Best AI tools for< Evaluate Neighborhood >
20 - AI tool Sites
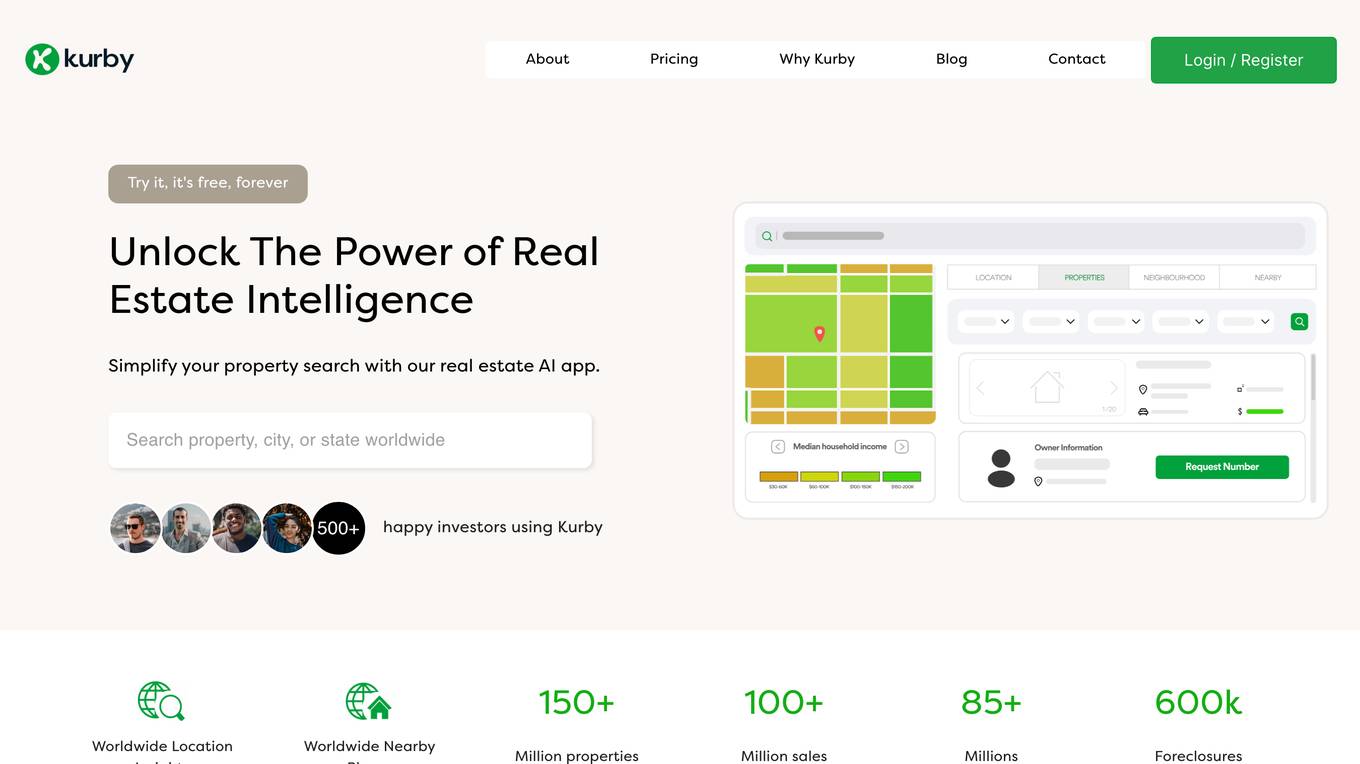
Kurby
Kurby is a real estate AI platform that leverages GPT-4 technology to provide comprehensive location insights for homebuyers and investors. It offers powerful property insights, personalized recommendations, and deep dives into neighborhood statistics, revolutionizing the real estate industry with its data-driven approach. Kurby combines AI insights with real-time market data to ensure accurate and up-to-date information for users worldwide.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.

RebeccAi
RebeccAi is an AI-powered business idea evaluation and validation tool that uses AI technology to provide accurate insights into the potential of users' ideas. It helps users refine and improve their ideas quickly and intelligently, serving as a one-person team for business dreamers. The platform assists in turning ideas into reality, from business concepts to creative projects, by leveraging the latest AI tools and technologies to innovate faster and smarter.

