Best AI tools for< Evaluate Understanding >
20 - AI tool Sites
ClassPoint
ClassPoint is an AI quiz generator tool integrated with PowerPoint that allows users to effortlessly create engaging quiz questions from their presentation slides. The tool leverages AI technology to analyze slide content and generate various quiz types, such as Multiple Choice, Short Answer, and Fill in the Blanks. With multi-language support powered by OpenAI, ClassPoint caters to diverse user needs, enabling educators to captivate students and evaluate their understanding through interactive quizzes. The tool also enhances questioning strategies by incorporating Bloom's Taxonomy levels, fostering critical thinking and creativity in quizzes. ClassPoint's AI feature simplifies quiz creation, live response collection, and grading, making teaching more interactive and efficient.
AI Interviewer Pro
AI Interviewer Pro is an AI-driven interviewing platform that helps businesses streamline their hiring process. With AI Interviewer Pro, businesses can automate the interview process, reduce bias, and make more informed hiring decisions. AI Interviewer Pro uses AI to assess candidates' skills, personality, and fit for a given role. The platform also provides businesses with insights into candidates' strengths and weaknesses, which can help them make better hiring decisions. AI Interviewer Pro is easy to use and integrates with most job application pages. Businesses can get started with AI Interviewer Pro for free and there are no long-term contracts.
Compassionate AI
Compassionate AI is a cutting-edge AI-powered platform that empowers individuals and organizations to create and deploy AI solutions that are ethical, responsible, and aligned with human values. With Compassionate AI, users can access a comprehensive suite of tools and resources to design, develop, and implement AI systems that prioritize fairness, transparency, and accountability.
InstantPersonas
InstantPersonas is an AI-powered SWOT Analysis Generator that helps organizations and individuals evaluate their Strengths, Weaknesses, Opportunities, and Threats. By using a company description, the tool generates a comprehensive SWOT Analysis, providing insights for strategic planning and decision-making. InstantPersonas aims to assist users in understanding their target audience and market more successfully, enabling them to develop strategies to leverage strengths, address weaknesses, seize opportunities, and mitigate threats.
LlamaIndex
LlamaIndex is a framework for building context-augmented Large Language Model (LLM) applications. It provides tools to ingest and process data, implement complex query workflows, and build applications like question-answering chatbots, document understanding systems, and autonomous agents. LlamaIndex enables context augmentation by combining LLMs with private or domain-specific data, offering tools for data connectors, data indexes, engines for natural language access, chat engines, agents, and observability/evaluation integrations. It caters to users of all levels, from beginners to advanced developers, and is available in Python and Typescript.
Inductor
