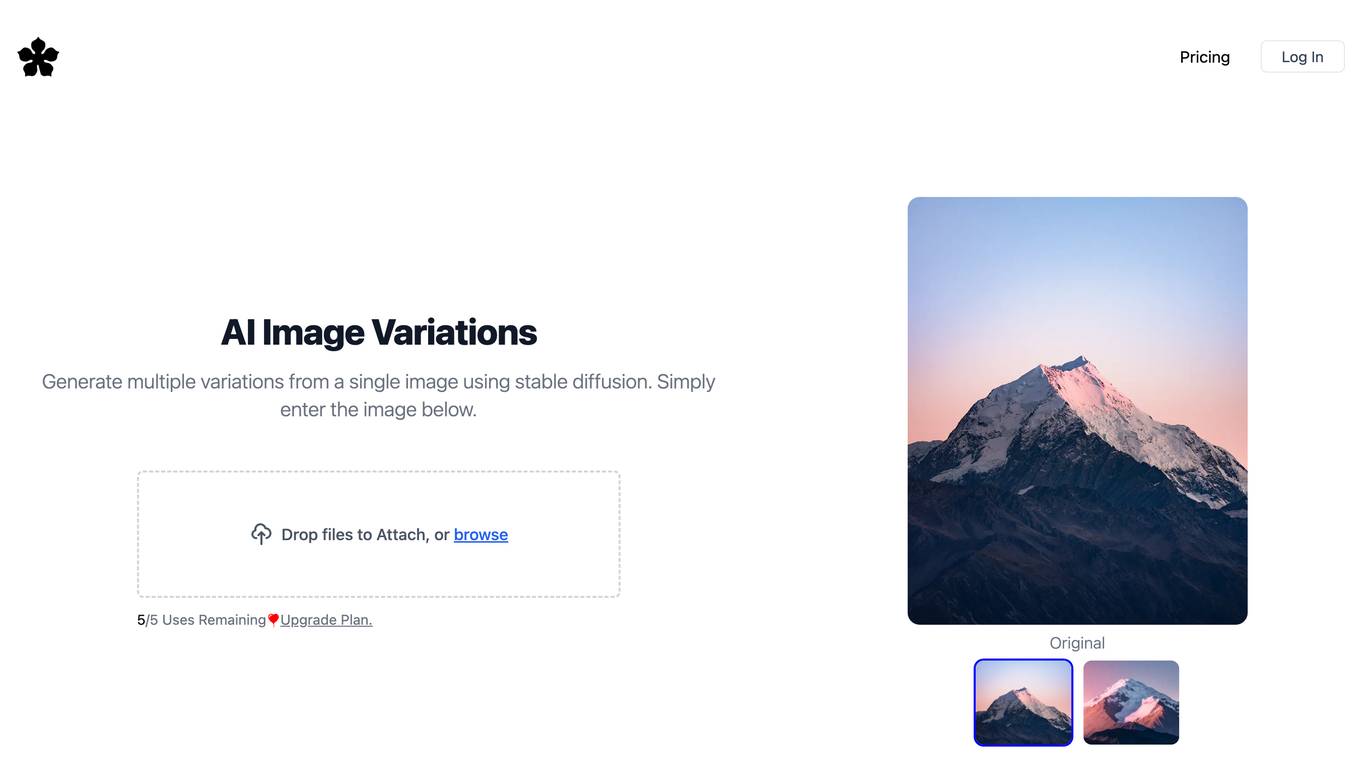
Image Variations
Image Variations (IV) is a free online tool that allows users to generate multiple variations of an image using a stable diffusion model. The tool is easy to use, simply upload an image and the tool will generate multiple variations that match the style of the original image. The generated images are copyright free and can be used for personal or commercial projects.