Codei
Codei is an AI-powered platform designed to help individuals land their dream software engineering job. It offers features such as application tracking, question generation, and code evaluation to assist users in honing their technical skills and preparing for interviews. Codei aims to provide personalized support and insights to help users succeed in the tech industry.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.
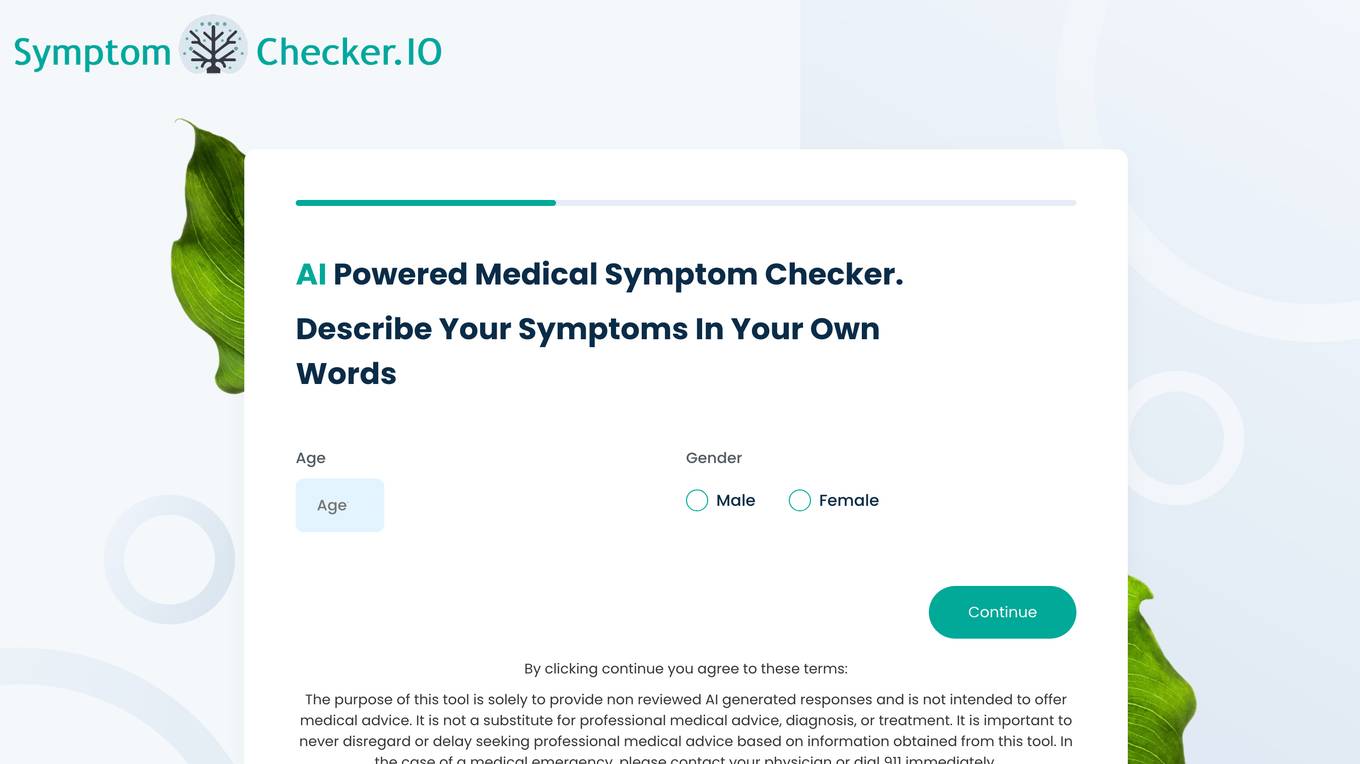
SymptomChecker.io
SymptomChecker.io is an AI-powered medical symptom checker that allows users to describe their symptoms in their own words and receive non-reviewed AI-generated responses. It is important to note that this tool is not intended to offer medical advice, diagnosis, or treatment and should not be used as a substitute for professional medical advice. In the case of a medical emergency, please contact your physician or dial 911 immediately.
ELSA
ELSA is an AI-powered English speaking coach that helps you improve your pronunciation, fluency, and confidence. With ELSA, you can practice speaking English in short, fun dialogues and get instant feedback from our proprietary artificial intelligence technology. ELSA also offers a variety of other features, such as personalized lesson plans, progress tracking, and games to help you stay motivated.
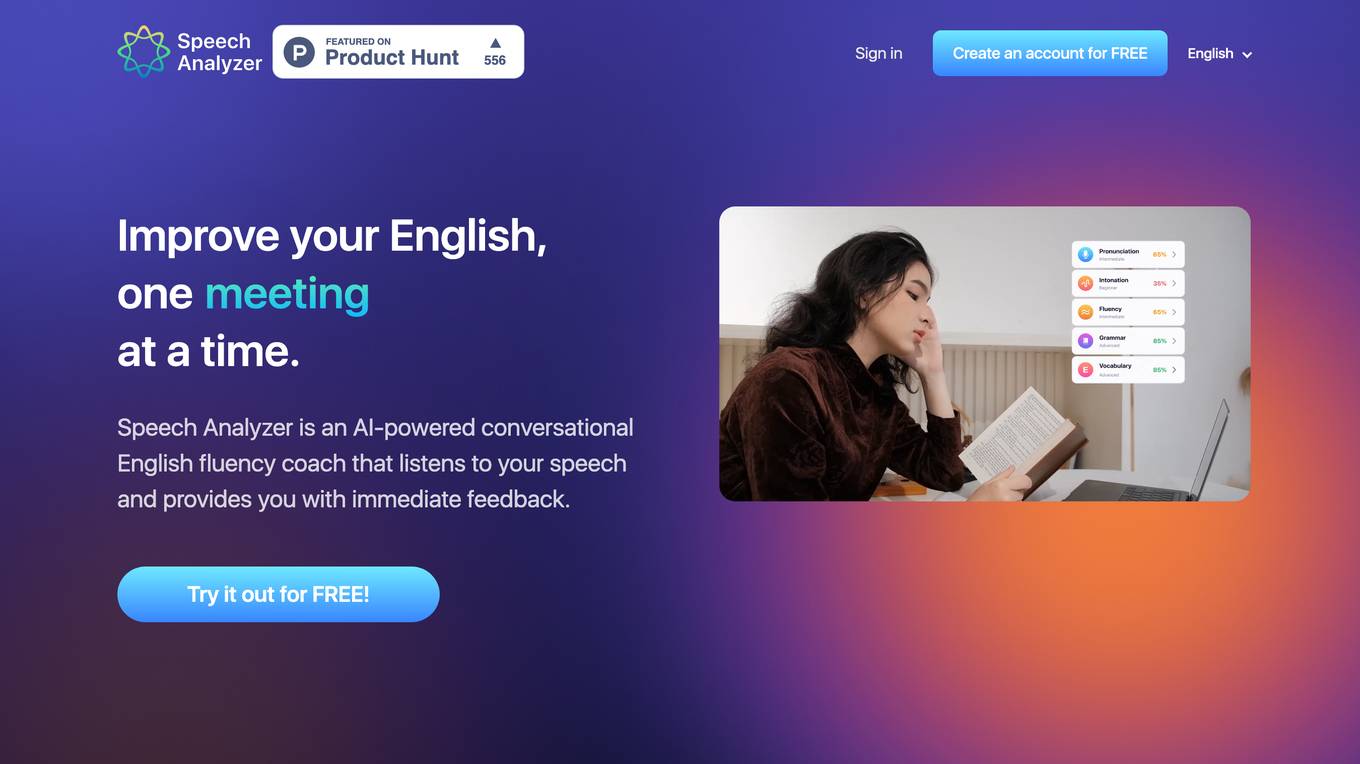
ELSA Speech Analyzer
