Best AI tools for< Generate Speech Parodies >
20 - AI tool Sites
Hey Commish
Hey Commish is a fantasy sports website that allows users to create personalized content for their fantasy leagues. The platform offers tools for creating matchup recaps, writing songs about players, explaining fantasy sports, and more. Users can engage in banter and competition while enhancing their fantasy football experience.
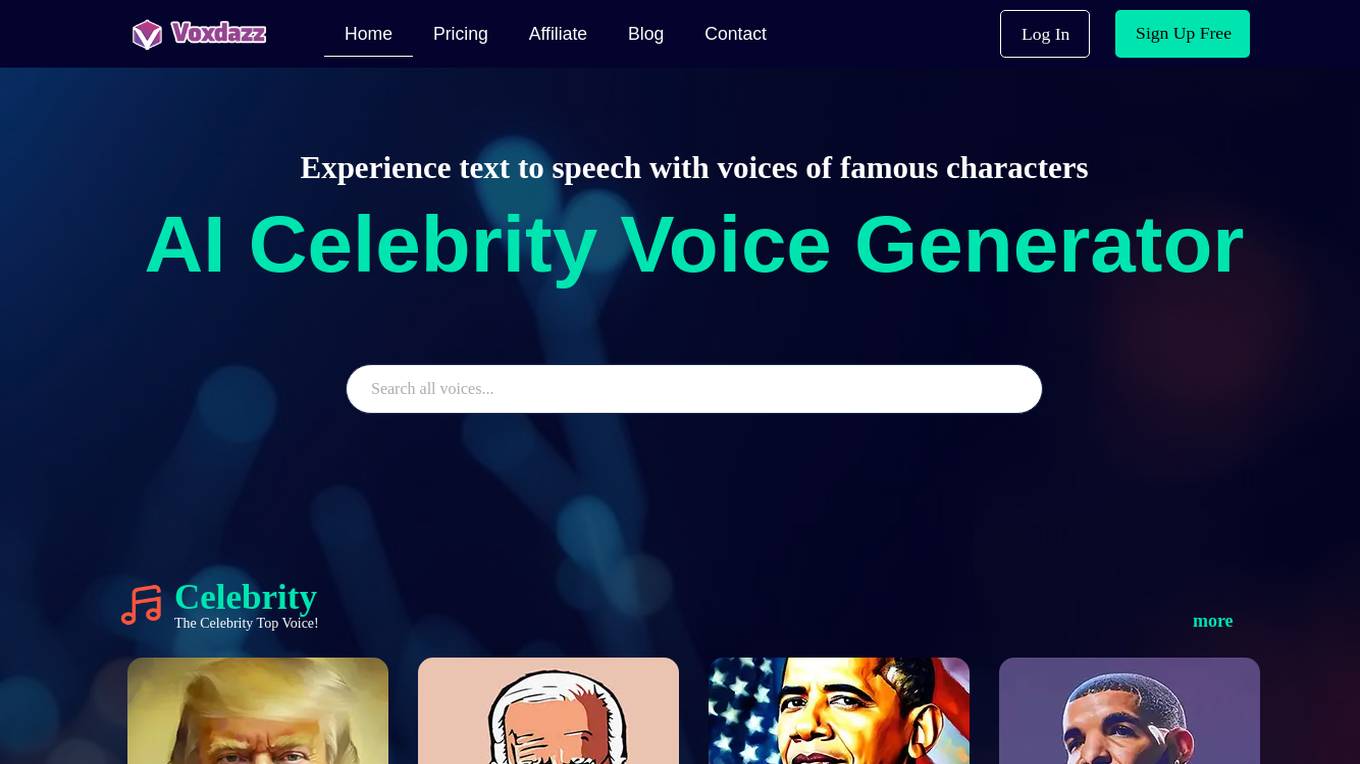
Voxdazz
Voxdazz is a celebrity AI voice generator website that allows users to select a celebrity template, input text, and generate a video with lifelike voices. With famous characters like Donald Trump, Joe Biden, and more, Voxdazz offers a fun and entertaining way to bring words to life through AI-generated voices. The service provides realistic voice cloning technology for creating humorous content, skits, and parodies with friends and family.
ChatTTS
ChatTTS is an open-source text-to-speech model designed for dialogue scenarios, supporting both English and Chinese speech generation. Trained on approximately 100,000 hours of Chinese and English data, it delivers speech quality comparable to human dialogue. The tool is particularly suitable for tasks involving large language model assistants and creating dialogue-based audio and video introductions. It provides developers with a powerful and easy-to-use tool based on open-source natural language processing and speech synthesis technologies.