Inductor is a developer tool for evaluating, ensuring, and improving the quality of your LLM applications – both during development and in production. It provides a fantastic workflow for continuous testing and evaluation as you develop, so that you always know your LLM app’s quality. Systematically improve quality and cost-effectiveness by actionably understanding your LLM app’s behavior and quickly testing different app variants. Rigorously assess your LLM app’s behavior before you deploy, in order to ensure quality and cost-effectiveness when you’re live. Easily monitor your live traffic: detect and resolve issues, analyze usage in order to improve, and seamlessly feed back into your development process. Inductor makes it easy for engineering and other roles to collaborate: get critical human feedback from non-engineering stakeholders (e.g., PM, UX, or subject matter experts) to ensure that your LLM app is user-ready.
Web3 Summary
Web3 Summary is an AI-powered platform that simplifies on-chain research across multiple chains and protocols, helping users find trading alpha in the DeFi and NFT space. It offers a range of products including a trading terminal, wallet study tool, Discord bot, mobile app, and Chrome extension. The platform aims to streamline the process of understanding complex crypto projects and tokenomics using AI and ChatGPT technology.
MeDA School
MeDA School is an educational platform dedicated to promoting and nurturing talents in the field of Medical Artificial Intelligence (AI). The platform aims to establish a solid foundation for intelligent and precision medical talent pools in Taiwan and globally. MeDA School facilitates interaction and communication among members of the intelligent medical ecosystem, fostering deep understanding and trust in the operation and tasks of medical AI. The platform offers a blend of virtual and physical courses, inviting domain experts to share cutting-edge knowledge and integrating interdisciplinary knowledge to be practically applied in various fields.
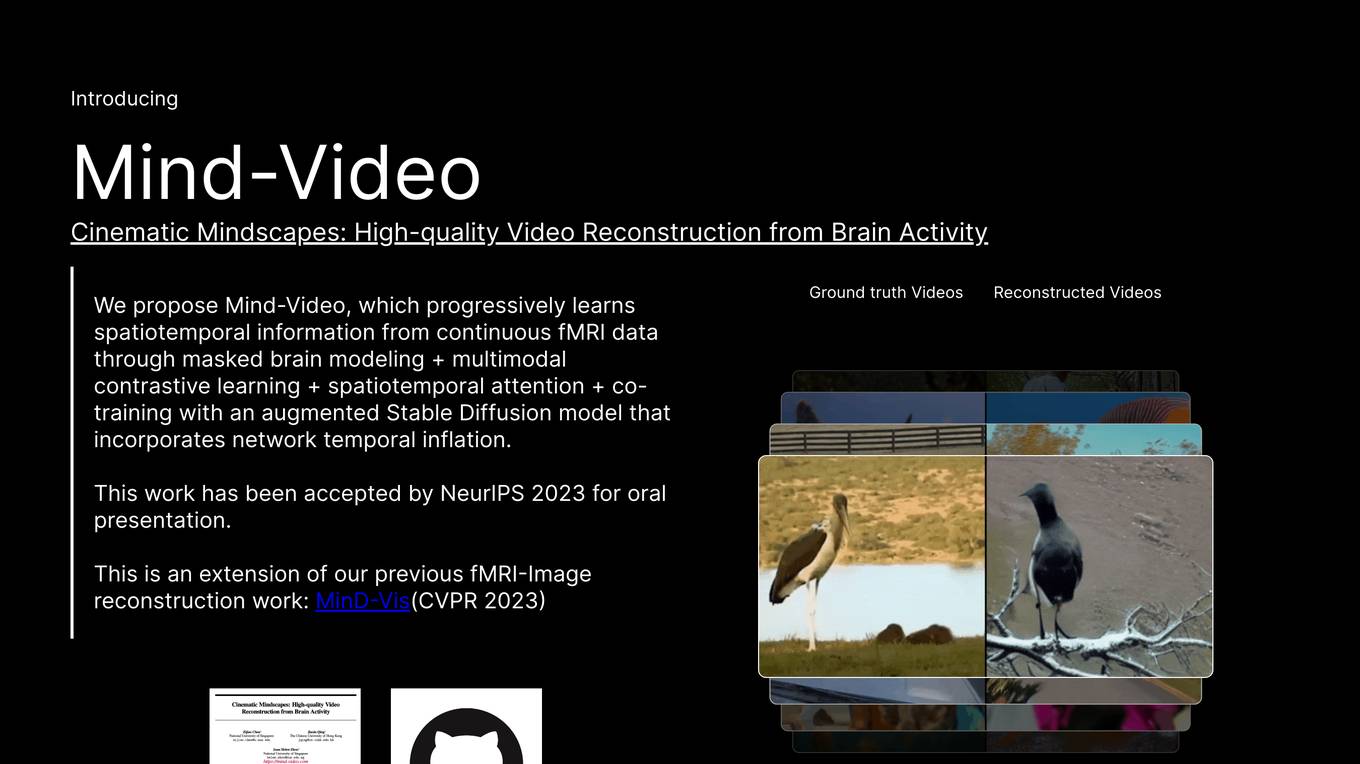
Mind-Video
Mind-Video is an AI tool that focuses on high-quality video reconstruction from brain activity data obtained through fMRI scans. The tool aims to bridge the gap between image and video brain decoding by leveraging masked brain modeling, multimodal contrastive learning, spatiotemporal attention, and co-training with an augmented Stable Diffusion model. It is designed to enhance the generation consistency and accuracy of reconstructing continuous visual experiences from brain activities, ultimately contributing to a deeper understanding of human cognitive processes.
PlaymakerAI
PlaymakerAI is an AI-powered platform that provides football analytics and scouting services to football clubs, agents, media companies, betting companies, researchers, and educators. The platform offers access to AI-evaluated football data from hundreds of leagues worldwide, individual player reports, analytics and scouting services, media insights, and a Playmaker Personality Profile for deeper understanding of squad dynamics. PlaymakerAI revolutionizes the way football organizations operate by offering clear, insightful information and expert assistance in football analytics and scouting.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.