ELSA Speech Analyzer is an AI-powered conversational English fluency coach that provides instant, personalized feedback on speech. It helps users improve pronunciation, intonation, fluency, grammar, and vocabulary through real-time analysis. The tool caters to individuals, professionals, students, and organizations seeking to enhance their English communication skills.
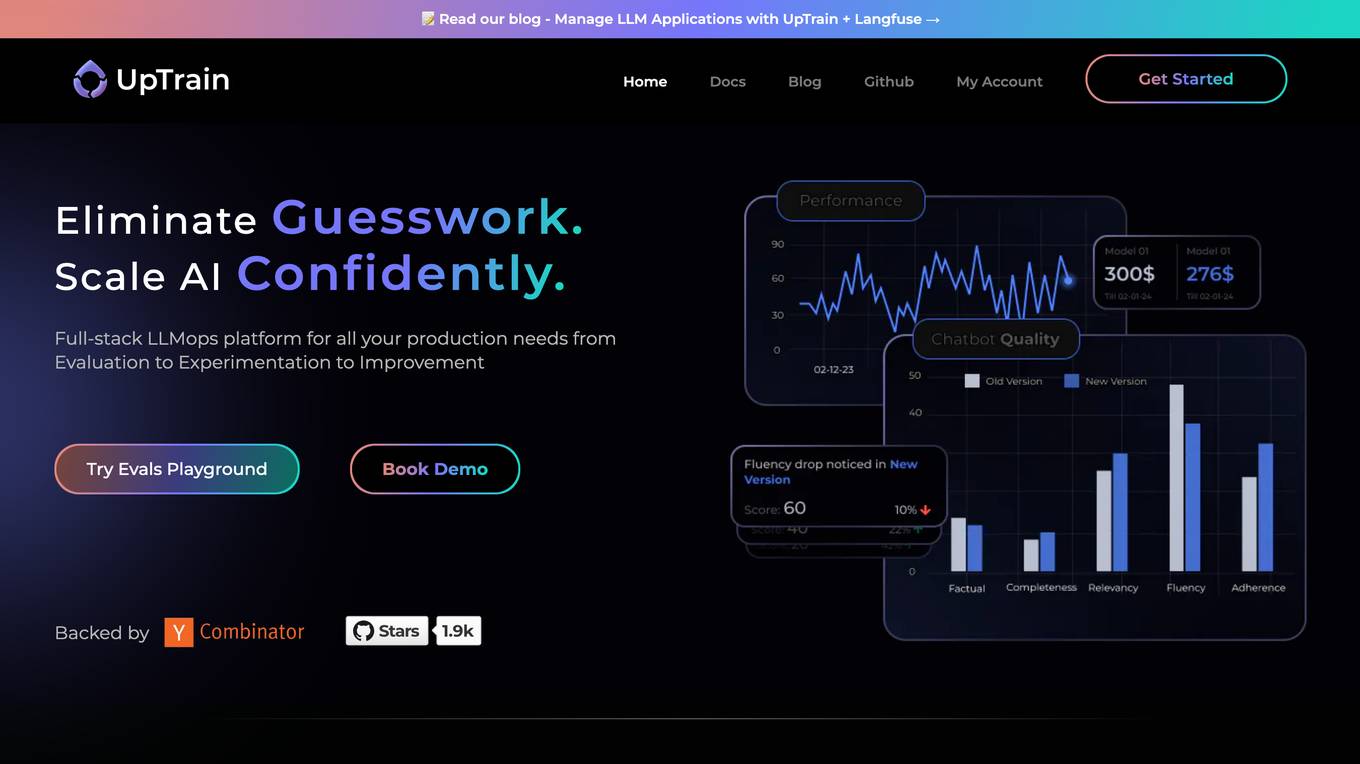
UpTrain
UpTrain is a full-stack LLMOps platform designed to help users with all their production needs, from evaluation to experimentation to improvement. It offers diverse evaluations, automated regression testing, enriched datasets, and precision metrics to enhance the development of LLM applications. UpTrain is built for developers, by developers, and is compliant with data governance needs. It provides cost efficiency, reliability, and open-source core evaluation framework. The platform is suitable for developers, product managers, and business leaders looking to enhance their LLM applications.
Workable
Workable is a leading recruiting software and hiring platform that offers a full Applicant Tracking System with built-in AI sourcing. It provides a configurable HRIS platform to securely manage employees, automate hiring tasks, and offer actionable insights and reporting. Workable helps companies streamline their recruitment process, from sourcing to employee onboarding and management, with features like sourcing and attracting candidates, evaluating and collaborating with hiring teams, automating hiring tasks, onboarding and managing employees, and tracking HR processes.