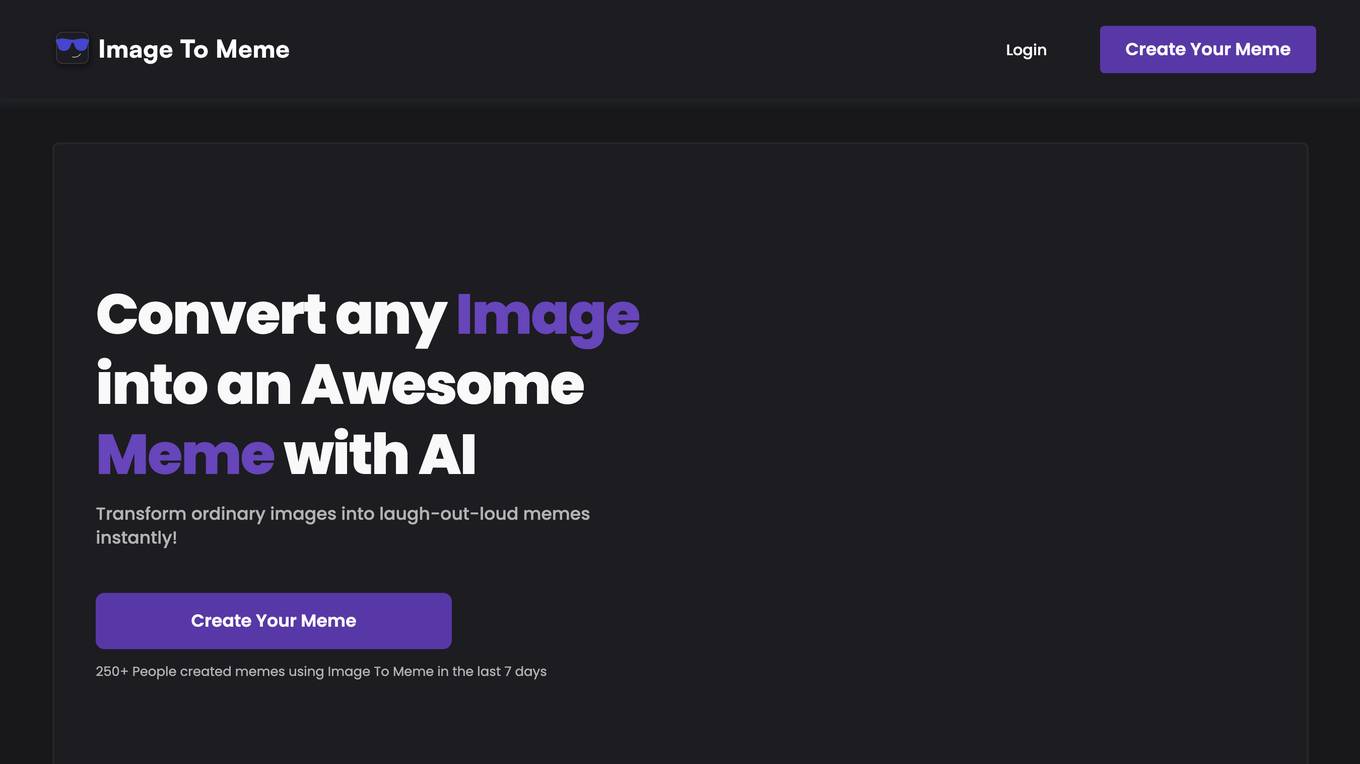
Image To Meme
Image To Meme is an online tool that allows users to convert any image into a meme. The tool uses artificial intelligence to generate memes that are both funny and relevant to the image. Image To Meme is easy to use and can be used to create memes for any occasion. The tool is free to use and offers a variety of features, including the ability to customize the text, colors, and alignment of the meme. Image To Meme is a great way to create funny and shareable memes with friends and family.
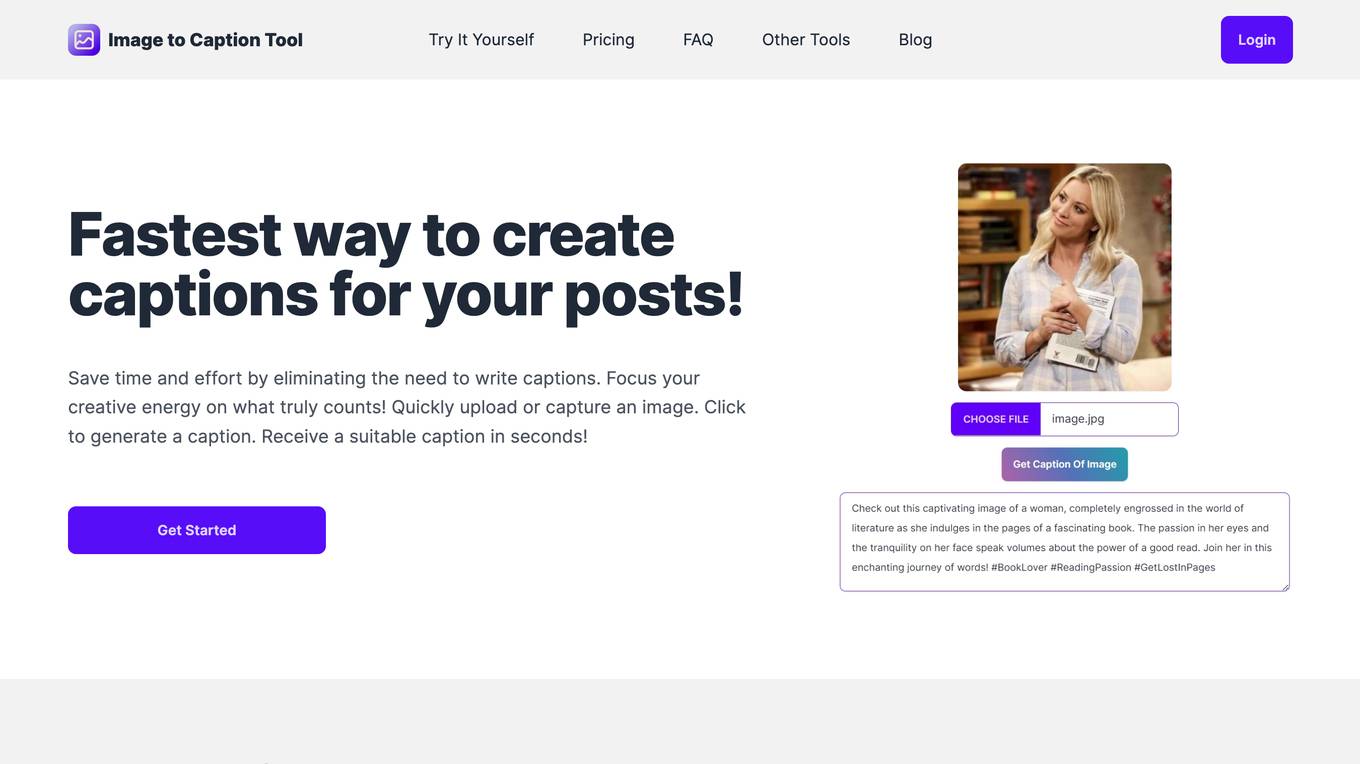
Image to Caption Tool