RebeccAi
RebeccAi is an AI-powered business idea evaluation and validation tool that uses AI technology to provide accurate insights into the potential of users' ideas. It helps users refine and improve their ideas quickly and intelligently, serving as a one-person team for business dreamers. The platform assists in turning ideas into reality, from business concepts to creative projects, by leveraging the latest AI tools and technologies to innovate faster and smarter.
FindOurView
FindOurView is an AI-powered Discovery Insight Platform that provides instant discovery synthesis for teams. The platform reads interview transcripts, evaluates hypotheses, and facilitates discussions within teams. It enables users to evaluate hypotheses without the need for tags, extract relevant quotes, and make data-driven decisions. FindOurView aims to empower users with the collective intelligence of humans and AI to drive empathic conversations and confident decisions.

Codei
Codei is an AI-powered platform designed to help individuals land their dream software engineering job. It offers features such as application tracking, question generation, and code evaluation to assist users in honing their technical skills and preparing for interviews. Codei aims to provide personalized support and insights to help users succeed in the tech industry.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.
20 - Open Source AI Tools
MMLU-Pro
MMLU-Pro is an enhanced benchmark designed to evaluate language understanding models across broader and more challenging tasks. It integrates more challenging, reasoning-focused questions and increases answer choices per question, significantly raising difficulty. The dataset comprises over 12,000 questions from academic exams and textbooks across 14 diverse domains. Experimental results show a significant drop in accuracy compared to the original MMLU, with greater stability under varying prompts. Models utilizing Chain of Thought reasoning achieved better performance on MMLU-Pro.
AIStudyAssistant
AI Study Assistant is an app designed to enhance learning experience and boost academic performance. It serves as a personal tutor, lecture summarizer, writer, and question generator powered by Google PaLM 2. Features include interacting with an AI chatbot, summarizing lectures, generating essays, and creating practice questions. The app is built using 100% Kotlin, Jetpack Compose, Clean Architecture, and MVVM design pattern, with technologies like Ktor, Room DB, Hilt, and Kotlin coroutines. AI Study Assistant aims to provide comprehensive AI-powered assistance for students in various academic tasks.

eval-dev-quality
DevQualityEval is an evaluation benchmark and framework designed to compare and improve the quality of code generation of Language Model Models (LLMs). It provides developers with a standardized benchmark to enhance real-world usage in software development and offers users metrics and comparisons to assess the usefulness of LLMs for their tasks. The tool evaluates LLMs' performance in solving software development tasks and measures the quality of their results through a point-based system. Users can run specific tasks, such as test generation, across different programming languages to evaluate LLMs' language understanding and code generation capabilities.

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.
TurtleBenchmark
Turtle Benchmark is a novel and cheat-proof benchmark test used to evaluate large language models (LLMs). It is based on the Turtle Soup game, focusing on logical reasoning and context understanding abilities. The benchmark does not require background knowledge or model memory, providing all necessary information for judgment from stories under 200 words. The results are objective and unbiased, quantifiable as correct/incorrect/unknown, and impossible to cheat due to using real user-generated questions and dynamic data generation during online gameplay.
LLM-RGB
LLM-RGB is a repository containing a collection of detailed test cases designed to evaluate the reasoning and generation capabilities of Language Learning Models (LLMs) in complex scenarios. The benchmark assesses LLMs' performance in understanding context, complying with instructions, and handling challenges like long context lengths, multi-step reasoning, and specific response formats. Each test case evaluates an LLM's output based on context length difficulty, reasoning depth difficulty, and instruction compliance difficulty, with a final score calculated for each test case. The repository provides a score table, evaluation details, and quick start guide for running evaluations using promptfoo testing tools.