FinetuneDB
FinetuneDB is an AI fine-tuning platform that allows users to easily create and manage datasets to fine-tune LLMs, evaluate outputs, and iterate on production data. It integrates with open-source and proprietary foundation models, and provides a collaborative editor for building datasets. FinetuneDB also offers a variety of features for evaluating model performance, including human and AI feedback, automated evaluations, and model metrics tracking.
Career Copilot
Career Copilot is an AI-powered hiring tool that helps recruiters and hiring managers find the best candidates for their open positions. The tool uses machine learning to analyze candidate profiles and identify those who are most qualified for the job. Career Copilot also provides a number of features to help recruiters streamline the hiring process, such as candidate screening, interview scheduling, and offer management.
FindOurView
FindOurView is an AI-powered Discovery Insight Platform that provides instant discovery synthesis for teams. The platform reads interview transcripts, evaluates hypotheses, and brings results into team chats. It helps keep teams aligned with data at their fingertips, enabling instant evaluation of hypotheses without the need for tags. Users can easily bring discovery into decisions that matter, going as deep as they want with the available data. The platform aims to empower human alignment with AI, enabling empathic conversations, human insight, and confident decisions.
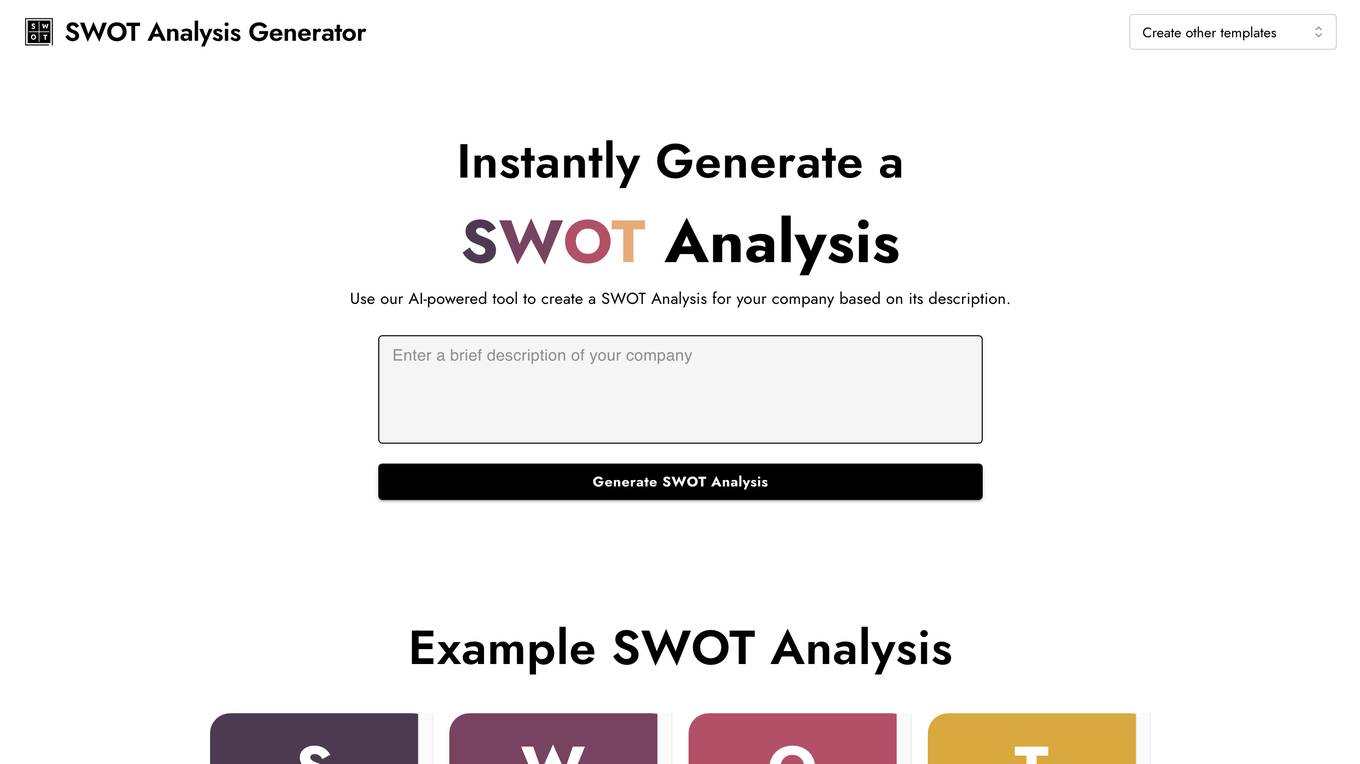
InstantPersonas
InstantPersonas is an AI-powered SWOT Analysis Generator that helps organizations and individuals evaluate their Strengths, Weaknesses, Opportunities, and Threats. By using a company description, the tool generates a comprehensive SWOT Analysis, providing insights for strategic planning and decision-making. InstantPersonas aims to assist users in understanding their target audience and market more successfully, enabling them to develop strategies to leverage strengths, address weaknesses, seize opportunities, and mitigate threats.
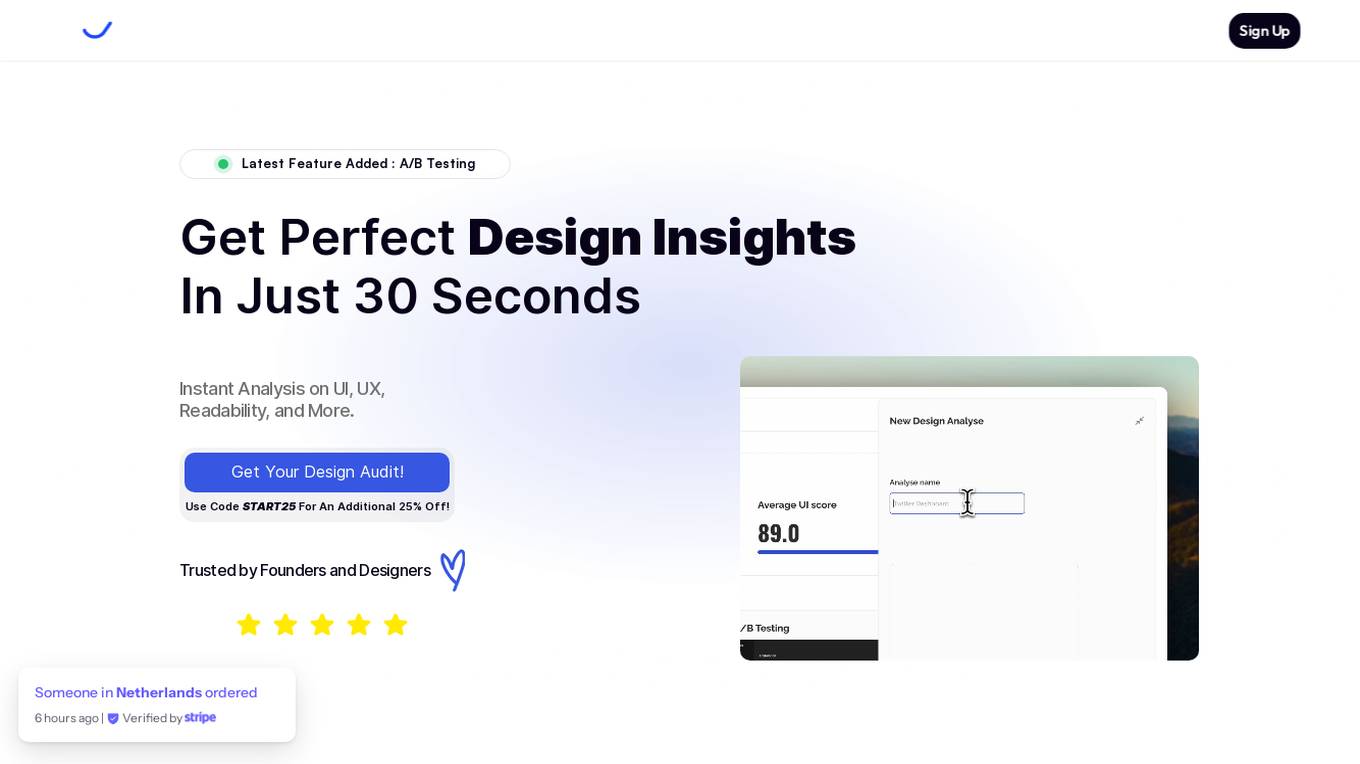
VisualHUB
VisualHUB is an AI-powered design analysis tool that provides instant insights on UI, UX, readability, and more. It offers features like A/B Testing, UI Analysis, UX Analysis, Readability Analysis, Margin and Hierarchy Analysis, and Competition Analysis. Users can upload product images to receive detailed reports with actionable insights and scores. Trusted by founders and designers, VisualHUB helps optimize design variations and identify areas for improvement in products.
20 - Open Source AI Tools