Image to Caption Tool is an AI-powered tool that helps you generate image captions quickly and efficiently. It's perfect for social media managers, content creators, and anyone who needs to create engaging captions for their images. With Image to Caption Tool, you can simply upload an image and click a button to generate a caption. The tool will analyze the image and generate a caption that is relevant, engaging, and shareable. You can also customize the caption to fit your specific needs.
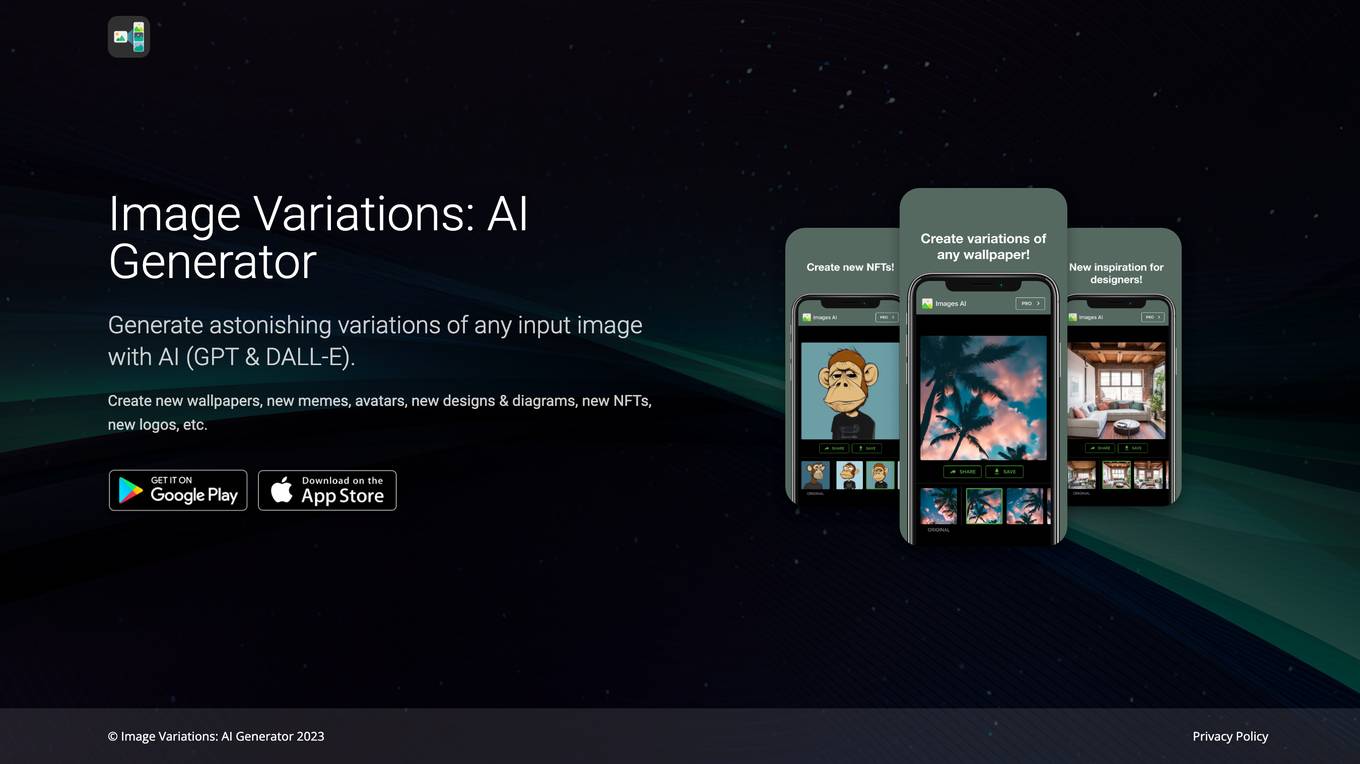
Image Variations
Image Variations is an AI-powered tool that allows you to generate variations of any input image. With just a few clicks, you can create unique and interesting variations of your photos, perfect for social media, marketing, or design projects.