raga-llm-hub
Raga LLM Hub is a comprehensive evaluation toolkit for Language and Learning Models (LLMs) with over 100 meticulously designed metrics. It allows developers and organizations to evaluate and compare LLMs effectively, establishing guardrails for LLMs and Retrieval Augmented Generation (RAG) applications. The platform assesses aspects like Relevance & Understanding, Content Quality, Hallucination, Safety & Bias, Context Relevance, Guardrails, and Vulnerability scanning, along with Metric-Based Tests for quantitative analysis. It helps teams identify and fix issues throughout the LLM lifecycle, revolutionizing reliability and trustworthiness.
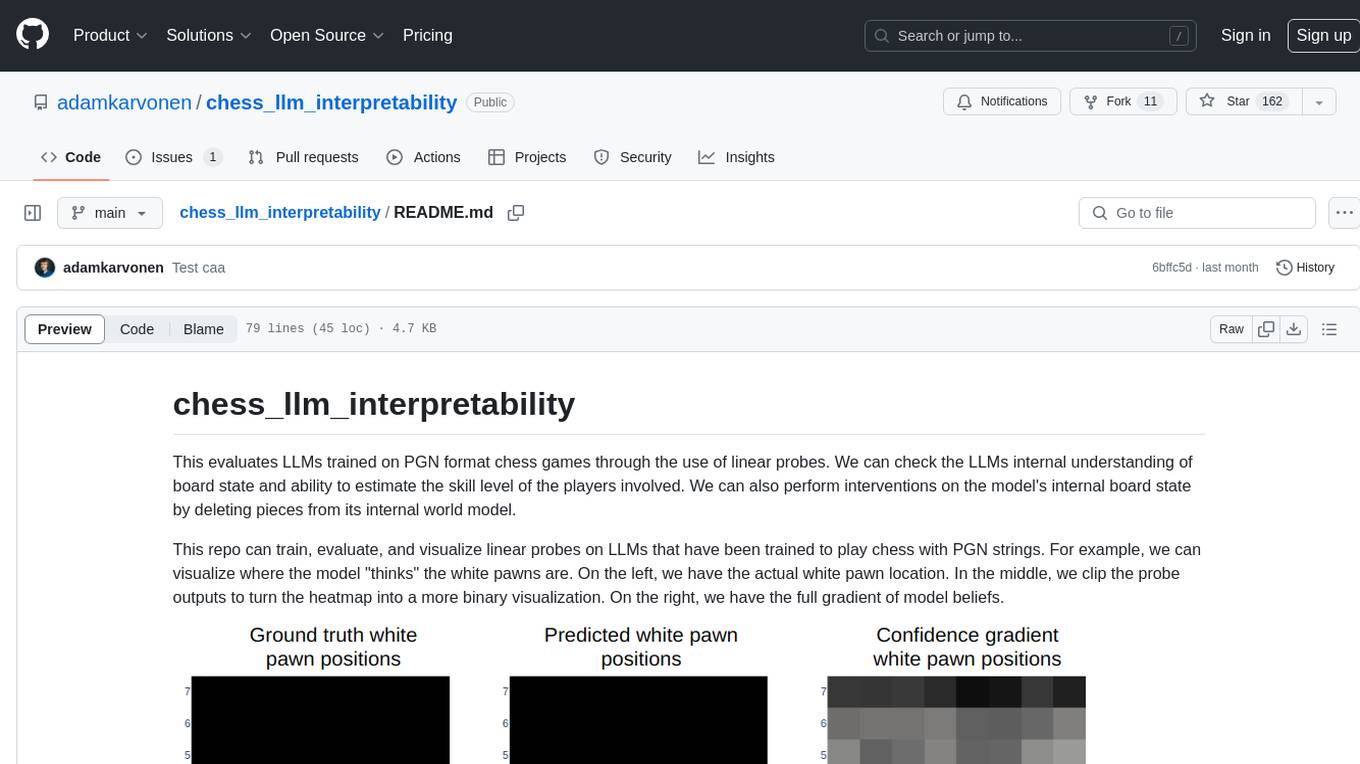
chess_llm_interpretability
This repository evaluates Large Language Models (LLMs) trained on PGN format chess games using linear probes. It assesses the LLMs' internal understanding of board state and their ability to estimate player skill levels. The repo provides tools to train, evaluate, and visualize linear probes on LLMs trained to play chess with PGN strings. Users can visualize the model's predictions, perform interventions on the model's internal board state, and analyze board state and player skill level accuracy across different LLMs. The experiments in the repo can be conducted with less than 1 GB of VRAM, and training probes on the 8 layer model takes about 10 minutes on an RTX 3050. The repo also includes scripts for performing board state interventions and skill interventions, along with useful links to open-source code, models, datasets, and pretrained models.
moai
moai is a PyTorch-based AI Model Development Kit (MDK) designed to improve data-driven model workflows, design, and understanding. It offers modularity via monads for model building blocks, reproducibility via configuration-based design, productivity via a data-driven domain modelling language (DML), extensibility via plugins, and understanding via inter-model performance and design aggregation. The tool provides specific integrated actions like play, train, evaluate, plot, diff, and reprod to support heavy data-driven workflows with analytics, knowledge extraction, and reproduction. moai relies on PyTorch, Lightning, Hydra, TorchServe, ONNX, Visdom, HiPlot, Kornia, Albumentations, and the wider open-source community for its functionalities.