EasyEdit
EasyEdit is a Python package for edit Large Language Models (LLM) like `GPT-J`, `Llama`, `GPT-NEO`, `GPT2`, `T5`(support models from **1B** to **65B**), the objective of which is to alter the behavior of LLMs efficiently within a specific domain without negatively impacting performance across other inputs. It is designed to be easy to use and easy to extend.
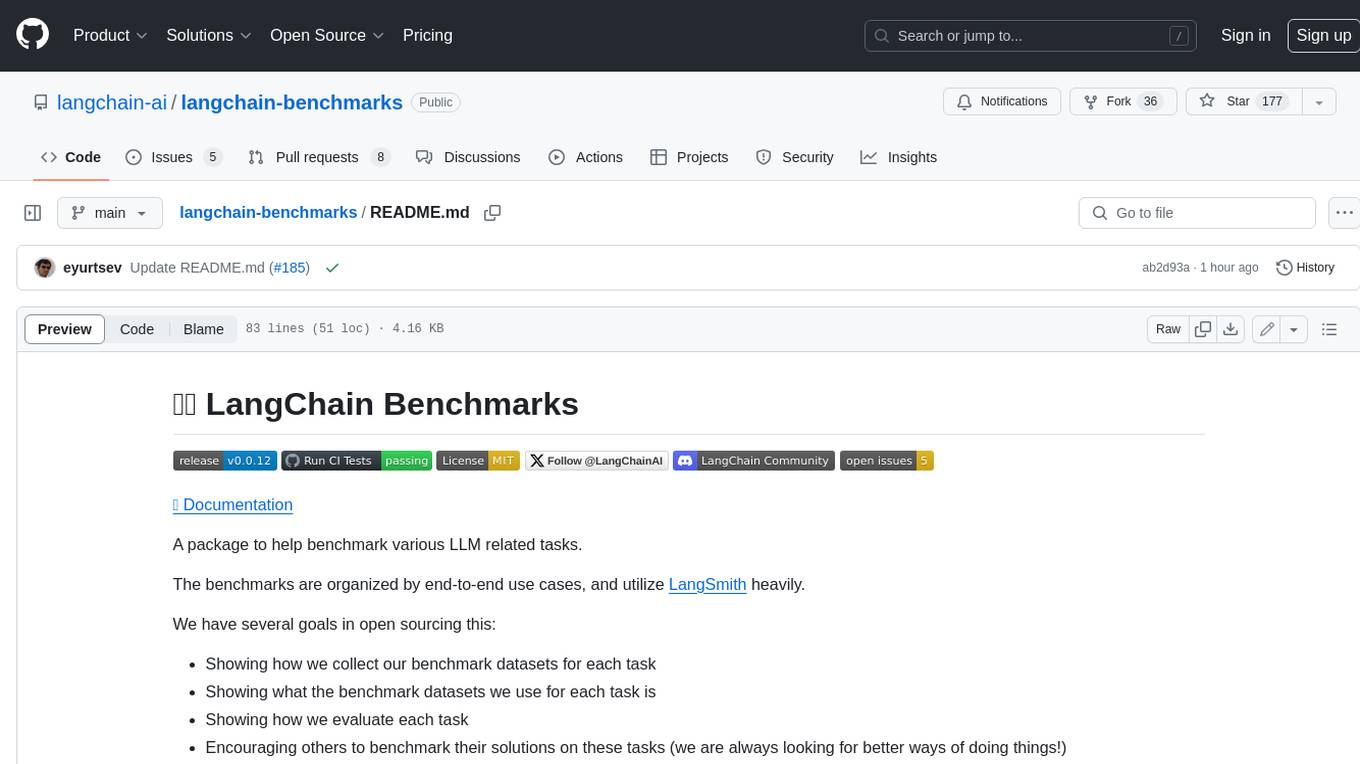
langchain-benchmarks
A package to help benchmark various LLM related tasks. The benchmarks are organized by end-to-end use cases, and utilize LangSmith heavily. We have several goals in open sourcing this: * Showing how we collect our benchmark datasets for each task * Showing what the benchmark datasets we use for each task is * Showing how we evaluate each task * Encouraging others to benchmark their solutions on these tasks (we are always looking for better ways of doing things!)
ragas
Ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM’s context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where Ragas (RAG Assessment) comes in. Ragas provides you with the tools based on the latest research for evaluating LLM-generated text to give you insights about your RAG pipeline. Ragas can be integrated with your CI/CD to provide continuous checks to ensure performance.
adversarial-robustness-toolbox
Adversarial Robustness Toolbox (ART) is a Python library for Machine Learning Security. ART provides tools that enable developers and researchers to defend and evaluate Machine Learning models and applications against the adversarial threats of Evasion, Poisoning, Extraction, and Inference. ART supports all popular machine learning frameworks (TensorFlow, Keras, PyTorch, MXNet, scikit-learn, XGBoost, LightGBM, CatBoost, GPy, etc.), all data types (images, tables, audio, video, etc.) and machine learning tasks (classification, object detection, speech recognition, generation, certification, etc.).
Awesome-LLM-in-Social-Science
This repository compiles a list of academic papers that evaluate, align, simulate, and provide surveys or perspectives on the use of Large Language Models (LLMs) in the field of Social Science. The papers cover various aspects of LLM research, including assessing their alignment with human values, evaluating their capabilities in tasks such as opinion formation and moral reasoning, and exploring their potential for simulating social interactions and addressing issues in diverse fields of Social Science. The repository aims to provide a comprehensive resource for researchers and practitioners interested in the intersection of LLMs and Social Science.