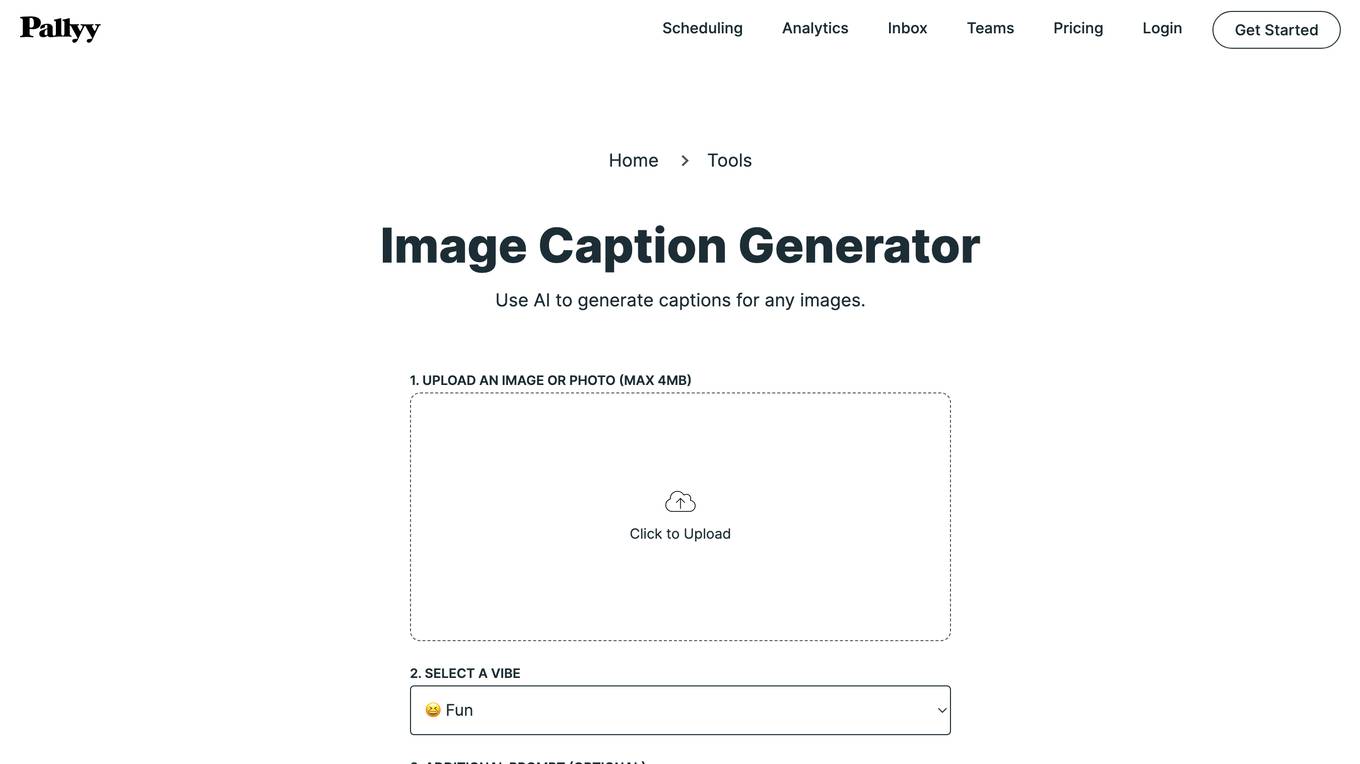
Image Caption Generator
Image Caption Generator is a free online tool that uses artificial intelligence to generate captions for any image. With this tool, you can quickly and easily create engaging and informative captions for your social media posts, website content, or any other purpose. Simply upload an image, select a vibe, and add an optional prompt. The tool will then generate a list of captions that you can use. You can also use the tool to generate image descriptions, translate emojis, convert images to text, and generate hashtags for TikTok.