Speech Studio
Speech Studio is a cloud-based speech-to-text and text-to-speech platform that enables developers to add speech capabilities to their applications. With Speech Studio, developers can easily transcribe audio and video files, generate synthetic speech, and build custom speech models. Speech Studio is a powerful tool that can be used to improve the accessibility, efficiency, and user experience of any application.
ChatTTS
ChatTTS is a natural and expressive text-to-speech tool designed for dialogue applications. It supports mixed language input and offers multi-speaker capabilities with precise control over prosodic elements like laughter, pauses, and intonation. Users can explore the unique capabilities of ChatTTS, enjoy conversational TTS optimized for dialogue-based tasks, and benefit from fine-grained control over prosodic features. The tool is multilingual, supporting both English and Chinese languages, and is open-source and customizable with pretrained models available for further research and development.
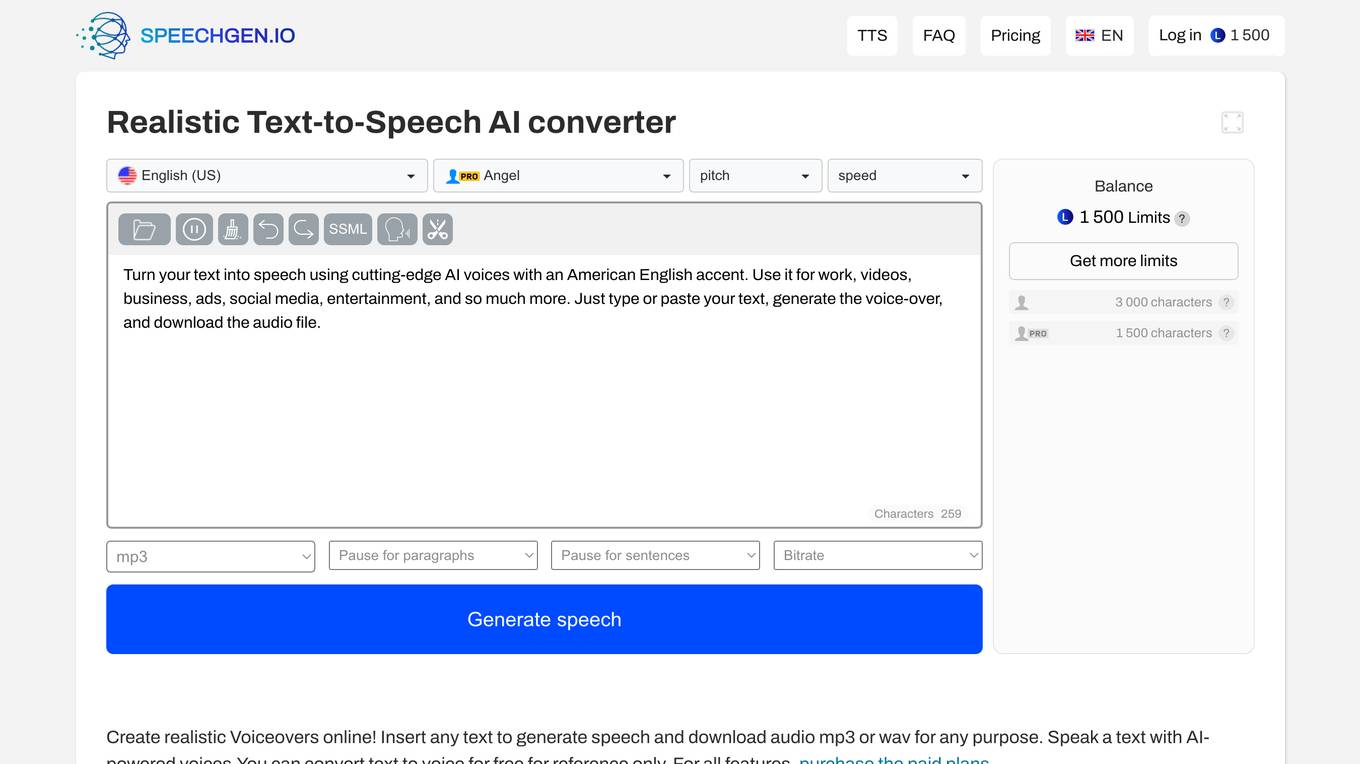
SpeechGen.io
SpeechGen.io is a realistic text-to-speech converter and AI voice generator that allows users to convert text into speech using cutting-edge AI voices with an American English accent. With SpeechGen.io, users can create realistic voiceovers for videos, e-learning materials, advertising, public announcements, podcasts, mobile apps, presentations, and more. The platform offers a wide range of features, including the ability to download converted audio files in MP3, WAV, and OGG formats, support for long texts, commercial use of generated audio, multi-voice editing, custom voice settings, SSML support, and more. SpeechGen.io is accessible in any browser and offers an intuitive interface suitable for beginners. The platform also provides powerful support and is compatible with various editing programs.
VoiceGen
VoiceGen is an AI audio platform that enables users to create realistic speech using the best technology from leading providers like OpenAI, Google, AWS, and Azure. It offers natural, high-quality voices with support for multiple languages and unrestricted commercial use. VoiceGen prioritizes simplicity, transparency, and innovation, providing an accessible and affordable solution for voice generation needs. The platform ensures security and privacy of user data, offering a pay-as-you-go pricing model with fair and transparent costs.