Awesome-LLM-Watermark
This repository contains a collection of research papers related to watermarking techniques for text and images, specifically focusing on large language models (LLMs). The papers cover various aspects of watermarking LLM-generated content, including robustness, statistical understanding, topic-based watermarks, quality-detection trade-offs, dual watermarks, watermark collision, and more. Researchers have explored different methods and frameworks for watermarking LLMs to protect intellectual property, detect machine-generated text, improve generation quality, and evaluate watermarking techniques. The repository serves as a valuable resource for those interested in the field of watermarking for LLMs.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.

MMMU
MMMU is a benchmark designed to evaluate multimodal models on college-level subject knowledge tasks, covering 30 subjects and 183 subfields with 11.5K questions. It focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. The evaluation of various models highlights substantial challenges, with room for improvement to stimulate the community towards expert artificial general intelligence (AGI).
llm_benchmarks
llm_benchmarks is a collection of benchmarks and datasets for evaluating Large Language Models (LLMs). It includes various tasks and datasets to assess LLMs' knowledge, reasoning, language understanding, and conversational abilities. The repository aims to provide comprehensive evaluation resources for LLMs across different domains and applications, such as education, healthcare, content moderation, coding, and conversational AI. Researchers and developers can leverage these benchmarks to test and improve the performance of LLMs in various real-world scenarios.
Awesome-LLM-in-Social-Science
This repository compiles a list of academic papers that evaluate, align, simulate, and provide surveys or perspectives on the use of Large Language Models (LLMs) in the field of Social Science. The papers cover various aspects of LLM research, including assessing their alignment with human values, evaluating their capabilities in tasks such as opinion formation and moral reasoning, and exploring their potential for simulating social interactions and addressing issues in diverse fields of Social Science. The repository aims to provide a comprehensive resource for researchers and practitioners interested in the intersection of LLMs and Social Science.
ByteMLPerf
ByteMLPerf is an AI Accelerator Benchmark that focuses on evaluating AI Accelerators from a practical production perspective, including the ease of use and versatility of software and hardware. Byte MLPerf has the following characteristics: - Models and runtime environments are more closely aligned with practical business use cases. - For ASIC hardware evaluation, besides evaluate performance and accuracy, it also measure metrics like compiler usability and coverage. - Performance and accuracy results obtained from testing on the open Model Zoo serve as reference metrics for evaluating ASIC hardware integration.
LLMEvaluation
The LLMEvaluation repository is a comprehensive compendium of evaluation methods for Large Language Models (LLMs) and LLM-based systems. It aims to assist academics and industry professionals in creating effective evaluation suites tailored to their specific needs by reviewing industry practices for assessing LLMs and their applications. The repository covers a wide range of evaluation techniques, benchmarks, and studies related to LLMs, including areas such as embeddings, question answering, multi-turn dialogues, reasoning, multi-lingual tasks, ethical AI, biases, safe AI, code generation, summarization, software performance, agent LLM architectures, long text generation, graph understanding, and various unclassified tasks. It also includes evaluations for LLM systems in conversational systems, copilots, search and recommendation engines, task utility, and verticals like healthcare, law, science, financial, and others. The repository provides a wealth of resources for evaluating and understanding the capabilities of LLMs in different domains.
AlignBench
AlignBench is the first comprehensive evaluation benchmark for assessing the alignment level of Chinese large models across multiple dimensions. It includes introduction information, data, and code related to AlignBench. The benchmark aims to evaluate the alignment performance of Chinese large language models through a multi-dimensional and rule-calibrated evaluation method, enhancing reliability and interpretability.