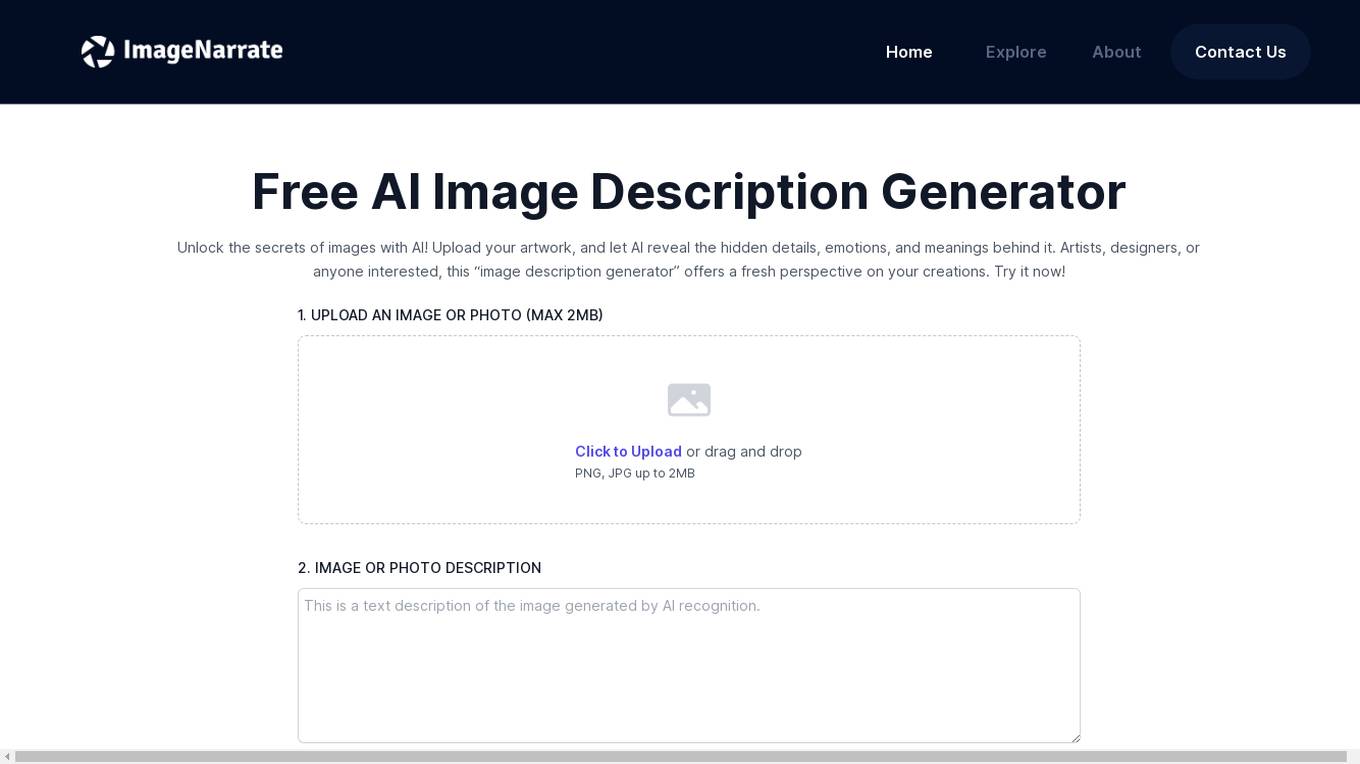
Image Narrate
This free AI image description generator tool allows users to upload an image and receive a detailed description of its contents. The tool utilizes advanced AI algorithms to analyze the image's elements, including color, shape, and texture, to generate a comprehensive description that captures the hidden meanings and emotions conveyed by the image. The tool is particularly useful for artists, designers, and anyone interested in gaining a deeper understanding of their own creations or exploring the hidden narratives within images.