Deepgram
Deepgram is a powerful API platform that provides developers with tools for building speech-to-text, text-to-speech, and intelligence applications. With Deepgram, developers can easily add speech recognition, text-to-speech, and other AI-powered features to their applications.
ChatTTS
ChatTTS is a text-to-speech tool optimized for natural, conversational scenarios. It supports both Chinese and English languages, trained on approximately 100,000 hours of data. With features like multi-language support, large data training, dialog task compatibility, open-source plans, control, security, and ease of use, ChatTTS provides high-quality and natural-sounding voice synthesis. It is designed for conversational tasks, dialogue speech generation, video introductions, educational content synthesis, and more. Users can integrate ChatTTS into their applications using provided API and SDKs for a seamless text-to-speech experience.
DubSmart
DubSmart is an AI-powered platform that offers advanced video dubbing and voice cloning services. It allows users to transform text into lifelike speech, dub videos with voice cloning technology, and generate subtitles for audio or video content. With a user-friendly interface, DubSmart enables users to create unique voices, edit projects, and download finished projects in various formats. The platform supports 33 languages for AI dubbing and 60+ languages for speech-to-text conversion. DubSmart caters to small creators, YouTubers, and companies looking to enhance their audiovisual content with personalized voices and multilingual capabilities.
Synthesis
Synthesis is a web-based application that allows users to create realistic-sounding synthetic speech from text. The application uses a variety of AI techniques, including natural language processing and machine learning, to generate speech that is both natural-sounding and easy to understand. Synthesis can be used for a variety of purposes, including creating voiceovers for videos, podcasts, and presentations.