tonic_validate
Tonic Validate is a framework for the evaluation of LLM outputs, such as Retrieval Augmented Generation (RAG) pipelines. Validate makes it easy to evaluate, track, and monitor your LLM and RAG applications. Validate allows you to evaluate your LLM outputs through the use of our provided metrics which measure everything from answer correctness to LLM hallucination. Additionally, Validate has an optional UI to visualize your evaluation results for easy tracking and monitoring.
uptrain
UpTrain is an open-source unified platform to evaluate and improve Generative AI applications. We provide grades for 20+ preconfigured evaluations (covering language, code, embedding use cases), perform root cause analysis on failure cases and give insights on how to resolve them.

ollama-grid-search
A Rust based tool to evaluate LLM models, prompts and model params. It automates the process of selecting the best model parameters, given an LLM model and a prompt, iterating over the possible combinations and letting the user visually inspect the results. The tool assumes the user has Ollama installed and serving endpoints, either in `localhost` or in a remote server. Key features include: * Automatically fetches models from local or remote Ollama servers * Iterates over different models and params to generate inferences * A/B test prompts on different models simultaneously * Allows multiple iterations for each combination of parameters * Makes synchronous inference calls to avoid spamming servers * Optionally outputs inference parameters and response metadata (inference time, tokens and tokens/s) * Refetching of individual inference calls * Model selection can be filtered by name * List experiments which can be downloaded in JSON format * Configurable inference timeout * Custom default parameters and system prompts can be defined in settings
eval-scope
Eval-Scope is a framework for evaluating and improving large language models (LLMs). It provides a set of commonly used test datasets, metrics, and a unified model interface for generating and evaluating LLM responses. Eval-Scope also includes an automatic evaluator that can score objective questions and use expert models to evaluate complex tasks. Additionally, it offers a visual report generator, an arena mode for comparing multiple models, and a variety of other features to support LLM evaluation and development.
ByteMLPerf
ByteMLPerf is an AI Accelerator Benchmark that focuses on evaluating AI Accelerators from a practical production perspective, including the ease of use and versatility of software and hardware. Byte MLPerf has the following characteristics: - Models and runtime environments are more closely aligned with practical business use cases. - For ASIC hardware evaluation, besides evaluate performance and accuracy, it also measure metrics like compiler usability and coverage. - Performance and accuracy results obtained from testing on the open Model Zoo serve as reference metrics for evaluating ASIC hardware integration.