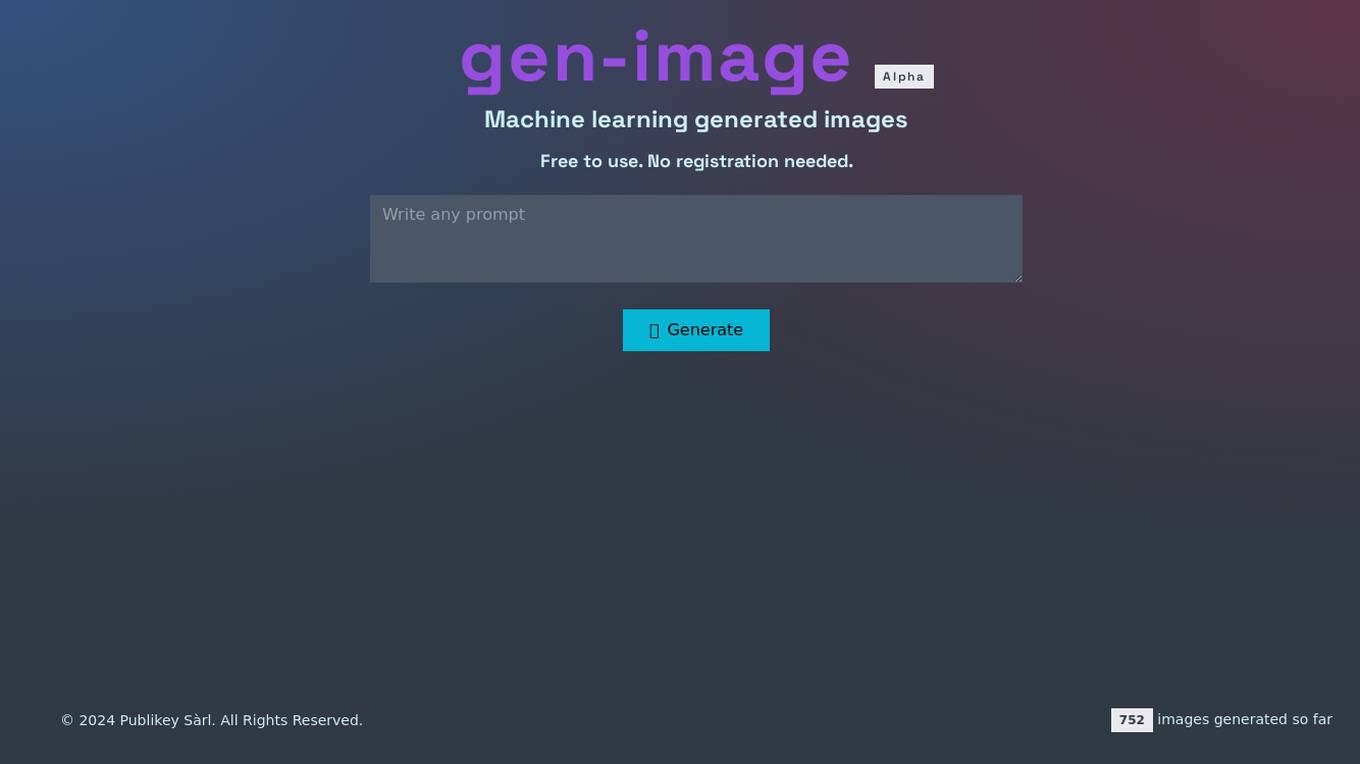
Gen-image Alpha
Gen-image Alpha is an AI-powered tool that generates images using machine learning algorithms. It allows users to create images for free without the need for registration. The tool is designed to provide high-quality generated images for various purposes. With a copyright notice of 2024 by Publikey Sàrl, users can access the tool to generate images without any limitations on the number of images created.
20 - Open Source AI Tools
awesome-generative-ai
A curated list of Generative AI projects, tools, artworks, and models

QualityScaler
QualityScaler is a Windows app powered by AI to enhance, upscale, and de-noise photographs and videos. It provides an easy-to-use GUI for upscaling images and videos using multiple AI models. The tool supports automatic image tiling and merging to avoid GPU VRAM limitations, resizing images/videos before upscaling, and interpolation between the original and upscaled content. QualityScaler is written in Python and utilizes external packages such as torch, onnxruntime-directml, customtkinter, OpenCV, moviepy, and nuitka. It requires Windows 11 or Windows 10, at least 8GB of RAM, and a Directx12 compatible GPU with 4GB VRAM or more. The tool aims to continue improving with upcoming versions by adding new features, enhancing performance, and supporting additional AI architectures.

RealScaler
RealScaler is a Windows app powered by RealESRGAN AI to enhance, upscale, and de-noise photos and videos. It provides an easy-to-use GUI for upscaling images and videos using multiple AI models. The tool supports automatic image tiling and merging to avoid GPU VRAM limitations, resizing images/videos before upscaling, interpolation between original and upscaled content, and compatibility with various image and video formats. RealScaler is written in Python and requires Windows 11/10, at least 8GB RAM, and a Directx12 compatible GPU with 4GB VRAM. Future versions aim to enhance performance, support more GPUs, offer a new GUI with Windows 11 style, include audio for upscaled videos, and provide features like metadata extraction and application from original to upscaled files.