Narration Box
Narration Box is a text-to-speech tool that uses artificial intelligence to generate realistic voiceovers in over 70 languages. It offers a variety of features, including the ability to create multi-speaker content, fine-tune the voice's output, and generate speech in real-time. Narration Box is used by a variety of professionals, including authors, educators, product managers, marketing teams, founders, podcasters, content creators, media houses, and agencies.
AppTek
AppTek is a global leader in artificial intelligence (AI) and machine learning (ML) technologies for automatic speech recognition (ASR), neural machine translation (NMT), natural language processing/understanding (NLP/U) and text-to-speech (TTS) technologies. The AppTek platform delivers industry-leading solutions for organizations across a breadth of global markets such as media and entertainment, call centers, government, enterprise business, and more. Built by scientists and research engineers who are recognized among the best in the world, AppTek’s solutions cover a wide array of languages/ dialects, channels, domains and demographics.

Replicate
Replicate is an AI tool that allows users to run and fine-tune open-source models, deploy custom models at scale, and generate various types of content such as images, text, music, and speech with just one line of code. It provides a platform where users can explore and utilize thousands of production-ready AI models contributed by the community. Replicate aims to make AI accessible and practical by enabling users to push AI beyond academic papers and demos.
Replicate
Replicate is an AI tool that allows users to run and fine-tune open-source models, deploy custom models at scale, and generate images, text, videos, music, and speech with just one line of code. It provides a platform for the community to contribute and explore thousands of production-ready AI models, enabling users to push the boundaries of AI beyond academic papers and demos. With features like fine-tuning models, deploying custom models, and scaling on Replicate, users can easily create and deploy AI solutions for various tasks.
TopTools.ai
The website toptools.ai is the #1 AI Tools Directory, providing a platform for users to discover and access various AI tools and applications. Users can filter tools based on pricing models and categories such as advertising, analysis, chatbots, design, education, marketing, and more. The site offers a wide range of AI-powered tools for different purposes, from content creation and SEO optimization to mental health support and influencer marketing. Users can find tools for free, on a free trial, freemium, or paid basis, catering to diverse needs and preferences in the AI space.
Neoform AI
Neoform AI is an innovative AI tool that focuses on developing AI models specifically for African dialects. The platform aims to bridge the gap in AI technology by providing solutions tailored to the linguistic diversity of Africa. With a commitment to inclusivity and cultural representation, Neoform AI is revolutionizing the field of artificial intelligence by addressing the unique challenges faced by African languages. Through cutting-edge research and development, Neoform AI is paving the way for greater accessibility and accuracy in AI applications across the continent.
Best Man Pro
Best Man Pro is an AI-powered tool that helps users craft memorable best man speeches. With its simple three-step process, users can create a speech outline, generate three speech options to choose from, and refine their speech to perfection. The tool provides guidance and assistance throughout the process, ensuring that users can deliver a speech that is both heartfelt and polished. Best Man Pro is designed to help users overcome writer's block and create a speech that is tailored to their unique style and the occasion.
Descript
Descript is an AI-powered video and podcast editing tool that allows users to edit videos and podcasts like a document. It offers features such as easy video editing, multitrack audio editing, AI-generated clips, crystal-clear recording rooms, automatic transcription, AI speech generation, and more. Descript is designed to streamline the editing process and enhance creativity for content creators. It also provides AI features for market promotion, creating clips, YouTube descriptions, show notes, translation, and more. With Underlord AI assistant, teams can collaborate efficiently and produce high-quality videos. The platform caters to various functions like marketing, sales, learning and development, customer success, and support, making it a versatile tool for content creation.
Beepbooply
Beepbooply is a text-to-speech tool that uses artificial intelligence to generate realistic and natural-sounding speech. With over 900 voices to choose from, you can create audio content for any purpose, including videos, podcasts, and customer service. Beepbooply is easy to use and affordable, making it a great option for anyone who needs to create high-quality audio content.
20 - Open Source AI Tools