babilong
BABILong is a generative benchmark designed to evaluate the performance of NLP models in processing long documents with distributed facts. It consists of 20 tasks that simulate interactions between characters and objects in various locations, requiring models to distinguish important information from irrelevant details. The tasks vary in complexity and reasoning aspects, with test samples potentially containing millions of tokens. The benchmark aims to challenge and assess the capabilities of Large Language Models (LLMs) in handling complex, long-context information.
do-not-answer
Do-Not-Answer is an open-source dataset curated to evaluate Large Language Models' safety mechanisms at a low cost. It consists of prompts to which responsible language models do not answer. The dataset includes human annotations and model-based evaluation using a fine-tuned BERT-like evaluator. The dataset covers 61 specific harms and collects 939 instructions across five risk areas and 12 harm types. Response assessment is done for six models, categorizing responses into harmfulness and action categories. Both human and automatic evaluations show the safety of models across different risk areas. The dataset also includes a Chinese version with 1,014 questions for evaluating Chinese LLMs' risk perception and sensitivity to specific words and phrases.
20 - OpenAI Gpts
Design Crit
I conduct design critiques focused on enhancing understanding and improvement.

FinWiz
FinWiz-GPT is designed for finance professionals. It assists in market analysis, financial modeling, and understanding complex financial instruments. It's a great tool for financial analysts, investment bankers, and accountants.

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model


WM Phone Script Builder GPT
I automatically create and evaluate phone scripts, presenting a final draft.

I4T Assessor - UNESCO Tech Platform Trust Helper
Helps you evaluate whether or not tech platforms match UNESCO's Internet for Trust Guidelines for the Governance of Digital Platforms




Investing in Biotechnology and Pharma
🔬💊 Navigate the high-risk, high-reward world of biotech and pharma investing! Discover breakthrough therapies 🧬📈, understand drug development 🧪📊, and evaluate investment opportunities 🚀💰. Invest wisely in innovation! 💡🌐 Not a financial advisor. 🚫💼

B2B Startup Ideal Customer Co-pilot
Guides B2B startups in a structured customer segment evaluation process. Stop guessing! Ideate, Evaluate & Make data-driven decision.

Education AI Strategist
I provide a structured way of using AI to support teaching and learning. I use the the CHOICE method (i.e., Clarify, Harness, Originate, Iterate, Communicate, Evaluate) to ensure that your use of AI can help you meet your educational goals.

Competitive Defensibility Analyzer
Evaluates your long-term market position based on value offered and uniqueness against competitors.

Vorstellungsgespräch Simulator Bewerbung Training
Wertet Lebenslauf und Stellenanzeige aus und simuliert ein Vorstellungsgespräch mit anschließender Auswertung: Lebenslauf und Anzeige einfach hochladen und starten.