deepdoctection
**deep** doctection is a Python library that orchestrates document extraction and document layout analysis tasks using deep learning models. It does not implement models but enables you to build pipelines using highly acknowledged libraries for object detection, OCR and selected NLP tasks and provides an integrated framework for fine-tuning, evaluating and running models. For more specific text processing tasks use one of the many other great NLP libraries. **deep** doctection focuses on applications and is made for those who want to solve real world problems related to document extraction from PDFs or scans in various image formats. **deep** doctection provides model wrappers of supported libraries for various tasks to be integrated into pipelines. Its core function does not depend on any specific deep learning library. Selected models for the following tasks are currently supported: * Document layout analysis including table recognition in Tensorflow with **Tensorpack**, or PyTorch with **Detectron2**, * OCR with support of **Tesseract**, **DocTr** (Tensorflow and PyTorch implementations available) and a wrapper to an API for a commercial solution, * Text mining for native PDFs with **pdfplumber**, * Language detection with **fastText**, * Deskewing and rotating images with **jdeskew**. * Document and token classification with all LayoutLM models provided by the **Transformer library**. (Yes, you can use any LayoutLM-model with any of the provided OCR-or pdfplumber tools straight away!). * Table detection and table structure recognition with **table-transformer**. * There is a small dataset for token classification available and a lot of new tutorials to show, how to train and evaluate this dataset using LayoutLMv1, LayoutLMv2, LayoutXLM and LayoutLMv3. * Comprehensive configuration of **analyzer** like choosing different models, output parsing, OCR selection. Check this notebook or the docs for more infos. * Document layout analysis and table recognition now runs with **Torchscript** (CPU) as well and **Detectron2** is not required anymore for basic inference. * [**new**] More angle predictors for determining the rotation of a document based on **Tesseract** and **DocTr** (not contained in the built-in Analyzer). * [**new**] Token classification with **LiLT** via **transformers**. We have added a model wrapper for token classification with LiLT and added a some LiLT models to the model catalog that seem to look promising, especially if you want to train a model on non-english data. The training script for LayoutLM can be used for LiLT as well and we will be providing a notebook on how to train a model on a custom dataset soon. **deep** doctection provides on top of that methods for pre-processing inputs to models like cropping or resizing and to post-process results, like validating duplicate outputs, relating words to detected layout segments or ordering words into contiguous text. You will get an output in JSON format that you can customize even further by yourself. Have a look at the **introduction notebook** in the notebook repo for an easy start. Check the **release notes** for recent updates. **deep** doctection or its support libraries provide pre-trained models that are in most of the cases available at the **Hugging Face Model Hub** or that will be automatically downloaded once requested. For instance, you can find pre-trained object detection models from the Tensorpack or Detectron2 framework for coarse layout analysis, table cell detection and table recognition. Training is a substantial part to get pipelines ready on some specific domain, let it be document layout analysis, document classification or NER. **deep** doctection provides training scripts for models that are based on trainers developed from the library that hosts the model code. Moreover, **deep** doctection hosts code to some well established datasets like **Publaynet** that makes it easy to experiment. It also contains mappings from widely used data formats like COCO and it has a dataset framework (akin to **datasets** so that setting up training on a custom dataset becomes very easy. **This notebook** shows you how to do this. **deep** doctection comes equipped with a framework that allows you to evaluate predictions of a single or multiple models in a pipeline against some ground truth. Check again **here** how it is done. Having set up a pipeline it takes you a few lines of code to instantiate the pipeline and after a for loop all pages will be processed through the pipeline.
stable-diffusion-webui
Stable Diffusion web UI is a web interface for Stable Diffusion, implemented using Gradio library. It provides a user-friendly interface to access the powerful image generation capabilities of Stable Diffusion. With Stable Diffusion web UI, users can easily generate images from text prompts, edit and refine images using inpainting and outpainting, and explore different artistic styles and techniques. The web UI also includes a range of advanced features such as textual inversion, hypernetworks, and embeddings, allowing users to customize and fine-tune the image generation process. Whether you're an artist, designer, or simply curious about the possibilities of AI-generated art, Stable Diffusion web UI is a valuable tool that empowers you to create stunning and unique images.
FluidFrames.RIFE
FluidFrames.RIFE is a Windows app powered by RIFE AI to create frame-generated and slowmotion videos. It is written in Python and utilizes external packages such as torch, onnxruntime-directml, customtkinter, OpenCV, moviepy, and Nuitka. The app features an elegant GUI, video frame generation at different speeds, video slow motion, video resizing, multiple GPU support, and compatibility with various video formats. Future versions aim to support different GPU types, enhance the GUI, include audio processing, optimize video processing speed, and introduce new features like saving AI-generated frames and supporting different RIFE AI models.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.