llm-jp-eval
LLM-jp-eval is a tool designed to automatically evaluate Japanese large language models across multiple datasets. It provides functionalities such as converting existing Japanese evaluation data to text generation task evaluation datasets, executing evaluations of large language models across multiple datasets, and generating instruction data (jaster) in the format of evaluation data prompts. Users can manage the evaluation settings through a config file and use Hydra to load them. The tool supports saving evaluation results and logs using wandb. Users can add new evaluation datasets by following specific steps and guidelines provided in the tool's documentation. It is important to note that using jaster for instruction tuning can lead to artificially high evaluation scores, so caution is advised when interpreting the results.

can-ai-code
Can AI Code is a self-evaluating interview tool for AI coding models. It includes interview questions written by humans and tests taken by AI, inference scripts for common API providers and CUDA-enabled quantization runtimes, a Docker-based sandbox environment for validating untrusted Python and NodeJS code, and the ability to evaluate the impact of prompting techniques and sampling parameters on large language model (LLM) coding performance. Users can also assess LLM coding performance degradation due to quantization. The tool provides test suites for evaluating LLM coding performance, a webapp for exploring results, and comparison scripts for evaluations. It supports multiple interviewers for API and CUDA runtimes, with detailed instructions on running the tool in different environments. The repository structure includes folders for interviews, prompts, parameters, evaluation scripts, comparison scripts, and more.
ice-score
ICE-Score is a tool designed to instruct large language models to evaluate code. It provides a minimum viable product (MVP) for evaluating generated code snippets using inputs such as problem, output, task, aspect, and model. Users can also evaluate with reference code and enable zero-shot chain-of-thought evaluation. The tool is built on codegen-metrics and code-bert-score repositories and includes datasets like CoNaLa and HumanEval. ICE-Score has been accepted to EACL 2024.

bocoel
BoCoEL is a tool that leverages Bayesian Optimization to efficiently evaluate large language models by selecting a subset of the corpus for evaluation. It encodes individual entries into embeddings, uses Bayesian optimization to select queries, retrieves from the corpus, and provides easily managed evaluations. The tool aims to reduce computation costs during evaluation with a dynamic budget, supporting models like GPT2, Pythia, and LLAMA through integration with Hugging Face transformers and datasets. BoCoEL offers a modular design and efficient representation of the corpus to enhance evaluation quality.
pyllms
PyLLMs is a minimal Python library designed to connect to various Language Model Models (LLMs) such as OpenAI, Anthropic, Google, AI21, Cohere, Aleph Alpha, and HuggingfaceHub. It provides a built-in model performance benchmark for fast prototyping and evaluating different models. Users can easily connect to top LLMs, get completions from multiple models simultaneously, and evaluate models on quality, speed, and cost. The library supports asynchronous completion, streaming from compatible models, and multi-model initialization for testing and comparison. Additionally, it offers features like passing chat history, system messages, counting tokens, and benchmarking models based on quality, speed, and cost.