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.
speech-to-speech
This repository implements a speech-to-speech cascaded pipeline with consecutive parts including Voice Activity Detection (VAD), Speech to Text (STT), Language Model (LM), and Text to Speech (TTS). It aims to provide a fully open and modular approach by leveraging models available on the Transformers library via the Hugging Face hub. The code is designed for easy modification, with each component implemented as a class. Users can run the pipeline either on a server/client approach or locally, with detailed setup and usage instructions provided in the readme.
openai-edge-tts
This project provides a local, OpenAI-compatible text-to-speech (TTS) API using `edge-tts`. It emulates the OpenAI TTS endpoint (`/v1/audio/speech`), enabling users to generate speech from text with various voice options and playback speeds, just like the OpenAI API. `edge-tts` uses Microsoft Edge's online text-to-speech service, making it completely free. The project supports multiple audio formats, adjustable playback speed, and voice selection options, providing a flexible and customizable TTS solution for users.

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

call-gpt
Call GPT is a voice application that utilizes Deepgram for Speech to Text, elevenlabs for Text to Speech, and OpenAI for GPT prompt completion. It allows users to chat with ChatGPT on the phone, providing better transcription, understanding, and speaking capabilities than traditional IVR systems. The app returns responses with low latency, allows user interruptions, maintains chat history, and enables GPT to call external tools. It coordinates data flow between Deepgram, OpenAI, ElevenLabs, and Twilio Media Streams, enhancing voice interactions.

modelfusion
ModelFusion is an abstraction layer for integrating AI models into JavaScript and TypeScript applications, unifying the API for common operations such as text streaming, object generation, and tool usage. It provides features to support production environments, including observability hooks, logging, and automatic retries. You can use ModelFusion to build AI applications, chatbots, and agents. ModelFusion is a non-commercial open source project that is community-driven. You can use it with any supported provider. ModelFusion supports a wide range of models including text generation, image generation, vision, text-to-speech, speech-to-text, and embedding models. ModelFusion infers TypeScript types wherever possible and validates model responses. ModelFusion provides an observer framework and logging support. ModelFusion ensures seamless operation through automatic retries, throttling, and error handling mechanisms. ModelFusion is fully tree-shakeable, can be used in serverless environments, and only uses a minimal set of dependencies.

llms-tools
The 'llms-tools' repository is a comprehensive collection of AI tools, open-source projects, and research related to Large Language Models (LLMs) and Chatbots. It covers a wide range of topics such as AI in various domains, open-source models, chats & assistants, visual language models, evaluation tools, libraries, devices, income models, text-to-image, computer vision, audio & speech, code & math, games, robotics, typography, bio & med, military, climate, finance, and presentation. The repository provides valuable resources for researchers, developers, and enthusiasts interested in exploring the capabilities of LLMs and related technologies.

Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.
Linly-Talker
Linly-Talker is an innovative digital human conversation system that integrates the latest artificial intelligence technologies, including Large Language Models (LLM) 🤖, Automatic Speech Recognition (ASR) 🎙️, Text-to-Speech (TTS) 🗣️, and voice cloning technology 🎤. This system offers an interactive web interface through the Gradio platform 🌐, allowing users to upload images 📷 and engage in personalized dialogues with AI 💬.

openedai-speech
OpenedAI Speech is a free, private text-to-speech server compatible with the OpenAI audio/speech API. It offers custom voice cloning and supports various models like tts-1 and tts-1-hd. Users can map their own piper voices and create custom cloned voices. The server provides multilingual support with XTTS voices and allows fixing incorrect sounds with regex. Recent changes include bug fixes, improved error handling, and updates for multilingual support. Installation can be done via Docker or manual setup, with usage instructions provided. Custom voices can be created using Piper or Coqui XTTS v2, with guidelines for preparing audio files. The tool is suitable for tasks like generating speech from text, creating custom voices, and multilingual text-to-speech applications.