NeMo-Guardrails
NeMo Guardrails is an open-source toolkit for easily adding _programmable guardrails_ to LLM-based conversational applications. Guardrails (or "rails" for short) are specific ways of controlling the output of a large language model, such as not talking about politics, responding in a particular way to specific user requests, following a predefined dialog path, using a particular language style, extracting structured data, and more.
manga-image-translator
Translate texts in manga/images. Some manga/images will never be translated, therefore this project is born. * Image/Manga Translator * Samples * Online Demo * Disclaimer * Installation * Pip/venv * Poetry * Additional instructions for **Windows** * Docker * Hosting the web server * Using as CLI * Setting Translation Secrets * Using with Nvidia GPU * Building locally * Usage * Batch mode (default) * Demo mode * Web Mode * Api Mode * Related Projects * Docs * Recommended Modules * Tips to improve translation quality * Options * Language Code Reference * Translators Reference * GPT Config Reference * Using Gimp for rendering * Api Documentation * Synchronous mode * Asynchronous mode * Manual translation * Next steps * Support Us * Thanks To All Our Contributors :

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.
djl-demo
The Deep Java Library (DJL) is a framework-agnostic Java API for deep learning. It provides a unified interface to popular deep learning frameworks such as TensorFlow, PyTorch, and MXNet. DJL makes it easy to develop deep learning applications in Java, and it can be used for a variety of tasks, including image classification, object detection, natural language processing, and speech recognition.

emgucv
Emgu CV is a cross-platform .Net wrapper for the OpenCV image-processing library. It allows OpenCV functions to be called from .NET compatible languages. The wrapper can be compiled by Visual Studio, Unity, and "dotnet" command, and it can run on Windows, Mac OS, Linux, iOS, and Android.
Awesome-Segment-Anything
The Segment Anything Model (SAM) is a powerful tool that allows users to segment any object in an image with just a few clicks. This makes it a great tool for a variety of tasks, such as object detection, tracking, and editing. SAM is also very easy to use, making it a great option for both beginners and experienced users.

ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.
albumentations
Albumentations is a Python library for image augmentation. Image augmentation is used in deep learning and computer vision tasks to increase the quality of trained models. The purpose of image augmentation is to create new training samples from the existing data.

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.

chaiNNer
ChaiNNer is a node-based image processing GUI aimed at making chaining image processing tasks easy and customizable. It gives users a high level of control over their processing pipeline and allows them to perform complex tasks by connecting nodes together. ChaiNNer is cross-platform, supporting Windows, MacOS, and Linux. It features an intuitive drag-and-drop interface, making it easy to create and modify processing chains. Additionally, ChaiNNer offers a wide range of nodes for various image processing tasks, including upscaling, denoising, sharpening, and color correction. It also supports batch processing, allowing users to process multiple images or videos at once.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

MONAI
MONAI is a PyTorch-based, open-source framework for deep learning in healthcare imaging. It provides a comprehensive set of tools for medical image analysis, including data preprocessing, model training, and evaluation. MONAI is designed to be flexible and easy to use, making it a valuable resource for researchers and developers in the field of medical imaging.
20 - OpenAI Gpts
UpScaler
DALL-E user? Resize/de-noise images or uploads! Print & show-off your masterpiece or display in 4K! Supports 0.5x-4x to poster size. Abbreviations support. Enter your image prompt or, "m" for a menu to begin.
Identify movies, dramas, and animations by image
Just send us an image of a scene from a video work and i will guess the name of the work!

Image Generation with Selfcritique & Improvement
More accurate and easier image generation with self critique & improvement! Try it now
Easy Image Maker
Question-and-answer style image design agent, solving the problem of not knowing how to describe design parameters to GPT.
The Ultimate Image Generator
Highly optimized prompts and top secret refinements to create the perfect image every time...
Reliable Image Generator with LGTM Overlay
Efficiently generates images and overlays 'LGTM'
Image Scout
A comprehensive guide for finding themed public domain images with a vast resource list.
Consistent Image Generator
Geneate an image ➡ Request modifications. This GPT supports generating consistent and continuous images with Dalle. It also offers the ability to restore or integrate photos you upload. ✔️Where to use: Wordpress Blog Post, Youtube thumbnail, AI profile, facebook, X, threads feed, Instagram reels
Image Translator(→日本語)
画像中の文章を日本語に翻訳します。(使い方:画像をアップロードするだけ。プロンプトの文章は不要です。) 2023/12/29 より自然な日本語になるように修正
Image Theme Clone
Type “Start” and Get Exact Details on Image Generation and/or Duplication
Precision Image Authenticity Analyzer 2.0
Determines if images are AI-generated or real, and learns from feedback.