babilong
BABILong is a generative benchmark designed to evaluate the performance of NLP models in processing long documents with distributed facts. It consists of 20 tasks that simulate interactions between characters and objects in various locations, requiring models to distinguish important information from irrelevant details. The tasks vary in complexity and reasoning aspects, with test samples potentially containing millions of tokens. The benchmark aims to challenge and assess the capabilities of Large Language Models (LLMs) in handling complex, long-context information.
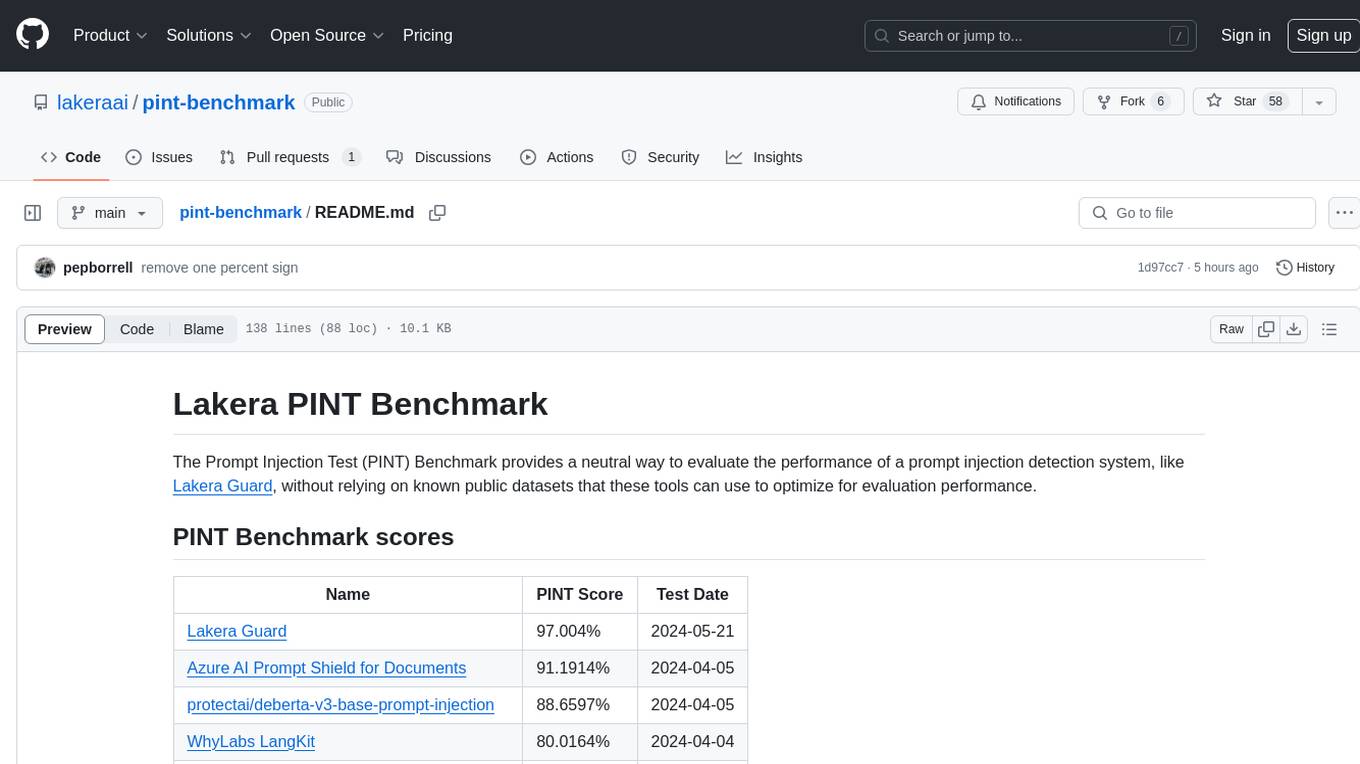
pint-benchmark
The Lakera PINT Benchmark provides a neutral evaluation method for prompt injection detection systems, offering a dataset of English inputs with prompt injections, jailbreaks, benign inputs, user-agent chats, and public document excerpts. The dataset is designed to be challenging and representative, with plans for future enhancements. The benchmark aims to be unbiased and accurate, welcoming contributions to improve prompt injection detection. Users can evaluate prompt injection detection systems using the provided Jupyter Notebook. The dataset structure is specified in YAML format, allowing users to prepare their datasets for benchmarking. Evaluation examples and resources are provided to assist users in evaluating prompt injection detection models and tools.

arena-hard-auto
Arena-Hard-Auto-v0.1 is an automatic evaluation tool for instruction-tuned LLMs. It contains 500 challenging user queries. The tool prompts GPT-4-Turbo as a judge to compare models' responses against a baseline model (default: GPT-4-0314). Arena-Hard-Auto employs an automatic judge as a cheaper and faster approximator to human preference. It has the highest correlation and separability to Chatbot Arena among popular open-ended LLM benchmarks. Users can evaluate their models' performance on Chatbot Arena by using Arena-Hard-Auto.
20 - OpenAI Gpts

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model


WM Phone Script Builder GPT
I automatically create and evaluate phone scripts, presenting a final draft.

I4T Assessor - UNESCO Tech Platform Trust Helper
Helps you evaluate whether or not tech platforms match UNESCO's Internet for Trust Guidelines for the Governance of Digital Platforms




Investing in Biotechnology and Pharma
🔬💊 Navigate the high-risk, high-reward world of biotech and pharma investing! Discover breakthrough therapies 🧬📈, understand drug development 🧪📊, and evaluate investment opportunities 🚀💰. Invest wisely in innovation! 💡🌐 Not a financial advisor. 🚫💼

B2B Startup Ideal Customer Co-pilot
Guides B2B startups in a structured customer segment evaluation process. Stop guessing! Ideate, Evaluate & Make data-driven decision.

Education AI Strategist
I provide a structured way of using AI to support teaching and learning. I use the the CHOICE method (i.e., Clarify, Harness, Originate, Iterate, Communicate, Evaluate) to ensure that your use of AI can help you meet your educational goals.

Competitive Defensibility Analyzer
Evaluates your long-term market position based on value offered and uniqueness against competitors.

Vorstellungsgespräch Simulator Bewerbung Training
Wertet Lebenslauf und Stellenanzeige aus und simuliert ein Vorstellungsgespräch mit anschließender Auswertung: Lebenslauf und Anzeige einfach hochladen und starten.


IELTS Writing Test
Simulates the IELTS Writing Test, evaluates responses, and estimates band scores.
Academic Paper Evaluator
Enthusiastic about truth in academic papers, critical and analytical.