shellChatGPT
ShellChatGPT is a shell wrapper for OpenAI's ChatGPT, DALL-E, Whisper, and TTS, featuring integration with LocalAI, Ollama, Gemini, Mistral, Groq, and GitHub Models. It provides text and chat completions, vision, reasoning, and audio models, voice-in and voice-out chatting mode, text editor interface, markdown rendering support, session management, instruction prompt manager, integration with various service providers, command line completion, file picker dialogs, color scheme personalization, stdin and text file input support, and compatibility with Linux, FreeBSD, MacOS, and Termux for a responsive experience.
AI
AI is an open-source Swift framework for interfacing with generative AI. It provides functionalities for text completions, image-to-text vision, function calling, DALLE-3 image generation, audio transcription and generation, and text embeddings. The framework supports multiple AI models from providers like OpenAI, Anthropic, Mistral, Groq, and ElevenLabs. Users can easily integrate AI capabilities into their Swift projects using AI framework.

marvin
Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.
MeloTTS
MeloTTS is a high-quality multi-lingual text-to-speech library by MyShell.ai. It supports various languages including English (American, British, Indian, Australian), Spanish, French, Chinese, Japanese, and Korean. The Chinese speaker also supports mixed Chinese and English. The library is fast enough for CPU real-time inference and offers features like using without installation, local installation, and training on custom datasets. The Python API and model cards are available in the repository and on HuggingFace. The community can join the Discord channel for discussions and collaboration opportunities. Contributions are welcome, and the library is under the MIT License. MeloTTS is based on TTS, VITS, VITS2, and Bert-VITS2.
CosyVoice
CosyVoice is a tool designed for speech synthesis, offering pretrained models for zero-shot, sft, instruct inference. It provides a web demo for easy usage and supports advanced users with train and inference scripts. The tool can be deployed using grpc for service deployment. Users can download pretrained models and resources for immediate use or train their own models from scratch. CosyVoice is suitable for researchers, developers, linguists, AI engineers, and speech technology enthusiasts.

HebTTS
HebTTS is a language modeling approach to diacritic-free Hebrew text-to-speech (TTS) system. It addresses the challenge of accurately mapping text to speech in Hebrew by proposing a language model that operates on discrete speech representations and is conditioned on a word-piece tokenizer. The system is optimized using weakly supervised recordings and outperforms diacritic-based Hebrew TTS systems in terms of content preservation and naturalness of generated speech.
LLM-Codec
This repository provides an LLM-driven audio codec model, LLM-Codec, for building multi-modal LLMs (text and audio modalities). The model enables frozen LLMs to achieve multiple audio tasks in a few-shot style without parameter updates. It compresses the audio modality into a well-trained LLMs token space, treating audio representation as a 'foreign language' that LLMs can learn with minimal examples. The proposed approach supports tasks like speech emotion classification, audio classification, text-to-speech generation, speech enhancement, etc., demonstrating feasibility and effectiveness in simple scenarios. The LLM-Codec model is open-sourced to facilitate research on few-shot audio task learning and multi-modal LLMs.
20 - OpenAI Gpts
Speech Parody
Create speech transcript parodies. Copyright (C) 2023, Sourceduty - All Rights Reserved.
AI Speech Guide
A helpful coach for speech writing, offering constructive advice and support
SpeechGPT User Guide
A guide for using SpeechGPT, focusing on its features, setup, and usage.
Book to Prompt
Turn Any Book into Actionable Prompts. 1. Upload the PDF of a book 2. Tell your goal to be turned into a prompt
Video GPT
AI Video Maker. Generate videos for social media - YouTube, Instagram, TikTok and more! Free text to video & speech tool with AI Avatars, TTS, music, and stock footage.

Chat with GPT 4o ("Omni") Assistant
Try the new AI chat model: GPT 4o ("Omni") Assistant. It's faster and better than regular GPT. Plus it will incorporate speech-to-text, intelligence, and speech-to-text capabilities with extra low latency.

Visionary Quotations And Context
Thought-provoking quotes relate to visionary thinking, human-AI collaboration, and Doughnut Economics. Fostering a sustainable and equitable future for all.
GPTrump
the best, the greatest replies from honestly one of the best leaders the world has ever seen